Definição: Uma matriz é uma coleção de elementos estabelecidos em linhas e colunas, da seguinte forma:
$$
A_{m \times n} = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n} \\
a_{21} & a_{22} & \cdots & a_{2 n} \\
\vdots & & & \vdots \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right],
$$
onde \(a_{i j} \) representa o elemento na \(i\)-ésima linha e \(j\) -ésima coluna. A matriz acima, portanto, tem \(m\) linhas e \(n\) colunas e dizemos que esta matriz tem dimensão \(m \times n\) . Como delimitadores de uma matriz podemos usar colchetes [ ] ou parênteses ( ), de acordo com a conveniência. Também podemos representar uma matriz por meio de um elemento genérico, colocado entre colchetes para indicar que se trata de uma coleção de linhas e coluna, na forma de
$$
A_{m \times n} = \{a_{i j} \},\;\; i = 1, \ldots, m, j = 1, \ldots, n,
$$
e, em algumas situações, nos referiremos a um elemento genérico da matriz \(A\) por \((A)_{i j} = a_{i j}\) . Os exemplos dados abaixo servirão para ilustrar este conceito e apresentar algumas matrizes de tipos mais comuns e mais utilizadas.
Exemplo: A matriz \(A\) abaixo é uma matriz \(2 \times 2\) , portanto uma matriz quadrada,
$$
A = \left[ \begin{array}{ll}
1 & 3\\
4 & 5
\end{array} \right],
$$
onde os elementos \(a_{11} = 1\) , \(a_{22} = 5\) , só para citar alguns exemplos. A matriz
$$
B = \left[ \begin{array}{ll}
1 & – 2\\
3 & \;0\\
5 & \;4
\end{array} \right]
$$
é uma matriz \(3 \times 2\) (ou seja, tem 3 linhas e duas colunas) enquanto \(C = [1]\) é uma matriz \(1 \times 1\) . Matrizes \(n \times 1\) são denominadas matrizes colunas, tais como \(D_{4 \times 1}\) abaixo
$$
D = \left[ \begin{array}{l}
2\\
0\\
1\\
3
\end{array} \right],
$$
enquanto matrizes \(1 \times n\) são denominadas matrizes linhas, tais como \(E = [1, 2, 6] .\) Uma matriz nula possue todos os seus componentes nulos,
$$
F = \left[ \begin{array}{ll}
0 & 0\\
0 & 0
\end{array} \right] .
$$
Podemos usar o símbolo \(\tilde{0}\) para representar a matriz nula quando isto for interessante para a discussão do momento. Uma matriz identidade é uma matriz quadrada com todos os elementos nulos exceto os da diagonal principal, que são de uma unidade, como \(\mathbb{I}_{3 \times 3}\) abaixo,
$$
\mathbb{I}= \left[ \begin{array}{lll}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{array} \right] .
$$
Observe que \(\mathbb{I}\) (ou outra matriz identidade de qualquer dimensão) tem elementos
$$
(I)_{i j} = \delta_{i j} = \left\{ \begin{array}{ll}
1 & \text{se } i = j,\\
0 & \text{se} i \neq j.
\end{array} \right.
$$
O símbolo \(\delta\) definido desta forma é o chamado delta de Kronecker. Logo ficará claro porque chamamos esta matriz de identidade. E interessante ainda definir as matrizes diagonais como aquelas que possuem todos os elementos nulos exceto os da diagonal principal, que podem ter qualquer valor, como
\begin{eqnarray*}
& & G = \left[ \begin{array}{lll}
7 & 0 & 0\\
0 & – 1 & 0\\
0 & 0 & 1
\end{array} \right],
\end{eqnarray*}
e as matrizes simétricas, que são aquelas que permanecem inalteradas quando suas linhas são tomadas como colunas, tal como
$$
H = \left[ \begin{array}{lll}
3 & 2 & 1\\
2 & 0 & 7\\
1 & 7 & 1
\end{array} \right] .
$$
Alternativamente, definimos a matriz \(H = \{h_{i j} \}\) como simétrica se \(h_{i j} = h_{j i}\) .
Definição: Se \(A\) é uma matriz \(n \times m\) sua transposta e a matriz \(A’_{m \times n} \) obtida de \(A\) por meio da transposição de suas linhas em colunas, \((A)_{i j} = (A’)_{j i}\) .
Exemplo: A transposta da matriz \(B\) acima é
$$
B’ = \left[ \begin{array}{ccc}
1 & 3 & 5\\
– 2 & 0 & 4
\end{array} \right] .
$$
As seguintes propriedades podem ser verificadas quanto à transposição de matrizes:
(i) Se \(S\) é uma matriz simétrica então \(S’ = S\) ,ou seja, uma matriz simétrica é igual a sua transposta.
(ii) \(A’ ‘ = A\) ,
(iii) \((A + B)’ = A’ + B’\) ,
(iv) \((k A)’ = k A’\) .
Definição: dizemos que duas matrizes são iguais se, e somente se, tem a mesma ordem e todos os seus elementos correspondentes (na mesma linha e mesma coluna) são iguais;
$$
A = B \Leftrightarrow a_{i j} = b_{i j.}
$$
A álgebra das Matrizes
Tendo definido as matrizes podemos agora definir uma álgebra ou um conjunto de operações sobre estes elementos.
1) Adição: Se \(A\) e \(B\) são matrizes de mesma ordem então \((A + B)_{i j} = a_{i j} + b_{i j}\) .
onde \(\mathbb{I}_{3 \times 3}\) é a matriz identidade .
As seguintes propriedades são válidas para as operações já consideradas: se \(A\) e \(B\) são matrizes de mesma ordem, \(k\) e \(l \) são escalares então:
(i) \(k (A + B) = k A + k B\) ;
(ii) \((k + l) A = k A + l A\) ;
(iii) \(0 \cdot A = \tilde{0}\) ;
(iv) \(k (l A) = (k l) A\) .
Observe na propriedade (iii) que o produto de qualquer matriz pelo escalar \(0\) é a matriz nula \(\tilde{0}\) embora seja costume representar este resultado simplesmente pelo número 0. Um outro exemplo onde isto pode ocorrer é o seguinte
$$
\left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] – \left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] = 0,
$$
onde o resultado escrito como 0 por abuso de linguagem, na verdade significa a matriz \(\tilde{0}\) de dimensões \(2 \times 2\) .
3) Multiplicação de matrizes
Dadas as matrizes \(A_{m \times n}\) e \(B_{n \times p}\) (notando portanto que \(B\) tem um número de linhas igual ao número de colunas de \(A\) ) definimos o produto de \(A\) por \(B\) da seguinte forma
$$
(A B)_{i j} = \sum^n_{k = 1} a_{i k} b_{k j} .
$$
Isto significa que o elemento da \(i\) -ésima linha e \(j\) -ésima coluna é obtido pela soma dos produtos de elementos da \(i\) -ésima linha de \(A\) com a \(j\) -ésima coluna de \(B\) . O produto é a matriz \(A B\) de dimensões \(m \times p\) . Alguns exemplos servirão para esclarecer este procedimento. No entanto é útil compreender a operação indicada simbolicamente pelo somatório acima.
Neste último exemplo observamos que, além da não co mutatividade do produto de matrizes, é possível que o produto de duas matrizes seja nulo sem que nenhuma delas seja a matriz nula.
Propriedades do produto de matrizes
(i) \(A B \neq B A\) ,
(ii) \(A\mathbb{I}=\mathbb{I}A = A\) , onde \(\mathbb{I}\) é a matriz identidade (e dai o seu nome),
(iii) \(A (B + C) = A B + A C\) ,(distributividade à esquerda),
(iv) \((B + C) A = B A + C A\) , (distributividade à direita),
(v) \((A B) C = A (B C)\) , (associatividade),
(vi) \((A B)’ = B’ A’\) ,
(vii) \(\tilde{0} A = A \tilde{0} = \tilde{0}\) , onde \(\tilde{0}\) é a matriz nula.
Sistemas de equações lineares
Definição: Um sistema com \(m\) equações lineares com \(n\) incógnitas é um conjunto de equações da forma de
\begin{eqnarray*}
a_{11} x_1 + a_{12} x_2 + \ldots + a_{1 n} x_n = b_1 & & \\
a_{21} x_1 + a_{22} x_2 + \ldots + a_{2 n} x_n = b_2 & & \\
\vdots & & \\
a_{m 1} x_1 + a_{m 2} x_2 + \ldots + a_{m n} x_n = b_m & &
\end{eqnarray*}
onde \(a_{i j}, 1 \leq i \leq m, 1 \leq j \leq n,\) são números reais (ou complexos) e \(x_k, 1 \leq k \leq n\) são \(n\) incógnitas. Uma solução do sistema acima, quando existir, é uma \(n\) -upla \((x_1, x_2, \ldots, x_n)\) que satisfaz simultaneamente as \(m\) equações do sistema. Podemos escrever o mesmo sistema sob forma matricial
$$
\left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \vdots\\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right] \left[ \begin{array}{l}
x_1\\
x_2\\
\vdots\\
x_n
\end{array} \right] = \left[ \begin{array}{l}
b_1\\
b_2\\
\vdots\\
b_m
\end{array} \right],
$$
sendo que \(A\) é denominada matriz dos coeficientes do sistema, \(X\) é a matriz das incógnitas e \(B\) a matriz dos termos constantes. Alternativamente é útil escrever o mesmo sistema como o conjunto das equações
\begin{eqnarray*}
\sum_{j = 1}^n a_{1 j} x_j = b_{1,} & & \\
\sum_{j = 1}^n a_{2 j} x_j = b_{2,} & & \\
\vdots & & \\
\sum_{j = 1}^n a_{m j} x_j = b_{m,} & &
\end{eqnarray*}
ou, de modo compacto,
$$
\sum_{j = 1}^n a_{i j} x_j = b_{i,} 1 \leq i \leq m.
$$
Embora todas estas formas de se escrever o sistema de equações sejam equivalentes, é útil compreender cada uma delas. A notação de somatório é poderosa, principalmente para demonstrações e considerações teóricas sobre este e muitos outros tópicos.
Sistemas lineares aparecem em um grande número de aplicações e é necessário que se aprenda técnicas para encontrar suas soluções. Para isto apresentamos as definições abaixo.
É usual, mas não obrigatório, o uso da barra de separação entre os termos \(a_{i j}\) e \(b_k\) .
Definição: Dois sistemas de equações lineares são ditos equivalentes se, e somente se, toda a solução de um deles é igualmente solução do outro.
Podemos obter sistemas equivalentes por meio das chamadas operações elementares:
(i) permutação de duas equações;
(ii) multiplicação de um das equações por um escalar;
(iii) substituição de uma das equações por sua soma com outra das equações do sistema.
Em termos das matrizes ampliadas associadas ao sistema estas mesmas operações significam as operações elementares sobre as linhas desta matriz. Exemplificando estas operações elementares sobre linhas de uma matriz temos:
(ii) Multiplicação de uma linha por um escalar: \(k L_i \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
1 & 2\\
5 & 6
\end{array} \right] 3 L_2 \rightarrow L_2 \left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
(iii) Substituição de uma linha por sua soma com outra linha: \(L_i + L_j \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] L_1 + L_2 \rightarrow L_1 \left[ \begin{array}{ll}
6 & 10\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
Definição: Duas matrizes são equivalentes se uma pode ser obtida da outra por meio de um número finito de operações elementares. Denotaremos a equivalência entre duas matrizes \(A\) e \(B\) por meio do símbolo \(A \sim B\) .
Definição: uma matriz está em sua forma linha reduzida à forma escada se
O primeiro elemento de cada linha é 1. Chamaremos de piloto a este elemento.
Cada coluna que possue um elemento piloto de alguma das linhas contém todos os demais elementos nulos.
O piloto de cada linha ocorre em colunas progressivas.
Linhas inteiramente nulas ocorrem abaixo de todas as demais.
A matriz reduzida à sua forma escada terá a forma indicada na figura.
Uma vez que as operações elementares sobre um sistema de equações lineares não alteram a solução do sistema, e que matrizes equivalentes são obtidas uma da outra por meio de operações elementares sobre suas linhas, podemos concluir que dois sistemas cujas matrizes ampliadas são equivalentes possuem a mesma solução ou soluções, quando estas existirem. Isto nos permite enunciar um método de solução.
Método de Gauss-Jordan para solução de sistema lineares
O método de Gauss-Jordan consiste no seguinte procedimento:
Dado um sistema de equações lineares começamos por escrever a sua matriz ampliada associada.
Através de operações elementares sobre linhas da matriz ampliada obtemos a matriz equivalente reduzida à forma escada.
A matriz equivalente reduzida à forma escada será associada a um sistema onde a solução do sistema original é de fácil leitura.
Vamos ilustrar estas operações elementares por meio de um exemplo. Nele indicaremos as operações realizadas sobre as linhas de uma matriz amplida apenas para efeito de acompanhanto do leitor. A operação \(L_1 + L_2 \rightarrow L_2\) , por exemplo, significa: substitua a linha 2 pela soma da linha 2 com a linha 1.
Exemplo . O sistema
\begin{eqnarray*}
x + 4 y + 3 z = 1 & & \\
2 x + 5 y + 4 z = 4 & & \\
x – 3 y – 2 z = 5 & &
\end{eqnarray*}
pode ser representado matricialmente por
$$
\left[ \begin{array}{lll}
1 & 4 & 3\\
2 & 5 & 4\\
1 & – 3 & – 2
\end{array} \right] \left[ \begin{array}{l}
x\\
y\\
z
\end{array} \right] = \left[ \begin{array}{l}
1\\
4\\
5
\end{array} \right]
$$
que é a solução do sistema inicial, como pode ser verificado por substituição direta.
Exercício resolvido: resolva o sistema
\begin{eqnarray*}
x + 2 y + 3 z = 9 & & \\
2 x – y + z = 8 & & \\
3 x – z = 3. & &
\end{eqnarray*}
A matriz ampliada associada a este sistema é
$$
A = \left[ \begin{array}{lll}
1 & 2 & 3\\
2 & – 1 & 1\\
3 & 0 & – 1
\end{array} \begin{array}{l}
9\\
8\\
3
\end{array} \right] .
$$
Para o leitor que considere isto necessário seguem alguns comentários sobre os passos executados nesta operação:
\(\{p_1 \}\) zeramos o elemento na coluna 1, onde ocorre o piloto da primeira linha;
\(\{p_2 \}\) idem para a linha 3;
\(\{p_3 \}\) introduzimos o piloto da linha 2;
\(\{p_4 \}\) apenas uma simplificação para os cálculos posteriores;
\(\{p_5 \}\) zeramos \(a_{12}\) ;
\(\{p_6 \}\) zeramos \(a_{32}\) ;
\(\{p_7 \}\) introduzimos o piloto da linha 3;
\(\{p_8 \}\) zeramos \(a_{13}\) ;
\(\{p_9 \}\) zeramos \(a_{23}\) . O procedimento é interrompido porque atingimos a matriz equivalente na forma reduzida .
é claro que não existe uma única forma para se atingir a matriz na forma escada e, algumas vezes, uma escolha apropriada de passos pode reduzir muito o trabalho necessário para atingí-la. No entanto, se um passo mais hábil ou mais rápido não for percebido, podemos executar etapas intermediárias que facilitem este processo. Para quem está aprendendo a operação pode ser preferível realizar um número maior de passos e um de cada vez.
Algumas vezes é necessário saber se existem uma ou mais soluções para um sistema linear. As definições dadas a seguir nos permitem obter esta informação mesmo sem resolvê-lo.
Definição: Seja \(A_{m \times n}\) uma matriz e \(B_{m \times n}\) sua matriz equivalente reduzida à forma escada. \(p\) ,o posto de \(A\) , é o número de linhas não nulas de \(B\) . A nulidade de \(A\) é igual ao número de colunas menos o posto, \(n – p\) .
Exemplo . Qual é o posto e a nulidade da matriz \(A\) dada abaixo?
$$
\begin{array}{ll}
A = & \left[ \begin{array}{l}
\begin{array}{llll}
1 & 2 & 1 & 0\\
– 1 & 0 & 3 & 5\\
1 & – 2 & 1 & 1
\end{array}
\end{array} \right] .
\end{array}
$$
\begin{eqnarray*}
\begin{array}{lll}
\sim & \left[ \begin{array}{lll}
1 & 0 & 14 / 9\\
0 & 1 & 1 / 9\\
0 & 0 & 0\\
0 & 0 & 0
\end{array} \right] = C & .
\end{array} & &
\end{eqnarray*}
sendo que a matriz \(B\) está em sua reduzida. O posto de \(A\) é \(p = 3\) porque \(B\) tem 3 linhas não nulas. Como \(A\) tem \(n = 4\) colunas, a nulidade de \(A\) é \(n – p = 1\) .
Continuando com a questão da existência de soluções vamos examinar alguns casos ilustrativos de sistemas e suas soluções.
(1) Sistema trivial, com uma incógnita e uma equação
$$
a x = b.
$$
Os seguintes casos podem ocorrer:
Se \(a \neq 0\) então existe uma única solução, \(x = b / a\) .
Se \(a = 0\) e \(b = 0\) o sistema é \(0 x = 0\), satisfeito por qualquer valor de \(x\) . Existem, portanto, infinitas soluções.
Se \(a = 0\) e \(b \neq 0\) o sistema \(0 x = b\) , não é satisfeito por nenhum valor de \(x\) , ou seja, não existem soluções.
(2) Sistema com uas equações e duas incógnitas.
Exemplo:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
x – 3 y = 6
\end{array} \right.
$$
Embora este seja um sistema de fácil solução por meio de uma simples substituição, para efeito de exercício da técnica aprendida, escrevemos matriz ampliada e suas matrizes equivalentes,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 7 / 2 & – 7 / 2
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 1 & – 1
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 0 & 3\\
0 & 1 & – 1
\end{array} \right], & &
\end{eqnarray*}
ou seja, \(x = 3\) e \(y = – 1\) é a solução única do sistema. A
matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
1 & – 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 0\\
0 & 1
\end{array} \right] & &
\end{eqnarray*}
tem posto 2 enquanto a matriz ampliada também tem posto 2. Lembramos ainda que \(n = 2\) é o número de incógnitas envolvidas. Como se pode ver na figura cada equação do sistema corresponde a uma reta do plano e a solução é dada pelo único ponto comum entre elas.
Exemplo 2:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 15
\end{array} \right.
$$
A matriz ampliada e suas matrizes equivalentes são, por exemplo,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 15
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & 0
\end{array} \right], & &
\end{eqnarray*}
indicando que existem infinitas soluções, que são todos os pontos da reta \(x + y / 2 = 5 / 2\) . Observamos que as duas equações do
sistema são uma múltiplo da outra e representam a mesma reta. A matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
6 & 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 1 / 2\\
0 & 0
\end{array} \right] & &
\end{eqnarray*}
tem posto 1 e a matriz ampliada também tem posto 1. A nulidade de \(A\) é 2 enquanto a nulidade da matriz dos coeficientes é 1. Geometricamente as duas equações do sistema são repreentadas pela mesma (uma delas é meramente um múltiplo da outra) e todos os pontos que satisfazem a primeira equação satisfazem também a segunda.
Exemplo: O sistema
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 10
\end{array} \right.
$$
pode ser resolvido da mesma forma; a matriz ampliada e sua reduzida são
\begin{eqnarray*}
A = \left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 10
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & – 5
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 0\\
0 & 0 & 1
\end{array} \right], & &
\end{eqnarray*}
que representam um sistema sem solução. O posto de \(A\) é 2 e o posto da matriz dos coeficientes é 1. Geometricamente as duas linhas são equações de retas são paralelas que, por isto, não possuem pontos comuns.
Relacionando o número de equações, incógnitas e o posto das matrizes ampliada e dos coeficientes temos o seguinte resultado:
Teorema: Dado um sistema de \(m\) equações e \(n\) incógnitas, denotamos por \(p_A \)o posto da matriz ampliada e \(p_C \) o posto da matriz dos coeficientes. Então
A condição \(p_A = p_C\) é necessária e suficiente para que o sistema admita uma ou mais soluções;
A condição \(p_A = p_C = n\) é necessária e suficiente para que o sistema admita uma única solução;
Se \(p_A = p_C \lt n\) então o sistema pode ser resolvido para \(p\) incógnitas em função das \(n – p\) incógnitas restantes.
Sistema linear de 3 equações e 3 incógnitas
Sistema de três equações e três incógnitas: Cada uma das equações pode ser representada por um plano, P1, P2 e P3. Podem ocorrer, por exemplo, algumas dessas situações: (i) os planos são paralelos e não coincidentes; não existe nenhuma solução para o sistema; (ii) dois planos são coincidentes e interceptam o terceiro plano em uma reta. Neste caso existem infinitas soluções (os pontos da reta). (iii) Nenhum dos planos é paralelo a outro. Esta é a situação mostrada na figura 6 e existe uma única solução.
Equações diferenciais são equações que envolvem uma função desconhecida de uma ou mais variáveis, e suas derivadas. Para uma função real de uma única variável, \(y=y(x)\), podemos expressar estas equações sob a forma geral de
$$
F(x,\,y,\,y^{\prime},\,y^{\prime\prime},\ldots,\,y^{(n)})=0,
$$
onde usamos a notação
$$
y^{\prime}=\frac{dy(x)}{dx},\,\,\,y^{\prime\prime}=\frac{d^{2}y(x)}{dx^{2}},\ldots,\,\,\,y^{(n)}=\frac{d^{n}y(x)}{dx^{n}}.
$$
As equações que envolvem derivadas em apenas uma variável são chamadas equações diferenciais ordinárias. Caso contrário, equações que envolvem derivadas em mais de uma variável são chamadas de equações diferenciais parciais. Para não sobrecarregar a notação, sempre que não houver risco de ambiguidade, escreveremos apenas \(y\) em lugar de \(y(x),\,\,\,y^{\prime}\) em lugar de \(y^{\prime}(x)\) ou \(dy(x)/dx,\) e assim por diante.
Estas equações representam uma parte da matemática muito utilizada em aplicações na física, na engenharia e diversas outras áreas do conhecimento. A absoluta maioria das leis da física são expressas por meio de equações diferenciais, como por exemplo a lei de Newton \(F=ma\), ou as equações de Maxwell para o eletromagnetismo.
Alguns exemplos podem ajudar a esclarecer os conceitos envolvidos:
Exemplo 1. Que função é idêntica à sua própria derivada? A resposta para esta pergunta é a solução da equação diferencial \(y’=y\). Ora, podemos nos lembrar, sem o uso de nenhuma técnica de solução, que a função \(y(x)=e^{x}\) satisfaz este requisito. Observe que a resposta mais geral é \(y(x)=Ce^{x}\), onde \(C\) é uma constante qualquer.
No exemplo anterior, encontramos não apenas uma mas infinitas soluções para a equação proposta. Uma constante de integração está sempre presente na solução de uma equação diferencial de primeira ordem. Como veremos existem várias técnicas para se encontrar soluções de equações como a do exemplo 1. Uma solução de uma equação diferencial é uma função que, quando substituída na equação original, a transforma em uma identidade.
Exemplo 2. Qual é a solução (ou soluções, se existirem mais de uma) de \(y^{\prime\prime}+y=0\)?
Conhecemos duas funções elementares que satisfazem esta equação: \(y_{1}=\text{sen}\,x\) e \(y_{2}=\cos x\). Verifique, derivando duas vezes e substituindo na equação diferencial que
$$
y(x)=C_{1}\text{sen}\,x+C_{2}\cos x
$$
onde \(C_{1}\) e \(C_{2}\) são constantes arbitrárias, é solução.
Exemplo 3. Vamos procurar a equação de movimento para uma partícula submetida a uma aceleração constante \(g\). Iniciamos por descrever a posição da partícula como \(x(t)\), onde a variável independente agora é \(t\), o tempo. Usaremos a notação inventada por Newton que consiste em representar a derivada em relação ao tempo por meio de um ponto sobre a quantidade derivada. Assim sua velocidade é a derivada primeira
$$
\frac{d}{dt}x(t)=\dot{x}(t)
$$
enquanto a aceleração é a derivada segunda
$$
\frac{d^{2}}{dt^{2}}x(t)=\ddot{x}(t).
$$
A segunda lei nos diz que
$$
F=ma\Rightarrow mg=m\ddot{x}\Rightarrow\ddot{x}=g.
$$
Resolvendo primeiro para a velocidade temos que
$$
\dot{x}(t)=gt+c_{1},
$$
onde \(c_{1}\) é uma constante qualquer, notando que esta é a expressão mais geral da função que, quando derivada em relação à \(t\), resulta na constante \(g\). Já a posição da partícula é dada pela função primitiva que, ao ser derivada, resulta na velocidade acima,
$$
x(t)=\frac{1}{2}gt^{2}+c_{1}t+c_{2}
$$
como pode ser verificado diretamente, por dupla derivação e substituição na equação inicial. Podemos ainda utilizar este exemplo para esclarecer um pouco mais sobre o papel das constantes de integração,
\(c_{1}\) e \(c_{2}\). No instante \(t=0\) temos que
$$
\dot{x}(0)=c_{1},\,\,\,x(0)=c_{2},
$$
o que mostra que \(c_{1}\) é velocidade inicial da partícula enquanto \(c_{2}\) é sua posição inicial. Isto reflete um fato físico: para descrever completamente a posição de uma partícula submetida a uma aceleração \(g\) é necessário fornecer sua posição e velocidade iniciais. Renomeando \(c_{1}=v_{0},\,\,\,c_{2}=x_{0}\), respectivamente velocidade e posição iniciais, podemos escrever
$$
x(t)=x_{0}+v_{0}t+\frac{1}{2}gt^{2},
$$
que é a conhecida expressão para o movimento uniformemente acelerado.
Exemplo 4. As equações diferenciais surgem com freqüência em problemas de geometria. Por exemplo, a equação da circunferência com centro na origem e raio \(r\) é
$$
x^{2}+y^{2}=r^{2}.
$$
Considerando \(y\) uma função de \(x\) e fazendo a derivação implícita da expressão acima em relação a \(x\) obtemos
$$
x+yy^{\prime}=0,
$$
ou seja,
$$
y^{\prime}=-\frac{x}{y},
$$
que é a equação diferencial cuja solução é a equação da circunferência. Observe que \(y^{\prime}\) é a inclinação da curva em cada ponto e que o raio não aparece nesta equação. Ele fica determinado pelas condições de contorno, como veremos mais tarde.
Classificações e Definições
Equações Ordinárias e Parciais
Já vimos que as equações diferenciais ordinárias são aquelas que envolvem apenas derivadas em uma variável independente. Todos os exemplos acima são de equações ordinárias. Existem também as equações diferenciais parciais que surgem em muitas áreas da ciência. São exemplos de equações parciais:
(a) equação de onda em uma dimensão,
$$
\frac{\partial^{2}u(x,t)}{\partial x^{2}}=\frac{1}{c^{2}}\frac{\partial^{2}u(x,t)}{\partial t^{2}},
$$
onde \(u\) representa um deslocamento no meio de propagação ou vetor de onda, para o caso em que não existe um meio de propagação, como ocorre com as ondas eletromagnéticas. Pode-se mostrar que \(c\) é a velocidade de propagação da onda.
(b) a equação de difusão do calor
$$
\frac{\partial T(x,t)}{\partial t}=k\frac{\partial^{2}T(x,t)}{\partial x^{2}},
$$
onde \(T\) é a temperatura e \(k\) uma constante que depende do material por onde o calor se difunde.
(c) em três dimensões, o potencial elétrico descrito por \(\phi(x,y,z)\) satisfaz a equação de Laplace
$$
\nabla^{2}\phi=0
$$
na ausência de cargas elétricas, onde \(\nabla^{2}\) é o Laplaciano. Em coordenadas cartesianas,
$$
\nabla^{2}=\frac{\partial^{2}}{\partial x^{2}}+\frac{\partial^{2}}{\partial y^{2}}+\frac{\partial^{2}}{\partial z^{2}}.
$$
Na presença de cargas elétricas o potencial satisfaz a equação de Poisson
$$
\nabla^{2}\phi=-\frac{\rho}{\varepsilon_{0}},
$$
onde \(\rho\) é a distribuição de cargas e \(\varepsilon_{0}\) uma constante característica do meio.
Estes exemplos ilustram a existência das equações parciais e não podem ser plenamente compreendidos por enquanto. Neste curso trataremos apenas das equações diferenciais ordinárias, e não das diferenciais parciais. No entanto elas são frequentemente resolvidas através de uma separação de variáveis que as transformam em um sistema de equações ordinárias, de forma que as técnicas aqui estudadas são importantes para as suas soluções.
Ordem de uma Equação Diferencial
A ordem de uma equação diferencial é definida como sendo a derivada de maior ordem que nela aparece. Equações de primeira ordem contém apenas a derivada primeira, de segunda ordem a derivada segunda e assim por diante. Equações de primeira e segunda ordem são as mais comuns em aplicações na física e na engenharia. A equação do exemplo 4,
$$
y^{\prime}=-\frac{x}{y},
$$
é de primeira ordem, enquanto no exemplo 3, a equação de Newton, envolve uma equação de segunda ordem,
$$
\ddot{x}=g.
$$
A equação
$$
y^{\prime\prime\prime}+y=0
$$
é uma equação de terceira ordem.
Equações lineares e não lineares
Se uma equação diferencial pode ser escrita sob a forma
$$
a_{0}y+a_{1}y’+a_{2}y^{\prime\prime}+a_{3}y^{\prime\prime\prime}+\cdots a_{n}y^{(n)}=r(x),
$$
onde \(a_{i}\,\,(i=0,1,2,…)\) são constantes, então ela é dita uma equação linear. Caso contrário ela é não linear. As equações diferenciais
$$
y^{\prime\prime}+2y’+y=0,
$$
$$
3y^{\prime}+2y=1
$$
são lineares, enquanto
$$
y^{\prime}+y^{2}=0,
$$
$$
yy^{\prime\prime}+y’=0
$$
são não lineares. Equações não lineares são, em geral, mais difíceis de serem resolvidas.
Exemplo 5. Uma situação interessante onde aparece uma equação não linear é o que descreve o movimento do pêndulo simples. Denotando por \(\theta(t)\) o ângulo que o pêndulo faz com a vertical então a evolução temporal deste ângulo é descrita pela equação
$$
\frac{d^{2}\theta}{dt^{2}}+\frac{g}{l}\text{sen}\,\theta=0,
$$
Pêndulo Simples
onde \(g\) é a aceleração da gravidade e \(l\) o comprimento do pêndulo. Se o pêndulo oscila com baixa amplitude em torno da posição de repouso então podemos fazer uma simplificação nesta equação. Observando que, para ângulos pequenos \(\text{sen}\,\theta\approx\theta\), reescrevemos a equação do pêndulo como
$$
\frac{d^{2}\theta}{dt^{2}}+\frac{g}{l}\theta=0,\;\;\;\text{ ou } \;\;\; \ddot{\theta}+k^{2}\theta=0,
$$
onde fizemos \(k=g/l.\) Esta é uma equação linear, a equação do oscilador harmônico, cujas soluções são
$$
\theta(t)=c_{1}\cos\sqrt{k}t+c_{2}\text{sen}\,\sqrt{k}t,
$$
como podemos verificar facilmente, por substituição.
A Solução de uma Equação Diferencial
Dada uma equação diferencial
$$
F(x,\,y,\,y^{\prime},\,y^{\prime\prime},\ldots,\,y^{(n)})=0
$$
buscamos encontrar a função desconhecida \(y(x)\). Uma solução da equação diferencial é a função (ou funções) que, quando inserida na equação original a transforma em uma identidade.
Exemplo 6. Aprenderemos em breve a encontrar a solução da equação
$$
(1+x)y^{\prime}=y.
$$
Por enquanto, podemos verificar que
$$
y(x)=C(1+x)
$$
é solução. Para ver isto derivamos \(y\),
$$
y^{\prime}=C
$$
e substituimos \(y\) e \(y’\) na equação 1 para obter
$$
(1+x)C=C(1+x),
$$
que é uma identidade.
Problema de Contorno ou Valores Iniciais
Vimos que a solução de uma equação diferencial de primeira ordem é, na verdade, uma família de soluções que depende de um parâmetro desconhecido, uma constante de integração, e que duas destas constantes aparecem na solução de uma equação de segunda ordem. Condições adicionais devem ser adicionadas para que estas constantes sejam determinadas, sobre a forma de valores fixados para a solução em um ponto ou mais de seu domínio.
Exemplo 7. Retornando ao problema do exemplo 6 acima, e adicionando uma condição de contorno, temos
$$
(1+x)y^{\prime}=y,\,\,\,y(1)=\frac{1}{2}.
$$
A família de funções
$$
y(x)=C(1+x)
$$
é chamada de solução geral do problema. Com a condição de contorno podemos determinar um valor para a constante \(C\):
$$
y(1)=2C=\frac{1}{2}\Rightarrow C=\frac{1}{4}.
$$
Desta forma encontramos
$$
y(x)=\frac{1}{4}(1+x).
$$
que é a chamada solução particular do problema.
Exemplo 8. A equação diferencial do exemplo 4,
$$
y^{\prime}=-\frac{x}{y}
$$
tem como solução a equação da circunferência
$$
x^{2}+y^{2}=r^{2},
$$
Figura 1. Soluções de y’=-x/y.
onde \(r\) é uma constante indeterminada. Uma condição de contorno ou valor inicial pode ser utilizado para especificar apenas uma das circunferências como a solução desejada. Digamos que, por qualquer motivo, queremos satisfazer a condição \(y(1)=1\).
Neste caso o valor de \(r\) fica determinado, \(r=\sqrt{2}\), e a solução particular do problema é
$$
x^{2}+y^{2}=2.
$$
Geometricamente, todas as circunferências com centro na origem e raio qualquer são soluções de (2) enquanto apenas uma delas, a que tem raio igual a \(\sqrt{2}\), passa pelo ponto \((1,1)\).
(1) Consulte qualquer livro de Cálculo Integral para rever os conceitos e principais técnicas de integração. Há uma revisão sobre as técnicas básicas no Apêndice.
Exercícios
1.Calcule as seguintes integrais:
a. \( \int\frac{dx}{x+1}\)
b. \( \int\frac{dx}{x^{2}+1}\)
c. \( \int\frac{dx}{x^{3}}\)
d. \( \int(e^{x}-e^{-x})dx\)
e. \( \int\text{sen}\,x\cos xdx\)
f. \( \int te^{4t}dt\)
g. \( \int x^{2}e^{x}dx\)
h. \( \int\ln(1-x)dx \)
i. \( \int_{0}^{1}(1-x^{2})dx\)
2. Encontre uma primitiva da função \(f(x)=\frac{1}{x^{2}}+1\) que se anula no ponto x=2.
Nos exercícios seguintes verifique que a função \(y(x)\) dada é solução da equação diferencial. Encontre o valor da constante de integração \(c\) para que o valor inicial dado seja satisfeito:
Esta seção contém referência a conceitos que só mais tarde serão estudados. Ela serve como uma motivação para o estudo das circunstâncias históricas envolvidas no desenvolvimento desta área da matemática. Não estudaremos neste texto as equações diferenciais parciais nem as não lineares. Consulte a bibliografia para referências nestas áreas.
Equações diferenciais são um ramo importante do cálculo e da análise e representam, provavelmente, a parte da matemática que maior número de aplicações encontra na física e na engenharia. Sua história tem origem no início do cálculo, desenvolvido por Newton e Leibniz no século XVII. Equações que envolvem as derivadas de uma função desconhecida logo apareceram no cenário do cálculo, mas, logo se constatou que elas podem ser de difícil tratamento. As mais simples são aquelas que podem ser diretamente integradas, por meio do uso do método de separação de variáveis, desenvolvido por Jakob Bernoulli e generalizado por Leibniz. No século XVIII muitas equações diferenciais começaram a surgir no contexto da física, astronomia e outras aplicações.
A equação de Newton para a gravitação universal foi usada por Jakob Bernoulli para descrever a órbita dos planetas em torno do Sol. Já nesta época ele podia usar as coordenadas polares e conhecia a catenária como solução de algumas equações. Halley usou os mesmos princípios para estudar o movimento do cometa que hoje tem o seu nome. Johann Bernoulli, irmão de Jakob, foi um dos primeiros a usar os conceitos do cálculo para modelar matematicamente fenômenos físicos e usar equações diferenciais para encontrar suas soluções.
Ricatti (1676 — 1754) levou a sério o estudo de uma equação particular, mais tarde também estudada pelos irmãos Bernoulli. Taylor foi o primeiro a usar o desenvolvimento de funções em séries de potência para encontrar soluções. Não havia, no entanto, uma teoria global ou unificada sobre o tema. Leonhard Euler, o primeiro matemático a compreender profundamente o significado das funções exponencial, logaritmica e trigonométricas, desenvolveu procedimentos gerais para a solução de equações diferenciais. Além de usar as funções elementares ele desenvolveu novas funções, definidas através de suas séries de potências como soluções de equações dadas. Sua técnica dos coeficientes indeterminados foi uma das etapas deste desenvolvimento. Em 1739 Euler desenvolveu o método da variação dos parâmetros e, mais tarde, técnicas numéricas que fornecem “soluções aproximadas” para quase todo o tipo de equação. Posteriormente muitos outros estudiosos se dedicaram ao assunto, refinando e ampliando as técnicas de Euler.
O trabalho de d’Alembert na física matemática permitiu que ele encontrasse soluções para algumas equações diferenciais parciais simples. Lagrange seguiu de perto os trabalhos de Euler e aperfeiçoou os estudos aplicados à mecânica, em particular no problema de três corpos e no estudo da energia potencial. Em 1788 ele introduziu as equações gerais do movimento para sistemas dinâmicos, o que hoje é conhecido como as equações de Lagrange, onde fazia uso do chamado cálculo variacional. O trabalho de Laplace na estabilidade do sistema solar produziu novos avanços, incluindo o uso de técnicas numéricas. Em 1799 ele apresentou o conceito de Laplaciano de uma função. Já o matemático Legendre trabalhou com equações diferenciais, primeiramente motivado pelo estudo do movimento de projéteis, examinando pela primeira vez a influência de fatores como a resistência do ar e velocidades iniciais.
Muitos dos desenvolvimentos seguintes se referem às equações diferenciais parciais. Parte importante deste desenvolvimento foi obtida por Joseph Fourier em sua busca por soluções do problema de difusão do calor. Ele desenvolveu uma representação de funções sob a forma de séries infinitas de funções trigonométricas, úteis para o tratamento de equações parciais e diversas outras aplicações. Até o início do século XIX o estudo das equações diferenciais, e do cálculo como um todo, padeciam de uma deficiência crônica no que se refere à fundamentação teórica de seus princípios. Esta fundamentação começou então a ser construída, iniciando pelo entendimento da teoria e conceitos das funções de variáveis complexas. Gauss e Cauchy foram os principais responsáveis por estes avanços. Gauss usou equações diferenciais para aprimorar as teorias de órbitas e da gravitação planetárias e estabeleceu a teoria do potencial como parte importante da matemática. Ele mostrou que as funções de variáveis complexas eram a chave para compreender muitos dos resultados exigidos pelas equações diferenciais. Cauchy usou equações diferenciais para modelar a propagação das ondas na superfície de um líquido. Ele foi o primeiro a definir de forma satisfatória a noção de convergência de uma série infinita, dando início à análise rigorosa do cálculo e das equações diferenciais. Cauchy também desenvolveu uma teoria sistemática para os números complexos e a usou a transformada de Fourier para encontrar soluções algébricas para as equações diferenciais. A solução de equações diferenciais nas proximidades de um ponto singular foi elaborada por Frobenius.
Muitas outras contribuições têm sido acumuladas ao longo da história mais recente. Poisson utilizou as técnicas das equações diferenciais em aplicações na física e em sistemas mecânicos, incluindo a elasticidade e vibrações. George Green aperfeiçoou os fundamentos da matemática utilizada em aplicações da gravitação, da eletricidade e do magnetismo. Baseados nestes fundamentos Thomson, Stokes, Rayleigh e Maxwell, construiram a teoria moderna do eletromagnetismo. Bessel utilizou a teoria das equações para o estudo da astronomia, buscando analisar perturbações dos planetas sobre as suas órbitas. Joseph Liouville foi o primeiro a resolver problemas de valor de contorno usando equações integrais, um método mais tarde aperfeiçoado Fredholm e Hilbert. Em meados do século XIX novas ferramentas se tornaram necessárias para a solução de sistemas de equações diferenciais. Jacobi desenvolveu a teoria dos determinantes e transformações para a solução de integrais múltipla e equações diferenciais. O conceito de jacobiano de uma transformação foi elaborado em 1841. Cayley também contribuiu para teoria das matrizes e determinantes publicando diversos artigos sobre matemática teórica, dinâmica e astronomia. Gibbs estudou a termodinâmica, eletromagnetismo e mecânica, sendo considerado a pai da análise vetorial. Os avanços durante o final do século XIX adquiriram uma natureza cada vez mais teórica. Em 1876 Lipschitz obteve a prova dos teoremas de existência para equações de primeira ordem. Uma contribuição importante para o estudo das equações diferenciais, apesar de não imediatamente reconhecida pela comunidade dos matemáticos devido a sua falta de rigor, foi feita por Oliver Heaviside. Entre 1880 e 1887 ele desenvolveu o cálculo operacional e o uso da transformada de Laplace para reduzir equações diferenciais a equações algébricas de solução muito mais simples. Como vantagem adicional seu formalismo permite o tratamento de sistemas com entradas descontínuase é extensamente usado na engenharia, especialmente na eletrônica e no tratamento de sinais.
No século XX os maiores impulsos vieram do desenvolvimento de métodos numéricos mais eficientes e da consideração de equações e sistemas de equações diferenciais não lineares. Carl Runge desenvolveu um método para resolver equações associadas à mecânica quântica, atualmente conhecido como método de Runge-Kutta. As equações diferenciais não lineares são um tema que permanece em aberto, recebendo até hoje contribuições importantes. Muitos fenônenos naturais são descritos por equações não lineares. Uma das características destes sistemas consiste na dependência muito sensível das condições iniciais, o que gera comportamentos de difícil previsibilidade que têm sido denominados de caos. Um exemplo importante de sistema não linear é o sistema de equações que descreve o movimento de muitos corpos, por exemplo na descrição do movimento planetário no sistema solar. Outros sistemas não lineares representam o crescimento de espécies em competição, na biologia, o fluxo turbulento de fluidos, a descrição das condições meteorológicas, entre outros. Henry Poincaré (1854 — 1912), matemático, físico e filósofo da ciência, foi um dos precursores nesta pesquisa, sendo o primeiro a descobrir o comportamento caótico das soluções para sistemas de três corpos. Liapunov, Lorenz e muitos outros matemáticos trabalharam nesta área que continua em franca expansão e é de se esperar que o progresso nesta área traga grandes inovações na descrição de diversas áreas do conhecimento.
As funções exponencial e logaritmo são utilizadas com freqüência na solução de equações diferenciais. Elas podem ser definidas de várias formas. Por exemplo, o logaritmo neperiano (de base e) é a área sob o gráfico da função \(1/x,\) de \(x=1\) até \(x\), ou seja
Logaritmo natural
$$
\ln x=\int_{1}^{x}\frac{dt}{t}.
$$Observamos desta definição que \(\ln1=0,\) que o logaritmo é uma função estritamente crescente e não está definida em \(x=0.\) A função exponencial, \(\exp(x)=\text{e}^{x},\) é a inversa do logaritmo,
$$
\ln x=y\Rightarrow\text{e}^{y}=x.
$$
Podemos usar as propriedades da exponencial para nos lembrar de algumas propriedades do logaritmo: observando que as seguintes igualdades são equivalentes
$$
y=\ln x^{n}\Longleftrightarrow\text{e}^{y}=x^{n},
$$
tomamos a raiz enésima dos dois lados
$$
x=\text{e}^{y/n}\Rightarrow\frac{y}{n}=\ln x
$$
o que resulta em
$$
y=n\ln x.
$$
Portanto
$$
\ln x^{n}=n\ln x.
$$
Além disto, se
$$
\ln x+\ln y=z
$$
então
$$
\text{e}^{z}=\text{e}^{\ln x+\ln y}=\text{e}^{\ln x}\text{e}^{\ln y}=xy\Rightarrow z=\ln\left(xy\right)
$$
e, portanto
$$
\ln\left(xy\right)=\ln x+\ln y.
$$
Observe que
$$
\ln x-\ln y=\ln x+\ln y^{-1}=\ln\left(\frac{x}{y}\right).
$$
A partir da exponencial definimos as funções seno hiperbólico e cosseno hiperbólico da seguinte forma
$$
\begin{array}{lll}
\text{senh }x=\frac{1}{2}(\text{e}^{x}-\text{e}^{-x}),
\ \;\; \cosh x=\frac{1}{2}\left(\text{e}^{x}+\text{e}^{-x}\right),
\ \;\; \tanh x=\frac{\text{ senh }x}{\cosh x}.
\end{array}
$$
Observe que \(\text{ senh }x\) é uma função impar enquanto \(\cosh x\) é par. Mostre, como exercício, as seguintes relações:
$$
\frac{d}{dx}\text{ senh }x=\cosh x,\ \ \ \frac{d}{dx}\cosh x=\text{ senh }x,\ \ \ \cosh^{2}x-\text{senh}^{2}x=1.
$$
A fórmula de Euler, que usaremos com freqüência ao longo do texto, pode ser justificada da seguinte maneira: partimos da expansão de Taylor para as funções exponencial, seno e cosseno, válidas para todo \(x\in \mathbb{R}\),
$$
\begin{array}{l}
\text{e}^{x}= \sum_{n=0}^{\infty}\frac{x^{n}}{n!}=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}+\cdots,
\\
\cos x= \sum_{n=0}^{\infty}\frac{\left(-1\right)^{n}x^{2n}}{\left(2n\right)!}=1-\frac{x^{2}}{2!}+\frac{x^{4}}{4!}+\cdots,
\\
\text{ sen }x= \sum_{n=0}^{\infty}\frac{\left(-1\right)^{n}x^{2n+1}}{\left(2n+1\right)!}=x-\frac{x^{3}}{3!}+\frac{x^{5}}{5!}+\cdots.
\end{array}
$$
Em seguida fazemos \(x=i\theta\) na expansão da exponencial, para obter
$$
\text{e}^{i\theta}= 1+i\theta+\frac{\left(i\theta\right)^{2}}{2!}+\frac{\left(i\theta\right)^{3}}{3!}+\frac{\left(i\theta\right)^{4}}{4!}+\frac{\left(i\theta\right)^{5}}{5!}+\frac{\left(i\theta\right)^{6}}{6!}+\cdots
$$
$$
=1+i\theta-\frac{\theta^{2}}{2!}-\frac{i\theta^{3}}{3!}+\frac{\theta^{4}}{4!}+\frac{i\theta^{5}}{5!}-\frac{\theta^{6}}{6!}+\cdots.
$$
onde usamos o fato de que \(i^{2}=-1,\) \(i^{3}=-i,\) etc. Agrupando os termos reais e imaginários temos
$$
\text{e}^{i\theta}=1-\frac{\theta^{2}}{2!}+\frac{\theta^{4}}{4!}-\frac{i\theta^{6}}{6!}+\cdots+i\left(\theta-\frac{\theta^{3}}{3!}+\frac{\theta^{5}}{5!}+\cdots\right),
$$
ou seja,
$$
\text{e}^{i\theta}=\cos\theta+i\text{ sen }\theta.
$$
Desta forma podemos definir a função exponencial de um número complexo qualquer, \(z=\varphi+i\theta,\) como
$$
\text{e}^{z}=\text{e}^{\varphi+i\theta}=\text{e}^{\varphi}\text{e}^{i\theta}=\text{e}^{\varphi}\left(\cos\theta+i\text{ sen }\theta\right).
$$
Técnicas de Integração
Dizemos que \(F(x)\) é uma primitiva de \(f(x)\) se
$$
\frac{dF\left(x\right)}{dx}=f(x).
$$
A diferencial da função \(F\) é definida como
$$
dF\left(x\right)=f(x)dx.
$$
Se \(F\) é primitiva de \(f\) defimos a integral de \(f(x)\) como
$$
\int f(x)dx=F\left(x\right)+c
$$
onde \(c\) é uma constante qualquer. Esta constante, a chamada constante de integração, é essencial na solução de equações diferenciais. Observe que, se \(F\left(x\right)\) é uma primitiva, \(F\left(x\right)+c\) também é. Algumas integrais mais simples podem ser calculadas por simples inspecção, se conhecermos uma primitiva do integrando.
Por exemplo
$$
\int\cos xdx=\text{ sen }x+c, \;\;\text{ porque }\;\;\frac{d}{dx}\left(\text{ sen }x\right)=\cos x.
$$
Outros exemplos:
$$
\int\frac{dx}{x}=\ln x+c, \;\; \int\text{e}^{x}dx=\text{e}^{x}+c,\;\;\int x^{n}dx=\frac{x^{n+1}}{n+1}+c.
$$
Mudança de Variáveis:
Algumas vezes uma integral pode ser colocada sob a forma de uma integral conhecida ou tabelada através de uma troca de variáveis. Por exemplo, para calcular a integral
$$
I_{1}=\int\text{ sen }\left(2x+1\right)dx
$$
fazemos a troca
$$
u=2x+1\Rightarrow du=2dx.
$$
Resolvemos a integral em termos da variável \(u\) e, em seguida, reinserimos a variável inicial \(x,\)
$$
I_{1}=\frac{1}{2}\int\text{ sen }udu=-\frac{1}{2}\cos u+c=-\frac{1}{2}\cos\left(2x+1\right)+c.
$$
Como outro exemplo, calculamos a integral
$$
I_{2}=\int x\text{e}^{-x^{2}}dx,
$$
trocando a variável,
$$
u=-x^{2}\Rightarrow du=-2xdx,
$$
que, substuitida na integral fornece
$$
I_{2}=-\frac{1}{2}\int\text{e}^{u}du=-\frac{1}{2}\text{e}^{u}+c=-\frac{1}{2}\text{e}^{-x^{2}}+c.
$$
Outro exemplo:
$$
I_{3}=\int\frac{1}{x-1}dx.
$$
Faça \(u=x-1,\;du=dx.\) A integral é
$$
I_{3}=\int\frac{1}{u}\,du=\ln u+c=\ln\left(x-1\right)+c.
$$
Integração por partes
Se \(u(x)\) e \(v(x)\) são funções deriváveis então vale a relação
$$
\int udv=uv-\int vdu.
$$
Vamos usar esta relação para calcular a seguinte integral
$$
I_{4}=\int x\text{e}^{-2x}dx.
$$
Identificando \(u\) e \(v\) da seguinte forma,
$$
u=x\Rightarrow du=dx;\;\;dv=\text{e}^{-2x}dx\Rightarrow v=\int\text{e}^{-2x}dx=-\frac{\text{e}^{-2x}}{2},
$$
temos
$$
I_{4}=-\frac{1}{2}x\text{e}^{-2x}+\frac{1}{2}\int\text{e}^{-2x}dx=-\frac{1}{2}\left(x+\frac{1}{2}\right)\text{e}^{-2x}+c.
$$
Outro exemplo: para calcular
$$
I_{5}=\int\text{e}^{2x}\text{ sen }xdx.
$$
identificamos agora as funções
$$
u=\text{e}^{2x} \Rightarrow du=2\text{e}^{2x}dx,
$$
$$
dv=\text{ sen }xdx \Rightarrow v=-\cos x.
$$
Usando a fórmula para a integração por partes temos
$$
I_{5}=-\text{e}^{2x}\cos x+2\int\text{e}^{2x}\cos xdx,
$$
onde trataremos a integral, mais uma vez, por partes, fazendo
$$
\begin{array}{ll} u=\text{e}^{2x} \Rightarrow du=2\text{e}^{2x}dx,
dv=\cos xdx \Rightarrow v=\text{ sen }x. \end{array}
$$
Agora temos
$$
I_{5}=-\text{e}^{2x}\cos x+2\text{e}^{2x}\text{ sen }x-4\int\text{e}^{2x}\text{ sen }xdx,
$$
ou, observando que a última integral é exatamente a integral que procuramos resolver,
$$
I_{5}=-\text{e}^{2x}\cos x+2\text{e}^{2x}\text{ sen }x-4I_{5}.
$$
Isto nos permite concluir que
$$
I_{5}=\frac{1}{5}\left(2\text{ sen }x-\cos x\right)\text{e}^{2x}+c.
$$
Frações Parciais:
A técnica de frações parciais pode ser bastante útil em várias situações. Ela consiste em modificar o integrando, quando possível, para reescrevê-lo sob a forma de uma soma de frações mais simples de serem integradas. Por exemplo, vamos calcular a integral
$$
I_{6}=\int\frac{dx}{x^{2}-1}.
$$
Reescrevemos o integrando como a soma de duas frações
$$
\frac{1}{x^{2}-1}=\frac{1}{\left(x+1\right)\left(x-1\right)}=\frac{A}{\left(x+1\right)}+\frac{B}{\left(x-1\right)},
$$
onde \(A\) e \(B\) são constantes a serem determinadas. Para encontrar estas constantes somamos os dois últimos termos e comparamos o resultado com a fração original
$$
\frac{A\left(x-1\right)+B\left(x+1\right)}{\left(x+1\right)\left(x-1\right)}=\frac{\left(A+B\right)x+B-A}{x^{2}-1}=\frac{1}{x^{2}-1},
$$
igualdade que só pode ser obtida se
$$
A+B=0,\;\; B-A=1 \Rightarrow A=-\frac{1}{2},\;B=\frac{1}{2}.
$$
Portanto o integrando é
$$
\frac{1}{x^{2}-1}=-\frac{1}{2}\frac{1}{\left(x+1\right)}+\frac{1}{2}\frac{1}{\left(x-1\right)}
$$
e a integral procurada é
$$
I_{6}=-\frac{1}{2}\int\frac{dx}{\left(x+1\right)}+\frac{1}{2}\int\frac{dx}{\left(x-1\right)}=-\frac{1}{2}\ln\left(x+1\right)+\frac{1}{2}\ln\left(x-1\right)+c,
$$
ou, usando as propriedades do logaritmo,
$$
I_{6}=\frac{1}{2}\ln\left(\frac{x-1}{x+1}\right)+c.
$$
A integral definida
Se \(F(x)\) é uma primitiva qualquer de \(f(x)\) então a integral definida de \(f\) no intervalo \(\left[a,b\right]\) é
$$
\int_{a}^{b}f(x)dx=\left.F\left(x\right)\right\vert _{a}^{b}=F(b)-F(a).
$$
Mostraremos um exemplo de integral definida realizada por substituição de variável,
$$
I_{7}=\int_{1}^{2}x\text{e}^{1-x^{2}}dx.
$$
A troca de variável agora envolve também a troca dos limites de integração:
$$
u=1-x^{2},\; du=-2xdx, \text{ quando } x=1 \text{ temos } u=0, \text{ quando } x=2 \text{ temos } u=-3.
$$
A integral então se torna
$$
I_{7}=-\frac{1}{2}\int_{0}^{-3}\text{e}^{u}du=\frac{1}{2}\int_{-3}^{0}\text{e}^{u}du=\frac{1}{2}\left.\text{e}^{u}\right\vert _{-3}^{0}=\frac{1}{2}\left(1-\frac{1}{\text{e}^{3}}\right).
$$
Sequências e Séries Infinitas
Sequências Infinitas
Definiremos uma seqüência infinita como um conjunto infinito de números que podem ser colocados em uma relação biunívoca com o conjunto dos números inteiros positivos. Denotaremos por \(\left\{ a_{n}\right\} \) a uma seqüência, sendo \(a_{n},\) com \(n=1,2,…\) os elementos individuais desta seqüência.
