

SQL e SQLAlchemy
Um projeto Python: SQLite.Essas notas e o código listado estão baseados na versão 2.0 do SQLAlchemy que é a versão lançada em 26 de janeiro de 2023. Um documento de migração, para quem está habituado com versões anteriores, está disponível em SQLAlchemy 2.0 – Major Migration Guide.
SQL é uma linguagem de consulta a bancos de dados relacionais universalmente usada para aplicativos em desktop ou na web. Existem muitas bibliotecas de integração desses bancos com o Python, inclusive o sqlite3 que vem instalado na biblioteca padrão, já descrito aqui em linhas básicas. Uma biblioteca Python poderosa e flexível muito usada é a SQLAlchemy, criada por Mike Bayer em 2005, de código aberto e disponibilizado sob licença MIT. Com ela se pode fazer consultas tradicionais, usando as queries padrões do SQL, mas também utilizar ferramentas que abstraem essas consultas associando as tabelas de banco de dados com classes. Ela pode ser usada para fazer a conexão com os bancos de dados mais comuns, como o Postgres, MySQL, SQLite, Oracle, entre outros.
Com o SQLAlchemy podemos abstrair do código específico do banco de dados subjacente. Com instruções comuns para todos os bancos ele facilita a migração de um banco para outro, sem maiores dificuldades. Além disso ele cuida de problemas de segurança comuns, tais como ataques de injeção de SQL. O SQLAlchemy é bastante flexível e permite duas formas principais de uso: o SQL Expression Language (referido como Core) e Object Relational Mapping (ORM), que podem ser usados separadamente ou juntos, dependendo das necessidades do aplicativo.
SQLAlchemy Core e ORM
SQL Expression Language (CORE): é uma forma de representar instruções e expressões SQL comuns de modo pitônico, uma abstração das consultas SQL sem se afastar muito delas. Ela é uma interface bem próxima das bancos de dados mas padronizado para ser consistente com muitos desses bancos. Além disso ela fundamenta o SQLAlchemy ORM.
SQLAlchemy ORM: é um mapeador relacional de objeto (ORM, Object Relational Mapper) que fornece uma abstração de alto nível sobre a SQL Expression Language. Ele utiliza um sistema declarativo semelhante aos utilizados em outros ORMs como, por exemplo, o do Ruby on Rails.

Diferente da maioria das outras ferramentas SQL/ORM, o SQLAlchemy não tenta ocultar os detalhes do mecanismo de SQL, deixando expostos e sob controle do programador todos os processos envolvidos. Ele estabelece uma associação entre o banco de dados e classes, geralmente atribuindo uma classe a cada tabela e cada instância dessa classe com linhas da tabela.
Instalando o SQLAlchemy
Um ambiente virtual é recomendado (embora não obrigatório).
# criamos um ambiente virtual com o comando $ python3 -m venv ~/Projetos/.venv # para ativar o ambiente virtual $ cd ~/Projetos/.venv $ source bin/activate # instalamos o sqlalchemy (última versão publicada) $ pip install sqlalchemy # para a distribuição Anaconda do Python $ conda install -c anaconda sqlalchemy # criamos uma pasta para o sqlalchemy $ mkdir ~/Projetos/.venv/sqlalchemy $ cd ~/Projetos/.venv/sqlalchemy # para verificar a versão instalada iniciamos o python e carregamos o sqlalchemy $ python >>> import sqlalchemy >>> sqlalchemy.__version__ '2.0.0rc3'
O sqlalchemy consegue se conectar com banco de dados sqlite sem a necessidade de nenhum drive adicional. Para o PostgreSQL podemos usar o psycopg2, instalado com pip install psycopg2. Para o MySQl uma boa opção é o PyMySQL (pip install pymysql). Para nosso processo de aprendizado usaremos o SQLite.
A engine do SQLAlchemy
Para estabelecer contato com o banco de dados criamos uma instância do objeto da classe engine com create_engine que usa uma string de conexão (connection string), uma string com formato próprio para fornecer o tipo do banco, detalhes de autenticação (usuário e senha), localização do banco (servidor ou arquivo), e a DBAPI† usada.
