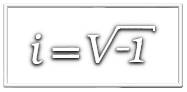Dados dois espaços vetoriais, \(V\) e \(W\), uma transformação entre eles é uma função que associa vetores de \(V\) em vetores de \(W\). Ela pode ser uma rotação de \(\mathbb{R}^2\) como as que foram estudadas na seção anterior, que associa vetores do plano em outros vetores do plano, girados de um ângulo \(\theta\). Outro exemplo seria a associação de um vetor do espaço em um vetor do plano que corresponde a uma projeção do primeiro vetor neste plano. Esta última transformação poderia, por exemplo, ser usada em uma aplicação gráfica para desenhar a sombra de um objeto tridimensional. Denotaremos por \(F : V \rightarrow W\) uma transformação que leva vetores de \(V\) em vetores de \(W\). Os termos transformação, aplicação e função são equivalentes e serão usados livremente neste texto.
Definição: Se \(V\) e \(W\) são dois espaços vetoriais, uma transformação \(F : V \rightarrow W\) é uma regra que associa a vetores de \(V\) um único vetor de \(W\).
Definição: Dados os espaços vetoriais \(U, V\) e \(W\), se \(F : U \rightarrow V\) e \(G : V \rightarrow W\), a transformação composta \(G \circ F : U \rightarrow W\) é definida da seguinte forma: se \(u \in U\) então
$$ G \circ F (u) = w = G (F (u)) \in W, $$
desde que \(F (u)\) esteja no domínio de \(G\).
Definição: Dada uma transformação \(F : V \rightarrow W\) entre dois espaços vetoriais a transformação inversa, quando existir, é uma transformação \(F^{-1} : W \rightarrow V\) tal que se
$$ F (v) = w \Rightarrow F^{-1}(w) = v. $$
Observe que, se \(F^{-1}\) é a inversa de \(F\), então \(F^{-1} \circ F : V \rightarrow V\) é a aplicação identidade, \(F^{-1} \circ F (v) = v, \forall v \in V\) (ela deixa inalterado qualquer vetor \(v)\).
Figura *
Exemplo . A composição de funções é uma prática rotineira em aplicações da matemática desde os estágios iniciais de seu estudo. Por exemplo, se \(f : \mathbb{R} \rightarrow \mathbb{R}\) dada por \(f (x) = x + 1\) e \(g : \mathbb{R} \rightarrow \mathbb{R}\) dada por \(g (x) = \sqrt{x}\) então a composta \(g \circ f : \mathbb{R} \rightarrow \mathbb{R}\) é a função \(g (f(x)) = g (x + 1) = \sqrt{x + 1}\).
As transformações lineares representam um caso particular das transformações me geral, de grande importância no estudo da matemática e aplicações. Elas são importantes porque muitos objetos e fenômenos que se pretende descrever ocorrem de forma linear, entre eles o estudo de circuitos passivos (contendo apenas resistores), o cálculo de estruturas de concreto, a manipulação computadorizada de imagens, etc. Além disto, mesmo objetos e fenômenos que não ocorrem de forma linear admitem, em seu tratamento, uma primeira aproximação linear, a partir da qual se procura fazer correções e aperfeiçoamentos.
Definição: Dados dois espaços vetoriais, \(V\) e \(W\), uma transformação linear entre eles é uma função de \(V\) em \(W\), \(F : V \rightarrow W\), satisfazendo:
- \(F (u + v) = F (u) + F (v), \forall u, v \in V\),
- \(F (k u) = k F (u), \forall u \in V, k\) um escalar qualquer.
Exemplo . A transformação de \(\mathbb{R}^2\) em \(\mathbb{R}^2\)
$$ \begin{array}{rl}
F : \mathbb{R}^2 \mapsto & \mathbb{R}^2 \\
(x, y) \mapsto & (x+y, x-y)
\end{array} $$
é uma transformação linear. Antes de mostrar isto, como ilustração do significado de uma transformação, observe que \(F\) tem o seguinte efeito sobre os vetores abaixo:
$$ \begin{array}{rrr}
F (1, 1) = (2, 0), & F (1, 0) = (1, 1), &\\
F (0, 0) = (0, 0), & F (3, 2) = (5, 1), & \text{etc..}
\end{array}
$$
Dados dois vetores de \(\mathbb{R}^2\), \(\vec{u} = (u_x, u_y)\) e \(\vec{v} = (v_x, v_y)\) então
$$ \begin{array}{rl}
F (\vec{u} + \vec{v}) = & F[(u_x + v_x, u_y + v_y)]=(u_x + v_x + u_y + v_y, u_x + v_x – u_y – v_y) = \\
& (u_x + u_y, u_x – u_y) + (v_x + v_y, v_x – v_y) = F (\vec{u}) + F (\vec{v}).
\end{array}
$$
Além disto, se \(k\) é um escalar temos
$$ F (k \vec{u}) = F [(k u_x, k u_y)] = (k u_x + k u_y, k u_x – k u_y) = k(u_x + u_y, u_x – u_y) = k F (\vec{u}).$$
Portanto a aplicação \(F\) satisfaz as duas condições e é, portanto, uma transformação linear. Vale a pena notar que \(F (\vec{0}) = \vec{0}\), i. e. ela leva o vetor nulo no vetor nulo, o que é, como veremos em breve, uma característica de todas as transformações lineares.
Exemplo . A transformação \(G : \mathbb{R} \rightarrow \mathbb{R}\) dada por \(G (u) = \alpha u\), (a multiplicação de um vetor por um fator \(\alpha\) ) é linear, pois:
$$ \begin{array}{rl}
G(u+v)= & \alpha (u + v)=\alpha u + \alpha v = G(u)+G(v), \\
G(ku)= & \alpha (ku)=k(\alpha u) = k\,G(u).
\end{array}
$$
Observamos novamente que \(G (0) = 0\).
Exemplo . A transformação
$$ \begin{array}{r}
H : \mathbb{R} \rightarrow \mathbb{R}\\
x \mapsto x^2
\end{array}
$$
não é linear. Qualquer uma das duas propriedades (i) e (ii) não são satisfeitas pois
$$ \begin{array}{rl}
H (u + v) = & (u + v)^2 = u^2 + v^2 + 2 u v \neq H (u) + H (v) ; \\
H (k u + v) = & (k u)^2 = k^2 u^2 \neq k H (u).
