

Agrupamentos e ordenações
GROUP BY e funções agregadas: A cláusula GROUP BY permite o agrupamento de linhas de forma a aplicar funções agregadas sobre os grupos gerados. Para estabelecer condições e filtros sobre linhas agrupadas não usamos WHERE e sim a cláusula HAVING. Funções de agregação são uma forma de inserir cálculos, tais como somas, contagem, médias ou localização de máximos e mínimos, sobre todos os elementos de um grupo.

No SQLAlchemy as funções de agregação estão em um namespace chamado de func, que é o construtor de instâncias da classe Function. Por exemplo, para contar quantas linhas tem a tabela aluno escolhemos uma coluna com valores únicos (como id) e contamos quantas linhas existem.
from sqlalchemy import func print(func.count(aluno.c.id)) ↳ count(user_account.id)
Nesse último caso, como nenhum agrupamento foi feito com GROUP BY, o grupo considerado consiste na tabela inteira e a contagem se refere a todas as linhas. Caso a tabela tenha sido particionada com GROUP BY as funções de agregação serão aplicadas a cada grupo individualmente. Para selecionar ou filtrar grupos usamos a cláusula HAVING sobre valores agregados. SQLAlchemy fornece os métodos Select.group_by() e Select.having().
with engine.connect() as conn:
result = conn.execute(
select(Aluno.nome, func.count(Endereco.id).label("count"))
.join(Endereco)
.group_by(Aluno.nome)
.having(func.count(Endereco.id) > 1)
)
print(result.all())
[SQL]
SELECT aluno.nome, count(endereco.id) AS count
FROM aluno JOIN endereco ON aluno.id = endereco.aluno_id
GROUP BY aluno.nome HAVING count(address.id) > 1
A consulta acima faz um JOIN das tabelas aluno e endereco, o que pode retornar várias linhas para cada aluno se ele tiver mais de um endereço registrado. Em seguida ela faz um agrupamento pelo nome e conta quantos endereços existem, retornando apenas aqueles que tem mais de um endereço.
O uso de aliases ou labels podem tornar uma instrução SQL mais legível por evitar repetições de nomes. Aliases também podem ser usados para ordenação e agrupamento.
from sqlalchemy import func, desc
query = (
select(Endereco.aluno_id, func.count(Endereco.id).label("n_enderecos"))
.group_by("aluno_id")
.order_by("aluno_id", desc("n_enderecos"))
)
print(query)
↳ SELECT endereco.aluno_id, count(endereco.id) AS n_enderecos
FROM endereco GROUP BY endereco.aluno_id ORDER BY endereco.aluno_id, n_enderecos DESC
Essa consulta faz um agrupamento da tabela endereco no campo endereco.aluno_id (ou seja, agrupa todos os endereços de cada aluno), conta endereços armazenando a contagem como n_enderecos e exibe o resultado por ordem crescente de endereco.aluno_id, decrescente em n_enderecos. O nome provisório n_enderecos (um label ou alias) é retornado e serve como ordenador das linhas no resultado.

Aliases, no CORE: Também acontece de precisarmos usar o nome de várias tabelas quando fazemos consultas com JOIN e os nomes precisam ser usados várias vezes na mesma consulta. Na SQLAlchemy Expression Language esses aliases são construídos como o objeto Alias retornados pelo método FromClause.alias(). Um objeto construído como um Alias tem a mesma estrutura de uma Table, possuindo objetos Column em sua coleção Alias.c.
alias_1 = aluno.alias()
alias_2 = aluno.alias()
print(
select(alias_1.c.name, alias_2.c.name)
.join_from(alias_1, alias_2, alias_1.c.id > alias_2.c.id)
)
↳ SELECT alias_1.nome AS nome_1, alias_2.nome AS nome_2
FROM aluno AS alias_1 JOIN aluno AS alias_2 ON alias_1.id > alias_2.id
Duas “tabelas” temporárias são construídas a partir da tabela aluno, com os nomes alias_1 e alias_2, que podem ser consultadas independentemente. Essa consulta retorna todos os pares de nomes da tabela aluno, sem repetições.
