ReorderableListView
Um controle ReorderableListView é um widget container que admite controles filhos reposicionáveis. Ele cria uma lista similar à ListView com filhos que podem ser arrastados para novas posições, mostrando uma animação durante o movimento. Ele pode ser usado para abrigar listas com elementos de prioridade ajustável, como uma lista de tarefas ou de músicas.
Exemplo Básico
O controle ReorderableListView permite a construção de linhas ou colunas que podem ser arrastadas e reposicionadas, mudando de lugar com uma animação suave. No exemplo abaixo, dois desses controles são inseridos em uma página. No primeiro, declarado como uma lista horizontal (horizontal=True) são inseridos 2 elementos do tipo ft.Container. No segundo, uma lista vertical (horizontal=False, que é o default), são inseridos 2 elementos ft.ListTile.
import flet as ft
def main(page: ft.Page):
page.add(
# 2 colunas dispostas horizontalmente
ft.ReorderableListView(
expand=True, horizontal=True,
controls=[
ft.Container(width=250, content=ft.Text("Festa"), alignment=ft.alignment.center, bgcolor="#228A82"),
ft.Container(width=250, content=ft.Text("Trabalho"), alignment=ft.alignment.center, bgcolor="#8A4F22"),
],
),
# 2 linhas dispostas verticalmente
ft.ReorderableListView(
controls=[
ft.ListTile(title=ft.Text("Comprar cerveja"), bgcolor="#6C8785"),
ft.ListTile(title=ft.Text("Tomar a cerveja"), bgcolor="#BA733C"),
],
)
)
ft.app(main)
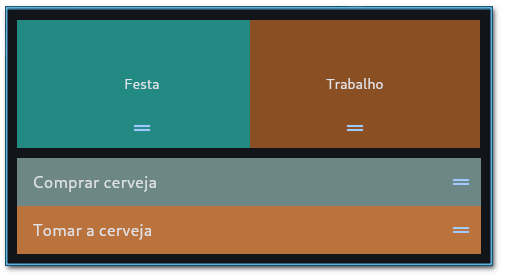
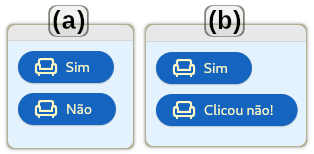
O resultado desse código está mostrado na figura 1.
Os containers Festa e Trabalho podem ser movidos e realocados horizontalmente. Na parte inferior as linhas Comprar cerveja e Tomar cerveja podem ser arrastados verticalmentes e alterados em sua posição. Em um caso mais completo, os eventos de arrastar podem ser capturados (veja abaixo) para alterar propriedades do aplicativo, alterar um banco de dados ou executar qualquer outra ação desejada.
O arrasto é feito com o mouse nas marcas de abas (traços em azul). Se existirem mais controles que que o espaço disponĩvel para exibí-los, uma barra de rolagem é disponibilizada.
Observação: No atual estado do Flet (em Abril de 2025) a atualização de qualquer controle no aplicativo, como por exemplo, uma linha de texto informando sobre o estado da página, atualiza toda a página, retornando os controles ReorderableListView ao seu estado original.
Propriedades
O controle ReorderableListView possui as seguintes propriedades. Como ele pode conter diversos outros controles filhos a formatação e coleta de eventos dos filhos pode ser feita de forma independante.
| Propriedade | Descrição |
|---|---|
| anchor | A posição relativa do deslocamento de rolagem zero. O default é 0,0. |
| auto_scroller_velocity_scalar | A velocidade escalar por pixel sobre rolagem. Representa como a velocidade é dimensionada com a distância de rolagem. A velocidade de rolagem automática = (distância da overscroll) * velocidade escalar. |
| build_controls_on_demand | Booleano. Se True controles são criados de forma preguiçosa/sob demanda, ou seja, somente quando se tornarem visíveis. Isso é útil quando de lida com um número grande de controles. O default é True. |
| cache_extent | A janela de visualização (viewport) possui uma área antes e depois da área visível onde armazena em cache itens que serão tornados visíveis quando o usuário rola a página.