\end{array}
$$
Embora esta não seja uma transformação linear é verdade que \(H (0) = 0\).
Exemplo . A transformação
$$ \begin{array}{r}
J : \mathbb{R}^2 \rightarrow \mathbb{R}^3\\
(x, y) \mapsto (2 x, 0, x + y)
\end{array}
$$
é linear. Dados o vetores de \(\mathbb{R}^2\), \(\vec{u} = (x_1, y_1)\) e \(\vec{v} = (x_2, y_2)\) então
$$ \begin{array}{rl}
J (\vec{u}+\vec{v})= & J [(x_1 + x_2, y_1 + y_2)] = (2 x_1 + 2 x_2, 0, x_1 + y_1 + x_2 + y_2) = \\
& (2 x_1, 0, x_1 + y_1) + (2 x_2, 0, x_2 + y_2) = F (\vec{u}) + F (\vec{v}).
\end{array}
$$
Sendo \(k\) um escalar
$$ J (k \vec{u}) = J [(k x_1, k y_1)] = (2 k x_1, 0, k x_1 + k y_1) = k (2x_1, 0, x_1 + y_1) = k J (\vec{u}) . $$
Afirmação: Se \(F : V \rightarrow W\) é uma transformação linear, então \(F (0_V) = 0_W,\) onde \(0_V \;\text{ e }\; 0_W\) são, respectivamente, os vetores nulos de \(V\) e de \(W\).
Demonstração: Podemos escrever o vetor nulo como \(W \ni 0 = u – u\). Se \(F\) é linear então,
$$ F (0) = F (u – u) = F (u) – F (u) = 0 \in W. $$
No último exemplo, \(J (x, y) = (2 x, 0, x + y)\) temos que \(J (0, 0) = (0, 0, 0)\), ou seja, \(J\) leva o vetor nulo de \(\mathbb{R}^2\) no vetor nulo de \( \mathbb{R}^3\). Vimos também que a transformação \(H : \mathbb{R} \rightarrow \mathbb{R}; H (x) = x^2\) não é linear mas \(H(0) = 0\). Esta é, portanto, uma condição necessária mas não suficiente para que a transformação seja linear.
Exemplo . A transformação \(L : \mathbb{R}^3 \rightarrow \mathbb{R}^3\), dada por
$$ \text{ } L (x, y, z) = (x + 1, y, z) $$
não é linear pois \(L (0, 0, 0) = (1, 0, 0) \neq 0\). As condições (i) e (ii) não precisam ser testadas, nesta caso.
Exemplo . A transformação \(M : \mathbb{R}^3 \rightarrow \mathbb{R}\), dada por
$$ \text{ } M (\vec{v}) = \vec{v} \cdot \vec{v} \;\;\; \text{(o produto escalar)} $$
não é linear, embora \(M (\vec{0})=0.\;\;\) Apesar disto, se \(\vec{u}\), \(\vec{v} \in \mathbb{R}^3\) então
$$ \begin{array}{rl}
M(\vec{u}+\vec{v})= & (\vec{u}+\vec{v})\cdot(\vec{u}+\vec{v})=\vec{u}\cdot\vec{u}+\vec{v}\cdot\vec{v}+2\vec{u}\cdot \vec{v}\neq M(\vec{u})+M(\vec{v}), \\
M(k\vec{u})= & (k \vec{u}) \cdot (k \vec{u}) = k^2 \vec{u} \cdot \vec{u}\neq k M (\vec{u}).
\end{array}$$
Naturalmente, se uma das condições não é satisfeita já sabemos que a transformação não é linear. Nos exemplos sempre testamos as duas condições, para efeito de exercício.
Exemplo . A operação derivada \(D : P_n \rightarrow P_n\) (que leva polinômios em polinômios, ambos de grau menor ou igual a \(n\) ) é uma transformação linear. Se \(f, g \in P_n\) (são polinômios), e \(k\) é um escalar então
$$ \begin{array}{l} D (f + g) = D (f) + D (g), \\ D (k f) = k D (f). \end{array} $$
Exemplo . \(N : V \rightarrow W\), \(N (u) = 0, \forall u \in V\), é uma transformação linear pois
$$ \begin{array}{l} N (u + v) = 0 = N (u) + N (v); \\ N (k u) = k N (u) = 0. \end{array} $$
Exemplo . Toda matriz \(m \times n\) esta associada a uma transformação linear \(A : \mathbb{R}^n \rightarrow \mathbb{R}^m\):
$$
\left[ \begin{array}{rrrr}
a_{11} & a_{12} & \cdots & a_{1 n} \\
a_{21} & a_{22} & \cdots & a_{2 n} \\
\vdots & & & \vdots \\
a_{m1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right]
\left[ \begin{array}{r} x_1\\ x_2\\ \vdots\\ x_n \end{array} \right] =
\left[ \begin{array}{r} y_1\\ y_2\\ \vdots\\ y_m\end{array} \right].
$$
Denotando a operação acima por \(A \vec{x} = \vec{y}\), sabemos da álgebra das matrizes que
$$ \begin{array}{l}
A (\overrightarrow{x_1} + \overrightarrow{x_2}) = A (\overrightarrow{x_1}) + A (\overrightarrow{x_2}); \\
A (k \vec{x}) = k A (\vec{x}).
\end{array}
$$
Veremos mais tarde que a afirmação inversa também é verdadeira, ou seja, que toda a transformação linear \(T : V \rightarrow W\) (dois espaços vetorais) pode ser representada por uma matriz \(m \times n\) onde \(n\) é a dimensão de \(V\) e \(m\) a dimensão de \(W\).
Exemplo . Dada a matriz \(3 \times 2\)
$$
A = \left[ \begin{array}{rr}
2 & 0\\
0 & 0\\
1 & 1
\end{array} \right]
$$
existe a aplicação linear \(L_A : \mathbb{R}^2 \rightarrow \mathbb{R}^3\),
$$ \left[ \begin{array}{r}
x\\
y
\end{array} \right] \mapsto \left[ \begin{array}{rr}
2 & 0\\
0 & 0\\
1 & 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{c}
x \\ 0 \\ x + y
\end{array} \right] .
$$
Esta transformação é idêntica à \(J (x, y) = (2 x, 0, x + y)\), usada anteriormente em um exemplo.