† A DBAPI (Python Database API Specification) do Python é um driver usado pelo SQLAlchemy para interagir com o banco de dados escolhido. Por exemplo, nos nossos exemplos estamos usando sqlite3, da biblioteca padrão.
A DBAPI é uma API de baixo nível usado pelo Python para conectar ao banco de dados. O sistema de dialetos do SQLAlchemy é construído pela DBAPI que fornece classes específicas para lidar com o mecanismo de BD usado, como POSTGRES, MYSQL, SQLite, etc.
Por exemplo, para uma conexão com um arquivo meu_banco.db do SQLite usamos:
from sqlalchemy import create_engine
# abaixo alguns exemplos de strings de conexão
engine1 = create_engine("sqlite:///meu_banco.db")
engine2 = create_engine("sqlite:////home/projeto/db/meu_banco.db")
engine3 = create_engine("sqlite:///:memory:")
# no windows
engine4 = create_engine("sqlite:///c:\\Users\\projeto\\db\\meu_banco.db")
# para efetivar a conexão
connection = engine1.connect()
# para ativar um serviço de log usamos echo=True
engine1 = create_engine("sqlite:///meu_banco.db", echo=True)
No caso 1 o arquivo está na pasta default, no 2 o caminho completo é informado. A conexão em engine3 cria um banco na memória (sem ser gravado em disco), o que é útil para aprendizado e experimentação. Em 4 se mostra a sintaxe de pastas para o Windows. A função create_engine retorna uma instância da engine mas não estabelece a conexão, o que é chamado de lazy connection. Essa conexão só é efetivada quando, pela primeira vez, alguma ação é executada no banco. Se o arquivo meu_banco.db não existe ele é criado com esse processo.
O ajuste do parâmetro opcional echo = True faz com que todas as operações feitas no banco sejam também exibidas no console com a sintaxe do SQL. Nessas notas exibiremos os comandos mostrados nesse log com a marcação [SQL].
Conexão
O SQLAlchemy Core usa uma linguagem de expressão (SQLAlchemy Expression Language) como forma de interagir com o código Python. Uma forma de enviar comandos SQL literais consiste no uso da função text(), útil no aprendizado e experimentação mas não muito usado na prática em projetos. Para efetivar a conexão usamos o método engine.connect(). No código abaixo o banco meu_banco.db será criado na pasta do projeto, se já não existir. O objeto engine é o elemento básico no relacionamento com o BD, basicamento feito através de sua função connect():
from sqlalchemy import create_engine, text
engine = create_engine("sqlite:///meu_banco.db")
with engine.connect() as conn:
conn.execute(text("CREATE TABLE IF NOT EXISTS coordenadas (x int, y int)"))
conn.execute(
text("INSERT INTO coordenadas (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}, {"x": 3, "y": 9}],
)
result = conn.execute(text("SELECT * FROM coordenadas"))
print(result.all())
# nenhuma alteração foi feito no banco de dados. Alterações são feitas com
conn.commit()
# agora o INSERT foi efetivado no BD
# o print acima exibe
↳ [(1, 1), (2, 4), (3, 9)]
O objeto result é um iterador que fica esgotado após a operação print(result.all()). Se quisermos utilizar esse resultado posteriormente temos que refazer a consulta ou armazenar os valores. O gerenciador de contexto with garante que a conexão (atribuída à variável conn) é criada e fechada após a operação, o que garante que os recursos usados são liberados. Podemos percorrer result em um loop:
with engine.connect() as conn:
result = conn.execute(text("SELECT x, y FROM coordenadas"))
for linha in result:
print(f"x = {linha.x} y = {linha.y}")
# ou print(f"x = {linha[0]} y = {linha[1]}")
# output
↳ x = 1 y = 1
x = 2 y = 4
x = 3 y = 9
Result possui vários métodos de busca e transformações de linhas. Um deles é result.all() visto acima, que retorna uma lista de todos os objetos Row. Ele age como um iterador do Python. Cada linha é um objeto row representado por uma tupla (e agindo como tuplas nomeadas). Para recuperar esses valores podemos usar fazer uma atribuição de tuplas, usar índices ou usar os nomes das tuplas nomeadas.