Itens nessa área de cache são dispostos antes de se tornarem visíveis na tela. O cache_extent define quantos pixels a área de cache inclui antes da borda inicial e depois da borda final da janela de visualização. |
| controls | Lista de controles que serão inseridos e reordenados. |
| clipe_behavior | O conteúdo será recortado (ou não) de acordo com esta opção. O valor é do tipo ClipBehavior e default é ClipBehavior.HARD_EDGE. |
| first_item_prototype | Booleano. Se True as dimensões (largura e altura) definidas para o primeiro item são usadas como “protótipo” para os demais itens. O default é False. |
| footer | Um controle a ser usado no rodapé. Esse item é não reordenável e será exibido ao final dos controles ordenáveis. O valor é do tipo Control. |
| header | Um controle a ser usado como cabeçalho. Esse item é não reordenável e será exibido antes dos controles ordenáveis. O valor é do tipo Control. |
| horizontal | Booleano, se os controles devem ser dispostos horizontalmente. O default é False. |
| item_extent | Se não nulo, força os filhos a terem a extensão fornecida na direção de rolagem.
É mais eficiente especificar um item_extent do que deixar que os filhos determinem sua própria extensão pois o mecanismo de rolagem tem informação prévia da extensão dos filhos. Isso economiza trabalho, por exemplo, quando a posição de rolagem muda drasticamente. |
| padding | Espaço de afastamento interno dos controles. O valor é do tipo Padding. |
Eventos
O controle ReorderableListView responde aos seguintes eventos:
| Evento | Descrição |
|---|---|
| on_reorder | Dispara quando um controle filho é arrastado para uma nova posicão. O aplicativo tem que ser atualizado para reordenar esses itens. |
| on_reorder_start | Dispara quando o arrasto do controle filho é iniciado. |
| on_reorder_end | Dispara quando termina o arrasto do controle filho. |
O argumento de evento é do tipo OnReorderEvent, chamado e nos exemplos dados.
Exemplo de Uso do ReorderableListView
Um exemplo mais completo de uso do ReorderableListView está apresentado abaixo:
import flet as ft
def main(page: ft.Page):
page.title = "Demonstração de ReorderableListView"
page.bgcolor=ft.Colors.WHITE
page.window.width=330
page.window.height=620
def move_coluna(e: ft.OnReorderEvent):
print(f"Coluna movida da posição {e.old_index+1} para {e.new_index+1}.")
def move_linha(e: ft.OnReorderEvent):
print(f"Linha movida da posição {e.old_index+1} para {e.new_index+1}.")
cor=[ft.Colors.GREEN_200, ft.Colors.GREEN_50, ft.Colors.GREEN_500, ft.Colors.GREEN]
coluna=["A","B","C","D","E"]
linha=["Comparar café","Tomar café","Comprar cerveja","Tomar cerveja","Dormir"]
# Colunas dispostas horizontalmente
lista_horizontal = ft.ReorderableListView(
expand=True,
horizontal=True,
on_reorder=move_coluna,
controls=[
ft.Container(
border=ft.border.all(1, ft.Colors.BLACK),
content=ft.Text(f"{coluna[i]}", color=ft.Colors.BLACK),
margin=ft.margin.symmetric(horizontal=1, vertical=5),
width=60,
alignment=ft.alignment.center,
bgcolor= cor[i%2],
) for i in range(5)
],
)
# linha_header
linha_header=ft.Container(
content=ft.Text("Coisas a Fazer", color=ft.Colors.WHITE),
