Usando métodos para alterar propriedades de widgets
Os valores de propriedades dos widgets (exceto aqueles que são de leitura somente) podem ser alterados dinamicamente pelo código e por ação do usuário. O código abaixo, além de inserir cidades previamente digitadas em uma lista, permite que usário insira novos nomes.
1 import flet as ft
2 import time
3
4 def main(page=ft.Page):
5 def inserir(e):
6 txt = txt_cidade.value.strip()
7 if txt:
8 page.controls.append(ft.Text(txt))
9 txt_cidade.value = ""
10 page.update()
11
12 page.add(ft.Row([ft.Text("Estas são cidades brasileiras")]))
13 txt_cidade = ft.TextField(label="Sua cidade")
14 page.add(
15 ft.Row([
16 txt_cidade,
17 ft.ElevatedButton(text="Insira o nome de sua cidade!", on_click=inserir)
18 ])
19 )
20 cidades = ["Belo Horizonte","Curitiba","São Paulo","Salvador","----------"]
21 for i in range(len(cidades)):
22 page.add(ft.Text(cidades[i]))
23 time.sleep(.5)
24
25 ft.app(target=main)
Figura 1
Na linha 17 atribuímos uma função ao evento on_click do botão. Essa função é disparada com o clique, enviando o parâmetro e que tem várias propriedades, não utilizadas aqui. A função inserir(e) coleta o conteúdo de txt_cidade, a caixa de texto definida na linha 16, remove espaços em branco nas bordas da string, testa se ela é uma string não vazia e, se não for, cria e insere um texto na página com o conteúdo digitado pelo usuário. Lembrando, na linha 7, if txt só retorna falso se txt for uma string vazia. A execução desse código produz o resultado mostrado na figura 1, após a inserção de nova cidade pelo usuário.
Alterando texto e cores de botões
Outro exemplo abaixo mostra dois botões associados a métodos diferentes, com a capacidade de alterar as propriedades do outro botão.
Um clique no botão 2 muda a cor do botão 1 escolhendo aleatóriamente entre as cores do dicionário cores. Cliques no botão 1 alternam a habilitação do botão 2.
Figura 2
Fontes, pés de página e referências a widgets
No próximo exemplo definimos duas fontes (de caracteres) para uso no aplicativo, que denominamos respectivamente por Kanit e Karma. A propriedade page.fonts é um dicionário com o nome e local do recurso, a primeira definida como um recurso externo por meio de uma URL, a segunda um recurso interno, na máquina onde roda o aplicativo, explicado abaixo.
A linha 68 define um flet.BottomSheet, uma janela modal (que impede a ação sobre outras partes do aplicativo), que pode ser usada como uma alternativa para uma janela modal ou de menu.
1 import flet as ft
2
3 def main(page: ft.Page):
4
5 page.title="Exibindo notas ocultas"
6 page.fonts = {
7 "Kanit": "https://raw.githubusercontent.com/google/fonts/master/ofl/kanit/Kanit-Bold.ttf",
8 "Karma": "fonts/Karma-Regular.ttf",
9 }
10 page.theme = ft.Theme(font_family="Kanit")
11 page.update()
12
13 def exibe_mensagem(txt):
14 mensagem.value=txt
15 mensagem.update()
16
17 def traduzir(e):
18 bt2.data = (bt2.data + 1)%2
19 conteudo.current.value = texto_nota[bt2.data]
20 page.update()
21
22 def bs_fechado(e):
23 exibe_mensagem("A nota foi ocultada por clique fora de sua área.")
24
25 def mostrar_pe(e):
26 bs.open = True
27 bs.update()
28 exibe_mensagem("A nota está exibida.")
29
30 def ocultar_pe(e):
31 bs.open = False
32 bs.update()
33 exibe_mensagem("A nota foi ocultada por clique no botão interno.")
34
35 def fechar_app(e):
36 page.window_destroy()
37
38 texto_nota=[(
39 'The Selfish Gene is a 1976 book on evolution by ethologist Richard Dawkins, in '
40 'which the author builds upon the principal theory of George C. Williams\'s '
41 'Adaptation and Natural Selection (1966). Dawkins uses the term "selfish gene" as '
42 'a way of expressing the gene-centred view of evolution (as opposed to the views '
43 'focused on the organism and the group), popularising ideas developed during the '
44 '1960s by W. D. Hamilton and others.'
45 ),
46 (
47 'O Gen Egoísta é um livro de 1976 sobre evolução do etólogo Richard Dawkins, no '
48 'qual o autor se baseia na teoria principal de Adaptação e Seleção Natural de '
49 'George C. Williams (1966). Dawkins usa o termo "gene egoísta" como forma de '
50 'expressar a visão da evolução centrada no gene (em oposição às visões focadas no '
51 'organismo e no grupo), popularizando ideias desenvolvidas durante a década de '
52 '1960 por W. D. Hamilton e outros.'
53 )]
54
55 bt1=ft.ElevatedButton("Fechar a nota", on_click=ocultar_pe)
56 bt2=ft.ElevatedButton("Traduzir", data=0, on_click=traduzir)
57 bt3=ft.ElevatedButton("Exibir pé de página", on_click=mostrar_pe)
58 bt4=ft.ElevatedButton("Fechar Aplicativo", on_click=fechar_app)
59
60 mensagem=ft.Text("A nota não está exibida.", font_family="Karma", size=20)
61 conteudo=ft.Ref[ft.Text()]()
62 coluna_texto=ft.Column([ft.Text(ref=conteudo), ft.Row([bt1, bt2])])
63 conteudo.current.font_family="Karma"
64 conteudo.width=600
65 conteudo.current.size=20
66 conteudo.current.value = texto_nota[0]
67
68 bs = ft.BottomSheet(ft.Container(coluna_texto, padding=50), open=False, on_dismiss=bs_fechado)
69
70 page.overlay.append(bs)
71 page.add(
72 ft.Text("Clique no botão para exibir a nota oculta", size=30),
73 mensagem,
74 ft.Row([bt3, bt4]),
75 )
76
77 ft.app(target=main, assets_dir="assets")
Figura 3: posição das fontes
A linha 77, que inicializa o aplicativo do flet, informa que estamos usando o diretório de recursos assets_dir=”assets”, onde podemos armazenar imagens, fontes e outros recursos. No caso do atual aplicativo o diretório code é a pasta raiz, de onde o código será executado. A fonte local Karma-Regular.ttf está gravada em code/assets/fonts/Karma-Regular.ttf, como mostrado na figura 3. Ela é inserida no dicionário page.fonts da linha 6 e utilizada nas linhas 60 e 63. A outra fonte é definida como padrão do aplicativo na linha 10.
A linha 68 inicializa o bs = BottomSheet, inicialmente fechado (invisível). Esse widget é exibido com o clique do botão bt3 (linha 57) e fechado com bt4 (linha 58). O BottomSheet é inserido na página com page.overlay.append(bs) (70). page.overlay é uma lista de controles que são exibidos por cima dos demais controles da página. O botão bt2 (traduzir) altera a exibição do texto em conteudo, escolhendo entre os dois textos armazenados na lista texto_nota. O índice do texto exibido a cada momento está armazenada na propriedade bt2.data.
Outro ponto digno de nota é o uso da referência para um controle usada na linha 61 em conteudo=ft.Ref[ft.Text()](). A classe Ref permite que se defina uma referência para um controle. No cao a referência é feita ao controle de texto associado à variável conteudo. Essa referência permite o uso posterior das propriedades e eventos do controle. Para lidar mais tarde com esse controle usamos a propriedade current como é feito nas linhas 66 e 19.
O resultado desse código ao ser executado é mostrado na figura 4, antes de pressionado o botão Exibir pé de página. A figura 5 exibindo o texto em inglês após pressionamento do botão. Um texto alternativo, em português é exibido quando se clica em Traduzir.
Figura 4: Aplicativo antes de exibir a nota.Figura 5: Exibindo o texto da nota.
Vimos que podemos executar comandos do python diretamente no interpretador, obtendo resultados imediatos. Também podemos gravar um arquivo contendo um Shebang#!na primeira linha, informando qual é o interpretador a ser usado nessa execução. Esse conteúdo pode ser lido no artigo Módulos e Pacotes, nesse site. Um exemplo simples pode ser o listado abaixo, gravando o arquivo teste.py.
#!/usr/bin/python3
print("Aprendendo Python no Phylos.net!")
Para executá-lo basta escrever no prompt do terminal, lembrando que, por default arquivos não pode ser executados diretamente por motivos de segurança (pois podem conter instruções maliciosas para o sistema). Eles devem ser tornados executáveis com chmod +x arquivo, o que dá permissão para todos os usuários e todos os grupos.
# a arquivo deve ter permissão do sistema para ser executado como programa
$ chmod +x teste.py
# depois:
$ ./teste.py
# alternativamente podemos executar (sem o #!)
$ python3 /caminho/completo/para/teste.py
# uma única linha no prompt de comando pode ser executada usando a opção -c
$ python3 -c 'print(2*67)'
↳ 134
#
$ /usr/bin/python -c 'print("Usuário")'
↳ Usuário
$ echo $PATH
↳ /var/home/usuario/.local/bin:/var/home/usuario/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin
No caso do comando /usr/bin/python3 o caminho completo para o interpretador (ou um link simbólico para ele) foi fornecido. A linha python3 -c ‘print(2*67)’ também funciona porque python3 está no PATH, o que pode ser verificado com echo $PATH, como mostrado acima.
Se um shebang não for incluído o sistema tentará executar o código na linguagem de comandos da própria shell, por exemplo a BASH shell.
Para que o script somente seja executado se for chamado diretamente do terminal modificamos teste.py usando a variável global __name__. Nada será executado se ele for chamado como módulo. Normalmente não colocamos um shebang em um módulo do Python contendo funções e definições de classes.
#!/usr/bin/python3
if __name__ == "__main__":
print("Aprendendo Python no Phylos.net!")
O shebang indica, através de um caminho absoluto, onde está o interpretador do Python, lembrando que ele pode variar em cada instalação. Caminhos relativos não são permitidos. Esse escolha aproveita o fato de que o sinal # (cerquilha ou hash, em inglês), representa um comentário no python e em várias outras linguagens de programação.
Essa notação é válida em shells Z shell ou Bash, que são usados em sistema como o macOS e Linux. No Windows ela é ignorada, sem causar danos. Para usar shebangs no Windows você pode instalar o Windows Subsystem for Linux (WSL). Podemos também associar globalmente no Windows arquivos com uma certa extensão (.py nesse caso) e um programa que o executará (como o interpretador Python). Mais sobre Python no Windows abaixo.
Shebang portátil
Como vimos um shebang deve conter o caminho completo (e não relativo) para o interpretador. Dessa forma se o código for executado em outro computador onde o interpretador esteja em local diferente, ele falhará em sua execução.
Para contornar essa questão podemos usar o comando (um aplicativo executável) env (ou printenv) que exibe as variáveis de ambiente (do environment). Se usado sem parâmetros ela simplesmente lista todas as variáveis definidas. Se usada com um parâmetro (no nosso caso o python3 ele indica a posição do interpretador e o acionada, como mostrado no código.
$ env
SHELL=/bin/bash
SESSION_MANAGER=local/unix:@/tmp/.ICE-unix/2035,unix/unix:/tmp/.ICE-unix/2035
COLORTERM=truecolor
... truncado ...
_=/usr/bin/env
# a última linha mostra onde está esse aplicativo
$ whereis env
env: /usr/bin/env /usr/share/man/man1/env.1.gz
# usado com um parâmetro
$ /usr/bin/env python3
Python 3.12.0 (main, Oct 2 2023, 00:00:00) [GCC 13.2.1 20230918 (Red Hat 13.2.1-3)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Nota: Por convencão o arquivo binário env (ou printenv) será sempre encontrado em /usr/bin/. Sua função é localizar arquivos binários executáveis (como python) usando PATH. Independentemented de como o python está instalado seu caminho será adicionado a esta variável e env irá encontrá-lo, caso contrário o python não está instalado. Ele é usado para criar ambientes virtuais, configurando as variáveis de ambiente.
Como resultado desse comportamento podemos escrever um shebang que encontra e executa o interpretador onde ele estiver. Para isso gravamos o arquivo teste.py da seguinte forma:
#!/usr/bin/env python3
print("Uma forma portátil de shebang!")
Como exemplo, podemos executar código em python 2 e python 3 informando qual interpretador queremos usar.
# gravamos 2 arquivos
# python_2.py
#!/usr/bin/env python2
print "Esse rodou no python 2"
# python_3.py
#!/usr/bin/env python3
print("Esse rodou no python 3")
# e os executamos com
$ ./python_2.py
Esse rodou no python 2
$ ./python_3.py
Esse rodou no python 3
Claro que ambas as versões devem estar instaladas. Observe que, no python 2 o print não é uma função e não exige o uso de parênteses. Podemos verificar qual é a versão do python em uso com o parâmetro -V.
$ /usr/bin/env python -V
Python 3.12.0
Nota: Na minha instalação os comandos python, python3 e python3.12 todos apontam para o mesmo interpretador. No entanto pode ser arriscado usar a forma $ /usr/bin/env python sem definir a versão pois ela pode ter significados diferentes em outras instalações.
Python no Windows
A maioria dos sistemas operacionais como o Unix, Linux, BSD, macOS e outros trazem uma instalação do Python suportada pelo sistema, o que não ocorre com o Windows. Para resolver essa situação a equipe do CPython compilou instaladores para o Windows para que se possa instalar o interpretador e as bibliotecas, para o usuário ou globalmente no sistema. Também são disponibilizados arquivos ZIPs para os módulos adicionais. As versões do Python ficam limitadas a algumas versões do Windows. Por exemplo, o Python 3.12 tem suporte no Windows 8.1 ou mais recentes. Para uso com o Windows 7 é necessário instalar o Python 3.8.
Diversos instaladores estão disponíveis para Windows, cada um com vantagens e desvantagens. O instalador completo contém todos os componentes e é a melhor opção para desenvolvedores que usam Python para projetos variados. O pacote da Microsoft Store é uma instalação simples do Python adequada para executar scripts e pacotes e usar IDLE ou outros ambientes de desenvolvimento. Ele requer Windows 10 ou superior e pode ser instalado com segurança sem corromper outros programas. Ele também fornece muitos comandos convenientes para iniciar o Python e suas ferramentas.
O pacote nuget.org instala um ambiente reduzido, suficientes para pacotes Python e executar scripts, mas não são atualizáveis, além de não possuiren ferramentas de interface de usuário. O pacote embeddable é um pacote mínimo de Python adequado para incorporação em um aplicativo maior sem ser diretamente acessível ao usuário. Uma descrição mais detalhada dos vários pacotes de instalação pode ser encontrada no documento Using Python on Windows.