# feita a consulta
result = conn.execute(text("SELECT x, y FROM coordenadas"))
# qualquer um dos métodos pode ser usado:
# atribuição de tuplas
for x, y in result:
print(x, y)
# uso de índices
for row in result:
print(row[0], row[1])
# tuplas nomeadas
for row in result:
print(row.x, row.y)
Também podemos usar as linhas recebidas mapeando o resultado em dicionários com o modificador Result.mappings():
result = conn.execute(text("SELECT x, y FROM coordenadas"))
for dict_row in result.mappings():
x = dict_row["x"]
y = dict_row["y"]
...
Passando parâmetros
O método Connection.execute() aceita parâmetros que modificam a consulta feita. Por exemplo, para fazer uma consulta SELECT, atendendo a alguns critérios, inserimos o modificador WHERE à instrução.
with engine.connect() as conn:
query = text("SELECT x, y FROM coordenadas WHERE y > :y")
result = conn.execute(query, {"y": 2})
for row in result:
print(f"x = {row.x} y = {row.y}")
[SQL]
SELECT x, y FROM coordenadas WHERE y > 2
# resulta em
↳ x = 2 y = 4
x = 3 y = 9
O valor do parâmetro em :y é lido no dicionário, resultando em WHERE y > 2. Essa técnica é chamada de “estilo de parâmetro qmark” e deve sempre ser usada para evitar ataques de injeção SQL no aplicativo.
Múltiplos parâmetros podem ser passados. Podemos enviar vários parâmetros para o método Connection.execute() por meio de uma lista de dicionários (no estilo conhecido como executemany). Isso já foi feito na nossa primeira operação de inserção.
# vamos apagar todas as linhas da tabela
with engine.connect() as conn:
result = conn.execute("DELETE FROM coordenadas")
conn.commit()
# agora vamos inserir várias linhas de uma vez
with engine.connect() as conn:
query = text("INSERT INTO coordenadas (x, y) VALUES (:x, :y)")
values = [{"x": 11, "y": 12}, {"x": 13, "y": 14}, {"x": 15, "y": 16}]
conn.execute(query, values,)
conn.commit()
# o BD agora contém a tabela mostrada na figura.

No código acima, values é uma lista de dicionários e a operação de INSERT é feita uma vez para cada item da lista.
Metadata, Table e Column
Nos bancos de dados relacionais os objetos mais básicos são as tabelas que são, por sua vez, constituídas por colunas e linhas, cada uma delas com seu correspondente objeto do Python via SQLAchemy.
Classe MetaData: O SQLAlchemy mantém um objeto chamado MetaData que armazena toda a informação sobre as tabelas usadas, as colunas, vínculos e relacionamentos. A sintaxe de criação de um objeto MetaData é a seguinte:
from sqlalchemy import MetaData metadata_objeto = MetaData()
É comum que um único objeto MetaData sirva para armazenar todas as tabelas de um aplicativo, geralmente como uma variável de nível de módulo. Pode ocorrer, embora seja menos comum, que existam vários objetos MetaData. Mesmo assim as tabelas continuam podendo se relacionar entre elas.
Table e Column: Objetos Table são inicializados em um objeto MetaData através do construtor de tabelas onde o nome é fornecido. Argumentos adicionais são considerados objetos de coluna. Objetos Column representam cada campo na tabela. A sintaxe de definição de uma tabela é variavel = Table("nome_tabela", metadata, Columns ...).
