Vimos que uma base de um espaço vetorial \(V\) é um conjunto de vetores de \(V\) que são linearmente independentes que geram este espaço vetorial. Vimos ainda que, escolhida uma base \(\alpha = \{v_1, v_2, \ldots, v_n \}\) então todo vetor de \(V\) pode ser escrito de forma única como combinação linear dos vetores desta base, \(v = a_1 v_1 + a_2 v_2 + \ldots + a_n v_n\).
Em muitas situações pode ser interessante descrever um vetor, ou outro objeto formado por vetores, em mais de uma base, lembrando que, alterada a base alteram-se também os coeficientes do vetor naquela base. é possível, em muitos casos, que a descrição se torne muito simplificada com a escolha mais adequada da base a ser usada. Um exemplo ilustrará a importância desta operação de mudança de bases.
Exemplo: A relação \(x^2 + x y + y^2 – 3 = 0\) descreve uma elipse no plano, como está ilustrado na figura 1.
Figura 1: Rotação de eixos
Em um novo sistema de coordenadas \((x’, y’)\) obtido por rotação dos eixos de coordenadas de um ângulo de \(45^0\) antihorário. Por meio de uma mudança adequada de base, que pode ser vista como a introdução de um novo sistema de coordenadas, a mesma elipse fica expressa como \(3 x^{\prime 2} + 2 y^{\prime 2}\) =6, onde os sistemas \((x, y)\) e \((x’, y’)\) se relacionam de uma forma que ficará clara em breve.
Considere que em um dado espaço vetorial \(V\) temos duas bases, \(\beta = \{u_1, \ldots, u_n \}\) e \(\beta’ = \{w_1, \ldots, w_n \}\). Então, se \(v\) é um vetor deste espaço, podemos escrevê-lo nas duas bases, respectivamente como
$$ v = x_1 u_1 + \ldots + x_n u_n, $$
$$ v = y_1 w_1 + \ldots + y_n w_n. $$
Queremos relacionar os dois grupos de coordenadas
$$
[v]_{\beta} = \left[ \begin{array}{r}
x_1\\
\ldots\\
x_n
\end{array} \right], [v]_{\beta’} = \left[ \begin{array}{r}
y_1\\
\ldots\\
y_n
\end{array} \right] .
$$
é importante observar que \(v\) é um objeto geométrico, independente do sistema de coordenadas usado ou, o que é equivalente, independente da base usada para este espaço vetorial. A transformação pode ser conseguida da seguinte forma: cada um dos vetores da base \(\beta’\) pode ser escrito como combinação dos vetores da base \(\beta\), uma vez que também são vetores de \(V\), portanto
$$
\begin{array}{lr}
w_1 = & a_{11} u_1 + \ldots + a_{n 1} u_n,\\
w_2 = & a_{12} u_1 + \ldots + a_{n 2} u_n,\\
\vdots & \vdots\\
w_n = & a_{1 n} u_1 + \ldots + a_{n n} u_n .
\end{array}
$$
A escolha de índices das constantes \(a_{i j}\) acima ficará clara a seguir. Substituindo os vetores acima em \(v = y_1 w_1 + \ldots + y_n w_n\) temos
$$
\begin{array}{rll}
v = & y_1 (a_{11} u_1 + \ldots + a_{n 1} u_n) + & \ldots & + y_n (a_{1n} u_1 + \ldots + a_{n n} u_n) = \\
& (a_{11} y_1 + \ldots + a_{1 n} y_n) u_1 + & \ldots & + (a_{n 1} y_1+ \ldots + a_{n n} y_n) u_n .
\end{array}
$$
Na última linha foram colocados em evidência os vetores \(u_k\). Como podemos escrever \(v = x_1 u_1 + \ldots + x_n u_n\) (usando a base \(\beta\) ) e, lembrando que existe uma única combinação linear para descrever um vetor em cada base, podemos identificar os termos
$$ \begin{array}{r}
x_1 = a_{11} y_1 + \ldots + a_{1 n} y_n, \\
\vdots \\
x_n = a_{n 1} y_1 + \ldots + a_{n n} y_n,
\end{array} $$
que é exatamente a regra de transformação entre as coordenadas \(\{y_k \}\) na base \(\beta’\) para as coordenadas \(\{x_k \}\) na base \(\beta\). Podemos escrever a mesma expressão acima em forma matricial como
$$
\left[ \begin{array}{r}
x_1\\
\vdots\\
x_n
\end{array} \right] = \left[ \begin{array}{lll}
a_{11} & \ldots & a_{1 n}\\
\vdots & & \vdots\\
a_{n 1} & \ldots & a_{n n}
\end{array} \right] \left[ \begin{array}{r}
y_1\\
\vdots\\
y_n
\end{array} \right],
$$
onde se observa que a escolha dos índices, citada acima, leva a uma disposição natural dos elementos formadores da matriz de transformação. Denotaremos por
$$
I^{\beta’}_{\beta} = \left[ \begin{array}{rrr}
a_{11} & \ldots & a_{1 n}\\
\vdots & & \vdots\\
a_{n 1} & \ldots & a_{n \, n}
\end{array} \right]
$$
esta matriz, a chamada matriz mudança de base de \(\beta’\) para \(\beta\), onde os coeficientes \(a_{i j}\) são as coordenadas dos vetores \(w_k\) (os elementos do base \(\beta’\) ) na base \(\beta\). Com esta notação a transformação entre uma base e outra fica descrita por
$$ [v]_{\beta} = I^{\beta’}_{\beta} [v]_{\beta’}, $$
lembrando que os coeficientes de \(I^{\beta’}_{\beta} = \{a_{i j} \} \) são as coordenadas dos vetores da base \(\beta’\) \((w_j)\) desenvolvidos na base \(\beta = \{u_j \}\).
Repetindo de forma compacta: Considere que em um dado espaço vetorial \(V\) temos duas bases, \(\beta = \{u_i \}\) e \(\beta’ = \{w_j \}\). Se \(v \in V\), podemos escrevê-lo nas duas bases, como
$$ v = \sum_{i = 1}^n x_i u_i, \;\; \text{e} \;\; v = \sum_{j = 1}^n y_j w_j.$$
Queremos relacionar os dois conjuntos de coordenadas \(\{x_i \}\) e \(\{y_j \}\). Lembrando que cada um dos \(w_j \in V\) temos que
$$ w_i = \sum_{k = 1}^n a_{k i} u_k, i = 1, \ldots, n.$$
Substituindo na expressão para \(v\)
$$ v = \sum_{i = 1}^n y_i w_i = \sum_{i = 1}^n y_i \left( \sum_{k = 1}^n a_{k i} u_k \right) = $$
$$ = \sum_{k = 1}^n \left( \sum_{i = 1}^n a_{k i} y_i \right) u_k = \sum_{k = 1}^n x_k u_k.$$
Como os dois termos na expressão acima correspondem à decomposição do vetor \(v\) na base \(\beta\), e esta decomposição é única, podemos identificar
$$ x_k = \sum_{i = 1}^n a_{k i} y_i $$
ou seja
$$ [v]_{\beta} = I^{\beta’}_{\beta} [v]_{\beta’}, $$
onde os coeficientes de \(I^{\beta’}_{\beta} = \{a_{i j} \} \) são as coordenadas dos vetores da base \(\beta’\) \((w_j)\) desenvolvidos na base \(\beta
= \{u_j \}\).
Exemplo: Dadas duas bases de \(\mathbb{R}^2,\;\; \beta = \{(2, – 1), (3, 4)\}\) e \(\beta’ = \{(1, 0) (0, 1)\}\) procuramos a matriz \(I_{\beta}^{\beta’}\), a matriz de mudança de base de \(\beta’\) para \(\beta\). Primeiro encontramos a decomposição dos vetores de \(\beta’\) na base \(\beta\) (dos vetores da base de partida descritos na base de chegada):
$$
(1, 0) = a_{11} (2, – 1) + a_{21} (0, 1),
$$
$$
(0, 1) = a_{12} (2, – 1) + a_{22} (0, 1),
$$
o que nos leva a dois sistemas, e suas respectivas soluções
$$
\left\{ \begin{array}{r}
2 a_{11} + 3 a_{21} = 1\\
– a_{11} + 4 a_{21} = 0
\end{array} \Rightarrow \left\{ \begin{array}{r}
a_{11} = 4 / 11,\\
a_{21} = 1 / 11,
\end{array} \right. \right.
$$
Portanto, a matriz mudança de base de \(\beta’\) para \(\beta\) é
$$
I_{\beta}^{\beta’} = \left[ \begin{array}{rr}
4 / 11 & – 3 / 11\\
1 / 11 & 2 / 11
\end{array} \right] = \frac{1}{11} \left[ \begin{array}{rr}
4 & – 3\\
1 & 2
\end{array} \right] .
$$
Vamos prosseguir um pouco mais com este mesmo exemplo para compreender como se dá esta mudança de base. Dado o vetor \(v = (5, – 8)\) ele pode ser imediatamente escrito na base \(\beta’\) (que é a base canônica) como
$$
[v]_{\beta’} = \left[ \begin{array}{r}
5\\
– 8
\end{array} \right] .
$$
As coordenadas deste vetor na base \(\beta’\) são
$$
[v]_{\beta} = \frac{1}{11} \left[ \begin{array}{rr}
4 & – 3\\
1 & 2
\end{array} \right] \left[ \begin{array}{r}
5\\
– 8
\end{array} \right] = \left[ \begin{array}{r}
4\\
– 1
\end{array} \right] .
$$
Podemos verificar diretamente que isto está correto pois \((5, – 8) = 4 (2, – 1) – 1 (3, 4)\).
Além de converter um vetor de uma base para outra, é interessante conhecer um procedimento para obter a operação inversa, ou seja, retornar da base nova para a base antiga. Isto nos leva a considerar a inversa da matriz mudança de base.
Vimos que a mudança de base de \(\beta’\) para \(\beta\) pode ser realizada por meio da operação
$$
[v]_{\beta} = I^{\beta’}_{\beta} [v]_{\beta’} .
$$
Denotamos por \( [I^{\beta’}_{\beta}]^{- 1}\) a inversa da matriz acima, e multiplicando à esquerda temos
$$ [I^{\beta’}_{\beta}]^{- 1} [v]_{\beta} = [I^{\beta’}_{\beta}]^{- 1} I^{\beta’}_{\beta} [v]_{\beta’} = [v]_{\beta’}. $$
Isto significa que
$$ [v]_{\beta’} = I^{\beta}_{\beta’} [v]_{\beta} = [I^{\beta’}_{\beta}]^{- 1} [v]_{\beta}, $$
ou seja, a matriz \(I_{\beta’}^{\beta}\) (a mudança de base de \(\beta\) para \( \beta’\) ) é a inversa de \(I_{\beta}^{\beta’}\),
$$ I^{\beta}_{\beta’} = [I^{\beta’}_{\beta}]^{- 1}. $$
Exemplo: No exemplo anterior, vamos procurar a matriz mudança de base de \(\beta\) para \(\beta’\), onde \(\beta = \{(2, – 1), (3, 4)\}\) e \(\beta’ = \{(1, 0) (0, 1)\}\). Os vetores de \(\beta\) na base \(\beta’\) tem coordenadas
$$ (2, – 1) = 2 (1, 0) – 1 (0, 1), $$
$$ (3, 4) = 3 (1, 0) + 4 (0, 1), $$
Podemos verificar que esta é, de fato, a inversa de \(I_{\beta}^{\beta’}\) obtida acima, pois
$$
I_{\beta’}^{\beta} I_{\beta}^{\beta’} = \frac{1}{11} \left[
\begin{array}{rr}
2 & 3\\
– 1 & 4
\end{array} \right] \left[ \begin{array}{rr}
4 & – 3\\
1 & 2
\end{array} \right] = \left[ \begin{array}{rr}
1 & 0\\
0 & 1
\end{array} \right] .
$$
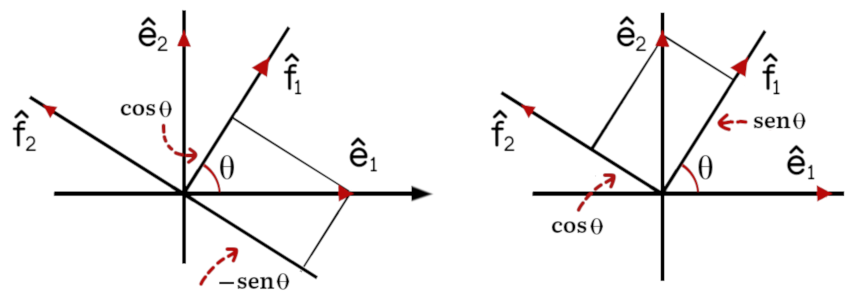
Exemplo: Uma mudança de base importante está associada a uma rotação dos eixos de coordenadas. Em \(\mathbb{R}^2\) considere que \(\beta = (\hat{e}_1, \hat{e}_2)\) é a base canônica e \(\beta’ = (\hat{f}_1, \hat{f}_2)\) a base obtida de \(\beta\) por meio de uma rotação antihorária de um ângulo \(\theta\), como indicado na figura 2.
Figura 2: Rotaçao dos Eixos
Analisando a figura podemos ver que
$$ \hat{e}_1 = \cos \theta \hat{f}_1 – \text{sen } \theta \hat{f}_2, $$
e, portanto, temos a matriz mudança de base,
$$
I_{\beta’}^{\beta} = \left[ \begin{array}{rr}
\cos \theta & \text{sen } \theta\\
– \text{sen } \theta & \cos \theta
\end{array} \right] .
$$
Se descrevermos um vetor (pode ser, por exemplo, uma posição) com relação ao sistema de eixos originais por meio de suas coordenadas usuais \((x, y)\) podemos obter as coordenadas \((x’, y’)\) no sistema após a rotação como
$$
\left[ \begin{array}{r}
x’\\
y’
\end{array} \right] = \left[ \begin{array}{rr}
\cos \theta & \text{sen } \theta\\
– \text{sen } \theta & \cos \theta
\end{array} \right] \left[ \begin{array}{r}
x\\
y
\end{array} \right] .
$$
Como um caso particular, se \(\theta = \pi / 3\) temos \(\text{sen } (\pi / 3) =\sqrt{3} / 2\) e \(\cos (\pi / 3) = 1 / 2\) e
$$
I_{\beta’}^{\beta} = \frac{1}{2} \left[ \begin{array}{rr}
1 & \sqrt{3}\\
– \sqrt{3} & 1
\end{array} \right] .
$$
e a matriz mudança de base \(\beta’ \rightarrow \beta\) é
$$
I_{\beta}^{\beta’} = \left[ \begin{array}{rr}
\cos \theta & – \text{sen } \theta\\
\text{sen } \theta & \cos \theta
\end{array} \right],
$$
que consiste na matriz de rotação de um ângulo de \(– \theta\) (ou \(\theta\), no sentido horário). Se fizermos uma rotação de um ângulo \(\theta\), seguida de uma rotação de ângulo \(– \theta\), voltaremos à posição original, equivalente a fazer uma rotação de ângulo nulo ou deixar inalterado o vetor a ser girado,
$$
\left[ \begin{array}{rr}
\cos \theta & – \text{sen } \theta \\
\text{sen } \theta & \cos \theta
\end{array} \right]
\left[ \begin{array}{rr}
\cos \theta & \text{sen } \theta\\
– \text{sen } \theta & \cos \theta
\end{array}\right] = \left[ \begin{array}{rr}
1 & 0\\
0 & 1
\end{array} \right].
$$
Definição: Sejam \(V\) um espaço vetorial, \(v_1, v_2, \ldots, v_n \in V\) (n vetores de \(V\) ) e \(a_1, a_2, \ldots, a_n \in \mathbb{R}\) (n escalares). Então
$$ v = a_1 v_1 + a_2 v_2 + \ldots + a_n v_n \in V $$
é uma combinação linear dos vetores \(v_1, v_2, \ldots, v_n\).
Definição: O conjunto \(W\) formado por todos os vetores que são combinações lineares de \(v_1, v_2, \ldots, v_n\) é chamado de subespaço gerado por estes vetores. Denotamos este subespaço por
$$
W = [v_1, v_2, \ldots, v_n] = \{ a_1 v_1 + a_2 v_2 + \ldots + a_n v_n ;\;\; a_i
\in \mathbb{R} \} .
$$
Exercício: Mostre que \(W\) é um subespaço vetorial de \(V\).
Quanto ao subespaço gerado por \(v_1, v_2, \ldots, v_n\) notamos que \(W = [v_1, v_2, \ldots, v_n]\) é o menor subespaço de \(V\) que contém todos os vetores \(v_1, v_2, \ldots, v_n\).
Reta gerada por um vetor
Exemplo: Se \(V =\mathbb{R}^3\) e \(\vec{v} \in \mathbb{R}^3\), \(\vec{v} \neq 0\) então \([\vec{v}] = \{\alpha \vec{v} ; \alpha \in \mathbb{R}\}\) é uma reta de \(\mathbb{R}^3\) passando pela origem.
Exemplo: Se denotarmos por \(\hat{\imath},\; \hat{\jmath},\; \hat{k} \) os três vetores unitários (de módulo unitário), na direção dos eixos \(O x,\; O y\) e \(O z\) então
$$[\hat{\imath}, \hat{\jmath}] \;\; \text{é o plano} \;\; x O y,$$
$$[\hat{\imath}, \hat{\jmath}, \hat{k}] =\mathbb{R}^3.$$
Exemplo: Tomando dois vetores não colineares \(\vec{u}, \vec{v} \in \mathbb{R}^3\) então \([\vec{u}, \vec{v}]\) é o plano pela origem que contém \(\vec{u}\) e \(\vec{v}\). Uma observação importante, que será mais elaborada a seguir, é a seguinte: qualquer outro vetor neste plano, por definição, é uma combinação linear de \(\vec{u}\) e \(\vec{v}\).
Exemplo: Dados \(v_1, v_2 \in M (2, 2)\) abaixo
$$
v_1 = \left[ \begin{array}{rr}
1 & 0\\
0 & 0
\end{array} \right], \;\; v_2 = \left[ \begin{array}{rr}
0 & 1\\
0 & 0
\end{array} \right]
$$
então o espaço gerado por eles é
$$ \left[ v_1, v_2 \right] = \left\{ \left[ \begin{array}{rr} a & b\\ 0 & 0 \end{array} \right];\;\; a, b \in \mathbb{R} \right\},$$
um subespaço vetorial de \(M (2, 2)\).
Dependência e Independência Linear
Em muitas situações é importante saber se um vetor é ou não uma combinação linear de outros vetores dados. Como foi mencionado acima, se \(\vec{w}\) é combinação linear de \(\vec{u}\) e \(\vec{v}\) podemos escrever (e é importante que o leitor compreenda esta afirmação),
$$ \vec{w} \in [\vec{u}, \vec{v}] \Rightarrow [\vec{u}, \vec{v}, \vec{w}] = [\vec{u}, \vec{v}].$$
Exercício: Mostre que a afirmação acima está correta.
Alternativamente, queremos saber se, em \(n\) vetores, \(v_1, v_2, \ldots, v_n\), alguns deles são combinações lineares dos demais.
Definição: Sejam \(V\) um espaço vetorial e \(v_1, v_2, \ldots, v_n\) vetores de \(V\). Dizemos que o conjunto \(\{v_1, v_2, \ldots, v_n \}\) é linearmente independente (abreviado por l.i.) se a expressão
$$ a_1 v_1 + a_2 v_2 + \ldots + a_n v_n = 0 $$
implica necessariamente que todas as constantes são nulas: \(a_1 = 0, a_2 = 0, \ldots, a_n = 0\). Caso contrário, se existe alguma outra forma de se obter o anulamento sem que todos os \(a_i\) sejam nulos, dizemos que os vetores são linearmente dependentes. Alternativamente temos o teorema abaixo:
Teorema: O conjunto \(\{v_1, v_2, \ldots, v_n \}\) é linarmente dependente se, e somente se, um, ou mais, dos vetores é combinação linear dos demais.
Demonstração: \(\Rightarrow)\) Supondo \(\{v_1, v_2, \ldots, v_n \}\) l.d. temos que a expressão (*) pode ser obtida com algum dos coeficientes não nulos. Tome \(a_j \neq 0\). Neste caso
$$ – a_j v_j = a_1 v_1 + \ldots + a_n v_n \Rightarrow v_j =-\frac{a_1}{a_j} v_1 – \ldots – \frac{a_n}{a_j} v_n, $$
o que mostra que \(v_j\) é uma combinação linear dos demais.
\( \Leftarrow)\) Por outro lado, se \(v_j\) é uma combinação linear dos demais, podemos escrever
$$ v_j = b_1 v_1 + \ldots + b_n v_n \Rightarrow b_1 v_1 + \ldots – v_j + \ldots + b_n v_n = 0, $$
que é uma combinação linear nula dos vetores com \(b_j = – 1\), portanto não nulo. Dai se conclui que \(\{v_1, v_2, \ldots, v_n \}\) é l.d..
Resumindo estes resultados, dizemos o conjunto \(\{v_i \}\) é l.i. se nenhum de seus vetores é uma combinação linear dos demais.
Exemplo: Se \(V =\mathbb{R}^3, \overrightarrow{v_1}\), \(\overrightarrow{v_2} \in V\). Então \(\{ \overrightarrow{v_1} \text{, } \overrightarrow{v_2} \}\) é l.d. \(\Leftrightarrow \overrightarrow{v_1} = \alpha \overrightarrow{v_2}\), onde \(\alpha\) é um escalar. Iso significa que dois vetores do espaço só podem ser l.d. se forem colineares. Três vetores de \(\mathbb{R}^3\) somente serão l.d. se estiverem sobre o mesmo plano. Quatro ou mais vetores de \(\mathbb{R}^3\) são necessariamente l.d., uma vez que existem apenas três direções independentes no espaço.
Exemplo: Em \(\mathbb{R}^2\) os vetores \(\hat{\imath} = (1, 0)\) e \(\hat{\jmath} = (0, 1)\) são l.i. pois
$$ a \hat{\imath} + b \hat{\jmath} = 0 \Rightarrow (a, b) = 0 \Rightarrow a = 0, b = 0.$$
Igualmente, os vetores \(\hat{\imath} = (1, 0, 0)\), \(\hat{\jmath} = (0, 1, 0)\) e \(\hat{k} = (0, 0, 1)\) em \(\mathbb{R}^3\) são l.i..
Base de um espaço vetorial
Dado \(V\), um espaço vetorial, procuramos por um conjunto mínimo de vetores \(\beta = \{v_1, \ldots, v_n \}\) tal que qualquer um dos vetores de \(V\) seja uma combinação linear dos vetores em \(\beta\). Neste caso temos que \(V = \{a_1 v_1 + \ldots + a_n v_n ; a_i \in \mathbb{R}\}\) ou seja \(V = [v_1, \ldots, v_n]\) (\(V\) é gerado pelos vetores de \(\beta\)).
Definição: Um conjunto \(\beta = \{v_1, \ldots, v_n \}\) é uma base do espaço vetorial \(V\) se:
\(\{v_1, \ldots, v_n \}\) é l.i.,
\(V = [v_1, \ldots, v_n]\).
Base de R³
Exemplo: (\( \hat{\imath}, \hat{\jmath}\) ) é uma base de \(\mathbb{R}^2\). (\( \hat{\imath}, \hat{\jmath}, \hat{k}\) ) é uma base de \(\mathbb{R}^3\). Estas são as chamadas bases canônicas de cada um destes espaços. Deve estar claro que nos dois casos o significado de cada um destes vetores é diferente. Por exemplo, em \(\mathbb{R}^3\), \(\hat{\imath} = (1, 0, 0)\); em \(\mathbb{R}^2\) temos que \(\hat{\imath} = (1, 0)\).
Exemplo: \(\{(1, 1), (0, 1)\}\) é uma base de \(\mathbb{R}^2\). Para mostrar isto devemos verificar as duas condições da definição. (i) O conjunto é l.i. pois a expressão
$$ a (1, 1) + b (0, 1) = 0 $$
só pode ser satisfeita se
$$ (a, a + b) = 0 \Rightarrow a = 0, b = 0. $$
(ii) Além disto o conjunto gera \(\mathbb{R}^2\), pois qualquer vetor \(\vec{v} = (\alpha, \beta) \in \mathbb{R}^2\) pode ser escrito como combinação linear destes vetores
$$
(\alpha, \beta) = a (1, 1) + b (0, 1) \Rightarrow
\left\{ \begin{array}{r} a = \alpha, \\ b = \beta – \alpha. \end{array} \right.
$$
Dizemos também que, nesta base, o vetor \(\vec{v} = (\alpha, \beta)\) tem componentes \(\alpha\) e \(\beta – \alpha\), ou seja
$$ (\alpha, \beta) = \alpha (1, 1) + (\beta – \alpha) (0, 1). $$
Exemplo: \(\{(0, 1), (0, 2)\}\) não é uma base de \(\mathbb{R}^2\) pois os vetores não são l.i. e nem geram o plano.
Exemplo: \(\{(1, 0, 0), (0, 1, 0)\}\) não é uma base de \(\mathbb{R}^3\). Estes vetores são l.i. mas não geram \(\mathbb{R}^3\), ou seja, a condição (ii) não é satisfeita.
Exemplo: O conjunto de matrizes
$$
\left\{
\left[\begin{array}{rr} 1 & 0 \\ 0 & 0\end{array} \right],
\left[\begin{array}{rr} 0 & 1 \\ 0 & 0 \end{array} \right],
\left[\begin{array}{rr} 0 & 0 \\ 1 & 0 \end{array} \right],
\left[\begin{array}{rr} 0 & 0\\ 0 & 1\end{array} \right]
\right\}
$$
é uma base de \(M (2, 2)\).
Exemplo: Considerando \(P_n (t)\) o conjunto dos polinômios em \(t\) de grau menor ou igual a \(n\) temos que o conjunto
$$
\{ 1, t, t^2, \ldots, t^n \}
$$
é uma de suas bases. O conjunto é l.i. e todo elemento do espaço vetorial \(P_n (t)\) é uma combinação linear destes vetores,
$$
u \in P_n (t) \Rightarrow u = a_0 + a_1 t + a_2 t^2 + \ldots + a_n t^n,
$$
onde os termos \(a_i\) são escalares. É importante observar que o vetor \(1\) é o polinômio de grau zero, sem o qual o conjunto acima não geraria \(P_n (t)\).
Observação: Dizemos que o conjunto \(\beta = \{v_1, \ldots, v_n \}\) é linearmente independente (l.i.) ou que os vetores \(v_1, \ldots, v_n\) são linearmente independentes. Igualmente dizemos que o conjunto \(\beta\) gera um espaço, ou que seus vetores, \(v_1, \ldots, v_n\), geram este espaço.
Teorema: Sejam \(V\) um espaço vetorial e \(v_1, \ldots, v_n\) vetores deste espaço. Se o conjunto \(\{v_1, \ldots, v_n \}\) gera este espaço vetorial então é possível extrair deles uma base para \(V\).
Demonstração: Se o conjunto \(\beta = \{v_1, \ldots, v_n \}\) é l.i. então \(\beta\) já é uma base de \(V\). Caso contrário é possível encontrar constantes \(a_i\) tal que \(a_1 v_1 + a_2 v_2 + \ldots + a_n v_n = 0\) com alguma destas constantes não nula. Suponha que \(a_k\) seja uma destas constantes não nula, \(a_k \neq 0\). O vetor \(v_k\) correspondente é
$$ v_k=-\frac{a_1}{a_k} v_1 – \ldots – \frac{a_n}{a_k} v_n,$$
uma combinação linear dos demais. Retiramos este vetor do conjunto e repetimos o processo de verificação até restarem \(r\) (\( r \lt n\)) vetores l.i. que geram \(V\). Estes vetores restantes formam uma base de \(V\).
Observação: Para fixar este conceito note que, no conjunto \(\{v_1, \ldots, v_r, u_1, \ldots, u_{n – r} \}\), se os vetores \(u_k \) forem combinação linear dos vetores \(v_i\) então
$$ [v_1, \ldots, v_r, u_1, \ldots, u_{n – r}] = [v_1, \ldots, v_r]. $$
Resta ainda notar que a escolha dos vetores restantes não é única e, portanto, não existe uma única base para um espaço vetorial.
Teorema: Seja \(V\) o espaço vetorial gerado por \(v_1, v_2, \ldots, v_n\). Então, qualquer conjunto com mais de \(n\) vetores de \(V\) é l.d..
Demonstração: Suponha que existam \(r\) vetores l.i. em entre os vetores \(v_1, v_2, \ldots, v_n\). Então temos que \(V = [v_1, v_2, \ldots, v_r], r \leq n\), onde os vetores podem ter sido renomeados de modo a tornar os \(r\) primeiros vetores l.i.. Tome um conjunto com \(m\) elementos \(\{w_1, w_2, \ldots, w_m; \;\; w_i \in V\}\), cada um deles uma combinação linear dos vetores da base,
$$ w_k \in V \Rightarrow w_k = \sum_{i = 1}^r a_{k i} v_i . $$
Para testar a independência linear (ou não) destes vetores fazemos, como de costume,
$$ 0 = \sum_{k = 1}^m x_k w_k = \sum_{k = 1}^m x_k \left( \sum_{i=1}^r a_{k i} v_i \right) = $$
e procuramos descobrir se existem soluções onde os coeficientes \(x_k\) sejam não nulos. Se existirem, estes vetores são l.d.. Na primeira linha os vetores \(w_k\) foram substituídos por sua decomposição na base \(\beta\). Na segunda os somatórios foram realizados em ordem invertida, o que é possível uma vez que estamos lidando com somas finitas. Retomando, como na última expressão os vetores \(v_i\) são l.i., decorre que os termos entre parênteses devem ser nulo para cada \(i =1, \ldots, r\),
$$ \sum_{k = 1}^m x_k a_{k i} = 0, $$
o que representa \(r\) equações com \(m\) incógnitas \(x_k\) onde \(r \leq n \lt m\) (um número de incógnitas maior que o número de equações no sistema linear). Logo existem soluções não triviais para o sistema, \(x_k \neq 0\) para algum \(k\), de onde concluimos que conjunto \(\{w_k\}\) de \(m\) vetores é l.d..
Definição: A dimensão de um espaço vetorial \(V\), que denotaremos por \(\dim V\), é igual ao número de vetores de uma de suas bases.
Exemplo: \(\dim \mathbb{R}^3 = 3, \dim \mathbb{R}^n = n\). Em \(\mathbb{R}^n\) a base formada pelos \(n\) vetores \(\{\hat{\text{e}}_i\}\) dados por
$$
\hat{\text{e}}_1 = (1, 0, \ldots, 0), \hat{\text{e}}_2 = (0, 1, \ldots, 0), \hat{\text{e}}_n = (0, 0, \ldots, 1),
$$
é denominada base canônica. Esta é uma base ortonormal, ou seja, todos os vetores são perpendicalares entre si (ortogonais) e todos são unitários ou normalizados, possuem módulo igual a 1. Em outros termos,
vale o produto interno ou escalar $$
\hat{\text{e}}_i \cdot \hat{\text{e}}_j = \delta_{i j.}
$$
Exemplo: \(\dim M (2, 2) = 4, \dim M (m, n) = m \times n\).