Afirmação: Se \(F : V \rightarrow W\) é uma transformação linear, então \(F\) leva retas de \(V\) em retas de \(W\).
Demonstração: Uma reta de \(V\) é um espaço gerado por um único vetor. Vamos aqui denotar esta reta por \(\alpha = [v] = \{t v\},\) onde \(v \in V\) é um vetor fixo, \(t\) uma variável. A imagem desta reta, sob a acão de \(F\) é \(F \{tv\} = \{tF (v)\} = [F (v)]\), que é uma reta de \(W\).
Observação: Esta é, aliás, o motivo do nome, transformação linear.
Figura *
Transformações do plano no plano
De particular importância entre as transformações lineares entre espaços vetoriais estão as transformações \(T : \mathbb{R}^2 \rightarrow \mathbb{R}^2\). Grande parte das operações em computação gráfica pertencem a este tipo de transformações, em particular as expansões e contrações (para aumentar ou diminuir o tamanho de uma figura na tela do computador), as reflexões, projeções e rotações.
Expansão e contração uniforme
Uma transformação
$$ \begin{array}{lll}
T : & \mathbb{R}^2 \rightarrow \mathbb{R}^2 & \\
& \vec{v} \mapsto \alpha \vec{v}, & \alpha \in \mathbb{R}
\end{array}
$$
é uma expansão ou dilatação se \(\alpha \gt 1\), ou uma contração se \(\alpha \lt 1\). Vale aqui nos lembrarmos de que a multiplicação de um vetor por um escalar \(\alpha\) tem o efeito de multiplicar seu comprimento por \(| \alpha |\) pois
$$ |T (\vec{v}) | = | \alpha \vec{v} | = \sqrt[]{\alpha^2 \vec{v} . \vec{v} } = | \alpha | | \vec{v} |. $$
Exemplo . A seguinte transformação é uma dilatação,
$$ \begin{array}{rr}
T : & \mathbb{R}^2 \rightarrow \mathbb{R}^2\\
& \vec{v} \mapsto 2 \vec{v},
\end{array}
$$
que dobra o comprimento do vetor, conforme a figura *a. Em termos matriciais ela pode ser expressa por
$$ T \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{rr}
2 & 0\\
0 & 2
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
2 x\\
2 y
\end{array} \right] .
$$
Por outro lado a aplicação \(F (x, y) = \frac{1}{2} (x, y)\) é uma contração, mostrada na figura *b.
figura
Reflexão em torno do eixo \(\mathcal{O}x\)
A transformação
$$ \begin{array}{rl}
R_x : & \mathbb{R}^2 \rightarrow \mathbb{R}^2 \\
& (x, y) \mapsto (x,- y),
\end{array} $$
representa uma reflexão em torno do eixo \(\mathcal{O}x\), ilustrada na figura *. Em notação matricial
$$ \left[ \begin{array}{r}
x’\\
y’
\end{array} \right] = \left[ \begin{array}{rr}
1 & 0\\
0 & – 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
x\\
– y
\end{array} \right], \;\;\;\text{ onde }\;\;\; \left[ \begin{array}{r}
x’\\
y’
\end{array} \right] = T \left[ \begin{array}{r}
x\\
y
\end{array} \right] .
$$
Rotação de um ângulo \(\theta\)
Dado um vetor \(\vec{v} \in \mathbb{R}^2\) queremos conhecer a transformação \(R_{\theta} : \mathbb{R}^2 \rightarrow \mathbb{R}^2\) tal que \(\vec{v}’ = R_{\theta} (\vec{v})\) tem o mesmo comprimento que \(\vec{v}\) mas está girado de um ângulo \(\theta\) no sentido antihorário, como mostrado na figura *. Vamos começar denotando por \(r = | \vec{v} |\) o módulo deste vetor, e \(\alpha\) o ângulo que ele faz com o eixo \(\mathcal{O}x\). Nesta notação, se \(\vec{v} = (x, y)\) temos
$$ \left. \begin{array}{r} x = r \cos \theta \\ y = r \text{sen } \theta\end{array} \right\} \Rightarrow \vec{v} = r (\cos \theta, \text{sen }\theta). $$
O novo vetor \(\vec{v}’\) obtido de \(\vec{v}\) por meio de um giro de ângulo \(\theta\) será escrito por
$$ \begin{array}{r} x’ = r \cos (\alpha + \theta),\\ y’ = r \text{sen } (\alpha + \theta). \end{array} $$
Podemos aqui usar as identidades trigonométricas para a soma de ângulos,
$$ \begin{array}
\cos (\alpha + \theta) = \cos \alpha \cos \theta – \text{sen } \alpha \text{sen } \theta, \\
\text{sen } (\alpha + \theta) = \text{sen } \alpha \cos \theta + \cos \alpha \text{sen } \theta.
\end{array} $$
Por conseguinte as coordenadas de \(\vec{v}’\) serão
$$ \begin{array} {l}
x’ = r \cos \alpha \cos \theta – r \text{sen } \alpha \text{sen } \theta = x \cos \theta – y \text{sen } \theta, \\
y’ = r \text{sen } \alpha \cos \theta + r \cos \alpha \text{sen } \theta = x \text{sen } \theta + y \text{sen } \theta.
\end{array} $$
Temos portanto, a transformação procurada,
$$ R_{\theta} \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
x’\\
y’
\end{array} \right] = \left[ \begin{array}{rr}
\cos \theta & – \text{sen } \theta\\
\text{sen } \theta & \cos \theta
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] .
$$
Exemplo . No caso particular de uma rotação de \(\theta = \pi / 2\) temos
$$ R_{\pi / 2} \left[ \begin{array}{r}
x\\ y
\end{array} \right] = \left[ \begin{array}{rr}
0 & – 1\\ 1 & 0
\end{array} \right] \left[ \begin{array}{r}
x\\ y
\end{array} \right] = \left[ \begin{array}{r}
– y\\ x
\end{array} \right].
$$
Exercício: Denotando por \(R_{\theta}\) a rotação antihorário de um ângulo \(\theta\) mostre que
$$ R_{\theta 1} \cdot R_{\theta_2} = R_{(\theta_1 + \theta_2)}.$$
Extra: Um conceito importante em álgebra moderna é o de um grupo. Um grupo é um conjunto \(G \neq \emptyset\), dotado de uma operação binária \(\ast\), satisfazendo as seguintes propriedades:
- Se \(a,\, b,\, c \in G \Rightarrow (a \ast b) \ast c = a \ast (b \ast c)\) (associatividade).
