Outras formas do construtor de dataframes
Se um dicionário aninhado (onde os valores associados às chaves externas são outros dicionários) é passado no construtor de um DataFrame o pandas interpretará as chaves externas como nomes das colunas e as chaves internas como índices das linhas. Na ausência de um par chave:valor em um ou mais dos dicionários o campo receberá o valor NaN.
» dic = {'Pedro': {'Prova 1': 5.4, 'Prova 3': 7.9},
'Ana': {'Prova 1': 8.5, 'Prova 2': 9.7, 'Prova 3': 6.6},
'Luna': {'Prova 2': 5.0, 'Prova 3': 7.0, 'Prova 4': 6.0}
}
» dfNotas = pd.DataFrame(dic)
» dfNotas
↳
Pedro Ana Luna
Prova 1 5.4 8.5 NaN
Prova 3 7.9 6.6 7.0
Prova 2 NaN 9.7 5.0
Prova 4 NaN NaN 6.0
Se os nomes das linhas e das colunas forem fornecidos eles serão exibidos.
» dfNotas.index.name = 'Prova'; » dfNotas.columns.name = 'Aluno' » dfNotas ↳ Aluno Pedro Ana Luna Prova Prova 1 5.4 8.5 NaN Prova 3 7.9 6.6 7.0 Prova 2 NaN 9.7 5.0 Prova 4 NaN NaN 6.0
Com frequência importamos de fontes externas, como faremos abaixo, uma fonte de dados e precisamos verificar sua integridade. Por ex., para encontrar elementos ausentes, preenchidos como NaN, usamos dataFrame.isnull() (o mesmo que pd.isnull(dataFrame)). Para saber quantos valores nulos existem usamos dataFrame.isnull().sum(), que fornece a soma dos campos True para cada campo.
» dfNotas.isnull() # o mesmo que pd.isnull(dfNotas) ↳ Aluno Pedro Ana Luna Prova Prova 1 False False True Prova 3 False False False Prova 2 True False False Prova 4 True True False » dfNotas.isnull().sum() ↳ Aluno Pedro 2 Ana 1 Luna 1 dtype: int64
O método dataFrame.notna() (o mesmo que dataFrame.notnull() e o inverso de dataFrame.isnull()) retorna um dataframe booleano com True onde os campos não são nulos. Para inserir manualmente campos nulos usamos a constante pd.NaT e para eliminar linhas (ou colunas) contendo nulos aplicamos dataframe.dropna().
» # para eliminar linhas contendo nulos (o default é axis=0)
» dfNotas.dropna()
↳ Aluno Pedro Ana Luna
Prova
Prova 3 7.9 6.6 7.0
» # para eliminar colunas contendo nulos
» dfNotas.dropna(axis=1)
# todas são eliminadas pois existem NaN em todas as colunas
Evidentemente é necessário ter cuidado ao eliminar linhas ou colunas com NaN. Em muitos casos pode ser necessário substituir esses valores por outros, dependendo da aplicação. Para fazer a alteração no próprio frame use o parâmetro inplace = True.
Colunas e índices são objetos do tipo array e podem ser usados com alguns métodos de conjuntos.
» dfNotas.columns ↳ Index(['Pedro', 'Ana', 'Luna'], dtype='object', name='Aluno') » dfNotas.index ↳ Index(['Prova 1', 'Prova 3', 'Prova 2', 'Prova 4'], dtype='object', name='Prova') » 'Ana' in dfNotas.columns # True » 'Ann' in dfNotas.columns # False » 'Prova 5' in dfNotas.index # False
O mesmo ocorre se o dicionário contiver Series como valores, sendo as chaves usadas como nomes das colunas e os índices das series usados como índices das linhas.
» serie1 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
» serie2 = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
» serie3 = pd.Series([9, 0, -1, -2], index=['a', 'b', 'c', 'd'])
» dic = {'A':serie1, 'B':serie2, 'C':serie3 }
» pd.DataFrame(dic)
↳
A B C
a 1 5 9
b 2 6 0
c 3 7 -1
d 4 8 -2
Dataframes podem ser criados recebendo Series no construtor.