Exemplo: \(\dim P_n (t) = n + 1\).
Consulte os exemplos dados anteriormente para confirmar estas afirmações.
Teorema: Se \(V\) é um espaço vetorial, qualquer conjunto \(\beta = \{v_1, \ldots, v_r;\;\; v_i \in V\}\), de vetores l.i., pode ser completado para formar uma base de \(V\).
Demonstração: Se \([v_1, \ldots, v_r] = V\) então \(\beta\) já é uma base de \(V\). Caso contrário procuramos um vetor \(v_{r + 1} \not\in [v_1, \ldots, v_r]\) e reiniciamos o procedimento de verificação até que tenhamos \(n\) vetores l.i. de forma que \([v_1, \ldots, v_n] = V\).
Corolário: Se a dimensão de um espaço vetorial \(V\) é \(\dim V = n\), então qualquer conjunto de \(n\) vetores l.i. deste espaço é uma base de \(V\).
Teorema: Se \(U\) e \(W\) são dois subespaços vetoriais do espaço vetorial \(V\), de dimensão finita, então \(\dim U \leq \dim V, \;\; \dim W \leq \dim V\). Além disto
$$\dim (U + W) = \dim U + \dim W – \dim (U \cap W).$$
Demonstração: A demonstração é deixada como um exercício.
Teorema: Dada uma base \(\beta\) do espaço vetorial \(V\), então cada vetor \(v \in V\) é escrito de maneira única como combinação linear dos vetores desta base.
Demonstração: Se \(\beta = \{v_1, \ldots, v_n \}\) é esta base e \(v\) um vetor deste espaço, então
$$ v = a_1 v_1 + \ldots + a_n v_n = \sum a_i v_i, $$
pois \(V = [v_1, \ldots, v_n]\). Suponha que seja possível escrever de outra forma esta mesma combinação linear, \(v = \sum b_i v_i\). Neste caso
$$ 0 = v – v = \sum a_i v_i – \sum b_i v_i = \sum (a_i – b_i) v_i .$$
Como \(\beta\) é um conjunto de vetores l.i. se conclui que \(a_i = b_i\), para \(i = 1, \ldots, n\).
Definição: Dada uma base \(\beta = \{v_1, \ldots, v_n \}\) do espaço vetorial \(V\), os coeficientes \(a_i\) da expansão \(v = a_1 v_1 + \ldots + a_n v_n = \sum a_i v_i\) são chamados de coordenadas do vetor \(v\) na base \(\beta\). Usaremos a seguinte notação:
$$
[v]_{\beta} = \left[ \begin{array}{r}
a_1\\
a_2\\
\cdots\\
a_n
\end{array} \right].
$$
Exemplo: Seja \(V =\mathbb{R}^2\), \(\beta = \{(1, 0), (0, 1)\}\) e \(\beta’ = \{(1, 1), (0, 1)\}\) duas de suas bases. O vetor \(\vec{v} = (4, 3)\) é
escrito, na base canônica, como
$$ \left[\vec{v}\right]_{\beta} = \left[ \begin{array}{r} 4 \\ 3 \end{array} \right].$$
Na base \(\beta’\) temos \((4, 3) = a (1, 1) + b (0, 1) = 4 (1, 1) + (- 1) (0, 1)\). Portanto
$$ [\vec{v}]_{\beta’} = \left[ \begin{array}{r} 4\\ – 1 \end{array} \right]. $$
Na tentativa de descrever rigorosamente os objetos e fenômenos da natureza alguns deles podem ser descritos com um número simples, um escalar, enquanto outros necessitam de uma complexidade adicional, sendo descritos por meio de vetores. Existem ainda objetos de maior comlexidade, os tensores que não são objetos de tratamento deste texto. Vale apenas mencionar que vetores são casos especiais de tensores, enquanto escalares são casos especiais de vetores.
Faremos uma breve revisão de vetores do plano (que denotaremos por \(\mathbb{R}^2\) ) e do espaço (que denotaremos por \(\mathbb{R}^3\) ).
Exemplo: Deslocamentos no espaço são exemplos típicos de vetores. Suponha que uma partícula se desloca do ponto \((1, 2, 1)\) até o ponto \((3, 3, 3)\) . O deslocamento é um vetor
$$
\vec{d} = (3, 3, 3) – (1, 2, 1) = (2, 1, 2) .
$$
Como veremos também as posições inicial e final, que são pontos de \(\mathbb{R}^3\) , são vetores. Representaremos os vetores por uma seta superscrita, como em \(\vec{d}\) , ou em negrito, como \(\mathbb{d}\) , dependendo da conveniência da notação em cada situação.
Exemplo: Podemos descrever a temperatura de pontos em uma sala por meio de um escalar, \(T (x, y, z)\) . A temperatura varia com o ponto onde é avaliada mas, escolhido o ponto, ela pode ser inteiramente dada por meio de um único número. Este é um exemplo de um campo escalar.
Outros exemplos de vetores na física e na matemática são: força, momento, velocidade, vetores tangentes à uma curva, normais a superfícies. Temperatura, intervalos de tempo, comprimentos e número de indivíduos em uma população são exemplos de quantidades escalares.
Definição: Um vetor de \(\mathbb{R}^2\) (do plano) é uma dupla ordenada que pode ser representada por uma matriz linha ou coluna,
$$
\vec{u} = (a, b) \;\; \text{ou} \;\; \vec{v} = \left[ \begin{array}{l} a\\ b\end{array} \right] .
$$
Um vetor do espaço, \(\mathbb{R}^3\) , é uma tripla ordenada que pode ser representada igualmente das duas maneiras acima. Não existe nenhuma razão para nos limitarmos a três dimensões e o formalismo matemático para isto não acrescenta grandes dificuldades adicionais.
Definição: Um vetor de \(\mathbb{R}^n\) é uma \(n\)-upla ordenada que pode ser representada por uma matriz linha ou coluna,
$$
\vec{u} = (x_1, x_2, \ldots, x_n) \text{ou} \vec{v} = \left[
\begin{array}{l}
x_1\\
x_2\\
\vdots\\
x_n
\end{array} \right] .
$$
Observe que existe uma correspondência biunívoca entre pontos e vetores de \(\mathbb{R}^n\) e por isto identificamos os dois conceitos.
Figura
Alguns exemplos de uso do \(\mathbb{R}^n\) .
A posição de uma partícula pode ser completamente dada por meio de suas coordenadas cartesianas, \(\vec{r} = (x, y, z)\) . Se esta partícula se move cada um das coordenadas é uma função do tempo, \(\vec{r} (t) = (x (t), y (t), z (t))\) e sua velocidade é a derivada primeira deste vetor em relação ao tempo, \(\vec{v} (t) = (\dot{x} (t), \dot{y} (t), \dot{z} (t))\) onde o ponto sobrescrito representa derivação em relação à variável livre, \(t\) . Todos estes são vetores de \(\mathbb{R}^{3.}\)
A posição de uma barra fina no espaço pode ser dada por meio das coordenadas cartesianas de cada uma de suas pontas, \(A = (a_1, a_2,
a_3), B = (b_1, b_2, b_3)\) . A posição da barra pode ser descrita pelo vetor \(X = (a_1, a_2, a_3, b_1, b_2, b_3),\) um vetor do \(\mathbb{R}^6\) .
A posição de \(n\) partículas no espaço pode ser dada por meio de \(3 n\) coordenadas, \(\vec{X} = (x_{11}, x_{12}, x_{13}, \ldots, x_{n 1}, x_{n 2}, x_{n 3})\) , um vetor do \(\mathbb{R}^{3 n}\) . Aqui foi adotada a convenção: \(x_{k 1}\) é a coordenada \(x\) da \(k\)-ésima partícula, e assim por adiante. Em muitas situações é necessário descrever os momentos das partículas, além de suas posições. O chamado espaço de fase é um espaço de \(6 n\) dimensões, \(\mathbb{R}^{6 n}\) , onde cada ponto contém a informação sobre a posição e o momento de todas as partículas do sistema.
Operações entre vetores
As seguintes operações podem ser definidas com vetores e entre vetores.
Multiplicação por escalar: Se \(\alpha \in \mathbb{R}\) e \(\vec{v} \in \mathbb{R}^3 \) definimos a multiplicação por escalar
$$ \alpha \vec{v} = \alpha (x_1, x_2, x_3) = (\alpha x_1, \alpha x_2, \alpha x_3). $$
se \(\theta\) é o ângulo entre \(\vec{u}\) e \(\vec{v}\) então
$$\vec{u} \cdot \vec{v} = \left| \vec{u} \right| \left| \vec{v} \right| \cos \theta, $$
onde \(\left| \vec{u} \right| = \sqrt{u_1^2 + \ldots + u_n^2 } = \sqrt{\sum u_i^2 }\) é o módulo (o comprimento) do vetor. Observe ainda que, com estas definições
$$ \left| \vec{u} \right| = \sqrt{\vec{u} \cdot \vec{u} } .
$$
Os vetores do \(\mathbb{R}^n\) , dotados das operações descritas, satisfazem as seguintes propriedades:
\((\vec{u} + \vec{v}) + \vec{w} = \vec{u} + (\vec{v} + \vec{w})\) , (a adição é associativa);
\(\vec{u} + \vec{v} = \vec{v} + \vec{u},\) (a adição é comutativa);
\(\exists \vec{0} \in \mathbb{R}^n\) tal que \(\vec{u} + \vec{0} = \vec{u}\) , (existência do elemento neutro da adição);
\(\exists – \vec{v} \in \mathbb{R}^n\) tal que \(\vec{v} + (- \vec{v}) = \vec{0}, \forall \vec{v}\) , (existência do elemento inverso da adição);
Muitos outros conjuntos partilham destas mesmas propriedades, o que motiva a definição de espaço vetorial, dada a seguir.
Espaços vetoriais
Definição: Um conjunto \(V\) não vazio, dotado de duas operações: soma, \(V \times V \rightarrow V\) , e multiplicação por escalar, \(\mathbb{R} \times V \rightarrow V\) , satisfazendo as condições acima (de i até viii) é denominado um espaço vetorial.
Vamos apresentar uma definição posta em outros termos, buscando clarificar este conceito:
Definição: Um espaço vetorial é um conjunto \(V \neq \emptyset\), dotado de duas operações \(\oplus\) e \(\odot\) , satisfazendo as seguintes propriedades:
Se \(u,\, v \in V\) então \(u \oplus v \in V\) , (\( V\) é fechado sob a operação \(\oplus\));
\(u \oplus v = v \oplus u \forall u, v \in V,\;\; V\) é comutativo em relação à operação \(\oplus\) );
\(u \oplus (v \oplus w) = (v \oplus u) \oplus w, \forall u, v, w \in V\) , (associatividade);
Existe um único elemento \(0 \in V\) tal que \(0 \oplus u = u \oplus 0 = u, \forall u \in V\) ;
Para cada \(\forall u \in V\) existe um único elemento \( – u \in V\) tal que \(u \oplus (- u) = 0\) ;
Se \(u \in V\) e \(\alpha \in \mathbb{R}\) então \(\alpha \odot v \in V\) ;
\(\alpha \odot (u \oplus v) = \alpha \odot v \oplus \alpha \odot u\) ;
\((\alpha + \beta) \odot u = \alpha \odot u + \beta \odot u\) ;
Observe que o primeiro grupo de propriedades se refere à operação \(\oplus\) enquanto o segundo se refere à operação \(\odot\) . No caso de \(V =\mathbb{R}^n\) a operação \(\oplus\) se refere à adição de vetores, enquanto a operação \(\odot\) se refere à multiplicação por um escalar. Para outros exemplos de espaços vetoriais estas operações podem ser totalmente diferentes destas, como veremos. No presente texto consideraremos em quase todos os casos que a multiplicação por escalar é feita com um número real mas ela pode, igualmente, ser realizada com complexos. Os elementos de \(V\) são chamados de vetores e nem sempre são designados por meio de setas sobrescritas ou letras em negrito, como é costume fazer para os vetores de \(\mathbb{R}^3\) . Estes vetores, algumas vezes, guardam semelhança muito remota com os familiares vetores de deslocamento no plano ou no espaço.
Exemplo: \(V =\mathbb{R}^n\) é um espaço vetorial. Embora isto seja verdadeiro por definição, uma vez que as propriedades satisfeitas por estes espaços tenham sido exatamente motivadas pelas propriedades de \(\mathbb{R}^n\) , vamos mostrar isto como um exercício.
\( V =\mathbb{R}^n = \{(x_1, x_2, \ldots, x_n) ; x_i \in \mathbb{R}\}\).
Tome \(u, v \in V, u = (x_1, x_2, \ldots, x_n) \) e \(v = (y_1, y_2, \ldots, y_n)\) .
Então
$$
u + v = (x_1, x_2, \ldots, x_n) + (y_1, y_2, \ldots, y_n) = (x_1 + y_1, x_2
+ y_2, \ldots, x_n + y_n) \in V,
$$
o que verifica a propriedade (i). O elemento neutro da soma e o inverso são, respectivamente
$$
0 = (0, 0, \ldots, 0),\;\; u = (- x_1, – x_2, \ldots, – x_n) .
$$
Se \(\alpha\) é um escalar então
$$
\alpha u = \alpha (x_1, x_2, \ldots, x_n) = (\alpha x_1, \alpha x_2, \ldots, \alpha x_n) \in V,
$$
o que mostra a propriedade (ii). As demais subpropriedades não mostradas aqui serão deixadas como exercícios.
Exemplo: Denote por \(M(2,2)\) o espaço das matrizes \(2 \times 2\) , sendo \(\oplus\) a soma de matrizes e \(\odot\) a multiplicação de uma matriz por um escalar,
$$
V = M (2, 2) = \left\{ \left[ \begin{array}{ll}
a & b\\
c & d
\end{array} \right];\;\; a, b, c, d \in \mathbb{R} \right\} \text{.}
$$
Dois vetores deste espaço são
$$
u = \left[ \begin{array}{ll}
a & b\\
c & d
\end{array} \right];\;\; v = \left[ \begin{array}{ll}
e & f\\
g & h
\end{array} \right] .
$$
A soma destes vetores é um novo elemento de \(V\) ,
$$
u + v = \left[ \begin{array}{ll}
a & b\\
c & d
\end{array} \right] + \left[ \begin{array}{ll}
e & f\\
g & h
\end{array} \right] = \left[ \begin{array}{ll}
a + e & b + f\\
c + g & d + h
\end{array} \right] \in V,
$$
e, se \(\alpha\) é um escalar, então
$$
\alpha u = \alpha \left[ \begin{array}{ll}
a & b\\
c & d
\end{array} \right] = \left[ \begin{array}{ll}
\alpha a & \alpha b\\
\alpha c & \alpha d
\end{array} \right] \in V,
$$
o que mostra que as propriedades (i) e (ii) são satisfeitas. O vetor nulo e o oposto de u são, respectivamente,
$$
\tilde{0} = \left[ \begin{array}{ll}
0 & 0\\
0 & 0
\end{array} \right], \;\;\; – u = \left[ \begin{array}{ll}
– a & – b\\
– c & – d
\end{array} \right] .
$$
Pelo mesmo procedimento se pode mostrar que \(M (m, n)\) , o espaço das matrizes \(m \times n\) , é um espaço vetorial.
Exemplo: Considere \(P_n\) o conjunto dos polinômios de grau menor ou igual a \(n, \oplus\) a soma de polinômios e \(\odot\) a multiplicação de um polinômio por um escalar. Então
$$ V = P_n = \{ a_0 + a_1 x + \ldots + a_n x^n ;\;\; a_i \in \mathbb{R} \} $$
é um espaço vetorial. Para ver isto tomamos dois elementos de \(P_n\) ,
$$
u = a_0 + a_1 x + \ldots + a_n x^n ; v = b_0 + b_1 x + \ldots + b_n x^n
$$
e encontramos sua soma
$$ u + v = (a_0 + a_1 x + \ldots + a_n x^n) + (b_0 + b_1 x + \ldots + b_n x^n) = $$
$$ (a_0 + b_0) + (a_1 + b_1) x + \ldots + (a_n + b_n) x^n $$
que é, também um elemento de \(P_n\) . A multiplicação de um polinômio por um escalar é
$$ \alpha u = \alpha (a_0 + a_1 x + \ldots + a_n x^n) = (\alpha a_0 + \alpha a_1 x + \ldots + \alpha a_n x^n) $$
que, novamente, é um elemento de \(P_n\) . O elemento nulo da soma é 0 (o polinômio com todos os \(a_i = 0\)) e o elemento oposto à \(u\) é \(– u = – a_0 – a_1 x – \ldots – a_n x^n\).
Para que um conjunto, escolhidas as duas operações particulares, seja um espaço vetorial é necessário que satisfaça todas as condições listadas na definição. Esta é uma característica especial, não satisfeita por grande número de conjuntos. Com frequência o espaço que se deseja testar é subconjunto de um conjunto previamente conhecido como sendo um espaço vetorial. Isto nos leva à consideração dos subespaços vetoriais.
Subespaços Vetoriais
Observe que uma reta de \(\mathbb{R}^2\) passando pela origem é um espaço vetorial. Denotando por \(W\) esta reta $$
W = \{ \vec{v} \in \mathbb{R}^2 ; \vec{v} = \alpha \vec{u} \}
$$
e notando que esta é a reta composta por todos os vetores do plano na direção de \(\vec{u}\) (dizemos que ela é gerada por \(\vec{u}\) ), verificamos que se \(\vec{v}\) , \(\vec{w} \in W\) então \(\vec{v} + \vec{w} \in W\) e \(a \vec{v} \in W\) , onde \(a\) é um escalar qualquer.
No entanto, se \(W’\) for outra reta qualquer que não passe pela origem este não seria um espaço vetorial. Para concluir isto basta notar que, se \(\vec{v} \in W’\) , \(\vec{v} – \vec{v} = \vec{0}\) , que não está em \(W’\) .
Definição: Dado um espaço vetorial \(V\) , um subconjunto não vazio \(W\) de \(V\) é um subespaço vetorial de \(V\) se
Se \(u, v \in W \Rightarrow u + v \in W\) ,
Se \(u \in W\) e \(\alpha \in \mathbb{R} \Rightarrow \alpha u \in
W\) .
Resumidamente um subespaço vetorial é um subconjunto de um espaço vetorial que é, também, um espaço vetorial. As subpropriedades da definição de espaço vetorial estão garantidas pelo fato de ser \(V\) um espaço vetorial. Basta, portanto, testar as propriedades (i) e (ii). Vale observar que
todo subespaço vetorial \(W\) deve conter o vetor nulo (o elemento neutro da soma) pois, se \(v \in W\) , então \(v – v = 0\) também deve estar em \(W\) ;
todo espaço vetorial \(V\) admite pelo menos dois subespaços vetoriais: \(\{ 0 \}\) e \(V\) . Estes são os chamados subespaços vetoriais triviais.
Exemplo: Se \(V =\mathbb{R}^3\) então \(W \subset V\) , onde \(W\) é um plano qualquer passando pela origem, é um subespaço vetorial de \(V\) .
imagem
Exemplo: Tome \(V =\mathbb{R}^5\) e \(W = \{ (0, x_2, x_3, x_4, x_5) ; \;\; x_i \in \mathbb{R} \}\) . Então \(W \subset V\) e
\(u = (0, x_2, x_3, x_4, x_5), v = (0, y_2, y_3, y_4, y_5), u, v \in W\) então \(u + v = (0, x_2 + y_2, x_3 + y_3, x_4 + y_4, x_5 + y_5) \in W\) ;
Se \(k \in \mathbb{R}\) então \(k u = (0, k x_2, k x_3, k x_4, k x_5) \in W\) .
Logo \(W\) é subespaço vetorial de \(V\) .
Exemplo: Se \(V = M (m, n)\) e \(W\) o conjunto das matrizes triangulares superiores (onde apenas elementos acima da diagonal principal são não nulos) então \(W\) é subespaço vetorial de \(V\) .
Exemplo: Sejam \(V = M (n, n)\) e \(W\) o subconjunto das matrizes \(n \times n\) com \(a_{11} \lt 0\) . Então \(W\) não é um subconjunto vetorial de \(V\).
Exemplo: Um sistema de equações lineares homogêneo é um sistema com a matriz dos termos constantes nula, na forma de \(A \vec{X} = 0\) . Considere, por exemplo, o seguinte sistema homogêneo
$$
\begin{array}{l}
2 x + 4 y + z = 0\\
x + y + 2 z = 0\\
x + 3 y – z = 0
\end{array}
$$
ou, em termos matriciais,
$$
\left[ \begin{array}{lll} 2 & 4 & 1 \\ 1 & 1 & 2\\ 1 & 3 & – 1\end{array} \right]
\left[ \begin{array}{l} x \\ y\\ z \end{array} \right] = 0.
$$
O conjunto de todas as soluções deste sistema, \(W\) , é um subespaço vetorial de \(M (3, 1)\) . Podemos concluir isto mesmo sem resolver explicitamente o sistema. Suponha que \(\vec{X}_1\) e \(\overrightarrow{X_2} \) sejam soluções, então, \(\vec{X}_1 + \overrightarrow{X_2} \in W\) pois
$$
A (\vec{X}_1 + \overrightarrow{X_2}) = A \vec{X}_1 + A \overrightarrow{X_2} = 0
$$
pois cada um dos dois vetores são solução do sistema. Além disto, para \(\alpha\) um escalar qualquer, \(\alpha \vec{X}_1 \in W\) pois
$$
A (\alpha \vec{X}_1) = \alpha A \vec{X}_1 = 0.
$$
A exata relação entre estes espaços será objeto de nosso estudo em breve.
Algumas considerações adicionais sobre sistemas lineares homogêneos serão úteis. Podemos identificar \(M (1, 3)\) com o espaço \(\mathbb{R}^3\) . Cada uma das equações do sistema acima descreve os pontos de um plano no espaço. \(W\) , a solução deste sistema, é a interseção entre estes três planos, se esta interseção existir. Para que \(W\) seja um espaço vetorial é necessário que esta interseção contenha a origem, ou seja, o ponto \((0, 0, 0)\) . O conjunto de soluções de um sistema não homogêneo, \(A \vec{X} = \vec{B}\) , com \(\vec{B} \neq 0\) , não é um subespaço vetorial.
Ainda sobre o sistema homogêneo \(A \vec{X} = 0\) , observe que \(\vec{X} = 0\) sempre será uma solução (que chamamos de solução trivial). Se a matriz \(A\) é invertível, multiplicamos à esquerda o sistema por sua inversa $$
A^{- 1} A \vec{X} = 0 \Rightarrow \vec{X} = 0,
$$
ou seja, só existe a solução trivial. Para que exista outra solução, além da trivial, é necessário que \(A\) seja não invertível, isto é, \(\det A = 0\) .
Teorema: Se \(W_1\) e \(W_2\) são subespaços vetoriais de \(V\) então a interseção entre eles, \(W_1 \cap W_2\) , também é subespaço vetorial de \(V\) .
Demonstração: Sabemos que \(W_1 \neq \emptyset\) e \(W_2 \neq \emptyset\) pois ambos são subespaços vetoriais de \(V\). Além disto \(W_1 \cap W_2 \neq \emptyset\) pois ambos contém pelo menos o vetor nulo. Então
Se \(x, y \in W_1 \cap W_2\) temos
$$
\left. \begin{array}{l}
x, y \in W_1 \Rightarrow x + y \in W_1\\
x, y \in W_2 \Rightarrow x + y \in W_2
\end{array} \right\} \Rightarrow \text{ } x + y \in W_1 \cap W_2 ;
$$
Se \(x \in W_1 \cap W_2\) e \(\alpha\) é um escalar, então
$$
\left. \begin{array}{l}
x \in W_1 \Rightarrow \alpha x \in W_1\\
x \in W_2 \Rightarrow \alpha x \in W_2
\end{array} \right\} \Rightarrow \alpha x \in W_1 \cap W_2,
$$
e isto conclui a demonstração.
Exemplo: \(V =\mathbb{R}^3, W_1\) e \(W_2\) são planos do espaço que contém a origem. Então \(W_1 \cap W_2\) é uma reta pela origem ou um plano, caso \(W_1\) e \(W_2\) sejam coincidentes. Em ambos os casos a interseção é um subespaço vetorial de \(V\) .
Exemplo: \(V = M (n, n)\) , \(W_1\) composto pelas matrizes triangulares superiores \((a_{i j} = 0,\) se \(j > i)\) e \(W_2\) matrizes triangulares inferiores \((a_{i j} = 0,\) se \(i > j)\) . A interseção, \(W_1 \cap W_2\) , é o conjunto das matrizes diagonais, \((a_{i j} = 0,\) se \(i \neq j)\) , um subespaço vetorial de \(V\) .
Exemplo: \(V =\mathbb{R}^3\) , \(W_1\) e \(W_2\) retas não coincidentes pela origem. Neste caso a interseção contém apenas a origem, \( W_1 \cap W_2 = \{ 0 \}\) . Observe que, se \(\vec{u} \in W_1\) e \(\vec{v} \in W_2\) , então \(\vec{u} + \vec{v} \not\in W_1 \cap W_2\) , exceto se ambos os vetores forem nulos. Dai se conclui que \(W_1 \cap W_2\) não é um subespaço vetorial de \(V\) .
Imagem
É possível, no entanto, definir a soma de dois subespaços vetoriais, \(W = W_1 + W_2\) , de forma a que \(W\) seja um subespaço vetorial de \(V\) .
Teorema: Sejam \(W_1\) e \(W_2\) dois subespaços vetoriais de \(V\) . Então
$$
W=W_1+W_2=\{\vec{v}\in V;\;\vec{v}=\overrightarrow{w_1}+\overrightarrow{w_2};\;\;\overrightarrow{w_1} \in W_1, \overrightarrow{w_2}\in W_2\}
$$
é um subespaço vetorial de \(V\) .
A demonstração fica como um exercício para o leitor.
Exemplo: Se \(V =\mathbb{R}^3\) , \(W_1\) o eixo \(Ox\) e \(W_2\) o eixo \(Oy\) , então \(W_1 + W_2\) é o plano \(x\,y\) .
Exemplo: Sejam \(W_1\) e \(W_2\) dois subespaços vetoriais de \(M (2, 2)\), dados por
$$
W_1 = \left\{\left[
\begin{array}{ll} a & b\\ 0 & 0 \end{array}
\right];\;\; a, b \in \mathbb{R}
\right\},
W_2 = \left\{\left[
\begin{array}{ll} 0 & 0\\ c & d \end{array}
\right];\;\; c, d \in \mathbb{R}
\right\},
$$
então \(W_1 + W_2 = M (2, 2)\) .
Quando \( W_1 \cap W_2 = \{ \vec{0} \}\) então a soma \(W_1 + W_2\) é chamada de soma direta, denotada em muitos textos por \(W_1 \oplus W_2\) .
A álgebra linear1 é o ramo da matemática que estuda os espaços vetoriais, ou espaços lineares, além de funções (ou aplicações, ou transformações) lineares que associam vetores entre dois espaços vetoriais. Espaços vetoriais são uma generalização do espaço \(\mathbb{R}^3\) cotidiano e de senso comum onde vivemos, com dimensões tais como largura, altura e profundidade. Os pontos de \(\mathbb{R}^3\) podem ser associados a vetores, visualizados nos cursos básicos como setas que tem a base na origem, o ponto \((0,\,0,\,0)\), e extremo oposto no ponto em questão. Sob diversos aspectos diferentes é equivalente dizer que o próprio espaço \(\mathbb{R}^3\) é um conjunto de pontos, ou de vetores. Estes vetores e sua álgebra (o conjunto de operações que podem ser realizadas sobre eles) são uma ferramenta importante em diversas áreas da ciência, notadamente na física. Além disto é possível mostrar, como faremos neste texto, que vários outros espaços possuem propriedades semelhantes ao \(\mathbb{R}^3\). Estes espaços, chamados de forma generalizada de espaços vetoriais, podem ser profundamente diferentes dos espaços que consistem de “setas”. Por isto a noção primária de uma seta, assim como a notação usual de uma seta desenhada sobre o nome do vetor, deve ser abandonada.
(1) Muitos dos tópicos descritos aqui são estudados no decorrer do curso. Recomendo uma primeira leitura rápida e um retorno a esta seção, depois que os conceitos forem aprendidos.
Provavelmente o curso de álgebra linear é o curso, dentro das disciplinas da matemática, de maior importância para estudantes e profissionais de diversas áreas fora da própria matemática. Ele é essencial nas engenharias e, particularmente, na ciência da computação. Por outro lado, para alunos de matemática, ele significa a primeira grande incursão no terreno da abstração, onde conceitos bastantes concretos, válidos para os vetores de três dimensões, são aplicados em outros espaços de dimensões arbitrárias e de natureza diversa e muitas vezes surpreendente. Nem sempre é trivial a passagem entre tópicos tais como a solução de sistemas de n equações lineares com m incógnitas para outro como núcleos de transformações lineares, homomorfismos e isomorfismos.
O campo de aplicação da disciplina é muito vasto. A computação gráfica, por exemplo, a manipulação de imagens, rotação, redimensionamento, alteração de cores são operações lienares. Por outro lado, evidentemente nem todos os processos da natureza podem ser descritos por meio de sistemas ou equações lineares. No entanto muitos sistemas e aplicações importantes são lineares, o que por si já justificaria seu estudo. Além disto a matemática envolvida na solução de sistemas não lineares é complicada e ainda está sendo desenvolvida na atualidade. Por isto sua solução passa muitas vezes pela solução de um sistema linear que melhor representa o sistema em estudo. A partir das soluções aproximadas existem métodos para se obter soluções mais próximas do sistema real.
Um bom entendimento da geometria analítica contribui muito para o estudo da álgebra linear. Para aqueles que não tem este entendimento se recomenda uma revisão de alguns tópicos, notadamente dos vetores e suas operações. Em particular considerar a definição de um vetor, soma e subtração, módulo e produto interno e vetorial. Por outro lado, um aluno de matemática com pouca familiaridade com a álgebra linear terá dificuldade em seus cursos posteriores.
História resumida
Leibniz
O conceito de matriz e determinantes, básicos na álgebra linear, surgiu da necessidade de se resolver sistemas de equações lineares com coeficientes constantes. Leibnitz utilizava o determinante já em 1693, enquanto as matrizes foram pimeiramente utilizadas por Lagrange no final dos anos 1700. Lagrange buscava um método para determinar máximos e mínimos de funções com várias variáveis. Para isso ele exigiu que as derivadas parciais de primeira ordem fossem nulas e que uma matriz, construida com as derivadas de segunda ordem obedecesse uma determinada condição. Lagrange, no entanto não mencionou explicitamente a palavra ou conceito de matriz. Em 1772 Laplace discutiu a solução de sistemas lineares associados ao estudo de órbitas planetárias e apresentou seu método de cálculo usando cofatores e “matrizes menores”. Cramer apresentou sua fórmula em 1750, a que hoje chamamos de Regra de Cramer.