Os instaladores criam uma entrada do menu Iniciar para o interpretador Python. Também podemos iniciá-lo no prompt de comando, configurando a variável de ambiente PATH. O instalador oferece a opção de configurar isso automaticamente, na opção “Adicionar Python ao PATH”. A localização da pasta Scripts\ também é inserida. Com isso de pode digitar python na linha de comando para executar o interpretador e pip para instalar pacotes. Também é possível executar seus scripts com opções de linha de comando.
A variável PATH também pode ser modificar manualmente para incluir o diretório de instalação do Python, delimitado por ponto e vírgula de outras entradas. Por exemplo ela pode ter a seguinte conteúdo: C:\WINDOWS\system32;C:\WINDOWS;C:\Program Files\Python 3.9
Inicializador Python para Windows
O lançador, ou inicializador, Python para Windows é um utilitário que permite localizar e executar diferentes versões do Python. Com ele podemos indicar dentro dos scripts , ou na linha de comando, qual a versão do interpretador deve ser usada e executada, como fazemos com o Shebang no Linux ou macOS, independentemente do conteúdo da variável PATH. O inicializador foi originalmente especificado no PEP 397.
É preferível instalar o inicializar por usuário em vez de instalações globais no sistema. Instalações globais no sistema do Python 3.3 e posteriores incluem o inicializador e o adicionam ao PATH. Ele é compatível com todas as versões do Python. Para verificar se o inicializador está disponível, execute o comando py no prompt de comando. Essa e outras formas do comando ficam disponíveis:
$ py
# inicia e mostra a última versão do Python instalada.
# Comandos digitados aqui são enviados diretamente para o Python.
# Se existem mais de um versão instalada, a versão desejada deve ser especificada:
$ py -3.7
# para Python 2, se instalada:
$ py -2
# se o instalador não estiver instalado, a mensagem será mostrada:
$ py
↳ 'py' is not recognized as an internal or external command, operable program or batch file.
# para ver todas as versões do Python instaladas:
$ py --list
Muitas vezes, principalmente quando vamos instalar diversos módulos para desenvolver scripts ou aplicativos, usamos ambiente virtuais, descritos no artigo Ambientes Virtuais, Pip e Conda. Eles podem ser criados com o módulo venv da biblioteca padrão ou virtualenv, uma ferramenta externa. Se o inicializador for executado dentro de um ambiente virtual sem a especificação explícita de versão do Python, ele executará o interpretador do ambiente virtual, ignorando o global. Caso outro interpretador, que não o instalado no ambiente virtual, seja desejado é necessário especificar explicitamente a outra versão do Python.
Por exemplo: Suponha que Pyton3 e Pyton2 estão instalados, e Pyton3 aparece primeiro no PATH. Criamos um arquivo sistema.py com o conteúdo:
#! python
import sys
sys.stdout.write(f"Estamos usando a versão do Python \n (sys.version,)")
# na mesma pasta executamos
$ py sistema.py
# informações sobre Python 3 são exibidas
# Se alteramos o código do script para
#! python2
import sys
sys.stdout.write(f"Estamos usando a versão do Python \n (sys.version,)")
# e executamos
$ py sistema.py
# informações sobre Python 2 são exibidas
# Sub versões podem ser especificadas
! python3.10
# Isso corresponde ao comando
$ py -3.10 sistema.py
Claro que é uma boa prática para desenvolvedores Windows, por compatibilidade, usar o Shebang necessário para execução nos Sistema tipo Unix.
Criando executáveis
O Python não possui suporte integrado para a construção de executáveis independentes. No entanto podemos lançar mão de algumas ferramentas, geralmente desenvolvidos pela comunidade, que resolvem esse problema de alguma forma. As mais populares são as seguintes (os ícones são links para instruções):
Cada um deles possui suas limitações e aspectos fortes de uso. Para definir qual deles usar você deve decidir qual plataforma deseja atingir, pois cada ferramenta de empacotamento suporta um conjunto específico de operações dos sistemas. É melhor que você tome essa decisão logo no início da vida do projeto. Você pode encontrar uma descrição mais precisa e completa dessas ferramentas no texto de Jaworski e Ziadé, citado na bibliografia.
Bibliografia
Michał Jaworski e Tarek Ziadé: Expert Python Programming, Packt Publishing, Birmingham, 2021.
“Como é possível que uma massa gelatinosa de um quilo e meio que cabe na palma de uma mão, possa imaginar anjos, contemplar o significado do infinito e até mesmo questionar seu lugar no cosmos? Especialmente inspirador é saber que qualquer cérebro, incluindo o seu, é composto de átomos forjados há bilhões de anos nos corações de incontáveis estrelas distantes. Estas partículas flutuaram durante eras e por anos-luz, até serem reunidas pela gravidade nos blocos de matéria em que estamos aqui e agora. Parte desses átomos formaram conglomerados – os cérebros – capazes de ponderar sobre as próprias estrelas de onde vieram, fazer instropecção sobre sua própria capacidade de pensar e questionar sua capacidade de se maravilhar. Com a chegada dos humanos o universo se tornou consciente de si mesmo. Este é, verdadeiramente, o maior mistério de todos.”
— V. S. Ramachandran em The Tell-Tale Brain: A Neuroscientist’s Quest for What Makes Us Human.
O que é Consciência
Inseri no final vários vídeos do TED Talks que abordam esse tema. Todos estão em inglês mas com o recurso de legendas em português. Clique no ícone e selecione “Portuguese, Brazilian”.
Nós, humanos, somos seres que observam, dotados de introspecção, capacidade de análise e interpretação. Elaboramos uma descrição sofisticada do mundo externo através de nossa cultura e, principalmente, daquilo que chamamos de conhecimento científico. O que temos é uma descrição razoavelmente completa e bastante funcional. Para fazer isso usamos de criatividade. No entanto, não temos nenhuma certeza de que nossos modelos são uma descrição fiel do que existe e acontece no universo ou mesmo se as expressões “existe e acontece” têm algum sentido científico. Não temos a menor noção do que significa “mundo objetivo ou real”.
O pensamento moderno sustenta que os modelos científicos são aproximações recursivas do que se experimenta na natureza e se tenta descrever. Eles são aproximações porque é muito improvável que descrevam todo o fenômeno em questão, e são recursivos porque se reformam e ganham precisão e detalhe com o aumento da tecnologia de observação e do embasamento teórico envolvido, a partir do que já é conhecido. Aproveite para ler, nesse site:
Apesar de tantos progressos, conhecemos muito pouco do que se passa em nosso interior, em nossa subjetividade. Não sabemos como foi possível elaborar o edifício da ciência, nem da cultura nem da própria civilização. Entender a consciência é um grande problema não resolvido. E, no entanto, ainda que de natureza sutil e de difícil captura, a consciência é absolutamente tudo aquilo que experimentamos, o nosso único ponto de acesso ao que existe. O contato com objetos sólidos, a luz de tantas tonalidades que percebemos na natureza e até o calor da companhia humana, a raiva o apego e o amor, todos esses fenômenos estão em nossa consciência, são parte de nossa interioridade. Aquilo que chamamos de realidade objetiva consiste, em última análise, de tudo aquilo que conseguimos capturar do mundo externo por vários meios, e que conseguimos precessar com nosso mecanismo interno de cognição e processamento. De certa forma, não cabe dizer que vivemos em dois mundos, o exterior e o interior, porque tudo o que pudemos capturar, em todos os tempos, está dentro de nossa subjetividade … ou não existe para nós.
É possível argumentar que somos capazes de coletar, armazenar e analisar dados relativos a partes do mundo que não são diretamente acessíveis aos nossos sentidos, como ocorre com a coleta de imagens no infravermelho ou ultravioleta. Mas só tomamos consciência dessas coisas quando convertemos essas informações para algo que esteja dentro de nosso espectro de percepção, mesmo que sejam apenas números e gráficos. Diremos portanto que a experimentação converteu informações fora de nosso espectro sensorial para outra faixa que podemos observar.
Não se trata aqui de negar a existência do mundo exterior, como fazem algumas abordagens filosóficas e religiosas. O mundo está lá (ou aqui) de alguma (ou outra) forma. Mas não temos nenhuma noção de qualquer grau de realidade nesse mundo físico e objetivo. Sabemos que ele reage com regularidade e consistência às nossa perguntas, sejam por meio da mera interação cotidiana ou de um experimento científico. Para a alegação de que construímos com a nossa mente o mundo a nosso redor, podemos recuperar a memória dos vários “experimentos com resultado negativo”. São esses os experimentos realizados para confirmar uma visão de mundo amplamente aceita pela comunidade científica da época e que, no entanto, retornam resultados que negam essa mesma visão. Foi o que ocorreu com o experimento de Michelson Morley que mostrou que a velocidade da luz no vácuo é independente do observador, um dos fundamentos da Teoria de Relatividade de Einstein; ou as inúmeras observações incoerentes com a física clássica que originaram a mecânica quântica.
David John Chalmers, foto ao lado, (nascido em 20 de abril de 1966, na Austrália) é um filósofo e cientista cognitivo, especialista em filosofia da mente e da linguagem. Chalmers é bem conhecido por ter formulado o chamado problema difícil da consciência (the hard problem of consciousness).
O problema difícil
O problema difícil consiste na discussão de como e por que os humanos (ou outros organismos) possuem consciência dos fenômenos e os transformam em experiências subjetivas. Ele é diferente dos chamados “problemas fáceis” que demandam a explicação de sistemas físicos que nos permitem discriminar, coletar e processar informações, explicar nossos modos comportamento e relatar nossas descobertas, por exemplo. Esses são problemas que admitem explicações, pelo menos em princípio, seja por meios mecânicos ou de comportamento. Pesquisadores e filósofos que propõem a existência do “problema difícil” argumentam que ele é intrinsecamente diferente e não admitem a explicação mecanicista ou comportamental, nem mesmo em princípio.
Importante mencionar que nem todos os filósofos ou neurocientistas concordam sequer com a existência do “problema difícil”. Independentemente disso, o conceito é útil para se debater e pensar a questão.
Qualia
Para fazer referência às qualidades subjetivas da experiência mental e consciente foi proposto o termo QUALIA, buscando expressar a experiência pessoal e subjetiva da sensação de uma cor, de um sentimento como uma emoção ou a percepção da dor, por exemplo. O conceito de Qualia surge para representar uma lacuna em nosso entendimento sobre o que diferencia qualidades subjetivas da percepção e o mecanismo de captação e processamento, o cérebro. Por definição, as propriedades da experiência sensorial apenas são cognoscíveis para o indivíduo que as experimentam. Além disso, elas são incomunicáveis.
Daniel Dennett listou quatro propriedades comumente associadas aos qualia. Qualia são:
inefáveis; não podem ser comunicados ou apreendidos exceto pela experiência direta,
intrínsecos; são propriedades próprias e não definidas por meio de relações com outros objetos,
privados; não podem ser submetidos a comparações entre subjectividades diversas,
direta e imediatamente apreensíveis pela consciência; a experiência de qualia é completa e imediata.
Antes de prosseguir a leitura, imagine como você descreveria o que é o vermelho para uma pessoa que só enxerga tons de cinza!
Física e descrição do mundo
Consideramos Galileu Galilei o pai da física moderna por ele ter dado início a um longo programa de testes sobre a natureza inquirida sob a forma de experimentação. Entendemos hoje que a ciência é feita por meio de uma dinâmica entre o que foi chamado empirismo e idealismo. Um experimento sozinho, sem um embasamento teórico que o descreva, não é suficiente, e o puro processamento intelectual sobre o mundo dos fenômenos não traz respostas conclusivas se elas não podem ser verificadas empiricaamente. Esse programa nos permitiu elaborar um desenho do universo onde partículas e campos interagem de modo (razoavelmente) compreendido, ainda que não completo. Ainda assim a parte cognição, o próprio princípio que nos permite entender, permanece completamente fora do escopo científico. Na visão padrão das coisas a consciência está apenas em cérebros que, evidentemente, constituem uma porção muito reduzida do universo completo.
Panpsiquismo
A dificuldade em exibir uma teoria que explica o surgimento de consciência emanada de partículas supostamente sem propriedades conscientes levou muitos pensadores, antigos e modernos, a propor o conceito de “panpsiquismo”. Em seu livro “O Erro de Galileu: Fundamentos para uma Nova Ciência da Consciência” o filósofo Philip Goff apresenta essa perspectiva radical com a pergunta: “e se a consciência não for uma produção especial do cérebro, mas uma qualidade inerente a toda a matéria?” Nessa proposta as partículas, além de suas propriedades físicas usuais, como massa e carga elétrica, possuem alguma forma de interação com o resto do mundo de forma a poder formar consciências em algum nível de agrupamento complexo de matéria. Desnecessário pontuar que essa é uma especulação que pode se tornar importante no futuro, mas por enquanto não tem qualquer status de teoria (nem mesmo de hipótese) científica. Não existe qualquer noção sobre serem todas as partículas dotadas dessa propriedade ou se ela repousa em algumas, como elétrons ou quarks.
O próprio Chalmers propôs, em uma palestra do TED Talks, que um fóton “poderia possuir algum elemento de puro sentimento subjetivo, algum precursor da consciência.” Juntando-se a ele o neuroscientista Christof Koch afirmou no livro Consciousness, 2012, que se aceitarmos a consciência como um fenômeno real, independente de qualquer meio material particular, então “em um passo simples teremos que admitir que todo o cosmos está permeado pela senciência.”
Deve ficar claro aqui que o conceito de panpsiquismo não é aceito pela maioria dos cientistas e pensadores, nas ciências físicas ou mesmo na filosofia. Mesmo Goff admitiu as dificuldades existente para se responder alguns problemas, entre eles a explicação de como a reunião de muitas partículas com pequena senciência pode gerar um consciência como a humana. O neurocientista Anil Seth, em seu livro Being You, 2021, criticou o panpsiquismo como algo que “realmente não explica nada e não leva a hipóteses testáveis. É uma saída fácil para o aparente mistério representado pelo problema difícil.”
Fisicalismo
A consciência é modernamente vista (por uma maioria, com pequena margem) como um fenómeno emergente, o resultado da existência de sistemas complexos, como os cérebros humanos. Nesta proposta, também especulativa e exploratória, neurónios individuais não são conscientes, e as propriedades observadas de consciência cerebral só existem coletivamente como resultado da interação de um grande número de neurônios (entre 85 a 100 bilhões de neurônios, nos humanos). Essas interações e a emergência dos processos conscientes são também, reconhecidamente, pouco compreendidas.
Pesquisas mostram que um pouco mais da metade dos filósofos acadêmicos defendem essa visão, conhecida como “fisicalismo” ou “emergentismo”, enquanto aproximadamente um terço rejeita o fisicalismo para se inclinar a alguma alternativa, entre elas o panpsiquismo. Fisicalismo é o conceito de que o mundo pode ser inteiramente explicado usando descrições físicas. Até mesmo coisas aparentemente não físicas se reduziriam a uma descrição que usa apenas partículas e campos físicos, em a necessidade de se agregar elementos externos.
Crick e Watson descobriram juntos o mecanismo da hereditariedade por meio da dupla hélice de DNA.