Exemplo 1. \(\left\{ a_{n}\right\} =\left\{ \frac{1}{n}\right\} \) é a seqüência com termo genérico \(a_{n}=1/n.\) Neste caso
$$
\left\{ a_{n}\right\} =\left\{ 1,\,\frac{1}{2},\,\frac{1}{3},\,\cdots\right\} .
$$
Definição: Dizemos que a seqüência converge para um número \(L,\) ou tem limite \(L,\) se, dado qualquer número \(\varepsilon>0\) existe um número \(N\) tal que
$$
n>N\Rightarrow\left|a_{n}-L\right|<\varepsilon.
$$
Usaremos como notação
$$
L=\lim_{n\rightarrow\infty}a_{n},\;\;\text{ ou }a_{n}\rightarrow L.
$$
Observe que, se \(\left|a_{n}-L\right|<\varepsilon\) então
$$
-\varepsilon<a_{n}-L<\varepsilon\Longleftrightarrow L-\varepsilon<a_{n}<L+\varepsilon.
$$
Portanto, dizer que uma sequência converge para \(L\) significa dizer que \(a_{n}\) fica arbitrariamente próximo de \(L\) tomando-se \(n\) suficientemente grande. Se uma seqüência não converge para nenhum número dizemos que ela diverge.
Exemplo 2. A sequência do exemplo 1, \(a_{n}=1/n\) converge para \(L=0\).
Exemplo 3. A seguinte sequência converge para \(L=2/3\)
$$
a_{n}=\frac{2n^{2}+n-1}{3n^{2}-n}.
$$
Para ver isto dividimos o numerador e o denominador por \(n^{2}\),
$$
L=\lim_{n\rightarrow\infty}\frac{2n^{2}+n-1}{3n^{2}-n}=\lim_{n\rightarrow\infty}\frac{2+1/n-1/n^{2}}{3-1/n}=\frac{2}{3},
$$
onde usamos o fato de que \(1/n\rightarrow0\) e \(1/n^{2}\rightarrow0.\)
Séries Infinitas:
Definiremos uma série infinita como a soma dos elementos de uma seqüência \(\left\{ a_{n}\right\} .\) Denotaremos esta série por
$$
S=\sum_{n=1}^{\infty}a_{n}=a_{1}+a_{2}+a_{3}+\cdots.
$$
A soma de infinitos termos não tem um significado óbvio e imediato. Para atribuir a ela um sentido não ambíguo definiremos antes a soma dos \(N\) primeiros termos da série, denominada a soma reduzida,
$$
S_{N}=\sum_{n=1}^{N}a_{n}.
$$
Observe agora que o conjunto destas somas reduzidas forma uma seqüência
$$
\left\{ S_{n}\right\}:\;\; S_{1},\,S_{2},\,S_{3},\cdots,
$$
que pode convergir ou não. Dizemos que a série infinita converge para um número \(L\) se a seqüência \(\left\{ S_{n}\right\} \) converge para \(L,\) ou seja
$$
S_{n}\rightarrow L\Longleftrightarrow\sum_{n=1}^{\infty}a_{n}=L.
$$
Caso contrário a série diverge e denotamos
$$
\sum_{n=1}^{\infty}a_{n}=\infty\;\;\text{ ou }\sum_{n=1}^{\infty}a_{n}=-\infty,
$$
conforme o caso.
Exemplo 4. Um exemplo interesssante de uma série convergente é o seguinte:
$$
\sum_{n=0}^{\infty}\frac{1}{n!}=1+1+\frac{1}{2!}+\frac{1}{3!}+\cdots=\text{e},
$$
onde, por convenção, fazemos \(0!=1.\) Este é um caso particular da série mais geral
$$
\sum_{n=0}^{\infty}\frac{x^{n}}{n!}=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}+\cdots=\text{e}^{x}.
$$
No último exemplo a função exponencial foi escrita como uma soma infinita de termos em potências de \(x.\) As séries de potências são particularmente importantes no estudo das equações diferenciais e são o motivo pelo qual revisamos aqui este tema. Voltaremos a elas em breve.
Testes de convergência
Os seguintes testes são os mais utilizados para a verificação de convergencia de uma série.
Teste da Comparação:
Se duas séries \(\Sigma a_{n}\) e \(\Sigma b_{n}\) são séries de termos não negativos (ou seja, se \(a_{n}\geq0\) e \(b_{n}\geq0\) para todo \(n\)) e \(a_{n}\leq b_{n}\) para todo \(n,\) então:
i. se \(\Sigma b_{n} \;\text{ converge } \Rightarrow \Sigma a_{n}\,\) converge,
ii. se \( \Sigma a_{n} \;\text{ diverge } \Rightarrow \Sigma b_{n}\,\) diverge.
Teste da Razão:
Se \(\Sigma a_{n}\) é uma séries de termos positivos, definimos o limite
$$
R=\lim_{n\rightarrow\infty}\frac{a_{n+1}}{a_{n}}.
$$
Então:
se \(R \lt 1 \Rightarrow \Sigma a_{n}\) converge,
se \(R \gt 1 \Rightarrow \Sigma a_{n}\) diverge,
se \(R=1,\) o teste é inconclusivo.
Teste da Integral:
Se \(f(x)\) é uma função positiva não crescente para \(x>0,\) então a série \(\Sigma f(n)\) converge se, e
somente se, a integral imprópria \(\int_{1}^{\infty}f(x)dx\) converge. Além disto vale a desigualdade
Exemplo 5. Usamos o teste da razão para testar a convergência da série
$$
\sum_{n=1}^{\infty}\frac{n^{2}}{n!}.
$$
Temos, neste caso,
$$
a_{n}=\frac{n^{2}}{n!},\;\;a_{n+1}=\frac{\left(n+1\right)^{2}}{(n+1)!}
$$
Calculamos o limite
$$
R=\lim_{n\rightarrow\infty}\frac{\left(n+1\right)^{2}}{(n+1)!}\frac{n!}{n^{2}}=\lim_{n\rightarrow\infty}\frac{1}{n+1}\left(\frac{n+1}{n}\right)^{2}=\lim_{n\rightarrow\infty}\frac{n+1}{n^{2}}=0.
$$
Como \(R \lt 1\) concluimos que a série converge.
Séries de Maclaurin e de Taylor
Uma função que pode ser expressa em termos de uma série infinita de potências em torno do ponto \(x=x_{0},\)
$$
f(x)=a_{0}+a_{1}\left(x-x_{0}\right)+a_{2}\left(x-x_{0}\right)^{2}+\cdots=\sum_{n=0}^{\infty}a_{n}\left(x-x_{0}\right)^{n}\label{seri1}
$$
é dita uma função analítica (neste ponto). Os coeficientes \(a_{n}\) podem ser obtidos do seguinte modo. Calcule o valor de \(f\) e suas derivadas no ponto \(x_{0}\)
$$
f(x_{0})=a_{0},
$$
$$
f^{(3)}(x)=2.3a_{3}\Rightarrow a_{3}=\frac{1}{6}f^{(3)}(x_{0}).
$$
Continuando este procedimento podemos calcular qualquer um dos coeficientes da série, obtendo
$$
a_{n}=\frac{1}{n!}f^{(n)}(x_{0}).
$$
Com estes coeficientes a série é a chamada série de Taylor,
$$
f(x)=\sum_{n=0}^{\infty}\frac{1}{n!}f^{(n)}(x_{0})\left(x-x_{0}\right)^{n}\label{Taylor}
$$
onde \(f^{(n)}(x_{0})\) indica a derivada n-ésima calculada no ponto \(x=x_{0}\). Uma série de Maclaurin é uma série de Taylor que descreve o comportamento de uma função em torno do ponto \(x_{0}=0\).
Resumindo:
Sobre a série de potências \( S=\sum_{n=0}^{\infty}a_{n}\left(x-x_{0}\right)^{n} \) podemos coletar as seguintes propriedades:
(i) \(S\) converge (escolhido um valor para \(x\)) se existe o limite
$$
\lim_{N\rightarrow\infty}\sum_{n=0}^{N}a_{n}\left(x-x_{0}\right)^{n}.
$$
(ii) Se a série converge absolutamente, ou seja, existe o limite
$$
\lim_{N\rightarrow\infty}\sum_{n=0}^{N}\left|a_{n}\left(x-x_{0}\right)^{n}\right|,
$$
então ela converge.
(iii) Teste da razão: Definindo
$$
R=\lim_{n\rightarrow\infty}\left|\frac{a_{n+1}\left(x-x_{0}\right)^{n+1}}{a_{n}\left(x-x_{0}\right)^{n}}\right|=\left|x-x_{0}\right|\lim_{n\rightarrow\infty}\left|\frac{a_{n+1}}{a_{n}}\right|
$$
então a série é absolutamente convergente no ponto \(x\) se \(R \lt 1\) e é divergente se \(R \gt 1\). O teste é inconclusivo se \(R=1\).
(iv) Se a série \(S\) converge em \(x=a\) então ela converge absolutamente para \(x\) no intervalo \(\left[x-a,\;x+a\right].\) Se a série \(S\) diverge em \(x=a\) então ela diverge para \(x\) fora deste intervalo.
(v) O intervalo máximo de valores de \(x\) para os quais a série converge absolutamente é chamado o intervalo de convergência. O raio de convergência é \(\rho\) é definido de forma que \(\left[x_{0}-\rho,x_{0}+\rho\right]\) é este intervalo.
Algumas considerações finais sobre o uso do sinal de somatório podem ser úteis. O índice usado pode ser substituído de acordo com as conveniências
$$
\sum_{i=1}^{N}a_{i}=\sum_{j=1}^{N}a_{j},
$$
e as parcelas da soma podem ser agrupadas ou isoladas, como no exemplo a seguir:
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{N-1}a_{i}+a_{N}=a_{1}+\sum_{i=2}^{N}a_{i},
$$
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{P}a_{i}+\sum_{i=P+1}^{N}a_{i},\;\;1\lt P\lt N.
$$
Pode ser mostrado por indução que
$$
\sum_{i=1}^{N}\left(a_{i}+b_{i}\right)=\sum_{i=1}^{N}a_{i}+\sum_{i=1}^{N}b_{i},
$$
$$
\sum_{i=1}^{N}ka_{i}=k\sum_{i=1}^{N}a_{i},\;\;\forall k\in\mathbb{R}.
$$
Se \(a_{i}=a,\) uma constante, então
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{N}a=Na.
$$
Uma série de potências, se convergente, pode ser derivada termo a termo e a derivada obtida desta forma será uma representação fiel da derivada da função que ela representa:
$$
y\left(x\right)=\sum_{n=0}^{\infty}a_{n}x^{n}=a_{0}+a_{1}x+a_{2}x^{2}+\cdots+a_{r}x^{r}+\cdots,
$$
Na solução de equações diferenciais usando o método de séries de potências será útil alterar o índice para iniciar o somatório em valores diversos de \(n\). Por exemplo, podemos querer escrever a última série começando em \(n=0.\) Para fazer isto redefinimos o índice
$$
m=n-2 \Rightarrow n=m+2.
$$
A derivada segunda será escrita como
$$
y^{\prime\prime}\left(x\right)=\sum_{m=0}^{\infty}\left(m+2\right)\left(m+1\right)a_{m+2}x^{m}=\sum_{n=0}^{\infty}\left(n+2\right)\left(n+1\right)a_{n+2}x^{n},
$$
onde, no último sinal de soma restauramos o índice mudo \(n\).
Algumas Fórmulas Úteis
Para o estudo e trabalho com a matemática sempre é útil ter à disposição um bom resumo de fórmulas e propriedades matemáticas (Veja, por exemplo, Spiegel, Murray R.: Fórmulas Matemáticas, Coleção Schaum.) As seguintes fórmulas podem ser úteis na solução de equações diferenciais.
\(A\text{ sen }\lambda x+B\cos\lambda x=C\text{ sen }\left(\lambda x+\delta\right) \text{ onde } C=\sqrt{A^{2}+B^{2}},\;\delta=\text{arctg}(B/A)\)
\(\text{ sen }\left(x\pm y\right)=\text{ sen }x\cos y\pm\cos x\text{ sen }y\)
\(\cos2x=\cos^{2}x-\text{ sen }^{2}x\)
\(\cos\left(x\pm y\right)=\cos x\cos y\mp\text{ sen }x\text{ sen }y\)
Uma transformada integral é uma transformação do tipo \(f(t)\rightarrow F(s)\) obtida da seguinte forma
$$
F(s)=\int_{\alpha}^{\beta}K(s,t)f(t)dt.
$$
Dizemos que \(F\) é a transformada de \(f\), \(K\) é o núcleo da transformação. Se tomarmos o núcleo como \(K(s,t)=\text{e}^{-st}\) obtemos uma transformação particular, denominada a transformada de Laplace, definida por
(1) Consulte o Apêndice para uma revisão sobre métodos de integração.
\(F(s)\) é denominada a de transformada de Laplace da função \(f(t)\). Estas transformadas permitem a elaboração de um método muito útil na solução de equações diferenciais com valores iniciais que surgem em diversos contextos da matemática aplicada à física e engenharia. Para estudar este método faremos antes uma revisão sobre as integrais impróprias1.
Definição Uma integral é dita imprópria quando o integrando não é limitado dentro dos limites de integração ou quando o domínio de integração não é limitado. O último caso será de especial importância para nosso estudo das transformadas de Laplace. Precisaremos resolver integrais como a usada em (1). Estas integrais são definidas por meio de um limite:
$$
\int_{a}^{\infty}f(t)dt=\lim_{A\rightarrow\infty}\int_{a}^{A}f(t)dt.
$$
Se o limite existe dizemos que a integral converge. Caso contrário ela diverge.
Exemplo 1. Vamos calcular a seguinte integral imprópria, onde \(r\) é uma constante real:
$$
\int_{0}^{\infty}\text{e}^{rt}dt=\lim_{A\rightarrow\infty}\int_{0}^{A}\text{e}^{rt}dt=\lim_{A\rightarrow\infty}\frac{\text{e}^{rt}}{r}|_{0}^{A}=\lim_{A\rightarrow\infty}\frac{1}{r}(\text{e}^{rA}-1).
$$
Vemos, portanto, que a integral pode convergir ou divergir, dependendo do sinal de \(r\):
$$
\int_{0}^{\infty}\text{e}^{ll}dt=\left\{
\begin{array}{ll} -1/r & \text{ (converge) se } \; r\lt 0, \\
\infty & \text{(diverge) se } \; r\geq 0.\\
\end{array}
\right.
$$
Observe que, se \(r=0\) temos \(\lim_{A\rightarrow\infty}\int_{0}^{A}dt=\infty\), ou seja, a integral diverge.
Exemplo 2. Para resolver a integral
$$
\int_{1}^{\infty}t^{-r}dt
$$
temos que distinguir dois casos. Se \(r=1\) temos
$$
\int_{1}^{\infty}\frac{dt}{t}=\lim_{A\rightarrow\infty}\ln A=\infty;
$$
Caso contrário, para \(r\neq1\),
Resumindo,
$$
\int_{1}^{\infty} t^{-r}dt = \left\{
\begin{array}{l} \text{ converge se } \; r\leq1, \\
\text{ diverge se } \; r \gt 0.\\
\end{array}
\right.
$$
Como veremos, as transformadas de Laplace são particularmente importantes na solução de equações diferenciais que involvem funções descontínuas ou com derivadas descontínuas. Estas descontinuidades geralmente aparecem nas funções de entrada, a parte não homogênea das equações lineares, e podem representar, por exemplo, um efeito que é ligado e desligado sobre o sistema estudado ou uma ação externa que atua em um intervalo de tempo finito. Matematicamente as transformadas podem ser aplicadas à funções que envolvem um número finito de descontinuidades na região de interesse. A seguinte definição será útil:
Definição Uma função \(f(t)\) é seccionalmente contínua, ou contínua por partes, no intervalo \(\alpha\leq t\leq\beta\) se existir uma partição do intervalo \(\alpha=t_{0}\leq t_{1}\leq\cdots\leq t_{n}=\beta\) de forma que \(f\) é contínua em cada subintervalo aberto \(t_{i}\leq t\leq t_{i+1}\), além de possuir limite finito nas fronteiras de cada subintervalo. Isto equivale a dizer que \(f\) é uma função com um número finito de descontinuidades. Observe que, se \(f(t)\) é seccionalmente contínua no intervalo \(a\leq t\leq A\), então \(\int_{a}^{A}f(t)dt\) é finita para qualquer valor de \(A\), ainda que a integral imprópria \(\int_{a}^{\infty}f(t)dt\) possa divergir. O seguinte teorema fornece um teste de convergência.
Teorema 1. Seja \(f(t)\) uma função seccionalmente contínua para \(t\geq a,\; g(t)\) outra função qualquer, e \(M\) uma constante positiva. Então
(i) se \(|f(t)|\leq g(t) \text{ para } t\geq M \text{ e } \int_{M}^{\infty}g(t)dt \;\;\text{ converge então }\;\; \int_{a}^{\infty}f(t)dt\) converge.
(ii) se \(f(t)\geq g(t)\geq 0 \text{ para } t\geq M \text{ e } \int_{M}^{\infty}g(t)dt\;\;\text{ diverge então }\;\; \int_{a}^{\infty}f(t)dt\) diverge.
Teorema 2. Seja \(f(t)\) uma função seccionalmente contínua no intervalo \(0\leq t\leq A\) para qualquer \(A\) positivo. Se \(|f(t)|\leq K\text{e}^{at}\) quando \(t\geq M\), onde \(K\) e \(M\) são constantes positivas e \(a\) uma constante real qualquer então a integral definida pela expressão (1) converge e existe a transformada de Laplace \(F(s)=L\{f(t)\}\).
Demonstração Buscamos mostrar a convergência da integral
$$
\int_{0}^{\infty}\text{e}^{-st}f(t)dt=\int_{0}^{M}\text{e}^{-st}f(t)dt+\int_{M}^{\infty}\text{e}^{-st}f(t)dt.
$$
A primeira integral é convergente pois \(f\) é seccionalmente contínua. Como, por hipótese, temos que \(|f(t)|\leq K\text{e}^{at}\) então
$$
|\text{e}^{-st}f(t)|\leq K\text{e}^{-st}\text{e}^{at}=K\text{e}^{(a-s)t}
$$
e a segunda integral
$$
\int_{M}^{\infty}\text{e}^{-st}f(t)dt\leq K\int_{M}^{\infty}\text{e}^{(a-s)t}dt
$$
que converge quando \(a \lt s\), como foi mostrado no exemplo 1. Pelo teorema 1, \(\int_{0}^{\infty}\text{e}^{-st}f(t)dt\) converge.
Funções que satisfazem as condições do teorema 2 são seccionalmente contínuas e ditas funções de ordem exponencial. Trataremos apenas destas funções neste capítulo. Mostraremos a seguir alguns exemplos de funções que possuem transformadas de Laplace.
Exemplo 3. A transformada de \(f(t)=1\), \(t\geq0\), é
$$
L\{1\}=\int_{0}^{\infty}\text{e}^{-st}dt=\lim_{A\rightarrow\infty}\frac{1}{s}(1-\text{e}^{-sA})=\frac{1}{s},\;\text{ se }\;s\gt 0.
$$
Exemplo 4. A transformada de \(f(t)=t,\; t\geq0\):
$$
L\{t\}=\int_{0}^{\infty}t\text{e}^{-st}dt=\lim_{A\rightarrow\infty}t\text{e}^{-st}|_{0}^{A}-\frac{1}{s}\int_{0}^{A}\text{e}^{-st}dt=
$$
$$
=\lim_{A\rightarrow\infty}-\frac{1}{s^{2}}(\text{e}^{-st})|_{0}^{A}=\frac{1}{s^{2}},\;\text{ se }\;s\gt 0.
$$
Exemplo 5. Já calculamos a transformada de \(f(t)=\text{e}^{at}, \; t\geq0\):
$$
L\{\text{e}^{at}\}=\int_{0}^{\infty}\text{e}^{-st}\text{e}^{at}dt=\int_{0}^{\infty}\text{e}^{(a-s)t}dt=\frac{1}{s-a},\;\text{ se }\;s\lt a.
$$
Exemplo 6. A transformada de \(f(t)=\text{sen }at,\; t\geq 0\), é:
$$
F(s)=L\{\text{sen }at\}=\int_{0}^{\infty}\text{e}^{-st}\text{sen }atdt=\lim_{A\rightarrow\infty}\int_{0}^{A}\text{e}^{-st}\text{sen }atdt.
$$
Integrando por partes temos
Exemplo 7. Podemos encontrar as transformada das funções seno e cosseno de modo mais simples usando a linearidade da transformada e a transformada da exponencial encontrada no exemplo 5:
$$
L\{\text{e}^{iat}\}=\frac{1}{s-ia}=\frac{s+ia}{(s-ia)(s+ia)}=\frac{s+ia}{s^{2}+a^{2}}.
$$
Por outro lado, pela linearidade da transformação,
$$
L\{\text{e}^{iat}\}=L\{\cos at+i\text{sen }at\}=L\{\cos at\}+iL\{\text{sen }at\}.
$$
Identificando as partes real e imaginária das equações temos
$$
L\{\cos at\}=\frac{s}{a^{2}+s^{2}},
$$
$$
L\{\text{sen }at\}=\frac{a}{a^{2}+s^{2}}.
$$
Para considerar o uso das transformadas de Laplace para a solução de equações diferenciais com valores de contorno definidos precisaremos encontrar a transformada das derivadas de uma função. Disto trata o teorema seguinte.
Teorema 3. Seja \(f\) uma função contínua com derivada \(f^{\prime}\) seccionalmente contínua no intervalo \(0\leq t\leq A\), satisfazendo \(|f(t)|\leq K\text{e}^{at} \text{ para } t\geq M\) (uma função de ordem exponencial). Então \(L\{f^{\prime}(t)\}\) existe e dada por
$$
L\{f^{\prime}(t)\}=sL\{f(t)\}-f(0).
$$ Demonstração. A transformada da derivada, por definição, é
$$
L\{f^{\prime}(t)\}=\int_{0}^{\infty}\text{e}^{-st}f^{\prime}(t)dt.
$$
Vamos denotar por \(t_{1},\,t_{2}, \ldots, \, t_{n}\) os pontos onde \(f^{\prime}\) é descontínua no intervalo \(0\leq t\leq A\). Dai
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=\int_{0}^{t_{1}}\text{e}^{-st}f^{\prime}(t)dt+\int_{t_{1}}^{t_{2}}\text{e}^{-st}f^{\prime}(t)dt+\ldots+\int_{t_{n}}^{A}\text{e}^{-st}f^{\prime}(t)dt.
$$
Cada uma das integrais pode ser resolvida por partes, fazendo
$$
u=\text{e}^{-st},\,\,\,du=-s\text{e}^{-st}dt;\,\,\,dv=f^{\prime}dt,\,\,\,v=f.
$$
Assim
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=\text{e}^{-st}f|_{0}^{t_{1}}+\text{e}^{-st}f|_{t_{1}}^{t_{2}}+\ldots+\text{e}^{-st}f|_{t_{n}}^{A}+
$$
$$
s\int_{0}^{t_{1}}\text{e}^{-st}f(t)dt+s\int_{t_{1}}^{t_{2}}\text{e}^{-st}f(t)dt+\ldots+s\int_{t_{n}}^{A}\text{e}^{-st}f(t)dt.
$$
Como \(f\) é contínua o primeiro grupo de somas resulta simplesmente em \(\text{e}^{-st}f|_{0}^{A}\) enquanto a soma das integrais pode ser escrita como a integral sobre todo o domínio \(0\leq t\leq A\). Resulta, portanto, que
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=s\int_{0}^{A}\text{e}^{-st}f(t)dt+\text{e}^{-st}f|_{0}^{A}.
$$
O teorema fica demonstrado quando tomamos o limite \(A\rightarrow\infty\), lembrando que \(f\) é uma função de ordem exponencial.
Como consequência direta deste teorema podemos calcular a transformada da derivada segunda de uma função.
Corolário. Se \(f^{\prime} \text{ e } f^{\prime\prime} \) satisfazem as condições do teorema 3, então
$$
L\{f^{\prime\prime}(t)\}=sL\{f^{\prime}(t)\}-f^{\prime}(0)=s[sL\{f(t)\}-f(0)]-f^{\prime}(0),
$$
ou seja,
Generalizando este procedimento podemos encontrar as transformadas de derivadas de qualquer ordem. Se \(f,\,f^{(1)},\ldots,\,f^{(n-1)}\) são funções contínuas e \(f^{(n)}\) seccionalmente contínua, todas elas de ordem exponencial, então
Exemplo 8. Podemos usar o teorema 3 para calcular a transformada de funções se conhecemos a transformada de sua derivada. Por exemplo fazemos
$$
f(t)=t^{2},\,\,f^{\prime}(t)=2t,\,\,f(0)=0,
$$
no teorema para obter
$$
L\{2t\}=sL\{t^{2}\}\Rightarrow L\{t^{2}\}=\frac{2}{s^{3}}.
$$
De modo similar temos que
$$
L\{3t^{2}\}=sL\{t^{3}\}\Rightarrow L\{t^{3}\}=\frac{3!}{s^{4}}.
$$
Podemos mostrar por indução que
$$
L\{t^{n}\}=\frac{n!}{s^{n+1}},
$$
para \(n\) inteiro positivo.
Exemplo 9. Embora já tenhamos encontrado as transformadas das funções seno e cosseno podemos usar uma forma alternativa para encontrar suas transformadas através do corolário do teorema 3. Na equação
$$
L\{f^{\prime\prime}(t)\}=s^{2}L\{f(t)\}-sf(0)-f^{\prime}(0)
$$
fazemos \(f(t)=\cos at\) e, portanto, \(f(0)=1\), \(f^{\prime}(0)=0\) para obter
$$
-a^{2}L\{\cos at\}=s^{2}L\{\cos at\}-s\Rightarrow L\{\cos at\}=\frac{s}{s^{2}+a^{2}}.
$$
Procedimento análogo nos leva à transformada da função seno.
Para a utilização destas transformadas na solução de equações diferenciais necessitamos ainda definir a transformada inversa de Laplace. Se \(L\{f(t)\}=F(s)\) então chamamos \(f(t)\) a transformada inversa de \(F(s)\) e denotamos
$$
L^{-1}\{F(s)\}=f(t).
$$
O problema geral de encontrar transformadas inversas é bem definido mas involve a teoria de funções de variáveis complexas e não será aqui considerado. No entanto é possível mostrar que existe uma relação biunívoca entre as funções e suas transformadas e a transformada inversa é também um operador linear. Se \(F(s)\) é composto pela soma de \(n\) funções
$$
F(s)=F_{1}(s)+F_{2}(s)+\cdots+F_{n}(s)
$$
e as transformadas de cada uma das \(n\) funções são conhecidas
$$
f_{1}(t)=L^{-1}\{F_{1}(s)\},\cdots,f_{n}(t)=L^{-1}\{F_{n}(s)\}
$$
então
$$
L^{-1}\{F(s)\}=L^{-1}\{F_{1}(s)\}+\cdots+L^{-1}\{F_{n}(s)\}=f_{1}(t)+\cdots+f_{n}(t).
$$
Alem disto, se \(a\) é uma constante qualquer, então
$$
L^{-1}\{aF(s)\}=af(t).
$$
Portanto, para encontrar a transformada inversa de uma função nos a transformaremos até que ela possa ser reconhecida como a transformada de alguma função conhecida, como mostrado nos exemplos a seguir. Algumas transformadas mais usuais e propriedades estão listadas no final deste capítulo.
Exemplo 10. Procuramos a transformada inversa da função
$$
F(s)=\frac{3s+1}{s^{2}+9}.
$$
Esta função pode ser reescrita como
$$
F(s)=\frac{3s}{s^{2}+9}+\frac{1}{3}\frac{3}{s^{2}+9}.
$$
Lembrando, ou olhando na tabela, que as transformadas do seno e cosseno são
$$
L\{\text{sen }at\}=\frac{a}{s^{2}+a^{2}},\,\,\,\,L\{\cos at\}=\frac{s}{s^{2}+a^{2}}
$$
temos que
Exemplo 11. Vamos encontrar a transformada inversa da função
$$
F(s)=\frac{s+3}{s^{2}+3s+2}.
$$
Devemos expressar esta função como soma de funções que são transformadas conhecidas e dai obter a transformada inversa. Notando que as raizes do denominador são \(-1\) e \(-2\) escrevemos \(s^{2}+3s+2=(s+1)(s+2)\) e decompomos \(F\) em termos de frações parciais
$$
F(s)=\frac{s+3}{(s+1)(s+2)}=\frac{a}{(s+1)}+\frac{b}{(s+2)}=\frac{a(s+2)+b(s+1)}{(s+1)(s+2)}.
$$
\(a\) e \(b\) constantes. Para que o numerador seja o mesmo devemos ajustar \(a\) e \(b\):
$$
\left.(a+b)s+2a+b=s+3\Rightarrow
\begin{array}{c}a+b=1 \\ 2a+b=3 \\ \end{array}
\right\} \Rightarrow\begin{array}{c} a=2 \\ b=-1 \\ \end{array}
$$
ou seja
$$
F(s)=\frac{2}{(s+1)}-\frac{1}{(s+2)}.
$$
A transformada inversa procurada é
$$
f(t)=L^{-1}\{F(s)\}=2L^{-1}\left\{ \frac{1}{s+1}\right\} -L^{-1}\left\{ \frac{1}{s+2}\right\} .
$$
Lembrando que a transformada de \(L\{\text{e}^{at}\}=1/(s-a)\) e, portanto
$$
L^{-1}\left\{ \frac{1}{s-a}\right\} =\text{e}^{at},
$$
temos
Queremos resolver agora um problema de contorno do tipo
$$
y^{\prime\prime}+ay^{\prime}+by=r(t),\,\,\,\,y(0)=y_{0},\,\,\,\,y^{\prime}(0)=y_{0}^{\prime}.
$$
Caso os valores de contorno não estejam definidos no ponto \(x_{0}=0\) basta fazer uma translação do eixo de coordenadas colocando o contorno na origem das coordenadas. Se a função \(r(x)\) é de ordem exponencial possuindo, portanto, transformada de Laplace bem definida admitiremos que a solução \(y(t)\) é também de ordem exponencial e que suas derivadas satisfazem as condições do teorema 3 e seu corolário. Tomamos a transformada de ambos os lados da equação acima,
$$
L\{y^{\prime\prime}+ay^{\prime}+by\}=L\{r(t)\},
$$
para obter, pela linearidade da transformação,
$$
L\{y^{\prime\prime}\}+aL\{y^{\prime}\}+bL\{y\}=L\{r(t)\}.
$$
Denotando por \(R(s)=L\{r(t)\}\) e \(Y(s)=L\{y(t)\}\), temos
$$
Y(s)=\frac{R+(s+a)y_{0}+y_{0}^{\prime}}{s^{2}+sa+b}.
$$
\(Y(s)\) representa a transformada da solução procurada, já incorporadas as condições de contorno. O próximo passo é o de encontrar a transformada inversa, representada pela solução \(y(t)\), da forma tratada na seção anterior.
Exemplo 12. Vamos resolver pelo método de transformadas de Laplace a seguinte equação diferencial com valores de contorno:
$$
y^{\prime\prime}+3y^{\prime}+2y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=0.
$$
Transformando ambos os lados da equação e usando a linearidade obtemos
$$
L\{y^{\prime\prime}+3y^{\prime}+2y\}=L\{y^{\prime\prime}\}+3L\{y^{\prime}\}+2L\{y\}=0.
$$
Denotamos agora \(L\{y(t)\}=Y(s)\) e usamos as transformadas das derivadas
$$
L\{y^{\prime}\}=sY(s)-y(0)\;\text{ e }\;L\{y^{\prime\prime}\}=s^{2}Y(s)-sy(0)-y^{\prime}(0)
$$
para transformar a equação diferencial em uma equação algébrica (ou seja, uma equação sem derivadas)
$$
s^{2}Y(s)-s+3sY(s)-3+2Y(s)=0\Rightarrow
$$
$$
Y(s)=\frac{s+3}{s^{2}+3s+2}.
$$
A transformada inversa desta função foi encontrada no exemplo 5.11 da seção anterior,
$$
y(t)=L^{-1}\left\{ \frac{s+3}{s^{2}+3s+2}\right\} =2\text{e}^{-t}-\text{e}^{-2t}
$$
o que é a solução do problema, já incorporadas as condições de contorno fornecidas.
O tratamento das equações não homogêneas não acrescenta dificuldades extras no uso do método das transformadas da Laplace, como se mostra no exemplo seguinte.
Exemplo 13. Considere a equação não homogênea,
$$
y^{\prime\prime}+y=\text{sen }2t,\,\,y(0)=2,\,\,y^{\prime}(0)=1.
$$
Transformando a equação temos
$$
L\{y^{\prime\prime}+y\}=L\{y^{\prime\prime}\}+L\{y\}=L\{\text{sen }2t\}
$$
ou, usando a propriedade da derivada da derivada e a transformado do seno,
$$
s^{2}Y(s)+Y(s)-2s-1=\frac{2}{s^{2}+4}.
$$
Dai
$$
Y(s)=\frac{2s^{3}+s^{2}+8s+6}{(s^{2}+1)(s^{2}+4)}.
$$
Decompondo esta última expressão em frações parciais temos
$$
Y(s)=\frac{as+b}{s^{2}+1}+\frac{cs+d}{s^{2}+4}
$$
e determinamos que as constantes são \(a=2,\,\,b=5/3,\,\,c=0\) e \(d=-2/3\). Então
$$
Y(s)=\frac{2s}{s^{2}+1}+\frac{5/3}{s^{2}+1}-\frac{2/3}{s^{2}+4}.
$$
Lembrando que as transformadas do seno e cosseno são
$$
L\{\text{sen }at\}=\frac{a}{a^{2}+s^{2}},\,\,\,\,L\{\cos at\}=\frac{s}{a^{2}+s^{2}}
$$
temos a solução
$$
y(t)=2\cos t+\frac{5}{3}\text{sen }t-\frac{1}{3}\text{sen }2t.
$$
Em resumo, o método da transformada de Laplace é muito útil para o tratamento de equações que surgem em aplicações, especialmente em problemas de mecânica e na solução de circuitos elétricos. A transformação da equação diferencial leva a uma equação algébrica e sua transformada inversa fornece a solução procurada para o problema de valor inicial, seja ela homogênea ou não. A solução obtida desta forma já leva em consideração os valores do contorno apresentados no problema.
Exercícios 2
1. Determine as soluções de
a. \(y^{\prime\prime}+9y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=2\)b. \(y^{\prime\prime}+y^{\prime}-2y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=3\)
c. \(y^{\prime\prime}-2y^{\prime}-3y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=7\)
d. \(y^{\prime\prime}+2y^{\prime}-8y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=8\)
e. \(y^{\prime\prime}+2y^{\prime}-3y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=4\)
f. \(4y^{\prime\prime}+4y^{\prime}-3y=0,\,\,\,y(0)=8,\,\,\,y^{\prime}(0)=0\)
g. \(y^{\prime\prime}-4y^{\prime}+5y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
h. \(y^{\prime\prime}+2y^{\prime}+5y=0,\,\,\,y(0)=2,\,\,\,y^{\prime}(0)=-4\)
i. \(y^{\prime\prime}+2y^{\prime}+y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=-2\)
j. \(y^{\prime\prime}-4y^{\prime}+4y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=2\)
2. Determine as soluções das equações não homogêneas a. \(y^{\prime\prime}-y=1,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=2\)
b. \(y^{\prime\prime}-3y^{\prime}+2y=6\text{e}^{-t},\,\,\,y(0)=3,\,\,\,y^{\prime}(0)=3\)
c. \(y^{\prime\prime}+2y^{\prime}-3y=10\text{senh }2t,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=4\)
d. \(y^{\prime\prime}+2y^{\prime}+2y=10 \text{sen }2t,\,\,\,y(0)=-1,\,\,\,y^{\prime}(0)=-3\)
e. \(y^{\prime\prime}-2y^{\prime}+5y=8\text{sen }t-4\cos t,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
f. \(y^{\prime\prime}+y=-2\text{sen }t,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=1\)
g. \(y^{\prime\prime}+9y=6\cos3t,\,\,\,y(0)=2,\,\,\,y^{\prime}(0)=0\)
h. \(y^{\prime\prime}+4y=4(\cos2t-\text{sen }2t),\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
Para prosseguirmos com o estudo das propriedades da transformada de Laplace será necessário definir a função degrau unitário:
$$
u_{a}(t)=\left\{
\begin{array}{ll} 0, & t\lt a \\
1, & t\geq a, \\
\end{array}\right.
$$
onde \(a\) é uma constante. Em diversas aplicações surgem funções não contínuas como parte de uma equação diferencial. Um exemplo destas aplicações é a corrente elétrica em um circuito simples onde a tensão pode ser ligada e desligada. A corrente em uma lâmpada, ignorados efeitos indutivos e capacitivos do circuito, ligada aos polos de uma bateria no instante \(t=2\) e desligada em \(t=4\) é descrita por
$$
i(t)=u_{2}(t)-u_{4}(t),
$$
como ilustrado na figura.
Figura: Degrau unitário
A função degrau pode ser usada para descrever fenômenos que se iniciam (ou terminam) após um determinado tempo ou para introduzir descontinuidades quaisquer. Por exemplo, se \(h(t)\) é uma função qualquer, defina
$$
g(t)=\left\{
\begin{array}{ll} 0, & t \lt a, \\
h(t-a), & t\geq a, \\
\end{array}\right.
$$
o que representa uma translação de \(h\) na direção de \(t\) positivo. Usando a função degrau ela pode ser escrita em forma compacta
$$
g(t)=u_{a}(t)h(t-a).
$$
A transformada de Laplace da função degrau unitário pode ser facilmente obtida:
$$
L\{u_{a}(t)\}=\int_{0}^{\infty}u_{a}(t)\text{e}^{-st}dt=\int_{a}^{\infty}\text{e}^{-st}dt=
$$
$$
=-\frac{1}{s}\lim_{A\rightarrow\infty}\text{e}^{-st}|_{a}^{A}=\frac{\text{e}^{-as}}{s},\;\text{ para }\;s\gt 0.
$$
A “Função” Delta de Dirac
Outro tipo de descontinuidade frequente em equações diferenciais pode ser representado por meio da função delta de Dirac, que pode ser definida da seguinte forma:
$$
\delta(t)=0\text{ se } t\neq 0, \text{ e }
$$
$$
\int_{-\infty}^{\infty}f(t)\delta(t)dt=f(0).
$$
A função \(\delta(t-a)\) pode ser entendida como um pico fortemente concentrado em torno de \(x=a\), de forma que
$$
\int_{\alpha}^{\beta}f(t)\delta(t-a)dt=
\left\{ \begin{array}{ll} f(a), & \text{ se } \; \alpha\lt a \lt \beta, \\
0, & \text{ caso contrário}.
\end{array}\right.
$$
A transformada da função delta é
$$
L\{\delta(t-a)\}=\int_{0}^{\infty}\text{e}^{-st}\delta(t-a)dt=\text{e}^{-sa},\;\; a\gt 0.
$$
Esta função foi introduzida por P. A. M. Dirac e não é, na verdade, uma função mas sim uma distribuição ou uma função generalizada.
Teoremas de Translação
Estamos agora preparados para enunciar dois teoremas que descrevem propriedades da transformada de Laplace e que serão úteis na soluções de equações diferenciais.
Figura: Translações
Teorema 4: Seja \(f(t)\) uma função que possui transformada de Laplace \(F(s)=L\{f(t)\}\). Então
$$
L\{u_{a}(t)f(t-a)\}=\text{e}^{-as}F(s),\;\;s\gt 0,\,\,\,a\gt 0.
$$ Demonstração:
$$
L\{u_{a}(t)f(t-a)\}=\int_{0}^{\infty}\text{e}^{-st}u_{a}(t)f(t-a)dt=\int_{a}^{\infty}\text{e}^{-st}f(t-a)dt.
$$
Denotando \(t-a=w\), temos \(t=a+w\) e \(w=0\) quando \(t=a\). A transformada procurada é
$$
\int_{0}^{\infty}\text{e}^{-s(a+w)}f(w)dw=\text{e}^{-sa}\int_{0}^{\infty}\text{e}^{-sw}f(w)dw=\text{e}^{-as}F(s),
$$
como afirmado.
Exemplo 14. Encontraremos a transformada de
$$
f(t)=\left\{ \begin{array}{ll} \text{sen }t, & 0 \leq t \lt \pi/4, \\ \text{sen }t+\cos\left(t-\frac{\pi}{4}\right), & t\geq\pi/4. \\ \end{array}\right.
$$
Teorema 5 Seja \(f(t)\) uma função que possui transformada de Laplace \(F(s)=L\{f(t)\}\). Então
$$
L\{\text{e}^{at}f(t)\}=F(s-a),\,\,\,s>a,\,\,\,a\gt 0.
$$
Vale também a transformada inversa
$$
L^{-1}\{F(s-a)\}=\text{e}^{at}f(t).
$$
A condição \(s\gt a\) serve para garantir a convergência da última integral, desde que \(f\) seja de ordem exponencial.
Exemplo 15. A transformada inversa de \((s^{2}-4s+5)^{-1}\) é, completando quadrados,
$$
L^{-1}\left\{ \frac{1}{s^{2}-4s+5}\right\} =L^{-1}\left\{ \frac{1}{(s-2)^{2}+1}\right\} =L^{-1}\{F(s-2)\}
$$
onde \(F(s)=1/(s^{2}+1),\) que é a transformada da função \(\text{sen }t\). Então
$$
L^{-1}\{F(s-2)\}=\text{e}^{2t}\text{sen }t
$$
como se pode concluir pelo Teorema 2.
Exemplo 16. Vamos tratar do seguinte problema de valor inicial:
$$
y^{\prime\prime}-2y^{\prime}+2y=0,y(0)=0,y^{\prime}(0)=1.
$$
Pela linearidade da transformada de Laplace temos
$$
L\{y^{\prime\prime}\}-2L\{y^{\prime}\}+2L\{y\}=0,
$$
ou, escrevendo
$$
L\{y(t)\}=Y(s)
$$
e
Demonstração escrevemos a transformada como a soma de duas integrais
$$
L\{f(t)\}=\int_{0}^{\infty}f(t)\text{e}^{-st}dt=\int_{0}^{T}f(t)\text{e}^{-st}dt+\int_{T}^{\infty}f(t)\text{e}^{-st}dt.
$$
Fazendo a substituição de variáveis, \(t\rightarrow\tau=t-T\), a última destas integrais pode ser escrita como
$$
\int_{T}^{\infty}f(t)\text{e}^{-st}dt=\int_{0}^{\infty}f(\tau+T)\text{e}^{-s(\tau+T)}dt=\text{e}^{-sT}\int_{0}^{\infty}f(\tau)\text{e}^{-s\tau}dt=\text{e}^{-sT}L\{f(t)\},
$$
onde foi usado o fato de que \(f\) é periódica. A transformada procurada é, portanto,
$$
L\{f(t)\}=\int_{0}^{T}f(t)\text{e}^{-st}dt+\text{e}^{-sT}L\{f(t)\},
$$
ou seja,
$$
L\{f(t)\}=\frac{1}{1-\text{e}^{-sT}}\int_{0}^{T}f(t)\text{e}^{-st}dt,
$$
ficando assim mostrado o teorema.
Exemplo 17. Dada a função periódica, definida por
$$
\begin{array}{ll} f(t)=\frac{1}{2}t, & 0\leq t\lt 2, \\ f(t+2)=f(t) & \text{ fora deste intervalo,} \\ \end{array}
$$
Figura: Função dente de serra
procuramos sua transformada de Laplace. Esta é a função dente de serra que tem inúmeras aplicações, particularmente em circuitos eletrônicos. Usando o teorema 6 obtemos sua transformada de Laplace como
$$
L\{f(t)\}=\frac{1}{1-\text{e}^{-2s}}\int_{0}^{2}f(t)\text{e}^{-st}dt=\frac{1}{2}\frac{1}{1-\text{e}^{-2s}}\int_{0}^{2}t\text{e}^{-st}dt.
$$
Integrando por partes temos
$$
L\{f(t)\}=\frac{1}{2}\frac{1}{1-\text{e}^{-2s}}\left[\left.-\frac{t\text{e}^{-st}}{s}\right|_{0}^{2}++\frac{1}{s}\int_{0}^{2}\text{e}^{-st}dt\right]
$$
1 Faça um esboço do gráfico das funções e encontre suas transformadas de Laplace: a. \(f(t)=\left\{ \begin{array}{ll} 0, & t\lt 2 \\ (t-2)^{2}, & t\geq2 \\ \end{array}.\right.\)
A transformada de Laplace é apropriada para o tratamento de uma equação diferencial com um termo não homogêneo, também denominado a função de entrada, descontínua, como já mencionado.
Exemplo 18. Considere a equação diferencial
$$
y^{\prime\prime}+y^{\prime}+\frac{5}{4}y=g(t),\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=0,
$$
onde \(g(t)=1-u_{\pi}(t)\), uma função descontínua. Transformando a equação obtemos
$$
s^{2}Y(s)+sY(s)+\frac{5}{4}Y(s)=L\{1\}-L\{u_{\pi}(t)\}=\frac{1}{s}(1-\text{e}^{\pi s}),
$$
e, portanto,
$$
Y(s)=\frac{1-\text{e}^{\pi s}}{s\left(s^{2}+s+\frac{5}{4}\right)}.
$$
Vamos denotar \(H(s)\) a transformada de \(h(t)\), onde
$$
H(s)=\frac{1}{s\left(s^{2}+s+\frac{5}{4}\right)},\,\,\,\,h(t)=L^{-1}\{H(s)\}.
$$
Então, com esta notação,
$$
Y(s)=(1-\text{e}^{\pi s})H(s)
$$
e, pelo teorema 4 da seção anterior,
$$
y(t)=L^{-1}\{H(s)-\text{e}^{\pi s}H(s)\}=h(t)-u_{\pi}(t)h(t-\pi).
$$
Resta então encontrar \(L^{-1}\{H(s)\}\). Para fazer isto escrevemos \(H\) em termos das frações parciais
$$
H(s)=\frac{a}{s}+\frac{bs+c}{s^{2}+s+\frac{5}{4}}
$$
e encontramos as constantes \(a=4/5,\,\,b=-4/5\) e \(c=-4/5,\) portanto
$$
H(s)=\frac{4}{5}\frac{1}{s}-\frac{4}{5}\frac{s+1}{s^{2}+s+\frac{5}{4}}.
$$
Usando as transformadas conhecidas e suas propriedades encontramos
$$
h(t)=\frac{4}{5}-\frac{4}{5}\left(\cos t+\frac{1}{2}\text{sen }t\right)\text{e}^{-t/2}
$$
e, portanto,
Exemplo 19. Veremos como utilizar a transformada acima para resolver uma equação diferencial que tem como função de entrada uma distribuição delta. Considere o problema
$$
y^{\prime\prime}+y=4\delta(t-2\pi),\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=0.
$$
Este problema pode ser visto como a equação de movimento de uma partícula presa a uma mola com constante elástica unitária e em um meio sem atrito, submetida a uma força de curta duração, como uma colisão, no momento \(t=2\pi\). Ela parte afastada de uma unidade de distância da posição de equilíbrio no instante \(t=0\) e tem velocidade inicial nula. Transformando toda a equação temos
$$
s^{2}Y(s)-s+Y(s)=4\text{e}^{-2\pi s}
$$
ou seja
$$
Y(s)=\frac{s}{s^{2}+1}+\frac{4\text{e}^{-2\pi s}}{s^{2}+1}.
$$
Utilizando os teoremas e transformadas inversas pertinentes temos
$$
y(t)=\cos t+4\text{sen }(t-2\pi)u_{2\pi}(t).
$$
Como o seno é periódica com período \(T=2\pi\) temos \(\text{sen }(t-2\pi)=\text{sen }(t)\) e
$$
y(t)=\left\{ \begin{array}{ll} \cos t, 0\leq t\leq2\pi,
\cos t+4\text{sen }t, t\geq2\pi. \end{array}.\right.
$$
Função do exemplo 19
O gráfico desta solução mostra que a mola oscila com amplitude \(1\) até o instante \(t=2\pi\). Depois disto passa a oscilar com maior amplitude, devido ao impulso sofrido.
Exercícios 4
Encontre a solução dos problemas de valor inicial
1. \(y^{\prime\prime}+y=f(t),\; y(0)=0,y^{\prime}(0)=1 \text{ onde }
f(t)=\left\{ \begin{array}{ll} 1, & 0\leq t \lt \pi/2 \\
0, & t\geq\pi/2.\\
\end{array}\right.\)2. \(y^{\prime\prime}+2y^{\prime}+2y=f(t),\; y(0)=0,\;y^{\prime}(0)=1 \,\,\, \text{ onde } f(t)=\left\{ \begin{array}{ll} 1, & \pi\leq t\lt2\pi
\\0, & 0\leq t\lt\pi\text{e}t\geq2\pi. \\ \end{array}\right.\)
Pode ocorrer, na solução de uma equação diferencial, que a solução transformada \(Y(s)\) seja dada em termos do produto de duas transformadas conhecidas. Se \(F(s)=L\{f(t)\} \text { e } G(s)=L\{g(t)\}\) queremos saber qual é a transformada inversa do produto \(H(s)=F(s)G(s)\), ou seja \(L^{-1}\{F(s)G(s)\}\). O teorema da convolução nos fornece a transformada inversa deste produto.
Teorema 7. Seja \(f(t) \text { e } g(t)\) duas funções que possuem transformadas de Laplace, e \(F(s)=L\{f(t)\},\,\,G(s)=L\{g(t)\}\) as suas transformadas. Se \(H(s)=F(s)G(s)\) é o produto das transformadas então sua transformada inversa, \(h(t)=L^{-1}\{H(s)\}\) é
$$
h(t)=\int_{0}^{t}f(t^{\prime}-\tau)g(\tau)d\tau=\int_{0}^{t}f(\tau)g(t^{\prime}-\tau)d\tau.
$$
\(h(t)\) é a convolução de \(f\) e \(g\) e as integrais são chamadas de integrais de convolução.