Apesar da existência de manuscritos chineses muito antigos mostrando a solução de sistemas de três equações em três incógnitas por “eliminação”, o método de Gauss só foi apresentado em 1800. Este método foi usado inicialmente apenas em aplicações e sua importância teórica ignorada. A introdução definitiva de método de Gauss na matemática se deu com a contribuição de Wilhelm Jordan que aplicou o método de Gauss na solução de problemas associados à medição e representação da superfície terrestre, a geodesia. O método é citado em seu livro Textbook of Geodesy, 1888.
Arthur Cayley
(2) Não consegui verificar se, de fato, Cayley provou o teorema do determinante de produto de matrizes.
Sylvester, em 1848, usou pela primeira vez o termo matriz (uma palavra com origem no latim, significando útero, como sendo a base de onde surgem os números), apresentou a notação moderna para designá-las. A álgebra das matrizes foi elaborada por Arthur Cayley em 1855, em seu estudo de transformações lineares e suas composições. Cayley mostrou que, se duas transformações podem ser representadas pelas matrizes S e P, a transformação composta será representada pela matriz produto ST, desde que este produto seja devidamente definido. Cayley estudos ainda a álgebra dessas composições e, como decorrência, as matriz inversas, e mostrou2 que, dadas as matrizes A e B de dimensões apropriadas o determinate de seu produto é \(\det\,(AB) = \det\,(A)\det\,(B)\).
Progresso e Aplicações Modernas
Os principais passos posteriores estão além do que é descrito neste texto, e são citados aqui muito resumidamente. O estudo das matrizes continuou associado d perto ao das transformações lineares. A definição de espaço vetorial moderna foi introduzido por Peano em 1888. Ele também estudos espaços vetoriais abstratos, por exemplo aqueles constituídos por funções. Grassmann apresentou em 1844 o primeiro produto de vetores não comutativos (onde a ordem dos fatores é relevante no cálculo). Com o desenvolvimento dos computadores houve um ressurgimento no interesse em matrizes, particularmente no cálculo numérico.
A álgebra abstrata representa uma generalização moderna, introduzida na metade do século XX. Tensores, como generalização de vetores, surgiram no final do século XIX. Todo essas ferramentas são amplamente utilizadas na mecânica quântica, relatividade, e estatística, o que contribuiu para que o estudo da álgebra linear se tornasse generalizado para estudantes de ciências exatas. Ela é, ainda, uma importante base para o desenvolvimentos de tópicos teóricos avançados modernos.
Dado um sistema de duas equações e duas incógnitas
$$
\left\{ \begin{array}{r}
a_{11} x_1 + a_{12} x_2 = b_1\\
a_{21} x_1 + a_{22} x_2 = b_2
\end{array} \right.
$$
é possível resolvê-lo, por exemplo, por substituição e sua solução será
$$
x_1 = \frac{a_{11} b_1 – a_{12} b_2}{a_{11} a_{22} – a_{12} a_{21}} ; x_2 =
\frac{a_{11} b_2 – a_{21} b_1}{a_{11} a_{22} – a_{12} a_{21}} .
$$
Nas duas frações acima aparece o mesmo denominador, uma expressão que surge em diversos contextos dentro da álgebra linear. Por este motivo ele recebeu um nome e é objeto de estudo pormenorizado.
Definição: O determinante da matriz
$$
A = \left[ \begin{array}{rr}
a_{11} & a_{12}\\
a_{21} & a_{22}
\end{array} \right]
$$
é denotado por qualquer uma das formas abaixo
$$
\det A = \left| A \right| = \left|
\begin{array}{rr}
a_{11} & a_{12} \\
a_{21} & a_{22}
\end{array} \right|
= a_{11} a_{22} – a_{12} a_{21}.
$$
O determinante de uma matriz \(3 \times 3\)
$$
A = \left[ \begin{array}{rrr}
a_{11} & a_{12} & a_{13}\\
a_{21} & a_{22} & a_{23}\\
a_{31} & a_{32} & a_{33}
\end{array} \right].
$$
é definido como
$$
\det A = a_{11} a_{22} a_{33} + a_{13} a_{21} a_{32} + a_{12} a_{23} a_{31}
– a_{11} a_{23} a_{32} – a_{12} a_{21} a_{33} – a_{13} a_{22} a_{31}.
$$
O cálculo de determinantes de matrizes de dimensões maiores diretamente pode ficar longo e tedioso. No entanto algumas propriedades simplificam esta operação. Antes de mostrarmos estas propriedades e até mesmo antes de descrever uma definição mais geral do determinante é útil apresentar algumas definições.
Definição: Dada uma fila de elementos (ou seja, um conjunto de elementos ordenados, por exemplo por meio de sua posição), uma transposição destes elementos é a troca de posição entre dois deles. Uma permutação é o resultado de uma transformação entre elementos de um conjunto ordenado obtida por meio de um número finito de transposições.
Exemplos: (1 2 3 4) \(\rightarrow\) (3 2 1 4) representa uma transposição dos elementos 3 e 1.
(1 2 3 4) \(\rightarrow\) (3 1 2 4) representa uma permutação obtida por meio da transposição anterior, seguida de nova transposição dos elementos 1 e 2.
\( n\) objetos podem ser permutados de \(n\) ! maneiras diferentes pois, temos \(n\) escolhas para a primeira posição, \(n – 1\) para a segunda, e consecutivamente,
$$
n (n – 1) (n – 2) \ldots 1 = n!
$$
Observe que, para a contagem acima, a permutação identidade, que consiste em deixar a fila inalterada, foi considerada.
Uma permutação é par (ímpar) se envolve um número par (ímpar) de transposições.
De posse destas definições podemos apresentar uma definição para o determinante de uma matriz de qualquer dimensão, desde que seja uma matriz quadrada.
Definição: O determinante de uma matriz \(A_{3 \times 3}, A = \{a_{ij} \}\) é
$$
\det A = \sum^3_{i j k} a_{1 i} a_{2 j} a_{3 k} \,\varepsilon_{i j k} .
$$
O determinante de uma matriz \(A_{n \times n}, A = \{a_{i j} \}\) é
$$
\det A = \sum^n_{i_1 i_2 \ldots i_n} a_{1 i_1} a_{2 i_2} \ldots a_{n
i_n} \,\varepsilon_{i_1 i_2 \ldots i_n} .
$$
Usaremos esta definição, na maioria das vezes, apenas para mostrar resultados gerais sobre o determinante. Na prática, para matrizes com entradas numéricas, usaremos as propriedades para este cálculo. No entanto compreender esta notação é útil e facilita muito o desenvolvimento a seguir.
pois \(\,\varepsilon_{12} = 1 ;\; \,\varepsilon_{21} = – 1 ;\; \,\varepsilon_{11} = \,\varepsilon_{22} = 0\) . Este é, naturalmente, a mesma expressão já listada. O símbolo de Levi-Civita é utilizado aqui apenas para indicar um sinal e o cancelamento de termos incluem entradas de mesma linha ou mesma coluna da matriz. Para efeito de adquirir maior familiaridade com este formalismo vamos ainda listar o determinante de matrizes \(3 \times 3\) .
Na demonstração das propriedades do determinante usaremos apenas matrizes \(3 \times 3\) . A extensão destas demonstrações para matrizes de dimensões maiores é direta e não apresenta maior dificuldade. Denotaremos as matrizes \(A = \{a_{i j} \}\) e \(B = \{b_{i j} \}\) .
(i) Se todos os elementos de uma linha (ou coluna) de uma matriz são nulos, seu determinante é nulo.
Demonstração: Todos os termos do somatório que representa o determinante contém um elemento de todas as linhas (colunas). Se uma delas for nula o determinante é nulo. Alternativamente, se uma das linhas de \(A\) é nula, digamos que seja a primeira linha, \(a_{1 i} = 0\) , então $$
\det A = \sum_{i, j, k} a_{1 i} a_{2 j} a_{3 k} \,\varepsilon_{i j k} = 0.
$$
Como veremos a seguir todas as propriedades válidas para as linhas também valem para as colunas.
(ii) Se \(A’\) é a transposta de \(A\) então \(\det A’ = \det A\) .
(iii) Se, em uma matriz, uma linha (coluna) é multiplicada por uma constante o determinante da matriz fica multiplicado por esta constante.
Demonstração: Sem perda de generalidade considere que \(B\) é obtida de \(A\) pela multiplicação de sua primeira linha por uma constante \(k\) . Então \(b_{1 i} = k a_{1 i}\) e
$$
\det B = \sum_{i, j, k} b_{1 i} b_{2 j} b_{3 k} \,\,\varepsilon_{i j k} =
\sum_{i, j, k} k a_{1 i} a_{2 j} a_{3 k}\, \,\varepsilon_{i j k} = k \det A.
$$
(iv) Se, em uma matriz, duas linhas (colunas) são permutadas o determinante da matriz muda de sinal (fica multiplicado por \(– 1\)).
Demonstração: Seja \(B\) a matriz obtida de \(A\) pela permutação das linhas 1 e 2. (O resultado é análogo para qualquer outra escolha de linhas ou colunas). Então \(b_{1 i} = a_{2 i}\) e \(b_{2 i} = a_{2 i}\) e
$$
\det B = \sum_{i, j, k} b_{1 i} b_{2 j} b_{3 k} \,\varepsilon_{i j k} =
\sum_{i, j, k} a_{2 i} a_{1 j} a_{3 k} \,\varepsilon_{i j k} .
$$
Podemos renomear os índices, permutando os índices \(i\) e \(j\) sem alterar o determinante,
$$
\det B = \sum_{i, j, k} a_{1 i} a_{2 j} a_{3 k} \,\varepsilon_{j i k} = – \det A.
$$
Na última igualdade foi usado o fato de que \(\,\varepsilon_{j i k} = – \,\varepsilon_{i j k}\).
(v) Se \(A\) tem duas linhas (colunas) iguais então \(\det A = 0\) .
Demonstração: Devido à propriedade (iv) se \(B\) é obtida de \(A\) por permutação de duas linhas (colunas) então \(\det B = – \det A\) . Se \(A = B\) , pois as duas linhas são iguais, então \(\det A = 0\) .
(vi) Se \(B\) é obtida de \(A\) pela soma de cada elemento de uma linha (coluna) por constantes seu determinante fica alterado da seguinte forma:
$$
\left| \begin{array}{rrr}
a_{11} & \cdots & a_{1 n}\\
\vdots & & \vdots\\
a_{k 1} + b_1 & \cdots & a_{k n} + b_n\\
\vdots & & \vdots\\
a_{n 1} & \cdots & a_{n n}
\end{array} \right| = \left| \begin{array}{rrr}
a_{11} & \cdots & a_{1 n}\\
\vdots & & \vdots\\
a_{k 1} & \cdots & a_{k n}\\
\vdots & & \vdots\\
a_{n 1} & \cdots & a_{n n}
\end{array} \right| + \left| \begin{array}{rrr}
a_{11} & \cdots & a_{1 n}\\
\vdots & & \vdots\\
k_1 & \cdots & k_n\\
\vdots & & \vdots\\
a_{n 1} & \cdots & a_{n n}
\end{array} \right|
$$
Demonstração: Suponha que \(B\) é a matriz obtida de \(A\) pela soma de cada elemento de sua primeira linha com constantes, \(b_{1 i} = a_{1 i} + k_i\) , onde \(k_i (i – 1, \ldots, n)\) são constantes, suas outras linhas permanecendo inalteradas, \(b_{j i} = a_{j i}\) se \(j \neq 1\) . Então
que é o mesmo resultado mostrado acima. É importante observar que o determinante de uma soma de matrizes não é igual à soma dos determinantes, ou seja
$$
\det (A + B) \neq \det A + \det B.
$$
(vii) O determinante não se altera se somarmos à uma de suas linhas um múltiplo de outra linha. Devido à propriedade (ii) o mesmo vale para colunas da matriz.
Demonstração: Vamos denotar por \(B\) a matriz obtida de \(A\) por meio da operação \(L_1 + k L_2 \rightarrow L_2\) ,ou seja, \(b_{1 j} = a_{1 j} + k a_{2 j}\) . (A demonstração é análoga para quaisquer outras duas linhas ou colunas de \(A.)\) Então
$$
\det B = \sum_{i, j, k} b_{1 i} b_{2 j} b_{3 k} \,\varepsilon_{j i k} = \sum_{i, j, k} (a_{1 i} + k a_{2 i}) a_{2 j} a_{3 k} \,\varepsilon_{j i k} =
$$
$$
= \sum_{i, j, k} a_{1 i} a_{2 j} a_{3 k} \,\varepsilon_{j i k} + k \sum_{i, j, k} a_{2 i} a_{2 j} a_{3 k} \,\varepsilon_{j i k} = \det A.
$$
O último somatório é nulo porque representa o determinante de uma matriz com duas linhas iguais.
Exemplo: Usamos a propriedade (vii) para linhas, colunas (ou ambas) com maior número de entradas nulas. No determinante abaixo fazemos as operações indicadas à esquerda,
$$
L_2 – 2 L_3 \rightarrow L_2 \left| \begin{array}{rrr}
1 & 2 & 3\\
2 & 3 & 2\\
1 & 0 & 1
\end{array} \right| = \left| \begin{array}{rrr}
1 & 2 & 3\\
0 & 3 & 0\\
1 & 0 & 1
\end{array} \right| = 3 – 3 \times 3 = – 6,
$$
Colocando os elementos da primeira linha em evidência em todos os fatores temos
$$
\det A = a_{11} (a_{22} a_{33} – a_{23} a_{32}) + a_{12} (a_{23} a_{31} –
a_{21} a_{33}) + a_{13} (a_{21} a_{32} – a_{22} a_{31}) =
$$
O sinal do segundo termo foi invertido para que uma notação mais sintética pudesse ser adotada, da seguinte forma:
$$
\det A = a_{11} \left| A_{11} \right| – a_{12} \left| A_{12} \right|
+ a_{13} \left| A_{13} \right|,
$$
onde \(A_{i j}\) é uma submatriz obtida de \(A\) através da retirada de sua \(i\)-ésima linha e \(j\)-ésima coluna. Uma notação ainda mais compacta e que será útil pode ser conseguida definido-se o cofator do elemento \(a_{i j} \) como o número
$$
\Delta_{ij} = (- 1)^{i + j} \left| A_{i j} \right|.
$$
Desta forma podemos escrever
$$
\det A = a_{11} \Delta_{11} + a_{12} \Delta_{12} + a_{13} \Delta_{13} = \sum_{k = 1}^n a_{1 k} \Delta_{1 k},
$$
que é chamado de desenvolvimento de Laplace ao longo da primeira linha. O mesmo pode ser escrito para qualquer linha (ou coluna),
$$
\det A = \sum_{k = 1}^n a_{i k} \Delta_{i k}, i = 1, \ldots, n,
$$
que é o desenvolvimento de Laplace ao longo da \(i\)-ésima linha.
Esta forma compacta do desenvolvimento de Laplace será usada em demonstrações futuras. Ela também é usada na prática para o cálculo de determinantes, principalmente para matrizes de dimensões maiores que \(3 \times 3\) . Um exemplo pode tornar mais claro este uso.
Exemplo: Vamos obter o determinante da matriz \(A\) abaixo pelo desenvolvimento de Laplace ao longo da segunda coluna:
$$
A = \left[ \begin{array}{rrr}
1 & – 2 & 3\\
2 & 1 & – 1\\
– 2 & – 1 & 2
\end{array} \right].
$$
$$
\det A = + 2 \left| \begin{array}{rr}
2 & – 1\\
– 2 & 2
\end{array} \right| + 1 \left| \begin{array}{rr}
1 & 3\\
– 2 & 2
\end{array} \right| + 1 \left| \begin{array}{rr}
1 & 3\\
2 & – 1
\end{array} \right| = 2 (2) + 1 (8) + 1 (- 7) = 5.
$$
Em diversas situações o cálculo pode ser muito simplificado de usarmos juntamente com este desenvolvimento as demais propriedades do determinante.
Exemplo: Com a mesma matriz \(A\) acima fazemos primeiro a operação \(L_3 + L_2 \rightarrow L_3\) , que deixa o determinante inalterado,
$$
\det A = \left| \begin{array}{rrr}
1 & – 2 & 3\\
2 & 1 & – 1\\
– 2 & – 1 & 2
\end{array} \right| = \left| \begin{array}{rrr}
1 & – 2 & 3\\
2 & 1 & – 1\\
0 & 0 & 1
\end{array} \right| = (- 1)^{3 + 3} \left| \begin{array}{rr}
1 & – 2\\
2 & 1
\end{array} \right| = 5.
$$
Na penúltima igualdade foi feito o desenvolvimento de Laplace ao longo da terceira linha (escolhida porque contém apenas um elemento não nulo).
Exemplo: Para o cálculo do determinante da matriz \(A_{4 \times 4}\) abaixo usamos as propriedades do determinante para obter uma matriz com um único
termo não nulo, com a operação \(C_1 – 2 C_2 \rightarrow C_1\) ,
$$
\det A = \left| \begin{array}{rrrr}
– 1 & 2 & 3 & – 4\\
4 & 2 & 0 & 0\\
– 1 & 2 & – 3 & 0\\
2 & 5 & 3 & 1
\end{array} \right| = \left| \begin{array}{rrrr}
– 5 & 2 & 3 & – 4\\
0 & 2 & 0 & 0\\
– 5 & 2 & – 3 & 0\\
– 8 & 5 & 3 & 1
\end{array} \right| = – 3.2 \left| \begin{array}{rrrr}
5 & 2 & 1 & – 4\\
0 & 1 & 0 & 0\\
5 & 2 & – 1 & 0\\
8 & 5 & 1 & 1
\end{array} \right| .
$$
Na última igualdade foi colocado em evidência os fatores \(– 1\) da primeira coluna, 3 da terceira coluna, e 2 da segunda linha. Fazemos agora o desenvolvimento de Laplace ao longo da segunda linha e, em seguida, \(C_1 + 5 C_2 \rightarrow C_1 \) para obter
$$
\det A = -6 (-1)^{2 + 2} \left| \begin{array}{rrr}
5 & 1 & – 4\\
5 & – 1 & 0\\
8 & 1 & 1
\end{array} \right| = \left| \begin{array}{rrr}
10 & 1 & – 4\\
0 & – 1 & 0\\
13 & 1 & 1
\end{array} \right| = – 6 (- 1) \left| \begin{array}{rr}
10 & – 4\\
13 & 1
\end{array} \right| = 372.
$$
A última operação foi o desenvolvimento de Laplace ao longo da segunda linha.
Matriz adjunta e matriz inversa
Dada a matriz \(A =\{a_{i j}\}\) já definimos anteriormente o cofator do elemento \(a_{i j} \) como o número
$$
\Delta_{ij} = (- 1)^{i+j} \left| A_{ij} \right|,
$$
onde \(A_{ij}\) é uma submatriz obtida de \(A\) através da retirada de sua \(i\)-ésima linha e \(j\)-ésima coluna. Como existe um cofator para cada um dos \(n \times n\) elementos de \(A\) podemos construir a chamada matriz dos cofatores de \(A\), que denotaremos por \(\bar{A} = \{\Delta_{i j} \}\) , com as mesmas dimensões de \(A\) .
Exemplo: Vamos encontrar a matriz dos cofatores de
$$
A = \left[ \begin{array}{rrr}
2 & 1 & 0\\
– 3 & 1 & 4\\
1 & 6 & 5
\end{array} \right].
$$
Definição: Dada uma matriz quadrada \(A,\) a matriz adjunta de \(A\) é a matriz transposta da matriz dos cofatores. Denotaremos esta matriz por \(\text{adj} A = \bar{A}’\) .
Exemplo: Continuando com a mesma matriz \(A\) do exercício anterior, sua adjunta é
$$
\text{adj} A = \left[ \begin{array}{rrr}
– 19 & – 5 & 4\\
19 & 10 & – 8\\
– 19 & – 11 & 5
\end{array} \right].
$$
Aproveitando ainda o mesmo exemplo para mostrar uma utilidade da matriz adjunta, observe que o determinante de \(A\) é
$$
\left| \begin{array}{rrr}
2 & 1 & 0 \\
– 3 & 1 & 4 \\
1 & 6 & 5
\end{array} \right| = 2 \Delta_{11} + \Delta_{12} = 2 (- 19) + 19 = – 19,
$$
enquanto o produto de \(A\) por sua adjunta é
$$
A. \text{adj} A = \left[\begin{array}{rrr}2 & 1 & 0\\- 3 & 1 & 4\\1 & 6 & 5 \end{array}\right]
\left[\begin{array}{rrr}- 19 & – 5 & 4\\19 & 10 & – 8\\- 19 & – 11 & 5\end{array}\right]= – 19
\left[\begin{array}{rrr}1 & 0 & 0\\0 & 1 & 0\\ 0 & 0 & 1\end{array}\right] = – 19 \mathbb{I}_3.
$$
Este é um resultado geral e importante, válido para toda matriz \(A_{n \times n}\).
Teorema: Se \(A\) é uma matriz \(n \times n\) então
$$
A. \text{adj} A = (\det A) \mathbb{I}_n .
$$
Se denotarmos por \(c_{i j} = A. \text{adj} A_{i j}\) um elemento qualquer deste produto, observamos que
$$
c_{11} = a_{11} \Delta_{11} + a_{12} \Delta_{12} + a_{13} \Delta_{13} = \left| A \right|,
$$
uma vez que este é o desenvolvimento de Laplace para o determinante ao longo da primeira linha. Outro elemento é
$$
c_{12} = a_{11} \Delta_{21} + a_{12} \Delta_{22} + a_{13} \Delta_{23},
$$
que é o desenvolvimento de Laplace para o determinante
$$
c_{12} = \left| \begin{array}{rrr}
a_{11} & a_{12} & a_{13}\\
a_{11} & a_{12} & a_{13}\\
a_{31} & a_{32} & a_{33}
\end{array} \right| = 0,
$$
nulo porque duas linhas da matriz são iguais. Todos os demais elementos admitem igual tratamento e
$$
c_{i j} = (A . \text{adj} A)_{i j} = \left| A \right| \delta_{i j},
$$
significando que todos são nulos exceto os elementos da diagonal principal. Este é o resultado que procuramos mostrar
$$
A . \text{adj} A = \left[ \begin{array}{rrr}
\left| A \right| & 0 & 0\\
0 & \left| A \right| & 0\\
0 & 0 & \left| A \right|
\end{array} \right] = \det A.\mathbb{I}_3 .
$$
O mesmo procedimento pode ser feito para matrizes quadradas de qualquer dimensão.
se \(i \neq j\) pois representa o determinante de uma matriz com duas linhas iguais. Se \(i = j\)
$$
c_{i i} = \sum_{k = 1}^n a_{i k} \Delta_{i k} = \det A.
$$
Logo \(A.\text{adj} A = \left| A \right| \mathbb{I}_n\) .
Definição: Dada uma matriz quadrada \(A\) dizemos que \(A^{- 1}\) é a matriz inversa de \(A\) se \(A A^{- 1} = A^{- 1} A =\mathbb{I}\) . Dizemos ainda que \(A\) é invertível se existir a sua inversa.
Exemplo: considerando a matriz
$$
A = \left[ \begin{array}{rr}
6 & 2\\
11 & 4
\end{array} \right], \det A = 2,
$$
encontramos a matriz dos cofatores e sua adjunta
$$
\bar{A} = \left[ \begin{array}{rr}
4 & – 11\\
– 2 & 6
\end{array} \right],\;\;\; \text{adj} A = \left[ \begin{array}{rr}
4 & – 2\\
– 11 & 6
\end{array} \right] .
$$
O produto entre A e sua adjunta é
$$
A . \text{adj} A = \left[ \begin{array}{rr}
6 & 2\\
11 & 4
\end{array} \right] \left[ \begin{array}{rr}
4 & – 2\\
– 11 & 6
\end{array} \right] = \left[ \begin{array}{rr}
2 & 0\\
0 & 2
\end{array} \right] .
$$
A inversa de \(A\) é
$$
A^{- 1} = \frac{\text{adj} A}{\det (A)} = \frac{1}{2} \left[
\begin{array}{rr}
4 & – 2\\
– 11 & 6
\end{array} \right]
$$
Teorema: Uma matriz \(A\) é invertível se, e somente se, seu determinante é não nulo, \(\det A \neq 0\) . Neste caso sua inversa é
$$
A^{- 1} = \frac{\text{adj} A}{\det A} .
$$
Demonstração: Suponha que \(A\) é invertível (ou seja, existe a sua inversa \(A^{- 1}\) ). Neste caso
$$
A.A^{- 1} =\mathbb{I} \Rightarrow \det (A.A^{- 1}) = \det \mathbb{I}= 1.
(\times)
$$
Pela propriedade (ix) do determinante temos que
$$
\det A . \det (A^{- 1}) = 1 A
$$
Concluimos de (*) que \(\det A \neq 0\) é uma condição suficiente para que \(A\) admita uma inversa. Por outro lado, se \(\det A \neq 0\)
então
$$
A^{- 1} = \frac{\text{adj} A}{\det A} .
$$
Podemos listar ainda outras propriedades de matrizes e suas inversas e consequências das propriedades acima:
Se \(A\) e \(B\) são invertíveis então o produto \(A B\) é invertível e sua inversa é \((A B)^{- 1} = B^{- 1} A^{- 1}\).
Demonstração: \(B^{- 1} A^{- 1} (A B) = B^{- 1} (A^{- 1} A) B =
B^{- 1} \mathbb{I}B = B^{- 1} B =\mathbb{I}\) .
Se existe uma matriz \(B\) tal que \(B A =\mathbb{I}\) então \(A\) é invertível e \(B = A^{- 1}\) . Isto significa que a inversa é única e \(A^{- 1} A = A A^{- 1} =\mathbb{I}\) (a inversa à direita e à esquerda são idênticas). Demonstração: \(B = B\mathbb{I}= B A A^{- 1} = (B A) A^{- 1}
=\mathbb{I}A^{- 1} = A^{- 1}\).
Se \(A\) tem determinante nulo então não existe a inversa de \(A\).
Exemplo: Como um exercício procure uma matriz \(B_{2 \times 2}\) que seja a inversa de
$$ A = \left[ \begin{array}{rr}0 & 2\\0 & 1\end{array} \right]. $$
Tanto a operação de resolver um sistema linear quanto a de inverter um matriz são muito comuns na matemática aplicada e computacional. Estas operações envolvem um grande número de cálculos e nem sempre são realizadas na prática nas formas aqui descritas. Uma forma adicional de solução de sistemas de \(n\) equações e \(n\) incógnitas, ainda envolvendo muitas operações mas muito útil em manipulações algébricas e abstratas é a conhecida regra de Cramer.
Se o determinante de \(A\) é não nulo, \(\det A \neq 0\) , então existe a inversa \(A^{- 1}\) e o sistema fica completamente resolvido, bastando multiplicar o sistema por \(A^{- 1}\) à esquerda
$$
A^{- 1} A X = A^{- 1} B.
$$
Como \(A^{- 1} A =\mathbb{I}\) então a solução é
$$
X = A^{- 1} B.
$$
Lembrando que
$$
A^{- 1} = \frac{\text{adj} A}{\det A}
$$
Como exemplo vamos listar explicitamente o primeiro elemento da solução
$$
x_1 = \frac{1}{\det A} (\Delta_{11} b_1 + \Delta_{21} b_2 + \ldots + \Delta_{n 1} b_n),
$$
onde se observa que o termo entre parênteses é o determinante de uma matriz obtida de \(A\) substituindo-se sua primeira coluna pela matriz coluna \(B\) ,em seu desenvolvimento de Laplace ao longo da primeira linha:
$$
\left| \begin{array}{rrrr}
b_1 & a_{12} & \cdots & a_{1 n}\\
b_2 & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \vdots\\
b_n & a_{n 2} & \cdots & a_{n n}
\end{array} \right| = \Delta_{11} b_1 + \Delta_{21} b_2 + \ldots +
\Delta_{n 1} b_n .
$$
O mesmo ocorre com qualquer um dos elementos \(x_i\) da solução,
$$
x_i = \frac{1}{\det A} \left| \begin{array}{rrrrr}
a_{11} & \cdots & b_1 & \cdots & a_{1 n}\\
a_{21} & \cdots & b_2 & \cdots & a_{2 n}\\
\vdots & & & & \vdots\\
a_{n 1} & \cdots & b_n & \cdots & a_{n n}
\end{array} \right|, i = 1, \ldots, n,
$$
onde a matriz \(B\) substitui a \(i\)-ésima coluna no determinante. Esta é a chamada regra de Cramer.
Exemplo: Vamos resolver o seguinte sistema usando a regra de Cramer,
$$
\begin{array}{r}
2 x – 3 y + 7 z = 1\\
x + 3 z = 5\\
2 y – z = 0
\end{array}
$$
que equivale à \(A X = B\) ,
$$
A = \left[ \begin{array}{rrr}
2 & – 3 & 7\\
1 & 0 & 3\\
0 & 2 & – 1
\end{array} \right], \;\;\; B = \left[ \begin{array}{r}
1\\
5\\
0
\end{array} \right] .
$$
Notamos que \(\det A = – 1\) a solução do sistema é
$$
x = – \left| \begin{array}{rrr}
1 & – 3 & 7\\
5 & 0 & 3\\
0 & 2 & – 1
\end{array} \right| = – 49 ;
$$
Definição: Uma matriz é uma coleção de elementos estabelecidos em linhas e colunas, da seguinte forma:
$$
A_{m \times n} = \left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n} \\
a_{21} & a_{22} & \cdots & a_{2 n} \\
\vdots & & & \vdots \\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right],
$$
onde \(a_{i j} \) representa o elemento na \(i\)-ésima linha e \(j\) -ésima coluna. A matriz acima, portanto, tem \(m\) linhas e \(n\) colunas e dizemos que esta matriz tem dimensão \(m \times n\) . Como delimitadores de uma matriz podemos usar colchetes [ ] ou parênteses ( ), de acordo com a conveniência. Também podemos representar uma matriz por meio de um elemento genérico, colocado entre colchetes para indicar que se trata de uma coleção de linhas e coluna, na forma de
$$
A_{m \times n} = \{a_{i j} \},\;\; i = 1, \ldots, m, j = 1, \ldots, n,
$$
e, em algumas situações, nos referiremos a um elemento genérico da matriz \(A\) por \((A)_{i j} = a_{i j}\) . Os exemplos dados abaixo servirão para ilustrar este conceito e apresentar algumas matrizes de tipos mais comuns e mais utilizadas.
