Para uma revisão sobre matrizes na Álgebra Linear veja Matrizes
Uma matriz é um objeto de duas dimensões, um conjunto de elementos organizados em linhas e colunas. Todos os componentes de uma matriz devem ser do mesmo tipo. Uma matriz Mm×n contém m linhas e n colunas. Em R uma matriz pode ser criada à partir de um vetor, através da função matrix():
> # Criando uma matriz de 4 linhas e 5 colunas
> n <- matrix(1:20, nrow=4, ncol=5)
> n
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> # Por default as colunas são preenchidas por colunas.
> # Para preencher por linhas fazemos
> m <- matrix(1:20, nrow=4, ncol=5, byrow=TRUE)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
> # Os elementos podem ser lidos diretamente
> m[3,4]
[1] 14
> # A n-ésima linha pode ser obtida (fazendo n=2)
> m[2,]
[1] 6 7 8 9 10
> # A n-ésima coluna pode ser obtida (n=3)
> m[,3]
[1] 3 8 13 18
> # O segundo elemento da terceira coluna é
> m[,3][2]
[1] 8
> # O mesmo que
> m[2,3]
[1] 8
> # Mais de uma coluna pode ser extraída
> # Extraindo a 1a e 3a coluna da matriz m
> m [, c(1,3)]
[,1] [,2]
[1,] 1 3
[2,] 6 8
[3,] 11 13
[4,] 16 18
> # Uma matrix também pode ser declarada sem ter seus elementos definidos
> matr <- matrix(nrow=3,ncol=2)
> matr
[,1] [,2]
[1,] NA NA
[2,] NA NA
[3,] NA NA
> # NA é a forma de R representar que o valor não está disponível
> # A matrix pode ser populada em seguida:
> matr[1,1] <- 1
> matr[1,2] <- 4 # etc.
> # Matrizes, como vetores, possuem atributos.
> attributes(m)
$ dim
[1] 4 5
> # A matriz m possui apenas o atributo dimensão
> dim(m)
[1] 4 5
> # 4 linhas e 5 colunas.
> # Uma matriz pode ser criada associando-se dimensões à um vetor
> k <- 1:10
> k
[1] 1 2 3 4 5 6 7 8 9 10
> dim(k) <- c(2,5)
> k
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> # Finalmente matrizes podem ser criadas por agrupamento de colunas
> x <- 1:3
> y <- 10:12
> cbind(x,y)
x y
[1,] 1 10
[2,] 2 11
[3,] 3 12
> # ou agrupamento de linhas
> rbind(x,y)
[,1] [,2] [,3]
x 1 2 3
y 10 11 12
> # Os argumentos de rbind e cbind são vetores ou matrizes.
> # Por ex., se xy = rbind(x,y) então
> rbind(x,xy)
[,1] [,2] [,3]
x 1 2 3
x 1 2 3
y 10 11 12
> # As dimensões devem ser compatíveis ou os argumentos podem ser truncados
> rbind(xy, 100:104)
[,1] [,2] [,3]
x 1 2 3
y 10 11 12
100 101 102
Warning message:
In rbind(xy, 100:104) :
number of columns of result is not a multiple of vector length (arg 2)
> # Uma mensagem de erro foi gerada.
>
> # Uma matrix pode ser criada com atributos m linhas, n colunas
> # juntamente com nomes para as linhas e colunas
> celulas <- c(11, 12, 21, 22)
> nomesLinhas <- c("Linha 1", "Linha 2")
> nomesColunas <- c("Coluna 1", "Coluna 2")
> matriz <- matrix(celulas, nrow=2, ncol=2, byrow=TRUE,
dimnames=list(nomesLinhas, nomesColunas))
> matriz
Coluna 1 Coluna 2
Linha 1 11 12
Linha 2 21 22
>
> # Esta matriz tem atributos dim (dimensões 2X2) e dimnames
> attributes(matriz)
$dim
[1] 2 2
$dimnames
$dimnames[[1]]
[1] "Linha 1" "Linha 2"
$dimnames[[2]]
[1] "Coluna 1" "Coluna 2"
> # Os nomes das linhas e colunas podem ser lidos e alterados
> colnames(matriz)
[1] "Coluna 1" "Coluna 2"
> colnames(matriz) <- c("col1", "col2")
> row.names(matriz)
[1] "Linha 1" "Linha 2"
> row.names(matriz) <- c("lin1" , "lin2")
> # Agora a matriz tem novos atributos names
> matriz
col1 col2
lin1 11 12
lin2 21 22
> # O nome de uma linha (ou coluna) pode ser alterado isoladamente
> row.names(matriz)[2] <- "linha dois"
> matriz
col1 col2
lin1 11 12
linha dois 21 22
Os seguintes funções foram usadas para a criação, acesso e manipulação de matrizes:
Função
Efeito
M = matrix(vetor, nrow=m, ncol=n, byrow=TRUE)
cria matriz Mm x n usando os elementos do vetor, distribuídos por linhas
matriz[m,n]
retorna o elemento Mm,n
matriz[m,n] <- q
associa o valor q ao elemento Mm,n
matriz[m,]
retorna a m-ésima linha da matriz M
matriz[,n]
retorna a n-ésima coluna da matriz M
attributes(M)
exibe atributos da matriz M
rbind(x, y)
junta por linhas os objetos x, y
cbind(x, y)
junta por colunas os objetos x, y
colnames(M)
exibe (ou atribue) nomes para as colunas de M
row.names(M)
exibe (ou atribue) nomes para as linhas de M
Arrays
Arrays são generalizações dos objetos matrizes e são manipulados de forma semelhante. Um array de dimensões 2 × 3 × 5 pode ser visto como uma coleção de 5 matrizes 2 × 3. Para efeito de sua representação no console elas são representadas exatamente desta forma.
