

ORM Manipulação de Objetos
Vimos na seção sobre a definição de tabelas com o ORM como definir classes do Python que podem ser correlacionadas com entidades do SQL por meio do SQLAlchemy. Já fizemos uso, sem explorar muito o assunto, do método relationship() que insere no esquema de uma sessão os relacionamentos entre propriedades dos objetos que serão espelhadas nas tabelas envolvidas.
Recordando, criamos uma classe vazia herdando de DeclarativeBase que será a superclasse para os modelos de tabelas. No nosso exemplo criamos os objetos aluno e endereco
class Base(DeclarativeBase):
pass
class Aluno(Base):
__tablename__ = "aluno"
...
enderecos: Mapped[List["Endereco"]] = relationship(back_populates="aluno")
class Endereco(Base):
__tablename__ = "endereco"
...
aluno: Mapped[Aluno] = relationship(back_populates="enderecos")
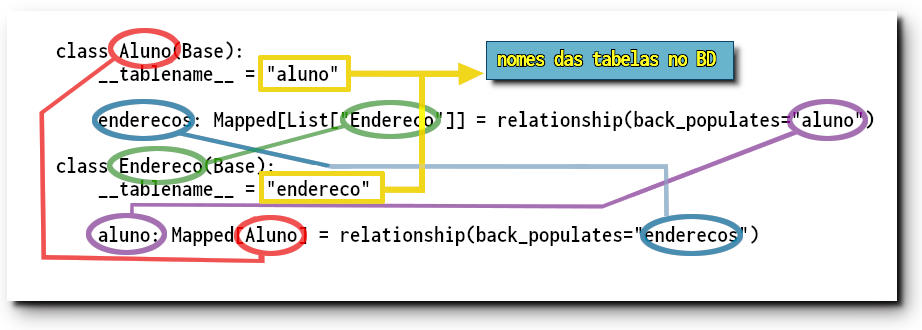
Vemos que a classe Aluno tem o atributo Aluno.enderecos e a classe Endereco tem o atributo Endereco.aluno, que estão em relacionamento. Vimos também que Mapped informa o tipo do campo. Objetos da classe Endereco se referem a uma tabela com a campo aluno que é uma chave estrangeira (ForeignKeyConstraint) ligada ao campo aluno.enderecos. O método relationship() pode determinar sem ambiguidade que existe um relacionamento de um para muitos: um aluno.enderecos (uma linha de aluno) pode estar ligada a várias linhas na tabela de endereco.
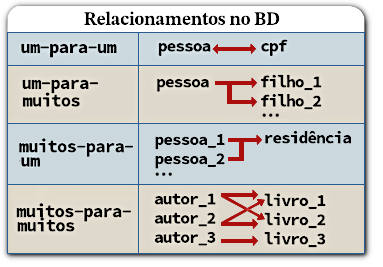
Relacionamentos um-para-muitos correspondem, é claro, a um relacionamento muitos-para-um na direção oposta. Portanto o parâmetro relacionship.back_populates, em ambas as classes, define que esses campos estão em relação complementar entre si.
Persistência de relacionamentos: Definidos os relacionamentos eles devem ser gravados na tabela e, quando as tabelas já estão definidas, carregados de volta para as classes do ORM. Suponha que inicializamos um objeto aluno com as seguintes propriedades:
aluno1 = Aluno(matricula="976567-123", nome="Mauro", sobrenome="Olivares") aluno1.enderecos ↳ [] # uma lista vazia
O campo retornado, inicialmente vazio, é uma versão de uma lista no SQLAlchemy (uma Mapped[List]) que pode rastrear e responder às alterações efetuadas sobre o objeto. Ela é inserido automaticamente quando tentamos acessar o atributo, mesmo que não o tenhamos definido na criação do objeto. Isso é semelhante à inserção de ids que não são informados na incialização. Esse comportamento é diferente daqueles das classes usuais do Python que geram uma exeção AttributeError se a propriedade não for definida na inicialização. O objeto aluno1 é transitório e a lista em aluno1.enderecos não sofreu nenhuma alteração.