Exemplo: A matriz \(A\) abaixo é uma matriz \(2 \times 2\) , portanto uma matriz quadrada,
$$
A = \left[ \begin{array}{ll}
1 & 3\\
4 & 5
\end{array} \right],
$$
onde os elementos \(a_{11} = 1\) , \(a_{22} = 5\) , só para citar alguns exemplos. A matriz
$$
B = \left[ \begin{array}{ll}
1 & – 2\\
3 & \;0\\
5 & \;4
\end{array} \right]
$$
é uma matriz \(3 \times 2\) (ou seja, tem 3 linhas e duas colunas) enquanto \(C = [1]\) é uma matriz \(1 \times 1\) . Matrizes \(n \times 1\) são denominadas matrizes colunas, tais como \(D_{4 \times 1}\) abaixo
$$
D = \left[ \begin{array}{l}
2\\
0\\
1\\
3
\end{array} \right],
$$
enquanto matrizes \(1 \times n\) são denominadas matrizes linhas, tais como \(E = [1, 2, 6] .\) Uma matriz nula possue todos os seus componentes nulos,
$$
F = \left[ \begin{array}{ll}
0 & 0\\
0 & 0
\end{array} \right] .
$$
Podemos usar o símbolo \(\tilde{0}\) para representar a matriz nula quando isto for interessante para a discussão do momento. Uma matriz identidade é uma matriz quadrada com todos os elementos nulos exceto os da diagonal principal, que são de uma unidade, como \(\mathbb{I}_{3 \times 3}\) abaixo,
$$
\mathbb{I}= \left[ \begin{array}{lll}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{array} \right] .
$$
Observe que \(\mathbb{I}\) (ou outra matriz identidade de qualquer dimensão) tem elementos
$$
(I)_{i j} = \delta_{i j} = \left\{ \begin{array}{ll}
1 & \text{se } i = j,\\
0 & \text{se} i \neq j.
\end{array} \right.
$$
O símbolo \(\delta\) definido desta forma é o chamado delta de Kronecker. Logo ficará claro porque chamamos esta matriz de identidade. E interessante ainda definir as matrizes diagonais como aquelas que possuem todos os elementos nulos exceto os da diagonal principal, que podem ter qualquer valor, como
\begin{eqnarray*}
& & G = \left[ \begin{array}{lll}
7 & 0 & 0\\
0 & – 1 & 0\\
0 & 0 & 1
\end{array} \right],
\end{eqnarray*}
e as matrizes simétricas, que são aquelas que permanecem inalteradas quando suas linhas são tomadas como colunas, tal como
$$
H = \left[ \begin{array}{lll}
3 & 2 & 1\\
2 & 0 & 7\\
1 & 7 & 1
\end{array} \right] .
$$
Alternativamente, definimos a matriz \(H = \{h_{i j} \}\) como simétrica se \(h_{i j} = h_{j i}\) .
Definição: Se \(A\) é uma matriz \(n \times m\) sua transposta e a matriz \(A’_{m \times n} \) obtida de \(A\) por meio da transposição de suas linhas em colunas, \((A)_{i j} = (A’)_{j i}\) .
Exemplo: A transposta da matriz \(B\) acima é
$$
B’ = \left[ \begin{array}{ccc}
1 & 3 & 5\\
– 2 & 0 & 4
\end{array} \right] .
$$
As seguintes propriedades podem ser verificadas quanto à transposição de matrizes:
(i) Se \(S\) é uma matriz simétrica então \(S’ = S\) ,ou seja, uma matriz simétrica é igual a sua transposta.
(ii) \(A’ ‘ = A\) ,
(iii) \((A + B)’ = A’ + B’\) ,
(iv) \((k A)’ = k A’\) .
Definição: dizemos que duas matrizes são iguais se, e somente se, tem a mesma ordem e todos os seus elementos correspondentes (na mesma linha e mesma coluna) são iguais;
$$
A = B \Leftrightarrow a_{i j} = b_{i j.}
$$
A álgebra das Matrizes
Tendo definido as matrizes podemos agora definir uma álgebra ou um conjunto de operações sobre estes elementos.
1) Adição: Se \(A\) e \(B\) são matrizes de mesma ordem então \((A + B)_{i j} = a_{i j} + b_{i j}\) .
onde \(\mathbb{I}_{3 \times 3}\) é a matriz identidade .
As seguintes propriedades são válidas para as operações já consideradas: se \(A\) e \(B\) são matrizes de mesma ordem, \(k\) e \(l \) são escalares então:
(i) \(k (A + B) = k A + k B\) ;
(ii) \((k + l) A = k A + l A\) ;
(iii) \(0 \cdot A = \tilde{0}\) ;
(iv) \(k (l A) = (k l) A\) .
Observe na propriedade (iii) que o produto de qualquer matriz pelo escalar \(0\) é a matriz nula \(\tilde{0}\) embora seja costume representar este resultado simplesmente pelo número 0. Um outro exemplo onde isto pode ocorrer é o seguinte
$$
\left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] – \left[ \begin{array}{ll}
3 & 2\\
1 & 3
\end{array} \right] = 0,
$$
onde o resultado escrito como 0 por abuso de linguagem, na verdade significa a matriz \(\tilde{0}\) de dimensões \(2 \times 2\) .
3) Multiplicação de matrizes
Dadas as matrizes \(A_{m \times n}\) e \(B_{n \times p}\) (notando portanto que \(B\) tem um número de linhas igual ao número de colunas de \(A\) ) definimos o produto de \(A\) por \(B\) da seguinte forma
$$
(A B)_{i j} = \sum^n_{k = 1} a_{i k} b_{k j} .
$$
Isto significa que o elemento da \(i\) -ésima linha e \(j\) -ésima coluna é obtido pela soma dos produtos de elementos da \(i\) -ésima linha de \(A\) com a \(j\) -ésima coluna de \(B\) . O produto é a matriz \(A B\) de dimensões \(m \times p\) . Alguns exemplos servirão para esclarecer este procedimento. No entanto é útil compreender a operação indicada simbolicamente pelo somatório acima.
Neste último exemplo observamos que, além da não co mutatividade do produto de matrizes, é possível que o produto de duas matrizes seja nulo sem que nenhuma delas seja a matriz nula.
Propriedades do produto de matrizes
(i) \(A B \neq B A\) ,
(ii) \(A\mathbb{I}=\mathbb{I}A = A\) , onde \(\mathbb{I}\) é a matriz identidade (e dai o seu nome),
(iii) \(A (B + C) = A B + A C\) ,(distributividade à esquerda),
(iv) \((B + C) A = B A + C A\) , (distributividade à direita),
(v) \((A B) C = A (B C)\) , (associatividade),
(vi) \((A B)’ = B’ A’\) ,
(vii) \(\tilde{0} A = A \tilde{0} = \tilde{0}\) , onde \(\tilde{0}\) é a matriz nula.
Sistemas de equações lineares
Definição: Um sistema com \(m\) equações lineares com \(n\) incógnitas é um conjunto de equações da forma de
\begin{eqnarray*}
a_{11} x_1 + a_{12} x_2 + \ldots + a_{1 n} x_n = b_1 & & \\
a_{21} x_1 + a_{22} x_2 + \ldots + a_{2 n} x_n = b_2 & & \\
\vdots & & \\
a_{m 1} x_1 + a_{m 2} x_2 + \ldots + a_{m n} x_n = b_m & &
\end{eqnarray*}
onde \(a_{i j}, 1 \leq i \leq m, 1 \leq j \leq n,\) são números reais (ou complexos) e \(x_k, 1 \leq k \leq n\) são \(n\) incógnitas. Uma solução do sistema acima, quando existir, é uma \(n\) -upla \((x_1, x_2, \ldots, x_n)\) que satisfaz simultaneamente as \(m\) equações do sistema. Podemos escrever o mesmo sistema sob forma matricial
$$
\left[ \begin{array}{llll}
a_{11} & a_{12} & \cdots & a_{1 n}\\
a_{21} & a_{22} & \cdots & a_{2 n}\\
\vdots & & & \vdots\\
a_{m 1} & a_{m 2} & \cdots & a_{m n}
\end{array} \right] \left[ \begin{array}{l}
x_1\\
x_2\\
\vdots\\
x_n
\end{array} \right] = \left[ \begin{array}{l}
b_1\\
b_2\\
\vdots\\
b_m
\end{array} \right],
$$
sendo que \(A\) é denominada matriz dos coeficientes do sistema, \(X\) é a matriz das incógnitas e \(B\) a matriz dos termos constantes. Alternativamente é útil escrever o mesmo sistema como o conjunto das equações
\begin{eqnarray*}
\sum_{j = 1}^n a_{1 j} x_j = b_{1,} & & \\
\sum_{j = 1}^n a_{2 j} x_j = b_{2,} & & \\
\vdots & & \\
\sum_{j = 1}^n a_{m j} x_j = b_{m,} & &
\end{eqnarray*}
ou, de modo compacto,
$$
\sum_{j = 1}^n a_{i j} x_j = b_{i,} 1 \leq i \leq m.
$$
Embora todas estas formas de se escrever o sistema de equações sejam equivalentes, é útil compreender cada uma delas. A notação de somatório é poderosa, principalmente para demonstrações e considerações teóricas sobre este e muitos outros tópicos.
Sistemas lineares aparecem em um grande número de aplicações e é necessário que se aprenda técnicas para encontrar suas soluções. Para isto apresentamos as definições abaixo.
É usual, mas não obrigatório, o uso da barra de separação entre os termos \(a_{i j}\) e \(b_k\) .
Definição: Dois sistemas de equações lineares são ditos equivalentes se, e somente se, toda a solução de um deles é igualmente solução do outro.
Podemos obter sistemas equivalentes por meio das chamadas operações elementares:
(i) permutação de duas equações;
(ii) multiplicação de um das equações por um escalar;
(iii) substituição de uma das equações por sua soma com outra das equações do sistema.
Em termos das matrizes ampliadas associadas ao sistema estas mesmas operações significam as operações elementares sobre as linhas desta matriz. Exemplificando estas operações elementares sobre linhas de uma matriz temos:
(ii) Multiplicação de uma linha por um escalar: \(k L_i \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
1 & 2\\
5 & 6
\end{array} \right] 3 L_2 \rightarrow L_2 \left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
(iii) Substituição de uma linha por sua soma com outra linha: \(L_i + L_j \rightarrow L_i\),
$$
\left[ \begin{array}{ll}
3 & 4\\
3 & 6\\
5 & 6
\end{array} \right] L_1 + L_2 \rightarrow L_1 \left[ \begin{array}{ll}
6 & 10\\
3 & 6\\
5 & 6
\end{array} \right] .
$$
Definição: Duas matrizes são equivalentes se uma pode ser obtida da outra por meio de um número finito de operações elementares. Denotaremos a equivalência entre duas matrizes \(A\) e \(B\) por meio do símbolo \(A \sim B\) .
Definição: uma matriz está em sua forma linha reduzida à forma escada se
O primeiro elemento de cada linha é 1. Chamaremos de piloto a este elemento.
Cada coluna que possue um elemento piloto de alguma das linhas contém todos os demais elementos nulos.
O piloto de cada linha ocorre em colunas progressivas.
Linhas inteiramente nulas ocorrem abaixo de todas as demais.
A matriz reduzida à sua forma escada terá a forma indicada na figura.
Uma vez que as operações elementares sobre um sistema de equações lineares não alteram a solução do sistema, e que matrizes equivalentes são obtidas uma da outra por meio de operações elementares sobre suas linhas, podemos concluir que dois sistemas cujas matrizes ampliadas são equivalentes possuem a mesma solução ou soluções, quando estas existirem. Isto nos permite enunciar um método de solução.
Método de Gauss-Jordan para solução de sistema lineares
O método de Gauss-Jordan consiste no seguinte procedimento:
Dado um sistema de equações lineares começamos por escrever a sua matriz ampliada associada.
Através de operações elementares sobre linhas da matriz ampliada obtemos a matriz equivalente reduzida à forma escada.
A matriz equivalente reduzida à forma escada será associada a um sistema onde a solução do sistema original é de fácil leitura.
Vamos ilustrar estas operações elementares por meio de um exemplo. Nele indicaremos as operações realizadas sobre as linhas de uma matriz amplida apenas para efeito de acompanhanto do leitor. A operação \(L_1 + L_2 \rightarrow L_2\) , por exemplo, significa: substitua a linha 2 pela soma da linha 2 com a linha 1.
Exemplo . O sistema
\begin{eqnarray*}
x + 4 y + 3 z = 1 & & \\
2 x + 5 y + 4 z = 4 & & \\
x – 3 y – 2 z = 5 & &
\end{eqnarray*}
pode ser representado matricialmente por
$$
\left[ \begin{array}{lll}
1 & 4 & 3\\
2 & 5 & 4\\
1 & – 3 & – 2
\end{array} \right] \left[ \begin{array}{l}
x\\
y\\
z
\end{array} \right] = \left[ \begin{array}{l}
1\\
4\\
5
\end{array} \right]
$$
que é a solução do sistema inicial, como pode ser verificado por substituição direta.
Exercício resolvido: resolva o sistema
\begin{eqnarray*}
x + 2 y + 3 z = 9 & & \\
2 x – y + z = 8 & & \\
3 x – z = 3. & &
\end{eqnarray*}
A matriz ampliada associada a este sistema é
$$
A = \left[ \begin{array}{lll}
1 & 2 & 3\\
2 & – 1 & 1\\
3 & 0 & – 1
\end{array} \begin{array}{l}
9\\
8\\
3
\end{array} \right] .
$$
Para o leitor que considere isto necessário seguem alguns comentários sobre os passos executados nesta operação:
\(\{p_1 \}\) zeramos o elemento na coluna 1, onde ocorre o piloto da primeira linha;
\(\{p_2 \}\) idem para a linha 3;
\(\{p_3 \}\) introduzimos o piloto da linha 2;
\(\{p_4 \}\) apenas uma simplificação para os cálculos posteriores;
\(\{p_5 \}\) zeramos \(a_{12}\) ;
\(\{p_6 \}\) zeramos \(a_{32}\) ;
\(\{p_7 \}\) introduzimos o piloto da linha 3;
\(\{p_8 \}\) zeramos \(a_{13}\) ;
\(\{p_9 \}\) zeramos \(a_{23}\) . O procedimento é interrompido porque atingimos a matriz equivalente na forma reduzida .
é claro que não existe uma única forma para se atingir a matriz na forma escada e, algumas vezes, uma escolha apropriada de passos pode reduzir muito o trabalho necessário para atingí-la. No entanto, se um passo mais hábil ou mais rápido não for percebido, podemos executar etapas intermediárias que facilitem este processo. Para quem está aprendendo a operação pode ser preferível realizar um número maior de passos e um de cada vez.
Algumas vezes é necessário saber se existem uma ou mais soluções para um sistema linear. As definições dadas a seguir nos permitem obter esta informação mesmo sem resolvê-lo.
Definição: Seja \(A_{m \times n}\) uma matriz e \(B_{m \times n}\) sua matriz equivalente reduzida à forma escada. \(p\) ,o posto de \(A\) , é o número de linhas não nulas de \(B\) . A nulidade de \(A\) é igual ao número de colunas menos o posto, \(n – p\) .
Exemplo . Qual é o posto e a nulidade da matriz \(A\) dada abaixo?
$$
\begin{array}{ll}
A = & \left[ \begin{array}{l}
\begin{array}{llll}
1 & 2 & 1 & 0\\
– 1 & 0 & 3 & 5\\
1 & – 2 & 1 & 1
\end{array}
\end{array} \right] .
\end{array}
$$
\begin{eqnarray*}
\begin{array}{lll}
\sim & \left[ \begin{array}{lll}
1 & 0 & 14 / 9\\
0 & 1 & 1 / 9\\
0 & 0 & 0\\
0 & 0 & 0
\end{array} \right] = C & .
\end{array} & &
\end{eqnarray*}
sendo que a matriz \(B\) está em sua reduzida. O posto de \(A\) é \(p = 3\) porque \(B\) tem 3 linhas não nulas. Como \(A\) tem \(n = 4\) colunas, a nulidade de \(A\) é \(n – p = 1\) .
Continuando com a questão da existência de soluções vamos examinar alguns casos ilustrativos de sistemas e suas soluções.
(1) Sistema trivial, com uma incógnita e uma equação
$$
a x = b.
$$
Os seguintes casos podem ocorrer:
Se \(a \neq 0\) então existe uma única solução, \(x = b / a\) .
Se \(a = 0\) e \(b = 0\) o sistema é \(0 x = 0\), satisfeito por qualquer valor de \(x\) . Existem, portanto, infinitas soluções.
Se \(a = 0\) e \(b \neq 0\) o sistema \(0 x = b\) , não é satisfeito por nenhum valor de \(x\) , ou seja, não existem soluções.
(2) Sistema com uas equações e duas incógnitas.
Exemplo:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
x – 3 y = 6
\end{array} \right.
$$
Embora este seja um sistema de fácil solução por meio de uma simples substituição, para efeito de exercício da técnica aprendida, escrevemos matriz ampliada e suas matrizes equivalentes,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
1 & – 3 & 6
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 7 / 2 & – 7 / 2
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 1 & – 1
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 0 & 3\\
0 & 1 & – 1
\end{array} \right], & &
\end{eqnarray*}
ou seja, \(x = 3\) e \(y = – 1\) é a solução única do sistema. A
matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
1 & – 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 0\\
0 & 1
\end{array} \right] & &
\end{eqnarray*}
tem posto 2 enquanto a matriz ampliada também tem posto 2. Lembramos ainda que \(n = 2\) é o número de incógnitas envolvidas. Como se pode ver na figura cada equação do sistema corresponde a uma reta do plano e a solução é dada pelo único ponto comum entre elas.
Exemplo 2:
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 15
\end{array} \right.
$$
A matriz ampliada e suas matrizes equivalentes são, por exemplo,
\begin{eqnarray*}
\left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 15
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & 0
\end{array} \right], & &
\end{eqnarray*}
indicando que existem infinitas soluções, que são todos os pontos da reta \(x + y / 2 = 5 / 2\) . Observamos que as duas equações do
sistema são uma múltiplo da outra e representam a mesma reta. A matriz dos coeficientes
\begin{eqnarray*}
\left[ \begin{array}{ll}
2 & 1\\
6 & 3
\end{array} \right] \sim \left[ \begin{array}{ll}
1 & 1 / 2\\
0 & 0
\end{array} \right] & &
\end{eqnarray*}
tem posto 1 e a matriz ampliada também tem posto 1. A nulidade de \(A\) é 2 enquanto a nulidade da matriz dos coeficientes é 1. Geometricamente as duas equações do sistema são repreentadas pela mesma (uma delas é meramente um múltiplo da outra) e todos os pontos que satisfazem a primeira equação satisfazem também a segunda.
Exemplo: O sistema
$$
\left\{ \begin{array}{l}
2 x + y = 5\\
6 x + 3 y = 10
\end{array} \right.
$$
pode ser resolvido da mesma forma; a matriz ampliada e sua reduzida são
\begin{eqnarray*}
A = \left[ \begin{array}{lll}
2 & 1 & 5\\
6 & 3 & 10
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 5 / 2\\
0 & 0 & – 5
\end{array} \right] \sim \left[ \begin{array}{lll}
1 & 1 / 2 & 0\\
0 & 0 & 1
\end{array} \right], & &
\end{eqnarray*}
que representam um sistema sem solução. O posto de \(A\) é 2 e o posto da matriz dos coeficientes é 1. Geometricamente as duas linhas são equações de retas são paralelas que, por isto, não possuem pontos comuns.
Relacionando o número de equações, incógnitas e o posto das matrizes ampliada e dos coeficientes temos o seguinte resultado:
Teorema: Dado um sistema de \(m\) equações e \(n\) incógnitas, denotamos por \(p_A \)o posto da matriz ampliada e \(p_C \) o posto da matriz dos coeficientes. Então
A condição \(p_A = p_C\) é necessária e suficiente para que o sistema admita uma ou mais soluções;
A condição \(p_A = p_C = n\) é necessária e suficiente para que o sistema admita uma única solução;
Se \(p_A = p_C \lt n\) então o sistema pode ser resolvido para \(p\) incógnitas em função das \(n – p\) incógnitas restantes.
Sistema linear de 3 equações e 3 incógnitas
Sistema de três equações e três incógnitas: Cada uma das equações pode ser representada por um plano, P1, P2 e P3. Podem ocorrer, por exemplo, algumas dessas situações: (i) os planos são paralelos e não coincidentes; não existe nenhuma solução para o sistema; (ii) dois planos são coincidentes e interceptam o terceiro plano em uma reta. Neste caso existem infinitas soluções (os pontos da reta). (iii) Nenhum dos planos é paralelo a outro. Esta é a situação mostrada na figura 6 e existe uma única solução.
Equações diferenciais são equações que envolvem uma função desconhecida de uma ou mais variáveis, e suas derivadas. Para uma função real de uma única variável, \(y=y(x)\), podemos expressar estas equações sob a forma geral de
$$
F(x,\,y,\,y^{\prime},\,y^{\prime\prime},\ldots,\,y^{(n)})=0,
$$
onde usamos a notação
$$
y^{\prime}=\frac{dy(x)}{dx},\,\,\,y^{\prime\prime}=\frac{d^{2}y(x)}{dx^{2}},\ldots,\,\,\,y^{(n)}=\frac{d^{n}y(x)}{dx^{n}}.
$$
As equações que envolvem derivadas em apenas uma variável são chamadas equações diferenciais ordinárias. Caso contrário, equações que envolvem derivadas em mais de uma variável são chamadas de equações diferenciais parciais. Para não sobrecarregar a notação, sempre que não houver risco de ambiguidade, escreveremos apenas \(y\) em lugar de \(y(x),\,\,\,y^{\prime}\) em lugar de \(y^{\prime}(x)\) ou \(dy(x)/dx,\) e assim por diante.
Estas equações representam uma parte da matemática muito utilizada em aplicações na física, na engenharia e diversas outras áreas do conhecimento. A absoluta maioria das leis da física são expressas por meio de equações diferenciais, como por exemplo a lei de Newton \(F=ma\), ou as equações de Maxwell para o eletromagnetismo.
Alguns exemplos podem ajudar a esclarecer os conceitos envolvidos:
Exemplo 1. Que função é idêntica à sua própria derivada? A resposta para esta pergunta é a solução da equação diferencial \(y’=y\). Ora, podemos nos lembrar, sem o uso de nenhuma técnica de solução, que a função \(y(x)=e^{x}\) satisfaz este requisito. Observe que a resposta mais geral é \(y(x)=Ce^{x}\), onde \(C\) é uma constante qualquer.
No exemplo anterior, encontramos não apenas uma mas infinitas soluções para a equação proposta. Uma constante de integração está sempre presente na solução de uma equação diferencial de primeira ordem. Como veremos existem várias técnicas para se encontrar soluções de equações como a do exemplo 1. Uma solução de uma equação diferencial é uma função que, quando substituída na equação original, a transforma em uma identidade.
Exemplo 2. Qual é a solução (ou soluções, se existirem mais de uma) de \(y^{\prime\prime}+y=0\)?
Conhecemos duas funções elementares que satisfazem esta equação: \(y_{1}=\text{sen}\,x\) e \(y_{2}=\cos x\). Verifique, derivando duas vezes e substituindo na equação diferencial que
$$
y(x)=C_{1}\text{sen}\,x+C_{2}\cos x
$$
onde \(C_{1}\) e \(C_{2}\) são constantes arbitrárias, é solução.
Exemplo 3. Vamos procurar a equação de movimento para uma partícula submetida a uma aceleração constante \(g\). Iniciamos por descrever a posição da partícula como \(x(t)\), onde a variável independente agora é \(t\), o tempo. Usaremos a notação inventada por Newton que consiste em representar a derivada em relação ao tempo por meio de um ponto sobre a quantidade derivada. Assim sua velocidade é a derivada primeira
$$
\frac{d}{dt}x(t)=\dot{x}(t)
$$
enquanto a aceleração é a derivada segunda
$$
\frac{d^{2}}{dt^{2}}x(t)=\ddot{x}(t).
$$
A segunda lei nos diz que
$$
F=ma\Rightarrow mg=m\ddot{x}\Rightarrow\ddot{x}=g.
$$
Resolvendo primeiro para a velocidade temos que
$$
\dot{x}(t)=gt+c_{1},
$$
onde \(c_{1}\) é uma constante qualquer, notando que esta é a expressão mais geral da função que, quando derivada em relação à \(t\), resulta na constante \(g\). Já a posição da partícula é dada pela função primitiva que, ao ser derivada, resulta na velocidade acima,
$$
x(t)=\frac{1}{2}gt^{2}+c_{1}t+c_{2}
$$
como pode ser verificado diretamente, por dupla derivação e substituição na equação inicial. Podemos ainda utilizar este exemplo para esclarecer um pouco mais sobre o papel das constantes de integração,
\(c_{1}\) e \(c_{2}\). No instante \(t=0\) temos que
$$
\dot{x}(0)=c_{1},\,\,\,x(0)=c_{2},
$$
o que mostra que \(c_{1}\) é velocidade inicial da partícula enquanto \(c_{2}\) é sua posição inicial. Isto reflete um fato físico: para descrever completamente a posição de uma partícula submetida a uma aceleração \(g\) é necessário fornecer sua posição e velocidade iniciais. Renomeando \(c_{1}=v_{0},\,\,\,c_{2}=x_{0}\), respectivamente velocidade e posição iniciais, podemos escrever
$$
x(t)=x_{0}+v_{0}t+\frac{1}{2}gt^{2},
$$
que é a conhecida expressão para o movimento uniformemente acelerado.
Exemplo 4. As equações diferenciais surgem com freqüência em problemas de geometria. Por exemplo, a equação da circunferência com centro na origem e raio \(r\) é
$$
x^{2}+y^{2}=r^{2}.
$$
Considerando \(y\) uma função de \(x\) e fazendo a derivação implícita da expressão acima em relação a \(x\) obtemos
$$
x+yy^{\prime}=0,
$$
ou seja,
$$
y^{\prime}=-\frac{x}{y},
$$
que é a equação diferencial cuja solução é a equação da circunferência. Observe que \(y^{\prime}\) é a inclinação da curva em cada ponto e que o raio não aparece nesta equação. Ele fica determinado pelas condições de contorno, como veremos mais tarde.
Classificações e Definições
Equações Ordinárias e Parciais
Já vimos que as equações diferenciais ordinárias são aquelas que envolvem apenas derivadas em uma variável independente. Todos os exemplos acima são de equações ordinárias. Existem também as equações diferenciais parciais que surgem em muitas áreas da ciência. São exemplos de equações parciais:
(a) equação de onda em uma dimensão,
$$
\frac{\partial^{2}u(x,t)}{\partial x^{2}}=\frac{1}{c^{2}}\frac{\partial^{2}u(x,t)}{\partial t^{2}},
$$
onde \(u\) representa um deslocamento no meio de propagação ou vetor de onda, para o caso em que não existe um meio de propagação, como ocorre com as ondas eletromagnéticas. Pode-se mostrar que \(c\) é a velocidade de propagação da onda.
(b) a equação de difusão do calor
$$
\frac{\partial T(x,t)}{\partial t}=k\frac{\partial^{2}T(x,t)}{\partial x^{2}},
$$
onde \(T\) é a temperatura e \(k\) uma constante que depende do material por onde o calor se difunde.
(c) em três dimensões, o potencial elétrico descrito por \(\phi(x,y,z)\) satisfaz a equação de Laplace
$$
\nabla^{2}\phi=0
$$
na ausência de cargas elétricas, onde \(\nabla^{2}\) é o Laplaciano. Em coordenadas cartesianas,
$$
\nabla^{2}=\frac{\partial^{2}}{\partial x^{2}}+\frac{\partial^{2}}{\partial y^{2}}+\frac{\partial^{2}}{\partial z^{2}}.
$$
Na presença de cargas elétricas o potencial satisfaz a equação de Poisson
$$
\nabla^{2}\phi=-\frac{\rho}{\varepsilon_{0}},
$$
onde \(\rho\) é a distribuição de cargas e \(\varepsilon_{0}\) uma constante característica do meio.
Estes exemplos ilustram a existência das equações parciais e não podem ser plenamente compreendidos por enquanto. Neste curso trataremos apenas das equações diferenciais ordinárias, e não das diferenciais parciais. No entanto elas são frequentemente resolvidas através de uma separação de variáveis que as transformam em um sistema de equações ordinárias, de forma que as técnicas aqui estudadas são importantes para as suas soluções.
Ordem de uma Equação Diferencial
A ordem de uma equação diferencial é definida como sendo a derivada de maior ordem que nela aparece. Equações de primeira ordem contém apenas a derivada primeira, de segunda ordem a derivada segunda e assim por diante. Equações de primeira e segunda ordem são as mais comuns em aplicações na física e na engenharia. A equação do exemplo 4,
$$
y^{\prime}=-\frac{x}{y},
$$
é de primeira ordem, enquanto no exemplo 3, a equação de Newton, envolve uma equação de segunda ordem,
$$
\ddot{x}=g.
$$
A equação
$$
y^{\prime\prime\prime}+y=0
$$
é uma equação de terceira ordem.
Equações lineares e não lineares
Se uma equação diferencial pode ser escrita sob a forma
$$
a_{0}y+a_{1}y’+a_{2}y^{\prime\prime}+a_{3}y^{\prime\prime\prime}+\cdots a_{n}y^{(n)}=r(x),
$$
onde \(a_{i}\,\,(i=0,1,2,…)\) são constantes, então ela é dita uma equação linear. Caso contrário ela é não linear. As equações diferenciais
$$
y^{\prime\prime}+2y’+y=0,
$$
$$
3y^{\prime}+2y=1
$$
são lineares, enquanto
$$
y^{\prime}+y^{2}=0,
$$
$$
yy^{\prime\prime}+y’=0
$$
são não lineares. Equações não lineares são, em geral, mais difíceis de serem resolvidas.
Exemplo 5. Uma situação interessante onde aparece uma equação não linear é o que descreve o movimento do pêndulo simples. Denotando por \(\theta(t)\) o ângulo que o pêndulo faz com a vertical então a evolução temporal deste ângulo é descrita pela equação
$$
\frac{d^{2}\theta}{dt^{2}}+\frac{g}{l}\text{sen}\,\theta=0,
$$
Pêndulo Simples
onde \(g\) é a aceleração da gravidade e \(l\) o comprimento do pêndulo. Se o pêndulo oscila com baixa amplitude em torno da posição de repouso então podemos fazer uma simplificação nesta equação. Observando que, para ângulos pequenos \(\text{sen}\,\theta\approx\theta\), reescrevemos a equação do pêndulo como
$$
\frac{d^{2}\theta}{dt^{2}}+\frac{g}{l}\theta=0,\;\;\;\text{ ou } \;\;\; \ddot{\theta}+k^{2}\theta=0,
$$
onde fizemos \(k=g/l.\) Esta é uma equação linear, a equação do oscilador harmônico, cujas soluções são
$$
\theta(t)=c_{1}\cos\sqrt{k}t+c_{2}\text{sen}\,\sqrt{k}t,
$$
como podemos verificar facilmente, por substituição.
A Solução de uma Equação Diferencial
Dada uma equação diferencial
$$
F(x,\,y,\,y^{\prime},\,y^{\prime\prime},\ldots,\,y^{(n)})=0
$$
buscamos encontrar a função desconhecida \(y(x)\). Uma solução da equação diferencial é a função (ou funções) que, quando inserida na equação original a transforma em uma identidade.