Não é raro que físicos e biólogos adotem posições mais próximas do fisicalismo, na defesa de que não existe nada além de partículas e interações. Francis Crick, biofísico e neurocientista britânico, defendia que a consciência é sim um objeto tratável pela ciência. Ele e James Watson sustentavam que a ciência esclareceria a consciência através da descoberta de seus correlacionamentos neurais e identificaram como uma possível base para o fenômeno o disparo sincronizado de células do cérebro, numa taxa de 40 vezes por segundo.
O quarto de Mary
Frank Jackson sugeriu um experimento mental que ele denominou “O quarto de Mary” (Mary’s Room) para desafiar a visão fisicalista. Podemos descrever em termos completamente físicos os nossos sentimentos privados, nossas “qualia”?
Imagine uma neurocientista chamada Mary vivendo em um quarto fechado onde tudo é preto ou branco. Ele tem a seu dispor livros e um computador e passa seu tempo estudando tudo o que consegue sobre a cor “vermelha”. Ela estudou sobre a física das ondas de luz e sabe localizar o vermelho no espectro eletromagnético, aprendeu como o olho humano processa a luz e envia informações sobre ela para o cérebro. Ela entendeu perfeitamente como o cérebro interpreta esses sinais como a cor vermelha e ainda pesquisou sobre todas as associações poéticas envolvendo o vermelho. No entanto, tristemente, Mary nunca viu por si mesma o vermelho.
Um dia, suponha, Mary consegue sair de seu mundo preto e branco e vê uma rosa vermelha. Uma questão filosófica é levantada: Mary descobre alguma novidade quando vê a flor, sua compreensão de vermelho é ampliada?
Pense: Qual é a sua opinião? Mary obterá uma informação nova sobre o vermelho?
Se acreditamos que ela aprendeu algo novo então somos obrigados a concluir que uma descrição puramente física do mundo não pode ser completa. Existe algo que está além e o fisicalismo está incompleto. “Qualia” não estão entre as propriedades físicas e Mary jamais “saberia” o que é vermelho sem enxergá-lo diretamente.
Embora Jackson tenha criado esse experimento hipotético, ele mesmo rejeitou seu argumento pois não acreditava que Mary pudesse aprender algo novo sobre o mundo. Ele defendia que, nesse caso, ela teria aprendido uma novidade sobre si mesma. A “cor vermelha” em qualia não pertence ao mundo objetivo mas é uma propriedade de quem observa.
Mas, outra pergunta vem a tona quando se tenta salvar o fisicalismo: propriedades subjetivas estão no mundo físico? Jackson acredita que sim e argumenta que, se tivéssemos condições tecnológicas para reproduzir a neurobiologia, construir um cérebro artificial tão sofisticados como o cérebro humano, a cor vermelha, e os comportamentos associados a ela, seriam reproduzidos com fidelidade e transformaríamos qualia em algo objetivo.
O argumento de Frank Jackson para rebater o fisicismo, estabelecendo que a experiência envolve elementos que estão além das propriedades físicas da natureza, faz parte do Argumento do Conhecimento. Ele está baseado na ideia de que alguém, mesmo com pleno conhecimento físico sobre outro ser consciente, pode não ter conhecimento completo sobre como é ter as experiências do outro.
Você acredita que uma inteligência artificial ultra sofisticada, que simula perfeitamente um diálogo humano, incluindo suas emoções, perplexidades e inseguranças, possui qualia? Ela pode sofrer, admirar e sentir medo? Podemos um dia ter leis contra o “assassinato” de robôs e máquinas inteligentes?
Outras objeções contra o panpsiquismo são apresentadas, entre elas por ele não ajudar a resolver o problema de “Outras Mentes”. Temos, por definição, acesso a nossa própria mente mas, como podemos saber qualquer coisa sobre o que se passa na mente de outra pessoa? Esse problema está relacionado com as próprias propriedades de qualia, como as descritas por Dennet. Por causas de objeções desse tipo se tem sugerido que o panpsiquismo seja algo similar à invocação do Deus das Lacunas, uma invocação ex-machina para suprir deficiências da descrição científica.
Solipisismo é uma forma extrema da situação de “Outras Mentes”. Como você pode ter certeza de que uma pessoa em seu ambiente está de fato consciente ou se não passa de uma simulação? O solipisismo é a sugestão de que, talvez, você seja o único ser real do universo, criando a realidade que te cerca.
O cosmopsiquismo é outra tentativa, sugerindo que todo o universo é consciente e que as consciências individuais e localizadas não geram senciência mas apenas agregam aquela que já existe em toda a parte.
A Teoria da Mente
“Teoria da Mente é a capacidade em considerar os próprios estados mentais e os das outras pessoas, com a finalidade de compreender e predizer comportamentos e pensamentos do outro, por meio, por exemplo, de suas expressões, ações, jeito de falar.“
— Deborah Kerches, dradeborahkerches.com.br
Na psicologia a forma como percebemos a mente de outras pessoas, e seus estados, foi denominada Teoria da Mente. Ela consiste na formulação de um modelo pessoal e interno que visa descrever como a outra pessoa se sente, no que ela acredita, o que pretende e deseja. Consideramos que temos uma “teoria” sobre o estado da outra pessoa exatamente por não termos acesso direto a seus estados internos e, um bom desenvolvimentos desse modelo permite, por exemplo, que tenhamos empatia. Uma teoria da mente deficiente pode ser um sinal de uma desordem como o autismo, déficit de atenção ou esquizofrenia.
Imagine que você assiste, sem interferir, a cena representada na imagem acima: Bia guarda uma bola em sua cesta e sai da sala. Sem que Bia perceba, Ana tira a bola da cesta e coloca em sua caixa. Quando Bia voltar sabemos que ela irá procurar a bola em seu cesto. Temos um quadro mental que acompanha o estado do mundo na perspetiva de Bia. Este quadro é a teoria da mente, segundo o espectador. Uma criança muito pequena, ou um adulto com alguma deficiência para construir esse mapa mental, poderá dizer que Bia deve procurar a bola na caixa pertencente a Ana (onde ele sabe que a bola está).
Empatia é a capacidade de um indivíduo de compreender o estado emocional ou sofrimento físico de outra pessoa. Como ela é baseada na percepção de estados internos em outro indivíduo ela está associada de perto com a capacidade de construir teorias da mente eficazes. Pesquisas mostram que indivíduos do sexo feminino possuem, na média, maior empatia do que as do sexo masculino, enquanto as crianças, meninos e meninas, mais empáticos levam para a vida adulta essa propriedade. Essas verificações, segundo se acredita atualmente, são decorrentes de processos evolucionários e não explicadas por diferenciação ambiental ou aspectos culturais.
Diversos pesquisadores sugeriram independentemente que a empatia está intimamente associada com o funcionamento dos neurônios espelhos. Esses neurônios são responsáveis por atitudes causadas por volição própria do indivíduo mas também disparam quando ele observa as mesmas atitudes em outro indivíduo, estabelecendo uma conexão. Literalmente eles causam dor em quem observa outra pessoa em sofrimento.
Correlatos Neurais da Consciência
Todas essas considerações revelam dois aspectos: (1) o estudo da consciência é muito difícil; (2) algum progresso importante tem sido feito recentemente. Abandonamos o estado de aceitar a consciência como algo fora do universo, sem participação no fenômeno estudado para inserí-la no próprio mundo que queremos compreender. Queremos encontrar os “correlatos neurais da consciência” (Neuronal Correlates of Consciousness, NCC), os mecanismos neuronais mínimos que, em conjunto, são suficientes para provocar a experiência consciente. A dor corporal fazem as células nervosas se agitarem de alguma forma específica? Existem “neurônios especiais da consciência” que devem ser ativados? Eles estão localizados em regiões específicas do cérebro?
Neurônios. Nature: Dennis Kunkel Microscopy/Science Photo Library
A busca por “correlatos neuronais da consciência” não é meramente acadêmica. As pessoas passam por estados inconscientes por diversos motivos: ela pode estar dormindo, pode ter sofrido um trauma violento, uma doença desabilitante ou pode estar morta. Também é possível que tenha sido exposta a uma droga, como a anestesia. Muitos pacientes no mundo inteiro ficam desacordadas ou em coma por longos períodos e nem sempre é possível saber se existe uma consciência interna aprisionada e sem conseguir se manifestar. Alguns estudos indicam que esse estado não é raro. É, portanto, essencial que se busque verificar por meios objetivos, através de EEGs ou outros aparatos médicos, se o paciente é portador de algum nível de consciência.
Se uma determinada região do cérebro sofre uma lesão podemos perder funcionalidades associadas a essa região. O cerebelo, por exemplo, é controlador de movimentos, particularmente o movimento fino necessário para o controle de um músico ou um atleta olímpico. Ele contém quatro vezes mais neurônios que todo o restante do cérebro. Ainda assim uma pessoa que sofre dano no cerebelo mantém suas habilidades motoras, embora perca parte de sua fluidez. Eles mantém sua experiência pessoal, seus sentidos, seu senso de individualidade e sua memória. Concluímos portanto que o cerebelo não é essencial para a experiência subjetiva.
Por outro lado uma lesão na medula espinhal pode desabilitar completamente as funções motoras de uma pessoa, enquanto danos ao neocórtex podem prejudicar a experiência de sentimentos. Muito do que sabemos sobre a especialização de blocos do cérebro advém de estudo de pacientes que sofreram lesões, sendo o caso de Phineas Gage um exemplo espetacular.
Phineas Gage
Operários em Vermont, EUA, em setembro de 1848, construiam uma estrada de ferro usando dinamite para explodir rochas. Phineas Gage colocou pólvora em buraco na rocha quando uma explosão lançou uma barra de metal de 1 metro e meio de comprimento contra sua cabeça. A barra entrou pela bochecha esquerda, destruiu seu olho e atravessou a parte frontal do cérebro, saindo pelo alto da cabeça, do lado direito. Gage permaneceu consciente, conseguindo caminhar e falar normalmente.
Apesar da gravidade do acidente ele sobreviveu e se recuperou fisicamente. Dois meses depois Gage já podia caminhar normalmente pela vila onde morava. No entanto sua personalidade ficou completamente transformada. Ele se tornou um homem de mau gênio, grosseiro, desrespeitoso com as pessoas e incapaz de aceitar conselhos. Ele passou um tempo de sua vida se apresentando como atração circense, morrendo doze anos após o acidente.
O caso de Phineas Gage é mencionado como uma das primeiras evidências indicando que lesões nos lóbulos frontais podem alterar a personalidade, emoções e a interação social. Antes disso se considerava que os lóbulos frontais eram estruturas sem função e não relacionadas com o comportamento humano. No entanto, seu cérebro só começou a ser estudado quatro anos após sua morte. Não se pode ter certeza sobre as extensões de suas lesões e nem temos um conhecimento completo de suas alterações de comportamento. A narrativa contribuiu, mesmo assim, para ilustrar o longo e árduo debate do século XIX sobre se existem áreas específicas do cérebro especializadas em funções mentais, ou se as funções estão espalhadas por todo o conteúdo craniano.
A foto de Phineas Gage, à esquerda, estava originalmente na coleção de Jack e Beverly Wilgus. Hoje ela se encontra no Warren Anatomical Museum, Harvard Medical School.
Hoje se acredita que existe localização de funções no cérebro, entre elas:
Movimentos voluntários são controlados pelo córtex motor primário, localizado no lobo frontal.
Linguagem é controlada pela área de Broca, no lobo frontal, responsável pela produção da linguagem. A área de Wernicke, no lobo temporal, é responsável pela compreensão da linguagem.
Visão é processada na área visual primária, no lobo occipital.
Memória de longo prazo, é controlada pelo o hipocampo, no lobo temporal.
Duas outras áreas específicas do cérebro merecem menção. A área de Broca, parte do lobo frontal é responsável pela expressão da linguagem; e a área de Wernicke, localizado no córtex cerebral, permite a compreensão da linguagem oral e escrita.
O termostato é um aparelho que usa propriedades da matéria para acionar ou desligar um sistema elétrico.
Apesar dessa possibilidade de localização de funções o cérebro é um órgão complexo e as funções cerebrais são interdependentes umas das outras. A linguagem não é só uma função do lobo frontal, mas também dos lobos temporal e parietal, por exemplo. Além disso sabemos hoje que existe a neuroplasticidade, a capacidade do cérebro de se reorganizar, alocando para áreas diferentes as funções prejudicadas de alguma forma, como no caso de uma lesão por doença ou acidente.
Christof Koch (a esquerda) e David Chalmers em 23 de junho, 2023, Nova Iorque. Foto: Jesse Winter para a revista Nature.
Ainda pertinente ao fisicalismo, David Chalmers sugeriu que o problema difícil poderia ser resolvido se aceitarmos que a “informação” é uma propriedade fundamental da realidade, podendo ser exibido em qualquer sistema e não apenas no com cérebro. Dessa forma mesmo sistemas simples, como por exemplo um termostato, pode ser entendido com possuindo um nível de consciência.
Filosofia da Mente
A filosofia da mente é o estudo filosófico da natureza da mente e de como ela se relaciona com corpo. Ela considera o prolema difícil de qualia, de estados e funções da mente, seus correlatos neurais e o funcionamento da cognição. No entando sua questão central está na relação entre mente e corpo. Grosso modo duas visões centrais disputam ter uma resposta para esse problema: o dualismo e o monismo.
O dualismo tem suas origens, na filosofia ocidental, no pensamento de René Descartes, século XVII. Descartes sugeria que a mente é uma substância independente do corpo, enquanto outros dualistas sustentam que ela é um grupo de propriedades independentes e emergentes que não podem ser reduzidas ao cérebro (sem ser uma substância distinta). Monismo é a defesa de que mente e corpo são entidades que não podem ser separadas, tese defendida, por exemplo, por Baruch Spinoza, um racionalista do século XVII.
Os fisicalistas, na defesa de que existem apenas entidades postuladas pela teoria física e o processo mental poderá ser, eventualmente, explicado em termos dessas entidades, são, naturalmente monistas. Para os idealistas apenas a mente existe e o mundo externo é uma ilusão criada pela mente.
O Problema Corpo-Mente
Figura de Descartes para explicar o dualismo mente-corpo.
O problema corpo-mente consiste na difuldade em se explicar como processos mentais podem controlar o corpo, o que são esses processos mentais e o mecanismo que permite a eles ativar ações físicas no corpo.
Uma experência sensorial consiste na obtenção de estímulos físicos oriundos do mundo externo, como ondas de luz atingindo os olhos, levadas até os centros de percepção causando alteração em nossos estados mentais. Essa percepção pode provocar atração ou repulsão ativando uma resposta física que movimenta o corpo. Essa ação corporal pode ser causada até mesmo por crenças, a noção de que um objeto inexistente está próximo, disparando os mesmos neurônios e músculos.
Neurociência
Todos esses problemas adquirem uma nova perspectiva com o surgimento da neurociência. Baseada na biologia e medicina do cérebro ela busca basicamente encontrar os correlações neurais entre mente e corpo, e esse estudo tem sido amplamente ampliado com o desenvolvimentos de aparelhos medidores, como máquinas de ressonância magnética e muitas outras.