- \(\exists \, e \, \in G\) tal que \(e \ast a = a \ast e = a, \forall a \in G\) (existência do elemento neutro).
- \(\forall a \in G \; \exists b \; \in G\) tal que \(a \ast b = b \ast a = e\) (existência do elemento inverso).
Estas propriedades significam que um grupo é um conjunto com uma operação \(\ast\) associativa, onde existe um elemento neutro \(e\) (com relação àquela operação) e que para cada elemento \(a\) de \(G\) existe um inverso \(b\) (algumas vezes denotado por \(a^{-1}\)).
Mostre que o conjunto \(G = (R_{\theta}, \ast)\) onde \( \ast\) é a multiplição usual de matrizes, é um grupo. Quem são, neste grupo, os elementos \(e\) (a identidade) e \( [R_{\theta}]^{-1}\), o inverso de \(R_{\theta}\)?
Translações
Exemplos de transformações importantes no plano são as translações
$$ T (x, y) = (x + a, y + b) $$
ou
$$ T \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
x’\\
y’
\end{array} \right] = \left[ \begin{array}{rr}
1 & 0\\
0 & 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] + \left[ \begin{array}{r}
a\\
b
\end{array} \right] .
$$
Estas não são, no entanto, transformações lineares, como se pode mostrar facilmente.
O teorema seguinte seguinte mostra que, para conhecer o efeito de uma transformação linear sobre os vetores de um espaço vetorial, basta conhecer o efeito desta transformação sobre todos os vetores de uma de suas bases.
Teorema: Uma transformação linear \(T : V \rightarrow W\) fica inteiramente determinada por sua ação sobre os vetores de uma base de \(V\).
Demonstração: Seja \(\beta = \{v_1, \ldots, v_n \}\) uma base de \(V\) e suponha conhecidos \(T (v_1) = w_1, \ldots, T (v_n) = w_n\). Então, qualquer \(v \in V\) e sua transformação \(T(v)\) podem ser escritos respectivamente como
$$ \begin{array}{rl}
v = & a_1 v_1 + \ldots + a_n v_n \;\;\; \text{e} \\
T(v)= & T(a_1 v_1+\ldots +a_n v_n)=a_1 T(v_1)+ \ldots + a_n T(v_n) \\
= & a_1 w_1 + \ldots + a_n w_n,
\end{array} $$
como foi afirmado.
Exemplo . Qual é a transformação linear \(T : \mathbb{R}^2 \rightarrow \mathbb{R}^3\) satisfazendo
$$ T (1, 0) = (2, – 1, 0) \text{ e } T (0, 1) = (0, 0, 1) ? $$
Qualquer vetor \(\vec{v} \in \mathbb{R}^2\) pode ser escrito na base canônica
$$ \vec{v} = (x, y) = x (1, 0) + y (0, 1) . $$
Então
$$ T (\vec{v}) = xT (1, 0) + yT (0, 1) = x (2, – 1, 0) + y (0, 0, 1) = (2 x, – x, y) . $$
Em termos matriciais
$$ T \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{rr}
2 & 0\\
– 1 & 0\\
0 & 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
2 x\\
– x\\
y
\end{array} \right] .
$$
Relembramos aqui que uma matriz \(3 \times 2\) corresponde a uma transformação de \(\mathbb{R}^2\) em \(\mathbb{R}^3\).
Exemplo . Queremos encontrar a transformação linear \(T : \mathbb{R}^2 \rightarrow \mathbb{R}^3\) satisfazendo
$$ T (1, 1) = (3, 2, 1) \text{ e } T (0, – 2) = (0, 1, 0) . $$
Neste caso, \(\{(1, 1), (0, – 2)\}\) não é a base canônica de \(\mathbb{R}^2\). Temos então que encontrar a decomposição de um vetor qualquer nesta base. O \(\vec{v} = (x, y) \in \mathbb{R}^2\) pode ser escrito nesta base como
$$
\vec{v} = (x, y) = a (1, 1) + b (0, – 2) \Rightarrow \left\{
\begin{array}{r}
(a, a – 2 b) = (x, y), \\
a = x, \\
b = \frac{1}{2} (x – y).
\end{array} \right.
$$
Dai
$$ (x, y) = x (1, 1) + \frac{1}{2} (x – y) (0, – 2) $$
e o vetor transformado é
$$ T (x, y) = xT (1, 1) + \frac{1}{2} (x – y) T (0, – 2) = $$
$$ = x (3, 2, 1)+\frac{1}{2}(x-y)(0, 1, 0)=\left(3x,\frac{5 x-y}{2},x\right).$$
Em termos matriciais
$$ T \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{rr}
3 & 0\\
5 / 2 & – 1 / 2\\
1 & 0
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] .
$$
Vimos que uma transformação linear \(T : V \rightarrow W\) transforma vetores de um espaço vetorial \(V\) em vetores de outro, \(W\). Algumas definições serão necessárias para prosseguirmos.
Definição: Seja \(T : V \rightarrow W\) uma transformação linear. A imagem de \(T\) é o conjunto
$$ \text{Im} (T) = \{w \in W ; T (v) = w \text{ para algum } v \in V\} . $$
A imagem é, portanto, o conjunto de todos os vetores de \(W\) que são imagem de algum vetor de \(V\) pela transformação \(T\). Podemos denotar a imagem por \(\text{Im} (T)\) ou por \(T (V)\).