Exemplo 6. Aprenderemos em breve a encontrar a solução da equação
$$
(1+x)y^{\prime}=y.
$$
Por enquanto, podemos verificar que
$$
y(x)=C(1+x)
$$
é solução. Para ver isto derivamos \(y\),
$$
y^{\prime}=C
$$
e substituimos \(y\) e \(y’\) na equação 1 para obter
$$
(1+x)C=C(1+x),
$$
que é uma identidade.
Problema de Contorno ou Valores Iniciais
Vimos que a solução de uma equação diferencial de primeira ordem é, na verdade, uma família de soluções que depende de um parâmetro desconhecido, uma constante de integração, e que duas destas constantes aparecem na solução de uma equação de segunda ordem. Condições adicionais devem ser adicionadas para que estas constantes sejam determinadas, sobre a forma de valores fixados para a solução em um ponto ou mais de seu domínio.
Exemplo 7. Retornando ao problema do exemplo 6 acima, e adicionando uma condição de contorno, temos
$$
(1+x)y^{\prime}=y,\,\,\,y(1)=\frac{1}{2}.
$$
A família de funções
$$
y(x)=C(1+x)
$$
é chamada de solução geral do problema. Com a condição de contorno podemos determinar um valor para a constante \(C\):
$$
y(1)=2C=\frac{1}{2}\Rightarrow C=\frac{1}{4}.
$$
Desta forma encontramos
$$
y(x)=\frac{1}{4}(1+x).
$$
que é a chamada solução particular do problema.
Exemplo 8. A equação diferencial do exemplo 4,
$$
y^{\prime}=-\frac{x}{y}
$$
tem como solução a equação da circunferência
$$
x^{2}+y^{2}=r^{2},
$$
Figura 1. Soluções de y’=-x/y.
onde \(r\) é uma constante indeterminada. Uma condição de contorno ou valor inicial pode ser utilizado para especificar apenas uma das circunferências como a solução desejada. Digamos que, por qualquer motivo, queremos satisfazer a condição \(y(1)=1\).
Neste caso o valor de \(r\) fica determinado, \(r=\sqrt{2}\), e a solução particular do problema é
$$
x^{2}+y^{2}=2.
$$
Geometricamente, todas as circunferências com centro na origem e raio qualquer são soluções de (2) enquanto apenas uma delas, a que tem raio igual a \(\sqrt{2}\), passa pelo ponto \((1,1)\).
(1) Consulte qualquer livro de Cálculo Integral para rever os conceitos e principais técnicas de integração. Há uma revisão sobre as técnicas básicas no Apêndice.
Exercícios
1.Calcule as seguintes integrais:
a. \( \int\frac{dx}{x+1}\)
b. \( \int\frac{dx}{x^{2}+1}\)
c. \( \int\frac{dx}{x^{3}}\)
d. \( \int(e^{x}-e^{-x})dx\)
e. \( \int\text{sen}\,x\cos xdx\)
f. \( \int te^{4t}dt\)
g. \( \int x^{2}e^{x}dx\)
h. \( \int\ln(1-x)dx \)
i. \( \int_{0}^{1}(1-x^{2})dx\)
2. Encontre uma primitiva da função \(f(x)=\frac{1}{x^{2}}+1\) que se anula no ponto x=2.
Nos exercícios seguintes verifique que a função \(y(x)\) dada é solução da equação diferencial. Encontre o valor da constante de integração \(c\) para que o valor inicial dado seja satisfeito:
Esta seção contém referência a conceitos que só mais tarde serão estudados. Ela serve como uma motivação para o estudo das circunstâncias históricas envolvidas no desenvolvimento desta área da matemática. Não estudaremos neste texto as equações diferenciais parciais nem as não lineares. Consulte a bibliografia para referências nestas áreas.
Equações diferenciais são um ramo importante do cálculo e da análise e representam, provavelmente, a parte da matemática que maior número de aplicações encontra na física e na engenharia. Sua história tem origem no início do cálculo, desenvolvido por Newton e Leibniz no século XVII. Equações que envolvem as derivadas de uma função desconhecida logo apareceram no cenário do cálculo, mas, logo se constatou que elas podem ser de difícil tratamento. As mais simples são aquelas que podem ser diretamente integradas, por meio do uso do método de separação de variáveis, desenvolvido por Jakob Bernoulli e generalizado por Leibniz. No século XVIII muitas equações diferenciais começaram a surgir no contexto da física, astronomia e outras aplicações.
A equação de Newton para a gravitação universal foi usada por Jakob Bernoulli para descrever a órbita dos planetas em torno do Sol. Já nesta época ele podia usar as coordenadas polares e conhecia a catenária como solução de algumas equações. Halley usou os mesmos princípios para estudar o movimento do cometa que hoje tem o seu nome. Johann Bernoulli, irmão de Jakob, foi um dos primeiros a usar os conceitos do cálculo para modelar matematicamente fenômenos físicos e usar equações diferenciais para encontrar suas soluções.
Ricatti (1676 — 1754) levou a sério o estudo de uma equação particular, mais tarde também estudada pelos irmãos Bernoulli. Taylor foi o primeiro a usar o desenvolvimento de funções em séries de potência para encontrar soluções. Não havia, no entanto, uma teoria global ou unificada sobre o tema. Leonhard Euler, o primeiro matemático a compreender profundamente o significado das funções exponencial, logaritmica e trigonométricas, desenvolveu procedimentos gerais para a solução de equações diferenciais. Além de usar as funções elementares ele desenvolveu novas funções, definidas através de suas séries de potências como soluções de equações dadas. Sua técnica dos coeficientes indeterminados foi uma das etapas deste desenvolvimento. Em 1739 Euler desenvolveu o método da variação dos parâmetros e, mais tarde, técnicas numéricas que fornecem “soluções aproximadas” para quase todo o tipo de equação. Posteriormente muitos outros estudiosos se dedicaram ao assunto, refinando e ampliando as técnicas de Euler.
O trabalho de d’Alembert na física matemática permitiu que ele encontrasse soluções para algumas equações diferenciais parciais simples. Lagrange seguiu de perto os trabalhos de Euler e aperfeiçoou os estudos aplicados à mecânica, em particular no problema de três corpos e no estudo da energia potencial. Em 1788 ele introduziu as equações gerais do movimento para sistemas dinâmicos, o que hoje é conhecido como as equações de Lagrange, onde fazia uso do chamado cálculo variacional. O trabalho de Laplace na estabilidade do sistema solar produziu novos avanços, incluindo o uso de técnicas numéricas. Em 1799 ele apresentou o conceito de Laplaciano de uma função. Já o matemático Legendre trabalhou com equações diferenciais, primeiramente motivado pelo estudo do movimento de projéteis, examinando pela primeira vez a influência de fatores como a resistência do ar e velocidades iniciais.
Muitos dos desenvolvimentos seguintes se referem às equações diferenciais parciais. Parte importante deste desenvolvimento foi obtida por Joseph Fourier em sua busca por soluções do problema de difusão do calor. Ele desenvolveu uma representação de funções sob a forma de séries infinitas de funções trigonométricas, úteis para o tratamento de equações parciais e diversas outras aplicações. Até o início do século XIX o estudo das equações diferenciais, e do cálculo como um todo, padeciam de uma deficiência crônica no que se refere à fundamentação teórica de seus princípios. Esta fundamentação começou então a ser construída, iniciando pelo entendimento da teoria e conceitos das funções de variáveis complexas. Gauss e Cauchy foram os principais responsáveis por estes avanços. Gauss usou equações diferenciais para aprimorar as teorias de órbitas e da gravitação planetárias e estabeleceu a teoria do potencial como parte importante da matemática. Ele mostrou que as funções de variáveis complexas eram a chave para compreender muitos dos resultados exigidos pelas equações diferenciais. Cauchy usou equações diferenciais para modelar a propagação das ondas na superfície de um líquido. Ele foi o primeiro a definir de forma satisfatória a noção de convergência de uma série infinita, dando início à análise rigorosa do cálculo e das equações diferenciais. Cauchy também desenvolveu uma teoria sistemática para os números complexos e a usou a transformada de Fourier para encontrar soluções algébricas para as equações diferenciais. A solução de equações diferenciais nas proximidades de um ponto singular foi elaborada por Frobenius.
Muitas outras contribuições têm sido acumuladas ao longo da história mais recente. Poisson utilizou as técnicas das equações diferenciais em aplicações na física e em sistemas mecânicos, incluindo a elasticidade e vibrações. George Green aperfeiçoou os fundamentos da matemática utilizada em aplicações da gravitação, da eletricidade e do magnetismo. Baseados nestes fundamentos Thomson, Stokes, Rayleigh e Maxwell, construiram a teoria moderna do eletromagnetismo. Bessel utilizou a teoria das equações para o estudo da astronomia, buscando analisar perturbações dos planetas sobre as suas órbitas. Joseph Liouville foi o primeiro a resolver problemas de valor de contorno usando equações integrais, um método mais tarde aperfeiçoado Fredholm e Hilbert. Em meados do século XIX novas ferramentas se tornaram necessárias para a solução de sistemas de equações diferenciais. Jacobi desenvolveu a teoria dos determinantes e transformações para a solução de integrais múltipla e equações diferenciais. O conceito de jacobiano de uma transformação foi elaborado em 1841. Cayley também contribuiu para teoria das matrizes e determinantes publicando diversos artigos sobre matemática teórica, dinâmica e astronomia. Gibbs estudou a termodinâmica, eletromagnetismo e mecânica, sendo considerado a pai da análise vetorial. Os avanços durante o final do século XIX adquiriram uma natureza cada vez mais teórica. Em 1876 Lipschitz obteve a prova dos teoremas de existência para equações de primeira ordem. Uma contribuição importante para o estudo das equações diferenciais, apesar de não imediatamente reconhecida pela comunidade dos matemáticos devido a sua falta de rigor, foi feita por Oliver Heaviside. Entre 1880 e 1887 ele desenvolveu o cálculo operacional e o uso da transformada de Laplace para reduzir equações diferenciais a equações algébricas de solução muito mais simples. Como vantagem adicional seu formalismo permite o tratamento de sistemas com entradas descontínuase é extensamente usado na engenharia, especialmente na eletrônica e no tratamento de sinais.
No século XX os maiores impulsos vieram do desenvolvimento de métodos numéricos mais eficientes e da consideração de equações e sistemas de equações diferenciais não lineares. Carl Runge desenvolveu um método para resolver equações associadas à mecânica quântica, atualmente conhecido como método de Runge-Kutta. As equações diferenciais não lineares são um tema que permanece em aberto, recebendo até hoje contribuições importantes. Muitos fenônenos naturais são descritos por equações não lineares. Uma das características destes sistemas consiste na dependência muito sensível das condições iniciais, o que gera comportamentos de difícil previsibilidade que têm sido denominados de caos. Um exemplo importante de sistema não linear é o sistema de equações que descreve o movimento de muitos corpos, por exemplo na descrição do movimento planetário no sistema solar. Outros sistemas não lineares representam o crescimento de espécies em competição, na biologia, o fluxo turbulento de fluidos, a descrição das condições meteorológicas, entre outros. Henry Poincaré (1854 — 1912), matemático, físico e filósofo da ciência, foi um dos precursores nesta pesquisa, sendo o primeiro a descobrir o comportamento caótico das soluções para sistemas de três corpos. Liapunov, Lorenz e muitos outros matemáticos trabalharam nesta área que continua em franca expansão e é de se esperar que o progresso nesta área traga grandes inovações na descrição de diversas áreas do conhecimento.
As funções exponencial e logaritmo são utilizadas com freqüência na solução de equações diferenciais. Elas podem ser definidas de várias formas. Por exemplo, o logaritmo neperiano (de base e) é a área sob o gráfico da função \(1/x,\) de \(x=1\) até \(x\), ou seja
Logaritmo natural
$$
\ln x=\int_{1}^{x}\frac{dt}{t}.
$$Observamos desta definição que \(\ln1=0,\) que o logaritmo é uma função estritamente crescente e não está definida em \(x=0.\) A função exponencial, \(\exp(x)=\text{e}^{x},\) é a inversa do logaritmo,
$$
\ln x=y\Rightarrow\text{e}^{y}=x.
$$
Podemos usar as propriedades da exponencial para nos lembrar de algumas propriedades do logaritmo: observando que as seguintes igualdades são equivalentes
$$
y=\ln x^{n}\Longleftrightarrow\text{e}^{y}=x^{n},
$$
tomamos a raiz enésima dos dois lados
$$
x=\text{e}^{y/n}\Rightarrow\frac{y}{n}=\ln x
$$
o que resulta em
$$
y=n\ln x.
$$
Portanto
$$
\ln x^{n}=n\ln x.
$$
Além disto, se
$$
\ln x+\ln y=z
$$
então
$$
\text{e}^{z}=\text{e}^{\ln x+\ln y}=\text{e}^{\ln x}\text{e}^{\ln y}=xy\Rightarrow z=\ln\left(xy\right)
$$
e, portanto
$$
\ln\left(xy\right)=\ln x+\ln y.
$$
Observe que
$$
\ln x-\ln y=\ln x+\ln y^{-1}=\ln\left(\frac{x}{y}\right).
$$
A partir da exponencial definimos as funções seno hiperbólico e cosseno hiperbólico da seguinte forma
$$
\begin{array}{lll}
\text{senh }x=\frac{1}{2}(\text{e}^{x}-\text{e}^{-x}),
\ \;\; \cosh x=\frac{1}{2}\left(\text{e}^{x}+\text{e}^{-x}\right),
\ \;\; \tanh x=\frac{\text{ senh }x}{\cosh x}.
\end{array}
$$
Observe que \(\text{ senh }x\) é uma função impar enquanto \(\cosh x\) é par. Mostre, como exercício, as seguintes relações:
$$
\frac{d}{dx}\text{ senh }x=\cosh x,\ \ \ \frac{d}{dx}\cosh x=\text{ senh }x,\ \ \ \cosh^{2}x-\text{senh}^{2}x=1.
$$
A fórmula de Euler, que usaremos com freqüência ao longo do texto, pode ser justificada da seguinte maneira: partimos da expansão de Taylor para as funções exponencial, seno e cosseno, válidas para todo \(x\in \mathbb{R}\),
$$
\begin{array}{l}
\text{e}^{x}= \sum_{n=0}^{\infty}\frac{x^{n}}{n!}=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}+\cdots,
\\
\cos x= \sum_{n=0}^{\infty}\frac{\left(-1\right)^{n}x^{2n}}{\left(2n\right)!}=1-\frac{x^{2}}{2!}+\frac{x^{4}}{4!}+\cdots,
\\
\text{ sen }x= \sum_{n=0}^{\infty}\frac{\left(-1\right)^{n}x^{2n+1}}{\left(2n+1\right)!}=x-\frac{x^{3}}{3!}+\frac{x^{5}}{5!}+\cdots.
\end{array}
$$
Em seguida fazemos \(x=i\theta\) na expansão da exponencial, para obter
$$
\text{e}^{i\theta}= 1+i\theta+\frac{\left(i\theta\right)^{2}}{2!}+\frac{\left(i\theta\right)^{3}}{3!}+\frac{\left(i\theta\right)^{4}}{4!}+\frac{\left(i\theta\right)^{5}}{5!}+\frac{\left(i\theta\right)^{6}}{6!}+\cdots
$$
$$
=1+i\theta-\frac{\theta^{2}}{2!}-\frac{i\theta^{3}}{3!}+\frac{\theta^{4}}{4!}+\frac{i\theta^{5}}{5!}-\frac{\theta^{6}}{6!}+\cdots.
$$
onde usamos o fato de que \(i^{2}=-1,\) \(i^{3}=-i,\) etc. Agrupando os termos reais e imaginários temos
$$
\text{e}^{i\theta}=1-\frac{\theta^{2}}{2!}+\frac{\theta^{4}}{4!}-\frac{i\theta^{6}}{6!}+\cdots+i\left(\theta-\frac{\theta^{3}}{3!}+\frac{\theta^{5}}{5!}+\cdots\right),
$$
ou seja,
$$
\text{e}^{i\theta}=\cos\theta+i\text{ sen }\theta.
$$
Desta forma podemos definir a função exponencial de um número complexo qualquer, \(z=\varphi+i\theta,\) como
$$
\text{e}^{z}=\text{e}^{\varphi+i\theta}=\text{e}^{\varphi}\text{e}^{i\theta}=\text{e}^{\varphi}\left(\cos\theta+i\text{ sen }\theta\right).
$$
Técnicas de Integração
Dizemos que \(F(x)\) é uma primitiva de \(f(x)\) se
$$
\frac{dF\left(x\right)}{dx}=f(x).
$$
A diferencial da função \(F\) é definida como
$$
dF\left(x\right)=f(x)dx.
$$
Se \(F\) é primitiva de \(f\) defimos a integral de \(f(x)\) como
$$
\int f(x)dx=F\left(x\right)+c
$$
onde \(c\) é uma constante qualquer. Esta constante, a chamada constante de integração, é essencial na solução de equações diferenciais. Observe que, se \(F\left(x\right)\) é uma primitiva, \(F\left(x\right)+c\) também é. Algumas integrais mais simples podem ser calculadas por simples inspecção, se conhecermos uma primitiva do integrando.
Por exemplo
$$
\int\cos xdx=\text{ sen }x+c, \;\;\text{ porque }\;\;\frac{d}{dx}\left(\text{ sen }x\right)=\cos x.
$$
Outros exemplos:
$$
\int\frac{dx}{x}=\ln x+c, \;\; \int\text{e}^{x}dx=\text{e}^{x}+c,\;\;\int x^{n}dx=\frac{x^{n+1}}{n+1}+c.
$$
Mudança de Variáveis:
Algumas vezes uma integral pode ser colocada sob a forma de uma integral conhecida ou tabelada através de uma troca de variáveis. Por exemplo, para calcular a integral
$$
I_{1}=\int\text{ sen }\left(2x+1\right)dx
$$
fazemos a troca
$$
u=2x+1\Rightarrow du=2dx.
$$
Resolvemos a integral em termos da variável \(u\) e, em seguida, reinserimos a variável inicial \(x,\)
$$
I_{1}=\frac{1}{2}\int\text{ sen }udu=-\frac{1}{2}\cos u+c=-\frac{1}{2}\cos\left(2x+1\right)+c.
$$
Como outro exemplo, calculamos a integral
$$
I_{2}=\int x\text{e}^{-x^{2}}dx,
$$
trocando a variável,
$$
u=-x^{2}\Rightarrow du=-2xdx,
$$
que, substuitida na integral fornece
$$
I_{2}=-\frac{1}{2}\int\text{e}^{u}du=-\frac{1}{2}\text{e}^{u}+c=-\frac{1}{2}\text{e}^{-x^{2}}+c.
$$
Outro exemplo:
$$
I_{3}=\int\frac{1}{x-1}dx.
$$
Faça \(u=x-1,\;du=dx.\) A integral é
$$
I_{3}=\int\frac{1}{u}\,du=\ln u+c=\ln\left(x-1\right)+c.
$$
Integração por partes
Se \(u(x)\) e \(v(x)\) são funções deriváveis então vale a relação
$$
\int udv=uv-\int vdu.
$$
Vamos usar esta relação para calcular a seguinte integral
$$
I_{4}=\int x\text{e}^{-2x}dx.
$$
Identificando \(u\) e \(v\) da seguinte forma,
$$
u=x\Rightarrow du=dx;\;\;dv=\text{e}^{-2x}dx\Rightarrow v=\int\text{e}^{-2x}dx=-\frac{\text{e}^{-2x}}{2},
$$
temos
$$
I_{4}=-\frac{1}{2}x\text{e}^{-2x}+\frac{1}{2}\int\text{e}^{-2x}dx=-\frac{1}{2}\left(x+\frac{1}{2}\right)\text{e}^{-2x}+c.
$$
Outro exemplo: para calcular
$$
I_{5}=\int\text{e}^{2x}\text{ sen }xdx.
$$
identificamos agora as funções
$$
u=\text{e}^{2x} \Rightarrow du=2\text{e}^{2x}dx,
$$
$$
dv=\text{ sen }xdx \Rightarrow v=-\cos x.
$$
Usando a fórmula para a integração por partes temos
$$
I_{5}=-\text{e}^{2x}\cos x+2\int\text{e}^{2x}\cos xdx,
$$
onde trataremos a integral, mais uma vez, por partes, fazendo
$$
\begin{array}{ll} u=\text{e}^{2x} \Rightarrow du=2\text{e}^{2x}dx,
dv=\cos xdx \Rightarrow v=\text{ sen }x. \end{array}
$$
Agora temos
$$
I_{5}=-\text{e}^{2x}\cos x+2\text{e}^{2x}\text{ sen }x-4\int\text{e}^{2x}\text{ sen }xdx,
$$
ou, observando que a última integral é exatamente a integral que procuramos resolver,
$$
I_{5}=-\text{e}^{2x}\cos x+2\text{e}^{2x}\text{ sen }x-4I_{5}.
$$
Isto nos permite concluir que
$$
I_{5}=\frac{1}{5}\left(2\text{ sen }x-\cos x\right)\text{e}^{2x}+c.
$$
Frações Parciais:
A técnica de frações parciais pode ser bastante útil em várias situações. Ela consiste em modificar o integrando, quando possível, para reescrevê-lo sob a forma de uma soma de frações mais simples de serem integradas. Por exemplo, vamos calcular a integral
$$
I_{6}=\int\frac{dx}{x^{2}-1}.
$$
Reescrevemos o integrando como a soma de duas frações
$$
\frac{1}{x^{2}-1}=\frac{1}{\left(x+1\right)\left(x-1\right)}=\frac{A}{\left(x+1\right)}+\frac{B}{\left(x-1\right)},
$$
onde \(A\) e \(B\) são constantes a serem determinadas. Para encontrar estas constantes somamos os dois últimos termos e comparamos o resultado com a fração original
$$
\frac{A\left(x-1\right)+B\left(x+1\right)}{\left(x+1\right)\left(x-1\right)}=\frac{\left(A+B\right)x+B-A}{x^{2}-1}=\frac{1}{x^{2}-1},
$$
igualdade que só pode ser obtida se
$$
A+B=0,\;\; B-A=1 \Rightarrow A=-\frac{1}{2},\;B=\frac{1}{2}.
$$
Portanto o integrando é
$$
\frac{1}{x^{2}-1}=-\frac{1}{2}\frac{1}{\left(x+1\right)}+\frac{1}{2}\frac{1}{\left(x-1\right)}
$$
e a integral procurada é
$$
I_{6}=-\frac{1}{2}\int\frac{dx}{\left(x+1\right)}+\frac{1}{2}\int\frac{dx}{\left(x-1\right)}=-\frac{1}{2}\ln\left(x+1\right)+\frac{1}{2}\ln\left(x-1\right)+c,
$$
ou, usando as propriedades do logaritmo,
$$
I_{6}=\frac{1}{2}\ln\left(\frac{x-1}{x+1}\right)+c.
$$
A integral definida
Se \(F(x)\) é uma primitiva qualquer de \(f(x)\) então a integral definida de \(f\) no intervalo \(\left[a,b\right]\) é
$$
\int_{a}^{b}f(x)dx=\left.F\left(x\right)\right\vert _{a}^{b}=F(b)-F(a).
$$
Mostraremos um exemplo de integral definida realizada por substituição de variável,
$$
I_{7}=\int_{1}^{2}x\text{e}^{1-x^{2}}dx.
$$
A troca de variável agora envolve também a troca dos limites de integração:
$$
u=1-x^{2},\; du=-2xdx, \text{ quando } x=1 \text{ temos } u=0, \text{ quando } x=2 \text{ temos } u=-3.
$$
A integral então se torna
$$
I_{7}=-\frac{1}{2}\int_{0}^{-3}\text{e}^{u}du=\frac{1}{2}\int_{-3}^{0}\text{e}^{u}du=\frac{1}{2}\left.\text{e}^{u}\right\vert _{-3}^{0}=\frac{1}{2}\left(1-\frac{1}{\text{e}^{3}}\right).
$$
Sequências e Séries Infinitas
Sequências Infinitas
Definiremos uma seqüência infinita como um conjunto infinito de números que podem ser colocados em uma relação biunívoca com o conjunto dos números inteiros positivos. Denotaremos por \(\left\{ a_{n}\right\} \) a uma seqüência, sendo \(a_{n},\) com \(n=1,2,…\) os elementos individuais desta seqüência.
Exemplo 1. \(\left\{ a_{n}\right\} =\left\{ \frac{1}{n}\right\} \) é a seqüência com termo genérico \(a_{n}=1/n.\) Neste caso
$$
\left\{ a_{n}\right\} =\left\{ 1,\,\frac{1}{2},\,\frac{1}{3},\,\cdots\right\} .
$$
Definição: Dizemos que a seqüência converge para um número \(L,\) ou tem limite \(L,\) se, dado qualquer número \(\varepsilon>0\) existe um número \(N\) tal que
$$
n>N\Rightarrow\left|a_{n}-L\right|<\varepsilon.
$$
Usaremos como notação
$$
L=\lim_{n\rightarrow\infty}a_{n},\;\;\text{ ou }a_{n}\rightarrow L.
$$
Observe que, se \(\left|a_{n}-L\right|<\varepsilon\) então
$$
-\varepsilon<a_{n}-L<\varepsilon\Longleftrightarrow L-\varepsilon<a_{n}<L+\varepsilon.
$$
Portanto, dizer que uma sequência converge para \(L\) significa dizer que \(a_{n}\) fica arbitrariamente próximo de \(L\) tomando-se \(n\) suficientemente grande. Se uma seqüência não converge para nenhum número dizemos que ela diverge.
Exemplo 2. A sequência do exemplo 1, \(a_{n}=1/n\) converge para \(L=0\).
Exemplo 3. A seguinte sequência converge para \(L=2/3\)
$$
a_{n}=\frac{2n^{2}+n-1}{3n^{2}-n}.
$$
Para ver isto dividimos o numerador e o denominador por \(n^{2}\),
$$
L=\lim_{n\rightarrow\infty}\frac{2n^{2}+n-1}{3n^{2}-n}=\lim_{n\rightarrow\infty}\frac{2+1/n-1/n^{2}}{3-1/n}=\frac{2}{3},
$$
onde usamos o fato de que \(1/n\rightarrow0\) e \(1/n^{2}\rightarrow0.\)
Séries Infinitas:
Definiremos uma série infinita como a soma dos elementos de uma seqüência \(\left\{ a_{n}\right\} .\) Denotaremos esta série por
$$
S=\sum_{n=1}^{\infty}a_{n}=a_{1}+a_{2}+a_{3}+\cdots.
$$
A soma de infinitos termos não tem um significado óbvio e imediato. Para atribuir a ela um sentido não ambíguo definiremos antes a soma dos \(N\) primeiros termos da série, denominada a soma reduzida,
$$
S_{N}=\sum_{n=1}^{N}a_{n}.
$$
Observe agora que o conjunto destas somas reduzidas forma uma seqüência
$$
\left\{ S_{n}\right\}:\;\; S_{1},\,S_{2},\,S_{3},\cdots,
$$
que pode convergir ou não. Dizemos que a série infinita converge para um número \(L\) se a seqüência \(\left\{ S_{n}\right\} \) converge para \(L,\) ou seja
$$
S_{n}\rightarrow L\Longleftrightarrow\sum_{n=1}^{\infty}a_{n}=L.
$$
Caso contrário a série diverge e denotamos
$$
\sum_{n=1}^{\infty}a_{n}=\infty\;\;\text{ ou }\sum_{n=1}^{\infty}a_{n}=-\infty,
$$
conforme o caso.
Exemplo 4. Um exemplo interesssante de uma série convergente é o seguinte:
$$
\sum_{n=0}^{\infty}\frac{1}{n!}=1+1+\frac{1}{2!}+\frac{1}{3!}+\cdots=\text{e},
$$
onde, por convenção, fazemos \(0!=1.\) Este é um caso particular da série mais geral
$$
\sum_{n=0}^{\infty}\frac{x^{n}}{n!}=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}+\cdots=\text{e}^{x}.
$$
No último exemplo a função exponencial foi escrita como uma soma infinita de termos em potências de \(x.\) As séries de potências são particularmente importantes no estudo das equações diferenciais e são o motivo pelo qual revisamos aqui este tema. Voltaremos a elas em breve.
Testes de convergência
Os seguintes testes são os mais utilizados para a verificação de convergencia de uma série.
Teste da Comparação:
Se duas séries \(\Sigma a_{n}\) e \(\Sigma b_{n}\) são séries de termos não negativos (ou seja, se \(a_{n}\geq0\) e \(b_{n}\geq0\) para todo \(n\)) e \(a_{n}\leq b_{n}\) para todo \(n,\) então:
i. se \(\Sigma b_{n} \;\text{ converge } \Rightarrow \Sigma a_{n}\,\) converge,
ii. se \( \Sigma a_{n} \;\text{ diverge } \Rightarrow \Sigma b_{n}\,\) diverge.
Teste da Razão:
Se \(\Sigma a_{n}\) é uma séries de termos positivos, definimos o limite
$$
R=\lim_{n\rightarrow\infty}\frac{a_{n+1}}{a_{n}}.
$$
Então:
se \(R \lt 1 \Rightarrow \Sigma a_{n}\) converge,
se \(R \gt 1 \Rightarrow \Sigma a_{n}\) diverge,
se \(R=1,\) o teste é inconclusivo.
Teste da Integral:
Se \(f(x)\) é uma função positiva não crescente para \(x>0,\) então a série \(\Sigma f(n)\) converge se, e
somente se, a integral imprópria \(\int_{1}^{\infty}f(x)dx\) converge. Além disto vale a desigualdade
Exemplo 5. Usamos o teste da razão para testar a convergência da série
$$
\sum_{n=1}^{\infty}\frac{n^{2}}{n!}.
$$
Temos, neste caso,
$$
a_{n}=\frac{n^{2}}{n!},\;\;a_{n+1}=\frac{\left(n+1\right)^{2}}{(n+1)!}
$$
Calculamos o limite
$$
R=\lim_{n\rightarrow\infty}\frac{\left(n+1\right)^{2}}{(n+1)!}\frac{n!}{n^{2}}=\lim_{n\rightarrow\infty}\frac{1}{n+1}\left(\frac{n+1}{n}\right)^{2}=\lim_{n\rightarrow\infty}\frac{n+1}{n^{2}}=0.
$$
Como \(R \lt 1\) concluimos que a série converge.