from sqlalchemy import Table, Column, Integer, Numeric, String
# tabela alunos
alunos = Table("alunos", metadata,
Column("id", Integer(), primary_key=True),
Column("matricula", String(50), nullable=False, unique=True),
Column("nome", String(50), index=True, nullable=False),
Column("sobrenome", String(50)),
Column("idade", Integer()),
Column("curso", String(50)),
Column("nota_final", Numeric(2, 2)),
Column("nascimento", DateTime()),
Column("atualizado", DateTime(), default=datetime.now, onupdate=datetime.now)
)
# tabela notas
notas = Table("notas", metadata,
Column("id", Integer(), primary_key=True),
Column("id_aluno", ForeignKey("aluno.id"), nullable=False),
Column("nota", Numeric(2, 2)),
Column("data_prova", DateTime())
)
# as chaves primárias podem ser visualizadas
print(alunos.primary_key)
# resulta em:
PrimaryKeyConstraint(Column('id', Integer(), table=, primary_key=True, nullable=False))
# as tabelas são criadas no BD com
engine = create_engine('sqlite:///meu_banco.db')
metadata.create_all(engine)
O campo id é uma chave primária, nome é um índice, usado para agilizar consultas. O construtor de table usa vários construtores de colunas, cada um com seu nome e definição. O campo matricula não pode ser nulo nem repetido (nullable=False, unique=True). O campo atualizado é um campo de datas com default (now), e é atualizado automaticamente toda vez que o registro é alterado. Os parênteses no import servem para quebrar a linha sem a necessidade de uso da barra invertida, \.
Quando uma coluna é definida como ForeignKey dentro da definição da tabela, como foi feito acima, o tipo de dado pode ser omitido pois é automaticamente ajustado de acordo com a coluna a que se refere. No caso acima id_aluno tem o mesmo tipo que aluno.id, que é um inteiro.
Chaves e vínculos: (Keys, Constraints) são formas de forçar algum critério sobre os dados e seus relacionamentos. Chaves primárias (primary keys ou “PK”) são identificadores únicos e nunca nulos usados em relacionamentos. Vimos que escolhemos um campo como chave primária usando primary_key=True. Vários campos podem ser usados em chaves compostas. Nesse caso a chave será usada como uma tupla contendo os vários campos. O vínculo UniqueConstraint (informado com unique=True) é a exigência de que um valor não pode ser duplicado no campo. Além desses temos o CheckConstraint que estabelece que os dados satisfaçam regras definidas pelo programador. Todos esses campos podem ser definidos em linhas próprias, depois das definições das colunas, como mostrado abaixo:
from sqlalchemy import PrimaryKeyConstraint, UniqueConstraint, CheckConstraint
PrimaryKeyConstraint("id", name="aluno_pk")
UniqueConstraint("matricula", name="aluno_matricula")
CheckConstraint("nota_final >= 0.00", name="aluno_nota")
Índices: são usados para agilizar buscas de valores em um campo e devem ser aplicados a campos que servem para buscas em uma tabela. Além da criação com index=True usado na tabela alunos podemos criar o índice explicitamente com
from sqlalchemy import Index
Index("ix_alunos_nome", "alunos_nome")
Mais de uma coluna podem ser usadas como índice.
Relacionamentos, chaves estrangeiras: O próximo passo é o estabelecimento de relacionamentos. Por ex., a tabela notas tem cada registro (linhas da tabela) vinculado à um aluno. Essa associação permite uma relação um-para-muitos, no nosso caso com a possibilidade de registrar várias notas para cada aluno. Isso é feito com a seguinte alteração na tabela notas para incluir uma chave estrangeira (forein key):
from sqlalchemy import ForeignKey
notas = Table("notas", metadata,
Column("id", Integer(), primary_key=True),
Column("id_aluno", ForeignKey("alunos.id")),
...
)
# as outras colunas ficam inalteradas
# alternativamente podemos definir a chave em uma linha posterior à definição
from sqlalchemy import ForeignKeyConstraint
ForeignKeyConstraint(["id_aluno"], ["alunos.id"])
Claro que as tabelas podem ter várias chaves estrangeiras. Após todas as definições as alterações podem ser executadas e tornadas permanentes com create_all.
from sqlalchemy import MetaData metadata_objeto = MetaData() # ... definições de tabelas metadata_objeto.create_all(engine)
Por default create_all() não recria tabelas que já existem. Podemos, portanto, executar o comando várias vezes.