Definição: Seja \(T : V \rightarrow W\) uma transformação linear. O núcleo da transformação \(T\) é o conjunto
$$ \text{Nuc } (T) = \{v \in V ; T (v) = 0\} . $$
O núcleo é, portanto, o conjunto de todos os vetores de \(V\) que são levados no vetor nulo de \(W\). Observe que \(\text{Nuc } (T) \neq \emptyset\) pois se \(0_V\) é o vetor nulo de \(V\) então \(T (0_V) = 0_W\) (i.e. pelo menos o vetor nulo de \(V\) está no núcleo).
Obs. Em alguns textos o núcleo é denotado por \(\text{Ker} (T)\) (do inglês, kernel).
Exercício importante: Mostre que \(T (V)\) é um subespaço vetorial de \(W\) e \(\text{Nuc }(V)\) é um subespaço vetorial de \(V\).
Figura: Imagem e núcleo (feita)
Exemplo . Considere a transformação linear
$$ \begin{array}{rl}
T : & \mathbb{R}^2 \mapsto \mathbb{R} \\
& (x, y) \mapsto x + y.
\end{array}
$$
O núcleo desta transformação é \(\text{Nuc } (T) = \{(x, y) \in \mathbb{R}^2 ; x + y = 0\}\). Portanto o núcleo desta transformação é a reta \(y = – x\), exibida na figura *. A imagem de \(T\) é \(\text{Im} (T) =\mathbb{R}\), (toda a reta real) pois qualquer ponto \(r\) desta reta pode ser obtido pela expressão \(r = x + y\), escolhndo-se \(x, y\) adequadamente.
figura *
Exemplo . A transformação linear \(T : \mathbb{R}^3 \rightarrow \mathbb{R}^3\) dada por \(T (x, y, z) = (x, 2 y, 0)\) tem como imagem o conjunto
$$ \text{Im} (T) = \{(x, 2 y, 0) | x, y \in \mathbb{R}\} . $$
Observe que esta imagem é o plano \([(1, 0, 0), (0, 1, 0)]\), isto é, o plano gerado por \(\hat{\imath}\) e \(\hat{\jmath}\) ou ainda o plano \(x\mathcal{O}y\) \((z = 0)\). A dimensão da imagem é \(\dim \text{Im} (T) = 2\), pois existem 2 vetores em sua base. O núcleo desta transformação é
$$ \text{Nuc } (T) = \{(x, y, z) \in \mathbb{R}^3 ; (x, 2 y, 0) = 0\}, $$
ou seja, \(x = 0, y = 0\). Não há qualquer restrição sobre o valor de \(z\), portanto
$$ \text{Nuc } (T) = \{(0, 0, z) ; z \in \mathbb{R}\} . $$
Isto significa que \(\text{Nuc } (T) = [(0, 0, 1)]\), o eixo \(\mathcal{O}z\) e \(\dim \text{Nuc } (T) = 1\). Observe que
$$ \dim \text{Im} (T) + \dim \text{Nuc } (T) = 3 = \dim V. $$
Este resultado será explorado em breve.
Definição: Uma aplicação \(T : V \rightarrow W\) é injetora se, dados \(u, v \in V\), com \(T (u) = T (v)\), então \(u = v\). Equivalentemente, se \(u \neq v\) então \(T (u) \neq T (v)\).
figura
Uma aplicação injetora é aquela que tem imagens distintas para vetores distintos.
Definição: Uma aplicação \(T : V \rightarrow W\) é sobrejetora se \(T (V) = W\), ou seja, a imagem de \(V\) por \(T\) é todo o espaço \(W\). Isto significa que todo vetor de \(W\) é imagem de algum vetor de \(V\) por \(T\).
figura *
Definição: Uma aplicação que é simultaneamente injetora e sobrejetora é uma aplicação bijetora (ou uma bijeção).
Exemplo . A aplicação \(T : \mathbb{R} \rightarrow \mathbb{R}^2\), dada por \(T (x) = (x, 0)\) é injetora pois, se \(x \neq y\) temos \(T (x) \neq T (y)\). No entanto ela não é sobrejetora pois sua imagem é apenas o eixo \(\mathcal{O}x\) de \(\mathbb{R}^2\).
Teorema: Uma aplicação linear \(T : V \rightarrow W\) é injetora se, e somente se, \(\text{Nuc } (T) = \{0\}\).
Demonstração: Suponha que \(\text{Nuc } (T) = \{ \vec{0} \}\). Tome dois vetores \(u, v \in V\) tal que \(T (u) = T (v)\). Então \(T (u) – T (v) = 0 \Rightarrow T (u – v) = 0\), já que a aplicação é linear. Isto indica que \(u – v \in \text{Nuc } (T)\) logo \(u – v = 0\) (pois o núcleo contém apenas o vetor nulo). Resumindo, se \(T (u) = T (v)\) temos, obrigatoriamente que \(u = v\), logo \(T\) é injetora.
Por outro lado, suponha \(T\) injetora e tome um vetor \(v \in \text{Nuc } (T) \Rightarrow\) \(T (v) = 0\). Mas \(T (0) = 0\) para qualquer aplicação linear logo \(T (v) = T (0)\) ou seja \(v = 0\) (pois \(T\) é injetora) de onde se conclui que \(\text{Nuc } (T) = \{0\}\).
Exemplo . Queremos descobrir se a aplicação
$$ \begin{array}{rl}
T : & \mathbb{R}^2 \rightarrow \mathbb{R}^3 \\
& (x, y) \mapsto (x + y, x, x – y),
\end{array}
$$
é injetora. Sem usar a definição do que é uma aplicação injetora procuramos por núcleo,
$$ \begin{array}{r}
\text{Nuc }(T)=\{(x, y) \in \mathbb{R}^2 ; T (x, y) = 0 \} \Rightarrow \\
(x + y, x, x – y) = 0 \Rightarrow x = 0, y = 0.
\end{array}
$$
portanto \(\text{Nuc } (T) = \{0\}\), logo \(T\) é injetora.