Subqueries e CTEs
Subqueries (subconsultas) são instruções SELECT realizadas entre parênteses, dentro de uma consulta que a envolve (geralmente outro SELECT). O resultado da subconsulta é usado para a consulta que a envolve. O SQLAlchemy usa o objeto Subquery (em Select.subquery()) para representar uma subconsulta. Qualquer objeto pode ser usado como um elemento FROM dentro de uma construção select() maior.
Como exemplo vamos construir uma subconsulta que selecionará uma contagem agregada de linhas da tabela de endereços (funções agregadas e GROUP BY foram introduzidas anteriormente em Funções Agregadas com GROUP BY / HAVING):
sub_query = (
select(func.count(endereco.c.id).label("contagem"), endereco.c.aluno_id)
.group_by(endereco.c.aluno_id).subquery()
)
# sub_query é uma consulta SELECT (sem os parênteses)
print(sub_query)
↳ SELECT count(endereco.id) AS countagem, endereco.aluno_id
FROM endereco GROUP BY endereco.aluno_id
O objeto Subquery se comporta como qualquer outro objeto FROM (como uma Table), incluindo uma Subquery.c que contém as colunas selecionadas, de onde podemos fazer referência às colunas aluno_id e aquela rotulada “contagem” que contém o resultado da função agregada. Essa subconsulta pode ser usada como parte de FROM em uma nova consulta.
print(select(sub_query.c.user_id, sub_query.c.contagem)) ↳ SELECT alias_1.aluno_id, alias_1.contagem FROM (SELECT count(endereco.id) AS contagem, endereco.aluno_id FROM endereco GROUP BY endereco.aluno_id) AS alias_1
A subconsulta retorna uma tabela com linhas agrupadas por aluno (aluno.id) e o número de endereços registrados para cada um deles no campo “contagem”. A consulta externa simplesmente lista esses linhas. Consultas mais gerais podem ser realizadas, usando a subquery como uma tabela qualquer.
query = select(aluno.c.nome, aluno.c.sobrenome, sub_query.c.contagem).join_from(aluno, sub_query)
print(query)
↳ SELECT aluno.nome, aluno.sobrenome, alias_1.contagem FROM aluno JOIN
(SELECT count(endereco.id) AS contagem, endereco.aluno_id AS aluno_id FROM endereco
GROUP BY endereco.aluno_id) AS alias_1 ON aluno.id = alias_1.aluno_id
A subconsulta gera a tabela com os campos alias_1.contagem e alias_1.aluno_id. A consulta externa faz um JOIN dessa tabela com aluno, retornando nome e sobrenome de cada aluno, junto com o número de endereços cada um tem registrado. A cláusula ON, nesse caso, foi inferida com base nos vínculo e na chave extrangeira (aluno.id = alias_1.aluno_id).
CTEs ou Common Table Expression (Expressões Comuns de Tabelas) são usadas de modo similar às subconsultas mas possuindo recursos adicionais. Um objeto CTE é construído com método Select.cte() e, da mesma forma que as subqueries, pode ser usado como tabela dentro da cláusula FROM. O uso é muito similar ao das subqueries mas o comando SQL gerado é bastante diferente.
ctable = (
select(func.count(endereco.c.id).label("contagem"), endereco.c.aluno_id)
.group_by(endereco.c.aluno_id)
.cte()
)
query = select(aluno.c.nome, aluno.c.sobrenome, ctable.c.contagem).join_from(aluno, ctable)
print(query)
↳ WITH anon_1 AS
(SELECT count(endereco.id) AS contagem, endereco.aluno_id AS aluno_id
FROM endereco GROUP BY endereco.aluno_id)
SELECT aluno.nome, aluno.sobrenome, anon_1.contagem
FROM aluno JOIN anon_1 ON aluno.id = anon_1.aluno_id
A cláusula WITH gera uma tabela temporária (criada pela consulta entre parânteses) a atribui a ela o aliás anon_1. Essa tabela pode ser usada na consulta que se segue.