Para inserir um elemento nessa coleção criamos um endereço e usamos o método list.append(objeto_endereco).
end1 = Endereco(email="olivares@gmail.com") aluno1.enderecos.append(end1) # um endereço é anexado ao objeto aluno1 aluno1.enderecos ↳ [Endereco(id=None, email='olivares@gmail.com')] # o objeto end1 é sincronizado (veja descrição abaixo) end1.aluno ↳ Aluno(id=None, nome='Mauro', sobrenome='Olivares')
A operação de inserir um Endereco ao objeto Aluno, além de atualizar o próprio campo aluno1.enderecos também realiza a sincronização automática de Endereco.aluno, inserindo uma referência ao aluno dono desse endereço de email. Essa sincronização é o resultado do parâmetro relationship.back_populates entre os objetos relacionados.
Essa sincronização funciona também na outra direção: se criamos outro objeto Endereco com atributo Endereco.aluno referenciando o aluno1 esse novo endereço fará parte da coleção Aluno.enderecos, para o aluno em questão.
# criamos novo endereco, já associado ao aluno1 end2 = Endereco(email="olivar@aol.com", aluno=aluno1) # o novo endereco se torna parte da coleção aluno1.enderecos ↳ [Endereco(id=None, email='olivares@gmail.com'), Endereco(id=None, email='olivar@aol.com')]
Esses novos elementos precisam ser inseridos na sessão, o que pode ser feito com o método session.add(). Com a inserção de aluno1 os dois endereços ficam também inseridos.
session.add(aluno1) # com esse procedimento temos aluno1 in session ↳ True end1 in session ↳ True end2 in session ↳ True
Essas são as chamadas operações de save e update em cascata. Agora os 3 objetos envolvidos estão em estado pendente: nenhum deles tem um id designado, por enquanto. Além disso os objetos end1 e end2 possuem o atributo aluno_id que é a referência à coluna com um ForeignKeyConstraint ligada à aluno.id. Esse atributo também não foi ainda atribuído a uma linha real do banco de dados, portanto aluno.id = None.
print(aluno1.id) ↳ None print(end1.aluno_id) ↳ None

Quando comitamos as transações os passos ocorrem na ordem correta, gerenciados pelo SQLAlchemy, para gerar as ids e propagar essa informação para os campos relacionados.
session.commit()
[SQL]
INSERT INTO aluno (nome, sobrenome) VALUES (?, ?) ('Mauro', 'Olivares')
INSERT INTO endereco (email, aluno_id) VALUES (?, ?), (?, ?) RETURNING id
('olivares@gmail.com', 6, 'olivar@aol.com', 6)
COMMIT
No último insert estamos supondo que o id de aluno recém inserido seja 6.
Carregando Relacionamentos: Após a emissão de Session.commit() é emitida automaticamemnte um Session.commit.expire_on_commit que faz com que todos os objetos da sessão fiquem expirados. No próximo acesso de um atributo desses objetos um SELECT é emitido para a linha, permitindo a visualização da chave primária recém-gerada.
aluno1.id ↳ 6 [SQL] SELECT aluno.id AS aluno_id, aluno.nome AS aluno_nome, aluno.sobrenome AS aluno_sobrenome FROM aluno WHERE aluno.id = ? (6,)
Podemos também acessar a coleção persistente aluno.enderecos de aluno1, que consiste em um conjunto adicional de linhas da tabela de endereços. Quando acessamos essa coleção ocorre uma lazy load † (uma carga lenta) emitida para recuperar os objetos:
aluno1.enderecos ↳ [Endereco(id=4, email='olivares@gmail.com'), Endereco(id=5, email='olivar@aol.com')] [SQL] SELECT endereco.id AS endereco_id, endereco.email AS endereco_email, endereco.aluno_id AS endereco_aluno_id FROM endereco WHERE endereco.aluno_id = ? (6,)

As coleções e atributos relacionados no SQLAlchemy ORM são persistentes na memória. Depois que o valor é atribuído não há mais necessidade de emitir consultas SQL até que a coleção ou atributo expire. Podemos acessar, adicionar ou remover itens em aluno1.enderecos sem que novas consultas SQL sejam executadas.
