

Layout do Flet: View e Container
Flet: View
Um aplicativo do Flet abre sempre uma page que serve de container para o objeto View. Uma View é criado automaticamente quando uma nova sessão é iniciada. Ela é basicamente uma coluna (column) básica, que abriga todos os demais controles que serão inseridos na página. Dessa forma ele tem comportamento semelhante ao de uma column, e as mesmas propriedades. Uma descrição resumida será apresentada aqui. Para maiores detalhes consulte a descrição de column.
O objeto View é o componente visual de uma página Flet, responsável por renderizar os elementos da UI e gerenciar seu estado. Ele pode abrigar outros objetos como botões, campos de texto, imagens, etc, e organizá-los em uma estrutura hierárquica. Esses elementos são então renderizados na tela. O objeto View também possui métodos para lidar com eventos do usuário, como cliques em botões ou textos digitados nas caixas de texto.
Por exemplo, o código:
page.controls.append(ft.Text("Um texto na página!"))
page.update()
# ou, o que é equivalente
page.add(ft.Text("Um texto na página!"))
insere o texto na View que está diretamente criada sobre page. View possui as seguintes propriedades e métodos.
View: Propriedades
| Propriedade | Descrição |
| appbar | recebe um controle AppBar para exibir na parte superior da página. |
| auto_scroll | Booleano. True para que a barra de rolagem se mova para o final quando os filhos são atualizados. Para que scroll_to() funcione deve ser atribuído auto_scroll=False. |
| bgcolor | Cor de fundo da página. |
| controls | Lista de controles a serem inseridos na página. O último controle da lista pode se removido com page.controls.pop(); page.update(). |
| fullscreen_dialog | Booleano. True se a página atual é um diálogo em tela cheia. |
| route | Rota da visualização (não usada atualmente). Pode ser usada para atualizar page.route em caso de nova visualização. |
| floating_action_button | Recebe um controle FloatingActionButton a ser exibido no alto da página. |
| horizontal_alignment | Alinhamento horizontal dos filhos. Default: horizontal_alignment=CrossAxisAlignment.START. |
| on_scroll_interval | Definição do intervalo de tempo para o evento on_scrollo, em milisegundos. Default: 10. |
| padding | Espaço entre o conteúdo do objeto e suas bordas, em pixeis. Default: 10. |
| scroll | Habilita rolagem (scroll) vertical para a página, evitando overflow. O valor da propriedade está em um ENUM ScrollMode com as possibilidades:
|
| spacing | Espaço vertical entre os controles da página, em pixeis. Default: 10. Só aplicado quando alignment = start, end, center. |
| vertical_alignment | Alinhamento vertical dos filhos. A propriedade está em um ENUM MainAxisAlignmente com as possibilidades:
Exemplos: page.vertical_alignment = ft.MainAxisAlignment.CENTER page.horizontal_alignment = ft.CrossAxisAlignment.CENTER |
| scroll_to(offset, delta, key, duration, curve) | Move a barra de scroll para uma posição absoluta ou salto relativo para chave especificada. |
View: Evento
| Evento | Descrição |
| on_scroll | Dispara quando a posição da barra de rolagem é alterada pelo usuário. |
O controle View é útil em situações que se apresenta mais em uma visualização na mesma página e será visto mais tarde com maiores detalhes.
Flet: Container
Um objeto Container é basicamente um auxiliar de layout, um controle onde se pode inserir outros controles, permitindo a decoração de cor de fundo, borda, margem, alinhamento e preenchimento. Ele também pode responder a alguns eventos.
Como exemplo, o código abaixo:
import flet as ft
def main(page: ft.Page):
page.title = "Contêineres com cores de fundo"
def cor(e):
c4 = ft.Container(content=ft.Text("Outro conteiner azul!"), bgcolor=ft.colors.BLUE, padding=5)
page.add(c4)
c1 = ft.Container(content=ft.ElevatedButton("Um botão \"Elevated\""),
bgcolor=ft.colors.YELLOW, padding=5)
c2 = ft.Container(content=ft.ElevatedButton("Elevated Button com opacidade=0.5",
opacity=0.5), bgcolor=ft.colors.YELLOW, padding=5)
c3 = ft.Container(content=ft.Text("Coloca outra área azul"),
bgcolor=ft.colors.YELLOW, padding=5, on_click=cor)
page.add(c1, c2, c3)
ft.app(target=main)
gera a janela na figura 1, após 1 clique no botão c3.