Subqueries e CTEs com ORM
Aliases, no ORM: O equivalente ORM para gerar aliases é a função aliased(). Quando aplicada a um objeto de classes mapeadas em tabelas, como Aluno e Endereco, essa função retorna um objeto que representa o objeto Table original, mantendo toda a sua funcionalidade ORM original.
from sqlalchemy.orm import aliased
Alias_1 = aliased(Address)
Alias_2 = aliased(Address)
print(
select(Aluno)
.join_from(Aluno, Alias_1)
.where(Alias_1.email == "marcos@aol.com")
.join_from(Aluno, Alias_2)
.where(Alias_2.email == "soares@gmail.com")
)
↳ SELECT aluno.id, aluno.nome, aluno.sobrenome
FROM aluno
JOIN endereco AS alias_1 ON aluno.id = alias_1.aluno_id
JOIN endereco AS alias_2 ON aluno.id = alias_2.aluno_id
WHERE alias_1.email = :email_1 AND alias_2.email = :email_2
O SELECT acima seleciona id, nome e sobrenome da tabela aluno que têm dois endereços de e-mail especificados (no caso “marcos@aol.com” e “soares@gmail.com”).
Subqueries e CTEs: No caso das classes do ORM o método subquery() gera objeto semelhante à Table, com todas as suas propriedades. O mesmo ocorre com aliased() que pode armazenar uma Tabela inteira ou o resultado de uma consulta.
sub_query = select(Endereco).where(~Endereco.email.like("%@gmail.com")).subquery()
endereco_query = aliased(Endereco, sub_query)
query = (
select(Aluno, endereco_query)
.join_from(Aluno, endereco_query)
.order_by(Aluno.id, endereco_query.id)
)
with Session(engine) as session:
for aluno, endereco in session.execute(query):
print(f"{aluno} {endereco}")
# a seguinte consulta é executada
[SQL]
SELECT aluno.id, aluno.nome, aluno.sobrenome,
anon_1.id AS id_1, anon_1.email, anon_1.aluno_id
FROM aluno JOIN (
SELECT endereco.id AS id, endereco.email AS email, endereco.aluno_id AS aluno_id
FROM endereco WHERE endereco.email NOT LIKE ?
) AS anon_1 ON aluno.id = anon_1.user_id
ORDER BY aluno.id, anon_1.id ('%@gmail.com',)
Nessa consulta anon_1 é a representação SQL de endereco_query que, por sua vez, é um aliás para a consulta em sub_query sobre a tabela endereco. A consulta retorna id, nome e sobrenome de alunos, id e email de endereços para aqueles que não possuem email do gmail. Uma consulta análoga com cte pode ser realizada substituindo subquery() por cte() na consulta acima. A consulta gerada usa WITH.
O operador de negação ~ foi usado acima. Por exemplo: ~Aluno.enderecos.any() seleciona as linhas
de Aluno que não possuem endereços cadastrados.
query = select(Aluno.nome).where(~Aluno.enderecos.any()) session.execute(query).all() # a seguinte consulta é executada ↳ SELECT aluno.nome FROM aluno WHERE NOT (EXISTS (SELECT 1 FROM endereco WHERE aluno.id = endereco.aluno_id))
A consulta interna retorna 1 se a linha de aluno possui algum endereço associado.
Subqueries escalares e correlacionadas
Uma subquery escalar (scalar subquery) é uma subquery que retorna apenas 1, ou nenhuma, linha em uma única coluna. Diferente de uma consulta com mais de uma linha e uma coluna, ela pode ser usada em cláusulas WHERE de um SELECT subjacente (que envolve a subquery).
Esse tipo de objeto é obtido com o método .scalar_subquery() e é frequentemente usado com funções de agregamento.
sub_query = (
select(func.count(endereco.c.id))
.where(aluno.c.id == endereco.c.aluno_id)
.scalar_subquery()
)
print(sub_query)
↳ (SELECT count(endero.id) AS count_1 FROM endereco, aluno
WHERE aluno.id = endereco.aluno_id)
O comando SQL gerado é uma query usual e o resultado da consulta é uma única linha com a coluna count_1. A subquery pode ser usada como qualquer outra expressão de coluna.
print(sub_query == 5)
↳ (SELECT count(endereco.id) AS count_1 FROM endereco, aluno
WHERE aluno.id = endereco.aluno_id) = :param_1 {5, }
No exemplo abaixo a subquery é usada em uma consulta ****

Uniões entre tabelas: UNION
Com consultas SQL usuais podemos unir o resultado de duas consultas obtidas com SELECT usando os operadores UNION e UNION ALL. Eles produzem o conjunto de todas as linhas resultantes em cada uma das consultas envolvidas. Também estão disponíveis consultas com INTERSECT [ALL] e EXCEPT [ALL]. No SQLAlchemy essas operações são obtidas com as funções union(), intersect() e except_(), além de union_all(), intersect_all() e except_all() para incluir o modificador ALL. Todas essas funções aceitam um número arbitrário de conjuntos selecionáveis.