Séries de Maclaurin e de Taylor
Uma função que pode ser expressa em termos de uma série infinita de potências em torno do ponto \(x=x_{0},\)
$$
f(x)=a_{0}+a_{1}\left(x-x_{0}\right)+a_{2}\left(x-x_{0}\right)^{2}+\cdots=\sum_{n=0}^{\infty}a_{n}\left(x-x_{0}\right)^{n}\label{seri1}
$$
é dita uma função analítica (neste ponto). Os coeficientes \(a_{n}\) podem ser obtidos do seguinte modo. Calcule o valor de \(f\) e suas derivadas no ponto \(x_{0}\)
$$
f(x_{0})=a_{0},
$$
$$
f^{(3)}(x)=2.3a_{3}\Rightarrow a_{3}=\frac{1}{6}f^{(3)}(x_{0}).
$$
Continuando este procedimento podemos calcular qualquer um dos coeficientes da série, obtendo
$$
a_{n}=\frac{1}{n!}f^{(n)}(x_{0}).
$$
Com estes coeficientes a série é a chamada série de Taylor,
$$
f(x)=\sum_{n=0}^{\infty}\frac{1}{n!}f^{(n)}(x_{0})\left(x-x_{0}\right)^{n}\label{Taylor}
$$
onde \(f^{(n)}(x_{0})\) indica a derivada n-ésima calculada no ponto \(x=x_{0}\). Uma série de Maclaurin é uma série de Taylor que descreve o comportamento de uma função em torno do ponto \(x_{0}=0\).
Resumindo:
Sobre a série de potências \( S=\sum_{n=0}^{\infty}a_{n}\left(x-x_{0}\right)^{n} \) podemos coletar as seguintes propriedades:
(i) \(S\) converge (escolhido um valor para \(x\)) se existe o limite
$$
\lim_{N\rightarrow\infty}\sum_{n=0}^{N}a_{n}\left(x-x_{0}\right)^{n}.
$$
(ii) Se a série converge absolutamente, ou seja, existe o limite
$$
\lim_{N\rightarrow\infty}\sum_{n=0}^{N}\left|a_{n}\left(x-x_{0}\right)^{n}\right|,
$$
então ela converge.
(iii) Teste da razão: Definindo
$$
R=\lim_{n\rightarrow\infty}\left|\frac{a_{n+1}\left(x-x_{0}\right)^{n+1}}{a_{n}\left(x-x_{0}\right)^{n}}\right|=\left|x-x_{0}\right|\lim_{n\rightarrow\infty}\left|\frac{a_{n+1}}{a_{n}}\right|
$$
então a série é absolutamente convergente no ponto \(x\) se \(R \lt 1\) e é divergente se \(R \gt 1\). O teste é inconclusivo se \(R=1\).
(iv) Se a série \(S\) converge em \(x=a\) então ela converge absolutamente para \(x\) no intervalo \(\left[x-a,\;x+a\right].\) Se a série \(S\) diverge em \(x=a\) então ela diverge para \(x\) fora deste intervalo.
(v) O intervalo máximo de valores de \(x\) para os quais a série converge absolutamente é chamado o intervalo de convergência. O raio de convergência é \(\rho\) é definido de forma que \(\left[x_{0}-\rho,x_{0}+\rho\right]\) é este intervalo.
Algumas considerações finais sobre o uso do sinal de somatório podem ser úteis. O índice usado pode ser substituído de acordo com as conveniências
$$
\sum_{i=1}^{N}a_{i}=\sum_{j=1}^{N}a_{j},
$$
e as parcelas da soma podem ser agrupadas ou isoladas, como no exemplo a seguir:
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{N-1}a_{i}+a_{N}=a_{1}+\sum_{i=2}^{N}a_{i},
$$
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{P}a_{i}+\sum_{i=P+1}^{N}a_{i},\;\;1\lt P\lt N.
$$
Pode ser mostrado por indução que
$$
\sum_{i=1}^{N}\left(a_{i}+b_{i}\right)=\sum_{i=1}^{N}a_{i}+\sum_{i=1}^{N}b_{i},
$$
$$
\sum_{i=1}^{N}ka_{i}=k\sum_{i=1}^{N}a_{i},\;\;\forall k\in\mathbb{R}.
$$
Se \(a_{i}=a,\) uma constante, então
$$
\sum_{i=1}^{N}a_{i}=\sum_{i=1}^{N}a=Na.
$$
Uma série de potências, se convergente, pode ser derivada termo a termo e a derivada obtida desta forma será uma representação fiel da derivada da função que ela representa:
$$
y\left(x\right)=\sum_{n=0}^{\infty}a_{n}x^{n}=a_{0}+a_{1}x+a_{2}x^{2}+\cdots+a_{r}x^{r}+\cdots,
$$
Na solução de equações diferenciais usando o método de séries de potências será útil alterar o índice para iniciar o somatório em valores diversos de \(n\). Por exemplo, podemos querer escrever a última série começando em \(n=0.\) Para fazer isto redefinimos o índice
$$
m=n-2 \Rightarrow n=m+2.
$$
A derivada segunda será escrita como
$$
y^{\prime\prime}\left(x\right)=\sum_{m=0}^{\infty}\left(m+2\right)\left(m+1\right)a_{m+2}x^{m}=\sum_{n=0}^{\infty}\left(n+2\right)\left(n+1\right)a_{n+2}x^{n},
$$
onde, no último sinal de soma restauramos o índice mudo \(n\).
Algumas Fórmulas Úteis
Para o estudo e trabalho com a matemática sempre é útil ter à disposição um bom resumo de fórmulas e propriedades matemáticas (Veja, por exemplo, Spiegel, Murray R.: Fórmulas Matemáticas, Coleção Schaum.) As seguintes fórmulas podem ser úteis na solução de equações diferenciais.
\(A\text{ sen }\lambda x+B\cos\lambda x=C\text{ sen }\left(\lambda x+\delta\right) \text{ onde } C=\sqrt{A^{2}+B^{2}},\;\delta=\text{arctg}(B/A)\)
\(\text{ sen }\left(x\pm y\right)=\text{ sen }x\cos y\pm\cos x\text{ sen }y\)
\(\cos2x=\cos^{2}x-\text{ sen }^{2}x\)
\(\cos\left(x\pm y\right)=\cos x\cos y\mp\text{ sen }x\text{ sen }y\)
Uma transformada integral é uma transformação do tipo \(f(t)\rightarrow F(s)\) obtida da seguinte forma
$$
F(s)=\int_{\alpha}^{\beta}K(s,t)f(t)dt.
$$
Dizemos que \(F\) é a transformada de \(f\), \(K\) é o núcleo da transformação. Se tomarmos o núcleo como \(K(s,t)=\text{e}^{-st}\) obtemos uma transformação particular, denominada a transformada de Laplace, definida por
(1) Consulte o Apêndice para uma revisão sobre métodos de integração.
\(F(s)\) é denominada a de transformada de Laplace da função \(f(t)\). Estas transformadas permitem a elaboração de um método muito útil na solução de equações diferenciais com valores iniciais que surgem em diversos contextos da matemática aplicada à física e engenharia. Para estudar este método faremos antes uma revisão sobre as integrais impróprias1.
Definição Uma integral é dita imprópria quando o integrando não é limitado dentro dos limites de integração ou quando o domínio de integração não é limitado. O último caso será de especial importância para nosso estudo das transformadas de Laplace. Precisaremos resolver integrais como a usada em (1). Estas integrais são definidas por meio de um limite:
$$
\int_{a}^{\infty}f(t)dt=\lim_{A\rightarrow\infty}\int_{a}^{A}f(t)dt.
$$
Se o limite existe dizemos que a integral converge. Caso contrário ela diverge.
Exemplo 1. Vamos calcular a seguinte integral imprópria, onde \(r\) é uma constante real:
$$
\int_{0}^{\infty}\text{e}^{rt}dt=\lim_{A\rightarrow\infty}\int_{0}^{A}\text{e}^{rt}dt=\lim_{A\rightarrow\infty}\frac{\text{e}^{rt}}{r}|_{0}^{A}=\lim_{A\rightarrow\infty}\frac{1}{r}(\text{e}^{rA}-1).
$$
Vemos, portanto, que a integral pode convergir ou divergir, dependendo do sinal de \(r\):
$$
\int_{0}^{\infty}\text{e}^{ll}dt=\left\{
\begin{array}{ll} -1/r & \text{ (converge) se } \; r\lt 0, \\
\infty & \text{(diverge) se } \; r\geq 0.\\
\end{array}
\right.
$$
Observe que, se \(r=0\) temos \(\lim_{A\rightarrow\infty}\int_{0}^{A}dt=\infty\), ou seja, a integral diverge.
Exemplo 2. Para resolver a integral
$$
\int_{1}^{\infty}t^{-r}dt
$$
temos que distinguir dois casos. Se \(r=1\) temos
$$
\int_{1}^{\infty}\frac{dt}{t}=\lim_{A\rightarrow\infty}\ln A=\infty;
$$
Caso contrário, para \(r\neq1\),
Resumindo,
$$
\int_{1}^{\infty} t^{-r}dt = \left\{
\begin{array}{l} \text{ converge se } \; r\leq1, \\
\text{ diverge se } \; r \gt 0.\\
\end{array}
\right.
$$
Como veremos, as transformadas de Laplace são particularmente importantes na solução de equações diferenciais que involvem funções descontínuas ou com derivadas descontínuas. Estas descontinuidades geralmente aparecem nas funções de entrada, a parte não homogênea das equações lineares, e podem representar, por exemplo, um efeito que é ligado e desligado sobre o sistema estudado ou uma ação externa que atua em um intervalo de tempo finito. Matematicamente as transformadas podem ser aplicadas à funções que envolvem um número finito de descontinuidades na região de interesse. A seguinte definição será útil:
Definição Uma função \(f(t)\) é seccionalmente contínua, ou contínua por partes, no intervalo \(\alpha\leq t\leq\beta\) se existir uma partição do intervalo \(\alpha=t_{0}\leq t_{1}\leq\cdots\leq t_{n}=\beta\) de forma que \(f\) é contínua em cada subintervalo aberto \(t_{i}\leq t\leq t_{i+1}\), além de possuir limite finito nas fronteiras de cada subintervalo. Isto equivale a dizer que \(f\) é uma função com um número finito de descontinuidades. Observe que, se \(f(t)\) é seccionalmente contínua no intervalo \(a\leq t\leq A\), então \(\int_{a}^{A}f(t)dt\) é finita para qualquer valor de \(A\), ainda que a integral imprópria \(\int_{a}^{\infty}f(t)dt\) possa divergir. O seguinte teorema fornece um teste de convergência.
Teorema 1. Seja \(f(t)\) uma função seccionalmente contínua para \(t\geq a,\; g(t)\) outra função qualquer, e \(M\) uma constante positiva. Então
(i) se \(|f(t)|\leq g(t) \text{ para } t\geq M \text{ e } \int_{M}^{\infty}g(t)dt \;\;\text{ converge então }\;\; \int_{a}^{\infty}f(t)dt\) converge.
(ii) se \(f(t)\geq g(t)\geq 0 \text{ para } t\geq M \text{ e } \int_{M}^{\infty}g(t)dt\;\;\text{ diverge então }\;\; \int_{a}^{\infty}f(t)dt\) diverge.
Teorema 2. Seja \(f(t)\) uma função seccionalmente contínua no intervalo \(0\leq t\leq A\) para qualquer \(A\) positivo. Se \(|f(t)|\leq K\text{e}^{at}\) quando \(t\geq M\), onde \(K\) e \(M\) são constantes positivas e \(a\) uma constante real qualquer então a integral definida pela expressão (1) converge e existe a transformada de Laplace \(F(s)=L\{f(t)\}\).
Demonstração Buscamos mostrar a convergência da integral
$$
\int_{0}^{\infty}\text{e}^{-st}f(t)dt=\int_{0}^{M}\text{e}^{-st}f(t)dt+\int_{M}^{\infty}\text{e}^{-st}f(t)dt.
$$
A primeira integral é convergente pois \(f\) é seccionalmente contínua. Como, por hipótese, temos que \(|f(t)|\leq K\text{e}^{at}\) então
$$
|\text{e}^{-st}f(t)|\leq K\text{e}^{-st}\text{e}^{at}=K\text{e}^{(a-s)t}
$$
e a segunda integral
$$
\int_{M}^{\infty}\text{e}^{-st}f(t)dt\leq K\int_{M}^{\infty}\text{e}^{(a-s)t}dt
$$
que converge quando \(a \lt s\), como foi mostrado no exemplo 1. Pelo teorema 1, \(\int_{0}^{\infty}\text{e}^{-st}f(t)dt\) converge.
Funções que satisfazem as condições do teorema 2 são seccionalmente contínuas e ditas funções de ordem exponencial. Trataremos apenas destas funções neste capítulo. Mostraremos a seguir alguns exemplos de funções que possuem transformadas de Laplace.
Exemplo 3. A transformada de \(f(t)=1\), \(t\geq0\), é
$$
L\{1\}=\int_{0}^{\infty}\text{e}^{-st}dt=\lim_{A\rightarrow\infty}\frac{1}{s}(1-\text{e}^{-sA})=\frac{1}{s},\;\text{ se }\;s\gt 0.
$$
Exemplo 4. A transformada de \(f(t)=t,\; t\geq0\):
$$
L\{t\}=\int_{0}^{\infty}t\text{e}^{-st}dt=\lim_{A\rightarrow\infty}t\text{e}^{-st}|_{0}^{A}-\frac{1}{s}\int_{0}^{A}\text{e}^{-st}dt=
$$
$$
=\lim_{A\rightarrow\infty}-\frac{1}{s^{2}}(\text{e}^{-st})|_{0}^{A}=\frac{1}{s^{2}},\;\text{ se }\;s\gt 0.
$$
Exemplo 5. Já calculamos a transformada de \(f(t)=\text{e}^{at}, \; t\geq0\):
$$
L\{\text{e}^{at}\}=\int_{0}^{\infty}\text{e}^{-st}\text{e}^{at}dt=\int_{0}^{\infty}\text{e}^{(a-s)t}dt=\frac{1}{s-a},\;\text{ se }\;s\lt a.
$$
Exemplo 6. A transformada de \(f(t)=\text{sen }at,\; t\geq 0\), é:
$$
F(s)=L\{\text{sen }at\}=\int_{0}^{\infty}\text{e}^{-st}\text{sen }atdt=\lim_{A\rightarrow\infty}\int_{0}^{A}\text{e}^{-st}\text{sen }atdt.
$$
Integrando por partes temos
Exemplo 7. Podemos encontrar as transformada das funções seno e cosseno de modo mais simples usando a linearidade da transformada e a transformada da exponencial encontrada no exemplo 5:
$$
L\{\text{e}^{iat}\}=\frac{1}{s-ia}=\frac{s+ia}{(s-ia)(s+ia)}=\frac{s+ia}{s^{2}+a^{2}}.
$$
Por outro lado, pela linearidade da transformação,
$$
L\{\text{e}^{iat}\}=L\{\cos at+i\text{sen }at\}=L\{\cos at\}+iL\{\text{sen }at\}.
$$
Identificando as partes real e imaginária das equações temos
$$
L\{\cos at\}=\frac{s}{a^{2}+s^{2}},
$$
$$
L\{\text{sen }at\}=\frac{a}{a^{2}+s^{2}}.
$$
Para considerar o uso das transformadas de Laplace para a solução de equações diferenciais com valores de contorno definidos precisaremos encontrar a transformada das derivadas de uma função. Disto trata o teorema seguinte.
Teorema 3. Seja \(f\) uma função contínua com derivada \(f^{\prime}\) seccionalmente contínua no intervalo \(0\leq t\leq A\), satisfazendo \(|f(t)|\leq K\text{e}^{at} \text{ para } t\geq M\) (uma função de ordem exponencial). Então \(L\{f^{\prime}(t)\}\) existe e dada por
$$
L\{f^{\prime}(t)\}=sL\{f(t)\}-f(0).
$$ Demonstração. A transformada da derivada, por definição, é
$$
L\{f^{\prime}(t)\}=\int_{0}^{\infty}\text{e}^{-st}f^{\prime}(t)dt.
$$
Vamos denotar por \(t_{1},\,t_{2}, \ldots, \, t_{n}\) os pontos onde \(f^{\prime}\) é descontínua no intervalo \(0\leq t\leq A\). Dai
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=\int_{0}^{t_{1}}\text{e}^{-st}f^{\prime}(t)dt+\int_{t_{1}}^{t_{2}}\text{e}^{-st}f^{\prime}(t)dt+\ldots+\int_{t_{n}}^{A}\text{e}^{-st}f^{\prime}(t)dt.
$$
Cada uma das integrais pode ser resolvida por partes, fazendo
$$
u=\text{e}^{-st},\,\,\,du=-s\text{e}^{-st}dt;\,\,\,dv=f^{\prime}dt,\,\,\,v=f.
$$
Assim
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=\text{e}^{-st}f|_{0}^{t_{1}}+\text{e}^{-st}f|_{t_{1}}^{t_{2}}+\ldots+\text{e}^{-st}f|_{t_{n}}^{A}+
$$
$$
s\int_{0}^{t_{1}}\text{e}^{-st}f(t)dt+s\int_{t_{1}}^{t_{2}}\text{e}^{-st}f(t)dt+\ldots+s\int_{t_{n}}^{A}\text{e}^{-st}f(t)dt.
$$
Como \(f\) é contínua o primeiro grupo de somas resulta simplesmente em \(\text{e}^{-st}f|_{0}^{A}\) enquanto a soma das integrais pode ser escrita como a integral sobre todo o domínio \(0\leq t\leq A\). Resulta, portanto, que
$$
\int_{0}^{A}\text{e}^{-st}f^{\prime}(t)dt=s\int_{0}^{A}\text{e}^{-st}f(t)dt+\text{e}^{-st}f|_{0}^{A}.
$$
O teorema fica demonstrado quando tomamos o limite \(A\rightarrow\infty\), lembrando que \(f\) é uma função de ordem exponencial.
Como consequência direta deste teorema podemos calcular a transformada da derivada segunda de uma função.
Corolário. Se \(f^{\prime} \text{ e } f^{\prime\prime} \) satisfazem as condições do teorema 3, então
$$
L\{f^{\prime\prime}(t)\}=sL\{f^{\prime}(t)\}-f^{\prime}(0)=s[sL\{f(t)\}-f(0)]-f^{\prime}(0),
$$
ou seja,
Generalizando este procedimento podemos encontrar as transformadas de derivadas de qualquer ordem. Se \(f,\,f^{(1)},\ldots,\,f^{(n-1)}\) são funções contínuas e \(f^{(n)}\) seccionalmente contínua, todas elas de ordem exponencial, então
Exemplo 8. Podemos usar o teorema 3 para calcular a transformada de funções se conhecemos a transformada de sua derivada. Por exemplo fazemos
$$
f(t)=t^{2},\,\,f^{\prime}(t)=2t,\,\,f(0)=0,
$$
no teorema para obter
$$
L\{2t\}=sL\{t^{2}\}\Rightarrow L\{t^{2}\}=\frac{2}{s^{3}}.
$$
De modo similar temos que
$$
L\{3t^{2}\}=sL\{t^{3}\}\Rightarrow L\{t^{3}\}=\frac{3!}{s^{4}}.
$$
Podemos mostrar por indução que
$$
L\{t^{n}\}=\frac{n!}{s^{n+1}},
$$
para \(n\) inteiro positivo.
Exemplo 9. Embora já tenhamos encontrado as transformadas das funções seno e cosseno podemos usar uma forma alternativa para encontrar suas transformadas através do corolário do teorema 3. Na equação
$$
L\{f^{\prime\prime}(t)\}=s^{2}L\{f(t)\}-sf(0)-f^{\prime}(0)
$$
fazemos \(f(t)=\cos at\) e, portanto, \(f(0)=1\), \(f^{\prime}(0)=0\) para obter
$$
-a^{2}L\{\cos at\}=s^{2}L\{\cos at\}-s\Rightarrow L\{\cos at\}=\frac{s}{s^{2}+a^{2}}.
$$
Procedimento análogo nos leva à transformada da função seno.
Para a utilização destas transformadas na solução de equações diferenciais necessitamos ainda definir a transformada inversa de Laplace. Se \(L\{f(t)\}=F(s)\) então chamamos \(f(t)\) a transformada inversa de \(F(s)\) e denotamos
$$
L^{-1}\{F(s)\}=f(t).
$$
O problema geral de encontrar transformadas inversas é bem definido mas involve a teoria de funções de variáveis complexas e não será aqui considerado. No entanto é possível mostrar que existe uma relação biunívoca entre as funções e suas transformadas e a transformada inversa é também um operador linear. Se \(F(s)\) é composto pela soma de \(n\) funções
$$
F(s)=F_{1}(s)+F_{2}(s)+\cdots+F_{n}(s)
$$
e as transformadas de cada uma das \(n\) funções são conhecidas
$$
f_{1}(t)=L^{-1}\{F_{1}(s)\},\cdots,f_{n}(t)=L^{-1}\{F_{n}(s)\}
$$
então
$$
L^{-1}\{F(s)\}=L^{-1}\{F_{1}(s)\}+\cdots+L^{-1}\{F_{n}(s)\}=f_{1}(t)+\cdots+f_{n}(t).
$$
Alem disto, se \(a\) é uma constante qualquer, então
$$
L^{-1}\{aF(s)\}=af(t).
$$
Portanto, para encontrar a transformada inversa de uma função nos a transformaremos até que ela possa ser reconhecida como a transformada de alguma função conhecida, como mostrado nos exemplos a seguir. Algumas transformadas mais usuais e propriedades estão listadas no final deste capítulo.
Exemplo 10. Procuramos a transformada inversa da função
$$
F(s)=\frac{3s+1}{s^{2}+9}.
$$
Esta função pode ser reescrita como
$$
F(s)=\frac{3s}{s^{2}+9}+\frac{1}{3}\frac{3}{s^{2}+9}.
$$
Lembrando, ou olhando na tabela, que as transformadas do seno e cosseno são
$$
L\{\text{sen }at\}=\frac{a}{s^{2}+a^{2}},\,\,\,\,L\{\cos at\}=\frac{s}{s^{2}+a^{2}}
$$
temos que
Exemplo 11. Vamos encontrar a transformada inversa da função
$$
F(s)=\frac{s+3}{s^{2}+3s+2}.
$$
Devemos expressar esta função como soma de funções que são transformadas conhecidas e dai obter a transformada inversa. Notando que as raizes do denominador são \(-1\) e \(-2\) escrevemos \(s^{2}+3s+2=(s+1)(s+2)\) e decompomos \(F\) em termos de frações parciais
$$
F(s)=\frac{s+3}{(s+1)(s+2)}=\frac{a}{(s+1)}+\frac{b}{(s+2)}=\frac{a(s+2)+b(s+1)}{(s+1)(s+2)}.
$$
\(a\) e \(b\) constantes. Para que o numerador seja o mesmo devemos ajustar \(a\) e \(b\):
$$
\left.(a+b)s+2a+b=s+3\Rightarrow
\begin{array}{c}a+b=1 \\ 2a+b=3 \\ \end{array}
\right\} \Rightarrow\begin{array}{c} a=2 \\ b=-1 \\ \end{array}
$$
ou seja
$$
F(s)=\frac{2}{(s+1)}-\frac{1}{(s+2)}.
$$
A transformada inversa procurada é
$$
f(t)=L^{-1}\{F(s)\}=2L^{-1}\left\{ \frac{1}{s+1}\right\} -L^{-1}\left\{ \frac{1}{s+2}\right\} .
$$
Lembrando que a transformada de \(L\{\text{e}^{at}\}=1/(s-a)\) e, portanto
$$
L^{-1}\left\{ \frac{1}{s-a}\right\} =\text{e}^{at},
$$
temos
Queremos resolver agora um problema de contorno do tipo
$$
y^{\prime\prime}+ay^{\prime}+by=r(t),\,\,\,\,y(0)=y_{0},\,\,\,\,y^{\prime}(0)=y_{0}^{\prime}.
$$
Caso os valores de contorno não estejam definidos no ponto \(x_{0}=0\) basta fazer uma translação do eixo de coordenadas colocando o contorno na origem das coordenadas. Se a função \(r(x)\) é de ordem exponencial possuindo, portanto, transformada de Laplace bem definida admitiremos que a solução \(y(t)\) é também de ordem exponencial e que suas derivadas satisfazem as condições do teorema 3 e seu corolário. Tomamos a transformada de ambos os lados da equação acima,
$$
L\{y^{\prime\prime}+ay^{\prime}+by\}=L\{r(t)\},
$$
para obter, pela linearidade da transformação,
$$
L\{y^{\prime\prime}\}+aL\{y^{\prime}\}+bL\{y\}=L\{r(t)\}.
$$
Denotando por \(R(s)=L\{r(t)\}\) e \(Y(s)=L\{y(t)\}\), temos
$$
Y(s)=\frac{R+(s+a)y_{0}+y_{0}^{\prime}}{s^{2}+sa+b}.
$$
\(Y(s)\) representa a transformada da solução procurada, já incorporadas as condições de contorno. O próximo passo é o de encontrar a transformada inversa, representada pela solução \(y(t)\), da forma tratada na seção anterior.
Exemplo 12. Vamos resolver pelo método de transformadas de Laplace a seguinte equação diferencial com valores de contorno:
$$
y^{\prime\prime}+3y^{\prime}+2y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=0.
$$
Transformando ambos os lados da equação e usando a linearidade obtemos
$$
L\{y^{\prime\prime}+3y^{\prime}+2y\}=L\{y^{\prime\prime}\}+3L\{y^{\prime}\}+2L\{y\}=0.
$$
Denotamos agora \(L\{y(t)\}=Y(s)\) e usamos as transformadas das derivadas
$$
L\{y^{\prime}\}=sY(s)-y(0)\;\text{ e }\;L\{y^{\prime\prime}\}=s^{2}Y(s)-sy(0)-y^{\prime}(0)
$$
para transformar a equação diferencial em uma equação algébrica (ou seja, uma equação sem derivadas)
$$
s^{2}Y(s)-s+3sY(s)-3+2Y(s)=0\Rightarrow
$$
$$
Y(s)=\frac{s+3}{s^{2}+3s+2}.
$$
A transformada inversa desta função foi encontrada no exemplo 5.11 da seção anterior,
$$
y(t)=L^{-1}\left\{ \frac{s+3}{s^{2}+3s+2}\right\} =2\text{e}^{-t}-\text{e}^{-2t}
$$
o que é a solução do problema, já incorporadas as condições de contorno fornecidas.
O tratamento das equações não homogêneas não acrescenta dificuldades extras no uso do método das transformadas da Laplace, como se mostra no exemplo seguinte.
Exemplo 13. Considere a equação não homogênea,
$$
y^{\prime\prime}+y=\text{sen }2t,\,\,y(0)=2,\,\,y^{\prime}(0)=1.
$$
Transformando a equação temos
$$
L\{y^{\prime\prime}+y\}=L\{y^{\prime\prime}\}+L\{y\}=L\{\text{sen }2t\}
$$
ou, usando a propriedade da derivada da derivada e a transformado do seno,
$$
s^{2}Y(s)+Y(s)-2s-1=\frac{2}{s^{2}+4}.
$$
Dai
$$
Y(s)=\frac{2s^{3}+s^{2}+8s+6}{(s^{2}+1)(s^{2}+4)}.
$$
Decompondo esta última expressão em frações parciais temos
$$
Y(s)=\frac{as+b}{s^{2}+1}+\frac{cs+d}{s^{2}+4}
$$
e determinamos que as constantes são \(a=2,\,\,b=5/3,\,\,c=0\) e \(d=-2/3\). Então
$$
Y(s)=\frac{2s}{s^{2}+1}+\frac{5/3}{s^{2}+1}-\frac{2/3}{s^{2}+4}.
$$
Lembrando que as transformadas do seno e cosseno são
$$
L\{\text{sen }at\}=\frac{a}{a^{2}+s^{2}},\,\,\,\,L\{\cos at\}=\frac{s}{a^{2}+s^{2}}
$$
temos a solução
$$
y(t)=2\cos t+\frac{5}{3}\text{sen }t-\frac{1}{3}\text{sen }2t.
$$
Em resumo, o método da transformada de Laplace é muito útil para o tratamento de equações que surgem em aplicações, especialmente em problemas de mecânica e na solução de circuitos elétricos. A transformação da equação diferencial leva a uma equação algébrica e sua transformada inversa fornece a solução procurada para o problema de valor inicial, seja ela homogênea ou não. A solução obtida desta forma já leva em consideração os valores do contorno apresentados no problema.
Exercícios 2
1. Determine as soluções de
a. \(y^{\prime\prime}+9y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=2\)b. \(y^{\prime\prime}+y^{\prime}-2y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=3\)
c. \(y^{\prime\prime}-2y^{\prime}-3y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=7\)
d. \(y^{\prime\prime}+2y^{\prime}-8y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=8\)
e. \(y^{\prime\prime}+2y^{\prime}-3y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=4\)
f. \(4y^{\prime\prime}+4y^{\prime}-3y=0,\,\,\,y(0)=8,\,\,\,y^{\prime}(0)=0\)
g. \(y^{\prime\prime}-4y^{\prime}+5y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
h. \(y^{\prime\prime}+2y^{\prime}+5y=0,\,\,\,y(0)=2,\,\,\,y^{\prime}(0)=-4\)
i. \(y^{\prime\prime}+2y^{\prime}+y=0,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=-2\)
j. \(y^{\prime\prime}-4y^{\prime}+4y=0,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=2\)
2. Determine as soluções das equações não homogêneas a. \(y^{\prime\prime}-y=1,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=2\)
b. \(y^{\prime\prime}-3y^{\prime}+2y=6\text{e}^{-t},\,\,\,y(0)=3,\,\,\,y^{\prime}(0)=3\)
c. \(y^{\prime\prime}+2y^{\prime}-3y=10\text{senh }2t,\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=4\)
d. \(y^{\prime\prime}+2y^{\prime}+2y=10 \text{sen }2t,\,\,\,y(0)=-1,\,\,\,y^{\prime}(0)=-3\)
e. \(y^{\prime\prime}-2y^{\prime}+5y=8\text{sen }t-4\cos t,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
f. \(y^{\prime\prime}+y=-2\text{sen }t,\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=1\)
g. \(y^{\prime\prime}+9y=6\cos3t,\,\,\,y(0)=2,\,\,\,y^{\prime}(0)=0\)
h. \(y^{\prime\prime}+4y=4(\cos2t-\text{sen }2t),\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=3\)
Para prosseguirmos com o estudo das propriedades da transformada de Laplace será necessário definir a função degrau unitário:
$$
u_{a}(t)=\left\{
\begin{array}{ll} 0, & t\lt a \\
1, & t\geq a, \\
\end{array}\right.
$$
onde \(a\) é uma constante. Em diversas aplicações surgem funções não contínuas como parte de uma equação diferencial. Um exemplo destas aplicações é a corrente elétrica em um circuito simples onde a tensão pode ser ligada e desligada. A corrente em uma lâmpada, ignorados efeitos indutivos e capacitivos do circuito, ligada aos polos de uma bateria no instante \(t=2\) e desligada em \(t=4\) é descrita por
$$
i(t)=u_{2}(t)-u_{4}(t),
$$
como ilustrado na figura.