> arr <- array(1:12, c(2, 3, 2))
> arr
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
> # Como vemos acima o componente [,, 2] é uma matriz 2 por 3
> arr[,,2]
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
> # que tem na primeira linha e segunda coluna o valor
> arr[,,2][1,2]
[1] 9
>
> # Um array pode ser construído com seus atributos names
> # Um ex, a terceira dimensão do array representa valores em anos diversos
> dim1 <- c("Filho 1","Filho 2")
> dim2 <- c("Educação", "Saúde", "Alimentação")
> dim3 <- c("2010", "2011")
> Despesas <- array(, c(2, 3, 2), dimnames=list(dim1, dim2, dim3))
> # Todos os elementos são 'NA'Despesas
> Despesas[1,1,1]<-90.80
> Despesas[1,1,2]<-98.80
> Despesas
, , 2010
Educação Saúde Alimentação
Filho 1 90.8 NA NA
Filho 2 NA NA NA
, , 2011
Educação Saúde Alimentação
Filho 1 98.8 NA NA
Filho 2 NA NA NA
> Despesas["Filho 1",,]
2010 2011
Educação 90.8 98.8
Saúde NA NA
Alimentação NA NA
> Despesas["Filho 1","Saúde","2010"]<-456
> Despesas["Filho 1","Saúde","2010"]
[1] 456
> Despesas["Filho 1",,]
2010 2011
Educação 90.8 98.8
Saúde 456.0 NA
Alimentação NA NA
Como vimos na seção anterior, toda matriz \(m \times n\) corresponde a uma aplicação linear \(T : \mathbb{R}^n \rightarrow \mathbb{R}^m .\) A afirmação recíproca também é verdadeira: fixadas as bases de \(V\) e \(W\), toda aplicação linear \(T : V \rightarrow W\) está associada à uma única matriz \(m \times n\), desde que se escolha as bases de ambos os espaços. Vamos começar revendo a primeira parte deste conceito através de um exemplo para depois generalizá-lo.
Dados dois espaços vetoriais \(V\) e \(W\), com bases \(\beta\) e \(\beta’\), respectivamente, e uma matriz \(A_{m \times n}\), sendo \(n = \dim V\) e \(m = \dim
W\), então esta matriz corresponde a uma única aplicação linear.
Exemplo 1. Tome \(V = W =\mathbb{R}^2,\;\; \beta = \{(1, 0), (0, 1)\}, \;\;\beta’ = \{(1, 1), (- 1, 1)\},\) e a matriz
$$
A = \left[ \begin{array}{rr}
2 & 0\\
0 & 1
\end{array} \right],
$$
buscamos \(T_A\), a aplicação associada a esta matriz, lembrando que \(T_A\) depende das bases \(\beta\) e \(\beta’\). Se \(\vec{v} \in V\), escrevemos \(\vec{v} = (x, y)\) e o escrevemos na base \(\beta\) (que é a base canônica) como
$$ [\vec{v}]_{\beta} = \left[ \begin{array}{r} x\\ y \end{array} \right]. $$
O efeito da transformação sobre sobre este vetor é
$$
A \vec{v} = \left[ \begin{array}{rr}
2 & 0\\
0 & 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] = \left[ \begin{array}{r}
2 x\\
y
\end{array} \right] = \left[T_A (\vec{v})\right]_{\beta’},
$$
onde pretendemos que o vetor de chegada seja descrito na base \(\beta’\). Nesta base temos
$$ T_A (\vec{v}) = 2 x (1, 1) – y (- 1, 1) = (2 x – y, 2 x + y), $$
que é a aplicação procurada. Por exemplo, a imagem do vetor \(\vec{v} = (2, 3)\) é \(T_A (2, 3) = (1, 7)\).
Generalizando o procedimento acima, sejam \(V\) e \(W\) dois espaços vetoriais com suas respectivas bases, \(\beta = \{v_1, \ldots, v_n \}\) e \(\beta’ = \{w_1, \ldots, w_m \}\) e \(A\) uma matriz \(m \times n\),
$$
A = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right].
$$
Podemos então associar a esta matriz a aplicação \(T_A : V \rightarrow W\) da seguinte forma: escrevemos \(v\) na base \(\beta\),
$$ [v]_{\beta} = \vec{X} = \left[ \begin{array}{r} x_1 \\ x_2\\ \vdots\\ x_n \end{array} \right] $$
e a ação da aplicação sobre este vetor, \(T_A (v)\), descrita em termos da base \(\beta’\),
$$
[A \cdot \vec{X}]_{\beta’} = \left[ \begin{array}{r}
y_1\\
y_2\\
\vdots\\
y_n
\end{array} \right]_{\beta’} \;\; \text{ onde } \;\; \left[
\begin{array}{r}
y_1\\
y_2\\
\vdots\\
y_n
\end{array} \right] = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right] \left[ \begin{array}{r}
x_1\\
x_2\\
\vdots\\
x_n
\end{array} \right].
$$
Como queremos obter o vetor de chegada na base \(\beta’\) temos \(T_A (v) = y_{1} w_1 + y_{2} w_2 + \ldots + y_{m} w_m\). Se nenhuma base for explicitada usaremos, por convenção, as bases canônicas.