margin=ft.margin.symmetric(horizontal=0, vertical=5),
padding=5,
height=30,
bgcolor= cor[2],
)
# linha_footer
linha_footer=ft.Container(
content=ft.Text("Fim da Página", color=ft.Colors.WHITE),
margin=ft.margin.symmetric(horizontal=0, vertical=5),
padding=5,
height=30,
bgcolor=cor[2],
)
# Linhas dispostas verticalmente
lista_vertical=ft.ReorderableListView(
expand=True,
on_reorder=move_linha,
header=linha_header,
footer=linha_footer,
controls=[
ft.Container(
border=ft.border.all(1, ft.Colors.BLACK),
content=ft.Text(f"{linha[i]}", color=ft.Colors.BLACK),
margin=ft.margin.symmetric(horizontal=1, vertical=1),
width=330,
height=40,
padding=10,
alignment=ft.alignment.center_left,
bgcolor= cor[i%2],
) for i in range(5)
],
)
page.add(lista_horizontal, lista_vertical)
ft.app(main)
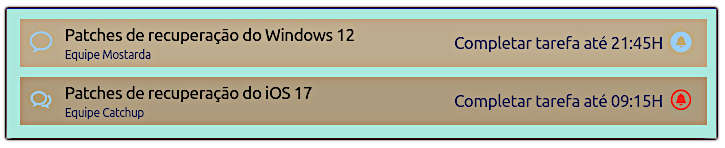
Após algumas operações de arrasto das linhas e colunas, as seguintes linhas são exibidas no console:
Linha movida da posição 1 para 4. Linha movida da posição 2 para 3. Coluna movida da posição 1 para 4. Coluna movida da posição 2 para 3.

O resultado desse código está mostrado na figura 2 em seu estado inicial e depois dos arrastos descritos acima.
Observe que as propriedades controls de ambos os ReorderableListView, que são listas (lists ordinárias do Python), foram preenchidos com compressão de listas. Esse mecanismo está descrito em Compreensão de listas no Python e resumido abaixo:
$ lista1=[i** for i in range(10)] $ print(lista1) ↳ [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] $ lista2=[i** for i in range(10) if i%2==0] $ print(lista2) ↳ [0, 4, 16, 36, 64]
Portanto o código preenche a lista ft.ReorderableListView.controls com 5 instâncias de ft.Container, com i=0,...,4. As propriedades internas variam com i em linha[i], definida como uma lista no início do código, e cor[i%2], que pode ser apenas cor[0] ou cor[1], de outra lista já definida.
A propriedade horizontal=True define que os controles são dispostos na horizontal.















 import flet as ft
def clicou_sim(e):
e.control.text = "Clicou sim!"
e.control.update()
def clicou_nao(e):
e.control.text = "Clicou não!"
e.control.update()
class NovoBotao(ft.ElevatedButton):
def __init__(self, clicou, texto="Não"):
super().__init__()
self.bgcolor = ft.colors.BLUE_800
self.color = ft.colors.YELLOW_100
self.icon="chair_outlined"
self.icon_color="GREEN_100"
self.text = texto
self.on_click = clicou
def main(page: ft.Page):
page.bgcolor=ft.colors.BLUE_50
page.add(
NovoBotao(texto="Sim", clicou = clicou_sim),
NovoBotao(clicou = clicou_nao)
)
ft.app(target=main)
import flet as ft
def clicou_sim(e):
e.control.text = "Clicou sim!"
e.control.update()
def clicou_nao(e):
e.control.text = "Clicou não!"
e.control.update()
class NovoBotao(ft.ElevatedButton):
def __init__(self, clicou, texto="Não"):
super().__init__()
self.bgcolor = ft.colors.BLUE_800
self.color = ft.colors.YELLOW_100
self.icon="chair_outlined"
self.icon_color="GREEN_100"
self.text = texto
self.on_click = clicou
def main(page: ft.Page):
page.bgcolor=ft.colors.BLUE_50
page.add(
NovoBotao(texto="Sim", clicou = clicou_sim),
NovoBotao(clicou = clicou_nao)
)
ft.app(target=main)