Figura: Degrau unitário
A função degrau pode ser usada para descrever fenômenos que se iniciam (ou terminam) após um determinado tempo ou para introduzir descontinuidades quaisquer. Por exemplo, se \(h(t)\) é uma função qualquer, defina
$$
g(t)=\left\{
\begin{array}{ll} 0, & t \lt a, \\
h(t-a), & t\geq a, \\
\end{array}\right.
$$
o que representa uma translação de \(h\) na direção de \(t\) positivo. Usando a função degrau ela pode ser escrita em forma compacta
$$
g(t)=u_{a}(t)h(t-a).
$$
A transformada de Laplace da função degrau unitário pode ser facilmente obtida:
$$
L\{u_{a}(t)\}=\int_{0}^{\infty}u_{a}(t)\text{e}^{-st}dt=\int_{a}^{\infty}\text{e}^{-st}dt=
$$
$$
=-\frac{1}{s}\lim_{A\rightarrow\infty}\text{e}^{-st}|_{a}^{A}=\frac{\text{e}^{-as}}{s},\;\text{ para }\;s\gt 0.
$$
A “Função” Delta de Dirac
Outro tipo de descontinuidade frequente em equações diferenciais pode ser representado por meio da função delta de Dirac, que pode ser definida da seguinte forma:
$$
\delta(t)=0\text{ se } t\neq 0, \text{ e }
$$
$$
\int_{-\infty}^{\infty}f(t)\delta(t)dt=f(0).
$$
A função \(\delta(t-a)\) pode ser entendida como um pico fortemente concentrado em torno de \(x=a\), de forma que
$$
\int_{\alpha}^{\beta}f(t)\delta(t-a)dt=
\left\{ \begin{array}{ll} f(a), & \text{ se } \; \alpha\lt a \lt \beta, \\
0, & \text{ caso contrário}.
\end{array}\right.
$$
A transformada da função delta é
$$
L\{\delta(t-a)\}=\int_{0}^{\infty}\text{e}^{-st}\delta(t-a)dt=\text{e}^{-sa},\;\; a\gt 0.
$$
Esta função foi introduzida por P. A. M. Dirac e não é, na verdade, uma função mas sim uma distribuição ou uma função generalizada.
Teoremas de Translação
Estamos agora preparados para enunciar dois teoremas que descrevem propriedades da transformada de Laplace e que serão úteis na soluções de equações diferenciais.
Figura: Translações
Teorema 4: Seja \(f(t)\) uma função que possui transformada de Laplace \(F(s)=L\{f(t)\}\). Então
$$
L\{u_{a}(t)f(t-a)\}=\text{e}^{-as}F(s),\;\;s\gt 0,\,\,\,a\gt 0.
$$ Demonstração:
$$
L\{u_{a}(t)f(t-a)\}=\int_{0}^{\infty}\text{e}^{-st}u_{a}(t)f(t-a)dt=\int_{a}^{\infty}\text{e}^{-st}f(t-a)dt.
$$
Denotando \(t-a=w\), temos \(t=a+w\) e \(w=0\) quando \(t=a\). A transformada procurada é
$$
\int_{0}^{\infty}\text{e}^{-s(a+w)}f(w)dw=\text{e}^{-sa}\int_{0}^{\infty}\text{e}^{-sw}f(w)dw=\text{e}^{-as}F(s),
$$
como afirmado.
Exemplo 14. Encontraremos a transformada de
$$
f(t)=\left\{ \begin{array}{ll} \text{sen }t, & 0 \leq t \lt \pi/4, \\ \text{sen }t+\cos\left(t-\frac{\pi}{4}\right), & t\geq\pi/4. \\ \end{array}\right.
$$
Teorema 5 Seja \(f(t)\) uma função que possui transformada de Laplace \(F(s)=L\{f(t)\}\). Então
$$
L\{\text{e}^{at}f(t)\}=F(s-a),\,\,\,s>a,\,\,\,a\gt 0.
$$
Vale também a transformada inversa
$$
L^{-1}\{F(s-a)\}=\text{e}^{at}f(t).
$$
A condição \(s\gt a\) serve para garantir a convergência da última integral, desde que \(f\) seja de ordem exponencial.
Exemplo 15. A transformada inversa de \((s^{2}-4s+5)^{-1}\) é, completando quadrados,
$$
L^{-1}\left\{ \frac{1}{s^{2}-4s+5}\right\} =L^{-1}\left\{ \frac{1}{(s-2)^{2}+1}\right\} =L^{-1}\{F(s-2)\}
$$
onde \(F(s)=1/(s^{2}+1),\) que é a transformada da função \(\text{sen }t\). Então
$$
L^{-1}\{F(s-2)\}=\text{e}^{2t}\text{sen }t
$$
como se pode concluir pelo Teorema 2.
Exemplo 16. Vamos tratar do seguinte problema de valor inicial:
$$
y^{\prime\prime}-2y^{\prime}+2y=0,y(0)=0,y^{\prime}(0)=1.
$$
Pela linearidade da transformada de Laplace temos
$$
L\{y^{\prime\prime}\}-2L\{y^{\prime}\}+2L\{y\}=0,
$$
ou, escrevendo
$$
L\{y(t)\}=Y(s)
$$
e
Demonstração escrevemos a transformada como a soma de duas integrais
$$
L\{f(t)\}=\int_{0}^{\infty}f(t)\text{e}^{-st}dt=\int_{0}^{T}f(t)\text{e}^{-st}dt+\int_{T}^{\infty}f(t)\text{e}^{-st}dt.
$$
Fazendo a substituição de variáveis, \(t\rightarrow\tau=t-T\), a última destas integrais pode ser escrita como
$$
\int_{T}^{\infty}f(t)\text{e}^{-st}dt=\int_{0}^{\infty}f(\tau+T)\text{e}^{-s(\tau+T)}dt=\text{e}^{-sT}\int_{0}^{\infty}f(\tau)\text{e}^{-s\tau}dt=\text{e}^{-sT}L\{f(t)\},
$$
onde foi usado o fato de que \(f\) é periódica. A transformada procurada é, portanto,
$$
L\{f(t)\}=\int_{0}^{T}f(t)\text{e}^{-st}dt+\text{e}^{-sT}L\{f(t)\},
$$
ou seja,
$$
L\{f(t)\}=\frac{1}{1-\text{e}^{-sT}}\int_{0}^{T}f(t)\text{e}^{-st}dt,
$$
ficando assim mostrado o teorema.
Exemplo 17. Dada a função periódica, definida por
$$
\begin{array}{ll} f(t)=\frac{1}{2}t, & 0\leq t\lt 2, \\ f(t+2)=f(t) & \text{ fora deste intervalo,} \\ \end{array}
$$
Figura: Função dente de serra
procuramos sua transformada de Laplace. Esta é a função dente de serra que tem inúmeras aplicações, particularmente em circuitos eletrônicos. Usando o teorema 6 obtemos sua transformada de Laplace como
$$
L\{f(t)\}=\frac{1}{1-\text{e}^{-2s}}\int_{0}^{2}f(t)\text{e}^{-st}dt=\frac{1}{2}\frac{1}{1-\text{e}^{-2s}}\int_{0}^{2}t\text{e}^{-st}dt.
$$
Integrando por partes temos
$$
L\{f(t)\}=\frac{1}{2}\frac{1}{1-\text{e}^{-2s}}\left[\left.-\frac{t\text{e}^{-st}}{s}\right|_{0}^{2}++\frac{1}{s}\int_{0}^{2}\text{e}^{-st}dt\right]
$$
1 Faça um esboço do gráfico das funções e encontre suas transformadas de Laplace: a. \(f(t)=\left\{ \begin{array}{ll} 0, & t\lt 2 \\ (t-2)^{2}, & t\geq2 \\ \end{array}.\right.\)
A transformada de Laplace é apropriada para o tratamento de uma equação diferencial com um termo não homogêneo, também denominado a função de entrada, descontínua, como já mencionado.
Exemplo 18. Considere a equação diferencial
$$
y^{\prime\prime}+y^{\prime}+\frac{5}{4}y=g(t),\,\,\,y(0)=0,\,\,\,y^{\prime}(0)=0,
$$
onde \(g(t)=1-u_{\pi}(t)\), uma função descontínua. Transformando a equação obtemos
$$
s^{2}Y(s)+sY(s)+\frac{5}{4}Y(s)=L\{1\}-L\{u_{\pi}(t)\}=\frac{1}{s}(1-\text{e}^{\pi s}),
$$
e, portanto,
$$
Y(s)=\frac{1-\text{e}^{\pi s}}{s\left(s^{2}+s+\frac{5}{4}\right)}.
$$
Vamos denotar \(H(s)\) a transformada de \(h(t)\), onde
$$
H(s)=\frac{1}{s\left(s^{2}+s+\frac{5}{4}\right)},\,\,\,\,h(t)=L^{-1}\{H(s)\}.
$$
Então, com esta notação,
$$
Y(s)=(1-\text{e}^{\pi s})H(s)
$$
e, pelo teorema 4 da seção anterior,
$$
y(t)=L^{-1}\{H(s)-\text{e}^{\pi s}H(s)\}=h(t)-u_{\pi}(t)h(t-\pi).
$$
Resta então encontrar \(L^{-1}\{H(s)\}\). Para fazer isto escrevemos \(H\) em termos das frações parciais
$$
H(s)=\frac{a}{s}+\frac{bs+c}{s^{2}+s+\frac{5}{4}}
$$
e encontramos as constantes \(a=4/5,\,\,b=-4/5\) e \(c=-4/5,\) portanto
$$
H(s)=\frac{4}{5}\frac{1}{s}-\frac{4}{5}\frac{s+1}{s^{2}+s+\frac{5}{4}}.
$$
Usando as transformadas conhecidas e suas propriedades encontramos
$$
h(t)=\frac{4}{5}-\frac{4}{5}\left(\cos t+\frac{1}{2}\text{sen }t\right)\text{e}^{-t/2}
$$
e, portanto,
Exemplo 19. Veremos como utilizar a transformada acima para resolver uma equação diferencial que tem como função de entrada uma distribuição delta. Considere o problema
$$
y^{\prime\prime}+y=4\delta(t-2\pi),\,\,\,y(0)=1,\,\,\,y^{\prime}(0)=0.
$$
Este problema pode ser visto como a equação de movimento de uma partícula presa a uma mola com constante elástica unitária e em um meio sem atrito, submetida a uma força de curta duração, como uma colisão, no momento \(t=2\pi\). Ela parte afastada de uma unidade de distância da posição de equilíbrio no instante \(t=0\) e tem velocidade inicial nula. Transformando toda a equação temos
$$
s^{2}Y(s)-s+Y(s)=4\text{e}^{-2\pi s}
$$
ou seja
$$
Y(s)=\frac{s}{s^{2}+1}+\frac{4\text{e}^{-2\pi s}}{s^{2}+1}.
$$
Utilizando os teoremas e transformadas inversas pertinentes temos
$$
y(t)=\cos t+4\text{sen }(t-2\pi)u_{2\pi}(t).
$$
Como o seno é periódica com período \(T=2\pi\) temos \(\text{sen }(t-2\pi)=\text{sen }(t)\) e
$$
y(t)=\left\{ \begin{array}{ll} \cos t, 0\leq t\leq2\pi,
\cos t+4\text{sen }t, t\geq2\pi. \end{array}.\right.
$$
Função do exemplo 19
O gráfico desta solução mostra que a mola oscila com amplitude \(1\) até o instante \(t=2\pi\). Depois disto passa a oscilar com maior amplitude, devido ao impulso sofrido.
Exercícios 4
Encontre a solução dos problemas de valor inicial
1. \(y^{\prime\prime}+y=f(t),\; y(0)=0,y^{\prime}(0)=1 \text{ onde }
f(t)=\left\{ \begin{array}{ll} 1, & 0\leq t \lt \pi/2 \\
0, & t\geq\pi/2.\\
\end{array}\right.\)2. \(y^{\prime\prime}+2y^{\prime}+2y=f(t),\; y(0)=0,\;y^{\prime}(0)=1 \,\,\, \text{ onde } f(t)=\left\{ \begin{array}{ll} 1, & \pi\leq t\lt2\pi
\\0, & 0\leq t\lt\pi\text{e}t\geq2\pi. \\ \end{array}\right.\)
Pode ocorrer, na solução de uma equação diferencial, que a solução transformada \(Y(s)\) seja dada em termos do produto de duas transformadas conhecidas. Se \(F(s)=L\{f(t)\} \text { e } G(s)=L\{g(t)\}\) queremos saber qual é a transformada inversa do produto \(H(s)=F(s)G(s)\), ou seja \(L^{-1}\{F(s)G(s)\}\). O teorema da convolução nos fornece a transformada inversa deste produto.
Teorema 7. Seja \(f(t) \text { e } g(t)\) duas funções que possuem transformadas de Laplace, e \(F(s)=L\{f(t)\},\,\,G(s)=L\{g(t)\}\) as suas transformadas. Se \(H(s)=F(s)G(s)\) é o produto das transformadas então sua transformada inversa, \(h(t)=L^{-1}\{H(s)\}\) é
$$
h(t)=\int_{0}^{t}f(t^{\prime}-\tau)g(\tau)d\tau=\int_{0}^{t}f(\tau)g(t^{\prime}-\tau)d\tau.
$$
\(h(t)\) é a convolução de \(f\) e \(g\) e as integrais são chamadas de integrais de convolução.
Demonstração por definição temos as expressões para \(F\) e \(G\),
$$
H(s)=F(s)G(s)=\int_{0}^{\infty}g(v)\text{e}^{-sv}dv\int_{0}^{\infty}f(u)\text{e}^{-su}du=\int_{0}^{\infty}g(v)\left[\int_{0}^{\infty}f(u)\text{e}^{-s(u+v)}du\right]dv.
$$
Para avaliar esta última integral introduzimos a variável \(u = t + v\). Neste caso \(t=v\) quando \(u=0\) e \(du=dt\), o que permite escrever
$$
H(s)=\int_{0}^{\infty}g(v)\left[\int_{v}^{\infty}f(t-v)\text{e}^{-st}dt\right]dv.
$$
Admitindo que a ordem de integração pode ser invertida, integramos primeiro em \(v\). Observe que os limites de integração, inicialmente \(v \lt t \lt \infty\), passam a ser \(0 \lt v \lt t\) (veja figura) e temos
Figura: Região de integração para a integral de convolução
$$
I=L^{-1}\left\{ \frac{1}{s^{2}+a^{2}}\frac{1}{s^{2}+a^{2}}\right\} =\frac{1}{a^{2}}\int_{0}^{t}\text{sen }(at)\text{sen }a(t-\tau)d\tau.
$$
Para calcular esta integral usamos a relação trigonométrica
$$
\text{sen }a\,\text{sen }b=\frac{1}{2}[\cos(a-b)+\cos(a+b)]
$$
ou, no caso presente
$$
\text{sen }a\tau\text{sen }a(t-\tau)=\frac{1}{2}[\cos a(2\tau-t)-\cos at]
$$
para obter
$$
I=\frac{1}{2a^{2}}\left[\int_{0}^{t}\cos a(2\tau-t)d\tau-\cos at\int_{0}^{t}d\tau\right]=\frac{1}{2a^{3}}(\text{sen }at-at\cos at).
$$
A primeira integral pode ser avaliada por meio de uma substituição de variáveis, \(u=a(2\tau-t)\), \(du=2ad\tau\).
Exercícios 5
1. Determine as transformadas inversas:
c. \(F(s)=\frac{1}{(s+1)^{3}(s^{2}+4)}\)d. \(F(s)=\frac{G(s)}{s^{2}+1}\)
Se \(f\) é função periódica, \(f(t+T)=f(t)\) então
\begin{array}{l}
L\{f(t)\}=\frac{1}{1-\text{e}^{-sT}}\int_{0}^{T}f(t)\text{e}^{-st}dt.\\
\end{array}
Transformada das derivadas:
\begin{array}{l}
L\{f(t)\}=sL\{f(t)\}-f(0), \\ L\{f^{\prime\prime}(t)\}=s^{2}L\{f(t)\}-sf(0)-f^{\prime}(0). \\
\end{array}
Integral de Convolução:
\begin{array}{l} h(t)=L^{-1}[F(s)G(s)]=\int_{0}^{t}f(t-\tau)g(\tau)d\tau \\ \end{array}
Até agora vimos como resolver apenas dois tipos de equações diferenciais de segunda ordem homogêneas: as com coeficientes constantes e as equações de Euler. O método que estudaremos agora se baseia na hipótese de que as soluções procuradas são analíticas pelo menos em alguma vizinhança de um ponto \(x_{0}\) onde são dadas as condições de contorno. Isto significa que estas funções possuem derivadas de todas as ordens neste ponto e portanto podem ser expressas como uma série de potências. É possível, em alguns casos, que uma solução encontrada desta forma seja identificada como uma das funções elementares do cálculo. No entanto, no caso geral, ela não representa nenhuma destas funções elementares e deve ser expressa e definida através de sua série de potências1.
(1) Consulte o Apêndice para uma revisão sobre séries de potências.
Soluções em torno de ponto ordinário
Procuramos agora um método para a solução de equações diferenciais homogêneas do segundo grau mais gerais que as anteriormente estudadas, na forma de
(1)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{d^{2}y(x)}{dx^{2}}+G(x)y(x)=0,
$$
onde \(P(x)\), \(F(x)\) e \(G(x)\) são funções contínuas.
Definição: Um ponto \(x_{0}\) onde a função \(P\) não se anula, ou seja \(P(x_{0})\neq0\), é chamado um ponto ordinário. Caso contrário, se \(P(x_{0})=0\), dizemos que \(x_{0}\) é um ponto singular da equação diferencial.
Se \(x_{0}\) é um ponto ordinário, como \(P(x_{0})\neq0\), e \(P\) é contínua, então existe um intervalo em torno de \(x_{0}\) onde a função não se anula. Para este intervalo podemos escrever
$$
y^{\prime\prime}+f(x)y^{\prime}+g(x)y=0,
$$
onde as funções
$$
f(x)=\frac{F(x)}{P(x)},\,\,\,\,g(x)=\frac{G(x)}{P(x)}
$$
são igualmente contínuas. Pelo teorema de existência e unicidade existe uma única solução de (1) neste intervalo, satisfazendo as condições de contorno
$$
y(x_{0})=y_{0}\,\,\,\text{e}\,\,\,y^{\prime}(x_{0})=y_{0}^{\prime}.
$$
O método de solução de equações diferenciais usando séries de potências se baseia na suposição de que a solução procurada é uma função analítica nas vizinhanças do ponto \(x_{0}\) e que, portanto, pode ser escrita como um polinônio com coeficientes constantes \(a_{n}\),
$$
y(x)=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n}.
$$
Em seguida substituimos esta expressão e suas derivadas na equação diferencial e procuramos identificar os coeficientes \(a_{n}\). O ponto \(x_{0}\), em torno do qual se busca as soluções válidas, geralmente é o ponto onde as condições de contorno são estabelecidas. Usaremos um exemplo para tornar mais claro o método.
Exemplo 1. Vamos resolver, pelo método de séries de potências, a equação diferencial
(2)
$$ y^{\prime\prime}-y=0 $$
em torno do ponto ordinário \(x_{0}=0\). Fazendo a suposição inicial de que \(y\) é analítica próximo de \(x=0\), escrevemos esta função e suas derivadas como as séries, respectvivamente,
onde se deve observar que a série correspondente à derivada primeira se inicia em \(n=1\) devido ao desaparecimento do termo constante \(a_{0}\). Analogamente, a derivada segunda se inicia em \(n=2\). Substituindo na equação (2) temos a identidade
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-\sum_{n=0}^{\infty}a_{n}x^{n}=0.
$$
Note que ambas as séries se iniciam com um termo constante. Para tornar mais fácil a comparação dos termos envolvidos introduzimos um novo índice \(k\), \(n=k+2\), e reescrevemos a primeira série da seguinte forma
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}=\sum_{k=0}^{\infty}(k+2)(k+1)a_{k+2}x^{k}.
$$
Reescrevemos agora a equação diferencial como
$$
\sum_{n=0}^{\infty}(n+2)(n+1)a_{n+2}x^{n}-\sum_{n=0}^{\infty}a_{n}x^{n}=0
$$
onde o índice \(n\) foi recolocado no primeiro termo. Podemos agora juntar as duas somas
$$
\sum_{n=0}^{\infty}[(n+2)(n+1)a_{n+2}-a_{n}]x^{n}=0.
$$
Observando que este polinômio só pode ser nulo se todos os coeficientes de cada potência de \(x\) for nulo temos
$$
(n+2)(n+1)a_{n+2}-a_{n}=0
$$
ou
$$
a_{n+2}=\frac{a_{n}}{(n+2)(n+1)}.
$$
Esta é a chamada relação de recorrência para os coeficientes \(a_{n}\) que nos permite expressar todos estes coeficientes em termos de apenas dois deles, que permanencem indeterminados. Tomando \(n\) com valores sucessivos obtemos
$$
n=0\Rightarrow a_{2}=\frac{a_{0}}{2.1},
$$
Prosseguindo com esta operação vemos que
$$
a_{n}=\frac{a_{0}}{n!}\;\;\text{ para n par}\;\;\;a_{n}=\frac{a_{1}}{n!}\,\,\,\,\text{ para n impar}.
$$
Juntando os termos na expressão
$$
y=a_{0}+a_{1}x+a_{2}x^{2}+\cdots
$$
$$
y=a_{0}\left(1+\frac{x^{2}}{2!}+\frac{x^{4}}{4!}+\cdots\right)+a_{1}\left(x+\frac{x^{3}}{3!}+\frac{x^{5}}{5!}+\cdots\right).
$$
As séries dentro dos parênteses correspondem às expansões em séries para as funções cosseno e seno hiperbólico, respectivamente e portanto
$$
y(x)=a_{0}\cosh x+a_{1}\text{senh}x,
$$
que é uma combinação linear das funções \(\text{e}^{x}\) e \(\text{e}^{-x}\) que já sabiamos ser soluções da equação (2).
Se for possível identificar a série obtida como solução com uma função elementar, como no caso acima, então já sabemos que ela converge para esta função. se isso não ocorrer, se não pudermos identificar qual é esta solução em termos das funções conhecidas, então teremos que realizar testes de convergência para descobrir o intervalo onde é válida a solução.
Exemplo 2. Vamos resolver a equação
$$
y^{\prime\prime}+x^{2}y=0
$$
em torno de \(x_{0}=0\) (um ponto ordinário). Substituimos \(y=\sum_{n=0}^{\infty}a_{n}x^{n}\) e sua derivada segunda na equação diferencial para obter
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0.
$$
Só o primeiro somatório contém termos constante e múltiplo de \(x\) por isto escrevemos estes termos (\(n=2\) e \(n=3\)) em separado,
$$
2a_{2}+3.2a_{3}x+\sum_{n=4}^{\infty}n(n-1)a_{n}x^{n-2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0.
$$
Estes termos devem se anular, \(a_{2}=0,a_{3}=0\). Modificando a primeira soma para que ela se inicie em \(n=0\) temos
$$
\sum_{n=0}^{\infty}(n+4)(n+3)a_{n+4}x^{n+2}+\sum_{n=0}^{\infty}a_{n}x^{n+2}=0\Rightarrow
$$
$$
\sum_{n=0}^{\infty}[(n+4)(n+3)a_{n+4}+a_{n}]x^{n+2}=0,
$$
de onde podemos extrair nossa relação de recorrência:
$$
a_{n+4}=-\frac{a_{n}}{(n+4)(n+3)}.
$$
Calculamos a seguir alguns termos da série
$$
a_{4}=\frac{-a_{0}}{3.4};\,\,\,a_{5}=\frac{-a_{1}}{4.5};\,\,\,a_{6}=\frac{-a_{2}}{5.6}=0;\,\,\,a_{7}=\frac{-a_{3}}{6.7}=0
$$
$$
a_{8}=\frac{-a_{4}}{7.8}=\frac{a_{0}}{3.4.7.8};\,\,\,a_{9}=\frac{-a_{5}}{8.9}=\frac{a_{1}}{4.5.8.9};\,\,\,a_{10}=\frac{-a_{6}}{9.10}=0.
$$
Como a solução é \(y\), obtida por
$$
y(x)=a_{0}+a_{1}x+a_{2}x^{2}+a_{3}x^{3}+…
$$
Exemplo 3. Observando que todos os pontos são pontos ordinários na equação de Airy
$$
y^{\prime\prime}-xy=0,
$$
procuramos uma solução em torno de \(x_{0}=0\). Fazemos a suposição inicial de que a solução é analítica em torno da origem, ou seja, \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n}\), e substituimos esta expressão e suas derivadas na equação diferencial para obter
de onde concluimos que \(a_{2}=0\). Para tornar a comparação entre as duas somas mais simples modificamos o primeiro somatório para que comece em \(n=0\) e juntamos as duas somas,
Inserindo estes coeficientes na série de potência temos a solução geral
$$
y(x)=a_{0}\left[1+\sum_{n=1}^{\infty}\frac{x^{3n}}{2\cdot3\ldots(3n-1)3n}\right]+a_{1}\left[x+\sum_{n=1}^{\infty}\frac{x^{3n+1}}{3\cdot4\ldots3n(3n+1)}\right].
$$
Exemplo 4. Queremos agora encontrar uma solução para a equação diferencial
$$
y^{\prime\prime}+xy^{\prime}+2y=0,
$$
em torno de \(x_{0}=0\). Para isto substituimos \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n}\) e suas derivadas na equação para obter
Desta forma conseguimos escrever todas os somatórios em potências de \(x^{n}\). No entanto, apenas a primeira e a terceira possuem o termo constante (\(n=0\)). Separamos estes termos constantes e juntamos no mesmo somatório os termos restantes para obter
$$
a_{6}=\frac{-a_{4}}{5}=\frac{-a_{0}}{3\cdot5},a_{7}=\frac{-a_{5}}{6}=\frac{-a_{1}}{2\cdot4\cdot6},a_{8}=\frac{-a_{6}}{7}=\frac{a_{0}}{3\cdot5\cdot7},
$$
e assim por diante. Juntando estes coeficientes na série inicial temos
Retornando ao método de séries de potências, cabe completar nossa discussão com um comentário adicional. Para resolver o problema
(3)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{dy(x)}{dx}+G(x)y(x)=0,
$$
em torno de um ponto ordinário \(x_{0}\) fizemos a hipótese de que existe uma solução analítica em uma vizinhança deste ponto, ou seja, que possui uma expansão de Taylor
(4)
$$ y(x)=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n} $$
convergente no intervalo \(|x-x_{0}|\lt \rho\). Vamos verificar se esta é realmente uma hipótese justificada, examinando o raio de convergência da solução. Derivando (4) \(m\) vezes obtemos
Calculando o valor desta derivada m-ésima no ponto \(x=x_{0}\), vemos que todos os termos da soma se anulam exceto o termo \(m = n\) e podemos escrever
$$
y^{(m)}(x_{0})=m!a_{m},
$$
de onde encontramos um valor para o coeficiente
$$
a_{n}=\frac{y^{(n)}(x_{0})}{n!}.
$$
Surge aqui uma questão. Partindo apenas da equação diferencial (3) é sempre possível encontrar \(y^{(n)}(x_{0})\) e portanto \(a_{n}\). Suponhamos que \(y(x)=\phi(x)\) é uma solução satisfazendo as condições iniciais \(y(x_{0})=y_{0}\), \(y^{\prime}(x_{0})=y_{0}^{\prime}\). Neste caso \(a_{0}=y_{0},a_{1}=y_{0}^{\prime}\). De (3) temos \(P\phi^{\prime\prime}+F\phi^{\prime}+G\phi=0\), ou seja,
(5)
$$
\phi^{\prime\prime}=-\frac{F}{P}\phi^{\prime}-\frac{G}{P}\phi=-f\phi^{\prime}-g\phi,
$$
lembrando que \(P\neq0\) em torno de \(x_{0}\). Notando que
$$
2!a_{2}=\phi^{\prime\prime}(x_{0}),\;\;\phi(x_{0})=y_{0}=a_{0},\;\;\phi^{\prime}(x_{0})=y_{0}^{\prime}=a_{1}
$$
temos
$$
2!a_{2}=\phi^{\prime\prime}(x_{0})=-f(x_{0})y^{\prime}(x_{0})-g(x_{0})y(x_{0})=-f(x_{0})a_{1}-g(x_{0})a_{0}.
$$
Derivando a equação (5) e fazendo \(x=x_{0}\) temos
$$
3!a_{3}=\phi^{(3)}(x_{0})=-[f\phi^{\prime\prime}+(f^{\prime}+g)\phi^{\prime}+g^{\prime}\phi]|_{x=x_{0}}=
$$
$$
=-2!a_{2}f(x_{0})+[f^{\prime}(x_{0})+g(x_{0})]a_{1}+g^{\prime}(x_{0})a_{0},
$$
onde denotamos por \(\phi^{(3)}\) a derivada terceira. Se as funções \(f(x)\) e \(g(x)\) são polinômios então possuem derivadas de qualquer ordem e podemos prosseguir com este mesmo tipo de cálculo para encontrar os demais coeficientes \(a_n\), para \(n\gt 3\). Caso contrário, se forem funções mais gerais, como por exemplo um quociente de polinômios, então é necessário que sejam funções analíticas e possamos escrever
$$
f(x)=\sum_{n=0}^{\infty}f_{n}(x-x_{0})^{n},\,\,\,\,g(x)=\sum_{n=0}^{\infty}f_{n}(x-x_{0})^{n}
$$
para que o método possa ser empregado. Neste mesma linha de pensamento, generalizaremos a noção de ponto ordinário da equação (3) que repetiremos aqui:
(3 – repetida)
$$
P(x)\frac{d^{2}y(x)}{dx^{2}}+F(x)\frac{dy(x)}{dx}+G(x)y(x)=0,
$$
Então \(x_{0}\) é um ponto ordinário se \(f=F/P\) e \(g=G/P\) são analíticas em \(x=x_{0}\). Se isso não ocorrer o ponto \(x=x_{0}\) é um ponto singular.
Exercícios 1
Resolva as seguintes equações diferenciais usando o método de séries de potências em torno do ponto \(x_{0}=0\), exceto quando outro ponto for indicado:
Teorema 1 Se \(x=x_{0}\) é um ponto ordinário da equação \(Py^{\prime\prime}+Fy^{\prime}+Gy=0\), ou seja, se \(f=F/P\) e \(g=G/P\) são analíticas em \(x=x_{0}\) então a sua solução geral é
$$
y=\sum_{n=0}^{\infty}a_{n}(x-x_{0})^{n}=a_{0}y_{1}(x)+a_{1}y_{2}(x)
$$
onde \(y_{1}\) e \(y_{2}\) são linearmente independentes em \(x_{0}\). O raio de convergência da séries para \(y_{1}\) e \(y_{2}\) é, no mínimo, igual ao menor dos raios de convergência das séries de \(f\) e \(g\). Para determinar estes raios de convergência podemos expandir \(f\) e \(g\) em séries de Taylor e realizar os testes habituais de convergência (Consulte o apêndice.). Por outro lado, se \(P,\,\,F\) e \(G\) são polinômios, é possível mostrar usando a teoria das funções de variáveis complexas que \(G/P\) possui desenvolvimento em séries em torno de \(x=x_{0}\) se \(P(x_{0})\neq0\). Além disto, o raio de convergência desta série é \(\rho=|x_{0}-r|\) onde \(r\) é raiz de \(P\) mais próxima de \(x_{0}\). Mostraremos a seguir, através de exemplos o cálculo deste raio de convergência, em particular no caso de as raízes de \(P\) serem complexas.