Demonstração por definição temos as expressões para \(F\) e \(G\),
$$
H(s)=F(s)G(s)=\int_{0}^{\infty}g(v)\text{e}^{-sv}dv\int_{0}^{\infty}f(u)\text{e}^{-su}du=\int_{0}^{\infty}g(v)\left[\int_{0}^{\infty}f(u)\text{e}^{-s(u+v)}du\right]dv.
$$
Para avaliar esta última integral introduzimos a variável \(u = t + v\). Neste caso \(t=v\) quando \(u=0\) e \(du=dt\), o que permite escrever
$$
H(s)=\int_{0}^{\infty}g(v)\left[\int_{v}^{\infty}f(t-v)\text{e}^{-st}dt\right]dv.
$$
Admitindo que a ordem de integração pode ser invertida, integramos primeiro em \(v\). Observe que os limites de integração, inicialmente \(v \lt t \lt \infty\), passam a ser \(0 \lt v \lt t\) (veja figura) e temos
Figura: Região de integração para a integral de convolução
$$
I=L^{-1}\left\{ \frac{1}{s^{2}+a^{2}}\frac{1}{s^{2}+a^{2}}\right\} =\frac{1}{a^{2}}\int_{0}^{t}\text{sen }(at)\text{sen }a(t-\tau)d\tau.
$$
Para calcular esta integral usamos a relação trigonométrica
$$
\text{sen }a\,\text{sen }b=\frac{1}{2}[\cos(a-b)+\cos(a+b)]
$$
ou, no caso presente
$$
\text{sen }a\tau\text{sen }a(t-\tau)=\frac{1}{2}[\cos a(2\tau-t)-\cos at]
$$
para obter
$$
I=\frac{1}{2a^{2}}\left[\int_{0}^{t}\cos a(2\tau-t)d\tau-\cos at\int_{0}^{t}d\tau\right]=\frac{1}{2a^{3}}(\text{sen }at-at\cos at).
$$
A primeira integral pode ser avaliada por meio de uma substituição de variáveis, \(u=a(2\tau-t)\), \(du=2ad\tau\).
Exercícios 5
1. Determine as transformadas inversas:
c. \(F(s)=\frac{1}{(s+1)^{3}(s^{2}+4)}\)d. \(F(s)=\frac{G(s)}{s^{2}+1}\)
Se \(f\) é função periódica, \(f(t+T)=f(t)\) então
\begin{array}{l}
L\{f(t)\}=\frac{1}{1-\text{e}^{-sT}}\int_{0}^{T}f(t)\text{e}^{-st}dt.\\
\end{array}
Transformada das derivadas:
\begin{array}{l}
L\{f(t)\}=sL\{f(t)\}-f(0), \\ L\{f^{\prime\prime}(t)\}=s^{2}L\{f(t)\}-sf(0)-f^{\prime}(0). \\
\end{array}
Integral de Convolução:
\begin{array}{l} h(t)=L^{-1}[F(s)G(s)]=\int_{0}^{t}f(t-\tau)g(\tau)d\tau \\ \end{array}
Até agora vimos como resolver apenas dois tipos de equações diferenciais de segunda ordem homogêneas: as com coeficientes constantes e as equações de Euler. O método que estudaremos agora se baseia na hipótese de que as soluções procuradas são analíticas pelo menos em alguma vizinhança de um ponto \(x_{0}\) onde são dadas as condições de contorno. Isto significa que estas funções possuem derivadas de todas as ordens neste ponto e portanto podem ser expressas como uma série de potências. É possível, em alguns casos, que uma solução encontrada desta forma seja identificada como uma das funções elementares do cálculo. No entanto, no caso geral, ela não representa nenhuma destas funções elementares e deve ser expressa e definida através de sua série de potências1.
(1) Consulte o Apêndice para uma revisão sobre séries de potências.
Soluções em torno de ponto ordinário
Procuramos agora um método para a solução de equações diferenciais homogêneas do segundo grau mais gerais que as anteriormente estudadas, na forma de
(1)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{d^{2}y(x)}{dx^{2}}+G(x)y(x)=0,
$$
onde \(P(x)\), \(F(x)\) e \(G(x)\) são funções contínuas.
Definição: Um ponto \(x_{0}\) onde a função \(P\) não se anula, ou seja \(P(x_{0})\neq0\), é chamado um ponto ordinário. Caso contrário, se \(P(x_{0})=0\), dizemos que \(x_{0}\) é um ponto singular da equação diferencial.
Se \(x_{0}\) é um ponto ordinário, como \(P(x_{0})\neq0\), e \(P\) é contínua, então existe um intervalo em torno de \(x_{0}\) onde a função não se anula. Para este intervalo podemos escrever
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0,
$$
onde as funções
$$
f(x)=\frac{F(x)}{P(x)},\,\,\,\,g(x)=\frac{G(x)}{P(x)}
$$
são igualmente contínuas. Pelo teorema de existência e unicidade existe uma única solução de (1) neste intervalo, satisfazendo as condições de contorno
$$
y(x_{0})=y_{0}\,\,\,\text{e}\,\,\,y^{\prime}(x_{0})=y_{0}^{\prime}.
$$
O método de solução de equações diferenciais usando séries de potências se baseia na suposição de que a solução procurada é uma função analítica nas vizinhanças do ponto \(x_{0}\) e que, portanto, pode ser escrita como um polinônio com coeficientes constantes \(a_{n}\),
$$
y(x)=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n}.
$$
Em seguida substituimos esta expressão e suas derivadas na equação diferencial e procuramos identificar os coeficientes \(a_{n}\). O ponto \(x_{0}\), em torno do qual se busca as soluções válidas, geralmente é o ponto onde as condições de contorno são estabelecidas. Usaremos um exemplo para tornar mais claro o método.
Exemplo 1. Vamos resolver, pelo método de séries de potências, a equação diferencial
(2)
$$ y^{\prime\prime}-y=0 $$
em torno do ponto ordinário \(x_{0}=0\). Fazendo a suposição inicial de que \(y\) é analítica próximo de \(x=0\), escrevemos esta função e suas derivadas como as séries, respectvivamente,
onde se deve observar que a série correspondente à derivada primeira se inicia em \(n=1\) devido ao desaparecimento do termo constante \(a_{0}\). Analogamente, a derivada segunda se inicia em \(n=2\). Substituindo na equação (2) temos a identidade
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-\sum_{n=0}^{\infty}a_{n}x^{n}=0.
$$
Note que ambas as séries se iniciam com um termo constante. Para tornar mais fácil a comparação dos termos envolvidos introduzimos um novo índice \(k\), \(n=k+2\), e reescrevemos a primeira série da seguinte forma
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}=\sum_{k=0}^{\infty}(k+2)(k+1)a_{k+2}x^{k}.
$$
Reescrevemos agora a equação diferencial como
$$
\sum_{n=0}^{\infty}(n+2)(n+1)a_{n+2}x^{n}-\sum_{n=0}^{\infty}a_{n}x^{n}=0
$$
onde o índice \(n\) foi recolocado no primeiro termo. Podemos agora juntar as duas somas
$$
\sum_{n=0}^{\infty}[(n+2)(n+1)a_{n+2}-a_{n}]x^{n}=0.
$$
Observando que este polinômio só pode ser nulo se todos os coeficientes de cada potência de \(x\) for nulo temos
$$
(n+2)(n+1)a_{n+2}-a_{n}=0
$$
ou
$$
a_{n+2}=\frac{a_{n}}{(n+2)(n+1)}.
$$
Esta é a chamada relação de recorrência para os coeficientes \(a_{n}\) que nos permite expressar todos estes coeficientes em termos de apenas dois deles, que permanencem indeterminados. Tomando \(n\) com valores sucessivos obtemos
$$
n=0\Rightarrow a_{2}=\frac{a_{0}}{2.1},
$$
Prosseguindo com esta operação vemos que
$$
a_{n}=\frac{a_{0}}{n!}\;\;\text{ para n par}\;\;\;a_{n}=\frac{a_{1}}{n!}\,\,\,\,\text{ para n impar}.
$$
Juntando os termos na expressão
$$
y=a_{0}+a_{1}x+a_{2}x^{2}+\cdots
$$
$$
y=a_{0}\left(1+\frac{x^{2}}{2!}+\frac{x^{4}}{4!}+\cdots\right)+a_{1}\left(x+\frac{x^{3}}{3!}+\frac{x^{5}}{5!}+\cdots\right).
$$
As séries dentro dos parênteses correspondem às expansões em séries para as funções cosseno e seno hiperbólico, respectivamente e portanto
$$
y(x)=a_{0}\cosh x+a_{1}\text{senh}x,
$$
que é uma combinação linear das funções \(\text{e}^{x}\) e \(\text{e}^{-x}\) que já sabiamos ser soluções da equação (2).
Se for possível identificar a série obtida como solução com uma função elementar, como no caso acima, então já sabemos que ela converge para esta função. se isso não ocorrer, se não pudermos identificar qual é esta solução em termos das funções conhecidas, então teremos que realizar testes de convergência para descobrir o intervalo onde é válida a solução.
Exemplo 2. Vamos resolver a equação
$$
y^{\prime\prime}+x^{2}y=0
$$
em torno de \(x_{0}=0\) (um ponto ordinário). Substituimos \(y=\sum_{n=0}^{\infty}a_{n}x^{n}\) e sua derivada segunda na equação diferencial para obter
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0.
$$
Só o primeiro somatório contém termos constante e múltiplo de \(x\) por isto escrevemos estes termos (\(n=2\) e \(n=3\)) em separado,
$$
2a_{2}+3.2a_{3}x+\sum_{n=4}^{\infty}n(n-1)a_{n}x^{n-2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0.
$$
Estes termos devem se anular, \(a_{2}=0,a_{3}=0\). Modificando a primeira soma para que ela se inicie em \(n=0\) temos
$$
\sum_{n=0}^{\infty}(n+4)(n+3)a_{n+4}x^{n+2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0\Rightarrow
$$
$$
\sum_{n=0}^{\infty}[(n+4)(n+3)a_{n+4}+a_{n}]x^{n+2}=0,
$$
de onde podemos extrair nossa relação de recorrência:
$$
a_{n+4}=-\frac{a_{n}}{(n+4)(n+3)}.
$$
Calculamos a seguir alguns termos da série
$$
a_{4}=\frac{-a_{0}}{3.4};\,\,\,a_{5}=\frac{-a_{1}}{4.5};\,\,\,a_{6}=\frac{-a_{2}}{5.6}=0;\,\,\,a_{7}=\frac{-a_{3}}{6.7}=0
$$
$$
a_{8}=\frac{-a_{4}}{7.8}=\frac{a_{0}}{3.4.7.8};\,\,\,a_{9}=\frac{-a_{5}}{8.9}=\frac{a_{1}}{4.5.8.9};\,\,\,a_{10}=\frac{-a_{6}}{9.10}=0.
$$
Como a solução é \(y\), obtida por
$$
y(x)=a_{0}+a_{1}x+a_{2}x^{2}+a_{3}x^{3}+…
$$
Exemplo 3. Observando que todos os pontos são pontos ordinários na equação de Airy
$$
y^{\prime\prime}-xy=0,
$$
procuramos uma solução em torno de \(x_{0}=0\). Fazemos a suposição inicial de que a solução é analítica em torno da origem, ou seja, \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n}\), e substituimos esta expressão e suas derivadas na equação diferencial para obter
de onde concluimos que \(a_{2}=0\). Para tornar a comparação entre as duas somas mais simples modificamos o primeiro somatório para que comece em \(n=0\) e juntamos as duas somas,
Inserindo estes coeficientes na série de potência temos a solução geral
$$
y(x)=a_{0}\left[1+\sum_{n=1}^{\infty}\frac{x^{3n}}{2\cdot3\ldots(3n-1)3n}\right]+a_{1}\left[x+\sum_{n=1}^{\infty}\frac{x^{3n+1}}{3\cdot4\ldots3n(3n+1)}\right].
$$
Exemplo 4. Queremos agora encontrar uma solução para a equação diferencial
$$
y^{\prime\prime}+xy^{\prime}+2y=0,
$$
em torno de \(x_{0}=0\). Para isto substituimos \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n}\) e suas derivadas na equação para obter
Desta forma conseguimos escrever todas os somatórios em potências de \(x^{n}\). No entanto, apenas a primeira e a terceira possuem o termo constante (\(n=0\)). Separamos estes termos constantes e juntamos no mesmo somatório os termos restantes para obter
$$
a_{6}=\frac{-a_{4}}{5}=\frac{-a_{0}}{3\cdot5},a_{7}=\frac{-a_{5}}{6}=\frac{-a_{1}}{2\cdot4\cdot6},a_{8}=\frac{-a_{6}}{7}=\frac{a_{0}}{3\cdot5\cdot7},
$$
e assim por diante. Juntando estes coeficientes na série inicial temos
Retornando ao método de séries de potências, cabe completar nossa discussão com um comentário adicional. Para resolver o problema
(3)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{dy(x)}{dx}+G(x)y(x)=0,
$$
em torno de um ponto ordinário \(x_{0}\) fizemos a hipótese de que existe uma solução analítica em uma vizinhança deste ponto, ou seja, que possui uma expansão de Taylor
(4)
$$ y(x)=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n} $$
convergente no intervalo \(|x-x_{0}|\lt \rho\). Vamos verificar se esta é realmente uma hipótese justificada, examinando o raio de convergência da solução. Derivando (4) \(m\) vezes obtemos
Calculando o valor desta derivada m-ésima no ponto \(x=x_{0}\), vemos que todos os termos da soma se anulam exceto o termo \(m = n\) e podemos escrever
$$
y^{(m)}(x_{0})=m!a_{m},
$$
de onde encontramos um valor para o coeficiente
$$
a_{n}=\frac{y^{(n)}(x_{0})}{n!}.
$$
Surge aqui uma questão. Partindo apenas da equação diferencial (3) é sempre possível encontrar \(y^{(n)}(x_{0})\) e portanto \(a_{n}\). Suponhamos que \(y(x)=\phi(x)\) é uma solução satisfazendo as condições iniciais \(y(x_{0})=y_{0}\), \(y^{\prime}(x_{0})=y_{0}^{\prime}\). Neste caso \(a_{0}=y_{0},a_{1}=y_{0}^{\prime}\). De (3) temos \(P\phi^{\prime\prime}+F\phi^{\prime}+G\phi=0\), ou seja,
(5)
$$
\phi^{\prime\prime}=-\frac{F}{P}\phi^{\prime}-\frac{G}{P}\phi=-f\phi^{\prime}-g\phi,
$$
lembrando que \(P\neq0\) em torno de \(x_{0}\). Notando que
$$
2!a_{2}=\phi^{\prime\prime}(x_{0}),\;\;\phi(x_{0})=y_{0}=a_{0},\;\;\phi^{\prime}(x_{0})=y_{0}^{\prime}=a_{1}
$$
temos
$$
2!a_{2}=\phi^{\prime\prime}(x_{0})=-f(x_{0})y^{\prime}(x_{0})-g(x_{0})y(x_{0})=-f(x_{0})a_{1}-g(x_{0})a_{0}.
$$
Derivando a equação (5) e fazendo \(x=x_{0}\) temos
$$
3!a_{3}=\phi^{(3)}(x_{0})=-[f\phi^{\prime\prime}+(f^{\prime}+g)\phi^{\prime}+g^{\prime}\phi]|_{x=x_{0}}=
$$
$$
=-2!a_{2}f(x_{0})+[f^{\prime}(x_{0})+g(x_{0})]a_{1}+g^{\prime}(x_{0})a_{0},
$$
onde denotamos por \(\phi^{(3)}\) a derivada terceira. Se as funções \(f(x)\) e \(g(x)\) são polinômios então possuem derivadas de qualquer ordem e podemos prosseguir com este mesmo tipo de cálculo para encontrar os demais coeficientes \(a_n\), para \(n\gt 3\). Caso contrário, se forem funções mais gerais, como por exemplo um quociente de polinômios, então é necessário que sejam funções analíticas e possamos escrever
$$
f(x)=\sum_{n=0}^{\infty}f_{n}(x-x_{0})^{n},\,\,\,\,g(x)=\sum_{n=0}^{\infty}f_{n}(x-x_{0})^{n}
$$
para que o método possa ser empregado. Neste mesma linha de pensamento, generalizaremos a noção de ponto ordinário da equação (3) que repetiremos aqui:
(3 – repetida)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{dy(x)}{dx}+G(x)y(x)=0,
$$
Então \(x_{0}\) é um ponto ordinário se \(f=F/P\) e \(g=G/P\) são analíticas em \(x=x_{0}\). Se isso não ocorrer o ponto \(x=x_{0}\) é um ponto singular.
Exercícios 1
Resolva as seguintes equações diferenciais usando o método de séries de potências em torno do ponto \(x_{0}=0\), exceto quando outro ponto for indicado:
Teorema 1 Se \(x=x_{0}\) é um ponto ordinário da equação \(Py^{\prime\prime}+Fy^{\prime}+Gy=0\), ou seja, se \(f=F/P\) e \(g=G/P\) são analíticas em \(x=x_{0}\) então a sua solução geral é
$$
y=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n}=a_{0}y_{1}(x)+a_{1}y_{2}(x)
$$
onde \(y_{1}\) e \(y_{2}\) são linearmente independentes em \(x_{0}\). O raio de convergência da séries para \(y_{1}\) e \(y_{2}\) é, no mínimo, igual ao menor dos raios de convergência das séries de \(f\) e \(g\). Para determinar estes raios de convergência podemos expandir \(f\) e \(g\) em séries de Taylor e realizar os testes habituais de convergência (Consulte o apêndice.). Por outro lado, se \(P,\,\,F\) e \(G\) são polinômios, é possível mostrar usando a teoria das funções de variáveis complexas que \(G/P\) possui desenvolvimento em séries em torno de \(x=x_{0}\) se \(P(x_{0})\neq0\). Além disto, o raio de convergência desta série é \(\rho=|x_{0}-r|\) onde \(r\) é raiz de \(P\) mais próxima de \(x_{0}\). Mostraremos a seguir, através de exemplos o cálculo deste raio de convergência, em particular no caso de as raízes de \(P\) serem complexas.
Raios de Convergência
Exemplo 5. Qual é o raio de convergência da série de \(f(x)=(1+x^{2})^{-1}\) em torno de \(x=0\)? Devemos encontrar primeiro a expansão em séries de potência para esta função,
$$
f(x)=\sum_{n=0}^{\infty}\frac{1}{n!}f^{(n)}(x_{0})(x-x_{0})^{n}.
$$
Temos
$$
f(0)=1,\;f^{\prime}(x)=\frac{-2x}{(1+x^{2})^{2}}, \;f^{\prime}(0)=0,\;\text{etc.}
$$
A função pode ser expressa em série
$$
f(x)1-x^{2}+x^{4}-x^{6}+\cdots+(-1)^{n}x^{2n}.
$$
Pelo teste da razão
$$
L=\lim_{n\rightarrow\infty}|\frac{(-1)^{n+1}x^{2(n+1)}}{(-1)^{n}x^{2n}}|=x^{2}.
$$
Portanto, a série converge no intervalo \(-1\lt x\lt 1\), e o raio de convergência é \(\rho=1\). Um outro procedimento, em geral mais simples, pode ser adotado. As raizes de \(1+x^{2}\) são \(x=\pm i\). A distância no plano complexo entre \(0\) e \(i\) é \(1\). Dai \(\rho=1\).
Exemplo 6 Vamos verificar a convergência da série de \((x^{2}-2x+2)^{-1}\) em torno de \(x=0\) e \(x=1\). A função possui denominador que se anula em \(x=1\pm i\). No plano complexo a distância entre \(x=0\) e \(1\pm i\) é \(\rho=\sqrt{2}\), que é o raio de convergência da série desta função em torno de \(x=0\). A distância entre \(x=1\) e \(1\pm i\) é \(\rho=1\), que é o raio de convergência da série desta função em torno de \(x=1\).
Raios de convergência
Exemplo 7: Determine a raio de convergência mínimo da solução de
$$
(1+x^2)y^{\prime\prime}+2xy^{\prime}+4x^2y=0
$$
em torno de \(x=0\) e \(x=1/2\). Neste caso as funções \(P\), \(F\) e \(G\) são polinômios e \(P\) tem zeros em \(x=\pm i\). Os raios de convergência são, respectivamente as distâncias
$$
d(0,\pm i)=1,\,\,\,d\left(\frac{1}{2},\pm i\right)=\frac{\sqrt{5}}{2},
$$
onde \(d(a,b)\) é a distância entre os pontos \(a\) e \(b\) no plano complexo.
Uma equação diferencial que surge com freqüência em aplicações matemática aplicada e na física e que, por isto, vale a pena ser tratada em separado é a equação de Legendre
(6)
$$
(1-x^{2})y^{\prime\prime}-2xy^{\prime}+l(l+1)y=0,
$$
onde \(l\) é uma constante real dada. Observando que os dois primeiros termos são a derivada de uma função
$$
\frac{d}{dx}[(1-x^{2})y^{\prime}]=(1-x^{2})y^{\prime\prime}-2xy^{\prime}
$$
reescreveremos a equação como
$$
[(1-x^{2})y^{\prime}]^{\prime}+ky=0.
$$
onde denotamos \(k=l(l+1)\) para obter uma notação mais compacta. Como \(x=0\) é um ponto ordinário da equação substituimos a solução analítica \(y=\sum_{n=0}^{\infty}a_{n}x^{n}\) na equação (6) obtendo
$$
(1-x^{2})\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-2x\sum_{n=1}^{\infty}na_{n}x^{n-1}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0\Rightarrow
$$
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n}-2x\sum_{n=1}^{\infty}na_{n}x^{n-1}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0\Rightarrow
$$
$$
\sum_{n=0}^{\infty}(n+2)(n+1)a_{n+2}x^{n}-\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n}-2\sum_{n=1}^{\infty}na_{n}x^{n}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0.
$$
Retomando a constante \(k=l(l+1)\), coletaremos primeiro os termos constantes (múltiplos de \(x^{0}\)) que correspondem àqueles quando \(n=0\):
$$
2a_{2}+l(l+1)a_{0}=0,
$$
e os termos coeficientes de \(x\,(n=1)\):
$$
6a_{3}+[-2+l(l+1)]a_{1}=0.
$$
Os termos restantes podem ser agrupados sob o mesmo sinal de somatório:
$$
\sum_{n=2}^{\infty}[(n+2)(n+1)a_{n+2}-n(n-1)a_{n}-2na_{n}+ka_{n}]x^{n}=0,
$$
que só é nulo se os coeficientes se anulam,
$$
(n+2)(n+1)a_{n+2}+\left[-n(n-1)-2n+l(l+1)\right]a_{n}=0,\,\,\,\,n\geq2.
$$
Podemos rearrumar a expressão em colchetes como \([…]=(l+n)(l+n+1)\) e dai obtemos a fórmula de recorrência
$$
a_{n+2}=-\frac{(l+n)(l+n+1)}{(n+2)(n+1)}a_{n},\,\,\,\,n\geq2.
$$
Destas relações podemos encontrar os coeficientes da expansão de \(y(x)\), em termos das constantes \(a_{0}\) e \(a_{1}\):
$$
a_{2}=-\frac{l(l+1)}{2!}a_{0},
$$
$$
a_{3}=-\frac{(l-1)(l+2)}{3!}a_{1},
$$
$$
a_{4}=-\frac{(l-2)(l+3)}{4\cdot3}a_{2}=\frac{(l-2)l(l+1)(l+3)}{4!}a_{0},
$$
$$
a_{5}=-\frac{(l-3)(l+4)}{5\cdot4}a_{3}=\frac{(l-3)(l-1)(l+2)(l+4)}{5!}a_{1},
$$
e assim por diante. Com estes coeficientes construimos duas soluções
$$
y_{1}(x)=1-\frac{l(l+1)}{2!}x^{2}+\frac{(l-2)l(l+1)(l+3)}{4!}x^{4}+\cdots,
$$
$$
y_{2}(x)=x-\frac{(l-1)(l+2)}{3!}x^{3}+\frac{(l-3)(l-1)(l+2)(l+4)}{5!}x^{5}+\cdots.
$$
Observe que \(y_{1}\) só possui potências pares de \(x\) e, portanto, é uma função par, enquanto \(y_{2}\) só possui potências ímpares de \(x\), sendo uma função impar. Logo elas são l. i. e \(y=a_{0}y_{1}+a_{1}y_{2}\) é uma solução geral da equação de Legendre. As soluções são convergentes no intervalo \(-1\lt x\lt 1\).
Solução em séries em torno de pontos singulares
Pontos singulares regulares
Se \(P(x),\,\,F(x)\) e \(G(x)\) são polinômios sem fatores comuns na equação
(7)
$$
P(x)y^{\prime\prime}+F(x)y^{\prime}+G(x)y=0,
$$
os pontos singulares da equação diferencial são aqueles onde \(P(x) = 0\). Neste caso o método tratado na seção anterior não pode ser aplicado pois a solução não será analítica nestes pontos.
Exemplo 8. A equação de Euler
$$
x^{2}y^{\prime\prime}-2y=0
$$
tem um ponto singular em \(x = 0\). Como vimos no capítulo anterior, esta equação tem soluções
$$
y_{1}=x^{2}\;\;\text{ e }\;\;y_{2}=\frac{1}{x}
$$
em um intervalo que não inclue o ponto singular. A primeira destas soluções é limitada e analítica em \(\mathbb{R}\). A segunda não é analítica em \(x=0\) e, por isto, não pode ser escrita como \(y_{2}=\sum_{n=0}^{\infty}a_{n}x^{n}\).
Definição Se as funções \(P\), \(F\) e \(G\) são polinômios e \(x_{0}\) é um ponto singular da equação (7) então \(x_{0}\) é chamado de ponto singular regular se existirem os limites
$$
\lim_{x\rightarrow x_{0}}(x-x_{0})\frac{F(x)}{P(x)},\;\;\; \lim_{x\rightarrow x_{0}}(x-x_{0})^{2}\frac{G(x)}{P(x)}.
$$
No caso de as funções \(P\), \(F\) e \(G\) não serem polinômios mas funções mais gerais, então um ponto singular \(x_{0}\) da equação (11) é um ponto singular regular se
$$
(x-x_{0})\frac{F(x)}{P(x)}\,\text{ e }\,(x-x_{0})^{2}\frac{G(x)}{P(x)}
$$
são funções analíticas. Se o ponto for singular mas não regular dizemos que ele é uma singularidade irregular.
Exemplo 9. Vamos verificar a natureza dos pontos singulares da equação de Legendre
$$
(1-x^{2})y-2xy^{\prime}+l(l+1)y=0,
$$
onde \(l\) é uma constante. Eles são regulares ou irregulares? Temos que, neste caso
$$
\frac{F(x)}{P(x)}=-\frac{2x}{1-x^{2}},\,\,\,\frac{G(x)}{P(x)}=\frac{l(l+1)}{1-x^{2}},
$$
e, portanto, \(x=\pm1\) são os pontos sigulares. O ponto \(x=1\) é ponto singular regular pois
$$
\lim_{x\rightarrow 1}(x-1)\frac{-2x}{1-x^{2}}=\lim_{x\rightarrow 1}\frac{-2x(x-1)}{(1-x)(1+x)}=\lim_{x\rightarrow 1}\frac{2x}{1+x}=1,
$$
$$
\lim_{x\rightarrow 1}(x-1)^{2}\frac{l(l+1)}{1-x^{2}}=\lim_{x\rightarrow 1}\frac{(1-x)^{2}l(l+1)}{(1-x)(1+x)}=\lim_{x\rightarrow 1}\frac{(1-x)l(l+1)}{1+x}=0.
$$
O mesmo ocorre com \(x=-1\),
$$
\lim_{x\rightarrow-1}(x+1)\frac{-2x}{1-x^{2}}=\lim_{x}\frac{-2x(x+1)}{(1-x)(1+x)}=\lim_{x}\frac{-2x}{1-x}=1,
$$
$$
\lim_{x\rightarrow-1}(x+1)^{2}\frac{l(l+1)}{1-x^{2}}=\lim_{x\rightarrow-1}\frac{(x+1)^{2}l(l+1)}{(1-x)(1+x)}=\lim_{x\rightarrow-1}\frac{(x+1)l(l+1)}{(1-x)}=0.
$$
Vimos, portanto, que os dois pontos singulares desta equação são regulares.
O Método de Frobenius
Existem diversos problemas advindos das aplicações onde a solução procurada está exatamente em torno de um ponto singular e portanto a técnica estudada até este ponto não é suficiente. Procuramos então encontrar soluções para equações diferenciais do tipo
(8)
$$P(x)y^{\prime\prime}+F(x)y^{\prime}+G(x)y=0,$$
em torno de \(x=x_{0}\), um ponto singular regular. Vale lembrar que \(f=F/P\) não é uma função analítica em torno destes pontos. Nos restringiremos ao estudos das soluções em torno de pontos singulares regulares. Podemos supor, sem perda de generalidade, que o ponto singular regular é \(x_{0}=0\). (Se não for este o caso basta fazer uma substituição de variável, tomando \(u=x-x_{0}\)). Como o ponto é regular, os limites
$$
\lim_{x\rightarrow0}x\frac{F}{P},\;\;\;\lim_{x\rightarrow0}x^{2}\frac{G}{P},
$$
são ambos finitos e as funções \(xF/P=xf\) e \(x^{2}G/P=x^{2}g\) são ambas analíticas. Sendo analíticas elas possuem expansão em séries de potências em torno \(x=0\)
$$
xf(x)=\sum_{n=0}^{\infty}f_{n}x^{n},\,\,\,\,x^{2}g(x)=\sum_{n=0}^{\infty}g_{n}x^{n},
$$
onde \(f_{n}\) e \(g_{n}\) são constantes, são convergentes em \(|x|\lt \rho\) em torno da origem. Dai notamos que
$$
f_{0}=\lim_{x\rightarrow0}x\frac{F}{P},\,\,\,\,g_{0}=\lim_{x\rightarrow0}x^{2}\frac{G}{P}.
$$
Reescrevemos a equação (8) multiplicada por \(x^{2}\) e dividida por \(P\).
$$
x^{2}y^{\prime\prime}+x\,xfy^{\prime}+x^{2}gy=0,
$$
ou ainda,
$$
x^{2}y^{\prime\prime}+xy^{\prime}\left(\sum_{n=0}^{\infty}f_{n}x^{n}\right)+y\left(\sum_{n=0}^{\infty}g_{n}x^{n}\right)=0,
$$
Note que esta seria uma equação de Euler se os termos dentro dos parênteses fossem constantes. Isto ocorreria se todas as constantes \(f_{n}\) e \(g_{n}\) (para \(n=1,\,2\),…) fossem nulas, restanto portanto apenas \(f_{0}\) e \(g_{0}\) não nulas. As equações de Euler foram resolvidas através da substituição \(y=x^{r}\). No caso presente tentaremos soluções na forma de
(9)
$$
y(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r}=x{}^{r}\sum_{n=0}^{\infty}a_{n}x^{n},
$$
onde \(r\) é uma constante por enquanto indeterminada. Deveremos ser capazes de determinar \(r\) por substituição de (9) na equação diferencial. Vamos ilustrar o uso desse método nos próximos exemplos.
Exemplo 10. A equação diferencial
$$
2xy^{\prime\prime}-y^{\prime\prime}+2y=0,
$$
possui um ponto singular em \(x=0\). Em torno deste ponto podemos utilizar a solução de Frobenius para resolvê-la. Vemos que, de fato, \(x=0\) é ponto singular regular pois
$$
f=-\frac{1}{2x},\,\,\,\,g=\frac{1}{x},
$$
$$
xf=-\frac{1}{2},\,\,\,\,x^{2}g=x,
$$
sendo os dois últimos termos finitos quando \(x\rightarrow0\). Derivamos a solução tentativa \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r},\) obtendo
$$
y^{\prime}=\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1},
$$
$$
y^{\prime\prime}=\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}.
$$
Observe que agora não é necessário eliminar o termo com \(n=0\) na derivada primeira pois este não é um termo constante na equação. O mesmo ocorre com o termo \(n=1\) na derivada segunda. Substituindo as derivadas na equação temos
$$
2x\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}-\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+2\sum_{n=0}^{\infty}a_{n}x^{n+r}=0,
$$
ou seja,
$$
\sum_{n=0}^{\infty}(n+r)(2n+2r-3)a_{n}x^{n+r-1}+\sum_{n=0}^{\infty}2a_{n-1}x^{n+r-1}=0.
$$
O último somatório foi modificado da seguinte forma:
$$
\sum_{n=0}^{\infty}a_{n}x^{n+r}=\sum_{n=1}^{\infty}a_{n-1}x^{n+r-1},
$$
para facilitar a comparação entre todos os termos da série. Escrevemos agora o termo multiplo de \(x^{r-1}\), correspondente a \(n=0\), em separado e os demais termos dentro do mesmo somatório, que começa em \(n=1\):
$$
[2r(r-1)-r]a_{0}x^{r-1}+\sum_{n=1}^{\infty}[(n+r)(2n+2r-3)a_{n}+2a_{n-1}]x^{n+r-1}=0.
$$
Os coeficientes de cada potência de \(x\) devem se anular independentemente, em particular o termo multiplo de \(x^{r-1}\) que fornece valores para a constante \(r\), até aqui desconhecida. Supondo \(a_{0}\neq 0\) temos
$$
2r(r-1)-r=2r^{2}-3r=0,
$$
é a chamada equação indicial com raizes, \(r_{1}=0\) e \(r_{2}=3/2,\) que são denominadas os expoentes da singularidade. Os termos restantes podem ser escritos como
$$
\sum_{n=1}^{\infty}[(n+r)(2n+2r-3)a_{n}+2a_{n-1}]x^{n+r-1}=0.
$$
Anulando os coeficientes de todas as potências de \(x\) temos uma relação de recorrência para os termos \(a_{n}\).
$$
a_{n}=\frac{-2a_{n-1}}{(n+r)(2n+2r-3)},\,\,\,\,n\geq1.
$$
Podemos agora obter uma solução para cada um dos valores de \(r\). Para \(r=0\) temos:
$$
a_{n}=\frac{-2a_{n-1}}{n(2n-3)},\,\,\,\,n\geq1,
$$
o que leva aos coeficientes
A solução correspondente é
$$
y_{1}(x)=a_{0}\left(1+2x-2x^{2}+\frac{4}{9}x^{3}-\frac{2}{45}x^{4}+\frac{4}{45^{2}}x^{5}+\ldots\right).
$$
Para \(r=3/2\) a relação de recorrência se torna
$$
a_{n}=\frac{-2a_{n-1}}{2n(n+3/2)}=\frac{-2a_{n-1}}{n(2n+3)},\,\,\,\,n\geq1.
$$
$$
y_{2}(x)=a_{0}\left(1-\frac{2x}{5}+\frac{2x^{2}}{5.7}-\frac{4x^{3}}{3.5.7.9}+\frac{4x^{4}}{3.5.7.9.11}+\cdots\right).
$$
A solução geral é uma combinação linear das duas.
Exemplo 11. Utilizaremos o método de Frobenius para resolver a equação
$$
2x^{2}y^{\prime\prime}-xy^{\prime}+(1+x)y=0,
$$
em torno de \(x=0\). Novamente vemos que o ponto é singular regular pois
$$
f=-\frac{1}{2x},\,\,\,\,g=\frac{1+x}{2x^{2}},
$$
$$
xf=-\frac{1}{2},\,\,\,\,x^{2}g=\frac{1+x}{2}.
$$
Substituindo \(y=\sum_{n=0}^{\infty}a_{n}x^{n+r}\) e suas derivadas obtemos
$$
2x^{2}\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}-x\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+(1+x)\sum_{n=0}^{\infty}a_{n}x^{n+r}=0,
$$
$$
\sum_{n=0}^{\infty}\left[2(n+r)(n+r-1)-(n+r)+1\right]a_{n}x^{n+r-1}+\sum_{n=0}^{\infty}a_{n}x^{n+r+1}=0,
$$
A última soma pode ser reescrita, para efeito de comparação com os termos anteriores, da seguinte forma:
$$
\sum_{n=0}^{\infty}a_{n}x^{n+r+1}=\sum_{n=0}^{\infty}a_{n-1}x^{n+r}.
$$
Voltamos a escrever a equação diferencial com o termo \(n=0\) isolado:
$$
[2r(r-1)-r+1]a_{0}x^{r}+\sum_{n=0}^{\infty}\left\{ \left[2(n+r)(n+r-1)-(n+r)+1\right]a_{n}+a_{n-1}\right\} x^{n+r}=0.
$$
Os coeficientes de potências diversas de \(x\) devem se anular independentemente. Em particular o termo múltiplo de \(x^{r}\) nos permite encontrar a equação indicial
$$
2r(r-1)-(r-1)=(r-1)(2r-1)=0,
$$
cujas raizes são \(r_{1}=1\) e \(r_{2}=1/2.\) Anulando os coeficientes das demais potências de \(x\) temos
$$
[2(n+r)(n+r-1)-(n+r)+1]a_{n}+a_{n-1}=0
$$
o que é uma relação de recorrência para os termos \(a_{n}\).
$$
a_{n}=\frac{-a_{n-1}}{2(n+r)(n+r-1)-(n+r-1)}=\frac{-a_{n-1}}{(n+r-1)[2(n+r)-1]},\,\,\,n\geq1.
$$
Cada uma das raízes encontradas das para \(r\) nos fornece um conjunto de coeficientes. Para \(r=1\) a relação de recorrência é
$$
a_{n}=\frac{-a_{n-1}}{(2n+1)n},\,\,\,n\geq1,
$$
e portanto
$$
a_{1}=-\frac{a_{0}}{3},\,\,\,a_{2}=\frac{a_{0}}{30},\,\,\,a_{3}=\frac{-a_{0}}{630},\,\,\cdots
$$
O termo genérico pode ser obtido neste caso
$$
a_{n}=\frac{(-1)^{n}a_{0}}{3.5.7\cdots(2n+1)n!},\,\,\,n\geq1.
$$
A solução correspondente é
$$
y_{1}=x^{r}\sum_{n=0}^{\infty}a_{n}x^{n}=x\left[1+\sum_{n=1}^{\infty}\frac{(-1)^{n}x^{n}}{3.5.7\cdots(2n+1)n!}\right].
$$
Para \(r=1/2\) a relação de recorrência se torna
$$
a_{n}=\frac{-a_{n-1}}{n(2n-1)},\,\,\,n\geq1.
$$
Dai
$$
a_{1}=-a_{0},\,\,\,a_{2}=\frac{-a_{1}}{6}=\frac{a_{0}}{6},\,\,\,a_{3}=\frac{-a_{0}}{6.15}\cdots
$$
O termo genérico é
$$
a_{n}=\frac{(-1)^{n}a_{0}}{3.5.7\cdots\left(2n-1\right)n!},\,\,\,n\geq1.
$$
A solução correspondente é
$$
y_{2}=x^{r}\sum_{n=0}^{\infty}a_{n}x^{n}=x^{1/2}\left[1+\sum_{n=1}^{\infty}\frac{(-1)^{n}x^{n}}{3.5.7\cdots\left(2n-1\right)n!}\right].
$$
A solução geral do problema é uma combinação linear das duas soluções
$$
y(x)=c_{1}y_{1}(x)+c_{2}y_{2}(x).
$$
Fica como exercício o cálculo dos raios de convergência das soluções encontradas.
Retornando ao formalismo geral, resolvemos equações do tipo estudado por Frobenius através de soluções que se decompõem em séries de potência
$$
y=\sum_{n=0}^{\infty}a_{n}x^{n+r},
$$
cujas derivadas são
$$
y^{\prime}=\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1},\,\,\,\,y^{\prime\prime}=\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}.
$$
Sendo \(x=0\) um ponto singular regular desta equação temos que \(xf\) e \(x^{2}g\) são analíticas e podem ser expressas como as séries de potências
$$
xf=\sum_{n=0}^{\infty}f_{n}x^{n}\,\,\text{e}\,\,x^{2}g=\sum_{n=0}^{\infty}g_{n}x^{n}.
$$
Substituindo \(y\) e suas derivadas na equação diferencial temos
$$
\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r}+\left(\sum_{n=0}^{\infty}f_{n}x^{n}\right)\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+
$$
$$
+\left(\sum_{n=0}^{\infty}g_{n}x^{n}\right)\sum_{n=0}^{\infty}a_{n}x^{n+r}=0.
$$
Fazendo a multiplicação das séries infinitas obtemos
$$
a_{0}F(r)x^{r}+\sum_{n=1}^{\infty}\left\{ F(r+n)a_{n}+\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}\right\} +x^{r+n}=0,
$$
onde
$$
F(r)=r(r-1)+f_{0}r+g_{0}.
$$
Para que o polinômio seja nulo o coeficiente de cada potência de \(x\) deve ser nulo. Como \(a_{0}\neq0\), a anulação do coeficiente de \(x^{r}\) leva à equação indicial, \(F(r)=0\). Caso existam duas raizes reais distintas para esta equação construimos duas soluções l. i.,
$$
y_{1}=x^{r_{1}}\sum_{n=0}^{\infty}a_{n}x^{n},\,\,\,\,y_{2}=x^{r_{2}}\sum_{n=0}^{\infty}b_{n}x^{n},
$$
e uma combinação linear destas duas representa uma solução geral do problema. Por outro lado, se as raízes da equação indicial forem iguais ou se diferirem por um inteiro, um tratamento diferenciado deve ser adotado, como se segue.
Raízes iguais ou que diferem por um inteiro
Na solução da equação de Euler vimos que se \(r_{1}=r_{2}\) então temos uma solução involvendo o logaritmo. O mesmo ocorre aqui, como expresso pelo teorema a seguir.
Teorema Considere a equação diferencial
(10)
$$
L[y]=x^{2}y^{\prime\prime}+x[xf(x)]y^{\prime}+[x^{2}g(x)]y=0,
$$
onde \(x=0\) é ponto singular regular. Neste caso \(xf\) e \(x^{2}g\) são analíticas e podem ser expressas como as séries de potências
$$
xf=\sum_{n=0}^{\infty}f_{n}x^{n},\,\,\,\,\,x^{2}g=\sum_{n=0}^{\infty}g_{n}x^{n}.
$$
A equação indicial é
$$
F(r)=r(r-1)+f_{0}r+g_{0}=0.
$$
Se as raizes desta equação forem reais, tome \(r_{1}\) como sendo a maior delas, \(r_{1}\geq r_{2}\). Uma das soluções será
$$
y_{1}(x)=|x|^{r_{1}}\left[1+\sum_{n=1}^{\infty}a_{n}x^{n}\right],
$$
onde estes coeficientes \(a_{n}\) foram calculados tomando-se \(r=r_{1}\). Caso a segunda raiz seja igual, \(r_{2}=r_{1}\) então uma segunda solução será
$$
y_{2}(x)=y_{1}(x)ln|x|+|x|^{r_{1}}\left[1+\sum_{n=1}^{\infty}b_{n}x^{n}\right].
$$ Se as raizes diferirem por um inteiro \(N\), \(r_{1}-r_{2}=N,\) então uma segunda solução será
$$
y_{2}(x)=Cy_{1}(x)\ln|x|+|x|^{r_{2}}\left[1+\sum_{n=1}^{\infty}c_{n}x^{n}\right],
$$
onde \(C\) é outra constante e os coeficientes \(c_{n}\) foram calculados tomando-se \(r=r_{2}\).
No caso das raizes iguais temos apenas uma solução e procuramos por uma segunda, da mesma forma que fizemos ao tratar das equações de Euler. Vamos procurar uma solução da equação (10) sob a forma de
$$
y=\phi(r,x)=x^{r}\left(\sum_{n=0}^{\infty}a_{n}x^{n}\right),
$$
uma função que depende de \(x\) e de \(r\). Como antes, obtemos a equação
(11)
$$
L\left[\phi\right](r,x)=a_{0}F(r)x^{r}+\sum_{n=1}^{\infty}\left\{ F(r+n)a_{n}+\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}\right\} x^{r+n}.
$$
Se as raizes são iguais fazemos \(r=r_{1}\) nesta equação e escolhemos \(a_{n}\) obtendo uma solução. Para encontrar a outra solução tomamos \(a_{n}\) de forma a anular o termo entre colchetes,
(12)
$$
a_{n}=-\frac{\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}}{F(r+n)},\,\,\,n\geq1,
$$
agora com \(r\) variando continuamente. Admitimos que \(F(r+n)\neq0\). Com esta escolha a equação (11) se reduz a
$$
L\left[\phi\right](r,x)=a_{0}F(r)x^{r},
$$
onde \(F(r)=(r-r_{1})^{2}\), já que \(r_{1}\) é uma raiz dupla da equação indicial. Tomando \(r=r_{1}\) obtemos a solução que já conhecemos,
$$
y_{1}(x)=\phi(r_{1},x)=x^{r_{1}}\left(a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right).
$$
Da mesma forma como fizemos com a equação de Euler, temos agora que
$$
L\left[\frac{\partial\phi}{\partial r}\right]\left(r_{1},x\right)=a_{0}\left.\frac{\partial}{\partial r}[x^{r}(r-r_{1})^{2}]\right|_{r=r_{1}}=
$$
$$
a_{0}[(r-r_{1})^{2}x^{r}\ln x+2(r-r_{1})x^{r}]|_{r=r_{1}}=0,
$$
de onde podemos concluir que
$$
y_{2}(x)=\frac{\partial\phi\left(r_{1},x\right)}{\partial r}|_{r=r_{1}}
$$
é também uma solução. Para obter a forma final desta solução vamos executar a derivação indicada:
$$
y_{2}(x)=\frac{\partial}{\partial r}\left[x^{r_{1}}\left(a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right)\right]{}_{r=r_{1}}=\left(x^{r_{1}}\ln x\right)\left[a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right]+x^{r_{1}}\sum_{n=1}^{\infty}a_{n}^{\prime}x^{n}=
$$
$$
=y_{1}(x)\ln x+x^{r_{1}}\sum_{n=1}^{\infty}a_{n}^{\prime}x^{n},\,\,\,\,x\gt 0,
$$
onde \(a_{n}^{\prime}=da_{n}/dr\) no ponto \(r=r_{1}\), sendo que \(a_{n}\) é obtida através da equação (12) , vista como função de \(x\) e \(r\).
No caso de raizes diferindo por um inteiro a solução se torna um pouco mais complicada. Apenas para esboçar a solução, se tentarmos usar uma solução na forma de
$$
y_{2}(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r_{2}},
$$
teríamos dificuldades ao calcular o termo \(a_{N}\), quando \(r=r_{2}\), por meio da equação (12). Neste caso temos
$$
F(r+N)=(N+r-r_{1})(N+r-r_{2})=(N+r-r_{2})(r-r_{2}),
$$
que é nula quando \(r=r_{2}\). Para contornar esta dificuldade escolhemos \(a_{0}=r-r_{2}\) e os demais termos \(a_{n}\) se tornam todos múltiplos de \(r-r_{2}\) uma vez que são múltiplos de \(a_{0}\) pela equação de recorrência. O fator comum \(r-r_{2}\) no numerador de (12) pode ser cancelado pelo termo igual no denominador, que surge quando \(n=N\). Fazendo uma análise análoga à que foi feita no caso anterior, de raizes iguais, encontra-se uma solução com a forma de
$$
y_{2}(x)=Cy_{1}(x)\ln\left|x\right|+\left|x\right|^{r_{2}}\left[1+\sum_{n=1}^{\infty}c_{n}x^{n}\right],
$$
onde os coeficientes \(c_{n}\) são dados por
$$
c_{n}=\left[\frac{d}{dr}\left(r-r_{2}\right)a_{n}\right]{}_{r=r_{2}},\,\,\,\,n=1,2,\ldots
$$
e \(a_{n}\) são definidos pela equação (12) com \(a_{0}=1\) e
$$
C=\lim_{r\rightarrow r_{2}}(r-r_{2})a_{N}.
$$
Observe que pode ocorrer que \(C\) seja nulo. Neste caso o termo com logaritmo não aparece na solução procurada.
Ela é uma equação linear se pode ser escrita como
$$
P(x)y^{\prime\prime}+F(x)y^{\prime}+G(x)y=R(x).
$$
Neste caso a equação é dita homogênea se \(R(x)=0\). Caso contrário ela é não homogênea. Em muitos casos é útil dividir toda a equação por \(P(x)\), onde esta função não se anula, e reescrever (1) como
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=r(x),
$$
onde os novos coeficientes de \(y\) e suas derivadas são agora
$$
f(x)=\frac{F(x)}{P(x)},\;\,g(x)=\frac{G(x)}{P(x)},\;\,r(x)=\frac{R(x)}{P(x)}.
$$
No caso de ser uma equação homogênea, \(r(x)=0\), então
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0.
$$
Figura: Sistema massa-mola.
Exemplo 1. Um exemplo importante de equação diferencial de segunda ordem, linear e não homogênea, é o de um corpo de massa \(m\), preso a uma mola de constante elástica \(k\), sob atrito e sujeito à uma força externa variável \(f(t)\), como ilustrado na figura 1. A força que a mola exerce sobre o corpo é dada pela lei de Hooke, \(f=-kx\), enquanto o atrito exerce uma força proporcional à sua velocidade e em direção oposta a ela. Adicionando-se uma força externa \(f(t)\) e usando a segunda lei de Newton temos
(2)
$$
m\frac{d^{2}x(t)}{dt}+c\frac{dx}{dt}+kx=f(t),
$$
onde \(c\) uma constante que descreve o atrito. Aprenderemos mais tarde técnicas de solução de problemas como este.
Exemplo 2. Considere o problema de contorno,
$$
y^{\prime\prime}-y=0;\;\,y(0)=2,\;\,y^{\prime}(0)=-1.
$$
Sabemos, sem auxílio de qualquer técnica de solução, que duas funções elementares satisfazem \(y^{\prime\prime}=y.\) Elas são as exponenciais
$$
y_{1}=e^{x},\;\,y_{2}=e^{-x},
$$
como se pode verificar por derivação e substituição direta. Observe também que uma combinação linear destas soluções formam ainda uma solução
$$
y(x)=Ae^{x}+Be^{-x},
$$
\(A\) e \(B\) constantes indeterminadas. Mostre, como um exercício, que esta é realmente uma solução. Esta é a chamada solução geral para este problema. Para satisfazer as condições de contorno precisamos da derivada
$$
y^{\prime}(x)=Ae^{x}-Be^{-x}.
$$
Calculando os valores de \(y\) e \(y^{\prime}\) no ponto \(x=0\) temos
$$
y(0)=A+B=2,\;\,y^{\prime}(0)=A-B=-1
$$
que é uma sistema, com solução \(A=1/2\) e \(B=3/2.\) A solução particular é, portanto,
$$
y(x)=\frac{1}{2}e^{x}+\frac{3}{2}e^{-x},
$$
satisfazendo simultaneamente a equação diferencial e os valores de contorno.
Exemplo 3. Vamos resolver o problema de contorno,
(3)
$$
y^{\prime\prime}+\omega^{2}y=0;\;\,y(0)=\frac{1}{2},\;\,y^{\prime}(0)=\omega,
$$
onde \(\omega\) é uma constante. Conhecemos duas funções cujas derivadas segundas são iguais a si mesmas com sinal invertido, que são as funções seno e cosseno. Devido à presença da constante \(\omega\) precisamos usar as soluções
$$
y_{1}=\cos\omega x,\;\,y_{2}=\text{ sen }\omega x.
$$
Mais uma vez, uma combinação linear destas soluções forma a solução geral,
$$
y(x)=A\cos\omega x+B\text{ sen }\omega x,
$$
como se pode verificar por derivação e substituição na equação (3). Sua derivada primeira é
$$
y^{\prime}(x)=-\omega A\text{ sen }x+\omega B\cos x.
$$
No ponto \(x=0\) temos
$$
y(0)=A=\frac{1}{2},\;\,y^{\prime}(0)=\omega B=\omega,
$$
e, portanto \(A=1/2\) e \(B=1\). Como resultado chegamos à solução particular
$$
y(x)=\frac{1}{2}\cos\omega x+\text{ sen }\omega x,
$$
satisfazendo a equação diferencial e os valores de contorno.
Vimos nos exemplos acima que cada uma das equações diferenciais consideradas admite duas soluções e que uma combinação linear destas soluções é também uma solução. é necessário agora considerar em que situações a combinação linear de duas soluções encontradas representa a solução mais geral do problema e quando esta solução poderá ser ajustada às condições de contorno. Na seção seguinte aprimoramos nosso tratamento formal das equações diferenciais lineares de segunda ordem.
Soluções Fundamentais das Equações Homogêneas Lineares
Vamos considerar novamente as soluções da equação linear homogênea
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0.
$$
Sejam \(f(x)\) e \(g(x)\) funções contínuas, definidas no intervalo \(I=[a,b]\) (que pode ser a reta real inteira, \(I=\mathbb{R}\)), e \(\phi\) uma função duplamente derivável no intervalo \(I\). Definimos o operador diferencial
(4)
$$
L[\phi]=\phi^{\prime\prime}+f\phi^{\prime}+g\phi.
$$
Escrita em termos deste operador a equação (4) é
$$
L[\phi]=0.
$$
O operador \(L\) é formado por derivações e multiplicação pelas funções \(f\) e \(g\)
$$
L=D^{2}+fD+g,
$$
onde escrevemos o operador derivada como \(D=d/dx\).
Definição Um operador \(O\) é dito linear se
$$
O[\alpha f+\beta g]=\alpha O[f]+\beta O[g],
$$
onde \(\alpha\) e \(\beta\) são constantes e \(f\) e \(g\) são funções dentro do domínio de atuação do operador.
(1) De fato, a derivada de qualquer ordem é um operador linear.
Exemplo 4. A derivada primeira e a derivada segunda são operadores lineares(1) pois
$$
\frac{d}{dx}[\alpha f(x)+\beta g(x)]=\alpha\frac{d}{dx}f(x)+\beta\frac{d}{dx}g(x),
$$
$$
\frac{d^{2}}{dx^{2}}[\alpha f(x)+\beta g(x)]=\alpha\frac{d^{2}}{d^{2}x}f(x)+\beta\frac{d^{2}}{d^{2}x}g(x),
$$
Podemos agora enunciar um teorema que nos permite determinar os intervalos sobre os quais a solução de uma equação diferencial é única.