» disciplinas = pd.Series(['Matemática', 'Física', 'História', 'Geografia'])
» notas = pd.Series([9.0, 5.4, 7.7, 8.9])
» df = pd.DataFrame({'Disciplina':disciplinas, 'Notas': notas})
» df
↳ Disciplina Notas
0 Matemática 9.0
1 Física 5.4
2 História 7.7
3 Geografia 8.9
Outros objetos podem ser passados como argumento no construtor:
- Ndarray (do NumPy) de 2 dimensões,
- dicionário de arrays, listas ou tuples (todas as sequências devem ter o mesmo comprimento),
- dicionários de arrays NumPy, de Series ou de outros dicionários,
- listas de dicionários, Series, listas ou tuplas,
- Series ou outro dataframe.
Tratamento de dados usando pandas.dataframe
Para os testes e demonstrações que se seguem vamos usar dados reais para demonstrar algumas funcionalidades úteis dos pandas.dataframes.
Fonte de dados
Para realizar os teste com dataframes vamos utilizar os dados encontrados no Gapminder nessa url: 08_gap-every-five-years.tsv. Esse é um arquivo contendo dados com um registro em cada linha e os valores na linha separados por tabs, (tabulação). Esse arquivo pode ser baixado para o seu computador e depois importado para um dataframe ou, como usamos abaixo, importada diretamente do site de Jennifer Bryan (jennybc): Gapminder, no Github.
O arquivo original tem o seguinte formato,
country continent year lifeExp pop gdpPercap Afghanistan Asia 1952 28.801 8425333 779.4453145 Afghanistan Asia 1957 30.332 9240934 820.8530296 Afghanistan Asia 1962 31.997 10267083 853.10071 ...
onde os espaços entre valores são tabulações (\t, no python). A primeira linha contém os ‘headers’ ou títulos das colunas. Traduziremos esses títulos da seguinte forma: country ⟼ pais, continent ⟼ continente, year ⟼; ano, lifeExp ⟼ expVida (expectativa de vida), pop ⟼ populacao, gdpPercap ⟼ pibPercap (produto interno bruto, percapita).
» import pandas as pd
» import numpy as np
» # Usando arquivo encontrado no Gapminder
» url =(
'https://raw.githubusercontent.com/jennybc/'
'gapminder/master/data-raw/08_gap-every-five-years.tsv'
)
» url
↳ 'https://raw.githubusercontent.com/jennybc/gapminder/master/data-raw/08_gap-every-five-years.tsv'
» # criamos o dataframe dfPaises. O arquivo importado tem campos separados por tabs
» dfPaises = pd.read_csv(url, sep='\t')
» # o dataframe tem 1704 linhas e 6 colunas
» dfPaises.shape
↳ (1704, 6)
» dfPaises.head()
↳
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
1704 rows × 6 columns
» # renomeando os campos para nomes em português
» dfPaises.rename(columns={'country':'pais',
'continent':'continente',
'year':'ano',
'lifeExp':'expVida',
'pop':'populacao',
'gdpPercap':'pibPercap',
}, inplace=True)
» # ficamos assim
» dfPaises.columns
↳ Index(['pais', 'continente', 'ano', 'expVida', 'populacao', 'pibPercap'], dtype='object')
» # para reordenar as colunas em sua exibição
» dfPaises = dfPaises[['continente', 'pais', 'ano', 'expVida', 'populacao', 'pibPercap']]
Podemos obter uma visão geral do conjunto de dados importados usando dois métodos. dataframe.info() retorno os nomes das colunas, quantos valores não nulos, seus dtypes, e memória usada nesse armazenamento. Por aí vemos que nossos dados não possuem valores nulos. Caso esses existissem eles teriam que ser localizados e tratados devidamente. O método df.describe() retorna um dataframe contendo a contagem count dos valores (nesse caso, o número de linhas), a média mean desses valores, o desvio padrão std, o valor mínimo e máximo, min, max e os quartis em 25%, 50%, 75%.