O resultado dessas funções é um CompoundSelect que é usado da mesma forma que um objeto resultante de Select, embora tenha menos métodos. Por exemplo:
from sqlalchemy import union_all
query1 = select(aluno).where(aluno.c.nome == "Marcos")
query2 = select(aluno).where(aluno.c.nome == "Joana")
u = union_all(query1, query2)
with engine.connect() as conn:
result = conn.execute(u)
print(result.all())
[SQL]
SELECT aluno.id, aluno.nome, aluno.sobrenome, aluno.enderecos
FROM aluno WHERE aluno.nome = ?
UNION ALL
SELECT aluno.id, aluno.nome, aluno.sobrenome, aluno.enderecos
FROM aluno WHERE aluno.nome = ?
↳ (Marcos', 'Joana')
O resultado são os dados dos alunos “Marcos” e “Joana”.
Ainda usando a união construída acima podemos ilustrar como usar o resultado da união (que é um objeto CompoundSelect) como uma subquery. O próprio objeto possui um método Subquery.
u_subq = u.subquery()
query = (
select(u_subq.c.name, aluno.c.email)
.join_from(endereco, u_subq)
.order_by(u_subq.c.name, endereco.c.email)
)
with engine.connect() as conn:
result = conn.execute(query)
print(result.all())
Uniões com ORM
Os exemplos acima mostram a união construída à partir de objetos Table retornando linhas do BD. Usando os objetos do ORM (as classes representando tabelas) construímos um objeto CompoundSelect que representa a união das entidades ORM e, portanto, das tabelas que elas mapeiam. O método Select.from_statement() pode ser usado para converter o objeto obtido de union_all() em um selecionável (que é uma coleção). Nesse caso UNION representa a consulta inteira, não necessitando de critérios adicionais. O exemplo tem o mesmo efeito que a consulta anterior feita com CORE.
query1 = select(Aluno).where(Aluno.nome == "Marcos")
query2 = select(Aluno).where(Aluno.nome == "Joana")
u = union_all(query1, query2)
orm_query = select(Aluno).from_statement(u)
with Session(engine) as session:
for obj in session.execute(orm_query).scalars():
print(obj)
Alternativamente, uma UNION pode ser usada como subquery e composta com outro objeto ORM por meio da função aliased(). No exemplo abaixo podemos adicionar critérios adicionais como ORDER BY fora do próprio UNION, inserindo filtros ou ordenamentos nas colunas geradas em uma subconsulta.
aluno_alias = aliased(Aluno, u.subquery())
orm_query = select(aluno_alias).order_by(aluno_alias.id)
with Session(engine) as session:
for obj in session.execute(orm_query).scalars():
print(obj)
↳ Aluno(id=1, matricula="12345-67890", nome='Marcos', sobrenome='Sobral', enderecos="")
Aluno(id=2, matricula="54321-12345", nome='Joana', sobrenome='Rosa', enderecos="")
[SQL]
SELECT anon_1.id, anon_1.matricula, anon_1.nome, anon_1.sobrenome, anon_1.enderecos
FROM (SELECT aluno.id AS id, aluno.matricula AS matricula,
aluno.nome AS nome, aluno.sobrenome AS sobrenome, aluno.enderecos AS enderecos
FROM user_account WHERE user_account.name = ?
UNION ALL
SELECT aluno.id AS id, aluno.nome AS nome, aluno.sobrenome AS sobrenome,
aluno.enderecos AS enderecos
FROM aluno WHERE aluno.nome = ?) AS anon_1 ORDER BY anon_1.id
('Marcos', 'Joana')
O resultado, visualizado com print(obj) são objetos ORM (como Aluno).