Teorema 1. Se \(f(x)\) e \(g(x)\) são funções contínuas no intervalo aberto \(I\) que contém o ponto \(x_{0}\) então o problema de valor inicial
$$
L[y]=y^{\prime\prime}+f(x)y^{\prime}+g(x)y=r(x),\;\,y(x_{0})=y_{0},\;\,y^{\prime}(x_{0})=y_{0}^{\prime},
$$
admite uma única solução sobre todo o intervalo \(I\).
Exemplo 6. Vamos encontrar o intervalo mais amplo onde o problema de valor inicial
$$
(x^{2}-x)y^{\prime\prime}+xy^{\prime}+(x-1)y=0,\;y\left(\frac{1}{2}\right)=1,\;y^{\prime}\left(\frac{1}{2}\right)=0
$$
admite solução. Começamos por reescrever a equação acima como
$$
y^{\prime\prime}+\frac{x}{x(x-1)}xy^{\prime}+\frac{x-1}{x(x-1)}y=0
$$
e, portanto, identificamos
$$
f=\frac{1}{x-1},\;g=\frac{1}{x}
$$
que possuem descontinuidades nos pontos \(x=1\) e \(x=0\). O maior intervalo que inclue o ponto \(x=1/2\) é o aberto \(I=(0,1)\).
Exemplo 7. Se \(f(x)\) e \(g(x)\) são funções contínuas em torno do intervalo \(I\) que contém o ponto \(x_{0}\), o problema de valor inicial
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0,\;y(x_{0})=0,\;y^{\prime}(x_{0})=0
$$
admite como solução \(y(x)\equiv0\). Pelo Teorema 1 esta é a única solução.
Teorema 2: (Princípio da superposição) Se \(y_{1}\) e \(y_{2}\) são soluções de
$$
L[y]=y^{\prime\prime}+fy^{\prime}+gy=0
$$
então a combinação linear
$$
y(x)=c_{1}y_{1}+c_{2}y_{2}
$$
é também uma solução.
Demonstração: Segue direto da linearidade do operador \(L\), pois
$$
L[c_{1}y_{1}+c_{2}y_{2}]=c_{1}L[y_{1}]+c_{2}L[y_{2}]=0,
$$
já que \(L[y_{1}]=0,\;\;L[y_{2}]=0\) (pois \(y_{1}\) e \(y_{2}\) são soluções).
Observe que o princípio da superposição somente se aplica a equações lineares e homogêneas. Os dois exemplos seguintes mostram que o teorema não se aplica a equações diferenciais não lineares ou não homogêneas.
Exemplo 8. Podemos verificar por substituição direta que
$$
y_{1}=x^{2},\;\;y_{2}=1
$$
são soluções da equação diferencial não linear
$$
y^{\prime\prime}y-xy^{\prime}=0.
$$
No entanto, as combinações lineares
$$
-y_{1}=-x^{2},\;\,y_{1}+y_{2}=1+x^{2}
$$
não são soluções.
Exemplo 9. Podemos verificar por substituição que a equação diferencial não homogênea
$$
y^{\prime\prime}+y=1
$$
admite as soluções
$$
y_{1}=1+\cos x,\;\;y_{2}=1+\text{ sen }x.
$$
As seguintes combinações lineares
$$
2y_{1}=2+2\cos x,\;\;y_{1}+y_{2}=2+\cos x+\text{ sen }x
$$
não são soluções desta equação.
Temos agora condições para responder à seguinte pergunta: na solução de um problema de segunda ordem, tendo encontrado uma solução geral na forma de
$$
y(x)=c_{1}y_{1}+c_{2}y_{2},
$$
é sempre possível ajustar as constantes \(c_{1} \text{ e } c_{2}\) de modo a satisfazer as condições de contorno
$$
y(x_{0})=y_{0},y^{\prime}(x_{0})=y_{0}^{\prime},
$$
onde \(x_{0},\;y_{0}\) e \(y_{0}^{\prime}\) são números reais? Para responder a esta pergunta escreveremos as condições de contorno
$$
y(x_{0})=c_{1}y_{1}(x_{0})+c_{2}y_{2}(x_{0})=y_{0},
$$
As mesmas equações podem ser escritas sob forma matricial como
(5)
$$
\begin{bmatrix} y_{1}(x_{0}) & y_{2}(x_{0}) \\ y_{1}^{\prime}(x_{0}) & y_{2}^{\prime}(x_{0}) \end{bmatrix}
\begin{bmatrix} c_{1} \\ c_{2} \end{bmatrix}
=
\begin{bmatrix} y_{0} \\ y_{0}^{\prime} \end{bmatrix}
$$
Usamos a notação para o determinante de uma matriz A: \(\det(A)= \left|A\right|\).
Sabemos, da álgebra Linear, que este sistema só admite solução se o determinante da matriz \(2\times2\) acima for não nulo. Este determinante aparece em diversos contextos na teoria das equações diferenciais e recebe o nome de Wronskiano.
Definição: O Wronskiano \(W\) de duas funções \(f(x)\) e \(g(x)\) é o determinante
onde \(W(y_{1},y_{2})|_{x_{0}}\) é o Wronskiano das duas soluções calculado no ponto \(x_{0}\).
Demonstramos desta forma um teorema importante, enunciado a seguir.
Teorema 3. O problema de valor inicial
$$
L(y)=0,\;\,y(x_{0})=y_{0},\;\,y^{\prime}(x_{0})=y_{0}^{\prime}
$$
possui solução se \(W(y_{1},y_{2})|_{x_{0}}\neq 0\). Isto equivale a dizer que \(y_{1}\) e \(y_{2}\) são linearmente independentes (l.i.).
Exercícios 1.
1. Calcule os Wronskianos
a. \( W(e^{2x},\,e^{-5x/2})\)
b. \( W(\text{ sen }x,\cos x)\)
c. \( W(x^{3},\,x^{5})\)
d. \( W(e^{x}\text{ sen }x,e^{x}\cos x)\)
e. \( W(x,\,xe^{x})\)
f. \( W(\cos^{2}x,1+\cos2x)\)
2. Encontre o maior intervalo sobre o qual se pode garantir a existência de solução para o problema de valor inicial:
$$
(x^{2}-3x)y^{\prime\prime}+xy^{\prime}-(x+3)y=0,\;y(1)=2,\;y^{\prime}(1)=1.
$$
Equações com Coeficientes Constantes
O caso mais simples e de mais fácil solução de equações lineares de segunda ordem homogêneas(2) ocorre quando os coeficientes da equação são constantes, resultando em uma equação do tipo
(6)
$$
ay^{\prime\prime}+by^{\prime}+cy=0,
$$
(2) Para resolver o caso não homogêneo, como veremos depois, utilizaremos a solução da homogênea, aqui estudada.
com \(a,\,b\) e \(c\) constantes. Apesar de ser um caso muito particular entre as equações lineares de segunda ordem um grande número de sistemas de interesse para a engenharia e a física é descrito por equações deste tipo, entre eles os osciladores mecânicos amortecidos e submetidos a forças externas e circuitos eletrônicos compostos por indutores, capacitores e resistências, como veremos adiante.
A solução de problemas do tipo proposto pela equação acima sugere o uso de uma solução tentativa sob a forma
$$
y=e^{rx},
$$
onde \(r\) é uma constante ainda desconhecida. Substituindo esta função e suas derivadas
$$
y^{\prime}=re^{rx},\;\,y^{\prime\prime}=r^{2}e^{rx}.
$$
na equação (6) obtemos
$$
e^{rx}(ra^{2}+br+c)=0.
$$
Como a exponencial é não nula para todos os valores de \(x\), o termo dentro dos parênteses deve se anular,
$$
ar^{2}+br+c=0.
$$
Esta é uma equação do segundo grau, denominada a equação característica da equação diferencial (6), e possui duas raízes,
$$
r_{1,2}=\frac{-b\pm\sqrt{b^{2}-4ac}}{2a}.
$$
Faremos o tratamento em separado dos três casos possíveis: (i) de duas raízes diferentes reais, (ii) raízes complexas, (iii) duas raízes iguais.
Raízes reais distintas da equação característica
Se as raízes da equação característica são duas raízes reais distintas, \(r_{1}\neq r_{2}\), então
$$
y_{1}=e^{r_{1}x}\;\,\text{ e }\;\,y_{2}=e^{r_{2}x}
$$
são duas soluções. Estas soluções são l.i. pois seu Wronskiano é
$$
W(y_{1},y_{2})=y_{1}y_{2}^{\prime}-y_{1}^{\prime}y_{2}=r_{2}e^{r_{1}x}e^{r_{2}x}-r_{1}e^{r_{1}x}e^{r_{2}x}=e^{(r_{1}+r_{2})x}(r_{2}-r_{1})\neq0,
$$
não nulo porque \(r_{1}\neq r_{2}\). A combinação das duas soluções,
$$
y(x)=c_{1}e^{r_{1}x}+c_{2}e^{r_{2}x},
$$
é, portanto, a solução geral do problema. Verifique, como um exercício, que esta é, de fato, uma solução da equação.
Exemplo 10. Problema de contorno, equação linear de segunda ordem, com coeficientes constantes:
$$
y^{\prime\prime}+y^{\prime}-2y=0,\;\;y(0)=1,\;\;y^{\prime}(0)=0.
$$
Fazemos a tentativa de solução \(y=e^{rx}\) e substituimos \(y\) e suas derivadas na equação diferencial. O resultado é a equação característica
$$
r^{2}+r-2=0.
$$
Esta última tem duas raízes distintas, \(r_{1}=1\) e \(r_{2}=-2\), de onde concluimos que
$$
y_{1}=e^{x}\;\;\text{e}\;\;y_{2}=e^{-2x}
$$
são soluções. O Wronskiano destas soluções é
$$
W(y_{1},y_{2})=y_{1}y_{2}^{\prime}-y_{1}^{\prime}y_{2}=-2e^{x}e^{-2x}-e^{x}e^{-2x}=-3e^{-x}\neq0.
$$
Como o Wronskiano é não nulo \(y_{1}\) e \(y_{2}\) são linearmente independentes e a solução geral tem a seguinte forma:
$$
y(x)=c_{1}e^{x}+c_{2}e^{-2x}.
$$
Para ajustar as constantes ao problema de valor inicial derivamos \(y\).
$$
y(x)=c_{1}e^{x}-2c_{2}e^{-2x},
$$
e o contorno implica no sistema
$$
y(0)=1=c_{1}+c_{2}
$$
$$
y^{\prime}(0)=0=c_{1}-2c_{2},
$$
com solução \(c_{1}=2/3,\) \(c_{2}=1/3.\) Então a solução particular é
$$
y(x)=\frac{2}{3}e^{x}+\frac{1}{3}e^{-2x}.
$$
Calculamos o Wronskiano \(W\) como mero exercíco pois já mostramos que o Wroskiano é sempre não nulo quando as raízes da equação característica são reais e distintas.
Exemplo 11. A equação diferencial
$$
y^{\prime\prime}+\frac{1}{6}y^{\prime}-\frac{1}{6}y=0;\;\,y(0)=5,\;\,y^{\prime}(0)=0
$$
pode ser resolvida com a substituição \(y=e^{rx}\), o que resulta em
$$
e^{rx}\left(r^{2}+\frac{r}{6}-\frac{1}{6}\right)=0.
$$
As raízes da equação característica são
$$
r=\frac{-\frac{1}{6}\pm\sqrt{\left(\frac{1}{6}\right)^{2}+\frac{4}{6}}}{2}\; \text{ e, portanto, }\; r_{1}=-1/2,\; r_{2}=1/3.
$$
A solução geral e sua derivada são, respectivamente,
$$
y=c_{1}e^{-x/2}+c_{2}e^{x/3},\;\,y^{\prime}=-\frac{1}{2}c_{1}e^{x/2}+\frac{1}{3}c_{2}e^{x/3}.
$$
Com as condições de contorno encontramos \(c_{1}\) e \(c_{2}\).
$$
\left.
\begin{array}{rl}
y(0)=c_{1}+c_{2} =5 \\
y^{\prime}(0)=-\frac{1}{2}c_{1}+\frac{1}{3}c_{2} =0 \\
\end{array}
\right\}
\Rightarrow c_{1}=2,\;\;c_{2}=3.
$$
A solução particular fica assim determinada:
$$
y(x)=2e^{-x/2}+3e^{x/3}.
$$
Se, na equação característica temos \(\Delta=b^{2}-4ac \lt 0\) então as raízes são dois números complexos, conjugados entre si,
$$
r_{1}=\lambda+i\mu,\;\;r_{2}=\lambda-i\mu,
$$
onde
$$
\lambda=\frac{-b}{2a},\;\,\mu=\frac{\sqrt{|\Delta|}}{2a},\,\lambda,\,\mu\in R.
$$
As duas soluções da forma \(y=e^{rx}\) são
$$
y_{1}=e^{(\lambda+i\mu)x}=e^{\lambda x}(\cos\mu x+i\text{ sen }\mu x),
$$
$$
y_{2}=e^{(\lambda-i\mu)x}=e^{\lambda x}(\cos\mu x-i\text{ sen }\mu x),
$$
onde foi usada a fórmula de Euler, \(e^{i\theta}=\cos\theta+i\text{ sen }\theta\). Podemos trabalhar com estas duas soluções ou com combinações lineares destas, em particular
$$
u=\frac{1}{2}(y_{1}+y_{2})=e^{\lambda x}\cos\mu x,
$$
$$
v=\frac{1}{2i}(y_{1}-y_{2})=e^{\lambda x}\text{ sen }\mu x.
$$
Notando que o Wronskiano de \(u\) e \(v\) é não nulo,
$$
W(u,v) = e^{\lambda x}\cos\mu x(\lambda e^{\lambda x}\text{ sen }\mu x+\mu e^{\lambda x}\cos\mu x)
$$
$$
-e^{\lambda x}\text{ sen }\mu x(\lambda e^{\lambda x}\cos\mu x-\mu e^{\lambda x}\text{ sen }\mu x)
$$
$$
=\mu e^{2\lambda x}\neq0,
$$
pois \(\mu\neq0\) (caso contrário as raízes não seriam complexas!), encontramos então a solução geral para o problema:
$$
y(x)=e^{\lambda x}(c_{1}\cos\mu x+c_{2}\text{ sen }\mu x).
$$
Exemplo 12. Encontre a solução geral de
$$
y^{\prime\prime}-2y^{\prime}+2y=0.
$$
Ajuste as constantes da solução geral para satisfazer ao contorno
$$
y(0)=2,\;\,y^{\prime}(0)=3.
$$
Fazendo \(y=e^{rx}\), obtemos a equação característica \(r^{2}-2r+2=0\) com soluções \(r=1\pm i\). Temos portanto o caso de raízes complexas com \(r_{\pm}=\lambda\pm i\mu,\;\lambda=1,\;\mu=1\) que levam a duas soluções
$$
y_{1}=e^{x}\cos x,\;\,y_{2}=e^{x}\text{ sen }x.
$$
Estas soluções são linearmente independentes pois
$$
W(y_{1},y_{2})=e^{x}\cos x(e^{x}\text{ sen }x+e^{x}\cos x)-e^{x}\text{ sen }x(e^{x}\cos x-e^{x}\text{ sen }x)=
$$
$$
=e^{2x}(\text{ sen }x\cos x+\cos^{2}x-\text{ sen }x\cos x+\text{ sen }^{2}x)=e^{2x}\neq0.
$$
A solução geral é
$$
y(x)=c_{1}e^{x}\cos x+c_{2}e^{x}\text{ sen }x.
$$
Para encontrar os valores de \(c_{1}\) e \(c_{2}\) precisamos da derivada
$$
y^{\prime}(x)=c_{1}e^{x}(\cos x-\text{ sen }x)+c_{2}e^{x}(\text{ sen }x+\cos x).
$$
A solução particular é
$$
y(x)=2e^{x}\cos x+e^{x}\text{ sen }x.
$$
Exemplo 13. Vamos agora resolver o problema relativo a um objeto preso a uma mola, deslizando sem atrito e não submetido a força externa, descrito pela equação (2) com \(c=0,\;F(t)=0\),
$$
m\frac{d^{2}x(t)}{dt}+kx=0,
$$
ou seja
$$
\ddot{x}+\frac{k}{m}x=0.
$$
Neste problema tomamos o tempo \(t\) como variável independente. \(x(t)\) é a posição do objeto, a função que queremos encontrar. O ponto sobrescrito indica derivada em relação ao tempo. A equação característica é
$$
r^{2}+\frac{k}{m}=0
$$
com raízes
$$
r=\pm\sqrt{\frac{k}{m}}.
$$
Encontramos neste caso
$$
\lambda=0,\;\,\mu=\sqrt{\frac{k}{m}},
$$
e a solução geral indica o movimento em oscilação harmônica do objeto,
$$
x(t)=A\cos\omega t+B\text{ sen }\omega t,
$$
onde definimos \(\omega=\mu\), a frequência da oscilação.
1. \( y=c_{1}e^{-x/2}\cos\left(\frac{\sqrt{3}}{2}x\right)+c_{2}e^{-x/2}\text{ sen }\left(\frac{\sqrt{3}}{2}x\right)\)
2. \( y=c_{1}\cos3x+c_{2}\text{ sen }3x\)
3. \( y=c_{1}e^{2x}+c_{2}e^{-4x}\)
4. \( y=c_{1}e^{-x}\cos x+c_{2}e^{-x}\text{ sen }x\)
5. \( y=c_{1}e^{-3x}\cos2x+c_{2}e^{-3x}\text{ sen }2x\)
6. \( y=c_{1}\cos(3x/2)+c_{2}\text{ sen }(3x/2)\)
7. \( y=c_{1}e^{-x}\cos(x/2)+c_{2}e^{-x}\text{ sen }(x/2)\)
8. \( y=c_{1}e^{x/3}+c_{2}e^{-4x/3}\)
9. \( y=\left(-2\cos3x+\frac{1}{4}\text{ sen }3x\right)e^{x/4}\)
10. \( y=\frac{1}{2}\text{ sen }2x\)
11. \( y=e^{-2x}\cos x+e^{-2x}\text{ sen }x\)
12. \( y=-e^{x-\pi/2}\text{ sen }2x\)
13. \( y=\left(1+2\sqrt{3}\right)\cos x-\left(2-\sqrt{3}\right)\text{ sen }x\)
14. \( y=\sqrt{2}e^{-(x-\pi/4)}\cos x+\sqrt{2}e^{-(x-\pi/4)}\text{ sen }x\)
Equação característica com raízes iguais
Se, na equação característica temos \(\Delta=b^{2}-4ac=0\) então temos uma raiz dupla, real,
$$
r=r_{1}=r_{2}=\frac{-b}{2a}.
$$
Neste caso temos apenas uma solução
(7)
$$
y_{1}=e^{rx}=e^{-bx/2a}.
$$
(3) Conhecido como o método de d’Alembert.
Sabemos, no entanto, que devemos ter duas soluções l.i. para construir a solução geral. Utilizaremos novamente o método de variação dos parâmetros(3) já usado para a solução de equações lineares não homogêneas de primeira ordem. Este método consiste no seguinte procedimento:
(i) Encontramos uma solução da equação diferencial. No caso aqui tratado a solução é \(y_{1}\) dada pela equação (7).
(ii) Sabemos, pela linearidade da equação diferencial, que \(y=cy_{1}\) é também uma solução. Fazemos a variação dos parâmetros, \(c\rightarrow v(x)\), ou seja, substituimos a constante \(c\) por uma função desconhecida.
(iii) Derivamos \(y=vy_{1}\) uma e duas vezes e substituimos \(y,\,y^{\prime}\) e \(y^{\prime\prime}\) na equação diferencial para encontrar uma expressão para a função \(v(x)\). Esta expressão é também uma equação diferencial para a função \(v\), mas em geral muito mais simples que a equação original.
Um exemplo, antes da formalização do procedimento, servirá para torná-lo mais claro.
Exemplo 14. Vamos resolver a equação diferencial
(8)
$$
y^{\prime\prime}+2y^{\prime}+y=0.
$$
A equação característica, neste caso, é \(r^{2}+2r+1=0\), que possui as raízes iguais, \(r_{1}=r_{2}=-1\). Neste caso encontramos apenas uma solução
$$
y_{1}=ce^{-x}.
$$
No método de variação dos parâmetros procuramos uma solução na forma de
$$
y(x)=v(x)e^{-x}.
$$
Derivamos \(y\) uma e duas vezes,
$$
y^{\prime}=v^{\prime}e^{-x}-ve^{-x}=e^{-x}(v^{\prime}-v),
$$
e substituimos \(y,\,y^{\prime}\) e \(y^{\prime\prime}\) na equação diferencial para obter
$$
e^{-x}(v^{\prime\prime}-2v^{\prime}+v+2v^{\prime}-2v+v)=0,
$$
ou, após os cancelamentos possíveis e considerando que \(e^{-x}\) não se anula,
$$
v^{\prime\prime}=0.
$$
Esta última equação diferencial tem solução simples
$$
v(x)=A+Bx,
$$
onde \(A\) e \(B\) constantes de integração. A solução procurada para a equação é
(9)
$$
y(x)=ve^{-x}=Ae^{-x}+Bxe^{-x}.
$$
Observe que, a partir da solução \(y_{1}=\) \(e^{-x}\), encontramos \(y_{2}=xe^{-x}\). Como o Wronskiano das soluções encontradas não se anula,
$$
W(e^{-x},xe^{-x})=e^{-x}(e^{-x}-xe^{-x})+e^{-x}xe^{-x}=e^{-2x}\neq0,
$$
estas soluções são l.i. e a função (9) é a solução geral para este problema.
Vamos recapitular o procedimento usado e generalizá-lo. Se, na solução de uma equação diferencial com coeficientes constantes
$$
L[y]=ay^{\prime\prime}+by^{\prime}+cy=0
$$
usamos \(y=e^{rx}\) e encontramos uma equação característica
$$
ar^{2}+br+c=0
$$
onde
$$
\Delta=b^{2}-4ac=0
$$
então encontramos apenas uma raíz real
$$
r=-\frac{b}{2a}
$$
que corresponde a uma única solução para a equação diferencial,
$$
y_{1}=e^{-b/2a}.
$$
Buscamos então uma solução sob a forma
$$
y(x)=v(x)e^{-b/2a},
$$
com derivadas primeira e segunda respectivamente
$$
y^{\prime}=e^{-b/2a}\left(v^{\prime}-\frac{b}{2a}v\right),
$$
Substituindo \(y\) e suas derivadas da equação diferencial obtemos
$$
e^{-b/2a}\left(av^{\prime\prime}-bv^{\prime}+\frac{b^{2}}{4a}v+bv^{\prime}-\frac{b^{2}}{2a}v+cv\right)=0
$$
ou, lembrando que a exponencial não se anula,
$$
av^{\prime\prime}+\left(-\frac{b^{2}}{4a}+c\right)v=0.
$$
O termo dentro dos parênteses é nulo (pois \(\Delta=0\)) e, portanto resta apenas a equação diferencial
$$
v^{\prime\prime}=0
$$
para função desconhecida, com solução
$$
v=Ax+B.
$$
A solução procurada para a equação (8) é
(10)
$$
y(x)=ve^{-b/2a}=Ae^{-b/2a}+Bxe^{-b/2a}.
$$
As duas soluções empregadas nesta solução são
$$
y_{1}=e^{-b/2a},\;\,y_{2}=xe^{-b/2a}
$$
que são l.i. pois
$$
W(y_{1},y_{2})=e^{-bx/a}\neq0,
$$
e, portanto a solução (10) é, de fato, a solução geral.
Exemplo 15. Vamos tratar o problema de valor inicial:
$$
9y^{\prime\prime}-12y^{\prime}+4y=0,\;y(0)=2,\;y^{\prime}(0)=-1.
$$
Tomando \(y=e^{rx}\) obtemos a equação característica
$$
9r^{2}-12r+4=0,
$$
que tem raízes reais duplas \(r_{1}=r_{2}=2/3.\) No caso de raízes repetidas para a equação característica a solução, obtida por meio do método da variação dos parâmetros, é
$$
y(x)=Ae^{2x/3}+Bxe^{2x/3}.
$$
e sua derivada,
$$
y^{\prime}(x)=\frac{2}{3}Ae^{2x/3}+Be^{2x/3}+\frac{2}{3}Bxe^{2x/3}.
$$
Para satisfazer as condições iniciais devemos ter
$$
y(0)=A=2,\;y^{\prime}(0)=\frac{2}{3}A+B=-1,
$$
o que implica em \(A=2,\;B=-7/2.\) A solução particular é
$$
y(x)=2e^{2x/3}-\frac{7}{2}xe^{2x/3}.
$$
Temos portanto os três seguintes casos de equações diferenciais lineares de segunda ordem, homogêneas com coeficientes constantes, \(ay^{\prime\prime}+by^{\prime}+cy=0\), que resumiremos no quadro abaixo para facilitar uma referência rápida:
\(r_{1}\neq r_{2}\),
raízes reais
\(y(x)=c_{1}e^{r_{1}x}+c_{2}e^{r_{2}x},\)
\(r_{1,2}=\lambda\pm i\mu\)
raízes complexas
\(y(x)=e^{\lambda x}(c_{1}\cos\mu x+c_{2}\text{ sen }\mu x)\),
\(r_{1}=r_{2}=r\)
uma raíz real
\(c_{1}e^{-b/2a}+c_{2}xe^{-b/2a}.\)
Com isto completamos o tratamento de todos os tipos de equações diferenciais lineares de segunda ordem homogêneas e com coeficientes constantes. Como veremos o método da variação dos parâmetros, discutido por último, pode ser rapidamente generalizado para a solução de uma classe mais ampla de equações diferenciais, desde que se conheça uma da soluções destas equações.
Usando o método de variação de parâmetros, discutido na seção anterior, podemos tratar de equações diferenciais mais gerais que aquelas já estudadas, com coeficientes constantes. Este método pode ser usado para abaixar a ordem de uma equação diferencial e tornar mais fácil a sua solução desde que uma de suas soluções seja conhecida. Considere uma equação diferencial linear homogênea sob a forma
(11)
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0,
$$
onde os coeficientes \(f(x)\) e \(g(x)\) não são necessariamente constantes. Ainda, suponha que de algum modo, por inspecção, por intuição advinda da natureza do problema que origina a equação diferencial, ou ainda por meio do uso de outro método qualquer, conhecemos uma das soluções de (11), que denotaremos por \(y_{1}(x)\). Pela linearidade da equação sabemos que \(cy_{1}\), com \(c\) constante, é também uma solução. Buscamos agora uma solução para a equação sob a forma
$$
y(x)=v(x)y_{1}(x)
$$
onde \(v(x)\) é uma função desconhecida. Derivamos a solução tentativa,
$$
y^{\prime}=v^{\prime}y_{1}+vy_{1}^{\prime},
$$
e substituimos na equação diferencial para obter
$$
v^{\prime\prime}y_{1}+v^{\prime}(2y_{1}^{\prime}+fy_{1})+v(y_{1}^{\prime\prime}+fy_{1}^{\prime}+gy_{1})=0.
$$
Observando que o segundo parênteses é nulo, pois \(y_{1}\) é solução da equação diferencial, resta apenas
$$
v^{\prime\prime}y_{1}+v^{\prime}(2y_{1}^{\prime}+fy_{1})=0,
$$
que é, por sua vez, uma equação diferencial para \(v(x)\). Esta equação, ou qualquer outra com esta mesma característica, pode ser transformada em uma equação de primeira ordem através do método de redução de ordem. Para isto fazemos
$$
\phi(x)=v^{\prime}(x)\Rightarrow\phi^{\prime}(x)=v^{\prime\prime}(x).
$$
A equação (11) se transforma em
$$
\phi^{\prime}y_{1}+\phi(2y_{1}^{\prime}+fy_{1})=0,
$$
que é uma equação homogênea de primeira ordem, cuja solução já sabemos encontrar. Lembrando que \(y_{1}\) e suas derivadas são funções conhecidas, primeiro encontramos \(\phi(x)\) e, por integração,
$$
v(x)=\int\phi(x)dx.
$$
A solução de (11) é
$$
y(x)=y_{1}\int\phi(x)dx.
$$
Exemplo 16. Sabendo que \(y_{1}=x\) é uma solução de
(12)
$$
x^{2}y^{\prime\prime}+2xy^{\prime}-2y=0,
$$
vamos encontrar a sua solução geral. Fazemos primeiro \(y=vy_{1}=vx\). Com esta escolha temos
$$
y^{\prime}=v^{\prime}x+v,\;\,y^{\prime\prime}=v^{\prime\prime}x+2v^{\prime}.
$$
Substituindo na equação diferencial (12) temos
$$
x^{2}(v^{\prime\prime}+2v^{\prime})+2x(v^{\prime}x+v)-2vx=0,
$$
$$
v^{\prime\prime}x+4v^{\prime}=0.
$$
Esta equação não contém um termo em \(y\) e por isto sua ordem pode ser reduzida. Denotamos então \(v^{\prime}=\phi\), e portanto \(v^{\prime\prime}=\phi^{\prime}\). Resta a equação separável
$$
\phi^{\prime}x+4\phi=0\Rightarrow\int\frac{d\phi}{\phi}=-\int\frac{4dx}{x}\Rightarrow
$$
Pelas definições feitas
$$
v=\int\phi dx=c\int x^{-4}dx=c\left(\frac{-1}{3x^{3}}\right)+B.
$$
Definindo uma nova constante \(A=-c/3\)
$$
y=vx=Ax^{-2}+Bx,
$$
é a solução geral do problema (12).
Exemplo 17. Uma equação que surge com freqüência dentro do contexto da mecânica quântica e do eletromagnetismo, após a separação de uma equação diferencial parcial em equações ordinárias, é a chamada equação de Legendre de primeira ordem
$$
(1-x^{2})y^{\prime\prime}-2xy^{\prime}+2y=0,-1\lt x\lt 1.
$$
Sabendo que \(y_{1}=x\) é uma solução desta equação encontre a solução geral. Começamos por fazer a variação dos parâmetros para uma solução tentativa
$$
y(x)=xv(x)
$$
cujas derivadas são
$$
y^{\prime}=xv^{\prime}+v,y^{\prime\prime}=xv^{\prime\prime}+2v^{\prime}.
$$
Substituindo na equação diferencial temos
$$
(1-x^{2})(xv^{\prime\prime}+2v^{\prime})-2x(xv^{\prime}+v)+2xv=0,
$$
que, após as devidas simplificações, leva a
$$
(1-x^{2})xv^{\prime\prime}+(2-4x^{2})v^{\prime}=0.
$$
Procedemos agora à redução de ordem fazendo
$$
v^{\prime}=\phi\Rightarrow v^{\prime\prime}=\phi^{\prime}.
$$
Vamos aproveitar este problema para fazer uma revisão da método das frações parciais para a solução de uma integral. O segundo termo acima pode ser transformado, por meio de frações parciais, da seguinte forma:
$$
\frac{4x^{2}-2}{x(1-x^{2})}=\frac{A}{x}+\frac{Bx}{1-x^{2}},
$$
onde \(A\) e \(B\) são constantes a serem encontradas. Efetuando a soma de fração no segundo termo
$$
\frac{4x^{2}-2}{x(1-x^{2})}=\frac{A(1-x^{2})+Bx^{2}}{x(1-x^{2})}=\frac{(B-A)x^{2}+A}{x(1-x^{2})}.
$$
Identificando, no numerador, os coeficientes de mesma potência em \(x\) temos \(A=-2,\;B=2\) e, portanto
$$
\frac{4x^{2}-2}{x(1-x^{2})}=-\frac{2}{x}+\frac{2x}{1-x^{2}}.
$$
Devemos integrar a equação (13),
$$
\int\frac{d\phi}{\phi}=-2\int\frac{dx}{x}+2\int\frac{xdx}{1-x^{2}}
$$
(4) Usamos acima as propriedades da função logaritmo: \(a\ln b=\ln b^{a},\;\;\ln a+\ln b=\ln(ab)\).
para obter(4)
$$
\ln\phi=-2\ln x-\ln(1-x^{2})+c=\ln\frac{1}{x^{2}(1-x^{2})}+c,
$$
ou seja
$$
\phi=c_{1}\frac{1}{x^{2}(1-x^{2})}.
$$
Retornando para a função \(v\),
$$
v=\int\phi dx=c_{1}\int\frac{dx}{x^{2}(1-x^{2})}.
$$
Vamos usar mais uma vez as frações parciais para transformar o integrando,
$$
\frac{1}{x^{2}(1-x^{2})}=\frac{1}{x^{2}}+\frac{1}{1-x^{2}}
$$
e assim encontramos
$$
v=c_{1}\int\left(\frac{1}{x^{2}}+\frac{1}{1-x^{2}}\right)dx.
$$
Observe que a segunda integral
$$
I=\int\frac{1}{1-x^{2}}dx
$$
pode ser resolvida, mais uma vez, pelo mesmo método usado acima, por meio das frações parciais. Para isto fazemos
$$
\frac{1}{1-x^{2}}=\frac{1}{(1+x)(1-x)}=\frac{A}{1+x}+\frac{B}{1-x}
$$
de onde encontramos, procedendo como antes, \(A=B=1/2.\) Então
$$
I=\frac{1}{2}\int\left(\frac{1}{1+x}+\frac{1}{1-x}\right)dx=\frac{1}{2}[\ln(1+x)-\ln(1-x)]=\frac{1}{2}\ln\left(\frac{1+x}{1-x}\right),
$$
e, daí
$$
v=c_{1}\left(-\frac{1}{x}+\frac{1}{2}\ln\frac{1+x}{1-x}\right)+c_{2}.
$$
Restaurando a função \(y=xv\) temos
$$
y=c_{1}\left(-1+\frac{x}{2}\ln\frac{1+x}{1-x}\right)+c_{2}x.
$$
que é a solução geral procurada.
A técnica de redução de ordem não precisa ser usada apenas em conjunção com a variação de parâmetros, tal como fizemos nos dois primeiros exemplos. Qualquer equação diferencial onde não apareça a função incógnita \(y(x)\) explícitamente, mas apenas suas derivadas, pode ter a sua ordem reduzida.
Exemplo 18. Podemos reduzir a ordem da seguinte equação diferencial
$$
xy^{\prime\prime}+2y^{\prime}=0.
$$
fazendo \(v^{\prime}=\phi\), e, portanto, \(v^{\prime\prime}=\phi^{\prime}\). Com esta alteração encontramos uma equação separável de primeira ordem,
$$
x\phi^{\prime}+2\phi=0,
$$
com solução geral
$$
\phi=cx^{-2}.
$$
A partir desta função encontramos \(y\) por integração
$$
y=\int\phi dx=c\int x^{-2}dx=c_{1}x^{-1}+c_{2}.
$$
Um caso adicional interessante pode ser tratado pela técnica de redução de ordem. Se, em uma equação diferencial de segunda ordem, a variável independente não aparece explícitamente, ou seja,
$$
y^{\prime\prime}=f(y,y^{\prime}),
$$
então a redução de ordem
$$
\phi=y^{\prime}\Rightarrow\phi^{\prime}=y^{\prime\prime}
$$
leva a uma equação diferencial sob a forma de
(14)
$$
\phi^{\prime}=f(y,\phi).
$$
Se considerarmos \(y\) como a variável independente então, pela regra da cadeia
$$
\phi^{\prime}=\frac{d\phi}{dx}=\frac{d\phi}{dy}\frac{dy}{dx}=\phi\frac{d\phi}{dy}
$$
e a equação diferencial (14) pode ser escrita como
$$
\phi\frac{d\phi}{dy}=f(y,\phi).
$$
Resolvendo esta equação teremos uma relação para \(\phi(y)\). A solução \(y(x)\) pode então ser obtida por meio da solução de
$$
y(x)=\int\phi dx.
$$
Exemplo 19. A equação diferencial
(15)
$$
yy^{\prime\prime}+(y^{\prime})^{2}=0
$$
pode ser resolvida através da substituição \(\phi=y^{\prime}\), \(\phi^{\prime}=y^{\prime\prime}\). Temos agora que
$$
\phi^{\prime}=\frac{d\phi}{dx}=\frac{d\phi}{dy}\,\frac{dy}{dx}=\phi\frac{d\phi}{dy}.
$$
Substituindo na equação (15) temos
$$
\phi^{\prime}=-\frac{\phi^{2}}{y}.
$$
Usamos agora \(\phi^{\prime}=\phi d\phi/dy\) para obter
$$
\frac{d\phi}{dy}=-\frac{\phi}{y}\Rightarrow\frac{d\phi}{\phi}=-\frac{dy}{y}
$$
cuja solução é
$$
\phi=\frac{A}{y}.
$$
Mas, como \(\phi=y^{\prime}\), então
$$
y^{\prime}=\frac{A}{y}\Rightarrow ydy=Adx,
$$
que, após integração resulta em
$$
y^{2}+c_{1}x+c_{2}=0,
$$
uma solução obtida sob forma implícita.
Exemplo 20. Na equação \(yy^{\prime\prime}=2y^{\prime2}\), faça \(\phi=y^{\prime}\). Pela regra da cadeia,
$$
y^{\prime\prime}=\frac{d\phi}{dx}=\frac{d\phi}{dy}\,\frac{dy}{dx}=\phi\frac{d\phi}{dy}.
$$
Substituindo na equação diferencial temos
$$
y\phi\frac{d\phi}{dy}=2\phi^{2}\Rightarrow\frac{d\phi}{\phi}=2\frac{dy}{y}\Rightarrow\ln\phi=2\ln y+c.
$$
Resolvemos primeiro para \(\phi\),
$$
\phi=y^{\prime}=Cy^{2},
$$
e integramos para encontrar \(y(x)\),
$$
\frac{dy}{y^{2}}=Cdx\Rightarrow-\frac{1}{y}=c_{1}x+c_{2}.
$$
Portanto,
$$
y(x)=\frac{1}{ax+b}.
$$
Exercícios 5.
1. Resolva as equações:
a. \(y^{\prime\prime}=2y^{\prime}\)
b. \(y^{\prime\prime}+4y^{\prime}=0\)
c. \(xy^{\prime\prime}=y^{\prime}\)
d. \(xy^{\prime\prime}+2y^{\prime}=0\)
e. \(y^{\prime\prime}+y^{\prime}=e^{-x}\)
f. \(y^{\prime\prime}=1+y^{\prime2}\)
g. \(x^{2}y^{\prime\prime}=y^{\prime2},x\gt 0\)
2. Equações diferenciais onde a variável independente \(x\) não aparece explicitamente:
a. \(y^{\prime\prime}+4y^{\prime}=0\)
b. \(xy^{\prime\prime}=y^{\prime}\)
c. \(xy^{\prime\prime}+2y^{\prime}=0\)
d. \(y^{\prime\prime}+(y^{\prime})^{2}=-e^{-y}\)
e. \(y^{\prime\prime}=1+(y^{\prime})^{2}\)
f. \(yy^{\prime\prime}-(y^{\prime})^{3}=0\)
Sabendo que \(y_{1}\) é uma solução da equação diferencial, use o método da redução de ordem para encontrar uma segunda solução:
(5) Resolvemos, na seção anterior, algumas destas equações para o caso de ser conhecida uma de suas soluções. Desenvolveremos aqui uma forma de se encontrar as duas soluções l.i..
Podemos agora considerar um caso particular(5) de equações diferenciais de segunda ordem lineares com coeficientes não constantes. Elas são as chamadas equações de Euler e têm a seguinte forma:
(16)
$$
L[y]=x^{2}y^{\prime\prime}+\alpha xy^{\prime}+\beta y=0,
$$
onde \(\alpha\) e \(\beta\) são constantes. Além de seu interesse próprio, como um tipo de equação que podemos tratar de forma completa com simplicidade, o conhecimento deste tipo de solução também servirá para nos orientar na busca de solução de casos mais gerais, feitos através do método de séries de potências tratados no capítulo seguinte. Trataremos inicialmente as soluções para \(x\gt 0\). O ponto \(x=0\) é um ponto que exige consideração especial como veremos no próximo capítulo.
Iniciamos por uma solução tentativa como \( y=x^{r}\), onde \(r\) é uma constante desconhecida à princípio. Derivando uma e duas vezes temos
$$
y^{\prime}=rx^{r-1},y^{\prime\prime}=r(r-1)x^{r-2},
$$
que, quando substituidos na equação diferencial resulta em
(17)
$$
[r(r-1)+\alpha r+\beta]x^{r}=0.
$$
Como \(x^{r}\) não se anula na região considerada (\(x\gt 0\)) temos uma equação do segundo grau para a constante \(r\)
$$
r^{2}+(\alpha-1)r+\beta=0,
$$
com raízes
(18)
$$
r_{1,2}=\frac{(1-\alpha)\pm\sqrt{(\alpha-1)^{2}-4\beta}}{2}.
$$
Mais uma vez temos que considerar em separado os três casos possíveis, de raízes reais distintas, de raízes idênticas e raízes complexas.
Raízes reais distintas
Se as raízes da equação (18) são reais e distintas então temos duas soluções, \(y_{1}=x^{r_{1}}\) e \(y_{2}=x^{r_{2}}\). Elas são l.i. pois o Wronskiano é não nulo,
$$
W(x^{r_{1}},x^{r_{2}})=(r_{2}-r_{1})x^{r_{1}+r_{2}-1}\neq0,
$$
uma vez que \(r_{1}\neq r_{2}\) e \(x\) não se anula no intervalo. Fazendo uma combinação linear destas duas soluções temos
$$
y(x)=c_{1}x^{r_{1}}+c_{2}x^{r_{2}},
$$
que é a solução geral para a equação (16).
Para tratar o caso seguinte, de raízes complexas da equação de Euler precisamos de uma breve discussão preliminar. Observe que, se \(r\in\mathbb{Q}\) (é um racional) então \(x^{r}=x^{m/n}=^{n}\sqrt{x^{m}}\). No caso geral, sendo \(r\) um número racional ou não, definimos
$$
x^{r}\overset{def}{=}e^{rlnx}.
$$
Assim podemos, sem dificuldades, obter a derivada
$$
\frac{\partial}{\partial r}x^{r}=\frac{\partial}{\partial r}(e^{rlnx})=x^{r}\ln x.
$$
Raízes complexas
Se as raízes da equação (18) são complexas, digamos
$$
r_{1}=\lambda+i\mu,\;\;r_{2}=\lambda-i\mu,
$$
as soluções são \(y_{1}=\) \(x^{\lambda+i\mu}\) e \(y_{2}=x^{\lambda-i\mu}\). Elas são igualmente l.i. pois o Wronskiano é não nulo,
$$
W(y_{1},y_{2})=x^{\lambda+i\mu}(\lambda-i\mu)x^{\lambda-i\mu-1}-(\lambda+i\mu)x^{\lambda+i\mu-1}x^{\lambda-i\mu}=
$$
$$
=(-2i\mu)x^{2\lambda-1}\neq 0 \text{ para } x\neq 0,
$$
lembrando que \(\mu\neq0\), caso contrário as raizes não seriam complexas. Encontramos então duas soluções l.i. dadas por
$$
y_{+}(x)=x^{\lambda+i\mu};\;\;y_{-}(x)=x^{\lambda-i\mu}.
$$
Podemos reescrever estas soluções usando a equação de Euler:
$$
y_{+}=e^{(^{\lambda+i\mu})\ln x}=e^{\lambda\ln x}e^{i\mu\ln x}=x^{\lambda}[\cos(\mu\ln x)+i\text{ sen }(\mu\ln x)],
$$
$$
y_{-}=e^{(^{\lambda-i\mu})\ln x}=e^{\lambda\ln x}e^{-i\mu\ln x}=x^{\lambda}[\cos(\mu\ln x)-i\text{ sen }(\mu\ln x)].
$$
Duas combinações lineares de \(y_{1}\) e \(y_{2}\) são obtidas da seguinte forma
$$
y_{1}=\frac{1}{2}(y_{+}+y_{-})=x^{\lambda}\cos\mu\ln x,
$$
$$
y_{2}=\frac{1}{2i}(y_{+}-y_{-})=x^{\lambda}\text{ sen }\mu\ln x,
$$
que são igualmente l. i.. A solução geral pode então ser escrita como
$$
y(x)=x^{\lambda}[c_{1}\cos(\mu\ln x)+c_{2}\text{ sen }(\mu\ln x)].
$$
Raízes iguais
Se na solução da equação (18) temos duas raízes iguais então encontramos apenas uma solução da equação diferencial e podemos usar o método da variação dos parâmetros para achar uma segunda solução e, daí, a solução geral. Substituindo \(y=x^{r}\) na equação diferencial
$$
L[y]=x^{2}y^{\prime\prime}+\alpha xy^{\prime}+\beta y=0
$$
obtemos, como antes,
$$
r^{2}+(\alpha-1)r+\beta=0.
$$
Se \(\Delta=(\alpha-1)^{2}-4\beta=0\) então temos uma raíz dupla que denotaremos simplesmente por \(r=(1-\alpha)/2,\) e uma única solução \(y_{1}=x^{r}\). Procuramos então encontrar uma solução da forma
$$
y(x)=u(x)x^{r}.
$$
Substituindo as derivadas
$$
y^{\prime}=u^{\prime}x^{r}+rux^{r-1},
$$
na equação diferencial inicial, e dividindo por \(x^{r}\), obtemos
$$
u^{\prime\prime}x^{2}+u^{\prime}x(2r+\alpha)+u[r(r-1)+\alpha r+\beta]=0.
$$
Observamos agora que o primeiro parênteses, \(2r+\alpha=1\), dado o valor de \(r\) neste caso, enquanto o colchete se anula devido à equação (18). Dividindo a equação restante por \(x\) temos
$$
u^{\prime\prime}x+u^{\prime}=0.
$$
Fazendo a substituição \(\phi=u^{\prime}\) chegamos a uma equação de primeira ordem
$$
\phi^{\prime}x+\phi=0,
$$
com soluções
$$
\phi=\frac{B}{x}.
$$
Integramos para obter
$$
u=B\int\frac{dx}{x}=A+B\ln x,
$$
e portanto
$$
y(x)=ux^{r}=Ax^{r}+Bx^{r}\ln x.
$$
Assim, além da solução já conhecida, \(y_{1}=x^{r_{1}}\), encontramos outra solução
$$
y_{2}(x)=x^{r_{1}}\ln x.
$$
Estas soluções são l.i. pois
$$
W(y_{1},y_{2})=x^{r_{1}}(r_{1}x^{r_{1}-1}\ln x+x^{r_{1}-1})-r_{1}x^{r_{1}-1}x^{r_{1}}\ln x=x^{2r_{1}-1}\neq0,
$$
sempre lembrando que estamos estudando apenas as soluções no intervalo \(x\gt 0\). Concluimos portanto que
$$
y(x)=c_1 x^{r_1} + c_2 x^{r_1}\ln x.
$$
é a solução geral da equação de Euler para o caso de raízes iguais.
Método Alternativo
Já encontramos a solução para o caso de raízes iguais. Descreveremos, no entanto, um procedimento diferente que servirá para introduzir técnicas de manipulação com operadores que podem ser úteis e poderosas em diversas situações. Queremos resolver a equação
$$
L[y]=x^{2}y^{\prime\prime}+\alpha xy^{\prime}+\beta y=0.
$$
Suponha agora que tomamos \(y=x^{r}\) com \(r\) variando continuamente. Com esta escolha obtemos
$$
L[x^{r}]=x^{r}[r(r-1)+\alpha r+\beta].
$$
Se existirem duas raízes reais distintas podemos escrever a equação do segundo grau dentro dos colchetes como
$$
r(r-1)+\alpha r+\beta=(r-r_{1})(r-r_{2}),
$$
onde \(r_{1}\) e \(r_{2}\) são as raízes, ou seja
$$
L[x^{r}]=x^{r}[(r-r_{1})(r-r_{2})].
$$
Observe que \(L[x^{r}]\) somente se anula se \(r=r_{1}\) ou \(r=r_{2}\). Se houver uma só raiz, \(r_{1}=r_{2}\), então
$$
L[x^{r}]=x^{r}(r-r_{1})^{2}.
$$
Agora derivamos os dois lados da última equação em relação a \(r\)
Vamos tratar primeiro o lado esquerdo da equação (19). Notamos que o operador \(L\) é construído com derivadas primeira e segunda em \(x\) e que podemos inverter a ordem de derivação
$$
\frac{\partial}{\partial r}\frac{\partial}{\partial x}\rightarrow\frac{\partial}{\partial x}\frac{\partial}{\partial r},
$$
se as funções envolvidas são contínuas com derivadas contínuas. Como consequência
$$
\frac{\partial}{\partial r}L[x^{r}]=L\left[\frac{\partial}{\partial r}x^{r}\right]=L[x^{r}\ln x].
$$
Quanto ao lado direito de (19) temos
$$
\frac{\partial}{\partial r}[x^{r}(r-r_{1})^{2}]=x^{r}\ln x(r-r_{1})^{2}+2x^{r}(r-r_{1}).
$$
Concluimos, portanto, que
$$
L[x^{r}\ln x]=x^{r}\ln x(r-r_{1})^{2}+2x^{r}(r-r_{1}).
$$
Em particular, se tomarmos \(r=r_{1}\) então teremos encontrado a outra solução para a equação diferencial proposta, pois
$$
L[x^{r_{1}}\ln x]=0.
$$
Isto indica que, além da solução já conhecida, \(y_{1}=x^{r_{1}}\), também
$$
y_{2}(x)=x^{r_{1}}\ln x
$$
é uma solução. Já mostramos que estas soluções são linearmente independentes.
Soluções para o caso \(x \lt 0\):
Relembramos aqui que apenas obtivemos as soluções para o intervalo \(x\gt 0\). Retornando mais uma vez à equação de Euler
$$
L[y]=x^{2}y^{\prime\prime}+\alpha xy^{\prime}+\beta y=0,
$$
estamos agora interessados em encontrar soluções para \(x\lt 0\). Para isto fazemos uma troca de variáveis
$$
x=-\xi,\;\;\xi\gt 0
$$
e com esta troca temos uma nova função
$$
y(x)=\mu(\xi).
$$
As derivadas das duas funções se relacionam da seguinte forma
$$
\frac{dy}{dx}=\frac{d\mu}{d\xi}\frac{d\xi}{dx}=-\frac{d\mu}{d\xi},
$$
Com estas derivadas reescrevemos a equação diferencial de Euler em termos da função \(\mu\) e da variável \(\xi\),
$$
L[\mu]=\xi^{2}\mu^{\prime\prime}+\alpha\xi\mu^{\prime}+\beta\mu=0,\xi\gt 0,
$$
cujas soluções já conhecemos e são idênticas às soluções anteriores se tomarmos \(x\) com sinal invertido.
Juntando as duas partes obtemos as soluções gerais para todos os valores de \(x\), exceto para \(x=0\):
\(r_{1}\neq r_{2}\),
reais
\(y(x)=c_{1}|x|^{r_{1}}+c_{2}|x|^{r_{2}},\)
\(r_{1,2}=\lambda\pm i\mu\)
complexos
\(y(x)=|x|^{\lambda}[c_{1}\cos(\mu\ln|x|)+c_{2}\text{ sen }(\mu\ln|x|)]\),
$$
L[y]=y^{\prime\prime}+f(x)y^{\prime}+g(x)y=r(x),
$$
onde \(f(x)\), \(g(x)\) e \(r(x)\) são contínuas em um intervalo aberto \(I\). A equação homogênea associada é
$$
L[y]=y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0,
$$
onde fizemos \(r(x)=0\). Podemos enunciar os seguintes teoremas:
Teorema 4: Sejam \(Y_{1} \text{ e } Y_{2}\) duas soluções da equação não homogênea (20). Então \(Y_{1}-Y_{2}\) é uma solução da equação homogênea associada \(L[y]=0\). Se, além disto, \(\{y_{1}, y_{2}\} \) é um conjunto fundamental de soluções de (20), então \(Y_{1}-Y_{2}=c_{1}y_{1}+c_{2}y_{2}\).
Demonstração: Como \(Y_{1}\) e \(Y_{2}\) são soluções de (20) então \(L[Y_{1}]=r(x),\;L[Y_{2}]=r(x)\), sendo \(L\) um operador linear temos que
$$
L[Y_{1}-Y_{2}]=L[Y_{1}]-L[Y_{2}]=r(x)-r(x)=0
$$
e, portanto, \(Y_{1}-Y_{2}\) é solução da homogênea associada. Como todas as soluções da homogênea podem ser escritas como uma combinação linear das soluções fundamentais então \(Y_{1}-Y_{2}=c_{1}y_{1}+c_{2}y_{2}\).
Teorema 5: A solução geral da equação não homogênea (20) pode ser escrita como
$$
y(x)=c_{1}y_{1}+c_{2}y_{2}+Y
$$
onde \(Y\) é uma solução qualquer da equação (20).
Demonstração: Pela linearidade de \(L\) temos que
$$
L[y(x)]=L[c_{1}y_{1}+c_{2}y_{2}+Y]=c_{1}L[y_{1}]+{Lc}_{2}[y_{2}]+L[Y]=r(x).
$$
Resumindo, seguimos os seguintes passos para encontrar a solução geral de uma equação diferencial não homogênea:
i Encontramos o conjunto fundamental de soluções da equação homogênea associada, \(\{y_{1},\;y_{2}\}\), ii Encontramos uma solução da não homogênea, \(Y\), iii Construimos a solução geral, \(\,y(x)=c_{1}y_{1}+c_{2}y_{2}+Y\).