» dfPaises.info()
↳ <class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 continente 1704 non-null object
1 pais 1704 non-null object
2 ano 1704 non-null int64
3 expVida 1704 non-null float64
4 populacao 1704 non-null int64
5 pibPercap 1704 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 80.0+ KB
» dfPaises.describe()
↳
ano expVida populacao pibPercap
count 1704.00000 1704.000000 1.704000e+03 1704.000000
mean 1979.50000 59.474439 2.960121e+07 7215.327081
std 17.26533 12.917107 1.061579e+08 9857.454543
min 1952.00000 23.599000 6.001100e+04 241.165876
25% 1965.75000 48.198000 2.793664e+06 1202.060309
50% 1979.50000 60.712500 7.023596e+06 3531.846988
75% 1993.25000 70.845500 1.958522e+07 9325.462346
max 2007.00000 82.603000 1.318683e+09 113523.132900
Gravação e recuperação de dados em arquivos pickle
Após a verificação de integridade dos dados e a realização das alterações básicas necessárias é boa ideia salvar em disco o dataframe nesse momento. Para isso usamos pandas.to_pickle(dfFrame, 'nomeArquivo.pkl'), gravando um arquivopickle. Para recuperá-lo em qualquer momento usamos dfPaises = pandas.read_pickle('./dados/dataframePaises.pkl').
» # gravando um arquivo pickle
» pd.to_pickle(dfPaises, './dados/dataframePaises.pkl')
» # mais tarde esse dataframe pode ser recuperado
» del dfPaises # para limpar essa variável
» dfPaises = pd.read_pickle('./dados/dataframePaises.pkl')
» # o dataframe é recuperado
Seleção e filtragem
As principais formas de seleção de um ou mais valores de um dataframe são os métodos dataframe.loc(), dataframe.iloc(), dataframe.at e dataframe.iat. Um subconjunto de dados do dataframe, seja por seleção de linhas, colunas ou ambas, é denominado de fatia ou slice.
A principal diferença entre loc (at) e iloc (iat) é a seguinte: loc é baseado em labels ou nomes das linhas ou colunas, enquanto iloc é baseado nos índices numéricos (mesmo que tenham nomes) sempre com base 0.
dataframe.at[row_label, column_label]dataframe.iat[row_position, column_position]dataframe.loc[row_label, column_label]dataframe.iloc[row_position, column_position]
Na tabela abaixo nos referiremos a um dataframe nomeado como df. (S) se refere a uma Series retornada, (D) a um dataframe.
| Operações df.iat e df.at | retorna: (índices são posições linhas/colunas) |
|---|---|
df.iat[m,n] |
elemento da m-ésima linha, n-ésima coluna |
df.at[lblLinha, lblColuna] |
elemento linha/coluna relativas aos labels lblLinha/lblColuna |
| Operações df.iloc | retorna: (índices são posições das linhas/colunas) |
df.iloc[n] |
n-ésima linha (S) |
df.iloc[[n]] |
n-ésima linha (D) |
df.iloc[-n] |
n-ésima linha, contando do final |
df.iloc[i,j:, n] |
linhas i, até j (exclusive), coluna n (S) |
df.iloc[[i,j,k]:[m,n,o]] |
linhas i, j, k, colunas m, n, o |
df.iloc[:, n] |
n-ésima coluna (S) |
df.iloc[:, [n]] |
n-ésima coluna (D) |
df.iloc[:,-1] |
última coluna |
df.iloc[i:j,m:n] |
linhas i até j (exclusive), colunas m até n (inclusive) |
| Operações df.loc | retorna: (índices linhas/colunas se referem aos seus labels) |
df.loc[n] |
linha de índice n (S) |
df.loc[[n]] |
linha de índice n (D) |
df.loc[:] |
todas as linhas e colunas (D) |
df.loc[:, 'col'] |
todas as linhas, coluna ‘col’ (S) |
df.loc[:, ['col']] |
todas as linhas, coluna ‘col’ (D) |
df.loc[:, ['col1', 'col2']] |
todas as linhas, colunas ‘col1’ e ‘col2’ (D) |
df.loc[i:j, ['col1', 'col2']] |
linhas com índices de i até i (inclusive), colunas ‘col1’ e ‘col2’ (D) |
df.loc[[i,j,k] , ['col1', 'col2']] |
linhas com índices i, j, k, colunas ‘col1’ e ‘col2’ (D) |
df.loc[i:j, 'col1':'coln']] |
linhas com índices i até j (inclusive), colunas ‘col1’ até ‘coln’ (inclusive) (D) |
| Atalhos | o mesmo que |
df['col1'] ou df.col1 |
df.loc[:, ‘col1’]] (S) |
df[['col1', 'col2']] |
df.loc[:, [‘col1’, ‘col2’]] (D) |
Em todos esses métodos uma exceção de KeyError é levantada se um índice ou label não existir na dataframe.