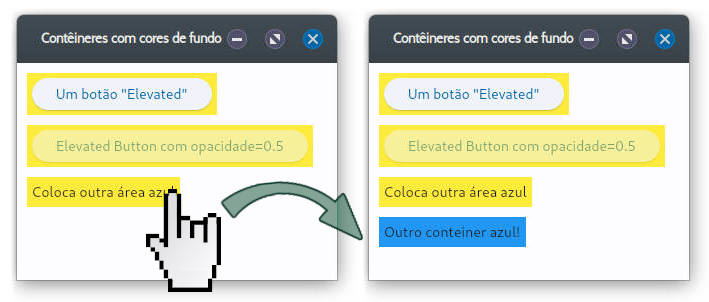
O container c3 reage ao evento clique, adicionando um (ou mais) botão azul à janela.
Container: Propriedades
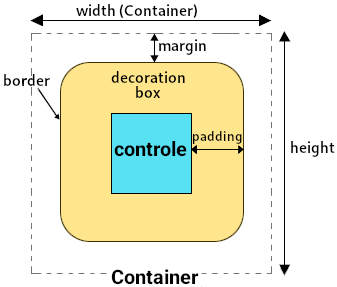
A figura 2 mostra o esquema de espaçamentos entre controles: a largura e altura (width, height) do container, a margem (margin) entre a caixa de decoração e o container, a borda (border) da caixa e o espaçamento interno (padding) entre o controle e a caixa.
| Propriedade | Descrição |
| alignment | Alinhamento do controle filho dentro do Container para exibir na parte superior da página. Alignment é uma instância do objeto alignment.Alignment com propriedades x e y que representam a distância do centro de um retângulo.
 Constantes de alinhamento pré-definidas no módulo flet.alignment são:
|
| animate | Ativa a animação predefinida do container, alterando valores de suas propriedades de modo gradual. O valor pode ser um dos seguintes tipos:
Por exemplo: import flet as ft
def main(page: ft.Page):
c = ft.Container(width=200, height=200, bgcolor="red", animate=ft.animation.Animation(1000, "bounceOut"))
def animar_container(e):
c.width = 100 if c.width == 200 else 200
c.height = 100 if c.height == 200 else 200
c.bgcolor = "blue" if c.bgcolor == "red" else "red"
c.update()
page.add(c, ft.ElevatedButton("Animate container", on_click=animar_container))
ft.app(target=main)
O código resulta na animação mostrada abaixo, na figura 5: |
| bgcolor | Cor de fundo do container. |
| blend_mode | modo de mistura (blend) de cores ou gradientes no fundo container. |
| blur | Aplica o efeito de desfoque (blur) gaussiano sobre o container.
O valor desta propriedade pode ser um dos seguintes:
|
| border | Borda desenhada em torno do controle e acima da cor de fundo. Bordas são descritas por uma instância de border.BorderSide, com as propriedades: width (número) e color (string). O valor da propriedade border é instância de border.Borderclasse, descrevendo os 4 lados do retângulo. Métodos auxiliares estão disponíveis para definir estilos de borda:
Por exemplo: container_1.border = ft.border.all(10, ft.colors.PINK_600) container_1.border = ft.border.only(bottom=ft.border.BorderSide(1, "black")) |
| border_radius | Permite especificar (opcional) o raio de arredondamento das bordas. O raio é instância de border_radius.BorderRadius com as propriedades: top_left, top_right, bottom_left, bottom_right. Esses valores podem ser passados no construtor da instância, ou por meio de métodos auxiliares:
Por exemplo: |
| clip_behavior | Opção para cortar (ou não) o conteúdo do objeto. A propriedade ClipBehavior é um ENUM com valores suportados:
Se |
| content | Define um controle filho desse container. |
| gradient | O gradiente na cor de fundo. O valor deve ser uma instância de uma das classes: LinearGradient, RadialGradient e SweepGradient.