Método dos Coeficientes Indeterminados
Já possuimos um método para encontrar soluções gerais para todas as equações de segunda ordem homogêneas com coeficientes constantes, para as equações de Euler e ainda para equações com coeficientes não constantes mais gerais, se conhecermos uma de suas soluções. Necessitamos agora estudar formas de obtenção de uma solução para as equações não homogêneas.
Em alguns casos podemos fazer uma hipótese inicial para a forma da solução procurada. Assim, por inspecção, supomos que a solução tem a forma de uma certa função com constantes indeterminadas, e a substituimos na equação diferencial com o propósito de determinar estas constantes. Geralmente, se a forma adotada como tentativa não for suficientemente ampla para acomodar a solução procurada, teremos que recomeçar com outra tentativa mais geral que a primeira. Alguns exemplos servirão para esclarecer melhor o método.
Exemplo 21. Vamos procurar, pelo método dos coeficientes indeterminados, a solução geral para a não homogênea
(21)
$$
y^{\prime\prime}+y^{\prime}=2\text{ sen }3x.
$$
Façamos primeiro a seguinte tentativa: \(y=A\text{ sen }3x\). Suas derivadas são
$$
y^{\prime}=3A\cos3x,\;y^{\prime\prime}=-9A\text{ sen }3x.
$$
Substituindo as derivadas na equação diferencial temos
$$
-9A\text{ sen }3x+3A\cos3x=2\text{ sen }3x,
$$
que não admite solução para a constante \(A\). Temos que tentar encontrar uma solução mais geral que esta. Tentaremos então
$$
Y=A\cos3x+B\text{ sen }3x,
$$
cujas derivadas são
$$
Y^{\prime}=-3A\text{ sen }3x+3B\cos3x,
$$
$$
Y^{\prime\prime}=-9A\cos3x-9B\text{ sen }3x.
$$
Substituindo na equação diferencial temos
$$
-9A\cos3x-9B\text{ sen }3x-3A\text{ sen }3x+3B\cos3x=2\text{ sen }3x.
$$
Agrupando termos em seno e cosseno temos
$$
(-9A+3B)\cos3x-(9B+3A)\text{ sen }3x=2\text{ sen }3x,
$$
e portanto, o sistema para \(A\) e \(B\) e sua respectiva solução,
$$
-9A+3B =0,\;\;3A+9B =-2\;\;\; \Rightarrow A=-\frac{1}{15},\;\;B=-\frac{1}{5}.
$$
Tendo encontrado as constantes \(A\) e \(B\) temos uma solução para a equação não homogênea (21),
$$
Y(x)=-\frac{1}{15}\cos3x+-\frac{1}{5}\text{ sen }3x.
$$
A equação homogênea associada \(y^{\prime\prime}+y^{\prime}=0\) tem solução geral
$$
y_{h}(x)=c_{1}+c_{2}e^{-x}.
$$
A solução geral do problema é
$$
y(x)=y_{h}(x)+Y(x)=c_{1}+c_{2}e^{-x}-\frac{1}{15}\cos3x+-\frac{1}{5}\text{ sen }3x.
$$
Exemplo 22. Encontre a solução geral para a equação não homogênea
$$
y^{\prime\prime}+2y^{\prime}=3+4\text{ sen }2x.
$$
Precisamos da solução geral da equação homogênea associada
$$
y^{\prime\prime}+2y^{\prime}=0,
$$
que pode ter sua ordem reduzida por meio da escolha
$$
\phi=y^{\prime},\;\phi^{\prime}=y^{\prime\prime}.
$$
A equação e sua solução são:
$$
\phi^{\prime}=-2\phi\Rightarrow\int\frac{d\phi}{\phi}=-2\int dx\Rightarrow\phi=ce^{-2x}.
$$
Daí obtemos \(y\) por integração
$$
y_{h}=c\int e^{-2x}dx=c_{1}e^{-2x}+c_{2}.
$$
Como solução para a não homogênea tentamos a seguinte função
$$
Y=Ax+B\text{ sen }2x+C\cos2x,
$$
com derivadas primeira e segunda respectivamente,
$$
Y^{\prime}=A+2B\cos2x-2C\text{ sen }2x,
$$
$$
Y^{\prime\prime}=-4B\text{ sen }2x-4C\cos2x.
$$
Substituindo na equação diferencial obtemos
$$
2A+(-4B-4C)\text{ sen }2x+(-4C+4B)\cos2x=3+4\text{ sen }2x.
$$
Comparando o termo constante e aqueles em seno e cosseno temos o sistema
$$
\left. \begin{array}{r} 2A =3, \\ B+C =-1 \\ -C+B=0 \end{array} \right\}
\Rightarrow A=\frac{3}{2},\;\;B=-\frac{1}{2},\;\;C=-\frac{1}{2}.
$$
A solução geral para a equação (26) é, portanto,
$$
y(x)=c_{1}e^{-2x}+c_{2}+\frac{3}{2}x-\frac{1}{2}(\text{ sen }2x+\cos2x).
$$
Exemplo 23. Encontre a solução geral para
$$
u^{\prime\prime}=\cos\omega_{0}t,
$$
onde \(u\) é função da variável independente \(t\) e \(\omega_{0}\) é uma constante. A equação homogênea tem solução
$$
u_{h}(t)=c_{1}+c_{2}t.
$$
Para a não homogênea tentamos
$$
U=A\cos\omega_{0}t+B\text{ sen }\omega_{0}t,
$$
com derivada segunda
$$
U^{\prime\prime}=-\omega_{0}^{2}U=-\omega_{0}^{2}A\cos\omega_{0}t-\omega_{0}^{2}B\text{ sen }\omega_{0}t.
$$
Então, substituindo na equação diferencial obtemos
$$
-\omega_{0}^{2}A\cos\omega_{0}t-\omega_{0}^{2}B\text{ sen }\omega_{0}t=\cos\omega_{0}t,
$$
e, portanto, \(B=0\), \(A=-1/\omega_{0}^{2}.\) A solução geral é
$$
u(t)=c_{1}+c_{2}t-\frac{1}{\omega_{0}^{2}}\cos\omega_{0}t.
$$
Observe que neste caso poderíamos ter tomado, logo no início, a solução tentativa \(U=A\cos\omega_{0}t\).
Exemplo 24. Encontre uma solução para a equação não homogênea
$$
y^{\prime\prime}-3y^{\prime}-4y=4x^{2}.
$$
Como solução para a não homogênea tentamos um polinômio de mesmo grau que \(r(x)\)
$$
Y=Ax^{2}+Bx+C,
$$
com derivadas
$$
Y^{\prime}=2Ax+B,Y^{\prime\prime}=2A.
$$
Substituindo \(Y,\;Y^{\prime}\) e \(Y^{\prime\prime}\) na equação diferencial obtemos
$$
2A-6Ax-3B-4Ax^{2}-4Bx+4C=4x^{2}.
$$
Igualando os coeficientes de termos de mesma ordem em \(x\) chegamos ao sistema
$$
\left. \begin{array}{r} -4A-4 =0 \\ -6A-4B =0 \\ 2A-3B-4c =0 \\ \end{array} \right\}
\Rightarrow A=-1,\;\;B=\frac{3}{2},\;\;c=-\frac{13}{8}.
$$
A solução da não homogênea é
$$
Y(x)=-x^{2}+\frac{3}{2}x-\frac{13}{8}.
$$
Esta solução deve ser somada à solução da homogênea associada para a obtenção da solução geral.
Exemplo 25. Encontre uma solução para a equação não homogênea
$$
2y^{\prime\prime}+3y^{\prime}+y=x^{2}+3\text{ sen }x.
$$
Para a não homogênea tentamos
$$
Y=Ax^{2}+Bx+C+D\text{ sen }x+E\cos x,
$$
observando que todas as cinco constantes \(A, B, C, D \text{ e } E\) são necessárias, como se pode verificar por tentativa direta de substituição. Suas derivadas são
$$
Y^{\prime}=2Ax+B+D\cos x-E\text{ sen }x,
$$
$$
Y^{\prime\prime}=2A-D\text{ sen }x-E\cos x,
$$
que, substituidas na equação diferencial resultam em
$$
4A-2D\text{ sen }x-2E\cos x+6Ax+3B+3D\cos x-3E\text{ sen }x+
$$
$$
+Ax^{2}+Bx+c+D\text{ sen }x+E\cos x=x^{2}+3\text{ sen }x.
$$
Reunindo os termos de mesma ordem em \(x\), os coeficientes de seno e cosseno chegamos ao sistema abaixo, e sua solução,
$$
\left. \begin{array}{r} 4A+3B+C=0 \\ 6A+B =0 \\ A=1 \\ \end{array} \right\}
\Rightarrow A=1,\;\;B=-6,\;\;C=14.
$$
$$
\left. \begin{array}{r} -3E-D=3 \\ 3D-E=0 \end{array} \right\}
\Rightarrow D=-\frac{3}{10},E=-\frac{9}{10}.
$$
A solução da não homogênea é
$$
Y(x)=x^{2}-6x+14-\frac{3}{10}\text{ sen }x-\frac{9}{10}\cos x.
$$
Uma observação final será útil para a solução de equações não homogêneas com o termo \(r(x)\) composto pela soma de duas ou mais funções. Suponha a equação diferencial na forma
$$
L[y]=r_{1}(x)+r_{2}(x).
$$
Observe que, se \(Y_{1}\) é solução de \(L[y]=r_{1}(x)\) e \(Y_{2}\) é solução de \(L[y]=r_{2}(x)\), então \(Y_{1}+Y_{2}\) é solução particular da equação (27) pois
$$
L[Y_{1}+Y_{2}]=L[Y_{1}]+L[Y_{2}]=r_{1}(x)+r_{2}(x).
$$
Exercícios 7.
1. \(y^{\prime\prime}-2y^{\prime}-3y=3e^{2x}\)
2. \(y^{\prime\prime}+2y^{\prime}+5y=3\text{ sen }2x\)
3. \(y^{\prime\prime}-2y^{\prime}-3y=-3xe^{-x}\)
4. \(y^{\prime\prime}+2y^{\prime}=3+4\text{ sen }2x\)
5. \(y^{\prime\prime}+9y=x^{2}e^{3x}+6\)
6. \(y^{\prime\prime}+2y^{\prime}+y=2e^{-x}\)
7. \(2y^{\prime\prime}+3y^{\prime}+y=x^{2}+3\text{ sen }x\)
8. \(y^{\prime\prime}+y=3\text{ sen }2x+x \cos2x\)
1. \(y=c_{1}e^{3x}+c_{2}e^{-x}-e^{2x}\)
2. \(y=c_{1}e^{-x}\cos2x+c_{2}e^{-x}\text{ sen }2x+\frac{3}{17}\text{ sen }2x-\frac{12}{17}\cos2x\)
3. \(y=c_{1}e^{3x}+c_{2}e^{-x}+\frac{3}{16}xe^{-x}+\frac{3}{8}x^{2}e^{-x}\)
4. \(y=c_{1}+c_{2}e^{-2x}+\frac{3}{2}x-\frac{1}{2}\text{ sen }2x-\frac{1}{2}\cos2x\)
5. \(y=c_{1}\cos3x+c_{2}\text{ sen }3x+\frac{1}{162}(9x^{2}-6x+1)e^{3x}+\frac{2}{3}\)
6. \(y=c_{1}e^{-x}+c_{2}xe^{-x}+x^{2}e^{-x}\)
7. \(y=c_{1}e^{-x}+c_{2}e^{-x/2}+x^{2}-6x+14-\frac{3}{10}\text{ sen }x-\frac{9}{10}\cos x\)
8. \(y=c_{1}\cos x+c_{2}\text{ sen }x-\frac{1}{3}x\cos2x-\frac{5}{9}\text{ sen }2x\)
9. \(y=c_{1}\cos\omega_{0}x+c_{2}\text{ sen }\omega_{0}x+(\omega_{0}^{2}-\omega^{2})^{-1}\cos\omega x\)
10. \(y=c_{1}\cos\omega_{0}x+c_{2}\text{ sen }\omega_{0}x+(1/2\omega_{0})x\text{ sen }\omega x\)
11. \(y=c_{1}e^{-x/2}\cos\left(\sqrt{15}x/2\right)+c_{2}e^{-x/2}\text{ sen }\left(\sqrt{15}x/2\right)+\frac{1}{6}e^{x}-\frac{1}{4}e^{-x}\)
12. \(y=c_{1}e^{-x}+c_{2}e^{2x}+\frac{1}{6}xe^{2x}+\frac{1}{8}e^{-2x}\)
13. \(y=e^{x}-\frac{1}{2}e^{-2x}-x-\frac{1}{2}\)
14. \(y=\frac{7}{10}\text{ sen }2x-\frac{19}{40}\cos2x-\frac{1}{8}+\frac{3}{5}e^{x}+\frac{1}{4}x^{2}\)
15. \(y=4xe^{x}-3e^{x}+\frac{1}{6}x^{3}e^{x}+4\)
16. \(y=e^{3x}+\frac{2}{3}e^{-x}-\frac{2}{3}e^{2x}-xe^{2x}\)
17. \(y=2\cos2x-\frac{1}{8}\text{ sen }2x-\frac{3}{4}\cos2x\)
18. \(y=e^{-x}\cos2x+\frac{1}{2}e^{-x}\text{ sen }2x+xe^{-x}\text{ sen }2x\)
Método da Variação dos Parâmetros
(6) Supondo que as integrais envolvidas possam ser explicitamente avaliadas. Caso contrário se pode realizar integrações numéricas ou simplesmente obter uma solução formal da qual se pode extrair informações úteis.
O método da variação dos parâmetros para a solução da equações diferenciais não homogêneas, atribuído a Lagrange, é um método mais geral e não implica em prever uma forma apropriada para a solução. Embora geralmente mais trabalhoso que o método anterior ele é também mais poderoso e fornece sempre, em princípio, uma solução(6).
O método consiste no seguinte procedimento: para encontrar uma solução geral para a equação não homogênea
$$
L[y]=y^{\prime\prime}+f(x)y^{\prime}+g(x)y=r(x)
$$
buscamos primeiro uma solução para a homogênea associada, \(L[y]=0\). Digamos que
$$
y_{h}(x)=Ay_{1}(x)+By_{2}(x),
$$
com \( A \text{ e } B\) constantes, seja esta solução. A variação dos parâmetros consiste em substituir as constantes por funções desconhecidas,
$$
A\rightarrow A(x),\;\;B\rightarrow B(x),
$$
o que resulta em uma solução tentativa mais geral que a anterior, sob a forma de
(22)
$$
y(x)=A(x)y_{1}(x)+B(x)y_{2}(x).
$$
Note que com isto estamos introduzindo uma grau de liberdade extra em nosso problema e que uma única equação do tipo não será suficente para determinar univocamente as funções \(A(x)\) e \(B(x)\). Como veremos, usaremos esta liberdade extra para inserir um vínculo ou restrição adicional de forma a simplificar a solução do problema. Omitindo os argumentos das funções, para ter uma notação mais compacta, escrevemos a derivada primeira da solução tentativa:
$$
y^{\prime}=Ay_{1}^{\prime}+A^{\prime}y_{1}+By_{2}^{\prime}+B^{\prime}y_{2}
$$
sobre a qual imporemos o vínculo adicional
(23)
$$
y_{1}A^{\prime}+y_{2}B^{\prime}=0.
$$
Assim resta apenas, para a derivada primeira
$$
y^{\prime}=Ay_{1}^{\prime}+By_{2}^{\prime}
$$
e, consequentemente
$$
y^{\prime\prime}=Ay_{1}^{\prime\prime}+By_{2}^{\prime\prime}+A^{\prime}y_{1}^{\prime}+B^{\prime}y_{2}^{\prime}.
$$
Com estas escolhas a equação (22) fica assim
$$
Ay_{1}^{\prime\prime}+By_{2}^{\prime\prime}+A^{\prime}y_{1}^{\prime}+B^{\prime}y_{2}^{\prime}+f(Ay_{1}^{\prime}+By_{2}^{\prime})+g(Ay_{1}+By_{2})=r.
$$
Reagruparemos os termos da seguinte forma
$$
A(y_{1}^{\prime\prime}+fy_{1}^{\prime}+gy_{1})+B(y_{2}^{\prime\prime}+fy_{2}^{\prime}+gy_{2})+A^{\prime}y_{1}^{\prime}+B^{\prime}y_{2}^{\prime}=r,
$$
para ver que a equação se reduz à
(24)
$$
A^{\prime}y_{1}^{\prime}+B^{\prime}y_{2}^{\prime}=r,
$$
uma vez que os termos dentros dos parênteses são nulos já que \(y_{1}\) e \(y_{2}\) são soluções da homogênea associada. Observamos que a escolha particular do vínculo adicional dada por (30) faz com que a derivada segunda de \(y\) contenha apenas termos com derivadas primeiras de \(A\) e \(B\), e que a substituição da solução tentativa na equação diferencial original leva a uma expressão simples (24) que, igualmente, contém apenas \(A^{\prime}\) e \(B^{\prime}\). As equações (23) e (24) devem ser resolvidas simultaneamente. Elas formam um sistema linear algébrico (isto é, não são equações diferenciais) para \(A^{\prime}\) e \(B^{\prime}\). Como último passo encontramos por integração as funções \(A(x)\) e \(B(x)\) e teremos assim resolvido a equação (22).
Exemplo 26. Vamos procurar a solução da equação não homogênea
(25)
$$
y^{\prime\prime}-5y^{\prime}+6y=2e^{x},
$$
pelo método da variação dos parâmetros. Temos que encontrar primeiro a solução geral da homogênea associada, que tem equação característica \(r^{2}-5r+6=0\) cujas raízes são \(r=2\) e \(r=3\). A solução da homogênea é
$$
y_{h}(x)=Ae^{2x}+Be^{3x},
$$
Para a não homogênea tentamos a solução
$$
y(x)=A(x)e^{2x}+B(x)e^{3x},
$$
onde \(A \text{ e } B\) são agora funções, e que tem derivada primeira
$$
y^{\prime}=A^{\prime}e^{2x}+B^{\prime}e^{3x}+2Ae^{2x}+3Be^{3x}.
$$
Introduzindo o vínculo ou restrição
$$
A^{\prime}e^{2x}+B^{\prime}e^{3x}=0
$$
ficamos com
$$
y^{\prime}=2Ae^{2x}+3Be^{3x},
$$
e a derivada segunda:
$$
y^{\prime\prime}=2A^{\prime}e^{2x}+4Ae^{2x}+3B^{\prime}e^{3x}+9Be^{3x}.
$$
Substituindo na equação diferencial e agrupando os termos de forma conveniente temos
$$
A(4e^{2x}-10e^{2x}+6e^{2x})+B(9e^{3x}-15e^{3x}+6e^{3x})+2A^{\prime}e^{2x}+3B^{\prime}e^{3x}=2e^{x}
$$
ou, já que os termos dentro dos parênteses são nulos,
$$
2A^{\prime}e^{2x}+3B^{\prime}e^{3x}=2e^{x}.
$$
Temos portanto o seguinte sistema algébrico e sua solução
$$
\left.
\begin{array}{l}
A^{\prime}e^{2x}+B^{\prime}e^{3x} =0 \\
2A^{\prime}e^{2x}+3B^{\prime}e^{3x} =2e^{x} \\
\end{array}
\right\}
\Rightarrow A^{\prime}=-2e^{-x},\;\;B^{\prime}=2e^{-2x}.
$$
Por integração destas funções obtemos \(A\) e \(B\),
$$
A=-2\int e^{-x}dx=2e^{-x}+c_{1},
$$
$$
B=2\int e^{-2x}dx=-e^{-2x}+c_{2}.
$$
A solução geral da equação (25) é
$$
y(x)=(2e^{-x}+c_{1})e^{2x}+(-e^{-2x}+c_{2})e^{3x}=c_{1}e^{2x}+c_{2}e^{3x}+e^{x}.
$$ Exemplo 27. Para resolver a equação não homogênea
(26)
$$
y^{\prime\prime}+4y^{\prime}+4y=x^{-2}e^{-2x}
$$
procuramos as soluções da homogênea associada, que tem equação característica
$$
r^{2}+4r+4=0
$$
com raíz dupla \(r=-2\). A solução da homogênea é
$$
y_{h}(x)=Ae^{-2x}+Bxe^{-2x},
$$
\(A \text{ e } B\) constantes. Para a não homogênea tentamos a variação dos parâmetros
$$
y(x)=Ae^{-2x}+Bxe^{-2x}
$$
onde agora \(A\) e \(B\) são funções. A derivada primeira é
$$
y^{\prime}=A^{\prime}e^{-2x}-2Ae^{-2x}+B^{\prime}xe^{-2x}+Be^{-2x}-2Bxe^{-2x}.
$$
Introdução a restrição
$$
(A^{\prime}+B^{\prime}x)e^{-2x}=0
$$
Como será ilustrado no exemplo a seguir, o método da variação dos parâmetros pode ser usado na solução de equações diferenciais com coeficientes não constantes. Vale lembrar que ainda não estudamos uma forma geral para a obtenção de soluções para estas equações mesmo no caso homogêneo, exceto para as equações de Euler. Este estudo será feito no capítulo sobre as soluções em séries de potências.
No exemplo seguinte supomos conhecidas duas soluções l.i. para a equação homogênea associada e, a partir delas, obtemos a solução geral para a não homogênea.
Exemplo 28. Dada a equação de Euler
$$
x^{2}y^{\prime\prime}-2y=3x^{2}-1,
$$
podemos encontrar as soluções da homogênea associada que são \(y_{1}=x^{2}\) e \(y_{2}=x^{-1}\). A partir dai procuramos a sua solução geral. Usando a variação dos parâmetros construimos a solução tentativa
$$
y(x)=A(x)x^{2}+B(x)x^{-1}.
$$
Na derivada primeira
$$
y^{\prime}=A^{\prime}x^{2}+B^{\prime}x^{-1}+2Ax-Bx^{-2},
$$
impomos a restrição
(27)
$$
A^{\prime}x^{2}+B^{\prime}x^{-1}=0,
$$
o que nos deixa com as seguintes derivadas de \(y\),
$$
y^{\prime}=2Ax-Bx^{-2},
$$
$$
2A^{\prime}x^{3}-B^{\prime}=3x^{2}-1.
$$
As equações (27) e (28) formam um sistema algébrico para \(A^{\prime}\) e \(B^{\prime}\), com solução
$$
A^{\prime}=\frac{1}{x}-\frac{1}{3x^{3}},\;\;B^{\prime}=\frac{1}{3}-x^{2}.
$$
As funções \(A\) e \(B\) podem ser encontradas por integração direta,
$$
A=\int\left(\frac{1}{x}-\frac{1}{3x^{3}}\right)dx=\ln x+\frac{1}{6x^{2}}+c_{1},
$$
Observamos que \(x^{2}/3\) é uma solução da equação homogênea e não contribui para a solução da não homogênea. Reescrevemos então a solução obtida como
$$
y(x)=c_{3}x^{2}+c_{2}x^{-1}+x^{2}\ln x+\frac{1}{2},
$$
onde \(c_{3}=c_{1}-1/3.\)
Exemplo 29. Dada a equação diferencial
(29)
$$
xy^{\prime\prime}-(1+x)y^{\prime}+y=x^{2}e^{2x}
$$
podemos verificar por substituição que \(y_{1}=1+x\) e \(y_{2}=e^{x}\) são soluções da homogênea asssociada. Usando a variação dos parâmetros procuramos sua solução geral construindo
$$
y(x)=A(1+x)+Be^{x},
$$
onde as funções \(A\) e \(B\) são desconhecidas. Sua derivada primeira é
$$
y^{\prime}=A^{\prime}(1+x)+A+B^{\prime}e^{x}+Be^{x}.
$$
Com a restrição adicional
$$
A^{\prime}(1+x)+B^{\prime}e^{x}=0
$$
ficamos com as seguintes derivadas de \(y\),
$$
y^{\prime}=A+Be^{x},
$$
Este desenvolvimento é, na prática, a forma usual apropriada para a solução de equações diferenciais usando este método. Apresentamos, no entanto, uma solução formal no teorema seguinte.
Teorema 6: Dada a equação diferencial não homogênea
onde \(f(x),\;g(x)\text{ e } r(x)\) são funções contínuas em um intervalo aberto \(I\) e \( y_{1}(x), y_{2}(x)\) são soluções linearmente independentes da homogênea \(L[y]=0 \) então uma solução particular de (30) é
$$
Y(x)=-y_{1}(x)\int\frac{y_{2}(x)r(x)}{W(y_{1},y_{2})}dx+y_{2}(x)\int\frac{y_{1}(x)r(x)}{W(y_{1},y_{2})}dx.
$$
A solução geral, já vista em teorema anterior, é
$$
y(x)=c_{1}y_{1}(x)+c_{2}y_{2}(x)+Y(x).
$$
Demonstração: Sabemos que
$$
y_{h}(x)=Ay_{1}(x)+By_{2}(x)
$$
é a solução geral da equação homogênea. Tentamos uma solução sob a forma
$$
y(x)=A(x)y_{1}(x)+B(x)y_{2}(x).
$$
Procedendo como já feito no início desta seção chegamos a uma sistema de equações lineares em \(A^{\prime}\) e \(B^{\prime}\)
$$
y_{1}A^{\prime}+y_{2}B^{\prime} =0
$$
$$
y_{1}^{\prime}A^{\prime}+y_{2}^{\prime}B^{\prime}=r
$$
Usando a regra de Cramer obtemos as soluções
$$
A^{\prime}=\frac{\det \begin{bmatrix} 0 & y_{2} \\ r & y_{2}^{\prime} \end{bmatrix}}
{W(y_{1},y_{2})}=\frac{-y_{2}r}{W(y_{1},y_{2})},
$$
$$
B^{\prime}=\frac{\det \begin{bmatrix} y_{1} & 0 \\ y_{1}^{\prime} & r \end{bmatrix}}
{W(y_{1},y_{2})}=\frac{y_{1}r}{W(y_{1},y_{2})},
$$
Observe que o Wronskiano não se anula pois \(y_{1}\) e \(y_{2}\) são l.i.. Integrando chegamos a expressões formais para \(A\) e \(B\),
$$
A=-\int\frac{y_{2}r}{W(y_{1},y_{2})}dx+c_{1},
$$
A solução geral para a equação (30) é
$$
y(x)=c_{1}y_{1}(x)+c_{2}y_{2}(x)-y_{1}(x)\int\frac{y_{2}r}{W(y_{1},y_{2})}dx+y_{2}(x)\int\frac{y_{1}r}{W(y_{1},y_{2})}dx,
$$
sendo que
$$
Y(x)=-y_{1}(x)\int\frac{y_{2}r}{W(y_{1},y_{2})}dx+y_{2}(x)\int\frac{y_{1}r}{W(y_{1},y_{2})}dx
$$
12. \(y=c_{1}\cos2x+c_{2}\text{ sen }2x+\frac{1}{2}\int f(t)\text{ sen }2(x-t)dt\)
13. \(Y=\frac{1}{2}+x^{2}\ln x\)
14. \( Y=-2x^{2}\)
15. \(Y=\frac{1}{2}(x-1)e^{2x}\)
16. \(Y=-\frac{1}{2}(2x-1)e^{-x}\)
17. \( Y=\frac{1}{6}x^{2}(\ln x)^{3}\)
18. \( Y=-\frac{3}{2}\sqrt{x}\cos x\).
O Método Complexo
Um pequeno acréscimo pode ser interessante neste ponto no que se refere ao uso das equações diferenciais em aplicações. Um tipo de equação comum em aplicações provenientes da mecânica e dos circuitos elétricos é
$$
Ay^{\prime\prime}+By^{\prime}+cy=r(x)
$$
onde a parte não homogênea \(r(x)\) involve senos e cossenos. Embora estas equações possam ser tratadas por um dos métodos já estudados, vamos considerar uma forma prática para se encontrar uma solução particular usando funções complexas. Faremos isto por meio de exemplos.
Exemplo 30. Considere a equação
(31)
$$
y^{\prime\prime}+y^{\prime}+3y=5\text{ sen }x.
$$
Pelo método dos coeficientes indeterminados fazemos
$$
y_{p}=a\cos x+b\text{ sen }x
$$
e substituimos na equação, para encontrar a solução particular
$$
y_{p}(x)=-\cos x+2\text{ sen }x.
$$
O método complexo consiste em resolver outra equação,
$$
Y^{\prime\prime}+Y^{\prime}+3Y=5e^{ix},
$$
(8) \(\text{Im}[f(x)]\) é a parte imaginária da função complexa \(f\), enquanto \(\text{Re}[f(x)]\) é a parte real.
notando que(8) \(\text{Im}(e^{ix})=\text{ sen }x\). Para esta equação fazemos a tentativa
$$
Y=ke^{ix}.
$$
Substituindo esta função e suas derivadas,
$$
Y^{\prime}=ike^{ix},\;\,Y^{\prime\prime}=-ke^{ix},
$$
na equação (31) temos
$$
-ke^{ix}+ike^{ix}+3ke^{ix}=5e^{ix}
$$
ou seja
$$
k(2+i)=5\Rightarrow k=\frac{5}{2+i}=\frac{5(2-i)}{(2+i)(2-i)}=\frac{10-5i}{5}=2-i.
$$
A solução particular para (31) é, então,
$$
Y_{p}=(2-i)e^{ix}=(2-i)(\cos x+i\text{ sen }x)=2\cos x+\text{ sen }x+i(-\cos x+2\text{ sen }x).
$$
Notamos agora que, para obter a solução da equação original (31), basta tomar a parte imaginária desta última expressão:
$$
y_{p}(x)=\text{Im}(Y_{p})=-\cos x+2\text{ sen }x,
$$
como já esperado.
Exercícios 9.
1. \(y^{\prime\prime}+3y^{\prime}+16y=24\cos4t\)
2. \(y^{\prime\prime}+y^{\prime}+4y=8\text{ sen }2t\)
4. \(y^{\prime\prime}+y^{\prime}+9y=-3\text{ sen }3t\)
Algumas Soluções:
1. \(y=2\text{ sen }4t\)
3. \(y=2\) sen \(4t\)
Aplicações
Movimento harmônico simples, forçado ou amortecido
As equações com coeficientes constantes, embora simples, servem como modelo para um grande número de sistemas importantes nas aplicações em física, engenharia e outras áreas. Já mencionamos que um corpo de massa \(m\), preso a uma mola de constante elástica \(k\), sob atrito e sujeito à uma força externa variável \(f(t)\) tem seu movimento descrito por um equação diferencial linear de segunda ordem com coeficientes constantes.
Figura: Sistema massa-mola.
A força que a mola exerce sobre o corpo é dada pela lei de Hooke, \(F_{mola}=-kx\), enquanto o atrito exerce uma força proporcional à sua velocidade e em direção oposta a ela, \(F_{atrito}=-cv\). De acordo com a segunda lei de Newton, \(\sum F=ma\), onde \(\sum F\) é a soma de todas as forças atuando sobre o corpo, ou seja
$$
ma=-cv-kx.
$$
Se além destas forças adicionarmos uma força externa \(f(t)\) provida, por exemplo, por um motor dotado de pistons ou outro mecanismo qualquer de transferência de energia para o sistema corpo-mola, teremos a equação
$$
m\frac{d^{2}x(t)}{dt}+c\frac{dx}{dt}+kx=f(t),
$$
ou, utilizando a notação compacta \(\dot{x}=dx/dt,\) \(\ddot{x}=d^{2}x/dt^{2},\)
$$
m\ddot{x}+c\dot{x}+kx=f(t).
$$
Exemplo 31. Movimento harmônico simples O caso mais simples de interesse é o da mola livre, sem a atuação de forças externas ou atrito. Nesta situação temos
$$
m\ddot{x}+kx=0
$$
cuja solução pode ser obtida substituindo-se \(x=e^{rt}\) na equação diferencial para obter
$$
mr^{2}+k=0\Rightarrow r=\pm i\omega
$$
onde \(\omega=\sqrt{k/m}\) é a frequência natural do sistema. A solução geral é
(32)
$$
x(t)=c_{1}\text{ sen }\omega t+c_{2}\cos\omega t.
$$
Ângulo de fase
As constantes de integração ficam determinadas por meio das condições iniciais como, por exemplo, a posição e a velocidade inicial do corpo. Uma outra forma interessante pode ser obtida para esta solução se definirmos novas constantes \(C\) e \(\delta\) que se relacionam com \(c_{1}\) e \(c_{2}\) de acordo com a figura,
A equação (32) fica escrita como
$$
x(t)=C(\text{ sen }\omega tcos\delta+\cos\omega t\text{ sen }\delta).
$$
Usamos a fórmula da adição de arco do seno
$$
\text{ sen }(a+b)=\text{ sen }a\cos b+\cos a\text{ sen }b
$$
para escrever
$$
x(t)=C\text{ sen }(\omega t+\delta).
$$
Observe que o gráfico deste movimento, que descreve um movimento harmônico simples, é simplesmente o de um seno (cosseno) com amplitude e fase modificados em relação ao seno (cosseno) puro.
Exemplo 32. Trataremos um exemplo particular da situação descrita no exemplo 1. Um objeto de massa igual a 4 kg está preso a uma mola com constante de Hooke \(k=9\) N/cm sobre uma mesa horizontal sem atrito. No instante \(t=0\) a massa é solta de uma posição inicial afastada 6cm da posição de equilíbrio da mola e com velocidade inicial de 3 cm/s. A equação diferencial que descreve o movimento do objeto é
$$
\ddot{x}=-\omega^{2}x,
$$
onde \(\omega=\sqrt{k/m}=3/2s^{-1}\). Observe que \(\omega\) tem unidades de \(\text{(tempo)}^{-1}\), sendo uma medida de frequência. A solução e sua derivada são, respectivamente,
$$
x(t)=c_{1}\text{ sen }\omega t+c_{2}\cos\omega t,
$$
$$
\dot{x}(t)=c_{1}\omega\cos\omega t-c_{2}\omega\text{ sen }\omega t.
$$
Determinamos agora as constantes \(c_{1}\) e \(c_{2}\) usando as condições iniciais:
$$
x(0)=6cm\Rightarrow c_{2}=6cm,
$$
A solução particular encontrada é
$$
x(t)=2\text{ sen }\frac{3t}{2}+6\cos\frac{3t}{2},
$$
onde o tempo \(t\) é medido em segundos, \(x\) em centímetros. Alternativamente podemos calcular a amplitude da oscilação:
$$
C=\sqrt{c_{1}^{2}+c_{2}^{2}}=\sqrt{40}cm\approx6,3cm
$$
enquanto o ângulo de fase é
$$
\delta=\arctan\left(\frac{c_{2}}{c_{1}}\right)=\arctan(3)\approx1,25\text{rad}.
$$
Portanto, a menos de arredondamentos, a posição é dada por
$$
x(t)\approx6,3\text{ sen }\left(\frac{3t}{2}+1,25\right).
$$
Observe que enquanto \(x\) é dado em centímetros o argumento do seno é adimensional.
Exemplo 33. Movimento amortecido Se o objeto preso a massa está submetido a algum tipo de atrito, por exemplo, por estar se movendo dentro de um meio viscoso ou por ter atrito com a superfície onde está apoiado, então parte da energia do sistema será dissipada por este atrito e a amplitude de oscilação decairá. A força de atrito é geralmente descrita por um termo proporcional à uma potência da velocidade. Tomaremos como exemplo a força de atrito como \(F_{atrito}=-c\dot{x}\), sendo que o sinal negativo indica que esta força age na direção contrária à do movimento. Aplicando a segunda lei de Newton temos
$$
F=-c\dot{x}-kx
$$
ou seja, denotando \(2\lambda=c/m\) e \(\omega=\sqrt{k/m}\)
$$
\ddot{x}+2\lambda\dot{x}+\omega^{2}x=0.
$$
Com esta notação a equação característica é \(r^{2}+2\lambda r+\omega^{2}=0\), com raízes
$$
r_{1}=-\lambda+\sqrt{\lambda^{2}-\omega^{2}};\;\;r_{2}=-\lambda-\sqrt{\lambda^{2}-\omega^{2}}.
$$
O comportamento do sistema pode ser descrito em três casos gerais:
i) Sistema superamortecido, quando \(\lambda^{2}-\omega^{2}\gt 0\). Neste caso o amortecimento \(c\) é grande quando comparado à constante elástica \(k\). A solução não apresenta oscilações, sendo dada por
$$
x(t)=\left(c_{1}e^{\sqrt{\lambda^{2}-\omega^{2}}t}+c_{2}e^{-\sqrt{\lambda^{2}-\omega^{2}}t}\right)e^{-\lambda t}.
$$
ii) Sistema subamortecido, quando \(\lambda^{2}-\omega^{2}\lt 0\). Neste caso o amortecimento \(c\) é pequeno quando comparado à constante elástica \(k\). As raízes da equação características são complexas
$$
r_{1}=-\lambda+i\sqrt{\omega^{2}-\lambda^{2}};\;\,r_{2}=-\lambda-i\sqrt{\omega^{2}-\lambda^{2}},
$$
e a solução é oscilatória, descrita por
$$
x(t)=\left(c_{1}\cos\sqrt{\omega^{2}-\lambda^{2}}t+c_{2}\text{ sen }\sqrt{\omega^{2}-\lambda^{2}}t\right)e^{-\lambda t}.
$$
A amplitude do movimento decresce devido ao fator \(e^{-\lambda t}\), tendendo ao repouso após a passagem de um tempo suficientemente longo.
iii) Sistema criticamente amortecido, quando \(\lambda^{2}-\omega^{2}=0\), representando um caso intermediário entre os dois primeiros casos. A solução é simplesmente
$$
x(t)=(c_{1}+c_{2}t)e^{-\lambda t}.
$$
Observe que esta solução pode ter apenas uma raiz, significando que o objeto pode passar pelo ponto de equilíbrio no máximo uma vez.
Figura: (a) Sistema amortecido (b) Amortecimento crítico (c) Superamortecido
Exemplo 34. Movimento forçado: Além da força restauradora da mola o objeto pode ainda estar submetido a uma força externa \(f(t)\), estando ou não sujeito a efeitos dissipativos de atrito. Teremos neste caso a equação diferencial completa, equação (2). Fazendo as mesmas identificações \(2\lambda=c/m\) e \(\omega_{0}=\sqrt{k/m}\) e denotando agora \(\phi(t)=f(t)/m\) temos a equação não homogênea
que pode ser resolvida por qualquer um dos métodos já estudados. Combinações de diferentes valores de \(\lambda\) e \(\omega_{0}\) resultarão em comportamentos diferentes para as soluções do sistema.
Suponhamos inicialmente que não existe amortecimento \((\lambda=0)\) e que a força externa aplicada ao sistema seja oscilatória, na forma de \(\phi(t)=\phi_{0}\cos\omega t\), onde \(\omega\) não é necessariamente a frequência natural do sistema, \(\omega_{0}\). De fato, se \(\omega\neq\omega_{0}\), então a solução geral da equação (33) será
$$
x(t)=c_{1}\text{ sen }\omega_{0}t+c_{2}\cos\omega_{0}t+\frac{\phi_{0}}{(\omega_{0}^{2}-\omega^{2})}\cos\omega t,
$$
onde as constantes de integração são determindas pelas condições iniciais. Se o objeto estiver em repouso e no ponto de equilíbrio da mola no instante inicial então
$$
x(0)=0,\;\;\dot{x}(0)=0
$$
e as constantes serão
$$
c_{1}=0;\;\;c_{2}=\frac{\phi_{0}}{\omega^{2}-\omega_{0}^{2}}.
$$
Usamos a relação trigonométrica
$$
\cos A-\cos B=2\text{ sen }\left(\frac{A+B}{2}\right)\text{ sen }\left(\frac{A-B}{2}\right)
$$
para escrever a solução na forma
$$
x(t)=\frac{\phi_{0}}{\omega_{0}^{2}-\omega^{2}}(\cos\omega t-\cos\omega_{0}t)
$$
que representa uma oscilação de maior frequência \((\omega_{0}+\omega)/2\) modulada por outra de menor frequência \((\omega_{0}-\omega)/2.\) Este fenômeno é denominado de batimento e ocorre, por exemplo, quando duas cordas de um instrumentos musical com frequências próximas, mas não iguais, são tocadas simultaneamente. Como se observa na figura 5 uma oscilação harmônica tem a sua amplitude modulada por outra harmônica de menor frequência.
Figura: Amplitude modulada, batimentos
Um segundo exemplo interessante é o caso de ser a frequência da força externa igual à da frequência natural do sistema. Neste caso o termo não homogêneo \(\phi_{0}\cos\omega t\) é solução da equação homogênea e a solução geral da equação (42) é
$$
x(t)=c_{1}\text{ sen }\omega_{0}t+c_{2}\cos\omega_{0}t+\frac{\phi_{0}}{2\omega_{0}}t\text{ sen }\omega_{0}t,
$$
de onde se observa, no terceiro termo, que o movimento tem amplitude crescente para valores crescentes de \(t\). Este é o chamado fenômeno da ressonância, ilustrado na figura, para um caso particular.
Naturalmente que uma mola sofrendo esticamentos progressivos deixaria de responder de forma linear, como descrito pela lei de Hooke. São conhecidos, no entanto, diversas situações onde o fenômeno da ressonância pode produzir efeitos desastrosos, tais como a completa destruição de uma ponte por efeito da oscilação produzida por ventos ou o rompimento de asas de aviões.
Circuitos RLC
Um circuito contendo um indutor, um capacitor, um resistor e uma fonte ligados em série satisfaz a mesma equação diferencial que os sistemas de osciladores mecânicos já estudados.
Digamos que o resistor tenha resistência de \(R\), medida em omhs (\(\Omega\)), o capacitor seja de \(C\) farads
(\(f\)) e o indutor de \(L\) henrys (\(H\)). Denotando por \(i(t)\) a corrente no circuito, a queda de tensão no resistor é \(V_{1}\), no capacitor \(V_{2}\) e no indutor \(V_{3}\), dadas por
$$
V_{1}=iR,\;\;V_{2}=\frac{1}{C}q,\;\;V_{3}=L\frac{di}{dt},
$$
onde \(q\) é a carga armazenada no capacitor. Pela lei de Kirchoff a soma das voltagens é a voltagem total, ou seja
$$
L\frac{di}{dt}+Ri+\frac{1}{C}q=E(t).
$$
Sabendo que a corrente no circuito é a variação no tempo da carga que flui temos que
$$
i=\frac{dq}{dt}
$$
e, portanto,
$$
L\frac{d^{2}q}{dt^{2}}+R\frac{dq}{dt}+\frac{1}{C}q=E(t),
$$
que é uma equação diferencial idêntica àquela obtida para oscilações mecânicas. Como exemplo da analogia a equação característica do sistema não forçado, \(E(t)=0\), é \(Lr^{2}+Rr+1/C=0.\) Então o circuito é superamortecido se \(R^{2}-4L/C\gt 0,\) é subamortecido se \(R^{2}-4L/C\lt 0\) e crítico se \(R^{2}-4L/C=0.\) Todas as características dos sistemas mecânicas estão presentes nos circuitos RLC, inclusive batimentos e ressonâncias.
As equações diferenciais de primeira ordem mais simples aparecem sob a forma diretamente integrável. São equações na forma
$$
h(y)y^{\prime}=f(x).
$$
Para resolvê-las tratamos provisoriamente as variáveis \(x\) e \(y\) como sendo ambas independentes. A solução da equação é, exatamente, a descrição da dependência entre \(x\) e \(y\). Primeiro reescrevemos a equação (1) como
$$
h(y)dy=f(x)dx
$$
e em seguida integramos os dois lados da equação
$$
\int h(y)dy=\int f(x)dx.
$$
Destas integrações resulta a solução sob forma implícita ou explícita, sempre envolvendo uma constante de integração. De posse desta técnica vamos tratar novamente o primeiro exemplo resolvido na Introdução.
Exemplo 1. Que função é idêntica à sua derivada? Vamos proceder à separação de variáveis
$$
y^{\prime}=y\Rightarrow\frac{dy}{y}=dx\Rightarrow\int\frac{dy}{y}=\int dx.
$$
y= C ex
Integrando a última equação obtemos
$$
\ln y=x+c,
$$
onde \(c\) é uma constante de integração. Para obter uma solução explícita para \(y(x)\), o que é sempre interessante quando possível, tomamos a exponencial de ambos os lados
$$
e^{\ln y}=e^{x+c}\Rightarrow y(x)=Ce^{x},
$$
onde renomeamos a constante \(e^{c}=C\) para obter uma notação mais enxuta.
A solução encontrada, \(y(x)=Ce^{x}\), é a chamada solução geral do problema. Observe que ela é, para sermos mais exatos, uma família de infinitas soluções, dada a liberdade de se escolher infinitos valores para \(C\). Considerando que \(C\) e \(c\) são ambas constantes desconhecidas não é essencial descrever como as duas se relacionam. Na verdade, na maior parte dos problemas, temos a liberdade para renomear a constante de integração de forma a obter uma solução final sob forma compacta e de fácil utilização.
Exemplo 2. Vamos resolver uma equação separável, desta vez acrescentando uma condição de contorno, o que será usada para determinar um valor para a constante de integração. Considere o problema de contorno para a equação diferencial separável:
$$
xy^{\prime}+y=0,\,\,\,y(1)=1.
$$
Primeiro separamos a equação e a integramos
$$
xdy=-ydx\Rightarrow\frac{dy}{y}=-\frac{dx}{x}\Rightarrow\int\frac{dy}{y}=-\int\frac{dx}{x}
$$
o que resulta em
$$
\ln y=-\ln x+c.
$$
Tomando a exponencial dos dois lados obtemos a solução geral:
$$
y(x)=e^{-\ln x+c}=e^{-\ln x}e^{c}=C(e^{\ln x})^{-1}=Cx^{-1}=\frac{C}{x}.
$$
Para satisfazer a condição de contorno ajustamos a constante C
$$
y(1)=\frac{C}{1}=1\Rightarrow C=1.
$$
A solução particular é, portanto,
$$
y(x)=\frac{1}{x}.
$$
É sempre interessante proceder à verificação da solução encontrada. Como
$$
y(x)=\frac{C}{x}\Rightarrow y^{\prime}=-\frac{C}{x^{2}}.
$$
Substituindo na equação (2)
$$
xy^{\prime}+y=x\left(-\frac{C}{x^{2}}\right)+\frac{C}{x}=0,
$$
o que mostra estar correta a solução encontrada.
Algumas Aplicações
Uma grande quantidade de problemas de natureza prática e aplicada podem ser resolvidos com a técnica vista até este ponto.
Decaimento radioativo Uma substância radioativa se decompõe, transformando-se em outra substância, em uma taxa proporcional à quantidade de massa presente. Matematicamente representamos esta afirmação por meio da equação diferencial
$$
\frac{dm}{dt}=km,
$$
onde \(m(t)\) é a quantidade de massa da substância radioativa para cada instante \(t\). A constante \(k\) é uma característica de cada material, sendo que, quanto maior o seu valor, mais radioativa é a substância e mais rapidamente ela se decompõe. Ela é uma constante negativa, indicando que a quantidade do material original está diminuindo. A meia-vida da substância é definida como o tempo gasto para que metade da substância se decomponha. Pode-se verificar em laboratório que a meia-vida da rádio é de 1.590 anos. Após 100 anos de decomposição quanto restará de rádio na amostra? A equação diferencial (3) é uma equação separável:
$$
\frac{dm}{m}=kdt\Rightarrow m(t)=m_{0}e^{kt},
$$
onde \(m_{0}\), a constante de integração, é a quantidade da substância em \(t=0\). Denotando a meia-vida por \(t_{m}\), temos por definição
$$
m(t_{m})=\frac{1}{2}m_{0}
$$
e, portanto
$$
e^{kt_{m}}=\frac{1}{2}.
$$
Tomando o logaritmo dos dois lados temos
$$
kt_{m}=\ln 0,5
$$
e dai, já que conhecemos a meia-vida, podemos calcular o valor de \(k\), para o rádio
$$
k=\frac{\ln0,5}{t_{m}}=\frac{\ln0,5}{1590}\text{anos}^{-1}\approx-4,36\times10^{-4}\text{anos}^{-1}.
$$
Observe que esta constante tem unidades de \(\text{(tempo)}^{-1}\), condição necessária para que o argumento da exponencial seja adimensional. Com isto descobrimos que, para qualquer instante \(t\) (medido em anos), a quantidade de massa do material radioativo é
$$
m(t)=m_{0}e^{-4,36\times10^{-4}t}.
$$
Ao final de \(100\) anos de decomposição teremos
$$
m(100)=m_{0}e^{-4,36\times10^{-4}\times100}\approx0,957m_{0},
$$
restando, portanto \(\approx95,7\%\) de rádio presente na amostra original. Este é basicamente o método usado para determinação de idade em fósseis e artefatos antigos.
Exemplo 3. Crescimento populacional: Uma cultura de bactérias, por exemplo, cresce com taxa proporcional ao número de bactérias presentes a cada instante. Denotando por \(N(t)\) este número a população deve satisfazer a equação
$$
\frac{dN(t)}{dt}=kN(t),
$$
onde \(k\) é uma constante positiva, para indicar crescimento da população. Esta constante depende do tipo da população considerada e deve ser medida empiricamente. A solução para este problema é
$$
N(t)=N_{0}e^{kt},
$$
onde \(N_{0}\) é a população inicial. Suponha que a observação tenha indicado que, medindo o tempo em horas, a experimentação tenha indicado que, após 1 dia, a população inicial terá se multiplicado por \(1000\), ou seja
$$
N(24)=1000N_{0}.
$$
Podemos então determinar o valor de \(k\)
$$
e^{24k}=1000\Rightarrow24k=\ln1000\approx6,91\Rightarrow k\approx2,88\times10^{-1}\text{horas}^{-1}.
$$
Ao final de \(10\) dias (ou seja, \(240\) horas) existirão
$$
N(240)=N_{0}\exp(240\times2,88\times10^{-1})\approx10^{30}N_{0}
$$
bactérias, um número muito superior que o número inicial! Evidentemente nenhuma população pode crescer indefinidamente nesta taxa exponencial o que indica que este nosso primeiro modelo é demasiamente simplista. Um modelo mais preciso para descrever estas populações foi proposto por Verhuslt, um biólogo e matemático que sugeriu a seguinte equação:
$$
\frac{dN}{dt}=N(a-bN),
$$
onde \(a\) é uma constante indicadora do número de nascimentos e \(b\) do número de óbitos. Esta é também uma equação separável
$$
\frac{dN}{N(a-bN)}=dt
$$
(1) Veja o Apêndice para uma revisão sobre as frações parcias.
que pode ser integrada pelo método das frações parciais1. Notando que
$$
\frac{1}{N(a-bN)}=\frac{1}{a}\frac{1}{N}+\frac{b}{a}\frac{1}{a-bN},
$$
ou ainda
$$
\ln\left(\frac{N}{a-bN}\right)=at+ac\Rightarrow\frac{N}{a-bN}=c_{1}e^{at}.
$$
Escrevendo \(N(0)=N_{0}\) e resolvendo para obter N explicitamente temos
$$
N(t)=\frac{aN_{0}}{bN_{0}+(a-bN_{0})e^{-at}}.
$$
Exercícios 1
Resolva as seguintes equações diferenciais. Considere \(m,\,\,n\) e \(\omega\) constantes.
1. \(y^{\prime}+y=0\)
2. \(y^{\prime}=my/x\)
3. \(y^{\prime}=x^{2}/y\)
4. \(mxy^{\prime}=ny\,\,\,(m\neq0)\)
5. \(yy^{\prime}=\cos^{2}\omega x\)
6. \(y^{\prime}=1+x+y^{2}+xy^{2}\)
7. \(xyy^{\prime}=2(y+1)\)
8. \(y^{\prime}+my+n=0\)
9. \(y^{2}y^{\prime}+x^{2}=0\)
10. \(y^{\prime}+ky=0, \,\,\, y(0)=3\)
11. \(xy^{\prime}=3y,y(2)=-8\)
12. \(y^{\prime}=4x^{3}e^{-y},\,\,\,y(1)=0\)
13. \(xy^{\prime}+y=0\), \(y(1)=1\)
14. \(xyy^{\prime}=y+3,\,\,\,y(1)=0\)
15. \(y^{\prime}+y=0\)
16. \(y^{\prime}=my/x\)
17.(Crescimento exponencial) Em uma cultura de levedo a taxa de transformação por unidade de tempo do fermento ativo é proporcional à quantidade do fermento presente, \(y(t)\). Se \(y(t)\) duplica a cada 30 minutos, quanto fermento haverá depois de 8 horas?
Algumas soluções
2. \(y=cx^{m}\)
4. \(y=cx^{n/m}\)
5. \(y^{2}=x+\frac{1}{2\omega}\text{ sen }\,2\omega x\)
9. \(y^{3}+x^{3}=c\)
10. \(3e^{-kx}\)
13. \(y=1/x\)
Equações Redutíveis à Forma Separável
Pode ocorrer que uma equação diferencial de primeira ordem não seja diretamente separável mas possa ser transformada em uma equação separável por meio de uma substituição apropriada de variáveis. A escolha da substituição nem sempre é simples e, em alguns casos, pode ser necessário um certo trabalho de tentativas e erros para se encontrar a escolha adequada. Mostraremos através de um exemplo o funcionamento do método.