Assim como em diversas outras áreas do conhecimento temos hoje uma enorme oportunidade de resolver grandes dúvidas e aperfeiçoar o entendimento do que significa ser humano. Claro que isso deve encontrar eco nos processos concretos da sociedade, como na medicina e na educação.
Você gostaria de ler mais sobre esse tema? Deixe nos comentários suas críticas, opiniões e sugestões para novos artigos.
Videos Recomendados sobre o tema da Consciência
Todos os vídeos estão em inglês mas com o recurso de legendas em português. Clique no ícone e selecione “Portuguese, Brazilian”.
What is Consciousness (O que é a consciência?)
Michael Graziano
How do you explain consciousness? (Como você expĺica a consciência?)
David Chalmers
Your brain hallucinates your conscious reality (Seu cérebro alucina sua realidade consciente)
Anil Seth
What is Consciousness? (O que é a consciência?)
Daniel Dennet
The long reach of reason
Steven Pinker e Rebecca Newberger Goldstein
Bibliografia
Livros:
Anil Seth: Being You, A New Science of Consciousness, Dutom, 2021.
Row (linha) é um controle que serve de container para outros controles e os exibe horizontalmente. Ele possui propriedades, eventos e métodos relativos ao layout e gerenciamento de rolagem da página (scroll) para evitar overflow (quando o conteúdo ocupa áerea maior que a disponível na página).
Propriedades de Row
Propriedades
Descrição
alignment
alinhamento horizontal dos filhos.
A propriedade MainAxisAlignment recebe um ENUM com os valores:
START(default) alinha à esquerda da Linha
END
CENTER
SPACE_BETWEEN
SPACE_AROUND
SPACE_EVENLY
auto_scroll
booleano, auto_scroll=True para mover a posição de scroll para o final quando ocorre atualização dos filhos. Para que o método scroll_to() funcione é necessário ajustar auto_scroll=False.
controls
uma lista de controles a serem exibidos na linha.
run_spacing
espaçamento entre as várias linhas (runs) quando wrap=True. Default: 10.
Linhas adicionais aparecem quando os controles não cabem dentro de uma linha única.
scroll
permite rolagem horizontal da linha para evitar overflow. A propriedade pode receber o ENUM ScrollMode com os valores:
None (default): não é rolagem e pode haver overflow.
AUTO: rolagem habilitada e a barra de rolagem só aparece quando ocorre o scroll.
ADAPTIVE: rolagem habilitada e a barra sempre visível quando aplicativo roda na web ou desktop.
ALWAYS: rolagem habilitada e a barra sempre visível.
HIDDEN: rolagem habilitada e a barra sempre oculta.
spacing
espaçamento entre controles na linha. Default: 10 pixeis. O espaçamento só é aplicado quando alignment é start, end ou center.
on_scroll_interval
limitação para o evento on_scroll em milisegundos. Default: 10.
tight
booleano, espaço a ser ocupado horizontalmente. Default: tight = False, usar todo o espaço os controles.
vertical_alignment
alinhamento vertical. A propriedade pode receber o ENUM CrossAxisAlignment os valores:
START (default)
CENTER
END
STRETCH
BASELINE
wrap
booleano, se wrap=True os controles filhos serão colocados em linhas adicionais (chamadas runs), caso não caibam em uma única linha.
Métodos de Row
Método
Descrição
scroll_to(offset, delta, key, duration, curve)
move a posição de rolagem para o offset absoluto, para um salto (delta) ou para o controle com key especificada.
Detalhes são idênticos ao do método de Column.scroll_to().
Eventos de Row
Evento
Dispara quando
on_scroll
a posição de rolagem da linha é alterada por um usuário. Consulte Column.on_scroll() para detalhes e exemplos do evento.
Uso das propriedades de row
No código abaixo são criados 30 controles container numerados que são dispostos em uma linha. Dois controle de deslizar (slide) ajustam as propriedades row.width (o número de colunas em cada linha) e row.spacing (o espaçamento entre cada objeto. Quando o número de objetos em uma linha é maior que o espaço permite, novas linhas são inseridas (runs).
import flet as ft # era 52
def main(page: ft.Page):
def items(count):
items = []
for i in range(1, count + 1):
items.append(ft.Container(ft.Text(value=str(i), color="white", size=20), alignment=ft.alignment.center,
width=40, height=40, bgcolor="#40A4D2", border_radius=ft.border_radius.all(10)))
return items
def muda_largura(e):
linha.width = float(e.control.value)
linha.update()
def muda_separa(e):
linha.spacing = int(e.control.value)
linha.update()
slid_separa = ft.Slider(min=0, max=50, divisions=50, value=0, label="{value}", on_change=muda_separa,)
slid_largura = ft.Slider(min=0, max=page.window_width, divisions=20, value=page.window_width,
label="{value}", on_change=muda_largura,)
linha = ft.Row(wrap=True, spacing=10, run_spacing=10, controls=items(30), width=page.window_width,)
txt1 = ft.Text("O primeiro controle seleciona o número de colunas:")
txt2 = ft.Text("O segundo controle seleciona espaçamento entre colunas:")
page.add(ft.Column([txt1, slid_largura,]),ft.Column([txt2, slid_separa,]), linha,)
ft.app(target=main)
O código gera, em algum ajuste dos controles de deslizar, a janela abaixo.
Column é um controle que serve de container para outros controles e os exibe verticalmente. Ele possui propriedades eventos e métodos relativos ao layout e gerenciamento do rolamento da página (scroll) para evitar overflow (quando o conteúdo ocupa áerea maior que a disponível na página.
Propriedades de Column
Propriedades
Descrição
alignment
define como os controles filhos devem ser colocados verticalmente.
A propriedade MainAxisAlignment recebe um ENUM com os valores:
START(default) alinha à esquerda da Linha
END
CENTER
SPACE_BETWEEN
SPACE_AROUND
SPACE_EVENLY
auto_scroll
auto_scroll=True para mover a posição de scroll o final quando ocorre atualização dos filhos. Para que o método scroll_to() funcione devemos fazer auto_scroll=False.
controls
lista de controles a serem exibidos na coluna.
horizontal_alignment
posicionamento horizontal dos controles filhos.
A propriedade recebe o ENUM CrossAxisAlignment com os valores:
START(default) alinha à esquerda da Linha
END
CENTER
STRETCH
BASELINE
on_scroll_interval
limita o evento on_scroll (em milisegundos). Default: 10.
scroll
habilita a rolagem vertical na coluna para evitar overflow de conteúdo.
A propriedade recebe um ENUM opcional ScrollMode com valores:
None (default): coluna não é rolável e pode haver overflow.
AUTO: rolagem habilitada e a barra de rolagem só aparece quando a rolagem é necessária.
ADAPTIVE: rolagem habilitada e a barra sempre visível em aplicativos na web ou desktop.
ALWAYS: rolagem habilitada e a barra sempre vivível.
HIDDEN: rolagem habilitada, a barra de rolagem está sempre oculta.
spacing
espaçamento entre os controles da coluna. Default: 10 pixeis. O espaçamento só é aplicado quando alignment = start, end, center.
run_spacing
espaçamento entre “runs” quando wrap=True. Default: 10.
tight
espaçamento vertical. Default: False (alocar todo o espaço para filhos).
wrap
se wrap=True a coluna distribuirá os controles filho em colunas adicionais (runs) se não couberem em uma coluna.
Métodos de Column
Método
Descrição
scroll_to(
offset, delta,
key, duration,
curve)
move a posição de rolagem para o offset absoluto, para um salto (delta) ou para o controle com key especificada.
Por exemplo:
(1) offset é a posição do controle, um valor entre a extensão mínima e máxima do controle de scroll.
(2) offset negativo conta a partir do final do scroll. offset=-1 para posicionar no final.
(3) delta move o scroll relativo à posição atual. Rola para trás, se negativo.
(4) key move o scroll para a posição especificada com key.
A maioria dos controles do Flet tem a propriedade key (equivalente ao global key do Flutter. keydeve ser única para toda a page/view. duration define a duração da animação de rolagem, em milisegundos. Default: 0 (sem animação). curve configura a curva de animação. Default: ft.AnimationCurve.EASE.
Eventos de Column
Evento
Dispara quando
on_scroll
a posição de rolagem é alterada por um usuário.
O argumento do gerenciador de eventos é instância da ft.OnScrollEvent com as propriedades:
event_type (str), tipo do evento de rolagem:
start: início da rolagem;
update: controle de rolagem mudou de posição;
end: início da rolagem (parou de rolar);
user: usuário mudou a direção da rolagem;
over: controle ficou inalterado por estar no início ou final;
pixels(float): posição de rolagem atual, em pixeis lógicos.
min_scroll_extent (float): valor mínimo no intervalo permitido, em pixeis.
max_scroll_extent (float): valor máximo no intervalo permitido, em pixeis.
viewport_dimension (float): extensão da viewport.
scroll_delta (float): distância rolada, em pixeis. Definido apenas em eventos update.
direction (str) : direção da rolagem: idle, forward, reverse. Definido apenas em evento user.
overscroll (float): número de pixeis não rolados, por overflow. Definido apenas em eventos over.
velocity (float): velocidade na posição de ScrollPosition quando ocorreu overscroll. Definido apenas em eventos over.
Expandindo controles na linha e na coluna
Todos os controles possuem a propriedade expand que serve para expandi-lo para preencher os espaços disponíveis dentro de uma linha. Ela pode receber um booleano ou um inteiro. expand=True significa expandir o controle para preencher todo o espaço. expand=int introduz um “fator de expansão” especificando como dividir um espaço com outros controles expandidos na mesma linha, ou coluna. O código:
cria uma linha contendo um TextField que ocupa o espaço disponível, e um ElevatedButton, sem expansão. A expansão é calculada em termos do tamanho de todos os controle na linha. É possível fornecer fatores que definem a proporção de expansão de cada controle. Por exemplo:
linha = ft.Row([
ft.Container(expand=1, content=ft.Text("A")),
ft.Container(expand=3, content=ft.Text("B")),
ft.Container(expand=1, content=ft.Text("C"))
])
cria uma linha com 3 controles ocupando 1, 3, 1 partes em 5, como exibido na figura,
Percentualmente a largura resultante de um filho é calculada como largura = expand / soma( todas as expands) * 100%.
Da mesma forma um controle filho em uma coluna pode ser expandido para preencher o espaço vertical disponível. Por exemplo, o código abaixo cria uma coluna com um Container que ocupando todo o espaço disponível e um controle Text na parte inferior servindo como uma barra de status:
coluna = ft.Column([
ft.Container(expand=True, content=ft.Text("Esse será expandido")),
ft.Text("Um texto usado como label")
])
Assim como no controle das linhas, podemos usar fatores numéricos em expand=n.
A palavra container do inglês é traduzida como contêiner (pt-br), plural contêineres. Para não criar confusão com a palavra técnica nós o chamaremos aqui por container, containers.
Um aplicativo do Flet abre sempre uma page que serve de container para o objeto View. Uma View é criado automaticamente quando uma nova sessão é iniciada. Ela é basicamente uma coluna (column) básica, que abriga todos os demais controles que serão inseridos na página. Dessa forma ele tem comportamento semelhante ao de uma column, e as mesmas propriedades. Uma descrição resumida será apresentada aqui. Para maiores detalhes consulte a descrição de column.
O objeto View é o componente visual de uma página Flet, responsável por renderizar os elementos da UI e gerenciar seu estado. Ele pode abrigar outros objetos como botões, campos de texto, imagens, etc, e organizá-los em uma estrutura hierárquica. Esses elementos são então renderizados na tela. O objeto View também possui métodos para lidar com eventos do usuário, como cliques em botões ou textos digitados nas caixas de texto.
Por exemplo, o código:
page.controls.append(ft.Text("Um texto na página!"))
page.update()
# ou, o que é equivalente
page.add(ft.Text("Um texto na página!"))
insere o texto na View que está diretamente criada sobre page. View possui as seguintes propriedades e métodos.
View: Propriedades
Propriedade
Descrição
appbar
recebe um controle AppBar para exibir na parte superior da página.
auto_scroll
Booleano. True para que a barra de rolagem se mova para o final quando os filhos são atualizados. Para que scroll_to() funcione deve ser atribuído auto_scroll=False.
bgcolor
Cor de fundo da página.
controls
Lista de controles a serem inseridos na página. O último controle da lista pode se removido com page.controls.pop(); page.update().
fullscreen_dialog
Booleano. True se a página atual é um diálogo em tela cheia.
route
Rota da visualização (não usada atualmente). Pode ser usada para atualizar page.route em caso de nova visualização.
floating_action_button
Recebe um controle FloatingActionButton a ser exibido no alto da página.
horizontal_alignment
Alinhamento horizontal dos filhos. Default: horizontal_alignment=CrossAxisAlignment.START.
on_scroll_interval
Definição do intervalo de tempo para o evento on_scrollo, em milisegundos. Default: 10.
padding
Espaço entre o conteúdo do objeto e suas bordas, em pixeis. Default: 10.
scroll
Habilita rolagem (scroll) vertical para a página, evitando overflow. O valor da propriedade está em um ENUM ScrollMode com as possibilidades:
None (padrão): nenhum scroll. Pode haver overflow.
AUTO: scroll habilitado, a barra só aparece quando a rolagem é necessária.
ADAPTIVE: scroll habilitado, a barra de rolagem visível quando aplicativo é web ou desktop.
ALWAYS: scroll habilitado, a barra sempre exibida.
HIDDEN: scroll habilitado, barra de rolagem invisível.
spacing
Espaço vertical entre os controles da página, em pixeis. Default: 10. Só aplicado quando alignment = start, end, center.
vertical_alignment
Alinhamento vertical dos filhos. A propriedade está em um ENUM MainAxisAlignmente com as possibilidades:
Move a barra de scroll para uma posição absoluta ou salto relativo para chave especificada.
View: Evento
Evento
Descrição
on_scroll
Dispara quando a posição da barra de rolagem é alterada pelo usuário.
O controle View é útil em situações que se apresenta mais em uma visualização na mesma página e será visto mais tarde com maiores detalhes.
Flet: Container
Um objeto Container é basicamente um auxiliar de layout, um controle onde se pode inserir outros controles, permitindo a decoração de cor de fundo, borda, margem, alinhamento e preenchimento. Ele também pode responder a alguns eventos.
Como exemplo, o código abaixo:
import flet as ft
def main(page: ft.Page):
page.title = "Contêineres com cores de fundo"
def cor(e):
c4 = ft.Container(content=ft.Text("Outro conteiner azul!"), bgcolor=ft.colors.BLUE, padding=5)
page.add(c4)
c1 = ft.Container(content=ft.ElevatedButton("Um botão \"Elevated\""),
bgcolor=ft.colors.YELLOW, padding=5)
c2 = ft.Container(content=ft.ElevatedButton("Elevated Button com opacidade=0.5",
opacity=0.5), bgcolor=ft.colors.YELLOW, padding=5)
c3 = ft.Container(content=ft.Text("Coloca outra área azul"),
bgcolor=ft.colors.YELLOW, padding=5, on_click=cor)
page.add(c1, c2, c3)
ft.app(target=main)
gera a janela na figura 1, após 1 clique no botão c3.