A subquery EXISTS

No SQL podemos usar o operador EXISTS junto com subconsultas escalares (aqueles que retornam apenas uma linha, ou nenhuma) para retornar um booleano informando se a instrução SELECT retorna uma linha (TRUE) ou nenhuma (FALSE). Esse funcionalidade é conseguida no SQLAlchemy com o uso de uma variante do objeto ScalarSelect chamado Exists.
subq = (
select(func.count(endereco.c.id))
.where(aluno.c.id == endereco.c.aluno_id)
.group_by(endereco.c.aluno_id)
.having(func.count(endereco.c.id) > 1)
).exists()
with engine.connect() as conn:
result = conn.execute(select(aluno.c.nome).where(subq))
print(result.all())
[SQL]
SELECT aluno.nome FROM aluno WHERE EXISTS
(SELECT count(endereco.id) AS count_1 FROM endereco
WHERE aluno.id = endereco.aluno_id GROUP BY endereco.aluno_id
HAVING count(endereco.id) > ?) (1,)
A consulta SELECT em subq é uma consulta que faz uma JOIN de aluno com endereco, agrupa e conta quantos endereços existem para cada aluno, retornando apenas aqueles que possuem mais de um endereço. A função exists() retorna TRUE se existir alguma linha nessa consulta, FALSE se nenhuma linha existe. Esse conjunto de boolenos é usado na consulta seguinte para retornar os nomes dos alunos que satisfazem à condição descrita.
EXISTS é mais usada como uma negação, como em NOT EXISTS. Ela fornece uma forma de localizar linhas de uma tabela associada à outra tabela que não possui linhas no relacionamento. Por exemplo, para encontrar nomes de alunos que não possuem endereços de e-mail podemos fazer:
subq = (select(endereco.c.id).where(aluno.c.id == endereco.c.aluno_id)).exists()
with engine.connect() as conn:
result = conn.execute(select(aluno.c.nome).where(~subq))
print(result.all())
[SQL]
SELECT aluno.nome FROM aluno WHERE NOT (EXISTS
(SELECT endereco.id FROM endereco WHERE aluno.id = endereco.aluno_id)
)
Observe o uso de ~ para negar o resultado de subq dentro da segunda cláusula WHERE.

Funções SQL
Funções do SQL são utilizadas em conjunto com agrupagamentos e filtros (GROUP BY, HAVING), ou sobre linhas ou campos individuais. Elas foram introduzidas na seção sobre agrupamentos. No SQLAlchemy o objeto func funciona como uma fábrica de funções (objetos da classe Function) que podem ser usados em uma construção tipo select() para representar uma função SQL. Elas consistem em um nome, parênteses (na maioria das vezes) e possíveis argumentos. Seguem alguns exemplos de funções SQL.
# count(): função sobre linhas agregadas, conta quantas linhas foram retornadas
print(select(func.count()).select_from(aluno))
↳ SELECT count(*) AS count_1 FROM aluno
# lower(): converte um string em minúsculas:
print(select(func.lower("A String With Much UPPERCASE")))
↳ SELECT lower(:lower_2) AS lower_1
(a string with much uppercase)
# now(): fornece data e hora atual. In sqlite:
query = select(func.now())
with engine.connect() as conn:
result = conn.execute(query)
print(result.all())
SELECT CURRENT_TIMESTAMP AS now_1
O resultado, a consulta SQL, depende do dialeto e BD usado. Como os diversos dialetos incluem muitas funções (que podem variar entre eles) o método func aceita parâmetros de forma liberal, tentando contruir com eles uma função válida. Por outro lado existe um conjunto pequeno de funções comuns a diversas versões do SQL, como count, now, max, concat, que possuem versões pre-definidas.
# uso de nome genérico print(select(func.uma_funcao_qualquer(tabela.c.campo, 17))) ↳ SELECT uma_funcao_qualquer(tabela, :uma_funcao_qualquer_2) AS uma_funcao_qualquer_1 FROM tabela # uso de função comum no postgresql e no oracle from sqlalchemy.dialects import postgresql print(select(func.now()).compile(dialect=postgresql.dialect())) ↳ SELECT now() AS now_1 from sqlalchemy.dialects import oracle print(select(func.now()).compile(dialect=oracle.dialect())) ↳ SELECT CURRENT_TIMESTAMP AS now_1 FROM DUAL
O segundo exemplo acima compara a geração da função SQL no PostgreSQL e no Oracle para a função now().