|
| image_fit | Descrita junto com o objeto image. |
| image_opacity | Define a opacidade da imagem ao mesclar com um plano de fundo: valor entre 0.0 e 1.0. |
| image_repeat | Descrita junto com o objeto image. |
| image_src | Define imagem do plano de fundo. |
| image_src_base64 | Define imagem codificada como string Base-64 como plano de fundo do container. |
| ink | True para efeito de ondulação quando o usuário clica no container. Default: False. |
| margin | Espaço vazio que envolve o controle. margin é uma instância de margin.Margin, definindo a propriedade para os 4 lados do retângulo: left, top, right e bottom. As propriedades podem ser dadas no construtor ou por meio de métodos auxiliares:
Por exemplo: container_1.margin = margin.all(10) container_2.margin = 20 # same as margin.all(20) container_3.margin = margin.symmetric(vertical=10) container_3.margin = margin.only(left=10) |
| padding | Espaço vazio de decoração entre borda do objeto e seu container. Padding é instância da padding.Padding com propriedades definidas como padding para todos os lados do retângulo: left, top, right e bottom. As propriedades podem ser dadas no construtor ou por meio de métodos auxiliares:
Por exemplo: container_1.padding = ft.padding.all(10) container_2.padding = 20 # same as ft.padding.all(20) container_3.padding = ft.padding.symmetric(horizontal=10) container_4.padding=padding.only(left=10) |
| shadow | Efeito de sombras projetadas pelo container. O valor dessa propriedade é uma instância ou uma lista de ft.BoxShadow, com as seguintes propriedades:
Exemplo: ft.Container(
shadow=ft.BoxShadow(
spread_radius=1,
blur_radius=15,
color=ft.colors.BLUE_GREY_300,
offset=ft.Offset(0, 0),
blur_style=ft.ShadowBlurStyle.OUTER,
)
)
|
| shape | A forma do conteiner. O valor é ENUM BoxShape: RECTANGLE (padrão), CIRCLE |
| theme_mode | O ajuste do theme_mode redefine o tema usado no container e todos os objetos dentro dele. Se não for definido o tema em theme é válido para o container e seus filhos. |
| theme | Ajuste o tema global e dos filhos na árvore de controle.
Segue um exemplo de uso: import flet as ft
def main(page: ft.Page):
page.theme = ft.Theme(color_scheme_seed=ft.colors.RED)
b1 = ft.ElevatedButton("Botão com tema da página")
b2 = ft.ElevatedButton("Botão com tema herdado")
b3= ft.ElevatedButton("Botão com tema dark")
c1 = ft.Container(
b1,
bgcolor=ft.colors.SURFACE_TINT,
padding=20,
width=300
)
c2 = ft.Container(
b2,
theme=ft.Theme(
color_scheme=ft.ColorScheme(primary=ft.colors.PINK)
),
bgcolor=ft.colors.SURFACE_VARIANT,
padding=20,
width=300
)
c3 = ft.Container(
b3,
theme=ft.Theme(
color_scheme_seed=ft.colors.INDIGO
),
theme_mode=ft.ThemeMode.DARK,
bgcolor=ft.colors.SURFACE_VARIANT,
padding=20,
width=300
)
page.add(c1, c2, c3)
ft.app(main)
|



O tema principal da página é definido em page.theme, usando um seed vermelho. Os botões b1 e b2 simnplesmente herdam o tema da página. O botão b3 está no container definido com theme_mode=ft.ThemeMode.DARK, exibindo o tema escuro. O código gera a janela mostrada na figura 6.
Vale lembrar que c1 = ft.Container(b1,...) é equivalente à c1 = ft.Container(content = b1,...) sendo que o content só pode ser omitido se o conteúdo for inserido como primeiro parâmetro.urlDefine a URL a ser abertta quando o container é clicado, disparando o evento on_click.url_target
Define onde abrir URL no modo web:
- _blank (default): em nova janela ou aba,
- _self: na mesma janela ou aba aberta.