Figura 1: Novo container é adicionado ao clicar em “Coloca outra área azul”.
O container c3 reage ao evento clique, adicionando um (ou mais) botão azul à janela.
Container: Propriedades
Figura 2
A figura 2 mostra o esquema de espaçamentos entre controles: a largura e altura (width, height) do container, a margem (margin) entre a caixa de decoração e o container, a borda (border) da caixa e o espaçamento interno (padding) entre o controle e a caixa.
Propriedade
Descrição
alignment
Alinhamento do controle filho dentro do Container para exibir na parte superior da página. Alignment é uma instância do objeto alignment.Alignment com propriedades x e y que representam a distância do centro de um retângulo.
x=0, y=0: o centro do retângulo,
x=-1, y=-1: parte superior esquerda do retângulo,
x=1.0, y=1.0: parte inferior direita do retângulo.
Figura 3
Constantes de alinhamento pré-definidas no módulo flet.alignment são: top_left, top_center, top_right, center_left, center, center_right, bottom_left, bottom_center, bottom_right. Por exemplo, mostrado na figura 4:
Ativa a animação predefinida do container, alterando valores de suas propriedades de modo gradual. O valor pode ser um dos seguintes tipos:
bool: True para ativar a animação do container com curva linear de duração de 1000 milisegundos.
int: ajusta tempo em milisegundos, com curva linear.
animation: Animation(duration: int, curve: str): ativa animação do container com duração e curva de transição especificadas.
Por exemplo:
import flet as ft
def main(page: ft.Page):
c = ft.Container(width=200, height=200, bgcolor="red", animate=ft.animation.Animation(1000, "bounceOut"))
def animar_container(e):
c.width = 100 if c.width == 200 else 200
c.height = 100 if c.height == 200 else 200
c.bgcolor = "blue" if c.bgcolor == "red" else "red"
c.update()
page.add(c, ft.ElevatedButton("Animate container", on_click=animar_container))
ft.app(target=main)
O código resulta na animação mostrada abaixo, na figura 5: Figura 5: animação
bgcolor
Cor de fundo do container.
blend_mode
modo de mistura (blend) de cores ou gradientes no fundo container.
blur
Aplica o efeito de desfoque (blur) gaussiano sobre o container.
O valor desta propriedade pode ser um dos seguintes:
um número: especifica o mesmo valor para sigmas horizontais e verticais, por exemplo 10.
uma tupla: especifica valores separados para sigmas horizontais e verticais, por exemplo (10, 1).
uma instância de ft.Blur: especifica valores para sigmas horizontais e verticais, bem como tile_mode para o filtro. tile_mode é o valor de ft.BlurTileMode tendo como default ft.BlurTileMode.CLAMP.
border
Borda desenhada em torno do controle e acima da cor de fundo. Bordas são descritas por uma instância de border.BorderSide, com as propriedades: width (número) e color (string). O valor da propriedade border é instância de border.Borderclasse, descrevendo os 4 lados do retângulo. Métodos auxiliares estão disponíveis para definir estilos de borda:
Permite especificar (opcional) o raio de arredondamento das bordas. O raio é instância de border_radius.BorderRadius com as propriedades: top_left, top_right, bottom_left, bottom_right. Esses valores podem ser passados no construtor da instância, ou por meio de métodos auxiliares:
Define a opacidade da imagem ao mesclar com um plano de fundo: valor entre 0.0 e 1.0.
image_repeat
Descrita junto com o objeto image.
image_src
Define imagem do plano de fundo.
image_src_base64
Define imagem codificada como string Base-64 como plano de fundo do container.
ink
True para efeito de ondulação quando o usuário clica no container. Default: False.
margin
Espaço vazio que envolve o controle. margin é uma instância de margin.Margin, definindo a propriedade para os 4 lados do retângulo: left, top, right e bottom. As propriedades podem ser dadas no construtor ou por meio de métodos auxiliares:
margin.all(value)
margin.symmetric(vertical, horizontal)
margin.only(left, top, right, bottom)
Por exemplo:
container_1.margin = margin.all(10)
container_2.margin = 20 # same as margin.all(20)
container_3.margin = margin.symmetric(vertical=10)
container_3.margin = margin.only(left=10)
padding
Espaço vazio de decoração entre borda do objeto e seu container. Padding é instância da padding.Padding com propriedades definidas como padding para todos os lados do retângulo: left, top, right e bottom. As propriedades podem ser dadas no construtor ou por meio de métodos auxiliares:
padding.all(value: float)
padding.symmetric(vertical, horizontal)
padding.only(left, top, right, bottom)
Por exemplo:
container_1.padding = ft.padding.all(10)
container_2.padding = 20 # same as ft.padding.all(20)
container_3.padding = ft.padding.symmetric(horizontal=10)
container_4.padding=padding.only(left=10)
shadow
Efeito de sombras projetadas pelo container. O valor dessa propriedade é uma instância ou uma lista de ft.BoxShadow, com as seguintes propriedades:
spread_radius: espalhamento, quanto a caixa será aumentada antes do desfoque. Default: 0.0.
blur_radius: desvio padrão da gaussiano de convolução da forma. Default: 0.0.
color: Cor da sombra.
offset: Uma instância de ft.Offsetclasse, deslocamentos da sombra, relativos à posição do elemento projetado. Os deslocamentos positivos em x e y deslocam a sombra para a direita e para baixo. Deslocamentos negativos deslocam para a esquerda e para cima. Os deslocamentos são relativos à posição do elemento que o está projetando. Default: ft.Offset(0,0).
blur_style: tipo de estilo, ft.BlurStyleque a ser usado na sombra. Default: ft.BlurStyle.NORMAL.
A forma do conteiner. O valor é ENUM BoxShape: RECTANGLE (padrão), CIRCLE
theme_mode
O ajuste do theme_mode redefine o tema usado no container e todos os objetos dentro dele. Se não for definido o tema em theme é válido para o container e seus filhos.
theme
Ajuste o tema global e dos filhos na árvore de controle.
Segue um exemplo de uso:
import flet as ft
def main(page: ft.Page):
page.theme = ft.Theme(color_scheme_seed=ft.colors.RED)
b1 = ft.ElevatedButton("Botão com tema da página")
b2 = ft.ElevatedButton("Botão com tema herdado")
b3= ft.ElevatedButton("Botão com tema dark")
c1 = ft.Container(
b1,
bgcolor=ft.colors.SURFACE_TINT,
padding=20,
width=300
)
c2 = ft.Container(
b2,
theme=ft.Theme(
color_scheme=ft.ColorScheme(primary=ft.colors.PINK)
),
bgcolor=ft.colors.SURFACE_VARIANT,
padding=20,
width=300
)
c3 = ft.Container(
b3,
theme=ft.Theme(
color_scheme_seed=ft.colors.INDIGO
),
theme_mode=ft.ThemeMode.DARK,
bgcolor=ft.colors.SURFACE_VARIANT,
padding=20,
width=300
)
page.add(c1, c2, c3)
ft.app(main)
Figura 6: Temas
O tema principal da página é definido em page.theme, usando um seed vermelho. Os botões b1 e b2 simnplesmente herdam o tema da página. O botão b3 está no container definido com theme_mode=ft.ThemeMode.DARK, exibindo o tema escuro. O código gera a janela mostrada na figura 6.
Vale lembrar que c1 = ft.Container(b1,...) é equivalente à c1 = ft.Container(content = b1,...) sendo que o content só pode ser omitido se o conteúdo for inserido como primeiro parâmetro.urlDefine a URL a ser abertta quando o container é clicado, disparando o evento on_click.url_target
Define onde abrir URL no modo web:
_blank (default): em nova janela ou aba,
_self: na mesma janela ou aba aberta.
Container: Eventos
Evento
Dispara quando
on_click
o usuário clica no container.
class ft.ContainerTapEvent():
local_x: float
local_y: float
global_x: float
global_y: float
Obs.: O objeto de evento e é uma instância de ContainerTapEvent, exceto se a propriedade ink = True. Nesse caso e será apenas ControlEvent com data vazio.
As propriedades e.local_x e e.local_y se referem à posição dentro do container c1, enquanto e.global_x e e.global_y se referem à posição global, dentro da página.
on_hover
o cursor do mouse entra ou abandona a área do container. A propriedade data do evento contém um string (não um booleano) e.data = "true" quando o cursor entra na área, e e.data = "false" quando ele sai.
Um exemplo de um container que altera sua cor de fundo quando o mouse corre sobre ele:
import flet as ft
def main(page: ft.Page):
def on_hover(e):
e.control.bgcolor = "blue" if e.data == "true" else "red"
e.control.update()
c1 = ft.Container(width=100, height=100, bgcolor="red",
ink=False, on_hover=on_hover)
page.add(c1)
ft.app(target=main)
on_long_press
quando o container recebe um click longo (pressionado por um certo tempo).
Detalhes sobre o gradiente de cores
O gradiente na cor de fundo admite como valor uma instância de uma das classes: LinearGradient, RadialGradient e SweepGradient.
Figura 9: LinearGradient, a segundo com RadialGradient e a última com SweepGradient
A primeira imagem é gerada com LinearGradient, a segunda com RadialGradient e a última com SweepGradient.
São propriedades da classe LinearGradient:
begin
instância de Alignment. Posicionamento inicial (0.0) do gradiente.
end
instância de Alignment. Posicionamento final (1.0) do gradiente.
colors
cores assumidas pelo gradiente a cada parada. Essa lista deve ter o mesmo tamanho que stops se a lista for não nula. A lista deve ter pelo menos duas cores.
stops
lista de valores de 0.0 a 1.0 marcando posições ao longo do gradiente. Se não nula essa lista deve ter o mesmo comprimento que colors. Se o primeiro valor não for 0.0 fica implícita uma parada em 0,0 com cor igual à primeira cor em colors. Se o último valor não for 1.0 fica implícita uma parada em 1.0 e uma cor igual à última cor em colors.
tile_mode
como o gradiente deve preencher (tile) a região antes de begin depois de end. O valor é um ENUM GradientTileMode com valores: CLAMP (padrão), DECAL, MIRROR, REPEATED.
rotation
rotação do gradiente em radianos, em torno do ponto central de sua caixa container.
Mais Informações:
Gradiente linear na documentação do Flutter.
Unidade de medida de radianos na Wikipedia.
São propriedades da classe RadialGradient:
colors, stops, tile_mode, rotation
propriedades idênticas às de LinearGradient.
center
instância de Alignment. O centro do gradiente em relação ao objeto que recebe o gradiente. Por exemplo, alinhamento de (0.0, 0.0) coloca o centro do gradiente radial no centro da caixa.
radius
raio do gradiente, dado como fração do lado mais curto da caixa. Supondo uma caixa com largura = 100 e altura = 200 pixeis, um raio de 1 no gradiente radial colocará uma parada de 1,0 afastado 100,0 pixeis do centro.
focal
ponto focal do gradiente. Se especificado, o gradiente parecerá focado ao longo do vetor do centro até esse ponto focal.
focal_radius
raio do ponto focal do gradiente, dado como fração do lado mais curto da caixa. Ex.: um gradiente radial desenhado sobre uma caixa com largura = 100,0 e altura = 200,0 (pixeis), um raio de 1,0 colocará uma parada de 1,0 a 100,0 pixels do ponto focal.
São propriedades da classe SweepGradient:
colors, stops, tile_mode, rotation
propriedades idênticas às de LinearGradient.
center
centro do gradiente em relação ao objeto que recebe o gradiente. Por exemplo, alinhamento de (0.0, 0.0) coloca o centro do gradiente no centro da caixa.
start_angle
ângulo em radianos onde será colocada a parada 0.0 do gradiente. Default: 0.0.
end_angle
ângulo em radianos onde será colocada a parada 1.0 do gradiente. Default: math.pi * 2.
Graus e radianos
Figura 10: graus e radianos.
A maiora das medidas angulares na programação do flet (e do python em geral) é dada em radianos. Segue uma breve imagem explicativa do uso de radianos.
O objeto page é o primeiro conteiner na construção da árvore de controles do Flet, sendo o único que não está ligado a um conteiner pai. Ele contém o objeto View que, por sua vez abriga todos os outros controles. Uma instância de page e uma view primária são criadas automaticamente quando uma sessão é iniciada.
Métodos de page
Método
Ação
can_launch_url(url)
Verifica se a url pode ser acessada pelo aplicativo.
Retorna True se é possível gerenciar uma URL com o aplicativo. Caso retorne False isso pode significar que não há como vertificar se o recurso está disponível, talvez devido à falta de permissões. Nas versões mais recentes do Android e iOS esse método sempre retornará False, exceto se o aplicativo for configurado com essa permissão. Na web ele retornará False exceto para esquemas específicos, pois páginas web, por princípio, não devem ter acesso aos aplicativos instalados.
close_banner()
Fecha o banner ativo.
close_bottom_sheet()
Fecha o pé de página.
close_dialog()
Fecha a caixa de diálogo ativa.
close_in_app_web_view()
Fecha visualização de página web iniciada com launch_url() de dentro do aplicativo.
get_clipboard()
Recupera o último texto salvo no clipboard do lado do cliente.
go(route)
Um método auxiliar para atualizar page.route. Ele aciona o evento page.on_route_change seguido de page.update().
launch_url(url)
Abre uma URL em nova janela do navegador.
Abre uma nova página exibindo o recurso descrito na URL.
Admite os argumentos opcionais:
web_window_name: nome da janela ou tab de destino. “_self”, na mesma janela/tab, “_blank”, nova janela/tab (ou em aplicativo externo no celular); ou “nome_do_tab”: um nome personalizado.
web_popup_window: True para abrir a URL em janela popup. Default: False.
window_width – opcional, largura da janela de popup.
window_height – opcional, altura da janela de popup.
page.get_upload_url(file_name, expires)
Gera URL para armazenamento de upload.
scroll_to(offset, delta, key, duration, curve)
Move a posição de scroll para local absoluto ou incremento relativo. Detalhes em scroll_to.
set_clipboard(data)
Insere conteúdo no clipboard do lado do cliente (navegador ou desktop). Ex.: page.set_clipboard("Esse valor vai para o clipboard").