Como as bases não são mencionadas, usamos as bases canônicas de \(\mathbb{R}^3\) e \(\mathbb{R}^2\), respectivamente
$$
\beta = \{(1, 0, 0), (0, 1, 0), (0, 0, 1)\} \;\; \text{ e } \;\; \beta’ = \{(1, 0),
(0, 1)\} .
$$
Tome \(\vec{v} = (x, y, z)\), ou, na base canônica
$$
[\vec{v}]_{\beta} = \vec{X} = \left[ \begin{array}{r}
x\\
y\\
z
\end{array} \right].
$$
A matriz \(A\) transforma este vetor em
$$
A \vec{X} = \left[ \begin{array}{rrr}
1 & – 3 & 5 \\
2 & 4 & – 1
\end{array} \right] \left[ \begin{array}{r}
x\\
y\\
z
\end{array} \right] = \left[ \begin{array}{r}
x – 3 y + 5 z\\
2 x + 4 y – z
\end{array} \right].
$$
Como queremos a transformação descrita nas bases canônicas dos dois espaços, que é, portanto
$$ T_A (\vec{v}) = (x – 3 y + 5 z, 2 x + 4 y – z). $$
Exemplo 3. Vamos procurar pela transformação \(F_A : P_2 (t) \rightarrow P_1 (t)\) (lembrando que \(P_n\) é o espaço dos polinômios em \(t\) de grau menor ou igual a \(n\) ) com as respectivas bases \(\beta = \{1, t, t^2 \}\) e \(\beta’ = \{1, t + 1\}\), associada à matriz
$$
A = \left[ \begin{array}{lll}
1 & 0 & 1\\
2 & 1 & 2
\end{array} \right].
$$
Se \(f \in P_2 (t)\) então \(f = a + bt + ct^2\) e podemos escrever, na base \(\beta\)
$$
[f]_{\beta} = \vec{X} = \left[ \begin{array}{r}
a\\
b\\
c
\end{array} \right].
$$
Transformado pela matriz \(A\) este vetor se torna
$$
A \vec{X} = \left[ \begin{array}{lll}
1 & 0 & 1\\
2 & 1 & 2
\end{array} \right] \left[ \begin{array}{r}
a\\
b\\
c
\end{array} \right] = \left[ \begin{array}{c}
a + c\\
2 a + b + 2 c
\end{array} \right] = [F_A (f)]_{\beta’} .
$$
O vetor transformado aparece na base \(\beta’\) por definição. A transformação procurada é
$$
F_A (f) = (a + c) 1 + (2 a + b + 2 c) (t + 1) = 3 a + b + 3 c + (2 a + b +
2 c) t.
$$
Como foi afirmado antes, toda transformação linear corresponde a uma única matriz se as bases de ambos os espaços forem especificadas. Considere transformação linear \(T : V \rightarrow W\), com bases \(\beta = \{v_1, \ldots, v_n \}\) e \(\beta’ = \{w_1, \ldots, w_m \}\), respectivamente. Os vetores de \(\beta\) transformados por \(T\) são vetores de \(W\), ou seja \(T (v_k) \in W\) e, portanto, podem ser decompostos na base \(\beta’\)
$$\begin{array}{cc}
T (v_1) = & a_{11} w_1 + a_{21} w_1 + \ldots + a_{m 1} w_m, \\
\vdots & \vdots \\
T (v_n) = & a_{1 n} w_1 + a_{2 n} w_2 + \ldots + a_{mn} w_m,
\end{array}
$$
onde, mais uma vez, a escolha dos índices fica explicada a seguir. A transposta da matriz dos coeficientes é a matriz que corresponde a \(T\) nas bases escolhidas,
$$
\left[T\right]^{\beta}_{\beta’} = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right].
$$
Novamente, escreveremos apenas \(\left[T\right]\) quando as bases envolvidas forem ambas canônicas.
Formalizando a afirmação acima temos:
Teorema: Dados os espaços vetoriais \(V\) e \(W\), com bases \(\alpha\) e \(\beta\) respectivamente, toda transformação linear \(T : V \rightarrow W\) corresponde a uma matriz \(A_{m \times n}\), onde \(n\) é a dimensão de \(V\) e \(m\) a dimensão de \(W\). Além disto, denotando esta matriz \(A = \left[T\right]_{\beta}^{\alpha}\) vale a relação
$$
\left[T(v)\right]_{\beta} = \left[T\right]_{\beta}^{\alpha} [v]_{\alpha} .
$$
Demonstração: Considere que \(\beta = \{v_1, \ldots, v_n\}\) e \(\beta’ = \{w_1, \ldots, w_m \}\) são, respectivamente, bases de \(V\) e \(W\). Escrevemos \(v \in V\) na base \(\alpha\) e \(T (v) \in W\) na base \(\beta\),
$$
[v]_{\alpha} = \left[ \begin{array}{r}
x_1\\
\vdots\\
x_n
\end{array} \right], \left[T(v)\right]_{\beta} = \left[ \begin{array}{r}
y_1\\
\vdots\\
y_m
\end{array} \right].
$$
A matriz procurada, correspondente a \(T\), é tal que \(A [v]_{\alpha} = [T(v)]_{\beta}\), ou seja,
$$
\left[
\begin{array}{lll}
a_{11} & \cdots & a_{1 n} \\
\vdots & & \vdots \\
a_{m 1} & \cdots & a_{m n}
\end{array}
\right]
\left[
\begin{array}{r}
x_1 \\
\vdots \\
x_n
\end{array}
\right] =
\left[
\begin{array}{r}
y_1 \\
\vdots \\
y_m
\end{array}
\right],
$$
onde denotamos \(A = \{a_{ij} \}\). Resta apenas encontrar as entradas \(a_{ij}\) da matriz. Para fazer isto tomamos \(v_1 \in \alpha\), o primeiro vetor desta base. Sendo um vetor de \(V\) ele pode ser escrito na própria base \(\alpha\) como
$$
[v_1]_{\alpha} = \left[ \begin{array}{r}
1\\
\vdots\\
0
\end{array} \right].