Exemplo 4. Resolva a equação
$$
xy^{\prime}=x+y.
$$
Dividindo os dois lados por \(x\) obtemos
$$
y^{\prime}=1+\frac{y}{x}
$$
o que sugere, como discutiremos a seguir, o uso da seguinte nova variável
$$
u=\frac{y}{x}.
$$
Necessitaremos também conhecer \(y^{\prime}\) em termos de \(u\). Para isto observamos que \(y=ux\) e, portanto, sua derivada é
$$
y^{\prime}=u^{\prime}x+u.
$$
Substituimos \(y\) e \(y^{\prime}\) na equação (4) para obter
$$
u^{\prime}x+u=1+u\Rightarrow du=\frac{dx}{x},
$$
que, após integração, resulta em
$$
u=\ln x+C.
$$
Retornando à variável \(y\) inicial
$$
y=ux=xlnx+Cx,
$$
que é a solução procurada.
No exemplo acima, como acontece em muitos casos, foi possível escrever a equação diferencial sob a forma
$$
y^{\prime}=g\left(\frac{y}{x}\right).
$$
Neste caso, a escolha
$$
u=\frac{y}{x},\,\,\,y^{\prime}=u^{\prime}x+u
$$
transforma a equação diferencial em
$$
u^{\prime}x+u=g(u)
$$
que é separável:
$$
\frac{du}{g(u)-u}=\frac{dx}{x}.
$$
No entanto esta não é a única mudança de variáveis possível, como veremos nos exemplos a seguir.
Exemplo 5. Para resolver a seguinte equação diferencial
$$
(x+1)(y^{\prime}-1)=2(y-x)
$$
introduziremos a nova variável \(u=y-x\). Neste caso temos
$$
y=u+x\Rightarrow y^{\prime}=u^{\prime}+1.
$$
Substituindo na equação (5) e fazendo os devidos cancelamentos temos
$$
(x+1)u^{\prime}=2u\Rightarrow\frac{du}{u}=\frac{2dx}{x}.
$$
Integrando obtemos
$$
ln\,u=2\ln(x+1)+c.
$$
Como uma revisão da álgebra envolvida, faremos com algum detalhe as etapas finais deste problema. Tomando a exponencial dos dois lados da equação anterior temos
$$
u=e^{2\ln(x+1)+c}=C(e^{\ln(x+1)})^{2}=C(x+1)^{2},
$$
onde denotamos \(C=e^{c}\). A solução é
$$
y=C(x+1)^{2}+x,
$$
depois que retornamos para a variável \(y=u+x\).
Exemplo 6. A equação diferencial
$$
xy^{\prime}=e^{-yx}-y
$$
pode ser resolvida através da mudança de variáveis \(y\rightarrow v\) onde \(v=xy\). Com esta escolha temos \( y=\frac{v}{x}\) e, consequentemente,
$$
y^{\prime}=\frac{v^{\prime}x-v}{x^{2}}\Rightarrow xy^{\prime}=\frac{v^{\prime}x-v}{x}
$$
Substituindo na equação (6) temos
$$
\frac{v^{\prime}x-v}{x}=e^{-v}-\frac{v}{x}\Rightarrow v^{\prime}=e^{-v}\Rightarrow e^{v}dv=dx.
$$
Podemos agora integrar os dois lados da equação para obter
$$
e^{v}=x+c\Rightarrow v=\ln(x+c).
$$
Dai encontramos
$$
y(x)=\frac{1}{x}\ln(x+c),
$$
a solução de (6).
Exemplo 7. A equação diferencial
$$
y^{\prime}=\frac{y^{2}+2xy}{x^{2}}=\frac{y^{2}}{x^{2}}+\frac{2y}{x}
$$
pode ser transformada em separável por meio da substituição \(y\rightarrow u\) onde \(u=y/x\). Com esta escolha temos
$$
y=ux\Rightarrow y^{\prime}=u^{\prime}x+u,
$$
e a equação diferencial se torna
$$
u^{\prime}x=u^{2}+u.
$$
Separando as variáveis \(u\) e \(x\) e integrando obtemos
$$
\int\frac{du}{u^{2}+u}=\int\frac{dx}{x}.
$$
Pelo método das frações parciais (consulte o Apêndice para uma revisão sobre as frações parciais) podemos escrever
$$
\frac{1}{u(u+1)}=\frac{1}{u}-\frac{1}{u+1},
$$
e, portanto, a primeira integral pode ser avaliada:
$$
\int\frac{du}{u(u+1)}=\int\left(\frac{1}{u}-\frac{1}{u+1}\right)du=lnu-\ln(u+1)=\ln\left(\frac{u}{u+1}\right).
$$
A solução do problema é dada por
$$
\ln\left(\frac{u}{u+1}\right)=\ln x+c.
$$
Para explicitar a função \(u(x)\) tomamos a exponencial de ambos os lados,
$$
\frac{u}{u+1}=Cx,
$$
onde \(C=e^{c}\), ou, em termos da função \(y(x)\) original,
$$
Cx=\frac{y}{y+x}.
$$
Resolvendo para \(y\) obtemos
$$
y(x)=\frac{Cx^{2}}{1-Cx},
$$
que é a solução de (7).
Exercícios 2
Resolva as equações abaixo. Use a transformação \(u=y/x,\) quando não houver outra sugestão.
Para a técnica que se segue é conveniente relembrar o conceito de diferencial de uma função de duas variáveis \(\psi(x,y)\). Para obter uma notação mais compacta usaremos a convenção de denotar derivadas parciais como
$$
\frac{\partial\psi}{\partial x}=\psi_{x},\,\,\,\frac{\partial\psi}{\partial y}=\psi_{y},\,\,\,\frac{\partial^{2}\psi}{\partial x\partial y}=\psi_{yx},
$$
e assim sucessivamente. Com esta notação a diferencial de uma função de duas variáveis pode ser escrita como
$$
d\psi=\frac{\partial\psi}{\partial x}dx+\frac{\partial\psi}{\partial y}dy=\psi_{x}dx+\psi_{y}.
$$
A diferencial representa uma medida de como a função \(\psi\) varia quando suas duas variáveis \(x\) e \(y\) variam infinitesimalmente de modo independente. Em vista desta definição vemos que a diferencial só é nula se a função \(\psi\) for uma constante, ou seja,
$$
d\psi=0\Rightarrow\psi_{x}=0,\,\,\,\psi_{y}=0\Rightarrow\psi=C,
$$
onde \(C\) é uma constante arbitrária.
Exemplo 8. A diferencial da função \(\psi(x,y)=x^{3}y^{2}+\text{ sen }\,x\) é
$$
d\psi=(3x^{2}y^{2}+\cos x)dx+(2x^{3}y)dy
$$
pois suas derivadas parcias são
$$
\psi_{x}=3x^{2}y^{2}+\cos x,\,\,\,\psi_{y}=2x^{3}y.
$$
Assim conhecemos desde já a solução da equação diferencial
$$
(3x^{2}y^{2}+\cos x)+(2x^{3}y)y^{\prime}=0,
$$
que é
$$
x^{3}y^{2}+\text{ sen }\,x=C.
$$
Considere agora uma equação diferencial que se apresenta sob a forma
$$
M(x,y)+N(x,y)y^{\prime}=0.
$$
Podemos reescrevê-la como
$$
M(x,y)dx+N(x,y)dy=0.
$$
Se pudermos identificar o lado esquerdo da expressão acima com a diferencial de alguma função \(\psi\) saberemos que \(d\psi=0\) e, portanto \(\psi=C\) é a solução procurada. Esta identificação é possível se existir uma função \(\psi\) tal que
$$
d\psi=Mdx+Ndy,
$$
e, portanto,
$$
M=\frac{\partial\psi}{\partial x}\equiv\psi_{x},\,\,\,\,N=\frac{\partial\psi}{\partial y}\equiv\psi_{y}.
$$
Podemos descobrir se esta função existe ou não utilizando a seguinte propriedade: se uma função de duas variáveis \(\psi\) e suas derivadas \(\psi_{x},\psi_{y}\), \(\psi_{xy}\) e \(\psi_{yx}\) são contínuas então
$$
\frac{\partial^{2}\psi}{\partial x\partial y}=\frac{\partial^{2}\psi}{\partial y\partial x}.
$$
Em notação mais compacta temos
$$
\psi_{xy}=\psi_{yx},
$$
ou, em termos das funções \(M\) e \(N\) definidas acima,
$$
M_{y}=N_{x}.
$$
(2) Veremos, na próxima seção, que em alguns casos é possível transformar uma equação não exata em uma diferencial exata.
Se a última identidade não é verdadeira a equação não é uma diferencial exata e o método que agora estudamos não é adequado para a sua solução(2). Por outro lado, se a identidade \(M_{y}=N_{x}\) é verdadeira, passamos a procurar a função \(\psi\) cuja diferencial é nula. Para isto usamos
$$
M=\frac{\partial\psi}{\partial x}
$$
que permite encontrar \(\psi\) \((x,y)\) por integração na variável \(x\),
$$
\psi(x,y)=\int M(x,y)dx+h(y).
$$
A função fica conhecida exceto pela existência do termo \(h\) que depende apenas da variável \(y\). Observe que \(h(y)\) faz o papel de uma constante arbitrária em relação à derivação e integração na variável \(x\). Usamos agora a relação \(N=\psi_{x}\). Derivando a expressão (10) em relação à \(y\) devemos obter \(N\).
$$
N=\frac{\partial\psi}{\partial y}=\frac{\partial}{\partial y}\int M(x,y)dx+h^{\prime}(y).
$$
que é uma equação diferencial de primeira ordem,
$$
h^{\prime}=N-\int M_{y}dx,
$$
que nos permite determinar a função \(h\) que é a parte que falta em nossa solução \(\psi\). Observe que o termo de integração \(h\) é de fato função de \(y\) somente pois, derivando a mesma expressão em relação a \(x\) obtemos
$$
\frac{\partial}{\partial x}\left(\frac{\partial h}{\partial y}\right)=N_{x}-M_{y}=0,
$$
uma vez que a equação já foi testada como sendo exata! Portanto a solução de (10) é \(\psi(x,y)=C,\) onde \(C\) é uma constante e
$$
\psi(x,y) =\int M(x,y)dx+\int\left[N(x,y)-\int M_{y}dx\right]dy.
$$
Exemplo 9. Encontre a curva que passa pelo ponto \((1,0)\) e tem inclinação \(y^{\prime}=(1-x)/(1+y)\).
Vamos resolver este problema de valor de contorno pelo método da diferencial exata. Para isto escrevemos a equação sob a forma \(Mdx+Ndy=0\), obtendo
$$
(x-1)dx+(1+y)dy=0.
$$
ou seja, verificamos que a equação é uma diferencial exata. Para encontrar \(\psi\) fazemos
$$
\psi=\int Mdx+h(y)=\int(x-1)dx+h(y)=\frac{x^{2}}{2}-x+h(y).
$$
Podemos obter a função \(h(y)\), até aqui desconhecida, derivando em \(y\) a expressão acima e usando \(\psi_{y}=N\).
$$
h^{\prime}(y)=1+y\Rightarrow h(y)=\int(1+y)dy=\left(\frac{y^{2}}{2}+y\right).
$$
Assim encontramos a função \(\psi\) completa. Sabemos que ela é uma constante porque possui diferencial nulo, ou seja
$$
\psi=\frac{x^{2}}{2}-x+\frac{y^{2}}{2}+y=c^{\prime},
$$
ou seja,
$$
x^{2}-2x+y^{2}+2y=c
$$
onde \(c=2c^{\prime}\). Para que a curva passe pelo ponto \((1,0)\) devemos inserir \(x=1\) e \(y=0\) na expressão acima, obtendo um valor para a constante \(c\),
$$
c=1-2=-1\Rightarrow x^{2}+y^{2}-2x+2y+1=0.
$$
Para escrever esta solução em uma forma mais familiar podemos completar quadrados,
$$
(x-1)^{2}+(y+1)^{2}=1,
$$
e descobrimos que o problema do exemplo 9 tem como solução a circunferência com centro em \((1,-1)\) e raio \(1\). A equação (12) é um exemplo de solução implícita para uma equação diferencial. Derivando implicitamente3 esta solução obtemos
$$
2(x-1)+2(y+1)y^{\prime}=0\Rightarrow y^{\prime}=\frac{1-x}{1+y},
$$
o que confirma que essa é a solução correta para o problema!
Exemplo 10. Verifique se a equação diferencial a seguir é exata e, em caso afirmativo, resolva a equação
$$
(e^{x}\text{ sen }\,y-2y\text{ sen }\,x)+(e^{x}\cos y+2\cos x)y^{\prime}=0.
$$
Reescrevemos a equação como
$$
(e^{x}\text{ sen }\,y-2y\text{ sen }\,x)dx+(e^{x}cosy+2\cos x)dy=0,
$$
e realizamos o teste para descobrir se a equação é exata ou não. Neste caso temos
$$
M= e^{x}\text{ sen }\,y-2y\text{ sen}\,x \Rightarrow M_{y}= e^{x}\cos y-2\text{ sen }\,x
$$
$$
N= e^{x}\cos y+2\cos x \Rightarrow N_{x}= e^{x}\cos y-2\text{ sen}\,x,
$$
de onde vemos que \(M_{y}=N_{x}\) e que a equação é exata. Neste caso existe uma função \(\psi\) que satisfaz
$$
d\psi=\frac{\partial\psi}{\partial x}dx+\frac{\partial\psi}{\partial y}dy=Mdx+Ndy,
$$
sendo que \(d\psi=0\) decorre da equação (13). Para encontrar esta função integramos \(\psi_{x}=M\),
$$
\psi=\int Mdx+h(y)=\int(e^{x}\text{ sen }\,y-2y\text{ sen }\,x)dx+h(y)=
$$
$$
=e^{x}\text{ sen }\,y+2y\cos x+h(y).
$$
Como \(\psi_{y}=N\) então derivamos (14),
$$
\psi_{y}=e^{x}\cos y+2\cos x+h^{\prime}(y)=e^{x}\cos y+2\cos x,
$$
de onde obtemos
$$
h^{\prime}(y)=0\Rightarrow h(y)=c^{\prime},
$$
uma constante. A solução é obtida de
$$
d\psi=0\Rightarrow\psi=c,
$$
e, portanto,
$$
e^{x}\text{ sen }\,y+2y\cos x=c.
$$
Note que \(y=0\) também é solução da equação (13).
Exercícios 3
Determine as diferenciais das funções:1. \(\psi=x^{2}+2xy^{2}-\text{ sen }\,(xy)\)
2. \(\psi=e^{x}\cos y+(x-y)^{2}\)
3. \(\psi=\ln(x^{2}+y^{2})-x^{3}+y^{3}\)
Verifique se as seguintes equações são diferenciais exatas e, se forem, determine as soluções:
1. \(\psi=[2x+2y^{2}-y\cos(xy)]dx+[4xy-x\cos(xy)]dy\)
4. \(x^{2}+4y^{2}=c\)
6. \(y=x+c(x+1)^{2}\)
8. Não é exata.
9. \(y=c/(x^{3}+\ln x)\)
10. \(e^{xy}+y^{2}=c\)
12. \(1/9(x-3)^{2}+(y-1)^{2}=1\)
14. \(y=\tan x\)
Fatores Integrantes
Pode ocorrer que uma equação \(M(x,y)dx+N(x,y)dy=0\) não seja uma diferencial exata mas possa ser transformada em exata atraves da multiplicação por um fator \(\mu(x,y)\neq0\). Neste caso buscamos encontrar o fator \(\mu\) de forma que \(\mu M(x,y)dx+\mu N(x,y)dy=0 \) seja uma diferencial exata. \(\mu(x,y)\) é denominado de fator integrante.
Exemplo 11. A diferencial \(xdy-ydx=0 \) não é exata pois
$$
M= -y;\,\,\, N= x \Rightarrow M_{y}= -1 \,\,\, N_{x}= 1 \Rightarrow M_{y}\neq N_{x}.
$$
Multiplicando a expressão (15) por
$$
\mu(x,y)=\frac{1}{x^{2}}
$$
ela se transforma em uma diferencial exata pois a diferencial de \(d(y/x)\) é exatamente
$$
d\left(\frac{y}{x}\right)=\frac{xdy-ydx}{x^{2}}=\mu(xdy-ydx).
$$
A solução da equação acima é, portanto,
$$
\frac{y}{x}=a\Rightarrow y=ax,
$$
que é a equação de uma reta com inclinação indeterminada \(a\) e que passa pela origem.
Naturalmente precisamos de uma técnica para encontrar o fator integrante \(\mu\). Para isto voltamos ao problema geral. Queremos examinar sob que situação existe um fator \(\mu\) tal que
$$
\mu(x,y)M(x,y)dx+\mu(x,y)N(x,y)dy=0
$$
seja uma diferencial exata. Realizando o teste, tal como fizemos na seção anterior, vemos que (16) é exata se
$$
(\mu M)_{y}=(\mu N)_{x}.
$$
Usando a regra da derivada do produto temos
$$
\mu_{y}M+\mu M_{y}=\mu_{x}N+\mu N_{x}.
$$
A condição para que (16) seja exata é
$$
M\mu_{y}-N\mu_{x}+(M_{y}-N_{x})\mu=0,
$$
(4) Observe que o caso em que \(\mu\) é função de \(y\) apenas é análogo.
uma equação diferencial parcial de difícil solução, no caso mais geral. Não é raro, no entanto, que se possa tomar um fator integrante função de apenas uma das variáveis, o que torna o tratamento do problema bem mais simples. Suponha que \(\mu\) é função de \(x\) apenas4. Neste caso, \(\mu_{y}=0\) e a expressão (17) é uma equação ordinária separável para \(\mu\).
$$
\frac{d\mu}{dx}=\frac{M_{y}-N_{x}}{N}\mu.
$$
Observe que o coeficiente de \(\mu\) na equação acima deve ser uma função de \(x\) apenas. Caso contrário a equação (18) não é válida. Desta forma podemos encontrar o fator integrante resolvendo a equação (17), ou seja,
$$
\mu(x)=C\exp\left[\int\frac{M_{y}-N_{x}}{N}dx\right].
$$
Agora \(\mu_{x}=0\) e a expressão (17) nos leva à expressão:
$$
\frac{d\mu}{dy}=\frac{N_{x}-M_{y}}{M}\mu,
$$
com solução
$$
\mu(y)=C\exp\left[\int\frac{N_{x}-M_{y}}{M}dy\right].
$$
Em qualquer um dos casos a constante \(C\) acima não afeta a solução da equação diferencial e, por isto, tomaremos sempre \(C=1\). Encontrado \(\mu\) multiplicamos a equação diferencial por este fator obtendo uma diferencial exata
$$
\mu Mdx+\mu Ndy=\bar{M}dx+\bar{N}dy=0,
$$
onde denotamos \(\bar{M}=\mu M\) e \(\bar{N}=\mu N\), e prosseguimos da mesma forma feita na seção anterior. Embora a nova equação seja uma diferencial exata por construção, é útil verificar que
$$
\bar{M}_{y}=\bar{N}_{x}.
$$
Em seguida encontramos \(\psi\), usando \(\psi_{x}=\bar{M}\),
$$
\psi(x,y)=\int\bar{M}dx+h(y)
$$
e a relação \(\psi_{y}=\bar{N}\) para determinar \(h(y)\) na equação diferencial
$$
\psi_{y} =\frac{\partial}{\partial y}\int\bar{M}dx+h^{\prime}(y).
$$
Exemplo 12. A seguinte equação diferencial,
$$
4xydx+\frac{3}{2}x^{2}dy=0,
$$
não é uma diferencial exata pois
$$
M=4xy\;\;M_{y}=4x;\;\;\;N=\frac{3}{2}x^{2},\; N_{x}=3x \Rightarrow M_{y}\neq N_{x}.
$$
Vamos então determinar o fator integrante para transformá-la em uma equação exata. Este fator deve satisfazer a equação
$$
\mu_{x}=\frac{M_{y}-N_{x}}{N}\mu\Rightarrow\mu_{x}=\frac{2}{3x}\mu,
$$
que é uma equação diferencial separável e de fácil solução,
$$
\frac{1}{\mu}d\mu=\frac{2}{3x}dx,
$$
A nova equação diferencial, que deve ser uma diferencial exata, é
$$
x^{2/3}\left(4xydx+\frac{3}{2}x^{2}dy\right)=0.
$$
Usando \(\bar{M}=\mu M\) e \(\bar{N}=\mu N\) observamos que agora temos, de fato, uma diferencial exata pois
$$
\bar{M}=4x^{5/3}y,\;\; \bar{M}_{y}=4x^{5/3}; \;\;\;\bar{N}=\frac{3}{2}x^{8/3},\;\;\bar{N}_{x}=4x^{5/3}\Rightarrow\bar{M}_{y}=\bar{N}_{x}.
$$
Para encontrar \(\psi\) prosseguimos como na seção anterior:
$$
\psi=\int\bar{M}dx+h(y)=4y\int x^{5/3}dx+h(y)=\frac{3}{2}{yx}^{8/3}+h(y),
$$
Dai, já que \(d\psi=0\), sabemos que \(\psi=c_{2}\), uma outra constante e, portanto
$$
\psi=c_{2}=\frac{3}{2}yx^{8/3}+c_{1}\Rightarrow y=Cx^{-8/3},
$$
onde \(C=2(c_{1}-c_{2})/3.\) Observe que este exemplo foi feito desta forma, procurando-se um fator integrante para transformar a equação em uma diferencial exata, como um exercício. É claro que a mesma solução poderia ser encontrada de modo mais simples notando-se que a equação em questão é diretamente separável:
$$
4xydx+\frac{3}{2}x^{2}dy=0\Rightarrow y^{\prime}=-\frac{8y}{3x},
$$
Exemplo 13. Dada a equação diferencial
$$
\frac{y}{x}+2y^{\prime}\ln x=0,
$$
verificamos que esta não é uma diferencial exata. Para este problema temos
$$
M=\frac{y}{x},\;\; M_{y}=\frac{1}{x};\;\;\;N=2\ln x,\;\;N_{x}=\frac{2}{x} \Rightarrow M_{y}\neq N_{x}.
$$
Vamos procurar, neste caso, um fator integrante dependente de \(y\) apenas. Uma solução dependente de \(x\) é também possível mas um pouco mais complicada, como o leitor pode verificar. Temos então
$$
\mu_{y}=\frac{N_{x}-M_{y}}{M}\mu=\frac{\mu}{y}
$$
com solução \(\mu=y\), a menos de uma constante multiplicativa. A equação diferencial multiplicada por \(\mu\) é
$$
\frac{y^{2}}{x}dx+2y\ln xdy=0,
$$
que é uma diferencial exata pois
$$
\bar{M}=y^{2}/x,\;\; \bar{M}_{y}=2y/x;\;\;\;\bar{N}=2y\ln x,\;\;\bar{N}_{x}=2y/x \Rightarrow\bar{M}_{y}=\bar{N}_{y}.
$$
Temos então que
$$
\psi=\int\bar{M}dx+h(y)=y^{2}\ln x+h(y),
$$
3. \( \mu=\frac{1}{x^{2}} ,\,\,\, \text{ sen } y=cx\),
5. \( \mu=\frac{1}{y^{3}},\,\,\,y=c\sqrt{x}\),
6. \( \mu=\frac{1}{x},\,\,\,y=\frac{c}{\ln x}\),
7. \( \mu=e^{x},\,\,\,e^{x}\text{ sen }\,y=c\),
9. \( \mu=x,\,\,\,x^{2}y=-4\),
10. \(\mu=e^{x},\,\,\,e^{x}{cosy}=-1\).
Exercício Resolvido:
2. Temos que \(M_{y}=1\) e \(N_{x}=-1\) portanto a diferencial não é exata. O fator integrante satisfaz
$$
\mu_{x}=\frac{(My-Nx)}{N}\mu\Rightarrow\frac{d\mu}{\mu}=-\frac{2dx}{x+1},
$$
que pode ser diretamente integrada
$$
\int\frac{d\mu}{\mu}=-\int\frac{2dx}{x+1}\Rightarrow\ln\mu=-2\ln(x+1).
$$
Tomando-se a exponencial dos lados da expressão acima temos \(\mu=(x+1)^{-2}\). Multiplicada por este fator integrante a equação se torna uma diferencial exata pois
$$
\bar{M}=\frac{y+1}{(x+1)^{2}},\,\,\,\overline{M_{y}}=\frac{1}{(x+1)^{2}},\bar{\,\,\,N}=-\frac{1}{(x+1)^ {}},\bar{\,\,\,N}_{x}=\bar{M}_{y}.
$$
Usamos agora a função \(\psi\) encontrada acima e sua derivada, \(\psi_{x}=\bar{M}\), para encontrar \(h(x)\),
$$
\frac{y}{(x+1)^{2}}+h'(x)=\frac{y+1}{(x+1)^{2}},
$$
ou seja
$$
h^{\prime}=\frac{1}{(x+1)^{2}}\Rightarrow h=-\frac{1}{x+1}.
$$
Sabemos agora que
$$
\psi(x,y)=-\frac{y+1}{x+1}=c,
$$
ou ainda \(y=C(x+1)-1\). Observe que, para encontrar \(\psi\), integramos primeiro em \(y\) e depois em \(x\), para encontrar \(h\). A ordem inversa poderia ter sido também escolhida e, neste caso, com o mesmo nível de dificuldade. Pode ocorrer, no entanto, que uma das abordagens leve a integrais mais simples ou diretas.
Equações Diferenciais Lineares de Primeira Ordem
Com as técnicas que já estudamos temos condições para resolver todas as equações lineares de primeira ordem. Sob a forma mais geral elas podem ser escritas como
$$
y^{\prime}+f(x)y=r(x).
$$
Se \(r(x)=0\) a equação é dita homogênea. Já sabemos resolver, em princípio pelo menos, todas as equações homogêneas por separação de variáveis
$$
y^{\prime}+f(x)y=0\Rightarrow\frac{dy}{y}=-f(x)dx.
$$
Integrando-se esta última chegamos a
$$
y(x)=Ce^{-\int f(x)dx}.
$$
Para a não homogênea, \(r(x)\neq0\), reescrevemos a equação (20) como
$$
(fy-r)dx+dy=0
$$
que não é uma diferencial exata, mas suscetível de ser transformada em exata por meio do fator integrante \(\mu\), obtido de
$$
\frac{d\mu}{dx}=\frac{M_{y}-N_{x}}{N}\mu=f(x)\mu\Rightarrow\frac{d\mu}{\mu}=f(x)dx
$$
cuja solução é
$$
\ln\mu=\int f(x)dx\Rightarrow\mu=\exp\left(\int f(x)dx\right),
$$
onde usamos a notação \(\exp(u)=e^{u}\) para a função exponencial. Denotamos, para obter uma expressão mais condensada,
$$
h(x)=\int f(x)dx,
$$
e multiplicamos a equação (21) pelo fator integrante \(\mu=e^{h}\)
$$
e^{h}(y^{\prime}+fy)=e^{h}r.
$$
Pelo teorema fundamental do cálculo \(h^{\prime}=f\) e
$$
\frac{d}{dx}(ye^{h})=y^{\prime}e^{h}+ye^{h}h^{\prime}=e^{h}(y^{\prime}+fy)=e^{h}r,
$$
e a expressão (23) pode ser escrita como
$$
\frac{d}{dx}(ye^{h})=e^{h}r
$$
que, após integração de ambos os lados resulta em
$$
ye^{h}=\int e^{h}rdx+c.
$$
Assim acabamos de conseguir uma solução geral para todas as equações lineares de primeira ordem,
$$
y(x)=e^{-h}\left[\int e^{h}rdx+c\right],
$$
onde \(h(x)=\int f(x)dx\).
Exemplo 14. A equação diferencial linear não homogênea
$$
y^{\prime}-y=e^{2x},
$$
pode ser por aplicação direta da fórmula (24). Iniciamos por identificar os termos usados na expressão(20). Temos
$$
f(x)=-1,\,\,\,r(x)=e^{2x}
$$
e, portanto
$$
h(x)=\int-dx=-x.
$$
Usando a equação (24) chegamos a
$$
y(x)=e^{x}\left[\int e^{-x}e^{2x}dx+c\right]=Ce^{x}+e^{2x},
$$
que é a solução geral.
Exemplo 15. O problema de valor inicial
$$
\frac{dy}{dx}=\frac{1}{e^{y}-x},\,\,\,y(1)=0.
$$
não é linear se entendido como um equação diferencial para a função \(y(x)\). No entanto podemos igualmente tratá-lo como uma equação para a função \(x(y)\) se invertermos, provisoriamente, o papel das variáveis \(x\) e \(y\). Para isto fazemos
$$
\frac{dx}{dy}=e^{y}-x
$$
A solução geral é
$$
x(y)=e^{-y}\left[\int e^{y}e^{y}dy+C\right]=Ce^{-y}+\frac{1}{2}e^{y}.
$$
Para satisfazer a condição de contorno \(y(1)=0\) substituimos \(x=1\) e \(y=0\) para determinar o valor da constante \(C\),
$$
1=Ce^{0}+\frac{1}{2}e^{0}=C+\frac{1}{2}\Rightarrow C=\frac{1}{2}.
$$
A solução particular é
$$
x(y)=\frac{1}{2}(e^{-y}+e^{y})=\cosh y.
$$
Caso seja necessário a obtenção de uma relação explícita para \(y(x)\) podemos usar a função inversa do cosseno hiperbólico,
$$
y(x)=\cosh^{-1}x=\ln\left(x+\sqrt{x^{2}-1}\right),
$$
válida para \(x\geq1\).
Algumas vezes uma equação diferencial pode ser manipulada e escrita sob forma mais simples, o que facilita a obtenção da solução. Isto é mostrado nos exemplos seguintes.
Exemplo 16. Vamos resolver a equação linear \(xy^{\prime}+y=\text{ sen }\,x\). Observamos primeiro que o lado esquerdo da equação é o diferencial de uma função
$$
d(xy)=(xy^{\prime}+y)dx.
$$
Portanto precisamos apenas integrar \(d(xy)=\text{ sen }\,xdx\) para obter
$$
xy=-\cos x+c
$$
ou ainda,
$$
y(x)=\frac{c}{x}-\frac{\cos x}{x}.
$$
Exemplo 17. Considere o problema de valor inicial
$$
x^{2}y^{\prime}+2xy-x+1=0,y(1)=0.
$$
Observe que
$$
\frac{d}{dx}(x^{2}y)=2xy+x^{2}y^{\prime}
$$
e, portanto, a equação diferencial pode ser reescrita como
$$
d(x^{2}y)=(x-1)dx.
$$
Integrando esta última expressão obtemos
$$
x^{2}y=\frac{1}{2}x^{2}-x+c
$$
ou seja, a solução geral é
$$
y(x)=\frac{c}{x^{2}}-\frac{1}{x}+\frac{1}{2}.
$$
Para satisfazer a condição inicial fazemos \(x=1\)
$$
y(1)=c-1+\frac{1}{2}=0\Rightarrow c=\frac{1}{2},
$$
e concluimos que
$$
y(x)=\frac{1}{2x^{2}}-\frac{1}{x}+\frac{1}{2}
$$
é a solução particular procurada.
Exercícios 5
Encontre as soluções gerais das equações lineares:
7. \( y=ce^{3x}-\frac{2}{13}\cos2x-\frac{3}{13}\text{ sen }\,2x\)
11. \( y=-\left(2x^{2}+x+\frac{1}{4}\right)\)
12. \( y=\frac{1}{2}(e^{-5x}+e^{x})\)
Variação de Parâmetros
Embora já tenhamos resolvido o problema geral das equações lineares de primeira ordem,
$$
y^{\prime}+f(x)y=r(x),
$$
vamos buscar uma solução alternativa para o mesmo problema denominada variação de parâmetros. Esta é uma técnica extremamente útil em diversas situações no estudo das equações diferenciais de segunda ordem e de ordens superiores e, por isto, convém aprendê-la desde já, dentro deste contexto mais simples. O método consiste em resolver primeiro a equação homogênea
$$
y^{\prime}+f(x)y=0,
$$
cuja solução, já obtida na seção anterior, passaremos a denominar de \(v\),
$$
v=Ce^{-\int f(x)dx},
$$
onde \(C\) é uma constante arbitrária. A variação de parâmetros consiste em permitir que \(C\), em vez de constante, seja uma função desconhecida, digamos
$$
C\rightarrow u(x).
$$
A solução da equação não homogênea será procurada sob a forma
$$
y(x)=u(x)v(x)
$$
que, após derivada e substituída na equação original deverá fornecer uma expressão para a determinação da função desconhecida \(u(x)\). Vamos então implementar este procedimento:
$$
y=uv\Rightarrow y^{\prime}=u^{\prime}v+uv^{\prime},
$$
onde foi usada a regra de derivação de um produto. Substituindo em (25) obtemos
$$
u^{\prime}v+uv^{\prime}+fuv=r,
$$
notando que a expressão dentro dos parênteses é nula porque \(v\) é solução da equação homogênea. Resta portanto resolver a equação separável
$$
u^{\prime}v=r\Rightarrow u^{\prime}=\frac{r}{v}\Rightarrow u=\int\frac{r}{v}dx+c.
$$
Como a solução da equação é \(y=uv\) temos então que
$$
y=v\left(\int\frac{r}{v}dx+c\right),
$$
a solução geral do problema. Claro que esta solução é idêntica à obtida descrita na seção anterior pelo método das diferenciais exatas. Basta notar que
$$
v=e^{-h}=\exp\left(-\int f(x)dx\right)
$$
é a solução da equação homogênea e portanto
$$
y(x)=e^{-h}\left[\int e^{h}rdx+c\right]
$$
é a solução geral da não homogênea, escrita da mesma forma que antes.
Exemplo 18. Resolva a equação diferencial
$$
xy^{\prime}+y+4=0.
$$
Reescrevemos a equação como
$$
y^{\prime}+\frac{y}{x}+\frac{4}{x}=0.
$$
A homogênea associada é
$$
y^{\prime}+\frac{y}{x}=0,
$$
que é separável e pode ser resolvida da seguinte forma:
$$
\frac{dy}{y}=-\frac{dx}{x}\Rightarrow\ln y=-\ln x+c\Rightarrow y=\frac{C}{x}.
$$
A variação de parâmetros consiste em tomar \(C\) como \(u\), uma função de \(x\). Procuramos então uma solução da forma
$$
y(x)=\frac{u}{x}
$$
cuja derivada, usando a regra de derivação de um quociente, é
$$
y^{\prime}=\frac{u^{\prime}x-u}{x^{2}}.
$$
Substituimos \(y\). \(y^{\prime}\) na equação diferencial para obter
$$
x\left(\frac{u^{\prime}x-u}{x^{2}}\right)+\frac{u}{x}+4=0\Rightarrow\frac{u^{\prime}x-u}{x}+\frac{u}{x}+4=0\Rightarrow u^{\prime}+4=0,
$$
ou seja
$$
u=-4x+c.
$$
A solução geral é
$$
y(x)=\frac{u}{x}=\frac{c}{x}-4.
$$
Exercícios 6
Encontre as soluções gerais, usando variação dos parâmetros:
1. \( y^{\prime}+y=2\)
2. \( (x+4)y^{\prime}+3y=3\)
3. \( y^{\prime}-y=3e^{x}\)
4. \( y^{\prime}-y=e^{x}\)
Algumas soluções:
1. \(y=ce^{-x}+2\)
3. \(y=(3x+c)e^{x}\)
Equações de Bernoulli
Nesta seção descrevemos métodos de solução para dois tipos de equações diferenciais que são não lineares no caso mais geral e que surgem no contexto de aplicações. Para ambos os casos tratamos de exemplos onde os problemas se reduzem a equações diferenciais lineares não homogêneas e, como um exercício, nós as resolvemos pelo método da variação dos parâmetros.
Uma equação de Bernoulli é uma equaçao diferencial do tipo
$$
y^{\prime}+P(x)y=Q(x)y^{n}.
$$
Se \(n=0\) ou \(n=1\) ela é uma equação linear, de primeira ordem, que pode ser tratada pelos métodos já estudados. Para \(n>1\) ela é uma equação não linear que pode, no entanto, ser transformada em uma equação linear através de uma troca de variáveis \(y\rightarrow v\), dada por \(v=y^{1-n}\), como passaremos a mostrar. Multiplicamos primeiro a equação (26) por \(y^{-n}\) obtendo
$$
y^{\prime}y^{-n}+P(x)y^{1-n}=Q(x).
$$
Fazemos agora a troca de variáveis sugerida,
$$
v=y^{1-n}\Rightarrow v^{\prime}=(1-n)y^{-n}y^{\prime}\Rightarrow y^{\prime}y^{-n}=\frac{v^{\prime}}{1-n}
$$
para chegar a
$$
\frac{v^{\prime}}{1-n}+Pv=Q,
$$
que é uma equação diferencial linear de primeira ordem, não homogênea, que pode ser resolvida por um dos dois métodos já estudados.
Exemplo 19. Vamos resolver a equação diferencial
$$
y^{\prime}-\frac{y}{x}=-\frac{y^{2}}{x}.
$$
Note que esta é uma equação diferencial de Bernoulli com
$$
n=2,\,\,\,Q(x)=P(x)=-\frac{1}{x}.
$$
Façamos então a mudança de variáveis, usando a nova variável
$$
v=y^{(1-2)}=\frac{1}{y},
$$
e sua derivada
$$
v^{\prime}=-\frac{y^{\prime}}{y^{2}}.
$$
Dividindo a equação (27) por \(y^{2}\) temos
$$
\frac{y^{\prime}}{y^{2}}-\frac{1}{xy}=-\frac{1}{x},
$$
onde substituimos a nova variável para chegar a
$$
v^{\prime}+\frac{v}{x}=\frac{1}{x}.
$$
Para resolver esta equação linear poderíamos simplesmente aplicar a equação (24) . Mas, como um exercício, nós a resolveremos pelo método da variação dos parâmetros. Para isto encontramos primeiro a solução da homogênea
$$
v^{\prime}+\frac{v}{x}=0\Rightarrow\frac{dv}{v}=-\frac{dx}{x}\Rightarrow v=\frac{C}{x}.
$$
Tentamos uma solução da não homogênea sob a forma
$$
v=\frac{u}{x},\,\,\,v^{\prime}=\frac{u^{\prime}x-u}{x^{2}}.
$$
Substituindo na equação diferencial
$$
\frac{u^{\prime}x-u}{x^{2}}+\frac{u}{x^{2}}=\frac{1}{x}\Rightarrow u^{\prime}=1\Rightarrow u=x+c,
$$
ou, em termos de \(v\),
$$
v=\frac{u}{x}=\frac{c}{x}+1.
$$
Finalmente retornamos à função \(y(x)\), relacionada a \(v\) por meio de (28),
$$
y(x)=\frac{1}{v}=\frac{x}{c+x}.
$$
Sugestão: Derive esta solução e verifique se ela satisfaz a equação (27)
Equação de Ricatti
As equações diferenciais de Ricatti são equações do tipo
$$
y^{\prime}=A(x)y^{2}+B(x)y+C(x).
$$
Podemos distinguir alguns casos:
i. Se \(A(x)=0\) a equação é linear.
ii. Se \(C(x)=0\) a equação de Ricatti se reduz a
$$
y^{\prime}-B(x)y=A(x)y^{2}
$$
que é uma equação de Bernoulli com \(n=2,\,\,P(x)=-B(x)\), \(Q(x)=A(x)\), tratada na seção anterior.
iii. No caso geral, suponha conhecida uma solução \(y_{1}\). Então a equação (29) pode ser reduzida a uma equação linear por meio de uma troca de variáveis \(y\rightarrow v\) dada por
$$
y=y_{1}+\frac{1}{v}.
$$
Para encontrar a equação linear associada derivamos \(y\),
$$
y^{\prime}=y_{1}^{\prime}-\frac{v^{\prime}}{v^{2}}
$$
e calculamos \(y^{2}\)
$$
y^{2}=\left(y_{1}+\frac{1}{v}\right)^{2}=y_{1}^{2}+2y_{1}\frac{1}{v}+\frac{1}{v^{2}}.
$$
Em seguida substituimos \(y,y^{2}\) e \(y^{\prime}\) na equação original para obter
$$
y_{1}^{\prime}-\frac{v^{\prime}}{v^{2}}=Ay_{1}^{2}+2Ay_{1}\frac{1}{v}+\frac{A}{v^{2}}+By_{1}+\frac{B}{v}+C.
$$
Observando que, como \(y_{1}\) é solução da equação de Ricatti então
$$
y_{1}^{\prime}=Ay_{1}^{2}+By_{1}+C.
$$
Cancelando estes termos na equação acima resta apenas
$$
-\frac{v^{\prime}}{v^{2}}=2Ay_{1}\frac{1}{v}+\frac{A}{v^{2}}+\frac{B}{v}
$$
ou seja
$$
v^{\prime}+(2Ay_{1}+B)v+A=0,
$$
que é uma equação linear, cuja solução sabemos calcular.
Exemplo 20. A equação diferencial
$$
y^{\prime}=(1-x)y^{2}+(2x-1)y-x.
$$
é uma equação se Ricatti onde identificamos
$$
A(x)=(1-x),\,\,\,B(x)=(2x-1),\,\,\,C(x)=-x.
$$
Sabendo que \(y_{1}=1\) é uma solução (como se pode verificar por substituição) procuramos uma solução sob a forma
$$
y=y_{1}+\frac{1}{v}=1+\frac{1}{v}.
$$
Com esta escolha para \(v\) calculamos \(y^{\prime} \text{ e } y^{2}\),
$$
y^{\prime}=\frac{v^{\prime}}{v^{2}},\,\,\,y^{2}=\left(1+\frac{1}{v}\right)^{2}=1+\frac{2}{v}+\frac{1}{v^{2}},
$$
que, após substituição na equação (30) resulta em
$$
\frac{v^{\prime}}{v^{2}}=(1-x)\left(1+\frac{1}{v}\right)^{2}+(2x-1)\left(1+\frac{1}{v}\right)-x.
$$
Simplificando esta equação obtemos a equação linear esperada,
$$
v^{\prime}+v=x-1.
$$
Mais uma vez temos que resolver uma equação não homogênea, e o faremos pelo método da variação de parâmetros. A equação homogênea e sua solução são, respectivamente,
$$
v^{\prime}+v=0,\,\,\,v=Ce^{-x}.
$$
Buscaremos então uma solução da forma
$$
v=\phi e^{-x},
$$
onde \(\phi\) é uma função de \(x\). Usamos a regra da derivada do produto para calcular
$$
v^{\prime}=\phi^{\prime}e^{-x}-\phi e^{-x}.
$$
Substituindo \(v\) e \(v^{\prime}\) na equação (31) chegamos a uma equação diferencial para \(\phi\)
$$
\phi^{\prime}e^{-x}=x-1,
$$
cuja solução é
$$
\phi=\int(x-1)e^{x}dx=e^{x}(x-1)+c.
$$
Isto representa uma solução para \(v\)
$$
v=\phi e^{-x}=(x-1)+ce^{-x},
$$
que, por sua vez, é ainda uma função auxiliar para a solução do problema. A solução final fica descrita por
$$
y=1+\frac{1}{v}=1+\frac{1}{ce^{-x}+x-1}.
$$
Exercícios 7
Resolva as equações:1. De Bernoulli: \(y^{\prime}+\frac{y}{x}=xy^{2}\).
2. De Bernoulli: \(y^{\prime}=y(xy^{3}-1)\).
3. De Ricatti: \(y^{\prime}=2-2xy+y^{2}\), observando que \(y_{1}=2x\) é uma solução.
4. De Ricatti: \(y^{\prime}=-\frac{4}{x^{2}}-\frac{1}{x}y+y^{2},\,\,\,y_{1}=\frac{2}{x}\).
Método Iterativo de Picard
Vimos, nas seções anteriores, que uma equação diferencial linear de primeira ordem sempre admite solução. Estudamos também algumas técnicas de solução que podem ser usadas para equações não lineares, por exemplo, as diferenciais exatas. No entanto, se uma equação diferencial não se apresenta sob formas conhecidas sua solução pode ser bastante difícil e existem equações que não podem ser resolvidas por nenhum dos métodos padronizados. Por outro lado, em diversas aplicações, uma solução aproximada talvez seja suficiente. Além disto, do ponto de vista teórico, o simples conhecimento de que existe uma solução pode ser útil. O método iterativo de Picard é uma forma de se obter soluções com a aproximação que se fizer necessária.
Pretendemos resolver um problema de valor inicial do tipo
$$
y^{\prime}=f(x,y),\,\,\,y(x_{0})=y_{0}.
$$
Pelo tereoma fundamental do cálculo sabemos que
$$
y(x)=\int_{x_{0}}^{x}f[t,y(t)]dt+y_{0},
$$
como pode ser facilmente verificado:
$$
y(x_{0})=y_{0},
$$
Podemos obter uma primeira aproximação para a solução da equação (32) fazendo \(y_{1}=y_{0}\) na integral (33)
$$
y_{1}(x)=\int_{x_{0}}^{x}f[t,y_{0}]dt+y_{0}.
$$
Uma segunda aproximação é obtida tomando \(y=y_{1}\),
$$
y_{2}(x)=\int_{x_{0}}^{x}f[t,y_{1}(t)]dt+y_{0},
$$
e assim sucessivamente, através de passos iterativos que fornecem uma solução cada vez mais precisa. No n-ésimo passo temos
$$
y_{n}(x)=\int_{x_{0}}^{x}f[t,y_{n-1}(t)]dt+y_{0}.
$$
Pode-se mostrar que a sequência
$$
y_{1}(x),\,\,\,y_{2}(x),\cdots,\,\,\,y_{n}(x),\cdots
$$
converge para \(y(x)\) sob condições bastante gerais.
Exemplo 21. Considere o problema de valor inicial, cuja solução conhecemos,
$$
y^{\prime}=y,\,\,\,y(0)=1.
$$
Observe primeiro que
$$
y_{0}=1,\,\,\,x_{0}=0,\,\,\,f(x,y)=y,\,\,\,f(t,y_{0})=y_{0}=1.
$$
Pela fórmula (33), em primeira aproximação
$$
y_{1}(x)=\int_{0}^{x}dt+1=x+1.
$$
o que já nos permite prever qual será o n-ésimo passo:
$$
y_{n}(x)=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}\frac{x^{4}}{4!}+\cdots+\frac{x^{n}}{n!}.
$$
Esta sequência de funções tende a
$$
\lim_{n\rightarrow\infty}y_{n}=\sum_{k=0}^{\infty}\frac{x^{k}}{k!}=e^{x},
$$
(5) Veja o Apêndice para uma revisão sobre expansões de funções em séries de Maclaurin e Taylor.
que, como já sabíamos, é a solução para o problema proposto. Neste caso a seqüência converge para uma função elementar cuja expansão de Maclaurin5 é conhecida.
Exemplo 22. Vamos aplicar o método de Picard ao problema
$$
y^{\prime}=2xy+1,\,\,\,y(0)=0.
$$
Identificando os termos necessários ao desenvolvimento
$$
y_{0}=0,\,\,\,x_{0}=0,\,\,\,f(x,y)=2xy+1,\,\,\,f(t,y_{0})=2ty_{0}+1=1,
$$
podemos encontrar em primeira aproximação
$$
y_{1}(x)=\int_{0}^{x}dt=x.
$$
Observando que
$$
f[t,y_{1}(t)]=f[t,t]=2t^{2}+1
$$
Vemos que a cada nova iteração acrescentamos um termo à nossa solução aproximada. A solução exata é a série
$$
y(x)=x+\frac{2x^{3}}{3}+\frac{2^{2}x^{5}}{3.5}+\frac{2^{3}x^{7}}{3.5.7}+\cdots
$$
Fica como um exercício, proposto na lista abaixo, a demonstração de que esta série é a expansão de Maclaurin da função
$$
y(x)=e^{x^{2}}\int_{0}^{x}e^{-t^{2}}dt.
$$
Exercícios 8
Use o método de Picard para determinar soluções aproximadas de:
1. \(y^{\prime}=1+y^{2},\,\,\,y(0)=0\)
2. \(y^{\prime}=2xy, \,\,\,y(0)=1\)
3. \(y^{\prime}=x+y, \,\,\,y(0)=1\)
4. \(y^{\prime}=x+y, \,\,\,y(0)=-1\)
5. \(y^{\prime}=xy, \,\,\,y(0)=2\)
6. \(y^{\prime}=2y, \,\,\,y(0)=-1 \)
7. \(y^{\prime}-xy-2x+x^{3}=0, \,\,\,y(0)=0\)
8. \(y^{\prime}-2xy+1=0, \,\,\,y(0)=0 \)
9. \(y^{\prime}=xy+1, \,\,\,y(0)=0\)
10. \(y^{\prime}+y^{2}-x=0, \,\,\,y(0)=0,5\)
11. Mostre que a série, solução do exemplo 2, é a expansão de Maclaurin da função \(y(x)=e^{x^{2}}\int_{0}^{x}e^{-t^{2}}dt\).
Existência e Unicidade
Um problema importante associado às equações diferenciais é o que se refere a existência e unicidade das soluções. Sob que condições um problema de valor inicial
$$
y^{\prime}=f(x,y),\,\,\,y(x_{0})=y_{0}
$$
admite uma solução e quando esta solução é única? As respostas para estas perguntas estão nos dois teoremas seguintes.
Teorema 1. (Existência): Se \(f(x,y)\) é contínua em todos os pontos do retângulo
$$
R=\left\{ \left(x,y\right)\in R^{2},\,\,\left|x-x_{0}\right| \lt a,\,\,\left|y-y_{0}\right|\lt b\,\right\}
$$
sendo, portanto, limitada em \(R\), ou seja, \(|f(x,y)|\leq K\) em \(R\), então o problema de valor inicial (34) possui pelo menos uma solução definida, no mínimo, para todo \(x\) no intervalo \(|x-x_{0}|\lt m\), onde \(m\) é o menor entre os dois valores \(a\) e \(b/K\).
Observe que esta solução pode ser obtida pelo método iterativo de Picard, como o limite da sequência \(y_{0,}\,y_{1},\,y_{2},\cdots, \, y_{n}\), onde
$$
y_{n}(x)=\int_{x_{0}}^{x}f[t,y_{n-1}(t)]dt+y_{0}.
$$
Figura 2:
\(\left\{ \left(x,y\right)\in R^{2},\,\,\left|x-x_{0}\right| \lt a,\,\,\left|y-y_{0}\right| \lt b\right\} \).
Teorema 2. (Unicidade): Se \(f(x,y)\) e \(f_{y}\) são funções contínuas em \(R\) (portanto limitadas) i. e.,
$$
\left|f(x,y\right|\leq K,\,\,\:\left|f_{y}\right|\leq K
$$
para pontos em \(R\), então o problema de valor inicial (34) admite uma única solução definida, no mínimo, em todo \(x\), \(|x-x_{0}|\lt m\).
Os dois teoremas juntos garantem que, dadas as condições enunciadas, existe uma única solução para o problema em (34). A demonstração destes teoremas está além do escopo deste texto.
Equações Diferenciais são equações matemáticas onde as incógnitas são funções, expressas por meio de suas derivadas e outras funções.
Elas são extremamente úteis para a descrição de fenômenos naturais e das aplicações das teorias na ciência e tecnologia e desempenham um papel fundamental na matemática, física, nas diversas áreas da engenharia, economia e biologia.
Suas soluções são funções que satisfazem as equações e alguns valores de contorno, que são especificações de certos pontos específicas destas soluções. Somente as equações diferenciais mais simples admitem soluções fechadas sob a forma das funções elementares conhecidas. Outras podem ser resolvidas por métodos de recorrência e, ainda, alguns problemas podem ser simplificados apensa pelo conhecimento de propriedades das soluções, mesmo que uma forma fechada não possa ser encontrada.
Com o advento dos computadores modernos sempre é possível se encontrar soluções numéricas para um problema, com níveis de precisão arbitrários, o que é suficiente para a maioria das aplicações práticas.
A palavra Cálculo vem do latim calculus, que significa pedregulho e é uma reminiscência da técnica primitiva de executar operações matemáticas simples por meio de pequenas pedras. Calculi eram as pessoas que contavam, calculones os professores. Escravos que tinham a função de contadores eram chamados de calculatores enquanto homens livres com a mesma tarefa recebiam a designação de numerarii.
O Cálculo, como o estudo das operações de diferenciação e integração, é o nome de um sistema ou método desenvolvido independentemente em grande parte por Newton e Leibniz no século XVII. O termo cálculo foi usado pela primeira vez por Leibniz em seu livro publicado em 1680, Os Elementos de um novo Cálculo das Diferenças e Somas, Tangentes e Quadraturas, Máximos e Mínimos, Medidas de Linhas, Superfícies e Sólidos e outras coisas que transcendem o cálculo usual.
O Cálculo é o resultado de uma longa série de avanços, iniciados com a geometria grega, na tentativa de estabelecer áreas de figuras com forma arbitrária, volumes de sólidos quaisquer, no estudo do movimento dos corpos e de sua velocidade instantânea bem como, no que consiste o problema inverso, o cálculo das distâncias percorridas conhecida sua velocidade a cada momento. A expressão Cálculo Infinitesimal foi usada por muitos anos como referência ao cálculo. O conceito de infinitesimal como uma quantidade arbitrariamente pequena foi amplamente empregado pelos matemáticos na ausência de uma teoria apropriada para os limites. Este desenvolvimento somente se deu no século XIX. Como conjunto de métodos matemáticos o cálculo se distingue da álgebra elementar e da geometria pela introdução da operação de passagem ao limite. As operações básicas do cálculo são a diferenciação e a integração, sendo ambos os conceitos utilizados em diversas situações tanto teóricas quanto em aplicações na física e engenharia, estatística, economia e em praticamente todas as áreas científicas modernas.