Teorema: Seja \(T : V \rightarrow W\) uma aplicação linear. Então
$$ \dim \text{Nuc } (T) + \dim \text{Im} (T) = \dim V. $$
Demonstração: Considere que \(\beta_N = \{v_1, \ldots, v_n \}\) é uma base de \(\text{Nuc } (T)\) à qual adicionamos o conjunto de vetores \(w_k\) necessários para que \(\beta_V = \{v_1, \ldots, v_n, w_1, \ldots, w_m \}\) seja uma base de \(V\). Com estas definições temos que \(\dim \text{Nuc } (T) = n\) e \(\dim V = n + m\). Qualquer vetor \(v \in V\) pode ser decomposto na base \(\beta_V \) como
$$ v = a_1 v_1 + \ldots + a_n v_n + b_1 w_1 + \ldots + b_m w_m . $$
O efeito da transformação \(T\) sobre este vetor é dada por
$$ \begin{array}{rl}
T(v) = & a_1 T (v_1) + \ldots + a_n T (v_n) + b_1 T (w_1) + \ldots + b_m T(w_m) = \\ & b_1 T (w_1) + \ldots + b_m T (w_m),
\end{array} $$
onde a última igualdade se deve a que os vetores \(v_k, k = 1, \ldots, n\) estão no núcleo, logo \(T (v_k) = 0\). A imagem de \(T\) é, portanto
$$ \text{Im} (T) = \{b_1 T (w_1) + \ldots + b_m T (w_m) ; b_k \in \mathbb{R}, k = 1, \ldots, m\} $$
ou ainda
$$ \text{Im} (T) = [T (w_1), \ldots, T (w_m)]. $$
Resta mostrar que os vetores \(T (w_i)\) são l.i.. Procedemos, como de costume, verificando se a combinação linear
$$ c_1 T (w_1) + \ldots + c_m T (w_m) = 0 $$
só pode ser obtida com todos os coeficientes \(c_k = 0\). Como \(T\) é linear podemos escrever
$$ T (c_1 w_1 + \ldots + c_m w_m) = 0, $$
concluindo que o vetor entre parênteses está no núcleo e pode, portanto, ser decomposto na base \(\beta_N\) como
$$ c_1 w_1 + \ldots + c_m w_m = d_1 u_1 + \ldots + d_n u_n . $$
A seguinte combinação linear é, por isto, nula,
$$ c_1 w_1 + \ldots + c_m w_m – d_1 u_1 – \ldots – d_n u_n = 0, $$
o que só pode ser conseguido com todos os coeficientes constantes nulos, \(c_k = 0\) e \(d_l = 0\), pois esta é uma combinação linear entre os vetores da base \(\beta_V\) de \(V\) (que são, por definição, l.i.). Isto mostra que o conjunto \(\beta_I = \{T (w_1), \ldots, T (w_m)\}\) é l.i. e gera \(\text{Im} (V)\), portanto é uma base da imagem. Dai se conclui que \(\dim \text{Im} (V) = m\) e o teorema fica provado.
Corolário: Se \(T : V \rightarrow W\) é uma aplicação linear e injetora, e \(\dim V = \dim W\) então \(T\) transforma bases de \(V\) em bases de \(W\).
Observação: Em outras palavras, o corolário afirma que, se \(\beta_V = \{v_1, \ldots, v_n \}\) é uma base de \(V\) então \(\beta_W = \{T (v_1), \ldots, T (v_n)\}\) é uma base de \(W\).
Demonstração: Tome \(\beta_V = \{v_1, \ldots, v_n \}\),uma base de \(V\). Queremos saber se \(\beta_W = \{T (v_1), \ldots, T (v_n)\}\) é l.i.. Para isto tornamos nula a combinação linear
$$ k_1 T (v_1) + \ldots + k_n T (v_n) = 0 \Rightarrow T (k_1 v_1 + \ldots + k_n v_n) = 0, $$
a última afirmação decorrendo de ser \(T\) linear. Como \(T\) é injetora então \(\text{Nuc } (T) = \{0\}\) e, portanto, \(k_1 v_1 + \ldots + k_n v_n = 0\), o que só pode ser obtido se todos os coeficientes constantes forem nulos, \(k_i = 0, i = 1, \ldots, n\). Dai se conclui que \(\beta_W\) é um conjunto de vetores l.i.. Como \(\dim V = \dim W = n\) então, como queríamos mostrar, \(\beta_W\) é uma base de \(W\).
Definição (isomorfismo): Se a aplicação linear \(T : V \rightarrow W\) é simultaneamente injetora e sobrejetora então dizemos que ela é um isomorfismo. Dizemos que os espaços vetoriais \(V\) e \(W\) são isomorfos.
Convém aqui enfatizar, apesar da repetição, alguns pontos importantes. Espaços isomorfos tem a mesma dimensão: como \(T\) é injetora temos que \(\dim \text{Nuc } (T) = 0\) e \(\dim \text{Im} (T) = \dim V\). Mas \(T\) é também sobrejetora, o que significa que sua imagem cobre todo o espaço \(W\), \(\text{Im} (T) = W\) logo \(\dim W = \dim V\). Além disto um isomorfismo leva bases de \(V\) em bases de \(W\). Como existe uma correspondência biunívoca entre vetores dos dois espaços e todos os vetores de \(W\) correspondem a algum vetor de \(V\), então é possível encontrar a aplicação inversa \(T^{-1} : W \rightarrow V\) e ela é também um isomorfismo.
Exemplo . Seja \(T : \mathbb{R}^3 \rightarrow \mathbb{R}^3\) dada por \(T (x, y, z) = (x – 2 y, z, x + y)\). Vamos mostrar que \(T\) é um isomorfismo e encontrar sua inversa, \(T^{-1}\).