$$
Por efeito da transformação acima ele é levado em um vetor \(T(v_1) \in W\), que pode, portanto, ser escrito na base \(\beta\) como
$$
\left[T (v_1)\right]_{\beta} = \left[ \begin{array}{r}
y_1\\
\vdots\\
y_m
\end{array} \right] = \left[ \begin{array}{lll}
a_{11} & \cdots & a_{1 n}\\
\vdots & & \vdots\\
a_{m 1} & \cdots & a_{m n}
\end{array} \right] \left[ \begin{array}{r}
1\\
\vdots\\
0
\end{array} \right] = \left[ \begin{array}{r}
a_{11}\\
\vdots\\
a_{m 1}
\end{array} \right].
$$
Pelo mesmo procedimento podemos mostrar que para qualquer vetor \(v_k \in \beta\) temos
$$ T (v_k) = a_{1 k} w_1 + \ldots + a_{mk} w_m, k = 1, \ldots, n. $$
o que representa uma forma de fácil memorização para representar todo o processo adotado. O símbolo \(\left[T\right]_{\beta}^{\alpha}\) significa a matriz associada a transformação \(T\) que leva vetores de \(V\), escritos na base \(\alpha\) para vetores de \(W\) escritos na base \(\beta\).
Resumindo: para encontrar os coeficientes da matriz associada a \(T\) nas bases dadas procedemos da seguinte forma:
Tomamos os vetores \(v_k \in \alpha\) e os escrevemos na base \(\beta\).
A matriz \(\left[T\right]_{\beta}^{\alpha}\) tem como componentes os termos \(a_{ik}\) da decomposição \(T (v_k) = \sum a_{ik} w_i\).
Exemplo 4. Dada uma transformação \(T : \mathbb{R}^3 \rightarrow \mathbb{R}^2\) dada por
$$ T (x, y, z) = (2 x + y – z, 3 x – 2 y + 4 z) $$
e considerando as bases \(\beta = \{(1, 1, 1), (1, 1, 0), (1, 0, 0)\}\) e \(\beta’ = \{(1, 3), (1, 4)\}\) vamos encontrar a matriz \(\left[T\right]_{\beta’}^{\beta}\) associada a esta transformação.
Primeiro calculamos o efeito de \(T\) sobre as vetores de \(\beta\) e escrevemos as imagens na base \(\beta’\):
$$ \begin{array}{rl}
T (1, 1, 1) = & (2, 5) = a (1, 3) + b (1, 4) = 3 (1, 3) – 1 (1, 4), \\
T (1, 1, 0) = & (3, 1) = c (1, 3) + d (1, 4) = 11 (1, 3) – 8 (1, 4), \\
T (1, 0, 0) = & (2, 3) = e (1, 3) + f (1, 4) = 5 (1, 3) – 3 (1, 4).
\end{array}
$$
As constantes \(a, b, \ldots, f\) foram calculadas como solução de sistemas. Por exemplo, na primeira equação temos
$$
\left. \begin{array}{l} a + b = 2 \\ 3 a + 4 b = 5 \end{array} \right\} \Rightarrow a = 3, \;\; b = – 1.$$
A matriz procurada é a transposta da matriz dos coeficientes, ou seja,
$$
\left[T\right]^{\beta}_{\beta’} = \left[ \begin{array}{rrr}
a & c & e\\
b & d & f
\end{array} \right] = \left[ \begin{array}{rrr}
3 & 11 & 5\\
– 1 & – 8 & – 3
\end{array} \right].
$$
Exemplo 5. Dada a mesma transformação \(T : \mathbb{R}^3 \rightarrow \mathbb{R}^2\) do exemplo anterior
$$ T (x, y, z) = (2 x + y – z, 3 x – 2 y + 4 z) $$
com as bases canônicas \(\beta = \{(1, 0, 0), (0, 1, 0), (0, 0, 1)\}\) e \(\beta’ = \{(1, 0), (0, 1)\}\) veremos que a matriz \(\left[T\right]\) associada a esta transformação será diferente da anterior. Listamos a seguir a transformação sobre os vetores de \(\beta\) e escrevemos as imagens na base \(\beta’\) :
$$ \begin{array}{rl}
T (1, 0, 0) = & (2, 3) = a (1, 0) + b (0, 1) = 2 (1, 0) + 3 (01, 1), \\
T (0, 1, 0) = & (1, – 2) = c (1, 0) + d (0, 1) = 1 (1, 0) – 2 (0, 1),\\
T (0, 0, 1) = & (- 1, 4) = e (1, 0) + f (0, 1) = – 1 (1, 0) + 4 (0, 1) .
\end{array}
$$
A transposta da matriz dos coeficientes é a matriz procurada,
$$
\left[T\right] = \left[ \begin{array}{lll}
2 & 1 & – 1\\
3 & – 2 & 4
\end{array} \right].
$$
Exemplo 6. Considere a transformação identidade, \(T : V \rightarrow V\), \(T (v) = v\), realizada entre as bases \(\beta = \{v_1, \ldots, v_n \}\) de \(V\) e \(\beta’ = \{w_1, \ldots, w_m \}\) de \(W\). Repetimos o procedimento, encontrando a imagem dos vetores de \(\beta\) e os escrevendo em \(\beta’\),
$$ \begin{array}{cc}
T (v_1) = & v_1 = a_{11} w_1 + a_{21} w_1 + \ldots + a_{m 1} w_m, \\
\vdots & \vdots \\
T (v_n) = & v_n = a_{1 n} w_1 + a_{2 n} w_2 + \ldots + a_{mn} w_m.
\end{array} $$
Fazemos o processo inverso, pois os coeficientes da expansão de \(T (1, 1)\) e \(T (0, 1)\) na base \(\beta’\) são conhecidos,
$$ \begin{array}{rl}
T (1, 1) = & 0 (0, 3, 0) – 1 (- 1, 0, 0) – 1 (0, 1, 1) = (1, – 1, – 1), \\
T (0, 1) = & 2 (0, 3, 0) + 0 (- 1, 0, 0) + 3 (0, 1, 1) = (0, 9, 3).