Os Primórdios Gregos
As idéias principais que formam a base do cálculo diferencial e integral foram desenvolvidas durante um longo intervalo de tempo, sendo que os primeiros passos foram dados pelos matemáticos gregos, em particular buscando soluções para problemas geométricos. Para os gregos, e em particular para a escola pitagórica que teve grande influência nas gerações posteriores de pensadores, o número um era considerado um átomo ou mônada formadora de todos os outros números. Desta forma os demais números eram compostos por uma quantidade de uns ou razões, entendidas como a divisão entre segmentos de comprimento inteiro. Daí o apreço pelos racionais e a dificuldade em aceitar números que não pertencem a este conjunto, como o número \(\pi\) ou \(\sqrt{2}\). Neste sentido eles acreditavam que nem todos os comprimentos pudessem ser representados por números. Tampouco trabalhavam com números negativos e não possuiam grande desenvolvimento em álgebra.
Zenão de Eléia (~450 a.C.) foi um dos primeiros pensadores a propor problemas baseados no conceito de infinito. Segundo um paradoxo famoso imaginado por ele, se uma flecha é atirada do ponto \(A\) até o ponto \(B\) ela deverá passar pela metade do caminho, digamos pelo ponto \(B_1\) , antes de chegar ao destino \(B\). Mas, antes de chegar a \(B_1\) deverá passar por \(B_2\) , o ponto médio entre \(A\) e \(B_1\) , e assim sucessivamente, realizando um número infinito de etapas em um intervalo finito de tempo. Desta forma ele concluiu que o movimento era impossível. Sabemos hoje que o conceito de limite é o que falta para a plena compreensão do paradoxo. Leucipo, Demócrito e Antífon fizeram contribuições para o método de exaustão mais tarde aprimorado por Eudóxo (~370 a.C.) e Arquimedes. O método é assim chamado porque as áreas medidas são tomadas em aproximações sucessivas e crescentes até que cubram a figura considerada.
Na visão de alguns historiadores o verdadeiro precursor do cálculo foi Arquimedes que viveu de 287 até 212 a.C. e, segundo se acredita, foi aluno de Euclides em Alexandria. Arquimedes aperfeiçoou o método da exaustão para a prática da integração buscando encontrar áreas de figuras planas. Em seu livro A Medida do Círculo ele mostrou que o valor exato do número \(\pi\) está entre \(\frac{310}{71}\) e \(\frac{31}{7}\) , aproximação que obteve inscrevendo e circunscrevendo o círculo em um polígono regular de 96 lados. Ele também descreveu uma técnica para o cálculo de raízes e inventou um sistema para a expressão de números grandes. Em O Contador de Areia (ou O Arenário) ele sugeriu um sistema de notação numérica capaz de expressar números até \(8\times 10^{63}\) argumentando que este é um número suficientemente grande para contar todos os grãos de areia do universo. Para estimar as dimensão do universo ele se baseava no sistema de Aristarco, que tinha o Sol no centro do sistema planetário que incluia a Terra.
Arquimedes também enunciou teoremas fundamentais concernentes ao centro de gravidade de figuras planas e sólidos. Seu teorema mais famoso, o chamado Princípio de Arquimedes, permite o cálculo do peso de um objeto imerso em água. Mais tarde ele introduziu algumas das contribuições mais significativas feitas na Grécia. Em primeiro lugar mostrou que a área de um segmento de parábola é \(\frac{4}{3}\) da área de um triângulo de mesma base e vértice e \(2/3\) da área de um paralelogramo circunscrito. Arquimedes construiu uma sequência infinita de triângulos partindo de um triângulo com área \(A\) e somando repetidamente novos triângulos entre os existentes e a parábola, até chegar a
$$A,\,A+\frac{1}{4},\,A+\frac{1}{4}+\frac{1}{16},\,A+\frac{1}{4}+\frac{1}{16}+\frac{1}{64},\ldots$$
A área do segmento de parábola é, portanto
$$ A \left( 1+\frac{1}{4} + \frac{1}{4^2} + \frac{1}{4^3} + \ldots \right) = A\sum_{n=0}^{\infty} = \frac{1}{4^n}= \left( \frac{4}{3} \right) A $$
Este é o primeiro exemplo histórico da soma de uma série infinita. Arquimedes também usou o método da exaustão para calcular aproximadamente a área de um círculo, no que consiste em um exemplo bem antigo do uso da integração para uma avaliação aproximada do número \(\pi\).
Figura 1: Quadratura do círculo e da parábola
Usando este método Arquimedes foi capaz de calcular o volume da esfera, o volume e a área do cone, a superfície subentendida por uma elipse, o volume obtido por revolução de qualquer segmento de uma parábola ou hipérbole.
Conta-se que Arquimedes estava fazendo contas na areia quando foi morto por um soldado romano.
Arquimedes foi morto em 212 a.C. quando Siracusa foi tomada pelos soldados romanos durante a Segunda Guerra Púnica apesar da ordem expressa do imperador romano para que sua vida fosse poupada. Esta morte se tornou um símbolo da destruição da civilização grega e de seu ímpeto na busca de resposta para questões científicas e filosóficas. Estes eventos determinaram, pelo menos parcialmente, a entrada da civilização ocidental em um longo período de estagnação cultural durante os princípios da Idade Média.
Desenvolvimento na Idade Média e Renascimento
(1) Apesar disto durante a Idade Média os algarismos hindu-arábicos foram difundidos na Europa, em particular devido ao trabalho de Fibonacci e alguns avanços sobre a solução de equações de segundo e terceiro grau foram obtidos.
(2) Uma crença derivada das idéias platônicas e pitagóricas.
Com o progresso das invasões romanas e o declínio geral da civilização grega a matemática passou por longos anos sem receber aprimoramentos importantes. A civilização romana era voltada para o uso pragmático da matemática e poucas descobertas marcaram este período. Mais tarde, com a expansão do império, tornou-se difícil mantê-lo unificado, o que motivou sua separação em império do ocidente, dirigido por Roma, e império bizantino, com sede em Constantinopla. O enfraquecimento do poder de Roma, as invasões dos germanos e outros povos vindos do norte da Europa, e o fortalecimento da igreja romana deram origem ao período conhecido como Idade Média, durante o qual grande parte dos textos científicos e filosóficos foi destruída e a cultura clássica foi quase totalmente esquecida(1). Esta situação durou até o final do século XVI d.C. com o Renascimento, caracterizado pelo avivamento do interesse pelos problemas relacionados ao movimento, tais como o estudo dos corpos em queda livre e de centros de gravidade. As idéias principais que se sucederam na formação da base do cálculo foram desenvolvidas durante um longo intervalo de tempo.
Luca Valério (1552-1618), um doutor em filosofia e teologia, publicou em Roma, 1604, seu livro De centro gravitatis onde empregava os métodos de Arquimedes para calcular volumes e centros de gravidade de corpos sólidos. Em 1606 ele publicou De quadratura parabolae onde empregava os métodos gregos para calcular áreas de figuras planas. Valério se encontrou com Galileu Galilei na cidade de Pisa em 1590 e iniciou com ele uma troca de correspondência. Em 1916 o Cardeal Belarmino, o principal teólogo da igreja Católica Romana da época, emitiu uma declaração oficial de que eram falsas as idéias de Copérnico e Valério se viu obrigado a interromper seu contato com Galilei, um dos principais defensores das idéias copernicanas.
Johannes Kepler
Kepler (1571-1630) também era um homem profundamente religioso que acreditava ser uma obrigação cristã a tarefa de compreender e revelar os segredos de Deus. Ele defendia que o ser humano, sendo feito a imagem de seu criador, deveria ser capaz de entender o Universo por ele criado e que a criação de tudo havia sido elaborada sobre um plano matemático(2). Uma vez que a matemática era, já na época, tida como um instrumento eficaz de se chegar à verdade, ele elaborou sua estratégia para a obtenção do conhecimento.
Em seu estudo sobre o movimento planetário Kepler precisava encontrar a área de setores de uma elipse. Seu método consistia em considerar as áreas como uma soma de linhas, outra forma primitiva de abordar uma integração. No entanto Kepler não se esforçou para manter um grande rigor em seu trabalho, tendo cometido erros que, por sorte, se cancelavam permitindo a obtenção de resultados corretos. Há um relato de que, durante a cerimônia de seu segundo casamento em 1613, Kepler teria notado que o volume dos barris de vinho era calculado por meio de uma barra inserida pelo orifício do barril para medir sua diagonal. Ele passou a considerar como este método poderia funcionar e, como resultado de suas meditações, publicou diversos artigos sobre volumes de sólidos de revolução. Seus métodos foram aperfeiçoados por Cavalieri e constituem parte importante do legado ancestral do cálculo diferencial.
As próximas contribuições importantes foram alcançadas por três matemáticos nascidos aproximadamente na mesma época: Cavalieri, Roberval e Fermat. O primeiro deles, Bonaventura Cavalieri (1598 – 1647), se tornou jesuíta quando ainda era criança e estudou em um monastério de Pisa. Assim como ocorreu com Luca Valério, seu interesse pela matemática foi despertado pelo estudo das obras de Euclides e seu contato com Galileu, de quem ele se considerava discípulo.
Em 1629 Cavalieri foi indicado como professor de matemática em Bologna. Nesta época ele já tinha desenvolvido seu método dos indivisíveis para o cálculo de áreas, um fator importante para o desenvolvimento do cálculo integral. A teoria dos indivisíveis de Cavalieri, apresentada em 1635 era um aprimoramento do método da exaustão de Arquimedes, incorporando a teoria das quantidades geométricas infinitesimalmente pequenas de Kepler. Por meio desta teoria Cavalieri podia calcular de forma prática e eficiente a área e volume de diversas figuras geométricas. Ele não era muito rigoroso em seu trabalho e não é fácil hoje entendermos como ele concebia seu método. Aparentemente Cavalieri considerava uma área como composta de componentes que eram retas e, a partir dai, somava um número infinito de “indivisíveis”. Usando esta técnica ele mostrou que a área sob a curva \(x^n\) avaliada de \(0\) até um número arbitrário \(a\) era \(a^{n+1}/(n+1)\) mostrando inicialmente que o resultado valia para alguns valores de \(n\) e depois inferindo sua validade para o caso geral.
(3) Os logaritmos foram inventados por John Napier (também conhecido por Neper) e aperfeiçoados por Briggs no século XVII.
(4) Marin Mersenne (1588-1648, França) foi um padre católico responsável pela formação de um grupo de debates envolvendo matemáticos importantes da época, tais como Fermat, Pascal, Roberval e outros que, mais tarde, formaram o núcleo da Academia Francesa. Mersenne se correspondia com diversos pensadores importantes e foi o responsável pela divulgação de suas idéias, algumas vezes contra a vontade do próprio pensador. Ele defendeu Descartes e Galileu contra os ataques teológicos e se esforçou para denunciar como pseudo-ciências as práticas da alquimia e astrologia.
Como resposta às críticas de que seus métodos não possuíam um embasamento teórico muito rigoroso Cavaliere publicou Exercitationes geometricae onde aperfeiçoava os fundamentos de sua teoria. Este texto se tornou a principal fonte de estudos dos matemáticos do século XVII. Cavalieri foi também um dos grandes responsáveis pela introdução dos logaritmos(3) na Itália como um instrumento computacional, tendo publicado tabelas de logaritmos e funções trigonométricas para uso dos astrônomos da época. Cavalieri também escreveu sobre as seções cônicas, trigonometria, óptica, astronomia e astrologia.
Gilles Personne de Roberval (1602-1675, França) iniciou seus estudos de matemática com 14 anos de idade. Ele viajou por toda a França fazendo contato com matemáticos da época e foi um dos pensadores sob influência do grupo de Mersenne(4). Roberval considerou problemas do mesmo tipo que os de Cavalieri embora procurasse manter maior rigor que ele. Assim como fazia Torricelli, ele procurou descrever uma curva plana como um movimento gerado por um ponto cujo movimento se pode decompor em dois movimentos conhecidos, o que corresponde à descrição moderna de uma curva sob forma paramétrica. A resultante das velocidades dos dois movimentos conhecidos fornece a tangente da curva em cada ponto. Roberval desenvolveu métodos para a integração escrevendo Traité des indivisibles onde apresenta o cálculo da integral definida da função sen x. Ele também calculou o comprimento de arco de uma espiral, trabalhou com ciclóides e apresentou a descrição de diversas curvas planas, desenvolvendo um método já sugerido por Torricelli para se traçar retas tangentes a curvas dadas. Ele considerava a área entre uma curva e uma reta como sendo composta por um grande número de faixas muito estreitas. Usando este processo na avaliação da área sob de \(x^n\) de \(0\) até \(1\) ele obteve o valor aproximado de
$$ \frac{1}{n^{m+1}} \left( 0^m + 1^m +2^m + \ldots +(n-1)^m \right) $$
e mostrou depois, aplicando técnicas precursoras do conceito de limite, que este valor tendia para \(\frac{1}{m+1},\) calculando desta forma a área procurada.
Pierre de Fermat
Pierre de Fermat (1601-1665, França) também procurou trabalhar com rigor, embora não tenha fornecido provas de suas afirmações e nem mostrado de forma clara quais foram os métodos empregados para se obter um determinado resultado. Ele se formou em Direito pela Universidade de Toulouse mas logo se interessou pela matemática praticamente como um amador, estudando em suas horas vagas. Em 1629 ele produziu uma restauração da obra de Apolônio, Plane loci e, na mesma época, escreveu um trabalho importante sobre máximos e mínimos de funções procurando pelos pontos onde as tangentes às suas curvas são paralelas ao eixo \(Ox\). Ele escreveu a Descartes descrevendo seu método, que era essencialmente o mesmo usado hoje que consiste em encontrar pontos de derivada nula. Devido a este episódio Lagrange afirmou considerar Fermat o inventor do cálculo.
Fermat considerou parábolas e hipérboles generalizadas do seguinte modo:
(5) Euclides mostrou que a expressão de Pitágoras \(x^2+y^2=z^2\) admite infinitas soluções inteiras, os ternos pitagóricos.
Enquanto examinava expressões como \(\frac{y}{b} = \left( \frac{x}{b} \right)^p\), Fermat calculou a soma de \(r^p\) de \(r=1\) até \(r=n\). No período de 1643 até 1654 Fermat esteve em contato com seus colegas cientistas em Paris, sob a influência de Mersenne. Surgiu então o seu interesse pela teoria dos números. Ele se tornou amplamente conhecido particularmente pelo que hoje conhecemos como último Teorema de Fermat que afirma que a expressão \(x^n+y^n=z^n\) não admite solução(5) inteira diferente de zero para \(n≥3.\) Fermat escreveu na margem de seu livro Aritmetica de Diofante: “descobri uma prova realmente maravilhosa para este teorema mas estas margens são estreitas demais para contê-la” . Acredita-se hoje que a prova de Fermat, se existiu, era incorreta. As tentativas de demonstração do teorema motivaram muitas gerações de matemáticos e deu origem a diversas novas áreas na matemática, particularmente na álgebra. Apesar disto o teorema permaneceu sem demonstração por séculos, problema que só foi resolvido em 1994 pelo matemático inglês Andrew Wiles.
Além de sua contribuição fundamental para a geometria analítica René Descartes (1596-1650, França) foi responsável pelo desenvolvimento de um método para a determinação de normais, publicado no livro La Géométrie, 1637. Este livro é considerado o mais importante de seus trabalhos em matemática devido à inserção do formalismo algébrico na geometria. Nele se toma o primeiro passo na direção da teoria dos invariantes que remove a arbitrariedade de escolha de um referencial. A adoção do formalismo algébrico no tratamento da geometria torna possível a consideração de problemas que seriam difíceis ou impossíveis sem esta técnica.
René Descartes
De Beaune ampliou o método de Descartes e o aplicou à determinação de tangentes. Hudde descobriu um método mais simples, hoje conhecido como Regra de Hudde, onde as tangentes são obtidas através das derivadas. Tanto o trabalho de Descartes quanto o de Hudde foram de primordial importância para influenciar Newton e conduzi-lo a sua formulação do Cálculo.
Huygens foi um crítico das provas apresentadas por Cavalieri. Ele afirmava que é necessário pelo menos produzir uma prova que, mesmo que incompleta, leve à convicção de que uma prova posterior, totalmente rigorosa, possa ser estabelecida. Ele exerceu uma influência profunda em Leibniz e, através deste, representa papel importante na construção de uma abordagem mais satisfatória do cálculo. fig Triângulo de Barrow
Os esforços de Torricelli e Barrow representam os passos seguintes de maior importância. Barrow foi o responsável pelo método de construção de tangentes a uma curva como o limite de uma corda secante quando os pontos que a definem se aproximam um do outro. Este método é conhecido como o triângulo diferencial de Barrow.
Tanto Torricelli como Barrow trataram do problema do movimento com velocidade variável. A derivada da distância em função do tempo é uma velocidade, enquanto a operação inversa permite que, conhecida a função velocidade a cada instante se possa obter, por integração, a distância percorrida. A partir dai foi desenvolvido o conceito de integração como o inverso da diferenciação. Barrow compreendia que a derivada e a integral são processos complementares, um o inverso do outro. Embora Barrow nunca tenha afirmado explicitamente o teorema fundamental do cálculo ele estava trabalhando nesta direção. Coube a Newton, que foi aluno de Barrow, continuar este trabalho e fazer a primeira afirmação explícita do teorema.
Isaac Newton
“Platão é meu amigo, Aristóteles é meu amigo, mas a Verdade é a minha melhor amiga.” Isaac Newton (1643 – 1727)
Issac Newton (1642-1727) nasceu no ano da morte de Galileu Galilei em Woolsthorpe, Inglaterra. Ele veio de uma família abastada, embora seu pai fosse um homem com pouca educação formal. Newton teve uma infância infeliz, não tendo conhecido seu pai que morreu antes que ele completasse um ano de idade. Sua mãe, Hannah Ayscough, se casou com o ministro da igreja de um vilarejo próximo e o jovem Isaac foi deixado com seus avós. Há indícios de que Newton sofreu de forte ressentimento pelo casamento da mãe, ao mesmo tempo em que não desenvolveu vínculos fortes com os avós.
Com a morte do padrasto em 1653, Newton passou a viver com a mãe, avó, um meio-irmão e duas meia-irmãs. Como estudante ele demonstrava poucas habilidades e interesse e, por isto, foi tirado da escola para cuidar dos interesses financeiros de sua mãe. Newton também não mostrou interesse em realizar esta tarefa. Em 1960, por influência de William Ayscough, tio de Newton, a família decidiu prepará-lo para a educação superior. Nesta época ele se alojava com a família de Stokes, o chefe da escola, que percebendo os talentos de Newton, foi um dos responsáveis por convencer a família de que ele possuía habilidades para o trabalho acadêmico.
Pouco se conhece sobre o que Isaac teria aprendido antes de ingressar na universidade, particularmente em matemática. Com certeza ele recebeu de Stokes um bom impulso e orientação e é possível que tenha tido o primeiro contato com Os Elementosde Euclides nesta época. Há um número de pequenas histórias, sem maior comprovação, de que Newton era hábil com as máquinas e gostava de construir modelos de relógios e moinhos.
Finalmente, em 1661, quando já era mais velho que a maioria dos colegas, Newton ingressou no Trinity College de Cambridge. Apesar de sua posição financeira confortável ele entrou como um sizar, uma espécie de posição de serviçal em relação aos outros colegas. Newton pretendia inicialmente se formar em Direito.
O currículo em Cambridge naquela época era dominado pelos estudos da filosofia aristotélica até o terceiro ano. A partir dai Newton se dedicou a estudar os textos de Descartes, Gassendi, Hobbes e, em particular, de Boyle. Ele também mostrou interesse pelas teorias revolucionárias de Copérnico, Kepler e Galileu em astronomia e ótica. Gradualmente ele se envolveu com o estudo da matemática e da física. Existe um relato, por parte de de Moivre, de que seu interesse pela matemática foi incrementado em 1663 quando comprou um livro de astronomia e não pode entender a matemática envolvida. Dai ele passou a fazer um esforço para aprimorar seu conhecimento desta disciplina, principalmente através do estudo de uma versão de Barrow de Os Elementos de Euclides. Em seguida ele passou a estudar a recém desenvolvida geometria analítica através dos textos de Viète e René Descartes. Neste período ele aprendeu sobre o método de Wallis para encontrar um quadrado com área sob segmentos da parábola e da hipérbole, usando os indivisíveis.
Ao receber sua graduação em abril de 1665 Newton não havia ainda mostrado toda a sua genialidade. Em 1665 a universidade foi fechada por causa da epidemia da peste negra (peste bubônica) que se espalhava por toda a Europa e Inglaterra. Newton se recolheu na casa de sua mãe onde aprofundou, por conta própria, seus estudos e investigações. Com menos de 25 anos de idade ele iniciou sua carreira fazendo contribuições importantes para a matemática, mecânica, ótica e astronomia. Neste período, como ele próprio relatou depois, ele fez quatro de suas grandes descobertas: o teorema binomial, o cálculo, a lei da gravitação universal e a natureza das cores. O método dos fluxos, como ele denominava o cálculo, estava baseado no reconhecimento fundamental de que as operações de derivação e integração estavam associadas, sendo simplesmente uma a operação inversa da outra. Partindo da derivação com operação básica ele desenvolveu técnicas analíticas que unificavam diversas abordagens anteriores para solucionar questões que antes se julgava serem não correlacionadas, tais como o cálculo de áreas, tangentes a curvas, comprimento de segmentos de curvas e a localização de máximos e mínimos de funções.
Quando a Universidade de Cambridge reabriu, ao término da peste negra em 1667, Newton foi aceito como professor no Trinity College. Nesta época se iniciaram os esforços de Barrow para divulgar os resultados obtidos por Newton que mantinha um contato bastante restrito com a comunidade científica de sua época. Aparentemente por receio às críticas e ao plágio ele tendia a não expor de pronto os seus métodos e, quando o fazia, não os relatava com clareza.
Em outubro de 1666 Newton escreveu um tratado sobre os fluxos. Seu trabalho não foi imediatamente publicado mas muitos matemáticos da época o conheciam de forma que o tratado exerceu grande influência sobre o desenvolvimento do cálculo naquele período. Ele iniciou suas considerações tratando uma curva como sendo a trajetória de uma partícula, dada por suas coordenadas em função do tempo. Em linguagem moderna ele representava a curva de uma função sob a sua forma paramétrica, usando o tempo como parâmetro – uma forma bastante apropriada para quem deseja estudar o movimento de uma partícula. A velocidade no sentido horizontal \(\dot{x}\) e a velocidade vertical \(\dot{y}\) eram os fluxos de \(x\) e \(y\) associados à passagem do tempo. Com esta notação \(\frac{\dot{y}}{\dot{x}}\) representa a tangente à curva \(f(x,y)=0\).
Em seu tratado de 1666 Newton discute a problema inverso. Dada a relação entre \(x\) e \(\frac{\dot{y}}{\dot{x}}\) procurava-se encontrar \(y\). Desta forma a inclinação da tangente era dada para cada \(x\). Considerando conhecida a inclinação a cada instante, Newton resolvia o problema por antidiferenciação (integração). Ele também usou o mesmo processo para calcular áreas e, pela primeira vez na história, ele afirma claramente o Teorema Fundamental do Cálculo, que estabelece a conexão entre os processos de derivação e de integração.
Em 1671 Newton escreveu De Methodis Serierum et Fluxionum mas não o conseguiu publicar até que John Colson preparou uma tradução para o inglês em 1736. Newton encontrou diversas dificuldades para publicar seu textos em matemática e, de certa forma, Barrow tinha parte da responsabilidade por isto. Em tempos recentes os editores de Barrow tinha ido a falência e os demais editores se encontravam receosos em continuar a publicação de textos sobre matemática. O livro de Newton sobre Análise contendo um tratamento das séries infinitas foi escrito em 1669 e circulou pelos meios acadêmicos em forma manuscrita, só sendo publicado em 1711. Da mesma forma seu Method of fluxions and infinite series foi escrito em 1671 e somente traduzido para o inglês e publicado no ano de 1736. O original em latim só foi publicado muitos anos mais tarde.
Nestas duas obras Newton encontrou as expansões em séries de potências para as funções \(\mbox{sen}{x}\) e \(\cos{x}\) assim como a expansão para a função que hoje conhecemos como função exponencial. Naquele tempo não havia uma definição clara desta função, o que foi estabelecido bem mais tarde por Euler, também o responsável pela atual notação, \(e^x\). As expansões em séries de potências para funções analíticas são hoje conhecidas como séries de Taylor ou de Maclaurin, dependendo do ponto em torno dos quais são consideradas. Através das expansões em séries de potência para cada função
Newton resolveu o problema da quadratura, ou seja, o de encontrar áreas subentendidas pelas curvas destas funções, fazendo a integração termo e termo,
$$\int f(x)dx = a_0 x + \frac{a_1}{2} x^2 + \frac{a_2}{3} x^3 + \ldots + \frac{a_n}{n+1} x^n+1 + \ldots,$$
o que, como hoje se sabe, somente está correto se a série é convergente.
A obra seguinte de Newton, Tractatus de Quadratura Curvarum, foi escrito em 1693 e só publicado em 1704 sob a forma de um apêndice em seu livro Optiks. O Tractatus contém uma outra abordagem que envolve uma operação primitiva de tomar limites. Para ilustrar o método de Newton suponha, por exemplo, que queremos derivar a função \(y=x^2\). Lembrando que ele tratava as variáveis sob a forma \(x(t)\) e \(y(t)\), nas palavras de Newton “devido ao fluxo de \(x\) com a passagem do tempo”, quando o tempo progride de uma quantidade \(o\), as variáveis mudam da seguinte forma
$$ x = x(t), \;\; x \to x + \dot{x}o, $$
$$ y = y(t), \;\; y \to y + \dot{y}o. $$
Dada a relação entre \(x\) e \(y\) (\(y=x^2\), neste caso)
$$y \to y + \dot{y}o = \left(x + \dot{x}o\right)^2 = x^2 + 2 x \dot{x}o + \dot{x}^2 o^2,$$
$$\dot{y} o = 2 x \dot{x}o + \dot{x}^2 o^2 \Rightarrow \dot{y} = 2 x \dot{x} + \dot{x}^2 o.$$
Tomando \(o = 0\), no que deveria ser um limite, obtém-se \(\dot{y} o = 2x\dot{x}\). A taxa de variação de \(y\) com \(x\), que é a inclinação da reta tangente, é \(\frac{\dot{y}}{\dot{x}} = 2x\).
Como professor Lucasiano, o primeiro trabalho de Newton foi um curso dedicado à ótica, iniciado em janeiro de 1670. Neste curso ele ensinava que a luz branca não é uma entidade simples mas sim composta por luz de diversas cores, como se pode observar no espectro obtido por meio de um prisma. Vale ressaltar que, desde Aristóteles, sempre se acreditou no contrário. A observação do efeito de aberração cromática em telescópios levou Newton a esta conclusão, bem como à sugestão da construção de telescópios refletores, que se utilizam de espelhos parabólicos no lugar de lentes para a obtenção de uma imagem ampliada dos objetos celestes.
Em 1672 Newton foi aceito membro da Royal Society e publicou seu primeiro artigo sobre a luz e a cor no periódico Philosophical Transactions of the Royal Society. Este artigo foi bem aceito pela comunidade científica mas também deu origem a críticas e oposições. Hooke e Huygens argumentaram contra a tentativa de Newton de provar que a luz possuía natureza corpuscular e não ondulatória. Devido ao peso da opinião de Newton este foi um erro que persistiu por muito tempo no estudo da luz até que experiências com o fenômeno da refração, no século XIX, indicaram uma preferência pelo modelo ondulatório. Vale dizer que hoje existe um modelo corpuscular da luz, e da radiação eletromagnética em geral, como parte integrante da moderna teoria quântica. No entanto, nenhum dos fenômenos de que fato evidenciam a natureza corpuscular da luz era conhecido na época de Newton. As críticas recebidas levaram Newton a adotar uma posição ainda mais retraída e ser mais reticente com relação a suas descobertas. Embora apreciasse a notoriedade ele ressentia enormemente as críticas recebidas e julgava que uma forma de evitá-las seria evitar a publicação de suas idéias.
Cópia de Newton de seu próprio livro Princípia, com correções de seu punho para a segunda edição.
As relações de Newton com Hooke se deterioraram em 1675, quando Hooke o acusou de plágio em algumas de suas conclusões em ótica. Isto fez com que Newton adiasse a publicação de suas conclusões em ótica até a morte do adversário, em 1703. O livro Opticks só apareceu em 1704, tratando da teoria da luz e da cor.
Por volta de 1678, em parte devido a uma nova discussão com os jesuítas sobre sua teoria da luz e devido à morte de sua mãe, Newton sofreu seu primeiro colapso nervoso. Muitos historiadores sustentam a tese de que seu envolvimento com as experimentações alquímicas e subseqüente exposição a vapores de mercúrio e outros metais teria contribuído para fragilizar seu sistema nervoso. é certo que ele passou grande parte de sua vida estudando alquimia, religião cronologia do Apocalipse e outros temas esotéricos, tendo escrito diversos tratados sobre estes assuntos.
As maiores contribuições de Newton para a física foram suas descobertas sobre a mecânica e a gravitação universal. Partindo de sua própria compreensão de forças centrífugas e da terceira lei de Kepler para o movimento planetário ele deduziu que duas partículas de massa \(m_1\) e \(m_2\) respectivamente se atraem com intensidade diretamente proporcional a suas massa e inversamente proporcional ao quadrado da distância entre elas,
$$ F = G \frac{m_1 m_2}{r^2}.$$
Ele foi o responsável pelo entendimento de que a força que age sobre a Lua, por exemplo, é a mesma força que atrai uma maçã para o chão, nas proximidades da superfície. Este entendimento, simples para a mente moderna, representou um grande passo dentro de um contexto cultural que predominantemente acreditava que os objetos celestes eram de natureza divina, em oposição aos de natureza terrena, e que não deveriam obedecer às mesmas leis. Ele representa uma grande unificação de princípios, assim como aquela obtida mais tarde por Maxwell e outros físicos na unificação das teorias da eletricidade e do magnetismo.
Em 1686 Halley, astrônomo e amigo de Newton, o convenceu a publicar uma descrição completa de suas descobertas sobre física e astronomia. Um ano mais tarde ele publicou o Philosophiae Naturalis Principia Mathematica, ou simplesmente Principia, como se tornou conhecido o livro. Este é considerado por muitos historiadores da ciência como o maior livro científico já escrito. Nele Newton trata do movimento dos corpos em meios resistentes e não resistentes e sob a ação de forças centrípetas. Os resultados podem ser aplicados a órbitas celestes, projéteis, pêndulos e corpos em queda livre nas proximidades da superfície da Terra. Em seguida Newton forneceu explicações sobre as órbitas excêntricas dos cometas, as marés e suas variações, a precessão do eixo da Terra e a perturbação do movimento da Lua pela atração gravitacional do Sol. Este trabalho o transformou no principal cientista de sua época embora diversos pensadores da Europa continental e da própria Inglaterra relutassem em aceitar suas visões sobre a gravitação como ação à distância, sua teoria corpuscular da luz, sua versão do cálculo em contraposição à versão de Leibniz e outros tópicos localizados.
Em 1685 James II se tornou rei da Grã-Bretanha, se convertendo ao catolicismo em 1669. Em seguida ele passou a nomear apenas católicos para cargos nas forças armadas e outros postos oficiais de estado. Posteriormente o rei passou a preencher postos vagos na Universidade de Cambrigde com catedráticos fiéis à Igreja Católica. Quando ele insistiu para que um monge beneditino recebesse os graus acadêmicos sem a necessidade de prestar exames ou proferir os juramentos de praxe na época, Newton assumiu a posição de opositor declarado do rei, uma disputa que durou até a fuga de James II e a tomada do poder por William de Orange. Newton, já visto como o maior matemático de sua época, agora famoso pela firme defesa da Universidade, foi eleito para um cargo político no Parlamento. Isto resultou em sua mudança para Londres, com o conseqüente afastamento de Cambridge e das atividades acadêmicas.
Em 1693 Newton sofre um segundo colapso nervoso e abandona suas atividades de pesquisa. Desta vez, além do envenenamento por metais, podem ter contribuído o descuido com os hábitos alimentares, uma frustração com o impacto de suas pesquisas no meio acadêmico e a dificuldade em se relacionar com os colegas, muitas vezes advindas de diferenças em suas convicções religiosas. Além disto houve o rompimento de uma amizade pessoal com Fatio de Duillier, um matemático suiço que residia em Londres. é provável que ele tenha sofrido de depressão durante grande parte de sua vida.
Em 1696 Newton foi designado para o cargo de Guardião da Casa da Moeda, mais tarde Mestre da Casa da Moeda. Ele coordenou com grande eficiência um período difícil de recunhagem da moeda, necessário devido ao grande volume de moeda falsa em circulação na época. Além de eficiente Newton foi rígido na perseguição e punição dos falsificadores.
Em 1703 Newton foi eleito presidente da Royal Society, mantendo este cargo até o final de sua vida. Em 1705 ele foi feito cavalheiro pela rainha Anne, sendo o primeiro cientista a receber esta distinção como reconhecimento por seu trabalho. Contudo toda a última fase de sua vida foi dominada pelo ressentimento causado pela controvérsia com Leibniz sobre a autoria da Cálculo.
Gottfried Wilhelm von Leibniz
Gottfried Leibniz (1646-1716)
Leibniz (1646-1716) nasceu em Leipzig, Alemanha, filho de Friedrich Leibniz, um professor de filosofia moral e cristão fervoroso e Catharina Schmuck. Leibniz perdeu o pai com apenas seis anos e aprendeu da mãe os valores religiosos e éticos que nortearam sua vida e filosofia. Na escola ele aprendeu a lógica de Aristóteles. Insatisfeito com a filosofia aristotélica dominante na época ele iniciou o desenvolvimento de suas próprias idéias sobre como aperfeiçoá-la. Ainda criança ele apreciava ler os livros de seu pai sobre metafísica e teologia nas visões de escritores católicos e protestantes. O próprio Leibniz reconheceu mais tarde como uma constante em sua vida a preocupação em estabelecer um ordenamento por trás do pensamento lógico e da dedução matemática, assim como uma tentativa sempre presente de estabelecer contatos entre pontos de vista conflitantes e o de unificar os diversos sistemas de pensamento.
Ao completar 16 anos, algo não muito incomum na época, Leibniz entrou para a Universidade de Leipzig onde estudou filosofia e matemática. Nenhuma destas disciplinas era, na época, ensinada com grande nível de aprofundamento. Após sua graduação, obtida em 1663, ele passou um período em Jena estudando com com Erhard Weigel, um filósofo e matemático com quem aprendeu a importância do método de provas matemáticas em assuntos tais como lógica e filosofia. Em 1663 Leibniz retornou a Leipzig para o programa de doutorado em Direito. Lá ele obteve primeiro o grau de Mestre em filosofia, tendo sido mais tarde recusado para o grau de doutor em Direito. Aparentemente isto ocorreu porque ele era muito jovem e havia na época poucos orientadores disponíveis. Se esperava então que ele aguardasse um ano até sua aceitação. Ao invés de esperar Leibniz foi para a Universidade de Altdorf, recebendo o grau de doutor em Direito em 1667.
Uma vez formado Leibniz iniciou uma carreira voltada para a diplomacia enquanto participava em diversos projetos científicos, literários e políticos. Ele se relacionava igualmente bem com católicos e luteranos e manteve durante toda a sua vida um interesse em trabalhar para a reunificação das igrejas. Outro de seus projetos permanentes era a intenção de reunir de forma organizada todo o conhecimento acumulado até a sua época. Simultaneamente Leibniz começou a estudar o movimento buscando explicar os resultados obtidos por Wren e Huygens sobre colisões elásticas. Em 1671 ele publicou Hypothesis Physica Nova onde afirmava, em acordo com Kepler, que o movimento é decorrente da ação do espírito sobre a matéria. Neste período, passou a se comunicar com Oldenburg, o secretário da Royal Society de Londres, um dos responsáveis por seu contato com Isaac Newton.
Diferente de Newton, Leibniz apreciava viajar pela Europa fazendo contatos com outros matemáticos e filósofos, se aproveitando para isto de sua posição como diplomata. Juntamente com sua atuação na diplomacia ele iniciou suas primeiras tentativas para construir uma máquina calculadora. Em Paris, no anos de 1672, Leibniz estudou matemática e física com Christian Huygens de quem recebeu a sugestão de trabalhar com séries. Em 1673 Leibniz visita a Royal Society em Londres onde apresentou sua tentativa incompleta de construir sua calculadora. Nesta ocasião, em contatos com Hooke, Boyle e Pell ele se atualizou sobre os resultados mais recentes obtidos em séries. Mais tarde, embora ausente de Londres, Leibniz recebeu críticas na Royal Society, especialmente no que se referia à máquina de calcular. Estas críticas tiveram um efeito interessante sobre Leibniz. Ele percebeu que seus conhecimentos em matemática eram, de fato, incompletos e que necessitavam de aprimoramento. Sem se abater ele redobrou seus esforços se aprofundar nesta disciplina.
Leibniz foi aceito membro da Royal Society de Londres em 1673 e iniciou um estudo sobre a geometria dos infinitesimais, trocando correspondência sobres estes esforços com Oldenburg que, por sua vez, o informou sobre os avanços de Newton nesta área. Deve-se notar que, neste período, Leibniz não gozava de grande reputação com os membros Royal Society devido à sua incapacidade de concluir sua máquina calculadora. Simultaneamente Oldenburg desconhecia que ele havia, devido a seus esforços para se superar, se transformado em um gênio criativo da matemática.
Em Paris, na mesma época, Leibniz começou a desenvolver os princípios de sua versão do cálculo. Consciente de que, para o pleno desenvolvimento de uma ferramenta matemática, era necessária a adoção de uma notação consistente e de fácil manipulação ele dedicou um bom tempo para o estabelecimento de sua notação que é basicamente a mesma que usamos até hoje. é sabido que suas primeiras anotações eram confusas e de difícil leitura. Já em 1675 ele escreveu um artigo manuscrito onde usava pela primeira vez a notação \(f(x)dx.\) No mesmo artigo ele apresentou a regra para a diferenciação de um produto. Em 1676 Leibniz apresentou o conceito de diferencial, inclusive escrevendo
$$dx^n = n x^{n-1}dx,$$
para \(n\) inteiro ou fracionário.
Em 1696 Leibniz aceitou um cargo na biblioteca de Hanover, onde ficou até o fim de sua vida. Ele continuou mantendo contato com outros matemáticos da época e viajando pela Europa. Outros projetos foram iniciados neste período, tais como moinhos bombeadores de água para serem empregados em minas nas montanhas de Harz. Seus projetos tecnológicos não foram bem sucedidos mas suas observações sobre a geologia das montanhas o levaram a propor a hipótese de que a terra foi formada no passado por lava derretida.
Além de seus trabalhos em cálculo Leibniz obteve outros resultados importantes em matemática. Ele trabalhou com sistemas aritméticos binários e com o conceito de determinantes, usado na solução de sistemas de equações lineares. Sobre a mecânica ele questionou o sistema de Descartes e examinou os conceitos de energia potencial e cinética e de momento.
Leibniz era um homem atuante, que buscava difundir as idéias mais modernas e interagir com os demais pensadores de seu tempo. Ele esteve envolvido na formação de academias e sociedades científicas e não seria exagero dizer que ele esteve em contato com a maioria dos matemáticos da época. Um exemplo foi sua correspondência com Grandi, iniciada em 1703, onde se discutiu o paradoxo obtido ao se atribuir o valor \(x=1\) na expansão em série para
$$\frac{1}{a+x}= 1-x+x^2-x^3+⋯.$$
Na filosofia ele buscou aperfeiçoar seu sistema de redução do raciocínio a uma álgebra do pensamento. Ele publicou seu Meditationes de Cognitione, Veritate et Ideis (Reflexões sobre o Conhecimento, Verdade e Idéias) visando aperfeiçoar sua teoria do conhecimento. Em 1686 Leibniz escreveu Discours de Métaphysique e, em 1710, Théodicée onde tratava da questão da existência do mal em um mundo criado por Deus. Neste tratado ele afirmava que o mundo necessariamente teria que ser imperfeito, caso contrário não seria distinto de Deus. No entanto, deveria ser o mais perfeito possível sem, no entanto, violar a lei natural. A eliminação dos desastres naturais, segundo ele, envolveria alterações tão dramáticas na lei natural que resultariam em um mundo ainda pior. Em 1714 Leibniz escreveu Monadologia sintetizando sua obra filosófica.
Leibniz era um homem de interesse e atuação universais, um livre-pensador incansável. Profundamente dedicado ao entendimento mútuo entre pessoas, escolas e correntes de pensamento, ele deliberadamente optou por ignorar a fragmentação entre as disciplinas que, já naquela época, se instalava no ambiente das universidades. Ele julgava que uma eventual deficiência em sua formação em determinada disciplina não deveria ser um empecilho para que contríbuisse naquela área. De certa forma ele se mostrava hostil para com a instituição universitária porque julgava que sua estrutura rígida dificultava a interação entre disciplinas, essencial para o avanço do conhecimento. É interessante notar como um homem de interesse universalista, dedicado ao processo de compreensão mútua entre escolas de pensamento diversas, tenha se envolvido em uma disputa tão áspera e duradoura com outro grande gênio, como ocorreu com Newton sobre a autoria do cálculo.
A Polêmica Newton versus Leibniz
Durante as viagens que fez pela Europa Leibniz estabeleceu contato com diversos matemáticos importantes da época. Ele estudou matemática e física com Christian Huygens em Paris, em 1672 e esteve com Hooke e Boyle em Londres no ano de 1673. Na mesma ocasião ele adquiriu diversos livros sobre matemática, inclusive os trabalhos de Barrow, com quem manteve extensa correspondência. Retornando para Paris Leibniz realizou importantes contribuições na área do cálculo, julgando que seu trabalho fosse muito diferente do de Newton. Newton tratava as variáveis como funções do tempo enquanto Leibniz considerava suas variáveis \(x\) e \(y\) como valores assumidos sobre sequências de valores infinitamente próximos. Ele introduziu a noção de \(dx\) e \(dy\) como diferenças entre valores próximos dentro destas sequências. Leibniz sabia que podia calcular a inclinação da tangente como \(dy/dx\) mas não usou este fato como definição da reta tangente.
Para Newton a integração consistia de se encontrar fluentes para um dado fluxo e, desta forma, a complementariedade da diferenciação e da integração como operações inversas estava implícita. Leibniz usava a integração como uma soma, de forma muito similar àquela usada por Cavalieri e, mais recentemente, por Riemann. Ele também se sentia à vontade com o uso dos infinitesimais \(dx\) e \(dy,\) enquanto Newton usava a notação \(\dot x, \dot y\) que representavam velocidades finitas. Nem Leibniz nem Newton pensavam em termos de funções e sim em termos dos gráficos envolvidos. Para Newton o cálculo era formado por operações geométricas enquanto Leibniz fez maior progresso na direção da análise.
Leibniz tinha consciência de que a definição e adoção de uma boa notação era de fundamental importância e se dedicou com esforço a esta questão. Por outro lado seu rival, Newton, parecia escrever mais para si mesmo do que para um público geral e, como consequência, tendia a usar uma notação que variava a cada momento. A notação de Leibniz, \(d/dx\) enfatizava o aspecto de operador da derivação, o que se revelou muito importante para o progresso posterior da disciplina. Até o ano de 1675 Leibniz já tinha estabelecido a notação que hoje nos permite escrever coisas como
$$\int xdx = \frac{x^2}{2},$$
com notação usada nos dias de hoje. Seus resultados em cálculo integral foram publicados em 1684 e 1686 sob o nome de Calculus Summatorius. O nome moderno, cálculo integral, só apareceu como sugestão Jacob Bernoulli, em 1690.
Nesta época 1676 Newton escreveu uma carta para Leibniz, enviada por meio de Oldenburg. Nesta carta, que demorou para chegar ao destino, Newton apresentava uma lista de suas conclusões sem dar, no entanto, uma descrição de seus métodos. Leibniz respondeu imediatamente sem perceber que houvera demora tão grande no recebimento daquela carta. Por sua vez Newton acreditou que Leibniz tivera seis semanas para elaborar sua resposta, aperfeiçoando suas considerações sobre o cálculo com base em sua própria carta. Percebendo o descontentamento do colega Leibniz compreendeu que deveria publicar sem atraso uma descrição completa de seus próprios métodos. Uma segunda carta foi enviada a Leibniz em outubro de 1676 onde Newton, ainda que mantendo o tom cortês, sugeria que seus métodos e operações haviam sido plagiados. Leibniz respondeu dando mais detalhes sobre os fundamentos de seu cálculo diferencial e integral, incluindo a regra para a derivação de uma função composta.
Embora Newton reclamasse que Leibniz não havia resolvido nenhum novo problema é inegável que seus métodos e formalismo foram vitais para o desenvolvimento posterior do cálculo. Cabe lembrar que Leibniz nunca considerou a derivada como um limite, um conceito só desenvolvido mais tarde com o trabalho de d’Alembert.
Em 1684 Leibniz publicou em detalhes seu método sobre o cálculo diferencial em um jornal denominado Nova Methodus pro Maximis et Minimis, itemque Tangentibus… in Acta Eruditorum. Neste artigo ele usa a notação hoje familiar de \(df\) para a diferencial de uma função, as regras para a derivação de potências, produtos e quocientes de funções. No entanto nem todas as demonstrações estavam presentes. Em 1686 Leibniz publicou um novo artigo sobre o cálculo integral.
O livro de Newton, Principia, apareceu no ano seguinte. O método dos fluxos foi desenvolvido em 1671 mas permaneceu não publicado até 1736, com a tradução para o inglês de John Colson. Este atraso na publicação, em grande parte motivado pela relutância de Newton em aceitar a exposição e críticas dos colegas matemáticos foi o responsável pelo conflito e disputas com Leibniz.
Grande parte das atividades científicas de Leibniz em seus últimos anos de vida estava relacionada com esta disputa sobre a invenção do cálculo. Em 1711 um artigo na Transactions of the Royal Society of London o acusava de plágio. Este artigo, bem como os demais ataques, partiam de partidários de Newton e não dele próprio, diretamente. Em sua defesa Leibniz argumentou que não tivera contato com o cálculo dos fluxos até o conhecimento da obra de Wallis. Em resposta Keill afirmou que a carta enviada por Newton através de Oldenburg continha indicações claras de seu método. Em carta para a Royal Society Leibniz pediu uma retratação, o que motivou a formação de um comitê para julgar a questão. O comitê, formado pelo próprio Newton, julgou a questão sem dar a Leibniz o direito de defesa emitindo parecer favorável a Newton. O relatório final, escrito por Newton, atribuía a ele a autoria do cálculo. Leibniz publicou um panfleto anônimo, intitulado Charta Volans, onde narrava sua versão dos fatos e se utilizava, em sua defesa, de um erro de Newton sobre derivadas de segunda ordem e ordens superiores. Mais uma vez os partidários de Newton vieram a público em sua defesa mas Leibniz se recusou a levar adiante o debate. Ao receber correspondência de Newton, Leibniz respondeu com uma descrição detalhada de sua descoberta do cálculo diferencial.
Entre seus correspondentes Leibniz manteve com Samuel Clarke, um defensor de Newton, um debate sobre os conceitos newtonianos sobre espaço e tempo, ação à distância e atração gravitacional através do vácuo. Parte desta discussão afetou, mais tarde, o pensamento de Ernst Mach e, por sua vez, Albert Einstein, levando à construção da nova teoria mecânica e da atração gravitacional exposta pela Teoria da Relatividade. A defesa apaixonada da posição de Newton e a recusa em adotar a terminologia e notação de Leibniz fizeram com que os progressos do cálculo fossem retardados na Inglaterra, enquanto na Europa continental os seguidores de Leibniz promoviam um rápido avanço da ciência.
Desenvolvimentos Posteriores
George Berkeley
Nem Newton, nem Leibniz, nem seus seguidores imediatos foram capazes de estabelecer uma base rigorosa para o cálculo. Não estava claro como a soma de elementos muito pequenos, tais como \(f(x) dx\) deveria resultar em uma quantidade finita. Na mecânica, se \(\nabla x\) é a variação espacial ocorrida em um tempo \(\nabla t\), ambos infinitesimais, que sentido teria a velocidade instantânea, entendida como um quociente, \(v = \frac{\nabla x}{\nabla t}\)? A fundamentação rigorosa do cálculo teria ainda que aguardar por muitos anos. A ausência de um formalismo algébrico consistente e o apego aos métodos geométricos herdados dos gregos representou uma dificuldade para este avanço. Na visão de Leibniz a preocupação excessiva com o rigor ausente não deveria impedir o uso e os progressos da disciplina. Como sabemos hoje o conceito que faltava era exatamente o conceito de limite, só estabelecido rigorosamente no século XIX.
(6) O problema da braquistócrona consiste em encontrar a curva percorrida por uma partícula que se move sujeita a um campo gravitacional constante de modo que gaste, para isto, o menor tempo possível. Este problema impulsionou a criação do cálculo das variações.
Um grande esforço foi feito por diversos pensadores quando o bispo George Berkeley (1685-1753) divulgou em 1734 um panfleto intitulado The Analyst atacando a ausência de rigor que se verificava no cálculo da época. Novos progressos foram atingidos pelos seguidores de Newton e Leibniz, em parte na tentativa de responder a estes ataques. Entre eles estavam Jacob e Johann Bernoulli, discípulos de Leibniz. Nove membros da família Bernoulli se destacaram na matemática ou na física, sendo que os principais foram os irmãos Jakob (1654-1705) e Johann (1667-1748) e o filho deste, Daniel (1700-1782). A teoria das probabilidades, os princípios do cálculo e a integração das equações diferenciais foram algumas das contribuições dos Bernoulli.
Jakob (Jacques) Bernoulli estudou teologia mas desde cedo, apesar da oposição de seu pai, mostrou vocação para a matemática. Suas principais contribuições foram a descoberta, em conjunto com seu irmão Johann, de que a série harmônica é divergente, a solução do problema da braquistócrona(6), a demonstração do teorema do binômio para expoentes inteiros e positivos e a introdução dos polinômios e dos números de Bernoulli, de grande importância para demonstrações de diversos teoremas da álgebra e para o estabelecimento de fórmulas do cálculo. Ele também contribuiu para a geometria diferencial com seu estudo sobre geodésicas de uma superfície.
Johann (Jean) Bernoulli iniciou os estudos matemáticos com o irmão Jakob. Formou em medicina mas logo dedicou-se ao estudo do cálculo integral e diferencial. Estudou o movimento pendular e estabeleceu suas características e formulou conceitos matemáticos referentes à ótica. Durante um período que passou em Paris ele foi professor do marquês de L’Hospital (1661-1704) ensinando a ele a nova disciplina criada por Leibniz. Em seguida assinou um documento se comprometendo a enviar ao marquês suas descobertas matemáticas, em troca de um salário regular, para que ele as usasse como quisesse. Como resultado o marquês publicou como sua uma das mais importantes contribuições de Bernoulli, desenvolvida em 1694 e mais tarde conhecida como regra de L’ Hospital sobre indeterminações. A regra de Bernoulli afirma que, se \(f(x)\) e \(g(x)\) são diferenciáveis em \(x_0\) e satisfazem as condições \(f(x_0)=0\) e \(g(x0)=0\) então
$$ \lim_{x\to a} \frac{f(x)}{g(x)} = \lim_{x\to a} \frac{f'(x)}{g'(x)}$$
desde que exista este último limite. Embora não sendo o autor intelectual dos conceitos expostos L’ Hospital realizou um bom trabalho didático e de compilação de forma que seu livro, Analyse des infiniment petits, publicado em Paris, 1696, foi amplamente utilizado até o final do século XVIII.
O segundo filho de Johann, Daniel Bernoulli, estudou lógica, filosofia e medicina, assumindo a posição de professor de mecânica, física e medicina. Considerado por alguns historiadores como o fundador da física matemática ele formulou o princípio da conservação de áreas, que complementa o princípio da conservação de massa de Newton e dedicou-se a diversos campos do conhecimento científico, como a fisiologia, a astronomia, o magnetismo, as correntes oceânicas e as marés. Em sua obra mais importante ele analisa as propriedades dos fluidos, formula a teoria cinética dos gases e expõe o teorema de Bernoulli, segundo o qual a pressão de um fluido diminui quando sua velocidade aumenta.