Pelo corolário, como a dimensão do espaço de partida e de chegada são as mesmas (pois são o mesmo espaço) se \(T\) é injetora então \(\dim \text{Nuc }(T)=0\) e \(\dim \text{Im}(T)=3\), o que significa que a imagem é o próprio \(\mathbb{R}^3\) (\( T\) é sobrejetora). Basta portanto verificar que a transformação é injetora. Para isto procuramos pelo núcleo de \(T\),
$$ \text{Nuc } (T) = \{(x, y, z) ; T (x, y, z) = 0\}$$
o que significa que vetores do núcleo devem satisfazer
$$ (x – 2 y, z, x + y) = 0 \Rightarrow \left\{ \begin{array}{r}
x – 2 y = 0\\
z = 0\\
x + y = 0
\end{array} \Rightarrow (x, y, z) = (0, 0, 0) . \right. $$
Como \(\text{Nuc } (T) = \{0\}\), \(T\) é injetora e, sendo sobrejetora, é um isomorfismo e existe a transformação inversa. Para achar a transformação inversa encontramos sua ação sobre 3 vetores l.i. de \(\mathbb{R}^3\). Em geral é mais simples usar a base canônica, embora qualquer base possa ser usada. Listamos abaixo a ação da transformação sobre a base canonônica e a ação de sua inversa sobre os vetores:
$$ \left\{ \begin{array}{rr}
T (1, 0, 0) = & (1, 0, 1) \\
T (0, 1, 0) = & (- 2, 0, 1) \\
T (0, 0, 1) = & (0, 1, 0)
\end{array} \right. \Rightarrow \left\{ \begin{array}{rr}
T^{-1} (1, 0, 1) = & (1, 0, 0), \\
T^{-1} (- 2, 0, 1) = & (0, 1, 0), \\
T^{-1} (0, 1, 0) = & (0, 0, 1).
\end{array} \right.
$$
Sabemos que \(\{(1, 0, 1), (- 2, 0, 1), (0, 1, 0) \}\) é uma base de \(\mathbb{R}^3\) pois isomorfismos transformam bases em bases. Qualquer vetor deste espaço pode ser escrito nesta base como
$$ (x, y, z) = a (1, 0, 1) + b (- 2, 0, 1) + c (0, 1, 0) $$
o que representa o sistema listado abaixo, com sua solução,
$$ \left. \begin{array}{r}
x = a – 2 b\\
y = c\\
z = a + b
\end{array} \;\;\right\} \Rightarrow \begin{array}{l}
a = \frac{1}{3} (x + 2 z),\\
b = \frac{1}{3} (z – x),\\
c = y.
\end{array}
$$
Podemos escrever qualquer vetor de \(\mathbb{R}^3\) nesta base como
$$(x,y,z)=\frac{1}{3} (x + 2 z) (1, 0, 1) + \frac{1}{3} (z – x) (- 2, 0, 1) + y (0, 1, 0) $$
enquanto a ação de \(T^{-1}\) sobre este vetor arbitrário é
$$ T^{-1} (x, y, z) = \frac{1}{3} (x + 2 z) T^{-1} (1, 0, 1) + \frac{1}{3} (z – x) T^{-1} (- 2, 0, 1) + yT^{-1} (0, 1, 0), $$
onde usamos o fato de que \(T\) é linear. Já conhecemos o efeito de \( T^{-1}\) sobre os vetores envolvidos, portanto encontramos **
$$ \begin{array}{rl}
T^{-1}(x, y, z)= & \frac{1}{3}(x + 2 z)(1, 0, 0)+\frac{1}{3}(z-x) (0, 1, 0)+y (0, 0, 1)= \\
& \left(\frac{x + 2 z}{3},\frac{z – x}{3}, y \right).
\end{array} $$
Esta é a transformação inversa procurada.
Segue um resumo dos resultados sobre as transformações lineares
• Uma transformação \(T : V \rightarrow W\) é linear se \(T (\alpha u + \beta v) = \alpha T (u) + \beta T (v)\)
• A transformação fica totalmente determinada por meio de sua ação sobre uma base de \(V\).
• Def.: \(\text{Im} (T) = T (V) ; \text{Nuc } (T) = \{v \in V ; T (v) = 0_W \}\).
• \(T\) é injetora se \(T (u) = T (v) \Rightarrow u = v\), ou, se \(u \neq v \Rightarrow T (u) \neq T (v)\).
• \(T\) é sobrejetora se \(\text{Im} (T) = W\). Se \(T\) é injetora e sobre então é um isomorfismo.
• \(T\) linear é injetora \( \Leftrightarrow \text{Nuc } (T) = \{0_V \}\).
• \(\dim \text{Nuc } (T) + \dim \text{Im} (T) = \dim V\).
• Se \(\dim V = \dim W\), T é injetora \(\Leftrightarrow T\) é sobrejetora.
• \(T\) injetora: Se \(\dim V = \dim W\) então \(T\) leva bases de \(V\) em bases de \(W\).
• Se \(T\) é um isomorfismo então \(\exists \; T^{-1} : W \rightarrow V\), (existe a inversa de \(T\) ).







 Enquanto os colegas faziam as contas: 1 + 2 + 3 + . . . . + 99 + 100 = S, Gauss agrupou os inteiros em duas colunas e depois somou os números em cada linha:Vemos que Gauss obteve 50 linhas cuja soma é 101. A soma total é, portanto, 50 × 101 = 5050.
Enquanto os colegas faziam as contas: 1 + 2 + 3 + . . . . + 99 + 100 = S, Gauss agrupou os inteiros em duas colunas e depois somou os números em cada linha:Vemos que Gauss obteve 50 linhas cuja soma é 101. A soma total é, portanto, 50 × 101 = 5050.

 Já em 1489 os sinais \( + \mbox{ e } –\) aparecem em uma obra sobre aritmética comercial de João Widman d’Eger, publicada em Leipzig, Alemanha. Eles não se referiam, no entanto, às representações de soma e subtração, ou à números positivos ou negativos, mas a excessos e déficit em problemas sobre operações comerciais. Os símbolos para positivos e negativos só se difundiram na Inglaterra com o uso feito por Robert Recorde em 1557. Os mesmos sinais já eram usados anteriormente, como exemplifica o pintura destes sinais em barris para indicar se estavam ou não cheios. Os gregos antigos, como Diofanto, por exemplo, indicavam a soma por justaposição das parcelas, assim como ainda é feito no caso de frações, \(1^{1/2}\), por exemplo. Os algebristas italianos usavam a palavra latina plus, ou sua letra \(p\) inicial, para indicar a operação de soma.