\end{array} $$
Como conhecemos o efeito desta transformação sobre os vetores da base \(\beta\), sabemos seu efeito sobre qualquer vetor \((x, y) \in \mathbb{R}^2\). Nesta base
$$ (x, y) = x (1, 1) + (y – x) (0, 1) $$
e, portanto,
$$ \begin{array}{rl}
T (x, y) = & T [x (1, 1) + (y – x) (0, 1)] = xT (1, 1) + (y – x) T (0, 1) \\
= & x (1, – 1, – 1) + (y – x) (0, 9, 3) = (x, 9 y – 10 x, 3 y – 4 x).
\end{array}$$
Portanto a transformação procurada é \(T (x, y, z,) = (x, 9 y – 10 x, 3 y – 4 x)\).
Definição: Uma matriz é uma coleção de elementos estabelecidos em linhas e colunas, da seguinte forma:
$$
A_{m \times n} = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n} \\
a_{21} & a_{22} & \cdots & a_{2 n} \\
\vdots & & & \vdots \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right],
$$
onde \(a_{i j} \) representa o elemento na \(i\)-ésima linha e \(j\) -ésima coluna. A matriz acima, portanto, tem \(m\) linhas e \(n\) colunas e dizemos que esta matriz tem dimensão \(m \times n\) . Como delimitadores de uma matriz podemos usar colchetes [ ] ou parênteses ( ), de acordo com a conveniência. Também podemos representar uma matriz por meio de um elemento genérico, colocado entre colchetes para indicar que se trata de uma coleção de linhas e coluna, na forma de
$$
A_{m \times n} = \{a_{i j} \},\;\; i = 1, \ldots, m, j = 1, \ldots, n,
$$
e, em algumas situações, nos referiremos a um elemento genérico da matriz \(A\) por \((A)_{i j} = a_{i j}\) . Os exemplos dados abaixo servirão para ilustrar este conceito e apresentar algumas matrizes de tipos mais comuns e mais utilizadas.
Exemplo: A matriz \(A\) abaixo é uma matriz \(2 \times 2\) , portanto uma matriz quadrada,
$$
A = \left[ \begin{array}{ll}
1 & 3\\
4 & 5
\end{array} \right],
$$
onde os elementos \(a_{11} = 1\) , \(a_{22} = 5\) , só para citar alguns exemplos. A matriz
$$
B = \left[ \begin{array}{ll}
1 & – 2\\
3 & \;0\\
5 & \;4
\end{array} \right]
$$
é uma matriz \(3 \times 2\) (ou seja, tem 3 linhas e duas colunas) enquanto \(C = [1]\) é uma matriz \(1 \times 1\) . Matrizes \(n \times 1\) são denominadas matrizes colunas, tais como \(D_{4 \times 1}\) abaixo
$$
D = \left[ \begin{array}{l}
2\\
0\\
1\\
3
\end{array} \right],
$$
enquanto matrizes \(1 \times n\) são denominadas matrizes linhas, tais como \(E = [1, 2, 6] .\) Uma matriz nula possue todos os seus componentes nulos,
$$
F = \left[ \begin{array}{ll}
0 & 0\\
0 & 0
\end{array} \right] .
$$
Podemos usar o símbolo \(\tilde{0}\) para representar a matriz nula quando isto for interessante para a discussão do momento. Uma matriz identidade é uma matriz quadrada com todos os elementos nulos exceto os da diagonal principal, que são de uma unidade, como \(\mathbb{I}_{3 \times 3}\) abaixo,
$$
\mathbb{I}= \left[ \begin{array}{lll}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{array} \right] .
$$
Observe que \(\mathbb{I}\) (ou outra matriz identidade de qualquer dimensão) tem elementos
$$
(I)_{i j} = \delta_{i j} = \left\{ \begin{array}{ll}
1 & \text{se } i = j,\\
0 & \text{se} i \neq j.
\end{array} \right.
$$
O símbolo \(\delta\) definido desta forma é o chamado delta de Kronecker. Logo ficará claro porque chamamos esta matriz de identidade. E interessante ainda definir as matrizes diagonais como aquelas que possuem todos os elementos nulos exceto os da diagonal principal, que podem ter qualquer valor, como
\begin{eqnarray*}
& & G = \left[ \begin{array}{lll}
7 & 0 & 0\\
0 & – 1 & 0\\
0 & 0 & 1
\end{array} \right],
\end{eqnarray*}
e as matrizes simétricas, que são aquelas que permanecem inalteradas quando suas linhas são tomadas como colunas, tal como
$$
H = \left[ \begin{array}{lll}
3 & 2 & 1\\
2 & 0 & 7\\
1 & 7 & 1
\end{array} \right] .
$$
Alternativamente, definimos a matriz \(H = \{h_{i j} \}\) como simétrica se \(h_{i j} = h_{j i}\) .
Definição: Se \(A\) é uma matriz \(n \times m\) sua transposta e a matriz \(A’_{m \times n} \) obtida de \(A\) por meio da transposição de suas linhas em colunas, \((A)_{i j} = (A’)_{j i}\) .
Exemplo: A transposta da matriz \(B\) acima é
$$
B’ = \left[ \begin{array}{ccc}
1 & 3 & 5\\
– 2 & 0 & 4
\end{array} \right] .
$$
As seguintes propriedades podem ser verificadas quanto à transposição de matrizes:
(i) Se \(S\) é uma matriz simétrica então \(S’ = S\) ,ou seja, uma matriz simétrica é igual a sua transposta.