Container: Eventos
| Evento | Dispara quando |
| on_click | o usuário clica no container.
class ft.ContainerTapEvent():
local_x: float
local_y: float
global_x: float
global_y: float
Obs.: O objeto de evento Um exemplo simples de uso: import flet as ft
def main(page: ft.Page):
t = ft.Text()
def clicou_aqui(e: ft.ContainerTapEvent):
t.value = (
f"local_x: {e.local_x}\nlocal_y: {e.local_y}"
f"\nglobal_x: {e.global_x}\nglobal_y: {e.global_y}"
)
t.update()
c1 = ft.Container(ft.Text("Clique dentro\ndo container"),
alignment=ft.alignment.center, bgcolor=ft.colors.TEAL_300,
width=200, height=200, border_radius=10, on_click=clicou_aqui)
col = ft.Column([c1, t], horizontal_alignment=ft.CrossAxisAlignment.CENTER)
page.add(col)
ft.app(target=main)
 As propriedades |
| on_hover | o cursor do mouse entra ou abandona a área do container. A propriedade data do evento contém um string (não um booleano) e.data = "true" quando o cursor entra na área, e e.data = "false" quando ele sai.
Um exemplo de um container que altera sua cor de fundo quando o mouse corre sobre ele: import flet as ft
def main(page: ft.Page):
def on_hover(e):
e.control.bgcolor = "blue" if e.data == "true" else "red"
e.control.update()
c1 = ft.Container(width=100, height=100, bgcolor="red",
ink=False, on_hover=on_hover)
page.add(c1)
ft.app(target=main)
|
| on_long_press | quando o container recebe um click longo (pressionado por um certo tempo). |
Detalhes sobre o gradiente de cores
O gradiente na cor de fundo admite como valor uma instância de uma das classes: LinearGradient, RadialGradient e SweepGradient.
Um exmplo de uso está no código abaixo:
import flet as ft
import math
def main(page: ft.Page):
c1 = ft.Container(
gradient=ft.LinearGradient(
begin=ft.alignment.top_center,
end=ft.alignment.bottom_center,
colors=[ft.colors.AMBER_900, ft.colors.BLUE],),
width=150, height=150, border_radius=5,)
c2 = ft.Container(
gradient=ft.RadialGradient(colors=[ft.colors.GREY, ft.colors.CYAN_900],),
width=150, height=150, border_radius=5,)
c3 = ft.Container(
gradient=ft.SweepGradient(center=ft.alignment.center,
start_angle=0.0, end_angle=math.pi * 2,
colors=[ft.colors.DEEP_PURPLE_800, ft.colors.DEEP_ORANGE_400],),
width=150, height=150, border_radius=5,)
page.add(ft.Row([c1, c2, c3]))
ft.app(target=main)
O código acima gera as imagens na figura 9:

A primeira imagem é gerada com LinearGradient, a segunda com RadialGradient e a última com SweepGradient.
São propriedades da classe LinearGradient:
begin |
instância de Alignment. Posicionamento inicial (0.0) do gradiente. |
end |
instância de Alignment. Posicionamento final (1.0) do gradiente. |
colors |
cores assumidas pelo gradiente a cada parada. Essa lista deve ter o mesmo tamanho que stops se a lista for não nula. A lista deve ter pelo menos duas cores. |
stops |
lista de valores de 0.0 a 1.0 marcando posições ao longo do gradiente. Se não nula essa lista deve ter o mesmo comprimento que colors. Se o primeiro valor não for 0.0 fica implícita uma parada em 0,0 com cor igual à primeira cor em colors. Se o último valor não for 1.0 fica implícita uma parada em 1.0 e uma cor igual à última cor em colors. |
tile_mode |
como o gradiente deve preencher (tile) a região antes de begin depois de end. O valor é um ENUM GradientTileMode com valores: CLAMP (padrão), DECAL, MIRROR, REPEATED. |
rotation |
rotação do gradiente em radianos, em torno do ponto central de sua caixa container. |
Mais Informações:
Gradiente linear na documentação do Flutter.
Unidade de medida de radianos na Wikipedia.