️ Move a janela do aplicativo para o centro da tela.
window_close()
️ Fecha a janela do aplicativo.
window_destroy()
️ Força o fechamento da janela. Pode ser usado com page.window_prevent_close = True para exigir a confirmação do usuário para encerramento do aplicativo.
import flet as ft
def main(page: ft.Page):
def fechar(e):
page.dialog = caixa_dialogo
caixa_dialogo.open = True
page.update()
def sim(e):
page.window_destroy()
def nao(e):
caixa_dialogo.open = False
page.update()
caixa_dialogo = ft.AlertDialog(
modal=True,
title=ft.Text("Confirme..."),
content=ft.Text("Você quer realmente fechar o aplicativo?"),
actions=[
ft.ElevatedButton("Sim", on_click=sim),
ft.ElevatedButton("Não", on_click=nao),
],
actions_alignment=ft.MainAxisAlignment.END,
)
page.add(ft.Text("Feche a janela do aplicativo clicando o botão \"Fechar\"!"))
page.add(ft.ElevatedButton("Fechar", icon="close", on_click=fechar, width=250))
ft.app(target=main)
window_to_front()
️ Traz a janela do aplicativo para o primeiro plano.
Eventos de page
Evento
Dispara quando
on_close
uma sessão expirou por um tempo configurado. Default: 60 minutos.
on_connect
o usuário da web conecta ou reconect uma sessão. Não dispara na primeira exibição de uma página mas quando ela é atualizada. Detecta a presença do usuário online.
on_disconnect
o usuário se desconecta de uma sessão, fechando o navegador ou a aba da página.on_error ocorre um erro não tratado.
on_keyboard_event
on_resize
É o evento disparado quando a janela do aplicativo é redimensionada pelo usuário.
Evento disparado quando a rota da página é alterada no código, pela alteração da URL no navegador ou uso dos botões de avançar ou retroceder. O objeto e passado automaticamente pelo evento é uma instância da classe RouteChangeEvent:
class RouteChangeEvent(ft.ControlEvent):
route: str # passando uma nova rota para a página raiz
on_scroll
a posição de scroll é alterada pelo usuário. Tem mesmo comportamento de Column.on_scroll.
on_view_pop
Evento disparado quando o usuário clica o botão Back na barra de controle AppBar.
O objeto de evento e é uma instância da classe ViewPopEvent.
class ViewPopEvent(ft.ControlEvent):
view: ft.View
sendo view uma instância do controle View, o conteiner da AppBar.
on_window_event
Evento disparado quando a janela do aplicativo tem uma propriedade alterada: position, size, maximized, minimized, etc.
Pode ser usado com window_prevent_close=True (para interceptar sinal de close) e page.window_destroy() para implementar uma lógica de confirmação de término do aplicativo.
Os nomes eventos de janela possíveis são: close, focus, blur, maximize, unmaximize, minimize, restore, resize, resized (macOS e Windows), move, moved (macOS e Windows), enterFullScreen e leaveFullScreen.
O objeto page é o primeiro conteiner na construção da árvore de controles do Flet, sendo o único que não está ligado a um conteiner pai. Ele contém o objeto View que, por sua vez abriga todos os outros controles. Uma instância de page e uma view primária são criadas automaticamente quando uma sessão é iniciada.
Vamos primeiro fazer uma descrição dessas propriedades, métodos e eventos, e depois mostrar exemplos de uso. Muitas vezes a mera descrição do elemento é suficiente para que as apliquemos no código. Em alguns casos notas adicionais estão linkadas.
Propriedades de page
Observação: Os itens marcados com o ícone tem disponibilidade restrita:
🌎 só disponíveis na Web,
🖥️ só disponíveis no desktop,
📱 só disponíveis em celulares,
🅾 Read Only (Somente leitura).
Propriedade
Descrição
auto_scroll
True se a barra de scroll deve ser automaticamente posicionada no final se seu filho é atualizado. Necessariamente auto_scroll = False para que o método scroll_to() funcione.
appbar
page.appbar recebe uma barra de controle do aplicativo no alto da page (diferente da barra da janela).
banner
Controle Banner no alto da página.
bgcolor
Cor de fundo da página.
client_ip
🌎 Endereço de IP do usuário conectado.
client_user_agent
🌎 Detalhes do navegador do usuário conectado.
controls
Lista de controles a exibir na página. Novos controles pode ser adicionados com o método usual de lista, controls.append(ctrl)). Para remover o último controle inserido na página usamos controls.pop().
# Exemplos:
page.controls.append(ft.Text("Olá!"))
page.update()
# alternativamente
page.add(ft.Text("Olá!"))
# page.add é um shortcut para page.controls.append() seguido de page.update()
# para remover (pop) o último controle da lista
page.controls.pop()
page.update()
dark_theme
Indica a instância do tema usado.
dialog
Um controle AlertDialog para ser exibido.
floating_action_button
Um controle FloatingActionButton para exibir no alto da página.
fonts
Importa fontes para uso em Text.font_family ou aplica fonte no aplicativo inteiro com theme.font_family. Flet admite o uso de fontes .ttc, .ttf, .otf. Exemplos: page.fonts
Recebe um dicionário {"nome_da_fonte" : "url_da_fonte"}. Essas fonts podem ser usadas com text.font_family ou theme.font_family, para aplicar a fonte em todo o aplicativo. Podem ser usadas fontes .ttc, .ttf, .otf.
Figura 1: Inserindo fontes
Para um recurso externo a “url_da_fonte” é a URL absoluta, e para fontes instaladas a URL relativa para um diretório assets_dir. Esse diretório deve ser especificado na chamada para flet.app(), podendo ser um caminho relativo ao local onde está main.py ou um caminho absoluto. Por exemplo, suponha a estrutura mostrada na figura 1:
Para usar a fonte “Open Sans” e “Kanit”, importada do GitHub, como default, podemos fazer:
import flet as ft
def main(page: ft.Page):
page.fonts = {
"Kanit": "https://raw.githubusercontent.com/google/fonts/master/ofl/kanit/Kanit-Bold.ttf",
"Open Sans": "/fonts/OpenSans-Regular.ttf"
}
page.theme = Theme(font_family="Kanit")
page.add(
ft.Text("Esse texto usa a fonte default Kanit"),
ft.Text("Esse texto usa a fonte Open Sans", font_family="Open Sans")
)
ft.app(target=main, assets_dir="assets")
height
🅾 Altura da página, geralmente usada junto com o evento page.on_resize.
horizontal_alignment
Alinhamento horizontal do controle filho em relação a seu conteiner. Determina como os controles serão posicionados na horizontal. Default é horizontal_alignment=CrossAxisAlignment.START, que coloca os controles à esquerda de page. CrossAxisAlignment é um ENUM com os valores: START (default), CENTER, END, STRETCH e BASELINE.
on_scroll_interval
Passos em milisegundo para o evento on_scroll event. Default é 10.
overlay
Lista de controles exibidos em pilha sobre o conteúdo da página.
padding
Espaço entre as bordas do controle e as do conteiner. Default é page.padding = 10.
platform
Sistema operacional onde o aplicativo está sendo executado. Pode ser: ios, android, macos, linux ou, windows.
pubsub
Implementação para transferência de mensagens entre sessões do aplicativo.
subscribe(handler)
Registra a sessão atual para emissão de mensagens. handler é uma função ou método contendo uma mensagem.
subscribe_topic(topic, handler)
Inscreve a sessão para recebimento de mensagens sobre tópico específico.
send_all(message)
Envia mensagem a todos os inscritos.
send_all_on_topic(topic, message)
Envia mensagem para todos os inscritos em um tópico específico.
send_others(message)
Envia mensagem para todos, exceto para quem envia.
send_others_on_topic(topic, message)
Envia mensagem para todos em um tópico específico, exceto para quem envia.
unsubscribe()
Remove inscrição da sessão atual de todas as mensagens enviadas.
unsubscribe_topic(topic)
Remove inscrição da sessão de todas as mensagens sobre o tópico.
unsubscribe_all()
Remove as inscrições da sessão de todas as mensagens.
Notas sobre subscribe, unsubscribe e send.
subscribe(handler) inscreve a sessão ativa do aplicativo para recebimento de mensagens. Se topic não for especificado todos os tópicos são enviados. handler é um método com um argumento que é a mensagem.subscribe_topic(topic, handler) especifica o tópico que será enviado.
send_all(message) envia para todos. send_all_on_topic(topic, message) especifica o tópico de envio.
Para remover a sessão da lista de destinatários de mensagens de um tópico use unsubscribe_topic(topic).
Para remover a sessão da lista de destinatários de mensagens de todos os tópicos: unsubscribe_all(), por exemplo quando o usuário fecha a janela:
🅾 pwa=True se o aplicativo está rodando como um Progressive Web App (PWA).
route
Define ou lê a rota de navegação da página
rtl
rtl=True para definir direção de texto da direita para esquerda. Default: False.
scroll
Habilita a página para rolagem (scroll), mostrando ou ocultando a barra de rolagem. scroll=ScrollMode.None é o default. ScrollMode é um ENUM com os valores:
None ▸ (default), a coluna não pode ser percorrida e o texto pode extrapolar o espaço (overflow).
AUTO ▸ a rolagem está ativada e a barra só aparece quando necessária.
ADAPTIVE ▸ a rolagem está ativada e barra aparece quando aplicativo está na web ou desktop.
ALWAYS ▸ a rolagem está ativada e barra está sempre visível.
HIDDEN ▸ a rolagem está ativado mas a barra está oculta.
session_id
🅾 ID único da sessão do usuário.
spacing
Espaço vertical entre controles na página. Default: 10 pixeis. Só é aplicado quando o alignment=start, end ou center.
splash
Um controle que é exibido sobre o conteúdo da página. Operações lentas podem ser indicadas por meio de um ProgressBar ou ProgressRing.
É exibido em cima da página de conteúdo. Pode ser usado junto com ProgressBar ou ProgressRing para indicar uma operação demorada.
from time import sleep
import flet as ft
def main(page: ft.Page):
def button_click(e):
page.splash = ft.ProgressBar()
btn.disabled = True
page.update()
sleep(3)
page.splash = None
btn.disabled = False
page.update()
btn = ft.ElevatedButton("Do some lengthy task!", on_click=button_click)
page.add(btn)
ft.app(target=main)
show_semantics_debugger
True para a exibição de informações emitidas pelo framework.
theme
Essa propriedade recebe uma instância de theme.Theme para personalizar o tema. No estágio atual de desenvolvimento do Flet um theme só pode ser gerado a partir de uma cor “semente” (“seed”). Por exemplo, para um tema claro sobre tom verde:
color_scheme_seed ▸ cor “semente” para servir de base ao algoritmo de construção do tema.
color_scheme ▸ uma instância de ft.ColorScheme para personalização do esquema Material colors derivedo de color_scheme_seed.
text_theme ▸ instância de ft.TextTheme para personalização de estilos de texto.
primary_text_theme ▸ instância de ft.TextTheme descrevendo o tema de texto que constrasta com a cor primária.
scrollbar_theme ▸ instância de ft.ScrollbarTheme para personalizar a aparência da barra de rolagem.
tabs_theme ▸ instância de ft.TabsTheme para personalizar a aparência do controle de Tabs.
font_family ▸ a fonte base para todos os elementos da UI.
use_material3 ▸ True (default) para usar Material 3; caso contrário use Material 2.
visual_density ▸ ThemeVisualDensity enum: STANDARD (default), COMPACT, COMFORTABLE, ADAPTIVE_PLATFORM_DENSITY.
page_transitions ▸ instância de PageTransitionsTheme para personalizar transições entre páginas (†).
† Transições de navegação: (theme.page_transitions personaliza transições entre páginas para diversas plataformas. Seu valor é uma instância de PageTransitionsTheme com as propriedades adicionais:
android ▸ default: FADE_UPWARDS
ios ▸ default: CUPERTINO
macos ▸ default: ZOOM)
linux ▸ default: ZOOM)
windows ▸ default: ZOOM
Transições suportadas estão em um ENUM ft.PageTransitionTheme: NONE (transição imediata e sem animação), FADE_UPWARDS, OPEN_UPWARDS, ZOOM, CUPERTINO.
Um conjunto de 30 cores para configuração de cores dos componentes.
TextTheme class
Personalização de estilo de textos.
ScrollbarTheme class
Personalização de cor, espessura, forma da barra de scroll.
TabsTheme class
Personalização da aparência de controles de TAB.
Navigation transitions
Personalização das transições entre páginas de navegação.
theme_mode
Tema da página: SYSTEM (default), LIGHT ou DARK
title
Título da página ou do navegador.
vertical_alignment
Alinhamento vertical dos controles filhos. Admite o ENUM MainAxisAlignment com os seguintes valores:
START (default)
END
CENTER
SPACE_BETWEEN
SPACE_AROUND
SPACE_EVENLY
Por exemplo vertical_alignment=MainAxisAlignment.START posiciona o filho no alto da página.
views
Uma lista de controles View para armazenar histórico de navegação. A última View é a página atual, a primeira é “root”, que não pode ser excluída.
web
True se a aplicativo está rodando no navegador.
width
🅾 Largura da página web ou janela de aplicativo, usualmente usada com o evento page.on_resize.
window_always_on_top
🖥️ Ajusta de a janela deve estar sempre acima das demais janelas. Default: False.
window_bgcolor
🖥️ Cor de fundo da janela do aplicativo. Pode ser usado com page.bgcolor para tornar a janela toda transparente.
Se usada com uma página transparente toda a janela fica transparente: page.window_bgcolor = ft.colors.TRANSPARENT e page.bgcolor = ft.colors.TRANSPARENT.
window_focused
🖥️ True para trazer o foco para essa janela.
window_frameless
🖥️ True para eliminar as bordas das janelas.
window_full_screen
🖥️ True para usar tela cheia. Default: False.
window_height
🖥️ Leitura ou ajuste da altura da janela.
window_left
🖥️ Leitura ou ajuste da posição horizontal da janela, em relação à borda esquerda da tela.
window_maximizable
🖥️ False para ocultar botões de “Maximizar”. Default: True.
window_maximized
🖥️ True se a janela do aplicativo está maximizada. Pode ser ajustada programaticamente.
window_max_height
🖥️ Leitura ou ajuste da altura máxima da janela do aplicativo.
window_max_width
🖥️ Leitura ou ajuste da largura máxima da janela do aplicativo.
window_minimizable
🖥️ Se False o botão de “Minimizar” fica oculto. Default: True.
window_minimized
🖥️ True se a janela está minimizada. Pode ser ajustada programaticamente.
window_min_height
🖥️ Leitura ou ajuste da altura mínima da janela do aplicativo.
window_min_width
🖥️ Leitura ou ajuste da largura mínima da janela do aplicativo.
window_movable
🖥️ macOS apenas. Se False impede a movimentação da janela. Default: True.
window_opacity
🖥️ Ajuste da opacidade da janela. 0.0 (transparente) and 1.0 (opaca).
window_resizable
🖥️ Marque como False para impedir redimensionamento da janela. Default: True.
window_title_bar_hidden
🖥️ True para ocultar a barra de título da janela. O controle WindowDragArea permite a movimentação de janelas de barra de título.
window_title_bar_buttons_hidden
🖥️ apenas macOS. True para ocultar butões de ação da janela quando a barra de título está invisível.
window_top
🖥️ Leitura ou ajuste da posição da distância da janela (em pixeis) ao alto da tela.
window_prevent_close
🖥️ True para interceptar o sinal nativo de fechamente de janela. Pode ser usado com page.on_window_event ou page.window_destroy() para forçar uma confirmação do usuário.
window_progress_bar
🖥️ Exibe uma barra de progresso com valor de 0.0 a 1.0 na barra de tarefas (Windows) ou Dock (macOS).
window_skip_task_bar
🖥️ True para ocultar a barra de tarefas (Windows) ou Dock (macOS).
window_visible
🖥️ True para tornar o aplicativo visível, se o app foi iniciado em janela oculta. window_visible=True torna a janela visível. Se o aplicativo é iniciado com view=ft.AppView.FLET_APP_HIDDENa janela é criada invisível. Para torná-la visível usamos page.window_visible = True.
window_width
🖥️ Leitura ou ajuste da largura da janela do aplicativo.