(ii) \(A’ ‘ = A\) ,
(iii) \((A + B)’ = A’ + B’\) ,
(iv) \((k A)’ = k A’\) .
Definição: dizemos que duas matrizes são iguais se, e somente se, tem a mesma ordem e todos os seus elementos correspondentes (na mesma linha e mesma coluna) são iguais;
$$
A = B \Leftrightarrow a_{i j} = b_{i j.}
$$
A álgebra das Matrizes
Tendo definido as matrizes podemos agora definir uma álgebra ou um conjunto de operações sobre estes elementos.
1) Adição: Se \(A\) e \(B\) são matrizes de mesma ordem então \((A + B)_{i j} = a_{i j} + b_{i j}\) .
onde \(\mathbb{I}_{3 \times 3}\) é a matriz identidade .
As seguintes propriedades são válidas para as operações já consideradas: se \(A\) e \(B\) são matrizes de mesma ordem, \(k\) e \(l \) são escalares então:
(i) \(k (A + B) = k A + k B\) ;
(ii) \((k + l) A = k A + l A\) ;
(iii) \(0 \cdot A = \tilde{0}\) ;
(iv) \(k (l A) = (k l) A\) .
Observe na propriedade (iii) que o produto de qualquer matriz pelo escalar \(0\) é a matriz nula \(\tilde{0}\) embora seja costume representar este resultado simplesmente pelo número 0. Um outro exemplo onde isto pode ocorrer é o seguinte
$$
\left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] – \left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] = 0,
$$
onde o resultado escrito como 0 por abuso de linguagem, na verdade significa a matriz \(\tilde{0}\) de dimensões \(2 \times 2\) .
3) Multiplicação de matrizes
Dadas as matrizes \(A_{m \times n}\) e \(B_{n \times p}\) (notando portanto que \(B\) tem um número de linhas igual ao número de colunas de \(A\) ) definimos o produto de \(A\) por \(B\) da seguinte forma
$$
(A B)_{i j} = \sum^n_{k = 1} a_{i k} b_{k j} .
$$
Isto significa que o elemento da \(i\) -ésima linha e \(j\) -ésima coluna é obtido pela soma dos produtos de elementos da \(i\) -ésima linha de \(A\) com a \(j\) -ésima coluna de \(B\) . O produto é a matriz \(A B\) de dimensões \(m \times p\) . Alguns exemplos servirão para esclarecer este procedimento. No entanto é útil compreender a operação indicada simbolicamente pelo somatório acima.
Neste último exemplo observamos que, além da não co mutatividade do produto de matrizes, é possível que o produto de duas matrizes seja nulo sem que nenhuma delas seja a matriz nula.
Propriedades do produto de matrizes
(i) \(A B \neq B A\) ,
(ii) \(A\mathbb{I}=\mathbb{I}A = A\) , onde \(\mathbb{I}\) é a matriz identidade (e dai o seu nome),
(iii) \(A (B + C) = A B + A C\) ,(distributividade à esquerda),
(iv) \((B + C) A = B A + C A\) , (distributividade à direita),
(v) \((A B) C = A (B C)\) , (associatividade),
(vi) \((A B)’ = B’ A’\) ,
(vii) \(\tilde{0} A = A \tilde{0} = \tilde{0}\) , onde \(\tilde{0}\) é a matriz nula.
Sistemas de equações lineares
Definição: Um sistema com \(m\) equações lineares com \(n\) incógnitas é um conjunto de equações da forma de
\begin{eqnarray*}
a_{11} x_1 + a_{12} x_2 + \ldots + a_{1 n} x_n = b_1 & & \\
a_{21} x_1 + a_{22} x_2 + \ldots + a_{2 n} x_n = b_2 & & \\
\vdots & & \\
a_{m 1} x_1 + a_{m 2} x_2 + \ldots + a_{m n} x_n = b_m & &
\end{eqnarray*}
onde \(a_{i j}, 1 \leq i \leq m, 1 \leq j \leq n,\) são números reais (ou complexos) e \(x_k, 1 \leq k \leq n\) são \(n\) incógnitas. Uma solução do sistema acima, quando existir, é uma \(n\) -upla \((x_1, x_2, \ldots, x_n)\) que satisfaz simultaneamente as \(m\) equações do sistema. Podemos escrever o mesmo sistema sob forma matricial
$$
\left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \vdots\\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right] \left[ \begin{array}{l}
x_1\\
x_2\\
\vdots\\
x_n
\end{array} \right] = \left[ \begin{array}{l}
b_1\\
b_2\\
\vdots\\
b_m
\end{array} \right],
$$
sendo que \(A\) é denominada matriz dos coeficientes do sistema, \(X\) é a matriz das incógnitas e \(B\) a matriz dos termos constantes. Alternativamente é útil escrever o mesmo sistema como o conjunto das equações
\begin{eqnarray*}
\sum_{j = 1}^n a_{1 j} x_j = b_{1,} & & \\
\sum_{j = 1}^n a_{2 j} x_j = b_{2,} & & \\
\vdots & & \\
\sum_{j = 1}^n a_{m j} x_j = b_{m,} & &
\end{eqnarray*}
ou, de modo compacto,
$$
\sum_{j = 1}^n a_{i j} x_j = b_{i,} 1 \leq i \leq m.
$$
Embora todas estas formas de se escrever o sistema de equações sejam equivalentes, é útil compreender cada uma delas. A notação de somatório é poderosa, principalmente para demonstrações e considerações teóricas sobre este e muitos outros tópicos.
Sistemas lineares aparecem em um grande número de aplicações e é necessário que se aprenda técnicas para encontrar suas soluções. Para isto apresentamos as definições abaixo.
É usual, mas não obrigatório, o uso da barra de separação entre os termos \(a_{i j}\) e \(b_k\) .