Historicamente sempre houve a necessidade de se representar funções, pelo menos como uma aproximação, por meio de polinômios. Como vimos foi desta forma que Newton e outros realizaram as primeiras operações de derivação e integração. Além disto existe a necessidade prática de se calcular o valor de diversas funções para uso em aplicações. Tábuas de valores para as funções logaritmo e trigonométricas eram necessárias para o uso na astronomia, cartografia e navegação, entre outros. Uma forma simples para a obtenção de tais tábuas era a de interpolar valores, ou seja, conhecidos os valores de uma função em dois pontos próximos os valores intermediários podiam ser obtidos por interpolação linear, supondo que a função fosse linear entre estes valores. Matematicamente, se conhecemos \(f(a)\) e \(f(b)\) então\(f(x)\) pode ser aproximada pela reta
$$y(x) = f(a) + \frac{f(b)-f(a)}{b-a}(x-a),$$
pelo menos para pontos interiores ao intervalo \([a,b]\) e esta aproximação será tanto melhor se a e b estiverem próximos. Observe que se \(b\) é tomado arbitrariamente próximo de \(a\) então temos a equação da tangente à curva de f(x) no ponto \(x=a:\)
$$ y(x) = f(a) + \frac{df}{dx}|_{x=a}(x-a).$$
Tangente e secante
Logo se tornou claro que aproximações mais refinadas poderiam ser obtidas aproximando-se a função por polinômios de ordem superior. Em 1624 um matemático chamado Briggs já utilizava esta abordagem. Uma generalização foi obtida por Newton em 1676 e, de modo independente, por James Gregory em 1670. Estas expansões, além de permitir o cálculo de valores para funções com precisão arbitrária também servia na avaliação de integrais e cálculos de áreas, reduzindo a operação de integrar uma função genérica à integração de \(x^n\) através da fórmula de Fermat,
$$\int x^ndx = \frac{x^{n+1}}{n+1}.$$
No esforço de sistematizar e estabelecer critérios de rigor para o cálculo, grandes progressos forma conseguidos por matemáticos do século XVIII, quando surgiram as teorias das Equações Diferenciais, das Séries Infinitas, da Geometria Diferencial, Cálculo das Variações e tópicos de análise. Neste período viveram matemáticos importantes como Taylor, Euler, d’Alembert, Lagrange e Laplace.
Um resultado já obtido por Gregory e Leibniz, mas só publicado em 1715 por Brook Taylor (1685-1731) estabelece formalmente a expansão de funções diferenciáveis em séries de potências. Matemático inglês, Taylor escreveu o primeiro tratado sobre o cálculo das diferenças finitas, estudou tópicos diversos em matemática, sobre a trajetória da luz num meio homogêneo, a freqüência das vibrações e oscilação transversal de uma corda. A fórmula de Taylor é a seguinte: uma função analítica \(f\) pode ser aproximada em uma vizinhança do ponto \(x=a\) pelo polinômio de grau \(N\) como
$$f(x)=\sum_{n=0}^N \frac{1}{n!}f^n(a)(x-a),$$
onde definimos
$$ f^{(n)}(a) = \frac{d^n f}{dx^n}\Biggl\arrowvert _{x=a},\;\;f^{(0)}(a)=f(a),\;\;0!=1.$$
Por analogia com a teoria das funções de variáveis complexas dizemos que uma função é analítica quando possui derivadas de todas as ordens e estas derivadas são contínuas. Portanto, uma função é analítica se, e somente se, possui expansão de Taylor. Um caso particular desta expansão foi publicado em 1742 por Colin MacLaurin (1698-1746), onde se fazia \(a=0\). Taylor, como seus contemporâneos, não trabalhava com o conceito de limite. Ele simplesmente fazia os desenvolvimentos em termos de uma quantidade suposta infinitesimal, digamos \(\nabla h\), e ao final da operação tomava \(\nabla h=0\). Esta falta de rigor dos primeiros tempos do cálculo, em flagrante contraste com rigor atingido pelos geômetras gregos, alimentaram a oposição daqueles que se opunham ao cálculo.
Por muitos anos os matemáticos trabalharam com as expansões em séries de potência até uma ordem \(N\), como se as funções pudessem ser fielmente representadas por polinômios. Diferenciações e integrações eram obtidas operando-se no polinômio, termo a termo. Embora este procedimento estivesse correto algumas vezes também dava origem a resultados incorretos e até absurdos. O que estava faltando eram a noção de convergência de uma série e os testes para estabelecer esta convergência. A própria noção de limite não estava estabelecida com clareza.
Leonhard Euler
Um passo importante para a rigorização do cálculo foi obtido por Euler. Leonhard Euler (Suiça: 1707-1783) foi um matemático de interesses variados e que produziu uma extensa obra científica. Como estudante Euler mostrou precocidade, despertando a atenção dos principais matemáticos de sua época, como Jean Bernoulli e seus filhos. Ele produziu trabalhos sobre Mecânica, Astronomia, ótica, Cartografia, Acústica, entre outros tópicos da Física. Euler foi um dos primeiros cientistas a defender a teoria ondulatória da luz, em oposição à teoria corpuscular de Newton, amplamente adotada na época. Na matemática ele expôs os fundamentos de sua contribuição na obra Introductio in analysim infinitorum (Introdução à análise dos infinitos) publicada em 1748. Euler trabalhou sobre os fundamentos da geometria analítica e do cálculo, desenvolveu a teoria das funções trigonométrica e logaritmica e simplificou as operações relacionadas à análise matemática. Além disto trabalhou na teoria dos números e criou o Cálculo Variacional, o estabelecimento de pontos críticos de funcionais, ou funções que dependem de outras funções, hoje uma das ferramentas básicas da física, particularmente na mecânica clássica e quântica e na teoria das partículas e campos. Ele foi o fundador da Mecânica Analítica, um aperfeiçoamento formal da mecânica newtoniana com poder de cálculo bastante superior aos métodos usados por Newton e estabeleceu os fundamentos da Geometria Diferencial, que consiste no estudo de curvas e superfícies por meio dos métodos do cálculo, generalizado mais tarde por Riemann em sua geometria de curvas e hiper-superfícies de qualquer dimensão.
Euler escreveu inúmeros livros e artigos científicos, mesmo após ter perdido a visão aos sessenta anos. Ele foi o responsável pela adoção de diversos símbolos hoje consagrados na literatura da matemática, tais como a letra grega \(\Sigma\) para indicar uma soma e a letra \(e\) para designar a base dos logaritmos naturais ou neperianos, \(e^x\) para a função exponencial. A famosa fórmula de Euler, \(e^{i\theta} =cos \theta + i \mbox{sen} \theta\) foi obtida quando se buscava uma interpretação coerente para o logaritmo de números negativos. Esta expressão já era conhecida por Jean Bernoulli e outros mas só foi expressa claramente por Euler. Fazendo \(\theta=\pi\) na expressão acima temos que \(e^{i\pi}=-1\) e, portanto, \(ln(-1) = \pi i,\), um número imaginário puro.
Em meados do século XVIII uma grande renovação intelectual teve início na França. Juntamente com Voltaire, Rousseau e Diderot, Jean Le Rond d’Alembert (França: 1717-1783) empreendeu a edição da célebre Encyclopédie que tanta ressonância teve naquele século e assentou a base cultural do movimento que culminou na revolução francesa de 1789. Recém nascido, d’Alembert foi abandonado por pais de origem aristocrática nos degraus da igreja de St. Jean Baptiste Le Ronde, de onde tirou seu nome, tendo sido recolhido por pessoas humildes que o criaram. Mais tarde, já um matemático de renome, ele haveria de recusar a reaproximação da mãe biológica, dando preferência a ser conhecido como filho de seus humildes pais adotivos.
d’Alembert estudou Direito e Medicina mas abandonou as estas atividades para se dedicar exclusivamente à matemática. Em 1741 publicou sua obra Traité de dynamique onde estabelece que a lei de ação e reação postulada por Isaac Newton também se aplica aos corpos sólidos rígidos, estudo de profunda relevância no projeto e construção de estruturas construídas para suportar grandes cargas. Ele também fez contribuições para a mecânica de fluidos, astronomia e ótica. No cálculo ele se opunha ao uso que Euler fazia das diferenciais de uma função, supondo que são quantidades nulas embora qualitativamente diferentes de zero. Em seu artigo para a Encyclopédie sob o verbete diferencial ele escreveu que “a diferenciação de equações consiste simplesmente em achar os limites da razão de diferenças finitas de duas variáveis na equação”. Este ponto de vista afasta a noção da diferencial como grandezas infinitesimalmente pequenas. A formulação de limites de d’Alembert não foi exposta sob forma clara e não foi aceita por seus contemporâneos que continuaram a usar a linguagem de Leibniz e Euler. Esta situação durou até o século XIX.
DAlembert, Laplace, Lagrange e Monge
O matemático e físico Joseph Louis de Lagrange (Itália: 1736-1813) teve importância decisiva para o desenvolvimento da teoria dos números, do cálculo e da mecânica celeste. Ele estudou o movimento da Lua e publicou vários trabalhos contendo notas complementares à gravitação newtoniana, sobre a teoria dos números, probabilidade e equações diferenciais e análise de problemas algébricos, precursores da teoria de grupos, desenvolvida mais tarde por évariste Galois.
Lagrange escreveu bem menos que Euler mas manteve sempre em seus escritos grande rigor e cuidados, o que lhe valeu a fama de maior matemático de seu século. Em sua obra principal, Mécanique Analytique (1788) Lagrange propôs um formalismo aperfeiçoado para o estudo da mecânica analítica, o que estabeleceu esta disciplina em definitivo como um ramo da análise matemática. Em 1797 ele publicou Théorie des Fonctions Analytiques onde procurou as bases algébricas do cálculo, sem a necessidade da consideração de quantidades infinitesimais. Partindo do desenvolvimento em séries de potências para uma função, estabelecido por Taylor, ele apresentava suas derivadas em termos dos coeficientes da expansão. Sua obra representou a fundação do maior rigor que seria alcançado no século XIX.
O físico, matemático e astrônomo francês, Pierre Simon Laplace (França: 1749-1827) pesquisou eletromagnetismo, probabilidade e mecânica celeste. De origem modesta, ele se destacou quando estudante e foi recomendado por d’Alembert para o cargo de professor da Escola Militar de Paris, em 1769. Ele chegou a colaborar com Lavoisier no estudo dos processos químicos em biologia, mostrando que a respiração orgânica é uma forma de combustão produzida pela oxidação de substâncias orgânicas. Laplace realizou uma compilação das teorias astronômicas de Isaac Newton, Edmundo Halley e outros cientistas cujas obras encontravam-se dispersas e, em seguida, realizou cálculos cuidadosos sobre os efeitos da gravitação de cada planeta sobre os demais corpos do sistema solar, descobrindo que as órbitas ideais propostas por Newton apresentavam desvios. Em seus estudos associados à atração gravitacional Laplace estudou a equação diferencial
$$ \frac{\partial^2 \phi}{\partial x^2} + \frac{\partial^2 \phi}{\partial y^2} + \frac{\partial^2 \phi}{\partial z^2} =0,$$
que deveria ser satisfeita para potencial gravitacional \(\phi,\) no vácuo. A mesma equação pode ser escrita, em notação moderna, \(\nabla ^2 \phi =0\), onde \(\nabla\) é o operador vetorial \((\partial_x, \partial_y, \partial_z )\). No entanto esta equação apareceu pela primeira vez em um artigo de Euler sobre hidrodinâmica, em 1752.
Em Exposition du Système du Monde (1796) Laplace propôs a teoria da formação nebular para o sistema solar que leva seu nome. Seus trabalhos sobre a teoria da probabilidade tornaram-se amplamente conhecidas e respeitados. Laplace estudou a transformação de uma função em outra, hoje denominada transformada de Laplace, \(\mathcal L \left[f(t)\right]\) definida como a integral imprópria
$$ F(s) = \mathcal L \left[ f(t)\right] = \int_0 ^\infty e^{-st}f(t)dt, $$
mais tarde utilizadas pelo engenheiro elétrico Oliver Heaviside (1850-1925) para a construção de um método para a solução de equações diferenciais particularmente importante no estudo de sistemas elétricos e mecânicos envolvendo oscilações, amortecimentos e fenômenos correlatos.
O trabalho desenvolvido por mais de quarenta anos por Adrien Marie Legendre (França: 1752-1833) no setor das integrais elípticas forneceu instrumentos analíticos básicos para a física matemática. Ainda jovem Legendre foi nomeado professor de matemática da Escola Militar. Ele escreveu quatro dissertações sobre a atração dos esferóides. Na primeira, de 1783, estudou as funções que receberam seu nome e são soluções para a equação diferencial
$$\left(1-x^2 \right) y” – 2xy’ + l(l+1)y =0,$$
que surgem frequentemente em problemas que envolvem simetria esférica, tais como o potencial elétrico em torno de distribuições esféricas de cargas e a distribuição eletrônica no átomo de hidrogênio. As soluções podem ser obtidas pelo método de séries de potências fazendo \(y=\sum_0 ^\infty a_n x\). Para o caso de \(l\) inteiro não negativo a série infinita é truncada para um valor de \(n\) e as soluções são os polinômios de Legendre:
$$P_0(x) = a_0,\,P_1(x) = a_1 x,\, P_2(x) = a_0,\,\left(1-3x^2 \right) a_0,\, P_3(x) = \left(x-\frac{5}{3}x^3 \right) a_1,\,\ldots.$$
(7) Em 1896 foi mostrado que \(\pi(n) \to n\ln n\).
Legendre adquiriu notoriedade por obra éléments de géométrie (1794), escrita, nas palavras do autor, “para satisfazer o espírito” onde ele procurava manter um alto nível de rigor formal. Legendre desenvolveu o método dos mínimos quadrados e, em 1798, publicou o primeiro livro exclusivamente à teoria dos números onde contribuiu para assentar as bases de um dos mais famosos problemas da aritmética, o da distribuição dos números primos. Já era conhecido, desde Euclides, que os números primos são infinitos. Embora seja claro que a densidade dos primos diminua para inteiros crescentes muitos estudiosos procuraram a regra de descrição desta densidade \(\pi(n)\), que expressa o número de primos menores que \(n\). Legendre fez conjecturas aproximadas para a solução desde problema(7).
Os trabalhos de Legendre, apesar do impulso dado ao crescimento da matemática, foram superados rapidamente pelos esforços de Carl Friedrich Gauss, em aritmética, e Niels Abel e Karl Jacobi, nas funções elípticas. Ele não mostrava grande simpatia para com Gauss, mas recebeu com entusiasmo as contribuições de Abel e Jacobi. Numa demonstração de altruísmo Legendre divulgou estes trabalhos com prazer, embora elas tornassem obsoletos os esforços de toda sua vida.
Vimos que o estabelecimento das séries de potência para a representação de funções sempre representou um papel importante no estabelecimento do cálculo, tanto para a operação de derivação como para a integração. Mas um novo formalismo para a descrição de funções como séries infinitas estava ainda por ser encontrado por Jean Baptiste Joseph Fourier (França: 1768-1830).
Fourier era filho de um alfaiate e mostrou cedo ter grande talento para a matemática. Ele participou ativamente na revolução francesa de 1789. Em 1795 se tornou professor da recém-criada école Normale e, em seguida, da école Polytechnique. Aproveitando-se de suas viagens ao Egito, motivadas pelo trabalho em política, Fourier fez estudos sobre a civilização antiga daquele povo e deixou contribuições notáveis no campo da egiptologia.
Fourier estava interessado em aplicar o formalismo matemático na solução de problemas físicos. Em sua obra mais importante, Théorie analytique de la chaleur (1822), ele mostrou que a condução do calor em corpos sólidos pode ser expressa por meio de séries trigonométricas infinitas. As séries trigonométricas propostas por Fourier se baseiam na ortogonalidade das funções seno e cosseno:
$$\frac{1}{l} \int_{-l}^{l} \cos \frac{n \pi x}{l} \cos \frac{m \pi x}{l} = \delta_{mn};\;\; \frac{1}{l} \int_{-l}^{l}\mbox{sen} \frac{n\pi x}{l} \mbox{sen} \frac{m\pi x}{l} =\delta_{mn}
$$
$$\int_{-l}^{l} \cos \frac{n\pi x}{l} \mbox{sen} \frac{m\pi x}{l} = 0.$$
onde \(\delta_{mn}\) é o símbolo de Kronecker,
$$\delta_{mn}=\left\{ \begin{array}{ll} 1, \mbox{ se } m = n \\
0, \mbox{ se } m \ne n
\end{array} \right.$$
(8) Basta que \(f\) e \(f′\) sejam seccionalmente contínuas, ou seja, contínuas em subintervalos da região considerada.
É possível então escrever uma expansão em séries trigonométricas para uma função contínua com derivada contínua(8) e periódica com período \(2l\) da seguinte forma:
$$f(x) = \frac{a_0}{2}+\sum_{n=1}^\infty\left(a_n\cos\frac{n\pi x}{l} + b_n\mbox{sen}\frac{n\pi x}{l} \right),$$
onde os coeficientes \(a_n\) e \(b_n\) são dados por
$$a_n=\frac{1}{l}\int_{-l}^{l}f(x)\cos\frac{n\pi x}{l}dx,\,\,b_n=\frac{1}{l}\int_{-l}^{l}f(x)\mbox{sen}\frac{n\pi x}{l}dx,$$
Fourier
Em uma apresentação para a Academia de Ciências de Paris, em 1807, Fourier descreveu seu trabalho afirmando que qualquer função poderia ser representada por uma série desta forma. Lagrange, presente à reunião, ficou surpreso e negou em termos definitivos que tal coisa pudesse ser correta. Embora tenha exagerado na generalidade do método, o trabalho de Fourier motivou uma grande quantidade de pesquisas em andamento até os dias de hoje, sobre as condições impostas à função para que seja representável desta forma e os critérios de convergência. As séries de Fourier estão geralmente associadas ao tratamento das equações diferenciais parciais e se aplicam a um grande número de problemas físicos e matemáticos, inclusive no tratamento de sinais, na compactação de informações e na base do formalismo matemático da mecânica quântica. Uma generalização deste conceito resulta na transformada de Fourier, que pode ser obtida heuristicamente pela tomada do limite \(l \to \infty.\)
Um trabalho importante para o estabelecimento do rigor no cálculo foi realizado pelo tcheco Bernhard Bolzano (1781-1848), um sacerdote católico que se dedicou ao estudo da filosofia e da matemática. Bolzano era um ativista em favor das reformas que buscavam a diminuição das desigualdades sociais, da condenação do militarismo e da guerra e pela liberdade de pensamento. Na matemática ele definiu, em 1817, o conceito de continuidade de uma função nos moldes em que hoje o conhecemos e criou o critério de convergência hoje chamado de “critério de Cauchy”. Ele também demonstrou o teorema do valor intermediário e o teorema de Bolzano-Weierstrass. Um de seus objetivos era o de estabelecer uma base formal e analítica para os métodos do cálculo, eliminando das demonstrações a intuição geométrica. Seus escritos, às vezes considerados pouco claros e excessivamente voltados para os fundamentos, receberam pouca divulgação e só foram devidamente apreciados na década de 1870.
Mais um dos responsáveis pelo lançamento das bases rigorosas do cálculo foi Augustin Louis Cauchy que viveu na França de 1789 a 1857. Cauchy foi considerado um dos matemáticos mais importantes dos tempos modernos. Formado em engenharia, publicou grande quantidade de artigos matemáticos e solucionou um problema proposto por Lagrange que estabelece uma relação entre o número de lados, vértices e faces de um poliedro convexo. Em 1814 publicou um trabalho sobre integrais definidas, que serviria de base para o desenvolvimento da teoria das funções complexas e, no ano seguinte, estudou os grupos de permutação, impulsionando a moderna teoria dos grupos.
Cauchy realizou trabalhos sobre mecânica, propagação das ondas e hidrodinâmica. Em 1822 lançou as bases da teoria matemática da elasticidade. Suas principais contribuições para a matemática, sempre pautadas pelo rigor e clareza dos métodos empregados, estão expostas em três grandes tratados: Cours d’analyse de l’école Royale Polytechnique (1821), Le Calcul infinitésimal (1832) e Leçons sur les applications du calcul infinitésimal à la géométrie (1826-1828).
Quatro anos após o surgimento do trabalho de Bolzano, que Cauchy desconhecia, ele publicou seu Cours d’analyse onde aparecem as definições de limite, continuidade de funções e o chamado critério de convergência, já desenvolvido por Bolzano e que leva seu nome. Ele também fez contribuições importantes para a álgebra linear e teoria dos determinantes. O próprio conceito de determinante, que recebeu de Cauchy esta designação, já havia sido empregado por Gauss mas só foi definitivamente incorporado à matemática graças a Cauchy.
A primeira demonstração correta da convergência das séries de Fourier e as condições sobre as funções para que esta convergência ocorra foi obtida em 1829 por Peter Gustav Lejeune Dirichlet (1805-1859). A definição de função usualmente apresentada nos cursos de cálculo modernos é basicamente a mesma apresentada por Dirichlet em 1837. A seguinte ““função de Dirichlet” foi proposta por ele para mostrar a generalidade do conceito de função:
$$\phi(x)=\left\{ \begin{array}{ll} a, & \mbox{ se } x \mbox{ é racional }\\
b, & \mbox{ se } x \mbox{ é irracional }
\end{array}\right.$$
Riemann
Esta função impulsionou Riemann a realizar estudos mais aprofundados sobre a teoria da integração. Apesar de ser mais conhecido pelas suas contribuições em análise e equações diferenciais Dirichlet foi também um grande pesquisador da teoria dos números.
(9) Uma função é analítica em uma região \(R\) se ela é derivável em todos os pontos de \(R\).
George Friedrich Bernhard Riemann (Alemanha: 1826-1866) influenciou profundamente a geometria e a análise. Embora sendo um matemático de idéias profundas e inovadoras Riemann era uma pessoa tímida e não gostava de exposição. Como estudante em Göttingen e Berlim ele se interessou pela teoria dos números primos, as funções elípticas e a geometria, que relacionou com as teorias mais modernas da física de sua época. Em 1851 doutorou-se com uma tese sobre os fundamentos de uma teoria geral das funções, estabelecendo relações entre os números complexos e a geometria. Nesta tese aparece uma sistematização das condições, já conhecidas no tempo de Euler, que uma função de uma variável complexa \(f(z)=u(x, y)+iv(x, y)\) deve satisfazer para ser uma função analítica(9), as chamadas equações de Cauchy-Riemann:
$$ \frac{\partial u(x,y)}{\partial x} = \frac{\partial v(x,y)}{\partial y}, \;\;\;\;
\frac{\partial u(x,y)}{\partial y} = -\frac{\partial v(x,y)}{\partial x}.
$$
Em notação mais compacta podemos escrever \(u_x=v_y,\,\,u_y=−v_x\).
Após um levantamento feito sobre o desenvolvimento histórico das séries trigonométricas, de d’Alembert a Dirichlet, Riemann percebeu que seria necessário estabelecer uma interpretação inequívoca da integração de uma função, desenvolvendo a integral de Riemann, e aplicando-a ao estudo das séries trigonométricas. A integral de Riemann pode ser definida da seguinte forma: se \(f\) é uma função real limitada, definida no intervalo \([a, b]\), construímos partições deste intervalo, \(a=\xi_0 \lt \xi_1 \lt \ldots \lt \xi_n = b\). Para cada partição definimos as somas
$$ S=\sum+{i=1}^n\left(\xi_i – \xi_{i-1} \right) M_i;\,\, s = \sum+{i=1}^n\left(\xi_i – \xi_{i-1} \right) m_i)$$
onde \(M_i\) e \(m_i\) são, respectivamente, o maior e o menor valor assumidos por \(f\) no subintervalo \([\epsilon_{i-1}, \epsilon_{i}]\). A integral superior \(\) e a integral inferior de Riemann são definidas assim:
$$ \overline{\int}_a ^b f(x)dx = \mbox{ inf } S, \;\; \underline{\int}_a ^b f(x)dx = \mbox{sup } s,$$
onde inf e sup são respectivamente o ínfimo e o supremo, consideradas todas as possíveis partições do intervalo. Se os dois valores são iguais então se diz que a função é integrável à Riemann e sua integral é denotada simplesmente por \(\int_a ^b f(x)dx\).
Figura 4: Integral de Riemann
Em 1854 o matemático, ao preparar uma dissertação para ingressar como professor assistente em Göttingen, Riemann abandonou os postulados da geometria euclidiana e formulou uma geometria mais geral, que englobava as geometrias de Nikolai Lobatchevski e János Bolyai, que ele desconhecia. Sua conferência, intitulada Sobre as hipóteses que estão nos fundamentos da geometria, se tornou célebre pela profundidade e generalidade dos conceitos apresentados. Nela ele não apresentava nenhum exemplo específico de seus conceitos e propunha o estudo de uma geometria como o estudo de variedades com qualquer número de dimensões em qualquer tipo de espaço, não necessariamente formado por conjuntos de pontos ou retas. A distância entre dois pontos infinitesimalmente próximos, na geometria euclidiana é dada por
$$ds^2 = dx^2 + dy^2 + dz^2,$$
o que é apenas uma dupla aplicação do teorema de Pitágoras. Riemann generalizou este conceito para tratar espaços onde estas distâncias são dadas por
$$
ds^2 = \left[dx\;\;dy\;\;dz \right]
\left[ \begin{array}{lll} g_{11} & g_{12} & g_{13} \\
g_{21} & g_{21} & g_{23} \\
g_{31} & g_{32} & g_{33} \\
\end{array} \right]
\left[ \begin{array}{l} dx \\ dy \\ dz \end{array} \right]
$$
no caso de três dimensões. Generalizando para um espaço de \(n\) dimensões, e usando uma notação mais compacta
$$ ds^2 = \sum_{i=1}^n \sum_{j=1}^n g_{ij}dx_i dx_j$$
onde denotamos \(x=x_1\), \(y=x_2,\), \(z=x_3,\) etc. A matriz \(G= \left\{ g_{ij}\right\}\) é denominada a métrica do espaço. Observamos que a geometria euclidiana, em \(\Bbb R^3\), é um caso particular onde
$$\left\{ g_{ij}\right\} = \left\{ \delta_{ij}\right\}=\left\{
\begin{array}{lll}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
\end{array}
\right\}
$$
é a métrica de Euclides. Este formalismo foi utilizado por Albert Einstein em sua Teoria da Relatividade Geral.
História dos Números Complexos
As equações do segundo grau apareceram na Matemática aproximadamente 1700 anos antes de Cristo, registradas nas tabuletas de argila da Suméria. Em alguns casos elas levavam a raízes de números negativos que, em geral, eram descartadas. O primeiro exemplo de raiz de número negativo foi publicado, aproximadamente em 75 d.C. por Heron, em um cálculo sobre o desenho de uma pirâmide em que surge a necessidade de avaliar a raiz \(\sqrt{84-100}\). Heron, no entanto, simplesmente substituiu este número por \(\sqrt{100-84}\).
Capa de Aritmetica Diofanto, edição 1621
Aproximadamente no ano 275 d.C. Diofanto de Alexandria, resolvendo um problema geométrico, chegou à equação
$$24x^2 -172x+366=0$$
cujas raízes são \(x=(±43\sqrt{-167})/12\). Ele continuou sem dar maiores explicações sobre o significado da raiz de um número negativo. Por volta de 850 d.C. o matemático indiano Mahavira afirmou que “… como na natureza das coisas um negativo não é um quadrado, ele não tem, portanto raiz quadrada”. Bhaskara (1114 – 1185 aproximadamente) afirmou: “O quadrado de um afirmativo é um afirmativo; e a raiz quadrada de um afirmativo é dupla: positiva e negativa. Não há raiz quadrada de um negativo pois ele não é um quadrado.”
O matemático Luca Paccioli (1445 – 1514) publicou em 1494 que a equação \(x^2+c=bx\) é solúvel se \(b^2\ge 4c\) e o francês Nicola Chuquet (1445 – 1500) faz observações semelhantes sobre “soluções impossíveis” em uma publicação de 1484.
Gerônimo Cardano (1501 – 1576) considerava que o surgimento de radicais negativos na resolução de um problema apenas indicava que o mesmo não tinha solução, mas apesar disso resolveu um problema que consiste em dividir um segmento de comprimento 10 em duas partes tal que o produto delas seja 40, a partir da equação \(x(10-x)=40\) ou \(x^2-10x+40=0\), cujas soluções são \(x=5±\sqrt{-15}\). Cardano sustentava que esta equação não tem solução, mas observou que a soma das duas raízes é 10 e seu produto é 40, desde que se aceite que \((\sqrt{-15})^2=15\).
Embora a solução de equações do segundo grau já demandem a existência dos complexos, o reconhecimento da necessidade destes só surgiu na resolução da equações do terceiro grau, dos seguintes tipos:
$$x^3 + a x=b;\;\; x^3=ax+b \mbox { e } x^3+b=ax.$$
Em 1545 Cardano publicou uma fórmula para resolver equações do terceiro grau, que ficou conhecida por “Fórmula de Cardano”. Sabemos, no entanto, que ele recebeu de Tartaglia (1500 – 1557 aproximadamente) a sugestão para esta fórmula. Raphael Bombelli (1526 – 1573) um admirador de Cardano, decidiu escrever um livro sobre os mesmos assuntos procurando explorar o assunto com maior clareza, e o publicou em 1572. Neste livro, enquanto resolvia a equação \(x^3=15x+4\) pela fórmula de Cardano encontrou a raiz
$$x=\sqrt[3]{2 + \sqrt{-121} } + \sqrt[3]{2 – \sqrt{-121} },$$
solução desprezada por Cardano como sendo “irredutível”. Bombelli, no entanto, propôs o que ele mesmo chamou de “idéia louca”, a sugestão de que \(\sqrt{-1}\) pudesse ser usado matematicamente desde que observadas algumas regras (aquelas que hoje chamamos de álgebra dos complexos). Neste caso o número \(a+b \sqrt{-1}\) é raiz de \(2 + \sqrt{-121}\) se \(\left( a+b\sqrt{-1}\right)^3=2+\sqrt{-121}\) ou, após manipulação algébrica, \(a=2\) e \(b=1\). Desta forma a raíz citada acima pode ser escrita como
$$x= \left( 2+\sqrt{-1}\right) + \left( 2-\sqrt{-1}\right) =4,$$
uma solução real que pode ser verificada diretamente na equação cúbica a ser resolvida.
Uma das dificuldades que Bombelli se deparava era a de não possuir uma notação adequada para seus cálculos. Ele usava uma notação sincopada, uma forma resumida da descrição literal que era feita anteriormente. Por exemplo, ele escrevia
$$x=\sqrt[3]{2 + \sqrt{-121} } \;\; \mbox{ como } \;\; R_c \lfloor \lfloor 2p R_q \lfloor \lfloor 0 – 121 \rfloor\rfloor \,\rfloor\rfloor.$$
Observe que nesta época nem mesmo o entendimento dos números negativos estava totalmente consolidado, sendo que \(-121\) era escrito como \(0-121\). Mesmo assim ele pode mostrar o papel importante que os números conjugados complexos viriam a desempenhar no futuro. Efetivamente o símbolo \(\sqrt{-1}\) foi usado pela primeira vez por Albert Girard em 1629, quando enunciou claramente as relações entre raízes e coeficientes de uma equação.
O uso de \(i\) como unidade imaginária, \(i=\sqrt{-1}\), foi adotado por Euler em 1777, mas só publicado em 1794 em seu Institutionum calculi integralis. Ele observou na época que \(ii=-1\) o que leva à \(1/i=-i\). O símbolo se tornou amplamente aceito após seu uso por Gauss em 1801. Embora os termos real e imaginário já tivessem sido usados René Descartes em 1637, a expressão número complexo só foi introduzida por Gauss em 1832.
A partir do trabalho de Bombelli os números complexos passaram a ser usados, mesmo que se duvidasse de sua existência. A primeira tentativa para atribuir um significado concreto aos números complexos por meio de uma “interpretação geométrica” é devida a John Wallis (1616 – 1703) em um trabalho que discutia a impossibilidade da existência de quantidades imaginárias e comparando este tema com questão à existência de quantidades negativas.
Em 1702 Jean Bernoulli afirmou que um número e seu oposto tem o mesmo logaritmo. Esse fato intrigou os matemáticos do início do século XVIII, que não sabiam como atribuir um valor ao logaritmo de um número negativo. Coube a Euler, em 1747, explicar a questão em uma carta dirigida a d’Alembert.
Em 1707 Moivre publicou a solução da equação de grau ímpar, por um método análogo ao de Cardano. A fórmula de Moivre,
$$\left( \cos \theta +i\mbox{sen} \theta \right)^n = \cos (n \theta) +i\mbox{sen}(n\theta)$$
foi publicada em 1722 para alguns casos particulares do argumento [/latex]\theta[/latex]. Em1748 Euler, além de demonstrar a validade da fórmula para o caso geral, estendeu sua validade para todo expoente real, estabelecendo definitivamente a existência de raízes no campo complexo.
A formalização completa dos números complexos como pares ordenados de números reais foi desenvolvida em 1833 por Hamilton (1805 – 1865) e em 1847 por Cauchy (1789 – 1857).
Equações Diferenciais
Equações diferenciais são um ramo importante do cálculo e da análise matemática e representam, provavelmente, a parte da matemática que maior número de aplicações encontra na física e na engenharia. Sua história tem origem no início do cálculo, desenvolvido por Newton e Leibniz no século XVII. Equações que envolvem as derivadas de uma função desconhecida logo apareceram no cenário do cálculo, mas, com igual rapidez se constatou que elas não são sempre fáceis de serem resolvidas. As mais simples são aquelas que podem ser diretamente integradas, por meio do uso do método de separação de variáveis, desenvolvido por Jakob Bernoulli e generalizado por Leibniz.
No século XVIII muitas equações diferenciais começaram a surgir no contexto da física, astronomia e outras aplicações. A equação de Newton para a gravitação universal foi usada por Jakob Bernoulli para descrever a órbita dos planetas em torno do Sol. Já nesta época ele podia usar as coordenadas polares e conhecia a catenária como solução de algumas equações. Halley usou os mesmos princípios para estudar o movimento do cometa que hoje tem o seu nome. Johann Bernoulli, irmão de Jakob, foi um dos primeiros a usar os conceitos do cálculo para modelar matematicamente fenômenos físicos e usar equações diferenciais para encontrar suas soluções. Ricatti (1676 – 1754) levou a sério o estudo de uma equação particular que levou o seu nome e, mais tarde, foi também estudada pelos irmãos Bernoulli. Taylor foi o primeiro a usar o desenvolvimento de funções em séries de potência para encontrar soluções. Não havia, no entanto, uma teoria global ou unificada sobre esta técnica.
Adrien Marie Legendre
Leonhard Euler, o primeiro matemático a compreender profundamente o significado das funções exponencial, logaritmica e trigonométricas, desenvolveu procedimentos gerais para a solução de equações diferenciais. Além de usar as funções elementares ele desenvolveu novas funções, definidas através de suas séries de potências como soluções de equações dadas. Sua técnica dos coeficientes indeterminados foi uma das etapas deste desenvolvimento. Em 1739 Euler desenvolveu o método da variação dos parâmetros e, mais tarde, propôs técnicas numéricas que fornecem “soluções aproximadas” para quase todo o tipo de equação.
Posteriormente muitos outros estudiosos de dedicaram ao assunto, refinando e ampliando as técnicas de Euler. A trabalho de d’Alembert na física matemática permitiu que ele encontrasse soluções para algumas equações diferenciais parciais simples. Lagrange seguiu de perto os trabalhos de Euler e aperfeiçoou os estudos aplicados à mecânica, em particular no problema de três corpos e no estudo da energia potencial. Em1788 ele introduziu as equações gerais do movimento para sistemas dinâmicos, o que hoje é conhecido como as equações de Lagrange, onde fazia uso do chamado cálculo variacional. O trabalho de Laplace na estabilidade do sistema solar produziu novos avanços, incluindo para o uso de técnicas numéricas. Em 1799 ele apresentou o conceito do Laplaciano de uma função. Já o matemático Legendre trabalhou com equações diferenciais, primeiramente motivado pelo estudo do movimento de projéteis, examinando pela primeira vez a influência de fatores como a resistência do ar e velocidades iniciais. Muitos dos desenvolvimentos seguintes se referem às equações diferenciais parciais. Parte importante deste desenvolvimento foi obtida por Fourier em sua busca por soluções do problema de difusão do calor. Ele desenvolveu uma representação de funções sob a forma de séries infinitas de funções trigonométricas, úteis para o tratamento de equações parciais e diversas outras aplicações.
Até o início do século XIX o estudo das equações diferenciais, e do cálculo como um todo, padeciam de uma deficiência crônica no que se refere à fundamentação teórica de seus princípios. Esta fundamentação começou então a ser construída, iniciando pelo entendimento da teoria e conceitos das funções de variáveis complexas. Gauss e Cauchy foram os principais responsáveis por estes avanços. Gauss usou equações diferenciais para aprimorar as teorias de órbitas e da gravitação planetárias e estabeleceu a teoria do potencial como parte importante da matemática. Ele mostrou que as funções de variáveis complexas eram a chave para compreender muitos dos resultados exigidos pelas equações diferenciais. Cauchy usou equações diferenciais para modelar a propagação das ondas na superfície de um líquido. Ele foi o primeiro a definir de forma satisfatória a noção de convergência de uma série infinita, dando início à análise rigorosa do cálculo e das equações diferenciais. Cauchy também desenvolveu uma teoria sistemática para os números complexos e a usou a transformada de Fourier para encontrar soluções algébricas para as equações diferenciais. A solução de equações diferenciais nas proximidades de um ponto singular foi elaborada por Frobenius.
Muitas outras contribuições têm sido acumuladas ao longo da história mais recente. Poisson utilizou as técnicas das equações diferenciais a aplicações na física e em sistemas mecânicos, incluindo a elasticidade e vibrações. Green aperfeiçoou os fundamentos da matemática utilizada em aplicações da gravitação, da eletricidade e do magnetismo. Baseados nestes fundamentos Thomson, Stokes, Rayleigh e Maxwell, construiram a teoria moderna do eletromagnetismo. Bessel utilizou a teoria das equações para o estudo da astronomia, buscando analisar perturbações dos planetas sobre as suas órbitas. Joseph Liouville foi o primeiro a resolver problemas de valor de contorno usando equações integrais, um método mais tarde aperfeiçoado Fredholm e Hilbert.
Em meados do século XIX novas ferramentas se tornaram necessárias para a solução de sistemas de equações diferenciais. Jacobi desenvolveu a teoria dos determinantes e transformações para a solução de integrais múltipla e equações diferenciais. O conceito de jacobiano de uma transformação foi elaborado em 1841. Cayley também contribuiu para teoria das matrizes e determinantes publicando diversos artigos sobre matemática teórica, dinâmica e astronomia. Gibbs estudou a termodinâmica, eletromagnetismo e mecânica, sendo considerado a pai da análise vetorial.
Os avanços durante o final do século XIX adquiriram uma natureza cada vez mais teórica. Em 1876 Lipschitz obteve a prova dos teoremas de existência para equações de primeira ordem. Uma contribuição importante para o estudo das equações diferenciais, apesar de não imediatamente reconhecida pela comunidade dos matemáticos devido a sua falta de rigor, foi feita por Oliver Heaviside. Entre 1880 e 1887 ele desenvolveu o cálculo operacional e o uso da transformada de Laplace para reduzir equações diferenciais a equações algébricas de solução muito mais simples. Como vantagem adicional seu formalismo permite o tratamento de sistemas com entradas descontínuas e é extensamente usado na engenharia, especialmente na eletrônica e no tratamento de sinais.
No século XX os maiores impulsos vieram do desenvolvimento de métodos numéricos mais eficientes e da consideração de equações e sistemas de equações diferenciais não lineares. Carl Runge desenvolveu um método para resolver equações associadas à mecânica quântica, atualmente conhecido como método de Runge-Kutta. O outro tema permanece em aberto e recebendo contribuições importantes até o presente. Muitos fenônenos naturais são descritos por equações não lineares. Uma das características destes sistemas consiste na dependência muito sensível das condições iniciais, o que gera comportamentos de difícil previsibilidade que têm sido denominados de caos. Um exemplo importante de sistema não linear é o sistema de equações que descreve o movimento de muitos corpos, por exemplo na descrição do movimento planetário no sistema solar. Outros sistemas não lineares representam o crescimento de espécies em competição, o fluxo turbulento de fluidos, a descrição das condições meteorológicas, entre outros. Henry Poincaré (1854 – 1912), matemático, físico e filósofo da ciência foi um dos precursores deste assunto, sendo o primeiro a descobrir o comportamento caótico das soluções para sistemas de três corpos. Liapunov, Lorenz e muitos outros matemáticos trabalharam nesta área que continua em franca expansão e é de se esperar que o progresso nesta área traga grandes inovações na descrição de diversas áreas do conhecimento.
Examinamos aqui duas formas diferentes para se demonstrar a fórmula das raízes de uma equação do segundo grau.
Usamos a notação [afirmação1] \(\Rightarrow\) [afirmação2] significando que a primeira afirmação implica na segunda, ou seja, que a segunda afirmação decorre logicamente da primeira.
x1, x2 e x3 são as raízes de f, uma função qualquer.
As raízes de uma função qualquer \(y = f(x)\) são os valores de \(x\) que tornam nula a função, \(f(x)=0\). Graficamente são os pontos onde o gráfico da função corta o eixo horizontal, \(\mathcal{O}x\).
No caso de uma função polinomial do segundo grau, \(f(x)=ax^{2}+bx+c\), cujo gráfico é uma parábola, queremos encontrar a solução de
$$ax^{2}+bx+c=0$$
onde \(a,b,c,\) são números reais quaisquer. Caso \(a=0\) a equação é do primeiro grau, muito mais fácil de resolver:
$$bx+c=0 \Rightarrow x=\frac{-c}{b}.$$
Se \(a\neq0\) podemos dividir a equação por \(a\) ficando com
$$x^{2}+\frac{b}{a}x+\frac{c}{a}=0.$$
A operação seguinte é chamada de completar quadrados e é muito útil em muitos contextos. Note que o produto notável
$$\left( x + \frac{b}{2a} \right)^{2} = x^{2}+\frac{b}{a}x+\frac{b}{4a},$$
O que nos permite reescrever a expressão acima como:
$$\left(x+\frac{b}{2a}\right)^{2}-\frac{b^2}{4a^2}+\frac{c}{a}=0,$$
ou ainda
$$\left(x+\frac{b}{2a}\right)^{2}=\frac{b^2}{4a^2}-\frac{c}{a}=\frac{b^2-4ac}{4a^{2}}.$$
No Brasil esta tem sido chamada, incorretamente, de fórmula de Bhaskara. Bhaskara foi um grande matemático e algebrista hindu que escreveu sobre tópicos variados. Existem textos que atribuem a ele descobertas importantes até mesmo na área do cálculo diferencial. Parece, no entanto, que não foi ele quem inventou ou provou esta fórmula. Alguns textos atribuem esta autoria a Sridhara, um matemático que viveu quase um século antes de Bhaskara.
Uma conveção útil consiste em denotar \(\Delta=b^{2}-4ac\). \(\Delta\) é a letra grega delta, que aqui define o que chamamos de discriminante da equação, por um motivo que já veremos. Temos agora
$$\left(x+\frac{b}{2a}\right)^{2}=\frac{\Delta}{4a^{2}}.$$
Extraindo as raízes de ambos os lados temos
$$x+\frac{b}{2a}=\pm\sqrt{\frac{\Delta}{4a^{2}}}=\pm\frac{\sqrt{\Delta}}{2a},$$
sendo que esta é a solução que preocuramos,
$$x=-\frac{b}{2a}\pm\frac{\sqrt{\Delta}}{2a}=\frac{-b\pm\sqrt{\Delta}}{2a}=\frac{-b\pm\sqrt{b^2-4ac}}{2a}.$$
O termo \(\Delta\) é chamado de discriminante porque podemos saber se a equação tem raízes reais ou não apenas pelo estudo de seu sinal. Existem três casos:
Figura 1
\(\Delta>0;\) existe \(\sqrt{\Delta}\) real e a equação tem as duas soluções dadas acima;
\(\Delta=0;\) \(\sqrt{\Delta} = 0\) e a equação possui apenas uma solução real, \(x=-b/2a\);
\(\Delta<0;\) não existe \(\sqrt{\Delta}\) real e a equação não possui raízes reais.
As três situações estão ilustradas na figura 1, onde representamos parábolas com \(a>0\), com concavidade voltada para cima, e \(a<0\), com concavidade para baixo.
Outra solução: mudança de coordenadas
Às vezes você consegue mostrar um resultado, ou resolver um exercício de uma forma diferente daquela que aparece no seu livro texto ou que foi mostrada por seu professor. Sempre é útil explorar estas outras possibilidades e, por isso, vamos desenvolver uma outra forma de chegar à mesma conclusão já exibida.
Observe que as raízes de uma equação do segundo grau na forma de \(y=ax^{2}+c\) (onde \(b=0\)) são simples de serem obtidas
$$
x^{2}=-\frac{c}{a}\Rightarrow x=\pm\sqrt{-\frac{c}{a}}.
$$
Figura 3
Uma equação deste tipo correponde à uma parábola simétrica em torno do eixo \(\mathcal{O}y\), (figura 3). O vértice desta parábola ocorre em \(x=0\), enquanto o vértice da parábola mais geral ocorre em \(x=-b/2a.\) Podemos fazer uma transformação de coordenadas deslocando o eixo \(\mathcal{O}x\) fazendo \(X=x+b/2a\), onde \(X\) (maiúsculo) foi usado para diferenciar da antiga coordenada. Isso equivale a estabelecer outro sistema de coordenadas de forma a fazer com que a parábola tenha seu vértice em \(X=0\), o que é mostrado na figura 4. Como
$$
x=X-\frac{b}{2a} \;\;\; \mbox{ portanto } \;\;\; x^{2}=X^{2}-\frac{b}{a}X+\frac{b^{2}}{4a^{2}}
$$
e a expressão da parábola pode ser escrita da seguinte forma
$$
y=aX^{2}-bX+\frac{b^{2}}{4a}+bX-\frac{b^{2}}{2a}+c=aX^{2}-\frac{b^{2}}{4a}+c.
$$
Figura 4
As raizes são, portanto,
$$
X=\pm\frac{1}{2a}\sqrt{b^{2}-4ac}.
$$
Como \(x=X-b/2a\), podemos encontrar a solução para \(x\):
$$
x=\frac{-b\pm\sqrt{b^{2}-4ac}}{2a},
$$
como esperado! Esta é uma solução um pouco mais complexa que a primeira mas esta técnica (a de se encontrar outro sistema de coordenadas que simplificam a solução de um problema) é usada em muitas situações, na matemática e suas aplicações. Vale a pena conhecer e dominar este conceito!
Raízes complexas
Este é um tópico um pouco mais avançado, normalmente só visto nos últimos semestres do ensino médio. No entanto não há porque um aluno curioso não possa ler e compreender esta seção! Leia também, neste site, a história dos números complexos e (muitas) outras mais operações que se pode fazer com eles, na seção sobre história do cálculo e no texto sobre variáveis complexas.
Este é um bom momento para antecipar um tópico muito interessante e útil da matemática – os números complexos. Historicamente os complexos só foram compreendidos com o estudo das equações do terceiro grau. No entanto não precisamos de tanto para introduzir e compreender estes números. Suponha, por exemplo, que precisamos resolver a seguinte equação do segundo grau: \(x^{2}+1=0\). Ela corresponde ao caso \(a=1, b=0, c=1\), da equação geral, ou seja \(\Delta=-1\) e não soluções reais. Temos
$$x^{2}+1=0\Rightarrow x^{2}=-1\Rightarrow x^{2}=\pm\sqrt{-1}.$$
Como sabemos, nenhum número real é raiz quadrada de \(\sqrt{-1}\) pois \((-1)^{2}=+1\) e \((+1)^{2}=+1\). Este problema intrigou os matemáticos por muito tempo, até que se propôs tratar o número \(i=\sqrt{-1}\) nas equações como obedecendo as mesmas regras sob as operações já usadas com os números reais. Suas propriedades foram estudadas e \(i\) foi denominado de “a unidade imaginária” (um nome um tanto infeliz que acabou por causar certa confusão e dificuldade na aceitação de seu uso).
Com esta convenção a raiz quadrada de um numero negativo pode ser obtida, por exemplo:
$$\sqrt{-9}=\sqrt{-1\times9}=\sqrt{-1}\sqrt{9}=3i.$$
Isto está correto \((3i)^2=-9\). Esta obordagem se mostrou eficaz e os números complexos (que possuem partes imaginárias) são de grande importância teórica e nas aplicações da matemática.
As seguintes consequências podem ser verificadas:
$$i^2 = i\times i=\left(\sqrt{-1}\right)^{2}=-1;$$
$$i^3 = i\times i\times i=i^2 \times i =-i;$$
$$i^4 = i^2\times i^2=(-1) \times (-1) =+1;$$
e assim por diante. Vamos ver como isso funciona resolvendo a seguinte equação de segundo grau
$$x^{2}-2x+2=0.$$
Identificamos que, neste caso, \(a=1,\,b=-2,\,c=2\). O discriminante é \(\Delta=b^2-4ac=-4\). Opa! Temos ai um caso de equação que não possui raíz real. Mas, como combinado, usaremos \(\sqrt{-4}=2i,\) de onde vemos que as raízes são
$$x=\frac{-b\pm\sqrt{\Delta}}{2a}=\frac{2\pm21}{2}=1\pm i.$$
Figura 2
Isto significa que encontramos duas raízes distintas: \(x=1+i\) e \(x=1-i\) que podem ser verificadas substituindo-se estes valores na equação original.
Um número da forma \(x=a+ib\), onde a e b são reais, é denominado um número complexo. Ele possui uma parte real, a, e uma parte imaginária, b. Estes números podem ser representados no plano de Argand, figura 2, onde a parte real é desenhada ao longo do eixo \(x\) (horizontal), a parte imaginária ao longo do eixo \(y\) (vertical).

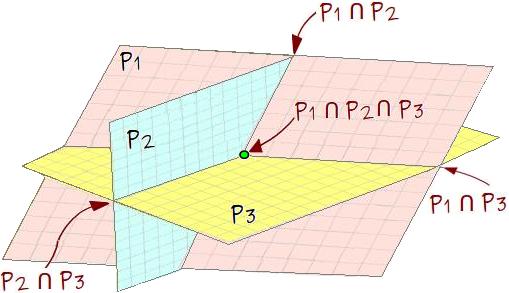






















 Zenão de Eléia (~450 a.C.) foi um dos primeiros pensadores a propor problemas baseados no conceito de infinito. Segundo um paradoxo famoso imaginado por ele, se uma flecha é atirada do ponto \(A\) até o ponto \(B\) ela deverá passar pela metade do caminho, digamos pelo ponto \(B_1\) , antes de chegar ao destino \(B\). Mas, antes de chegar a \(B_1\) deverá passar por \(B_2\) , o ponto médio entre \(A\) e \(B_1\) , e assim sucessivamente, realizando um número infinito de etapas em um intervalo finito de tempo. Desta forma ele concluiu que o movimento era impossível. Sabemos hoje que o conceito de limite é o que falta para a plena compreensão do paradoxo. Leucipo, Demócrito e Antífon fizeram contribuições para o método de exaustão mais tarde aprimorado por Eudóxo (~370 a.C.) e Arquimedes. O método é assim chamado porque as áreas medidas são tomadas em aproximações sucessivas e crescentes até que cubram a figura considerada.
Zenão de Eléia (~450 a.C.) foi um dos primeiros pensadores a propor problemas baseados no conceito de infinito. Segundo um paradoxo famoso imaginado por ele, se uma flecha é atirada do ponto \(A\) até o ponto \(B\) ela deverá passar pela metade do caminho, digamos pelo ponto \(B_1\) , antes de chegar ao destino \(B\). Mas, antes de chegar a \(B_1\) deverá passar por \(B_2\) , o ponto médio entre \(A\) e \(B_1\) , e assim sucessivamente, realizando um número infinito de etapas em um intervalo finito de tempo. Desta forma ele concluiu que o movimento era impossível. Sabemos hoje que o conceito de limite é o que falta para a plena compreensão do paradoxo. Leucipo, Demócrito e Antífon fizeram contribuições para o método de exaustão mais tarde aprimorado por Eudóxo (~370 a.C.) e Arquimedes. O método é assim chamado porque as áreas medidas são tomadas em aproximações sucessivas e crescentes até que cubram a figura considerada.















 Em 1702 Jean Bernoulli afirmou que um número e seu oposto tem o mesmo logaritmo. Esse fato intrigou os matemáticos do início do século XVIII, que não sabiam como atribuir um valor ao logaritmo de um número negativo. Coube a Euler, em 1747, explicar a questão em uma carta dirigida a d’Alembert.
Em 1702 Jean Bernoulli afirmou que um número e seu oposto tem o mesmo logaritmo. Esse fato intrigou os matemáticos do início do século XVIII, que não sabiam como atribuir um valor ao logaritmo de um número negativo. Coube a Euler, em 1747, explicar a questão em uma carta dirigida a d’Alembert.

 No Brasil esta tem sido chamada, incorretamente, de fórmula de Bhaskara. Bhaskara foi um grande matemático e algebrista hindu que escreveu sobre tópicos variados. Existem textos que atribuem a ele descobertas importantes até mesmo na área do cálculo diferencial. Parece, no entanto, que não foi ele quem inventou ou provou esta fórmula. Alguns textos atribuem esta autoria a Sridhara, um matemático que viveu quase um século antes de Bhaskara.
No Brasil esta tem sido chamada, incorretamente, de fórmula de Bhaskara. Bhaskara foi um grande matemático e algebrista hindu que escreveu sobre tópicos variados. Existem textos que atribuem a ele descobertas importantes até mesmo na área do cálculo diferencial. Parece, no entanto, que não foi ele quem inventou ou provou esta fórmula. Alguns textos atribuem esta autoria a Sridhara, um matemático que viveu quase um século antes de Bhaskara.