Estritamente dizendo deveríamos iniciar nosso estudo do Flet considerando os objetos mais básicos, no sentido de serem containeres de outros objetos. No entanto já vimos vários casos de pequenos aplicativos que usam botões. É difícil sequer exibir exemplos de código de GUI sem botões. Por isso vamos descrever aqui o uso dos botões, deixando para depois uma descrição dos controles de layout.
Alguns controles tem a função principal de obter informações do usuário, como botões, menus dropdown ou caixas de texto, para inserção de dados. Outros servem para a exibição de informações calculadas pelo código, mostrando gráficos, figuras ou textos. As caixas de textos podem ser usadas em ambos os casos.
Buttons (botões)
Os seguintes tipos de botões estão disponíveis (e ilustrados na figura 1), contendo as propriedades, métodos e respondendo a eventos:
Vamos usar alguns exemplos para ilustrar as propriedades e métodos desses objetos.
import flet as ft
def main(page: ft.Page):
def mudar(e):
bt2.disabled = not bt2.disabled
bt2.text = "Desabilitado" if bt2.disabled else "Habilitado"
page.update()
bt1 = ft.FilledButton(text="FilledButton", on_click=mudar, width=200)
bt2 = ft.ElevatedButton("Habilitado", disabled=False, width=200)
page.add(bt1, bt2)
ft.app(target=main)
Nesse caso um FilledButton aciona a função mudar que alterna a propriedade disabled do botão elevado. Observe que um botão com disabled=True não reage ao clique, nem à nenhum outro evento. O operador ternário foi usado: valor_se_true if condicao else valor_se_false.
Dois novos eventos são mostrados a seguir: on_hover, que é disparado quando o cursor se move sobre o botão (sem necessidade de clicar) e on_long_press, disparado com um clique longo. Um ícone é inserido nos botões ElevatedButton, cujas cores são alteradas pelos eventos descritos.
Os botões assumem os estados mostrados na figura 2.
Figura 2: Execução do código acima.
Alguns Ícones pré-definidos do Flet
Uma grande quantidade de ícones está disponível e pode ser pesquisada em Flet.dev: Icons Browser.
Botões possuem a propriedade data que pode armazenar um objeto a ser passado para as funções acionadas por eventos. As propriedades dos widgets funcionam como variáveis globais. No exemplo abaixo temos uma caixa de texto, que exibe a propriedade data. O botão elevado também tem uma propridade data que não é exibida mas serve para armazenar quantas vezes o botão foi clicado. Ele serve de container para um Row contendo 3 ícones (ft.Icon(ft.icons.NOME_DO_ICONE)).
import flet as ft
def main(page: ft.Page):
def bt_clicou(e):
bt.data += 1
txt.value = f"O botão foi clicado {bt.data} {'vezes' if bt.data >1 else 'vêz'}"
page.update()
txt = ft.Text("O botão não foi clicado", size=25, color="navyblue", italic=True)
bt = ft.ElevatedButton("Clica!",
content=ft.Row(
[
ft.Icon(ft.icons.CHAIR, color="red"),
ft.Icon(ft.icons.COTTAGE, color="green"),
ft.Icon(ft.icons.AGRICULTURE, color="blue"),
], alignment=ft.MainAxisAlignment.SPACE_AROUND,),
on_click=bt_clicou, data=0, width=150,
)
page.add(txt, bt)
ft.app(target=main)
Se o nome do ícone não for fornecido como primeiro parâmetro o nome do parâmetro deve ser nomeado: ft.Icon(color="red", name=ft.icons.CHAIR). E execução do código resulta nas janelas exibidas na figura 3.
Figura 3
As caixas de texto podem receber formatações diversas como size (tamanho da fonte), color (cor da fonte) bgcolor (cor do fundo), italic (itálico), weight (peso da fonte). A propriedade selectable informa se o texto exibido pode ser selecionado, e estilos diversos podem ser atribuídos em style. A página recebe a propriedade page.scroll = "adaptive" para que possa apresentar uma barra de scroll.
O resultado é mostrado na figura 4. A janela foi dimensionada para ser menor que o texto existente, mostrando a barra de scroll.
Figura 4
O número máximo de linhas exibidas, max_lines, ou largura e altura do texto, width e height são úteis quando se apresenta texto logo em uma janela.
import flet as ft
def main(page: ft.Page):
page.scroll = "adaptive"
texto1 = (
"René Descartes (La Haye en Touraine, 31 de março de 1596, Estocolmo, 11 de"
"fevereiro de 1650) foi um filósofo, físico e matemático francês. Durante a"
"Idade Moderna, também era conhecido por seu nome latino Renatus Cartesius."
)
texto2 = (
"Descartes, por vezes chamado de o fundador da filosofia moderna e o pai da"
"matemática moderna, é considerado um dos pensadores mais importantes e"
"influentes da História do Pensamento Ocidental. Inspirou contemporâneos e"
"várias gerações de filósofos posteriores; boa parte da filosofia escrita "
"a partir de então foi uma reação às suas obras ou a autores supostamente"
"influenciados por ele. Muitos especialistas afirmam que, a partir de"
"Descartes, inaugurou-se o racionalismo da Idade Moderna."
)
t7 = ft.Text("Limita texto longo a 1 linha, com elipses", style=ft.TextThemeStyle.HEADLINE_SMALL)
t8 = ft.Text(texto1, max_lines=1, overflow="ellipsis")
t9 = ft.Text("Limita texto longo a 2 linhas", style=ft.TextThemeStyle.HEADLINE_SMALL)
t10 = ft.Text(texto2, max_lines=2)
t11 = ft.Text("Limita largura e altura do texto longo", style=ft.TextThemeStyle.HEADLINE_SMALL)
t12 = ft.Text(texto2, width=700, height=100)
page.add(t7, t8, t9, t10, t11, t12)
ft.app(target=main)
Figura 5
Resultando na janela mostrada na figura 5. O parâmetro overflow="ellipsis" mostra uma elipses onde on texto foi quebrado. As definições de texto1 e texto2 correspondem a uma das formas de declarar strings longas no python.
Existem estilos pré-definidos. código abaixo usamos o texto do widget igual ao nome do estilo, para facilitar a visualização: style=ft.TextThemeStyle.NOME_DO_ESTILO. Apenas as definições estão mostradas e o resultado está na figura 6.
Propriedades dos controles pode ser alterados dinamicamente por meio de inputs recebidos do usuário (ou outra origem qualquer). No próximo exemplo o tamanho da fonte é controlado por um flet.Slider.
import flet as ft
def main(page: ft.Page):
def font_size(e):
t.size = int(sl.value)
t.value = f"Texto escrito com fonte Bookerly, size={t.size}"
t.update()
t = ft.Text("Texto escrito com fonte Bookerly, size=10", size=10, font_family="Bookerly")
sl = ft.Slider(min=0, max=100, divisions=10, value=10, label="{value}", width=500, on_change=font_size)
page.add(t, sl)
ft.app(target=main)
Figura 7
O app gerado está na figura 7. Observe que a propriedade do Slider.label="value" exibe acima do cursor (como um tooltip) o valor do controle. O tamanho da fonte é ajustado de acordo com esse valor.
Se a fonte está instalada localmente basta usar font_family="Nome_da_Fonte". Para fontes remotas podemos definir uma ou várias fontes a serem usadas. page.fonts recebe um dicionário com nomes e locais das fontes.
page.fonts = {
"Kanit": "https://raw.githubusercontent.com/google/fonts/master/ofl/kanit/Kanit-Bold.ttf",
"Open Sans": "fonts/OpenSans-Regular.ttf",
}
page.theme = Theme(font_family="Kanit")
page.add(
ft.Text("Esse texto é renderizado com fonte Kanit"),
ft.Text("Esse texto é renderizado com fonte 'Open Sans'", font_family="Open Sans"),
Ícones
O objeto fleet.Icon pode ser inserido em vários conteineres. Ele possui as propriedades (entre outras) color, name, size e tooltip. O tamanho default é size=24 enquanto tooltip é o texto exibido quando o cursor está sobre o ícone.
O código ilustra esse uso:
Figura 8: Resultado do código de exibição de ícones.
O nome do ícone pode ser dado como name=ft.icons.ZOOM_IN ou uma string name="child_care", onde o nome pode ser pesquisado no Icons Browser. Note que ft.icons contém ENUMS predefinidos e name=ft.icons.AIR_SHARP é o mesmo que name="air_sharp".
Ícones personalizados podem ser inseridos como imagens, como em flet.Image(src=f"img/Search.png"), onde o caminho pode ser absoluto ou relativo, em referência ao diretório onde está o aplicativo. Isso significa que a imagem da lupa exibida na figura está armazenada em pasta_do_aplicativo/img/Search.png.
Vimos no primeiro artigo dessa série que um aplicativo Python com Flet consiste em código Python para a realização da lógica do aplicativo, usando o Flet como camada de exibição. Mais tarde nos preocuparemos em fazer uma separação explícita das camadas. Por enquanto basta notar que o Flet cria uma árvore de widgets cujas propriedades são controladas pelo código. Widgets também podem estar associados à ações ligadas a funções. Portanto, para construir aplicativos com Flet, precisamos conhecer esses widgets, suas propriedades e eventos que respondem.
Alguns controles tem a função principal de obter informações do usuário, como botões, menus dropdown ou caixas de texto, para inserção de dados. Outros servem para a exibição de informações calculadas pelo código, mostrando gráficos, figuras ou textos. As caixas de textos podem ser usadas em ambos os casos.
Figura 10: Estrutura de árvore de um aplicativo Flet
A interface do Flet é montada como uma composição de controles, arranjados em uma hierarquia sob forma de árvore que se inicia com uma Page. Dentro dela são dispostos os demais controles, sendo que alguns deles são também conteineres, abrigando outros controles. Todos os controles, portanto, possuem um pai, exceto a Page. Controles como Column, Row e Dropdown podem conter controles filhos, como mostrado na figura 10.
Categorias de Controles
Controles
Categoria
Itens
Layout
diagramação
16 itens
Navigation
navegação
3 itens
Information Displays
exibição de informação
8 itens
Buttons
botões
8 itens
Input and Selections
entrada e seleções
6 itens
Dialogs, Alerts, Panels
dialogo e paineis
4 itens
Charts
gráficos
5 itens
Animations
animações
1 item
Utility
utilidades
13 itens
Propriedades comuns a vários controles
Algumas propriedades são comuns a todos (ou quase todos) os controles. Vamos primeiro listá-las e depois apresentar alguns exemplos de uso. As propriedades marcadas com o sinal ⏫ só são válidas quando estão dentro de uma controle Stack, que será descrito após a tabela.
bottom
⏫
Distância entre a borda inferior do filho e a borda inferior do Stack.
data
Um campo auxiliar de dados arbitrários que podem ser armazenados junto a um controle.
disabled
Desabilitação do controle. Por padrão disabled = False. Um controle desabilitado fica sombreado e não reage a nenhum evento. Todos os filhos de um controle desabilitado ficam desabilitados.
expand
Um controle dentro de uma coluna ou linha pode ser expandido para preencher o espaço disponível. expand=valor, onde valor pode ser booleano ou inteiro, um fator de expansão, usado para dividir o espaço entre vários controles.
hight
Altura do controle, em pixeis.
left
⏫
Distância da borda esquerda do filho à borda esquerda do Stack.
right
⏫
Distância da borda direita do filho à borda direita do Stack.
top
⏫
Distância da borda superior do filho ao topo do Stack.
visible
Visibilidade do controle e seus filhos. visible = True por padrão. Controles invisíveis não recebem foco, não podem ser selecionados nem respondem a eventos.
widht
Largura de controle em pixeis.
Um Stack é um controle usado para posicionar controles em cima de outros (empilhados). Veremos mais sobre ele na seção sobre layouts.
Transformações (Transformations)
Transformações são operações realizadas sobre os controles
offset
É uma translação aplicada sobre um controle, antes que ele seja renderizado. A translação é dada em uma escala relativa ao tamanho do controle. Um deslocamento de 0,25 realizará uma translação horizontal de 1/4 da largura do controle. Ex,: ft.Container(..., offset=ft.transform.Offset(-1, -1).
opacity
Torna o controle parcialmente transparente. O default é opacity=1.0, nenhuma transparência. Se opacity=0.0controle é 100% transparente.
rotate
Aplica uma rotação no controle em torno de seu centro. O parâmetro rotate pode receber um número, que é interpretado com o ângulo, em radianos, de rotação anti-horária. A rotação também pode ser especificada por meio de transform.Rotate, que permite estabelecer ângulo, alinhamento e posição de centro de rotação. Ex,: ft.Image(..., rotate=Rotate(angle=0.25 * pi, alignment=ft.alignment.center_left) representa uma rotação de 45° (π/4).
scale
Controla a escala ao longo do plano 2D. O fator de escala padrão é 1,0. Por ex.: ft.Image(..., scale=Scale(scale_x=2, scale_y=0.5) multiplica as dimensões em x por 2 e em y por .5. Alternativamente Scale(scale=3) multiplica por 3 nas duas direções.
bt6 ⇾ torna a cor mais translúcida (ct.opacity -= .1),
bt7 ⇾ retorna a imagem para o estado inicial,
Figura 12: Propriedades e Transformações
onde ct = ft.Container, é o container de cor vermelha, mostrado no figura 12.
Atalhos de Teclado
Qualquer pessoa que faz uso intensivo do computador sabe da importância dos Atalhos de Teclado (Keyboard shortcuts). A possibilidade de não mover a mão do teclado para acionar o mouse pode significar melhor usabilidade e aumento de produtividade. Para isso o Flet oferece para o programador a possibilidade de inserir atalhos em seus aplicativos para que seu usuário possa dinamizar seu uso.
Para capturar eventos produzidos pelo teclado o objeto page implementa o método on_keyboard_event, que gerencia o pressionamento de teclas de caracter, em combinação com teclas de controle. Esse evento passa o parâmetro eque é uma instância da classe KeyboardEvent, e tem as seguintes propriedades:
e.key
Representação textual da tecla pressionada. Veja nota†.
e.shift
Booleano: True se a tecla “Shift” foi pressionada.
e.ctrl
Booleano: True se a tecla “Control” foi pressionada.
e.alt
Booleano: True se a tecla “Alt” foi pressionada.
e.meta
Booleano: True se a tecla “Meta” foi pressionada††.