Tipos definidos de retorno: Algumas funções (mas não todas) retornam objetos com tipo de dados SQL definido. Eles serão chamados aqui de “tipos de retorno SQL” para diferenciá-los do “tipo de retorno” de uma função do Python. O tipo de retorno SQL de qualquer função SQL pode ser verificado com a leitura do atributo Function.type. Por exemplo func.now().type retorna DateTime(). Essa verificação é útil principalmente para debugging.
Considerar o tipo de retorno SQL pode ser importante dentro de uma declaração longa. Operadores matemáticos têm melhor desempenho quando atuam sobre expressões que retornam Integer ou Numeric, por exemplo. Existem operadores que esperam receber parâmetros JSON e funções que retornam colunas ao invés de linhas; as chamadas funções com valor de tabela. Portanto pode ser importante detectar o tipo de objeto que está em uso em algum ponto do código.
O tipo de retorno SQL da função também pode ser significativo quando o SQLAlchemy deve processar o resultado sobre um conjunto de resultados. Um bom exemplo são as funções de datas no SQLite, onde o SQLAlchemy deve converter strings em objetos datetime() do Python. Para garantir que um objeto de tipo específico seja aplicado a uma função passamos o parâmetro Function.type_ especificando esse tipo. No exemplo abaixo passamos a classe JSON para gerar a função PostgreSQL json_object(), lembrando que o tipo de retorno do SQL será do tipo JSON:
# passando a classe JSON para gerar um json_object() do PostgreSQL
from sqlalchemy import JSON
function_expr = func.json_object('{a, 1, b, "def", c, 3.5}', type_=JSON)
query = select(function_expr["def"])
print(query)
↳ SELECT json_object(:json_object_1)[:json_object_2] AS anon_1
O retorno dessa consulta será do tipo JSON.
As funções built-in, como count, max, min, algumas funções de data como now e funções de string como concat, têm tipos de retorno SQL pré-estabelecidos. Em alguns casos esse tipo depende dos argumentos fornecidos.
m1 = func.max(Column("Coluna_de_inteiros", Integer))
m1.type
↳ Integer()
m2 = func.max(Column("Coluna_de_strings", String))
m2.type
↳ String()
Funções de data e hora do SQLAlchemy correspondem às expressões SQL DateTime, Date ou Time. Uma função de string, como concat() retorna strings, como esperado.
func.now().type
↳ DateTime()
func.current_date().type
↳ Date()
func.concat("x", "y").type
↳ String()
No entanto o SQLAlchemy não tem tipo definido de retorno para a maioria das funções SQL. Isso significa que ele não tem essas funções pre-definidas mas apenas converte as consultas em SQL válido. Por exemplo, func.lower() e func.upper() para converter strings em minúsculas e maiúsculas, têm tipo de retorno SQL “nulo”. Isso não significa nenhum problema para funções simples (como lower() e upper()) pois strings podem ser recebidas do banco de dados sem tratamento de tipo no lado do SQLAlchemy e as regras internas de coerção de tipo do SQLAlchemy podem interpretar corretamente a intenção: por ex., o operador Python + do python é interpretado como operador de concatenação de strings ou soma, dependendo dos argumentos usados.
# upper() e json_object() não tem tipo pre-definido
func.upper("lowercase").type
↳ ()
func.json_object('{"a", "b"}').type
↳ NullType()
# inferência automática de tipo
print(select(func.upper("tudo minúscula") + " sufixo"))
↳ SELECT upper(:upper_1) || :upper_2 AS anon_1

Funções de janela SQL
Técnicas Avançadas de Função SQL: alguns gerenciadores de BD, como o PostgreSQL, dão suporte a um conjunto mais avançados de técnicas no uso de funções, em particular aquelas que retornam colunas ou tabelas, muito usadas quando se trabalha com dados em formato JSON.
Vimos que as funções SQL de agregação reúnem linhas sob a cláusula GROUP BY e realizam o cálculo sobre os grupos resultantes. A informação individual de cada linha fica perdida. As funções da janela SQL são diferentes: eles calculam seu resultado com base em um conjunto de linhas, retendo as informações individuais das linhas. Com elas podemos gerar um conjunto de resultados que incluem atributos de uma linha individual.