Esse carregamento lento pode se tornar pesado na memória se não forem tomadas medidas para otimizá-lo. Existe otimização para evitar trabalho redundante: a coleção aluno1.enderecos foi atualizada no mapa de identidade onde todas as referências apontam para as mesmas instâncias Endereco já criadas. Portanto, todos esses objetos já estão carregados.
Consultas com Relacionamentos: O SQLAlchemy admite diversos recursos para a construção consultas SQL que envolvem classes mapeadas coom relacionamentos. Os métodos Select.join() e Select.join_from() são usados para compor cláusulas JOIN nas consultas. Esses métodos inferem a cláusula ON com base na presença de um único e inequívoco objeto ForeignKeyConstraint quando constroem consultas com junções (JOIN), vinculando as tabelas à partir da estrutura dos metadados da sessão. Se desejado, também é possível fornecer explicitamente uma expressão SQL especificando a cláusula ON.
Outro mecanismo também está disponível para estabelecer junções quando usamos entidades ORM, usando os objetos gerados por relationship(), que foram configurados no mapeamento das classes. O atributo da classe que está em relacionamento, definido em relationship(), pode ser passado como argumento para Select.join(), para indicar tanto o lado direito da junção quanto o campo na cláusula ON.
# consulta (1) print(select(Endereco.email).select_from(Aluno).join(Aluno.enderecos)) # consulta (2) print(select(Endereco.email).join_from(Aluno, Endereco)) # ambas as consultas geram: [SQL] SELECT endereco.email FROM aluno JOIN endereco ON aluno.id = endereco.aluno_id
Consultas com Select.join() ou Select.join_from() não usam o relacionamento estabelecido no mapeamento para inferir a cláusula ON, exceto se isso for explicitamente especificado. Isso significa que, quando fazemos união de Aluno para Endereco sem incluir uma cláusula ON, uma consulta correta é emitida por causa da ForeignKeyConstraint entre os objetos mapeados e não devido à existência de um relationship().

Vale lembrar que Aluno, Endereco (com maiúsculas) se referem às classes do ORM enquanto aluno, endereco são os nomes das tabelas no BD.Consulte o manual do SQLAlchemy: ORM Query Guide, Select Join, Select Join On Clause.
Relacionamentos e WHERE
Existem algumas formas de gerar consultas e filtros com relationship(), tipicamente aplicados com WHERE (no SQL) e Select.where() (no SQLAlchemy).
EXISTS: has() e any(): Vimos na seção Agrupamentos e Subqueries: EXISTS como funciona EXISTS e sua contraparte no SQLAlchemy. O método exists() é usado para gerar a cláusula EXISTS do SQL que é aplicada sobre um conjunto de resultados obtidos com uma subconsulta escalar. A classe construída por relationship() tem métodos auxiliares responsáveis pela geração de algumas formas comuns de uso de EXISTS em consultas sobre colunas ligadas por relacionamentos.
Em um relacionamento um-para-muitos, como é o caso de Aluno.enderecos que se liga a uma coleção de Endereco.aluno, podemos gerar um EXISTS usando PropComparator.any(). Este método aceita um critério WHERE opcional para filtrar as linhas retornadas pela subconsulta.
query = select(Aluno.sobrenome)
.where(Aluno.enderecos.any(Enderecos.email == "olivares@gmail.com"))
session.execute(query).all()
# é retornado
↳ ['Olivares',)]
[SQL]
SELECT aluno.sobrenome FROM aluno
WHERE EXISTS (SELECT 1 FROM endereco WHERE aluno.id =
endereco.aluno_id AND aluno.email = ?) ('olivares@gmail.com',)
A subconsulta retorna 1 para cada linha que satisfaz
aluno.id = endereco.aluno_id AND aluno.email = 'olivares@gmail.com' .