Definição: Dois sistemas de equações lineares são ditos equivalentes se, e somente se, toda a solução de um deles é igualmente solução do outro.
Podemos obter sistemas equivalentes por meio das chamadas operações elementares:
(i) permutação de duas equações;
(ii) multiplicação de um das equações por um escalar;
(iii) substituição de uma das equações por sua soma com outra das equações do sistema.
Em termos das matrizes ampliadas associadas ao sistema estas mesmas operações significam as operações elementares sobre as linhas desta matriz. Exemplificando estas operações elementares sobre linhas de uma matriz temos:
(ii) Multiplicação de uma linha por um escalar: \(k L_i \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
1 & 2\\
5 & 6
\end{array} \right] 3 L_2 \rightarrow L_2 \left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
(iii) Substituição de uma linha por sua soma com outra linha: \(L_i + L_j \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] L_1 + L_2 \rightarrow L_1 \left[ \begin{array}{ll}
6 & 10\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
Definição: Duas matrizes são equivalentes se uma pode ser obtida da outra por meio de um número finito de operações elementares. Denotaremos a equivalência entre duas matrizes \(A\) e \(B\) por meio do símbolo \(A \sim B\) .
Definição: uma matriz está em sua forma linha reduzida à forma escada se
O primeiro elemento de cada linha é 1. Chamaremos de piloto a este elemento.
Cada coluna que possue um elemento piloto de alguma das linhas contém todos os demais elementos nulos.
O piloto de cada linha ocorre em colunas progressivas.
Linhas inteiramente nulas ocorrem abaixo de todas as demais.
A matriz reduzida à sua forma escada terá a forma indicada na figura.
Uma vez que as operações elementares sobre um sistema de equações lineares não alteram a solução do sistema, e que matrizes equivalentes são obtidas uma da outra por meio de operações elementares sobre suas linhas, podemos concluir que dois sistemas cujas matrizes ampliadas são equivalentes possuem a mesma solução ou soluções, quando estas existirem. Isto nos permite enunciar um método de solução.
Método de Gauss-Jordan para solução de sistema lineares
O método de Gauss-Jordan consiste no seguinte procedimento:
Dado um sistema de equações lineares começamos por escrever a sua matriz ampliada associada.
Através de operações elementares sobre linhas da matriz ampliada obtemos a matriz equivalente reduzida à forma escada.
A matriz equivalente reduzida à forma escada será associada a um sistema onde a solução do sistema original é de fácil leitura.
Vamos ilustrar estas operações elementares por meio de um exemplo. Nele indicaremos as operações realizadas sobre as linhas de uma matriz amplida apenas para efeito de acompanhanto do leitor. A operação \(L_1 + L_2 \rightarrow L_2\) , por exemplo, significa: substitua a linha 2 pela soma da linha 2 com a linha 1.
Exemplo . O sistema
\begin{eqnarray*}
x + 4 y + 3 z = 1 & & \\
2 x + 5 y + 4 z = 4 & & \\
x – 3 y – 2 z = 5 & &
\end{eqnarray*}
pode ser representado matricialmente por
$$
\left[ \begin{array}{lll}
1 & 4 & 3\\
2 & 5 & 4\\
1 & – 3 & – 2
\end{array} \right] \left[ \begin{array}{l}
x\\
y\\
z
\end{array} \right] = \left[ \begin{array}{l}
1\\
4\\
5
\end{array} \right]
$$
que é a solução do sistema inicial, como pode ser verificado por substituição direta.
Exercício resolvido: resolva o sistema
\begin{eqnarray*}
x + 2 y + 3 z = 9 & & \\
2 x – y + z = 8 & & \\
3 x – z = 3. & &
\end{eqnarray*}
A matriz ampliada associada a este sistema é
$$
A = \left[ \begin{array}{lll}
1 & 2 & 3\\
2 & – 1 & 1\\
3 & 0 & – 1
\end{array} \begin{array}{l}
9\\
8\\
3
\end{array} \right] .
$$
Para o leitor que considere isto necessário seguem alguns comentários sobre os passos executados nesta operação:
\(\{p_1 \}\) zeramos o elemento na coluna 1, onde ocorre o piloto da primeira linha;
\(\{p_2 \}\) idem para a linha 3;
\(\{p_3 \}\) introduzimos o piloto da linha 2;
\(\{p_4 \}\) apenas uma simplificação para os cálculos posteriores;
\(\{p_5 \}\) zeramos \(a_{12}\) ;
\(\{p_6 \}\) zeramos \(a_{32}\) ;
\(\{p_7 \}\) introduzimos o piloto da linha 3;
\(\{p_8 \}\) zeramos \(a_{13}\) ;
\(\{p_9 \}\) zeramos \(a_{23}\) . O procedimento é interrompido porque atingimos a matriz equivalente na forma reduzida .
é claro que não existe uma única forma para se atingir a matriz na forma escada e, algumas vezes, uma escolha apropriada de passos pode reduzir muito o trabalho necessário para atingí-la. No entanto, se um passo mais hábil ou mais rápido não for percebido, podemos executar etapas intermediárias que facilitem este processo. Para quem está aprendendo a operação pode ser preferível realizar um número maior de passos e um de cada vez.
Algumas vezes é necessário saber se existem uma ou mais soluções para um sistema linear. As definições dadas a seguir nos permitem obter esta informação mesmo sem resolvê-lo.
Definição: Seja \(A_{m \times n}\) uma matriz e \(B_{m \times n}\) sua matriz equivalente reduzida à forma escada. \(p\) ,o posto de \(A\) , é o número de linhas não nulas de \(B\) . A nulidade de \(A\) é igual ao número de colunas menos o posto, \(n – p\) .