Resumindo: O objeto MetaData armazena uma coleção de objetos Table que, por sua vez, armazena objetos Column e Constraint. Essa estrutura de objetos é a base da maioria das operações do SQLAlchemy, tanto Core quanto ORM.
Executando o código: Juntando as partes, colocamos todos os comando em um arquivo sqlal.py e o executamos com python sqlal.py.
from datetime import datetime
from sqlalchemy import (MetaData, Table, Column, Integer, Numeric, String,
DateTime, ForeignKey, create_engine)
metadata = MetaData()
# tabela alunos
alunos = Table("alunos", metadata,
Column("id", Integer(), primary_key=True),
Column("matricula", String(50), nullable=False, unique=True),
Column("nome", String(50), index=True, nullable=False),
Column("sobrenome", String(50)),
Column("idade", Integer()),
Column("curso", String(50)),
Column("nota_final", Numeric(2, 2)),
Column("nascimento", DateTime()),
Column("atualizado", DateTime(), default=datetime.now, onupdate=datetime.now)
)
# tabela notas
notas = Table("notas", metadata,
Column("id", Integer(), primary_key=True),
Column("id_aluno", ForeignKey("alunos.id")),
Column("nota", Numeric(2, 2)),
Column("data_prova", DateTime())
)
engine = create_engine("sqlite:///meu_banco.db", echo=True)
metadata.create_all(engine)
Podemos notar que a construção de um objeto Table tem semelhança com o processo de declarar um comando SQL CREATE TABLE. Foram usados os objetos: Table que representa uma tabela no banco de dados e fica armazenado em uma coleção MetaData; Column que representa uma coluna de uma tabela. A declaração de colunas incluem seu nome, e o tipo de objeto. A coleção de objetos coluna pode ser acessada por meio de um array associativo em Table.c.
alunos.c.nome
↳ Column('nome', String(length=50), table=)
alunos.c.keys()
↳ ['id', 'id_aluno', 'nome', 'data_prova']
Após a execução desse código temos as tabelas ilustradas na figura abaixo, inclusive o relacionamento de notas.id_alunos como foreign key ligado ao campo alunos.id.
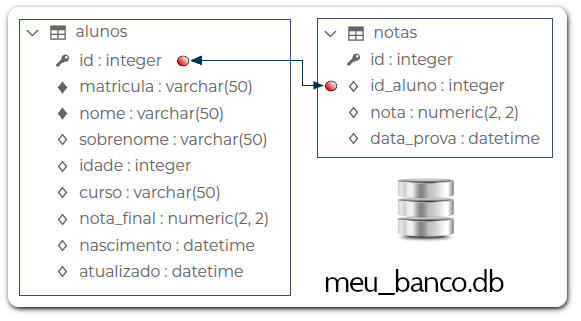
Inserção de dados
Após a definição das tabelas, colunas e relacionamentos podemos inserir dados.
# inserção de dados
query = alunos.insert().values(
matricula = "943.232-90",
nome = "Arduino",
sobrenome = "Bolivar",
idade = "17",
curso = "Eletrônica",
nota_final = 17.20,
nascimento = ""
)
print(str(query))
# o seguinte output é obtido:
↳ INSERT INTO alunos
(matricula, nome, sobrenome, idade, curso, nota_final, nascimento, atualizado)
VALUES
(:matricula, :nome, :sobrenome, :idade, :curso, :nota_final, :nascimento, :atualizado)
print(query.compile().params)
# o seguinte output é obtido:
↳ {"matricula": "943.232-90",
"nome": "Arduino",
"sobrenome": "Bolivar",
"idade": "17",
"curso": "Eletrônica",
"nota_final": 17.2,
"nascimento": "21/01/2023",
"atualizado": None}
Note que :nome_campo é a forma usado pelo SQLAlchemy para a representação de string dos valores dos campos em str(query). Internamente os dados são tratados por questões de segurança, como um ataque de injeção SQL. Os valores a serem inseridos podem ser visualizados com query.compile().params. Note que, nas consultas de inserção, não fornecemos valores para os campos de inserção automática, id e atualizado.