São propriedades da classe RadialGradient:
colors, stops, tile_mode, rotation |
propriedades idênticas às de LinearGradient. |
center |
instância de Alignment. O centro do gradiente em relação ao objeto que recebe o gradiente. Por exemplo, alinhamento de (0.0, 0.0) coloca o centro do gradiente radial no centro da caixa. |
radius |
raio do gradiente, dado como fração do lado mais curto da caixa. Supondo uma caixa com largura = 100 e altura = 200 pixeis, um raio de 1 no gradiente radial colocará uma parada de 1,0 afastado 100,0 pixeis do centro. |
focal |
ponto focal do gradiente. Se especificado, o gradiente parecerá focado ao longo do vetor do centro até esse ponto focal. |
focal_radius |
raio do ponto focal do gradiente, dado como fração do lado mais curto da caixa. Ex.: um gradiente radial desenhado sobre uma caixa com largura = 100,0 e altura = 200,0 (pixeis), um raio de 1,0 colocará uma parada de 1,0 a 100,0 pixels do ponto focal. |
São propriedades da classe SweepGradient:
colors, stops, tile_mode, rotation |
propriedades idênticas às de LinearGradient. |
center |
centro do gradiente em relação ao objeto que recebe o gradiente. Por exemplo, alinhamento de (0.0, 0.0) coloca o centro do gradiente no centro da caixa. |
start_angle |
ângulo em radianos onde será colocada a parada 0.0 do gradiente. Default: 0.0. |
end_angle |
ângulo em radianos onde será colocada a parada 1.0 do gradiente. Default: math.pi * 2. |
Graus e radianos
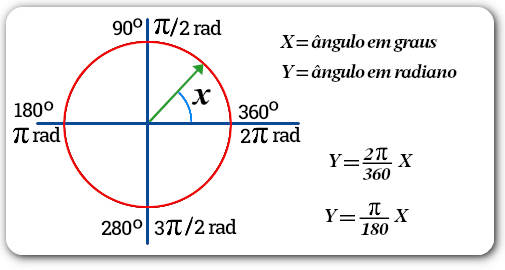
A maiora das medidas angulares na programação do flet (e do python em geral) é dada em radianos. Segue uma breve imagem explicativa do uso de radianos.
Bibiografia
- Python com Flet: Bibiografia Geral
- Flet Controls Galery: Galeria de Controles: Buttons
- Flet Controls: View
- Flet Controls: Container
![]()





 Exemplos: page.fonts
Exemplos: page.fonts


















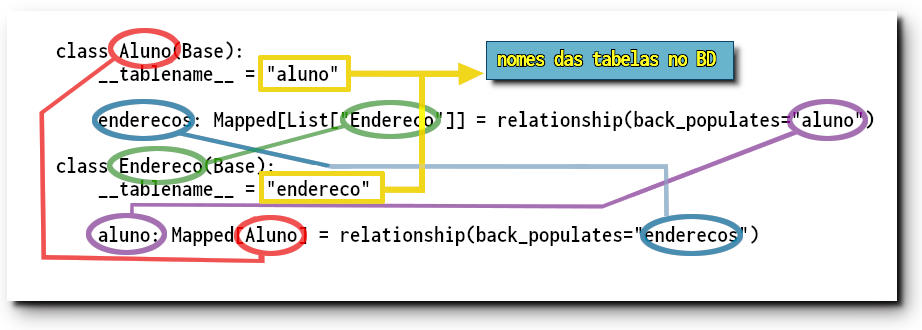






















 # múltiplos where()
print(
select(endereco.c.email)
.where(user_table.c.name == "Joana")
.where(endereco.c.aluno_id == aluno.c.id)
)
# ou, múltiplos argumentos (o que é equivalente)
print(select(endereco.c.email).where(user_table.c.name == "Joana",
endereco.c.aluno_id == aluno.c.id))
# em ambos os casos o resultado é
[SQL]
↳ SELECT endereco.email FROM endereco, aluno
WHERE aluno.nome = :nome_1 AND enderco.aluno_id = aluno.id
# múltiplos where()
print(
select(endereco.c.email)
.where(user_table.c.name == "Joana")
.where(endereco.c.aluno_id == aluno.c.id)
)
# ou, múltiplos argumentos (o que é equivalente)
print(select(endereco.c.email).where(user_table.c.name == "Joana",
endereco.c.aluno_id == aluno.c.id))
# em ambos os casos o resultado é
[SQL]
↳ SELECT endereco.email FROM endereco, aluno
WHERE aluno.nome = :nome_1 AND enderco.aluno_id = aluno.id