Se existir algum valor EXISTS retorna TRUE e o sobrenome é retornado pela consulta externa.
O uso de EXISTS é, em geral, mais eficiente para pesquisas negativas, quando se faz uma busca por elementos que não estão presentes nas linhas. Para isso basta negar um resultado, como ~Aluno.endereco.any(), para selecionar Alunos que não possuem linhas associadadas na tabela endereco.
query = select(Aluno.nome).where(~Aluno.enderecos.any())
session.execute(query).all()
[SQL]
SELECT aluno.nome FROM aluno WHERE NOT (EXISTS
(SELECT 1 FROM aluno WHERE aluno.id = endereco.aluno_id)
)
A consulta retorna os nomes dos alunos sem um endereço cadastrado.
O método PropComparator.has() age quase da mesma forma que PropComparator.any(), com a diferença de ser usado em relacionamentos muitos-para-um. Esse seria o caso se quisermos encontrar todos os endereços associados com um aluno determinado.
query = select(Endereco.email).where(Endereco.aluno.has(Aluno.nome == "Mauro"))
session.execute(query).all()
[SQL]
SELECT endereco.email FROM endereco WHERE EXISTS
(SELECT 1 FROM aluno WHERE aluno.id = endereco.aluno_id AND aluno.nome = ?) ('Mauro',)
↳ [('olivares@gmail.com',), ('olivar@aol.com',)]
As consultas 1-4 abaixo exibem outras propriedades: (1) Uma instância de um objeto pode ser comparada a um relacionamento muitos-para-um para selecionar linhas onde a chave estrangeira no destino corresponde à chave primária do objeto dado. (2) O operador not equals (!=) também pode ser usado. (3) Aluno.enderecos.contains(obj_endereco) testa se o objeto carregado é um dos endereços na coleção. (4) with_parent(obj_aluno, Aluno.enderecos) testa se obj_aluno tem Aluno.enderecos como classe pai.
# (1) obj_endereco = session.get(Endereco, 1) obj_aluno = session.get(aluno, 1) print(select(Endereco).where(Endereco.aluno == obj_aluno)) [SQL] SELECT endereco.id, endereco.aluno_id, endereco.email FROM endereco WHERE :param_1 = endereco.aluno_id # (2) print(select(Endereco).where(Endereco.aluno != obj_aluno)) [SQL] SELECT endereco.id, endereco.aluno_id, endereco.email FROM endereco WHERE endereco.aluno_id != :aluno_id_1 OR endereco.aluno_id IS NULL # (3) print(select(Aluno).where(Aluno.enderecos.contains(obj_endereco))) [SQL] SELECT aluno.id, aluno.matricula, aluno.nome, aluno.sobrenome FROM aluno WHERE aluno.id = :param_1 # (4) from sqlalchemy.orm import with_parent print(select(Endereco).where(with_parent(obj_aluno, Aluno.enderecos))) [SQL] SELECT endereco.id, endereco.aluno_id, endereco.email FROM endereco WHERE :param_1 = endereco.aluno_id
Lembramos aqui que Endereco.aluno está em relacionamento (muitos-para-1) com Aluno.enderecos.

Estratégias de de carregamento
Vimos que, quando acessamos atributos de objetos mapeados que usam relacionamentos, um carregamento lento (ou lazy load) será realizado quando a coleção ainda não estiver preenchida. O carregamento lento é um padrão importante no ORM, embora controverso. Quando temos muitos objetos ORM na memória que fazem referência a muitos atributos não carregados, a manipulação desses objetos pode gerar novas consultas em cascata, causando acúmulo (no que consiste no problema denominado “N mais um”). Para piorar o estado de coisas essas novas consultas são emitidas implicitamente. Elas podem causar erros quando são produzidas após o fechamento das transações com o BD, ou quando se usa gerenciadores de conexões assíncronas, como asyncio.