Exemplo . Qual é o posto e a nulidade da matriz \(A\) dada abaixo?
$$
\begin{array}{ll}
A = & \left[ \begin{array}{l}
\begin{array}{llll}
1 & 2 & 1 & 0\\
– 1 & 0 & 3 & 5\\
1 & – 2 & 1 & 1
\end{array}
\end{array} \right] .
\end{array}
$$
\begin{eqnarray*}
\begin{array}{lll}
\sim & \left[ \begin{array}{lll}
1 & 0 & 14 / 9\\
0 & 1 & 1 / 9\\
0 & 0 & 0\\
0 & 0 & 0
\end{array} \right] = C & .
\end{array} & &
\end{eqnarray*}
sendo que a matriz \(B\) está em sua reduzida. O posto de \(A\) é \(p = 3\) porque \(B\) tem 3 linhas não nulas. Como \(A\) tem \(n = 4\) colunas, a nulidade de \(A\) é \(n – p = 1\) .
Continuando com a questão da existência de soluções vamos examinar alguns casos ilustrativos de sistemas e suas soluções.
(1) Sistema trivial, com uma incógnita e uma equação
$$
a x = b.
$$
Os seguintes casos podem ocorrer:
Se \(a \neq 0\) então existe uma única solução, \(x = b / a\) .
Se \(a = 0\) e \(b = 0\) o sistema é \(0 x = 0\), satisfeito por qualquer valor de \(x\) . Existem, portanto, infinitas soluções.
Se \(a = 0\) e \(b \neq 0\) o sistema \(0 x = b\) , não é satisfeito por nenhum valor de \(x\) , ou seja, não existem soluções.
(2) Sistema com uas equações e duas incógnitas.
Exemplo:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
x – 3 y = 6
\end{array} \right.
$$
Embora este seja um sistema de fácil solução por meio de uma simples substituição, para efeito de exercício da técnica aprendida, escrevemos matriz ampliada e suas matrizes equivalentes,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 7 / 2 & – 7 / 2
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 1 & – 1
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 0 & 3\\
0 & 1 & – 1
\end{array} \right], & &
\end{eqnarray*}
ou seja, \(x = 3\) e \(y = – 1\) é a solução única do sistema. A
matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
1 & – 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 0\\
0 & 1
\end{array} \right] & &
\end{eqnarray*}
tem posto 2 enquanto a matriz ampliada também tem posto 2. Lembramos ainda que \(n = 2\) é o número de incógnitas envolvidas. Como se pode ver na figura cada equação do sistema corresponde a uma reta do plano e a solução é dada pelo único ponto comum entre elas.
Exemplo 2:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 15
\end{array} \right.
$$
A matriz ampliada e suas matrizes equivalentes são, por exemplo,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 15
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & 0
\end{array} \right], & &
\end{eqnarray*}
indicando que existem infinitas soluções, que são todos os pontos da reta \(x + y / 2 = 5 / 2\) . Observamos que as duas equações do
sistema são uma múltiplo da outra e representam a mesma reta. A matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
6 & 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 1 / 2\\
0 & 0
\end{array} \right] & &
\end{eqnarray*}
tem posto 1 e a matriz ampliada também tem posto 1. A nulidade de \(A\) é 2 enquanto a nulidade da matriz dos coeficientes é 1. Geometricamente as duas equações do sistema são repreentadas pela mesma (uma delas é meramente um múltiplo da outra) e todos os pontos que satisfazem a primeira equação satisfazem também a segunda.
Exemplo: O sistema
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 10
\end{array} \right.
$$
pode ser resolvido da mesma forma; a matriz ampliada e sua reduzida são
\begin{eqnarray*}
A = \left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 10
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & – 5
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 0\\
0 & 0 & 1
\end{array} \right], & &
\end{eqnarray*}
que representam um sistema sem solução. O posto de \(A\) é 2 e o posto da matriz dos coeficientes é 1. Geometricamente as duas linhas são equações de retas são paralelas que, por isto, não possuem pontos comuns.
Relacionando o número de equações, incógnitas e o posto das matrizes ampliada e dos coeficientes temos o seguinte resultado:
Teorema: Dado um sistema de \(m\) equações e \(n\) incógnitas, denotamos por \(p_A \)o posto da matriz ampliada e \(p_C \) o posto da matriz dos coeficientes. Então
A condição \(p_A = p_C\) é necessária e suficiente para que o sistema admita uma ou mais soluções;
A condição \(p_A = p_C = n\) é necessária e suficiente para que o sistema admita uma única solução;
Se \(p_A = p_C \lt n\) então o sistema pode ser resolvido para \(p\) incógnitas em função das \(n – p\) incógnitas restantes.
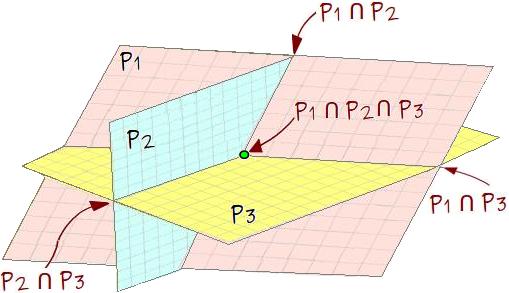
Sistema linear de 3 equações e 3 incógnitas
Sistema de três equações e três incógnitas: Cada uma das equações pode ser representada por um plano, P1, P2 e P3. Podem ocorrer, por exemplo, algumas dessas situações: (i) os planos são paralelos e não coincidentes; não existe nenhuma solução para o sistema; (ii) dois planos são coincidentes e interceptam o terceiro plano em uma reta. Neste caso existem infinitas soluções (os pontos da reta). (iii) Nenhum dos planos é paralelo a outro. Esta é a situação mostrada na figura 6 e existe uma única solução.