De modo similar podemos usar os demais métodos como update(), delete() e select() para gerar consultas UPDATE, DELETE e SELECT respectivamente. Finalmente podemos garantir a persistência dos dados gravando no BD esses valores.
resultado = connection.execute(query) print(resultado.inserted_primary_key) ↳ (1,0)
O útimo comando imprime o id da linha gravada.
Reflexão de tabelas

Além das consultas de criação de tabelas precisamos usar bancos de dados com tabelas já criadas, com suas colunas e relacionamentos estabelecidos. O SQLAlchemy consegue isso com as chamadas reflexões de tabelas (table reflections), o processo de gerar objetos Table (o seus componentes) lendo o estado de um banco de dados já construído.
Veremos uma breve apresentação dessa operação, para ser mais explorada em outra seção. Como exemplo desse processo vamos usar a tabela alunos definida anteriormente. A forma mais básica de se fazer isso é construindo um objeto Table fornecendo o nome da tabela e o objeto Metadata que a contém.
from sqlalchemy import (MetaData, Table, Column, Integer, Numeric, String,
DateTime, ForeignKey, create_engine)
metadata = MetaData()
engine = create_engine('sqlite:///meu_banco.db')
tbl_alunos = Table("alunos", metadata, autoload_with=engine)
print(tbl_alunos.c.keys())
↳ ['id', 'matricula', 'nome', 'sobrenome', 'idade', 'curso', 'nota_final', 'nascimento', 'atualizado']
Também podemos importar para as nossas classes mais de uma tabela de cada vez.
engine = create_engine('sqlite:///meu_banco.db')
metadata = MetaData()
metadata.reflect(bind=engine)
tbl_alunos = metadata.tables["alunos"]
tbl_notas = metadata.tables["notas"]
print("Alunos:", tbl_alunos.c.keys())
print("Notas:", tbl_notas.c.keys())
↳ Alunos: ['id', 'matricula', 'nome', 'sobrenome', 'idade', 'curso', 'nota_final', 'nascimento', 'atualizado']
↳ Notas: ['id', 'id_aluno', 'nota', 'data_prova']
Uma vez importada a tabela podemos extrair dela todas os dados, bem como realizar as alterações usuais de inserção e apagamento.
Tabelas e tipos de dados
O SQLAlchemy define diversos tipos de dados destinados a abstrair os tipos usados nos bancos SQL. Um exemplo disso é tipo genérico booleano que geralmente usa o tipo SQL BOOLEANO (True ou False no Python). No entanto ele possui também o SMALLINT para BDs que não suportam BOOLEANOs. Essa adaptação é automática e o desenvolvedor só tem que lidar com os campos bolleanos do Python: (True / False). A tabela mostra tipos genéricos e suas associações.
| SQLAlchemy | Python | SQL |
|---|---|---|
| BigInteger | int | BIGINT |
| Boolean | bool | BOOLEAN ou SMALLINT |
| Date | datetime.date | DATE (SQLite: STRING) |
| DateTime | datetime.datetime | DATETIME (SQLite: STRING) |
| Enum | str | ENUM ou VARCHAR |
| Float | float ou Decimal | FLOAT ou REAL |
| Integer | int | INTEGER |
| Interval | datetime.timedelta | INTERVAL ou DATE from epoch |
| LargeBinary | byte | BLOB ou BYTEA |
| Numeric | decimal.Decimal | NUMERIC ou DECIMAL |
| Unicode | unicode | UNICODE ou VARCHAR |
| Text | str | CLOB ou TEXT |
| Time | datetime.time | DATETIME |
Bibiografia
- SqlAlchemy.org: SQLAlchemy 2.0 Documentation
- RealPython: Working with Sqlalchemy and Python Objects
- TutorialsPoint: SqlAlchemy Quick Guide
- Datacamp: SqlAlchemy Tutorial with Examples
Michael Bayer: SQLAlchemy. In Amy Brown and Greg Wilson, editors, The Architecture of Open Source Applications Volume II: Structure, Scale, and a Few More Fearless Hacks 2012 aosabook.org