Apesar disso o carregamento lento é útil, principalmente quando bem ajustado com mecanismos de sincronização. Por isso o SQLAlchemy ORM inclui muitos recursos para controlar e otimizar o comportamento de carregamentos. A etapa principal no uso de carregamento lento consiste em testar o aplicativo ativando a exibição de saídas de consultas para análise do SQL emitido. A presença de muitas instruções SELECT redundantes, que poderiam ser agrupadas com mais eficiência, ou a ocorrência de carregamentos inadequados para objetos que já estão destacados (detached ) da sessão, são indicadores de que se deve usar estratégias de carregamento.
Essas estratégias são representadas por objetos que podem ser associados a uma instrução SELECT através do método Select.options(). A estratégia abaixo permite o acesso aos objetos já carregados de Aluno.enderecos.
enderecos_carregados = session.execute(select(Aluno)
.options(selectinload(Aluno.enderecos))).scalars()
for obj_aluno in enderecos_carregados:
obj_aluno.enderecos
Também é possível tornar o carregamento lento a forma default em relationship(), usando a opção relationship.lazy.
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import relationship
class Aluno(Base):
__tablename__ = "aluno"
...
enderecos: Mapped[List["Endereco"]] = relationship(back_populates="aluno", lazy="selectin")
Carregamento Selectin: Uma opção de carregamento muito útil é a selectinload() que resolve o problema frequente “N mais um”, citado acima. A opção selectinload() faz com que uma coleção completa de objetos relacionados seja carregada antecipadamente em uma única consulta. Isso é obtido com consultas SELECT aplicadas apenas sobre uma tabela, sem inserir JOINs ou subconsultas, seguida de consultas para os objetos relacionados que ainda não foram carregados.
No exemplo abaixo selectinload() é usado para carregar todos os objetos Alunos e os objetos Enderecos associados. Quando invocamos Session.execute() uma vez, passando um select(), o BD dados é acessado com duas instruções SELECT, sendo a segunda usada para carregar objetos Enderecos associados.
from sqlalchemy.orm import selectinload
query = select(Aluno).options(selectinload(Aluno.enderecos)).order_by(Aluno.id)
for row in session.execute(query):
print(f"Aluno: {row.Aluno.nome} {row.Aluno.sobrenome}")
for a in row.Aluno.enderecos:
print(f"{a.email}")
[SQL]
SELECT aluno.id, aluno.nome, aluno.sobrenome
FROM aluno ORDER BY aluno.id
SELECT endereco.aluno_id AS endereco_aluno_id, endereco.id AS endereco_id,
endereco.email AS endereco_email FROM endereco
WHERE endereco.aluno_id IN (?, ?, ?, ?, ?, ?) (1, 2, 3, 4, 5, 6)
A consulta retorna nome e sobrenome dos 6 primeiros alunos e seus respectivos emails.
Carregamento com JOIN: joinedload() é usado como estratégia de carregamento imediato (eager load ) que inclui a possibilidade de JOINs em uma instrução SELECT. Esse JOIN pode ser uma junção externa ou interna. Essa é a estratégia adequada para carregar objetos em relacionamentos muitos-para-um pois isso exige apenas o carregamento de colunas adicionais a uma linha da entidade primária. Ele também aceita a opção joinload.innerjoin para que a junção seja considerada interna (e não externa). No exemplo abaixo sabemos que todos os objetos Enderecos estão associados a algum Aluno.
from sqlalchemy.orm import joinedload
query = (
select(Endereco)
.options(joinedload(Endereco.aluno, innerjoin=True))
.order_by(Endereco.id)
)
for row in session.execute(query):
print(f"Aluno: {row.Endereco.aluno.nome}: email: {row.Endereco.email} ")
SELECT endereco.id, endereco.email, endereco.aluno_id,
aluno_1.id AS id_1, aluno_1.nome, aluno_1.sobrenome
FROM endereco JOIN aluno AS aluno_1 ON aluno_1.id = endereco.aluno_id
ORDER BY endereco.id
A consulta retorna os nomes e emails de alunos, ordenados pelo id do endereço. Lembrando que Endereco está em relação com aluno vemos que Endereco.aluno.nome fica carregado com o nome desse aluno.