Nota†: Além dos caracteres A … Z (todos apresentados em maiúsculas) também são representadas as teclas Enter, Backspace, F1 … F12, Escape, Insert … Page Down, Pause, etc. Alguns teclados permitem a reconfiguração de teclas, por exemplo fazendo F1 = Help, etc. Nota††: A tecla Meta é representada em geral no Windows como tecla Windows e no Mac como tecla Command.
O seguinte código ilustra esse uso. A linha page.on_keyboard_event = on_teclado faz com que eventos de teclado acionem a função on_teclado. O objeto e leva as propriedades booleanas e.ctrl, e.alt, e.shift, e.meta e o texto e.key.
O resultado desse código, quando executado e após o pressionamento simultaneo das teclas CTRL-ALT-SHIFT-J, está mostrado na figura 13.
O exemplo acima ilustra ainda uma característica da POO (programação orientada a objetos). Como temos que criar 5 caixas de texto iguais, exceto pelo seu valor, criamos uma classe BtControle (herdando de ft.TextField) e criamos cada botão como instância dessa classe. No código manipulamos a visibilidade desses botões.
Baseado no Flutter (veja seção abaixo) foi desenvolvida a biblioteca Flet, um framework que permite a construção de aplicações web, desktop e mobile multiusuário interativas usando o Python. O Flet empacota os widgets do Flutter e adiciona algumas combinações próprias de widgets menores, ocultando complexidades e estimulando o uso de boas práticas de construção da interface do usuário. Ele pode ser usado para construir aplicativos que rodam do lado do servidor, eliminando a necessidade de uso de HTML, CSS e Javascrip, e também aplicativos para celulares e desktop. Seu uso exige o conhecimento prévio de Python e um pouco de POO (programação orientada a objetos).
Atualmente (atualizado em abril de 2025) o Flet está na versão v0.27.6 e em rápido processo de desenvolvimento.
Flutter e Widgets
Flutter é um framework para o desenvolvimento (um SDK) de interface do usuário de software de código aberto criado pelo Google, e lançado em maio de 2017. Em outras palavras ele serve para a construção de GUIs (Interfaces Gráficas de Usuários), e é usado para desenvolver aplicativos em diversas plataformas usando um único código base.
A primeira versão do Flutter (Flutter Sky) rodava no sistema operacional Android e, segundo seus desenvolvedores, podia renderizar 120 quadros por segundo. O Flutter 1.0, a primeira versão estável do framework, foi lançado em 2018. Em 2020 surgiu o kit de desenvolvimento de software Dart (SDK) versão 2.8 com o Flutter 1.17.0, em que foi adicionado suporte para API que melhora o desempenho em dispositivos iOS, juntamente com novos widgets de materiais e ferramentas rastreamento em rede.
O Flutter 2 foi lançado pelo Google em 2021, incluindo um novo renderizador Canvas Kit para aplicativos baseados na web e aperfeiçoamento no suporte de aplicativos web e desktop para Windows, macOS e Linux. Em setembro de 2021, o Dart 2.14 e o Flutter 2.5 foram lançados, com melhorias para o modo de tela cheia do Android e a versão mais recente do Material Design do Google. Em 2022 o Flutter foi lançado expandindo o suporte a plataformas, com versões estáveis para Linux e macOS em arquiteturas diversas. O Flutter 3.3 trouxe interoperabilidade com Objective-C e Swift e uma versão preliminar de um novo mecanismo de renderização chamado “Impeller”. Em janeiro de 2023 foi anunciado o Flutter 3.7.
Aplicativos elaborados com Flutter são baseados em Widgets. Widgets são pequenos blocos de aplicativo com representação gráfica, que podem ser inseridos dentro de ambientes gráficos mais gerais , usados em aplicativos web ou desktop. Eles aparecem na forma de botões, caixas de texto, relógios e calendários selecionáveis, menus drop-down, etc, e servem basicamente para a interação com o usuário, ou recebendo inputs, como um clique em um botão, ou exibindo resultados, como um texto de resposta ou um gráfico.
Instalando o Flet
Podemos descobrir se o Flet está instalado iniciando uma sessão interativa do Python e tentando sua importação. Se não estiver instalado uma mensagem de erro será emitida:
$ python
Python 3.12.0 (... etc.)
>>> import flet
ModuleNotFoundError: No module named 'flet'
Flet exige Python 3.7 ou superior. Para instalar o módulo podemos usar o pip. Como ocorre em outros casos, é recomendado (mas não obrigatório) instalar a nova biblioteca dentro de um ambiente virtual.
# criamos um ambiente virtual com o comando
$ python3 -m venv ~/Projetos/.venv
# para ativar o ambiente virtual
$ cd ~/Projetos/.venv
$ source bin/activate
# agora podemos instalar o flet
$ pip install flet
# para upgrade do flet, se já instalado
$ pip install flet --upgrade
# para verificar a versão do flet instalado (em abril de 2025)
$ flet --version
↳ 0.27.6
Uma mensagem sugerindo o upgrade do próprio pip aparece se, se existir algum. O pip pode ser atualizado com: $ pip install --upgrade pip
Mesmo após a instalação do flet um erro pode aparecer. Para executar código do python com flet no Linux são necessárias as bibliotecas do GStreamer. A maioria das distribuições do Linux as instalam por default.
Caso isso não aconteça e a mensagem de erro abaixo for emitida, instale o GStreamer.
# mensagem de erro ao executar python com flet
error while loading shared libraries: libgstapp-1.0.so.0: cannot open shared object file: No such file or directory
# Instalando GStreamer no fedora
$ sudo dnf update
$ dnf install gstreamer1-devel gstreamer1-plugins-base-tools gstreamer1-doc gstreamer1-plugins-base-devel gstreamer1-plugins-good gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-bad-free-devel gstreamer1-plugins-bad-free-extras
# Instalando GStreamer no ubuntu
$ sudo apt-get update
$ sudo dnf install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav gstreamer1.0-doc gstreamer1.0-tools gstreamer1.0-x gstreamer1.0-alsa gstreamer1.0-gl gstreamer1.0-gtk3 gstreamer1.0-qt5 gstreamer1.0-pulseaudio
Um segundo erro pode ocorrer quando se tenta rodar um aplicativo do flet. Para resolver essa questão podemos instalar os pacotes mpv-libs e mpv-devel:
# ao executar um arquivo flet obtemos uma mensagem de erro
$ python flet3.py
/home/guilherme/.flet/bin/flet-0.23.2/flet/flet: error while loading shared libraries:
libmpv.so.1: cannot open shared object file: No such file or directory
# para resolver instalamos os pacotes (no fedora)
$sudo dnf install mpv-libs
$sudo dnf install mpv-devel
# podemos verificar a existência dos pacotes na pasta apropriada
$ cd /usr/lib64
$ find *mpv*
# devemos ver a resposta
libmpv.so
libmpv.so.2
libmpv.so.2.1.0
# criamos um link simbólico para a pasta /usr/lib64/
$ sudo ln -s /usr/lib64/libmpv.so /usr/lib64/libmpv.so.1
O último passo, com a criação do link simbólico (também chamado de symlink), cria o arquivo libmpv.so.1 no diretório /usr/lib64/ que, ao ser chamado, carrega libmpv.so.
Feito isso podemos escrever nosso primeiro código flet, apenas com o esqueleto de um aplicativo. Ao ser executado ele apenas abre uma janela sem conteúdo. Abra um editor de texto, ou sua IDE preferida, e grave o seguinte arquivo, com nome flet1.py:
import flet as ft
def main(page: ft.Page):
# controles da Página
pass
ft.app(target=main)
Esse código pode ser executado com:
$ python flet1.py
# ou
$ flet flet1.py
Ao executar python flet1.py veremos apenas uma janela vazia, que pode ser fechada com os controles usuais de janela (ou CTRL-F4). O programa termina com flet.app(target=main), recebendo no parâmetro target a função que apenas recebe o objeto fleet.Page, main (podia ter outro nome qualquer). O objeto Page é como um Canvas onde, mais tarde, inseriremos outros widgets.
Da forma como escrevemos esse código, uma janela nativa do sistema operacional será aberta no desktop. Para abrir o mesmo aplicativo no browser padrão trocamos a última linha por:
ft.app(target=main, view=ft.AppView.WEB_BROWSER)
Nota: Aplicativos do Flet, rodando no desktop ou dentro do navegador, são aplicativos web. Ele se utiliza de um servidor chamado “Fletd” que, por default usa uma porta TCP aleatória. Uma porta específica pode ser designada atribuindo-se um valor para a parâmetro port:
flet.app(port=8550, target=main)
Em seguida abra o navegador com o endereço http://localhost:8550 para ver o aplicativo em ação.


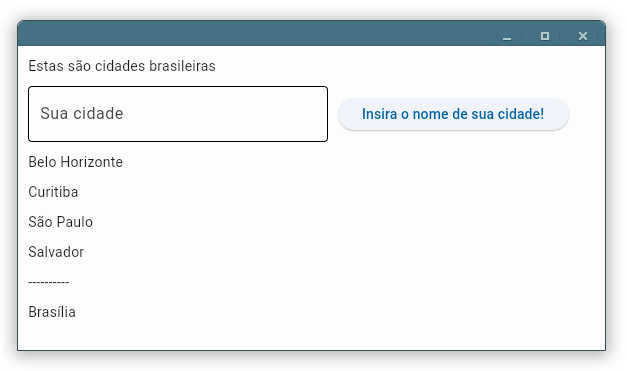
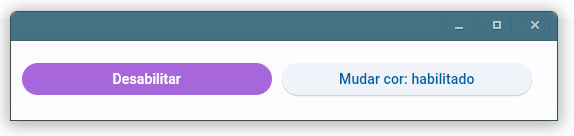
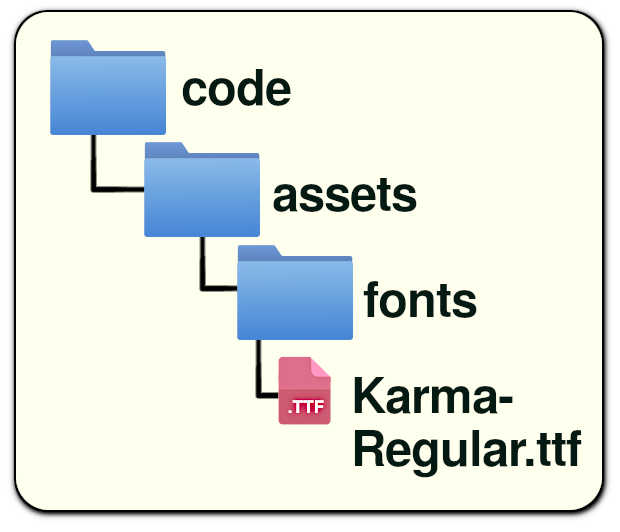
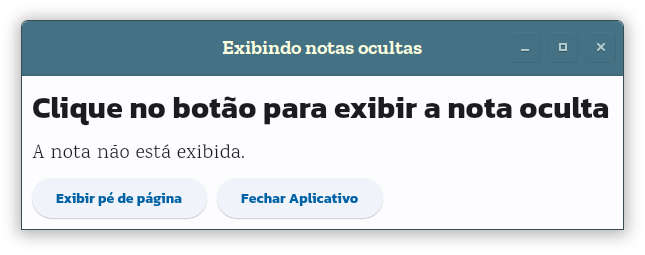
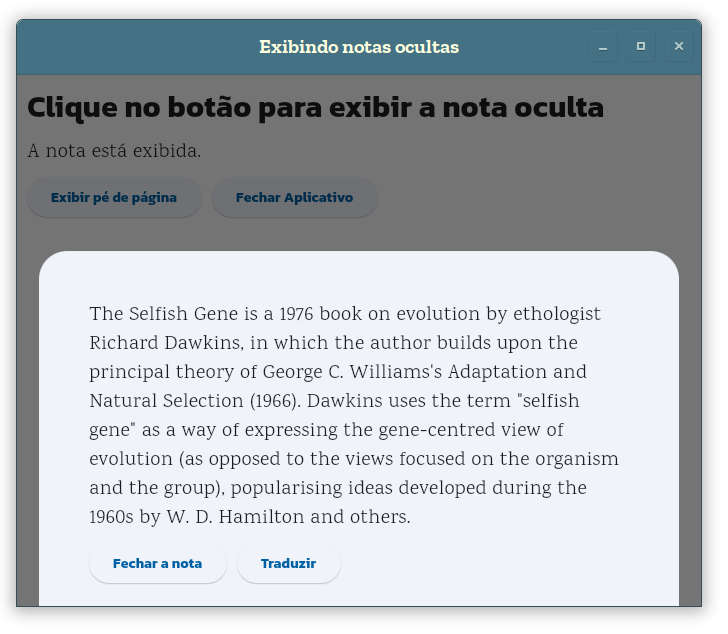



















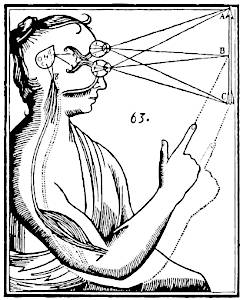

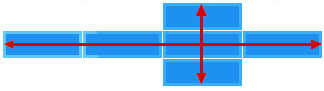








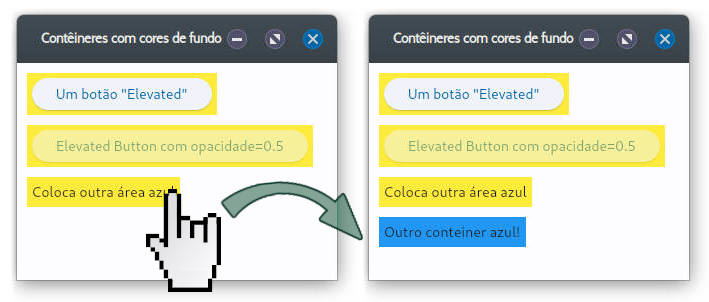
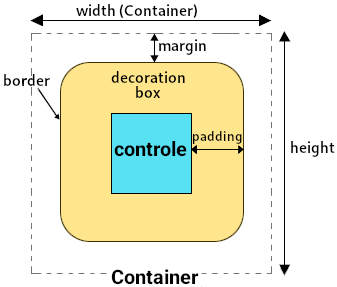






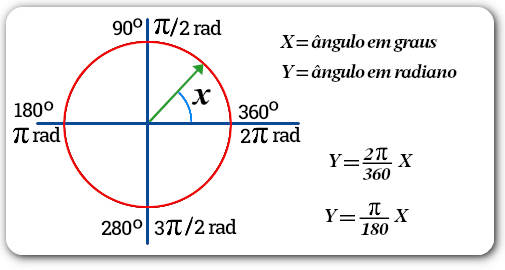





 Exemplos: page.fonts
Exemplos: page.fonts