No SQLAlchemy, todas as funções SQL geradas pelo namespace func incluem um método FunctionElement.over() que insere o modificador OVER na consulta SQL para a determinação de janelas.
Uma função comum usada com funções de janela é a função row_number() que conta as linhas. Podemos particionar essa contagem de linhas em relação ao nome de usuário para numerar os endereços de e-mail de usuários individuais:
query = (
select(
func.row_number().over(partition_by=aluno.c.nome),
aluno.c.nome,
endereco.c.email,
)
.select_from(aluno)
.join(endereco)
)
with engine.connect() as conn:
result = conn.execute(query)
print(result.all())
[SQL]
SELECT row_number() OVER (PARTITION BY aluno.nome) AS anon_1,
aluno.nome, endereco.email
FROM aluno JOIN endereco ON aluno.id = endereco.aluno_id
A consulta acima faz a junção entre aluno e endereco (pelo id do aluno) e retorna quantas linhas existem para cada aluno, com seu respectivo email.
Coerção de tipos de dados
No SQL podemos obrigar um valor resultado de uma consulta a ter um tipo específico, como string ou inteiro. Isso é feito com o operador CAST. No SQLAlchemy temos a função cast() que recebe uma expressão de coluna e um tipo de dado como argumento.
from sqlalchemy import cast
query = select(cast(user_table.c.id, String))
with engine.connect() as conn:
result = conn.execute(query)
result.all()
[SQL]
SELECT CAST(aluno.id AS VARCHAR) AS id FROM aluno
# resultando em strings
[('1',), ('2',), ('3',)]
Ocorre às vezes a necessidade de informar ao SQLAlchemy o tipo de dado de uma expressão para uso no código python mas sem renderizar a expressão CAST do lado SQL. Para conseguir isso podemos usar a função type_coerce(). Ela é particularmente importante quando usamos o tipo de dados JSON que pode em si mesmo conter informação de tipos de dados. No ex. usamos type_coerce() para entregar uma estrutura Python como uma string JSON em uma das funções JSON do MySQL:
import json
from sqlalchemy import JSON, type_coerce
from sqlalchemy.dialects import mysql
s = select(type_coerce({"nome_campo": {"foo": "bar"}}, JSON)["nome_campo"])
print(s.compile(dialect=mysql.dialect()))
↳ SELECT JSON_EXTRACT(%s, %s) AS anon_1
Bibliografia
Esse texto é baseado primariamente na documentação do SQLAlchemy, disponível em SQLAlchemy 2, Documentation. Outras referências no artigo Python e SQL: SQLAlchemy.





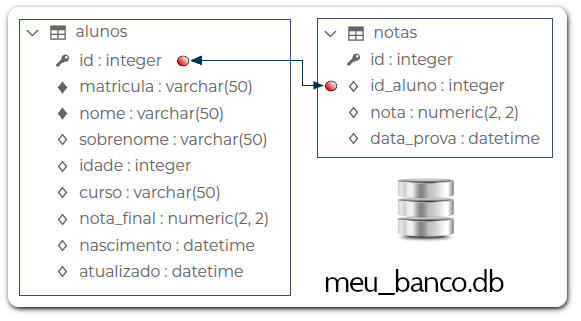






 Veja o artigo
Veja o artigo 















 O parâmetro request recebe os dados inseridos na requisição. Se um formulário foi preenchido e enviado o método de requisição foi POST. Um objeto form é carregado com esses dados. Se os dados estão inseridos corretamente eles são gravados. Se não for válida (se algum campo necessário não foi preenchido, ou um email está em formato incorreto, por ex.) um formulário vazio é reexibido.
O parâmetro request recebe os dados inseridos na requisição. Se um formulário foi preenchido e enviado o método de requisição foi POST. Um objeto form é carregado com esses dados. Se os dados estão inseridos corretamente eles são gravados. Se não for válida (se algum campo necessário não foi preenchido, ou um email está em formato incorreto, por ex.) um formulário vazio é reexibido.