joinload() também funciona para coleções, em relacionamentos um-para-muitos. Esse uso, no entanto, pode multiplicar as linhas linhas retornadas de maneira recursiva, o que exige cuidado nessa opção, e consideração do uso de selectinload().
Importante: os critérios WHERE e ORDER BY, usados para modificar a instrução Select, não agem sobre a tabela afetada por joinload(). Como mostra a consulta SQL acima um aliás é atribuído à tabela aluno para que ela não seja alvo desses filtros.
Vemos assim que joinload() recebe como argumento o campo que deve ser carregado de forma imediata. Nos exemplos abaixo os objetos ORM (com letra maiúscula) refletem tabelas Cliente, com campo (uma coleção) Cliente.pedidos; Pedidos com coleção Pedidos.itens, cada item com a descrição Item.descricao.
# joined-load um campo "pedidos" no objeto ORM Cliente
query(Cliente).options(joinedload(Cliente.pedidos))
# joined-load Pedidos.itens, depois Item.descricao (se Pedidos.itens é uma coleção de objetos Item)
query(Pedidos).options(
joinedload(Pedidos.itens).joinedload(Item.descricao))
# a mesma consulta, com lazy load
query(Pedidos).options(
lazyload(Pedidos.items).joinedload(Item.descricao))

Junções explícitas com carregamentos rápidos, contains_eager: Suponha que queremos carregar as linhas de endereço associadas à tabela aluno usando um método como Select.join() para aplicar um JOIN. Esse JOIN para ser aproveitado para uma carga rápida do conteúdo de Endereco.aluno em cada campo endereco retornado. Podemos realizar um carregamento rápido como JOIN, executando esse JOIN manualmente. Isso pode ser obtido com contains_eager(), uma opção semelhante a joinload() que libera o desenvolvedor para configurar o JOIN. Colunas adicionais na cláusula COLUMNS devem ser carregadas em atributos relacionados em cada objeto retornado. Por exemplo:
from sqlalchemy.orm import contains_eager
query = (
select(Endereco)
.join(Endereco.aluno)
.where(Aluno.nome == "Marcos")
.options(contains_eager(Endereco.aluno))
.order_by(Endereco.id)
)
for row in session.execute(query):
print(f"{row.Endereco.aluno.nome}, email: {row.Endereco.email} ")
[SQL]
SELECT aluno.id, aluno.nome, aluno.sobrenome, endereco.id AS id_1, endereco.email, endereco.aluno_id
FROM endereco JOIN aluno ON aluno.id = endereco.aluno_id
WHERE aluno.nome = ? ORDER BY endereco.id ('Marcos',)
Filtramos, na consulta acima, as linhas por aluno.nome e carregamos linhas de aluno no atributo Endereco.aluno. Se tivéssemos aplicado joinedload() seriam geradas partes desnecessárias na consulta SQL, como exibido abaixo.
query = (
select(Endereco)
.join(Endereco.aluno)
.where(Aluno.nome == "Marcos")
.options(joinedload(Endereco.aluno))
.order_by(Endereco.id)
)
print(query)
[SQL]
SELECT endereco.id, endereco.email, endereco.aluno_id,
aluno_1.id AS id_1, aluno_1.nome, aluno_1.sobrenome
FROM endereco JOIN aluno ON aluno.id = endereco.aluno_id
LEFT OUTER JOIN aluno AS aluno_1 ON aluno_1.id = endereco.aluno_id
WHERE aluno.nome = :nome_1 ORDER BY endereco.id
Esse exemplo produz a geração desnecessária de clásulas JOIN e LEFT OUTER JOIN junto com SELECT.