Raios de Convergência
Exemplo 5. Qual é o raio de convergência da série de \(f(x)=(1+x^{2})^{-1}\) em torno de \(x=0\)? Devemos encontrar primeiro a expansão em séries de potência para esta função,
$$
f(x)=\sum_{n=0}^{\infty}\frac{1}{n!}f^{(n)}(x_{0})(x-x_{0})^{n}.
$$
Temos
$$
f(0)=1,\;f^{\prime}(x)=\frac{-2x}{(1+x^{2})^{2}}, \;f^{\prime}(0)=0,\;\text{etc.}
$$
A função pode ser expressa em série
$$
f(x)1-x^{2}+x^{4}-x^{6}+\cdots+(-1)^{n}x^{2n}.
$$
Pelo teste da razão
$$
L=\lim_{n\rightarrow\infty}|\frac{(-1)^{n+1}x^{2(n+1)}}{(-1)^{n}x^{2n}}|=x^{2}.
$$
Portanto, a série converge no intervalo \(-1\lt x\lt 1\), e o raio de convergência é \(\rho=1\). Um outro procedimento, em geral mais simples, pode ser adotado. As raizes de \(1+x^{2}\) são \(x=\pm i\). A distância no plano complexo entre \(0\) e \(i\) é \(1\). Dai \(\rho=1\).
Exemplo 6 Vamos verificar a convergência da série de \((x^{2}-2x+2)^{-1}\) em torno de \(x=0\) e \(x=1\). A função possui denominador que se anula em \(x=1\pm i\). No plano complexo a distância entre \(x=0\) e \(1\pm i\) é \(\rho=\sqrt{2}\), que é o raio de convergência da série desta função em torno de \(x=0\). A distância entre \(x=1\) e \(1\pm i\) é \(\rho=1\), que é o raio de convergência da série desta função em torno de \(x=1\).
Raios de convergência
Exemplo 7: Determine a raio de convergência mínimo da solução de
$$
(1+x^2)y^{\prime\prime}+2xy^{\prime}+4x^2y=0
$$
em torno de \(x=0\) e \(x=1/2\). Neste caso as funções \(P\), \(F\) e \(G\) são polinômios e \(P\) tem zeros em \(x=\pm i\). Os raios de convergência são, respectivamente as distâncias
$$
d(0,\pm i)=1,\,\,\,d\left(\frac{1}{2},\pm i\right)=\frac{\sqrt{5}}{2},
$$
onde \(d(a,b)\) é a distância entre os pontos \(a\) e \(b\) no plano complexo.
Uma equação diferencial que surge com freqüência em aplicações matemática aplicada e na física e que, por isto, vale a pena ser tratada em separado é a equação de Legendre
(6)
$$
(1-x^{2})y^{\prime\prime}-2xy^{\prime}+l(l+1)y=0,
$$
onde \(l\) é uma constante real dada. Observando que os dois primeiros termos são a derivada de uma função
$$
\frac{d}{dx}[(1-x^{2})y^{\prime}]=(1-x^{2})y^{\prime\prime}-2xy^{\prime}
$$
reescreveremos a equação como
$$
[(1-x^{2})y^{\prime}]^{\prime}+ky=0.
$$
onde denotamos \(k=l(l+1)\) para obter uma notação mais compacta. Como \(x=0\) é um ponto ordinário da equação substituimos a solução analítica \(y=\sum_{n=0}^{\infty}a_{n}x^{n}\) na equação (6) obtendo
$$
(1-x^{2})\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-2x\sum_{n=1}^{\infty}na_{n}x^{n-1}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0\Rightarrow
$$
$$
\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n-2}-\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n}-2x\sum_{n=1}^{\infty}na_{n}x^{n-1}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0\Rightarrow
$$
$$
\sum_{n=0}^{\infty}(n+2)(n+1)a_{n+2}x^{n}-\sum_{n=2}^{\infty}n(n-1)a_{n}x^{n}-2\sum_{n=1}^{\infty}na_{n}x^{n}+k\sum_{n=0}^{\infty}a_{n}x^{n}=0.
$$
Retomando a constante \(k=l(l+1)\), coletaremos primeiro os termos constantes (múltiplos de \(x^{0}\)) que correspondem àqueles quando \(n=0\):
$$
2a_{2}+l(l+1)a_{0}=0,
$$
e os termos coeficientes de \(x\,(n=1)\):
$$
6a_{3}+[-2+l(l+1)]a_{1}=0.
$$
Os termos restantes podem ser agrupados sob o mesmo sinal de somatório:
$$
\sum_{n=2}^{\infty}[(n+2)(n+1)a_{n+2}-n(n-1)a_{n}-2na_{n}+ka_{n}]x^{n}=0,
$$
que só é nulo se os coeficientes se anulam,
$$
(n+2)(n+1)a_{n+2}+\left[-n(n-1)-2n+l(l+1)\right]a_{n}=0,\,\,\,\,n\geq2.
$$
Podemos rearrumar a expressão em colchetes como \([…]=(l+n)(l+n+1)\) e dai obtemos a fórmula de recorrência
$$
a_{n+2}=-\frac{(l+n)(l+n+1)}{(n+2)(n+1)}a_{n},\,\,\,\,n\geq2.
$$
Destas relações podemos encontrar os coeficientes da expansão de \(y(x)\), em termos das constantes \(a_{0}\) e \(a_{1}\):
$$
a_{2}=-\frac{l(l+1)}{2!}a_{0},
$$
$$
a_{3}=-\frac{(l-1)(l+2)}{3!}a_{1},
$$
$$
a_{4}=-\frac{(l-2)(l+3)}{4\cdot3}a_{2}=\frac{(l-2)l(l+1)(l+3)}{4!}a_{0},
$$
$$
a_{5}=-\frac{(l-3)(l+4)}{5\cdot4}a_{3}=\frac{(l-3)(l-1)(l+2)(l+4)}{5!}a_{1},
$$
e assim por diante. Com estes coeficientes construimos duas soluções
$$
y_{1}(x)=1-\frac{l(l+1)}{2!}x^{2}+\frac{(l-2)l(l+1)(l+3)}{4!}x^{4}+\cdots,
$$
$$
y_{2}(x)=x-\frac{(l-1)(l+2)}{3!}x^{3}+\frac{(l-3)(l-1)(l+2)(l+4)}{5!}x^{5}+\cdots.
$$
Observe que \(y_{1}\) só possui potências pares de \(x\) e, portanto, é uma função par, enquanto \(y_{2}\) só possui potências ímpares de \(x\), sendo uma função impar. Logo elas são l. i. e \(y=a_{0}y_{1}+a_{1}y_{2}\) é uma solução geral da equação de Legendre. As soluções são convergentes no intervalo \(-1\lt x\lt 1\).
Solução em séries em torno de pontos singulares
Pontos singulares regulares
Se \(P(x),\,\,F(x)\) e \(G(x)\) são polinômios sem fatores comuns na equação
(7)
$$
P(x)y^{\prime\prime}+F(x)y^{\prime}+G(x)y=0,
$$
os pontos singulares da equação diferencial são aqueles onde \(P(x) = 0\). Neste caso o método tratado na seção anterior não pode ser aplicado pois a solução não será analítica nestes pontos.
Exemplo 8. A equação de Euler
$$
x^{2}y^{\prime\prime}-2y=0
$$
tem um ponto singular em \(x = 0\). Como vimos no capítulo anterior, esta equação tem soluções
$$
y_{1}=x^{2}\;\;\text{ e }\;\;y_{2}=\frac{1}{x}
$$
em um intervalo que não inclue o ponto singular. A primeira destas soluções é limitada e analítica em \(\mathbb{R}\). A segunda não é analítica em \(x=0\) e, por isto, não pode ser escrita como \(y_{2}=\sum_{n=0}^{\infty}a_{n}x^{n}\).
Definição Se as funções \(P\), \(F\) e \(G\) são polinômios e \(x_{0}\) é um ponto singular da equação (7) então \(x_{0}\) é chamado de ponto singular regular se existirem os limites
$$
\lim_{x\rightarrow x_{0}}(x-x_{0})\frac{F(x)}{P(x)},\;\;\; \lim_{x\rightarrow x_{0}}(x-x_{0})^{2}\frac{G(x)}{P(x)}.
$$
No caso de as funções \(P\), \(F\) e \(G\) não serem polinômios mas funções mais gerais, então um ponto singular \(x_{0}\) da equação (11) é um ponto singular regular se
$$
(x-x_{0})\frac{F(x)}{P(x)}\,\text{ e }\,(x-x_{0})^{2}\frac{G(x)}{P(x)}
$$
são funções analíticas. Se o ponto for singular mas não regular dizemos que ele é uma singularidade irregular.
Exemplo 9. Vamos verificar a natureza dos pontos singulares da equação de Legendre
$$
(1-x^{2})y-2xy^{\prime}+l(l+1)y=0,
$$
onde \(l\) é uma constante. Eles são regulares ou irregulares? Temos que, neste caso
$$
\frac{F(x)}{P(x)}=-\frac{2x}{1-x^{2}},\,\,\,\frac{G(x)}{P(x)}=\frac{l(l+1)}{1-x^{2}},
$$
e, portanto, \(x=\pm1\) são os pontos sigulares. O ponto \(x=1\) é ponto singular regular pois
$$
\lim_{x\rightarrow 1}(x-1)\frac{-2x}{1-x^{2}}=\lim_{x\rightarrow 1}\frac{-2x(x-1)}{(1-x)(1+x)}=\lim_{x\rightarrow 1}\frac{2x}{1+x}=1,
$$
$$
\lim_{x\rightarrow 1}(x-1)^{2}\frac{l(l+1)}{1-x^{2}}=\lim_{x\rightarrow 1}\frac{(1-x)^{2}l(l+1)}{(1-x)(1+x)}=\lim_{x\rightarrow 1}\frac{(1-x)l(l+1)}{1+x}=0.
$$
O mesmo ocorre com \(x=-1\),
$$
\lim_{x\rightarrow-1}(x+1)\frac{-2x}{1-x^{2}}=\lim_{x}\frac{-2x(x+1)}{(1-x)(1+x)}=\lim_{x}\frac{-2x}{1-x}=1,
$$
$$
\lim_{x\rightarrow-1}(x+1)^{2}\frac{l(l+1)}{1-x^{2}}=\lim_{x\rightarrow-1}\frac{(x+1)^{2}l(l+1)}{(1-x)(1+x)}=\lim_{x\rightarrow-1}\frac{(x+1)l(l+1)}{(1-x)}=0.
$$
Vimos, portanto, que os dois pontos singulares desta equação são regulares.
O Método de Frobenius
Existem diversos problemas advindos das aplicações onde a solução procurada está exatamente em torno de um ponto singular e portanto a técnica estudada até este ponto não é suficiente. Procuramos então encontrar soluções para equações diferenciais do tipo
(8)
$$P(x)y^{\prime\prime}+F(x)y^{\prime}+G(x)y=0,$$
em torno de \(x=x_{0}\), um ponto singular regular. Vale lembrar que \(f=F/P\) não é uma função analítica em torno destes pontos. Nos restringiremos ao estudos das soluções em torno de pontos singulares regulares. Podemos supor, sem perda de generalidade, que o ponto singular regular é \(x_{0}=0\). (Se não for este o caso basta fazer uma substituição de variável, tomando \(u=x-x_{0}\)). Como o ponto é regular, os limites
$$
\lim_{x\rightarrow0}x\frac{F}{P},\;\;\;\lim_{x\rightarrow0}x^{2}\frac{G}{P},
$$
são ambos finitos e as funções \(xF/P=xf\) e \(x^{2}G/P=x^{2}g\) são ambas analíticas. Sendo analíticas elas possuem expansão em séries de potências em torno \(x=0\)
$$
xf(x)=\sum_{n=0}^{\infty}f_{n}x^{n},\,\,\,\,x^{2}g(x)=\sum_{n=0}^{\infty}g_{n}x^{n},
$$
onde \(f_{n}\) e \(g_{n}\) são constantes, são convergentes em \(|x|\lt \rho\) em torno da origem. Dai notamos que
$$
f_{0}=\lim_{x\rightarrow0}x\frac{F}{P},\,\,\,\,g_{0}=\lim_{x\rightarrow0}x^{2}\frac{G}{P}.
$$
Reescrevemos a equação (8) multiplicada por \(x^{2}\) e dividida por \(P\).
$$
x^{2}y^{\prime\prime}+x\,xfy^{\prime}+x^{2}gy=0,
$$
ou ainda,
$$
x^{2}y^{\prime\prime}+xy^{\prime}\left(\sum_{n=0}^{\infty}f_{n}x^{n}\right)+y\left(\sum_{n=0}^{\infty}g_{n}x^{n}\right)=0,
$$
Note que esta seria uma equação de Euler se os termos dentro dos parênteses fossem constantes. Isto ocorreria se todas as constantes \(f_{n}\) e \(g_{n}\) (para \(n=1,\,2\),…) fossem nulas, restanto portanto apenas \(f_{0}\) e \(g_{0}\) não nulas. As equações de Euler foram resolvidas através da substituição \(y=x^{r}\). No caso presente tentaremos soluções na forma de
(9)
$$
y(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r}=x{}^{r}\sum_{n=0}^{\infty}a_{n}x^{n},
$$
onde \(r\) é uma constante por enquanto indeterminada. Deveremos ser capazes de determinar \(r\) por substituição de (9) na equação diferencial. Vamos ilustrar o uso desse método nos próximos exemplos.
Exemplo 10. A equação diferencial
$$
2xy^{\prime\prime}-y^{\prime\prime}+2y=0,
$$
possui um ponto singular em \(x=0\). Em torno deste ponto podemos utilizar a solução de Frobenius para resolvê-la. Vemos que, de fato, \(x=0\) é ponto singular regular pois
$$
f=-\frac{1}{2x},\,\,\,\,g=\frac{1}{x},
$$
$$
xf=-\frac{1}{2},\,\,\,\,x^{2}g=x,
$$
sendo os dois últimos termos finitos quando \(x\rightarrow0\). Derivamos a solução tentativa \(y(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r},\) obtendo
$$
y^{\prime}=\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1},
$$
$$
y^{\prime\prime}=\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}.
$$
Observe que agora não é necessário eliminar o termo com \(n=0\) na derivada primeira pois este não é um termo constante na equação. O mesmo ocorre com o termo \(n=1\) na derivada segunda. Substituindo as derivadas na equação temos
$$
2x\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}-\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+2\sum_{n=0}^{\infty}a_{n}x^{n+r}=0,
$$
ou seja,
$$
\sum_{n=0}^{\infty}(n+r)(2n+2r-3)a_{n}x^{n+r-1}+\sum_{n=0}^{\infty}2a_{n-1}x^{n+r-1}=0.
$$
O último somatório foi modificado da seguinte forma:
$$
\sum_{n=0}^{\infty}a_{n}x^{n+r}=\sum_{n=1}^{\infty}a_{n-1}x^{n+r-1},
$$
para facilitar a comparação entre todos os termos da série. Escrevemos agora o termo multiplo de \(x^{r-1}\), correspondente a \(n=0\), em separado e os demais termos dentro do mesmo somatório, que começa em \(n=1\):
$$
[2r(r-1)-r]a_{0}x^{r-1}+\sum_{n=1}^{\infty}[(n+r)(2n+2r-3)a_{n}+2a_{n-1}]x^{n+r-1}=0.
$$
Os coeficientes de cada potência de \(x\) devem se anular independentemente, em particular o termo multiplo de \(x^{r-1}\) que fornece valores para a constante \(r\), até aqui desconhecida. Supondo \(a_{0}\neq 0\) temos
$$
2r(r-1)-r=2r^{2}-3r=0,
$$
é a chamada equação indicial com raizes, \(r_{1}=0\) e \(r_{2}=3/2,\) que são denominadas os expoentes da singularidade. Os termos restantes podem ser escritos como
$$
\sum_{n=1}^{\infty}[(n+r)(2n+2r-3)a_{n}+2a_{n-1}]x^{n+r-1}=0.
$$
Anulando os coeficientes de todas as potências de \(x\) temos uma relação de recorrência para os termos \(a_{n}\).
$$
a_{n}=\frac{-2a_{n-1}}{(n+r)(2n+2r-3)},\,\,\,\,n\geq1.
$$
Podemos agora obter uma solução para cada um dos valores de \(r\). Para \(r=0\) temos:
$$
a_{n}=\frac{-2a_{n-1}}{n(2n-3)},\,\,\,\,n\geq1,
$$
o que leva aos coeficientes
A solução correspondente é
$$
y_{1}(x)=a_{0}\left(1+2x-2x^{2}+\frac{4}{9}x^{3}-\frac{2}{45}x^{4}+\frac{4}{45^{2}}x^{5}+\ldots\right).
$$
Para \(r=3/2\) a relação de recorrência se torna
$$
a_{n}=\frac{-2a_{n-1}}{2n(n+3/2)}=\frac{-2a_{n-1}}{n(2n+3)},\,\,\,\,n\geq1.
$$
$$
y_{2}(x)=a_{0}\left(1-\frac{2x}{5}+\frac{2x^{2}}{5.7}-\frac{4x^{3}}{3.5.7.9}+\frac{4x^{4}}{3.5.7.9.11}+\cdots\right).
$$
A solução geral é uma combinação linear das duas.
Exemplo 11. Utilizaremos o método de Frobenius para resolver a equação
$$
2x^{2}y^{\prime\prime}-xy^{\prime}+(1+x)y=0,
$$
em torno de \(x=0\). Novamente vemos que o ponto é singular regular pois
$$
f=-\frac{1}{2x},\,\,\,\,g=\frac{1+x}{2x^{2}},
$$
$$
xf=-\frac{1}{2},\,\,\,\,x^{2}g=\frac{1+x}{2}.
$$
Substituindo \(y=\sum_{n=0}^{\infty}a_{n}x^{n+r}\) e suas derivadas obtemos
$$
2x^{2}\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}-x\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+(1+x)\sum_{n=0}^{\infty}a_{n}x^{n+r}=0,
$$
$$
\sum_{n=0}^{\infty}\left[2(n+r)(n+r-1)-(n+r)+1\right]a_{n}x^{n+r-1}+\sum_{n=0}^{\infty}a_{n}x^{n+r+1}=0,
$$
A última soma pode ser reescrita, para efeito de comparação com os termos anteriores, da seguinte forma:
$$
\sum_{n=0}^{\infty}a_{n}x^{n+r+1}=\sum_{n=0}^{\infty}a_{n-1}x^{n+r}.
$$
Voltamos a escrever a equação diferencial com o termo \(n=0\) isolado:
$$
[2r(r-1)-r+1]a_{0}x^{r}+\sum_{n=0}^{\infty}\left\{ \left[2(n+r)(n+r-1)-(n+r)+1\right]a_{n}+a_{n-1}\right\} x^{n+r}=0.
$$
Os coeficientes de potências diversas de \(x\) devem se anular independentemente. Em particular o termo múltiplo de \(x^{r}\) nos permite encontrar a equação indicial
$$
2r(r-1)-(r-1)=(r-1)(2r-1)=0,
$$
cujas raizes são \(r_{1}=1\) e \(r_{2}=1/2.\) Anulando os coeficientes das demais potências de \(x\) temos
$$
[2(n+r)(n+r-1)-(n+r)+1]a_{n}+a_{n-1}=0
$$
o que é uma relação de recorrência para os termos \(a_{n}\).
$$
a_{n}=\frac{-a_{n-1}}{2(n+r)(n+r-1)-(n+r-1)}=\frac{-a_{n-1}}{(n+r-1)[2(n+r)-1]},\,\,\,n\geq1.
$$
Cada uma das raízes encontradas das para \(r\) nos fornece um conjunto de coeficientes. Para \(r=1\) a relação de recorrência é
$$
a_{n}=\frac{-a_{n-1}}{(2n+1)n},\,\,\,n\geq1,
$$
e portanto
$$
a_{1}=-\frac{a_{0}}{3},\,\,\,a_{2}=\frac{a_{0}}{30},\,\,\,a_{3}=\frac{-a_{0}}{630},\,\,\cdots
$$
O termo genérico pode ser obtido neste caso
$$
a_{n}=\frac{(-1)^{n}a_{0}}{3.5.7\cdots(2n+1)n!},\,\,\,n\geq1.
$$
A solução correspondente é
$$
y_{1}=x^{r}\sum_{n=0}^{\infty}a_{n}x^{n}=x\left[1+\sum_{n=1}^{\infty}\frac{(-1)^{n}x^{n}}{3.5.7\cdots(2n+1)n!}\right].
$$
Para \(r=1/2\) a relação de recorrência se torna
$$
a_{n}=\frac{-a_{n-1}}{n(2n-1)},\,\,\,n\geq1.
$$
Dai
$$
a_{1}=-a_{0},\,\,\,a_{2}=\frac{-a_{1}}{6}=\frac{a_{0}}{6},\,\,\,a_{3}=\frac{-a_{0}}{6.15}\cdots
$$
O termo genérico é
$$
a_{n}=\frac{(-1)^{n}a_{0}}{3.5.7\cdots\left(2n-1\right)n!},\,\,\,n\geq1.
$$
A solução correspondente é
$$
y_{2}=x^{r}\sum_{n=0}^{\infty}a_{n}x^{n}=x^{1/2}\left[1+\sum_{n=1}^{\infty}\frac{(-1)^{n}x^{n}}{3.5.7\cdots\left(2n-1\right)n!}\right].
$$
A solução geral do problema é uma combinação linear das duas soluções
$$
y(x)=c_{1}y_{1}(x)+c_{2}y_{2}(x).
$$
Fica como exercício o cálculo dos raios de convergência das soluções encontradas.
Retornando ao formalismo geral, resolvemos equações do tipo estudado por Frobenius através de soluções que se decompõem em séries de potência
$$
y=\sum_{n=0}^{\infty}a_{n}x^{n+r},
$$
cujas derivadas são
$$
y^{\prime}=\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1},\,\,\,\,y^{\prime\prime}=\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r-2}.
$$
Sendo \(x=0\) um ponto singular regular desta equação temos que \(xf\) e \(x^{2}g\) são analíticas e podem ser expressas como as séries de potências
$$
xf=\sum_{n=0}^{\infty}f_{n}x^{n}\,\,\text{e}\,\,x^{2}g=\sum_{n=0}^{\infty}g_{n}x^{n}.
$$
Substituindo \(y\) e suas derivadas na equação diferencial temos
$$
\sum_{n=0}^{\infty}(n+r)(n+r-1)a_{n}x^{n+r}+\left(\sum_{n=0}^{\infty}f_{n}x^{n}\right)\sum_{n=0}^{\infty}(n+r)a_{n}x^{n+r-1}+
$$
$$
+\left(\sum_{n=0}^{\infty}g_{n}x^{n}\right)\sum_{n=0}^{\infty}a_{n}x^{n+r}=0.
$$
Fazendo a multiplicação das séries infinitas obtemos
$$
a_{0}F(r)x^{r}+\sum_{n=1}^{\infty}\left\{ F(r+n)a_{n}+\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}\right\} +x^{r+n}=0,
$$
onde
$$
F(r)=r(r-1)+f_{0}r+g_{0}.
$$
Para que o polinômio seja nulo o coeficiente de cada potência de \(x\) deve ser nulo. Como \(a_{0}\neq0\), a anulação do coeficiente de \(x^{r}\) leva à equação indicial, \(F(r)=0\). Caso existam duas raizes reais distintas para esta equação construimos duas soluções l. i.,
$$
y_{1}=x^{r_{1}}\sum_{n=0}^{\infty}a_{n}x^{n},\,\,\,\,y_{2}=x^{r_{2}}\sum_{n=0}^{\infty}b_{n}x^{n},
$$
e uma combinação linear destas duas representa uma solução geral do problema. Por outro lado, se as raízes da equação indicial forem iguais ou se diferirem por um inteiro, um tratamento diferenciado deve ser adotado, como se segue.
Raízes iguais ou que diferem por um inteiro
Na solução da equação de Euler vimos que se \(r_{1}=r_{2}\) então temos uma solução involvendo o logaritmo. O mesmo ocorre aqui, como expresso pelo teorema a seguir.
Teorema Considere a equação diferencial
(10)
$$
L[y]=x^{2}y^{\prime\prime}+x[xf(x)]y^{\prime}+[x^{2}g(x)]y=0,
$$
onde \(x=0\) é ponto singular regular. Neste caso \(xf\) e \(x^{2}g\) são analíticas e podem ser expressas como as séries de potências
$$
xf=\sum_{n=0}^{\infty}f_{n}x^{n},\,\,\,\,\,x^{2}g=\sum_{n=0}^{\infty}g_{n}x^{n}.
$$
A equação indicial é
$$
F(r)=r(r-1)+f_{0}r+g_{0}=0.
$$
Se as raizes desta equação forem reais, tome \(r_{1}\) como sendo a maior delas, \(r_{1}\geq r_{2}\). Uma das soluções será
$$
y_{1}(x)=|x|^{r_{1}}\left[1+\sum_{n=1}^{\infty}a_{n}x^{n}\right],
$$
onde estes coeficientes \(a_{n}\) foram calculados tomando-se \(r=r_{1}\). Caso a segunda raiz seja igual, \(r_{2}=r_{1}\) então uma segunda solução será
$$
y_{2}(x)=y_{1}(x)ln|x|+|x|^{r_{1}}\left[1+\sum_{n=1}^{\infty}b_{n}x^{n}\right].
$$ Se as raizes diferirem por um inteiro \(N\), \(r_{1}-r_{2}=N,\) então uma segunda solução será
$$
y_{2}(x)=Cy_{1}(x)\ln|x|+|x|^{r_{2}}\left[1+\sum_{n=1}^{\infty}c_{n}x^{n}\right],
$$
onde \(C\) é outra constante e os coeficientes \(c_{n}\) foram calculados tomando-se \(r=r_{2}\).
No caso das raizes iguais temos apenas uma solução e procuramos por uma segunda, da mesma forma que fizemos ao tratar das equações de Euler. Vamos procurar uma solução da equação (10) sob a forma de
$$
y=\phi(r,x)=x^{r}\left(\sum_{n=0}^{\infty}a_{n}x^{n}\right),
$$
uma função que depende de \(x\) e de \(r\). Como antes, obtemos a equação
(11)
$$
L\left[\phi\right](r,x)=a_{0}F(r)x^{r}+\sum_{n=1}^{\infty}\left\{ F(r+n)a_{n}+\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}\right\} x^{r+n}.
$$
Se as raizes são iguais fazemos \(r=r_{1}\) nesta equação e escolhemos \(a_{n}\) obtendo uma solução. Para encontrar a outra solução tomamos \(a_{n}\) de forma a anular o termo entre colchetes,
(12)
$$
a_{n}=-\frac{\sum_{k=0}^{n-1}\left[\left(r+k\right)f_{n-k}+g_{n-k}\right]a_{k}}{F(r+n)},\,\,\,n\geq1,
$$
agora com \(r\) variando continuamente. Admitimos que \(F(r+n)\neq0\). Com esta escolha a equação (11) se reduz a
$$
L\left[\phi\right](r,x)=a_{0}F(r)x^{r},
$$
onde \(F(r)=(r-r_{1})^{2}\), já que \(r_{1}\) é uma raiz dupla da equação indicial. Tomando \(r=r_{1}\) obtemos a solução que já conhecemos,
$$
y_{1}(x)=\phi(r_{1},x)=x^{r_{1}}\left(a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right).
$$
Da mesma forma como fizemos com a equação de Euler, temos agora que
$$
L\left[\frac{\partial\phi}{\partial r}\right]\left(r_{1},x\right)=a_{0}\left.\frac{\partial}{\partial r}[x^{r}(r-r_{1})^{2}]\right|_{r=r_{1}}=
$$
$$
a_{0}[(r-r_{1})^{2}x^{r}\ln x+2(r-r_{1})x^{r}]|_{r=r_{1}}=0,
$$
de onde podemos concluir que
$$
y_{2}(x)=\frac{\partial\phi\left(r_{1},x\right)}{\partial r}|_{r=r_{1}}
$$
é também uma solução. Para obter a forma final desta solução vamos executar a derivação indicada:
$$
y_{2}(x)=\frac{\partial}{\partial r}\left[x^{r_{1}}\left(a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right)\right]{}_{r=r_{1}}=\left(x^{r_{1}}\ln x\right)\left[a_{0}+\sum_{n=1}^{\infty}a_{n}x^{n}\right]+x^{r_{1}}\sum_{n=1}^{\infty}a_{n}^{\prime}x^{n}=
$$
$$
=y_{1}(x)\ln x+x^{r_{1}}\sum_{n=1}^{\infty}a_{n}^{\prime}x^{n},\,\,\,\,x\gt 0,
$$
onde \(a_{n}^{\prime}=da_{n}/dr\) no ponto \(r=r_{1}\), sendo que \(a_{n}\) é obtida através da equação (12) , vista como função de \(x\) e \(r\).
No caso de raizes diferindo por um inteiro a solução se torna um pouco mais complicada. Apenas para esboçar a solução, se tentarmos usar uma solução na forma de
$$
y_{2}(x)=\sum_{n=0}^{\infty}a_{n}x^{n+r_{2}},
$$
teríamos dificuldades ao calcular o termo \(a_{N}\), quando \(r=r_{2}\), por meio da equação (12). Neste caso temos
$$
F(r+N)=(N+r-r_{1})(N+r-r_{2})=(N+r-r_{2})(r-r_{2}),
$$
que é nula quando \(r=r_{2}\). Para contornar esta dificuldade escolhemos \(a_{0}=r-r_{2}\) e os demais termos \(a_{n}\) se tornam todos múltiplos de \(r-r_{2}\) uma vez que são múltiplos de \(a_{0}\) pela equação de recorrência. O fator comum \(r-r_{2}\) no numerador de (12) pode ser cancelado pelo termo igual no denominador, que surge quando \(n=N\). Fazendo uma análise análoga à que foi feita no caso anterior, de raizes iguais, encontra-se uma solução com a forma de
$$
y_{2}(x)=Cy_{1}(x)\ln\left|x\right|+\left|x\right|^{r_{2}}\left[1+\sum_{n=1}^{\infty}c_{n}x^{n}\right],
$$
onde os coeficientes \(c_{n}\) são dados por
$$
c_{n}=\left[\frac{d}{dr}\left(r-r_{2}\right)a_{n}\right]{}_{r=r_{2}},\,\,\,\,n=1,2,\ldots
$$
e \(a_{n}\) são definidos pela equação (12) com \(a_{0}=1\) e
$$
C=\lim_{r\rightarrow r_{2}}(r-r_{2})a_{N}.
$$
Observe que pode ocorrer que \(C\) seja nulo. Neste caso o termo com logaritmo não aparece na solução procurada.