Já em 1489 os sinais \( + \mbox{ e } –\) aparecem em uma obra sobre aritmética comercial de João Widman d’Eger, publicada em Leipzig, Alemanha. Eles não se referiam, no entanto, às representações de soma e subtração, ou à números positivos ou negativos, mas a excessos e déficit em problemas sobre operações comerciais. Os símbolos para positivos e negativos só se difundiram na Inglaterra com o uso feito por Robert Recorde em 1557. Os mesmos sinais já eram usados anteriormente, como exemplifica o pintura destes sinais em barris para indicar se estavam ou não cheios. Os gregos antigos, como Diofanto, por exemplo, indicavam a soma por justaposição das parcelas, assim como ainda é feito no caso de frações, \(1^{1/2}\), por exemplo. Os algebristas italianos usavam a palavra latina plus, ou sua letra \(p\) inicial, para indicar a operação de soma.
 O símbolo \(\infty\) para o infinito foi introduzido por John Wallis (1616-1703) em seu livro De sectionibus conicis (Sobre as seções cônicas, 1655 ). Wallis era um estudioso clássico com grande erudição e é possível que tenha se inspirado no sinal romano para o número 1000, escrito CD ou M. Também se cogita que ele tenha tido esta idéia a partir da última letra do alfabeto grego, o ômega grego minúsculo, \(\omega\), como uma metáfora para o limite superior, o fim.
O símbolo \(\infty\) para o infinito foi introduzido por John Wallis (1616-1703) em seu livro De sectionibus conicis (Sobre as seções cônicas, 1655 ). Wallis era um estudioso clássico com grande erudição e é possível que tenha se inspirado no sinal romano para o número 1000, escrito CD ou M. Também se cogita que ele tenha tido esta idéia a partir da última letra do alfabeto grego, o ômega grego minúsculo, \(\omega\), como uma metáfora para o limite superior, o fim.
 Para representar a integração Leibniz escrevia, no início de seu desenvolvimento, a palavra latina omnia (tudo) em frente à quantidade a ser integrada. Depois passou a escrever \(dx\) após a integração e, em carta de 1675 para Oldenburg, secretário da Royal Society, ele sugeriu o uso de \(\int\), uma degeneração de um S longo significando summa (soma). Em Quadratura curvarum, 1704, Newton usou uma pequena barra vertical \(\overline x\) para representar \(\int x dx\). Duas barras verticais paralelas, \(\overline {\overline x}\) indicava a integração dupla. Em outras ocasiões ele escrevia o termo a ser integrado dentro de um retângulo. As convenções de Newton, como se pode imaginar, davam margem a erros de interpretação e nunca se tornaram populares, nem mesmo entre seus seguidores diretos na Inglaterra.
Para representar a integração Leibniz escrevia, no início de seu desenvolvimento, a palavra latina omnia (tudo) em frente à quantidade a ser integrada. Depois passou a escrever \(dx\) após a integração e, em carta de 1675 para Oldenburg, secretário da Royal Society, ele sugeriu o uso de \(\int\), uma degeneração de um S longo significando summa (soma). Em Quadratura curvarum, 1704, Newton usou uma pequena barra vertical \(\overline x\) para representar \(\int x dx\). Duas barras verticais paralelas, \(\overline {\overline x}\) indicava a integração dupla. Em outras ocasiões ele escrevia o termo a ser integrado dentro de um retângulo. As convenções de Newton, como se pode imaginar, davam margem a erros de interpretação e nunca se tornaram populares, nem mesmo entre seus seguidores diretos na Inglaterra. Há um aspecto político importante associado a este problema. É muito evidente que o Brasil representa mundialmente apenas um mercado consumidor e que não precisa fazer um grande esforço para se manter atualizado com a rápida evolução científica e tecnológica mundial. O pais produz hoje um número reduzido de artigos e registros de patentes, em comparação com outras nações do mesmo porte. Este conceito, que parece dominar a elite dirigente, infelizmente está incorporado visceralmente pelas famílias e pelos próprios alunos que não assistem de perto à evolução tecnológica e que estão habituados simplesmente a comprar tecnologia pronta, assim como faz o próprio pais. A resistência contra o atingimento ou manutenção de ensino em nível elevado parte também destes alunos que não encontram motivos para se esforçar, tendo em vista um mercado de trabalho que parece valorizar pouco o desempenho acadêmico.
Há um aspecto político importante associado a este problema. É muito evidente que o Brasil representa mundialmente apenas um mercado consumidor e que não precisa fazer um grande esforço para se manter atualizado com a rápida evolução científica e tecnológica mundial. O pais produz hoje um número reduzido de artigos e registros de patentes, em comparação com outras nações do mesmo porte. Este conceito, que parece dominar a elite dirigente, infelizmente está incorporado visceralmente pelas famílias e pelos próprios alunos que não assistem de perto à evolução tecnológica e que estão habituados simplesmente a comprar tecnologia pronta, assim como faz o próprio pais. A resistência contra o atingimento ou manutenção de ensino em nível elevado parte também destes alunos que não encontram motivos para se esforçar, tendo em vista um mercado de trabalho que parece valorizar pouco o desempenho acadêmico.



 Exemplos de modelos mais prosaicos, mas igualmente úteis, podem ser encontrados na economia, no estudo das variações de preços dos produtos oferecidos ao consumidor, da inflação, do valor de um depósito feito meses atrás na caderna de poupança ou outra aplicação mais rentável. Modelos análogos serão usados para compreender a disseminação de uma doença, o contágio por um vírus ou a divulgação de um boato. Um modelo pode ser simples, como aquele que descreve os valores disponíveis em uma aplicação bancária com rendimento fixo, ou complicado e extenso como seria o modelo, ainda não desenvolvido, que descreve as oscilações nas bolsas de valores.
Exemplos de modelos mais prosaicos, mas igualmente úteis, podem ser encontrados na economia, no estudo das variações de preços dos produtos oferecidos ao consumidor, da inflação, do valor de um depósito feito meses atrás na caderna de poupança ou outra aplicação mais rentável. Modelos análogos serão usados para compreender a disseminação de uma doença, o contágio por um vírus ou a divulgação de um boato. Um modelo pode ser simples, como aquele que descreve os valores disponíveis em uma aplicação bancária com rendimento fixo, ou complicado e extenso como seria o modelo, ainda não desenvolvido, que descreve as oscilações nas bolsas de valores.







 Representamos graficamente as raízes obtidas nos dois exercícios na figura.
Representamos graficamente as raízes obtidas nos dois exercícios na figura.





 Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.
Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.