Raiseload é outra estratégia de carregamento. Ela é usada para impedir o surgimento do problema N-mais-um, transformando cargas lazy em um lançamento de erro. Usamos a opção raiseload.sql_only para bloquear cargas lentas feitas por consultas SQL ou bloquear todos os carregamentos, incluindo aqueles que apenas precisam consultar a sessão atual. Uma das formas consiste em usar raiseload() para configurar o relacionamento estabelecido em relationship(), ajustando o valor relationship.lazy = "raise_on_sql". Com isso nenhum acesso aos dados tentará emitir uma consulta SQL. Isso pode ser feito na definição dos objetos ORM que refletem as tabelas.
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import relationship
class Aluno(Base):
__tablename__ = "aluno"
id: Mapped[int] = mapped_column(primary_key=True)
enderecos: Mapped[List["Endereco"]] = relationship(back_populates="aluno", lazy="raise_on_sql")
class Endereco(Base):
__tablename__ = "endereco"
id: Mapped[int] = mapped_column(primary_key=True)
aluno_id: Mapped[int] = mapped_column(ForeignKey("aluno.id"))
aluno: Mapped["Aluno"] = relationship(back_populates="enderecos", lazy="raise_on_sql")
Esse tipo de definição no relacionamento impede a realização de “lazy loads” e obriga a definição de uma estratégia de carregamento para consultas nesses campos.
u1 = session.execute(select(Aluno)).scalars().first() [SQL] SELECT aluno.id FROM aluno # ao tentar acessar a propriedade relacionada u1.enderecos # um erro é lançado sqlalchemy.exc.InvalidRequestError: 'Aluno.enderecos' is not available due to lazy='raise_on_sql'
Essa exceção indica que a coleção devaria ter sido carregada antes do uso.
u1 = (
session.execute(select(User).options(selectinload(User.addresses)))
.scalars()
.first()
)
[SQL]
SELECT aluno.id FROM aluno
[...]
SELECT endereco.aluno_id AS endereco_aluno_id, endereco.id AS endereco_id
FROM endereco WHERE endereco.aluno_id IN (?, ?, ?, ?, ?, ?) (1, 2, 3, 4, 5, 6)
O opção lazy="raise_on_sql" também tenta o carregamneto correto em relacionamentos muitos-para-um. Se o atributo Endereco.aluno não estiver preenchido mas o objeto Aluno já está carregado no sessão atual, então a estratégia raiseload não lança erros.
Bibliografia
Esse texto é baseado primariamente na documentação do SQLAlchemy, disponível em SQLAlchemy 2, Documentation. Outras referências no artigo Python e SQL: SQLAlchemy.

















 # múltiplos where()
print(
select(endereco.c.email)
.where(user_table.c.name == "Joana")
.where(endereco.c.aluno_id == aluno.c.id)
)
# ou, múltiplos argumentos (o que é equivalente)
print(select(endereco.c.email).where(user_table.c.name == "Joana",
endereco.c.aluno_id == aluno.c.id))
# em ambos os casos o resultado é
[SQL]
↳ SELECT endereco.email FROM endereco, aluno
WHERE aluno.nome = :nome_1 AND enderco.aluno_id = aluno.id
# múltiplos where()
print(
select(endereco.c.email)
.where(user_table.c.name == "Joana")
.where(endereco.c.aluno_id == aluno.c.id)
)
# ou, múltiplos argumentos (o que é equivalente)
print(select(endereco.c.email).where(user_table.c.name == "Joana",
endereco.c.aluno_id == aluno.c.id))
# em ambos os casos o resultado é
[SQL]
↳ SELECT endereco.email FROM endereco, aluno
WHERE aluno.nome = :nome_1 AND enderco.aluno_id = aluno.id




















 Veja o artigo
Veja o artigo 