Se o index da linha coincidir com sua posição então df.loc[n] e df.iloc[n] serão as mesmas linhas. Isso nem sempre é verdade, como se verá abaixo com o reordenamento das linhas.
São incorretas as sintaxes: df.loc[-n], df.loc[:, n], df.loc[:, [n]] com n numérico pois os labels devem ser fornecidos.
Exemplos de consultas e seleções
dataframe.iloc()Para outros exemplos vamos usar o dataframe já carregado, dfPaises, para fazer consultas e seleções, primeiro usando dataframe.iloc(). Lembramos que a contagem de índices sempre se inicia em 0:
» # lembrando que dfPaises.iloc[[0]] é um dataframe, dfPaises.iloc[0] é uma Series » # primeira linha, pelo índice » dfPaises.iloc[[0]] ↳ continente pais ano expVida populacao pibPercap 0 Asia Afghanistan 1952 28.801 8425333 779.445314 » # última linha, pelo índice » dfPaises.iloc[[-1]] ↳ continente pais ano expVida populacao pibPercap 1703 Africa Zimbabwe 2007 43.487 12311143 469.709298 » # linhas 15 até 20 (exclusive), colunas 2 até 5 (exclusive) » dfPaises.iloc[15:20, 2:5] ↳ ano expVida populacao 15 1967 66.22 1984060 16 1972 67.69 2263554 17 1977 68.93 2509048 18 1982 70.42 2780097 19 1987 72.00 3075321 » # linhas 1, 3, 5 , colunas 2, 5 » dfPaises.iloc[[1,3,5],[2,5]] ↳ ano pibPercap 1 1957 820.853030 3 1967 836.197138 5 1977 786.113360 » # linhas 1, 3, 5, última coluna » dfPaises.iloc[[1,3,5],-1] ↳ 1 820.853030 3 836.197138 5 786.113360 Name: pibPercap, dtype: float64 » # todas as linhas, coluna 3 » dfPaises.iloc[:, [3]].head() ↳ expVida 0 28.801 1 30.332 2 31.997 3 34.020 4 36.088 » # linhas 0, 3, 6, 24; colunas 0, 3, 5 » dfPaises.iloc[[0,3,6,24], [0,3,5]] ↳ continente expVida pibPercap 0 Asia 28.801 779.445314 3 Asia 34.020 836.197138 6 Asia 39.854 978.011439 24 Africa 43.077 2449.008185
A seleção das linhas nos dois métodos é diferente. Em dataframe.loc[m,n] linhas com labels de m até n (inclusive) são selecionadas. Em dataframe.iloc[m,n] são selecionadas linhas com índices (numéricos) de m até n (exclusive).
» # iloc[m,n] exibe linhas m até n (exclusive) » dfPaises.iloc[1:2] ↳ continente pais ano expVida populacao pibPercap 1 Asia Afghanistan 1957 30.332 9240934 820.85303 » # loc[m:n] exibe linhas m até n (inclusive) » dfPaises.loc[1:2] ↳ continente pais ano expVida populacao pibPercap 1 Asia Afghanistan 1957 30.332 9240934 820.85303 2 Asia Afghanistan 1962 31.997 10267083 853.10071
dataframe.loc()Os próximos testes são feitos com dataframe.loc(), que deve receber os labels como índices.
» # todas as linhas, só colunas 'ano' e 'populacao' (limitadas por head()) » dfPaises.loc[:,['ano','populacao']].head() ↳ ano populacao 0 1952 8425333 1 1957 9240934 2 1962 10267083 3 1967 11537966 4 1972 13079460 » # linhas 3 até 6 (inclusive), só colunas 'ano' e 'expVida' » dfPaises.loc[3:6,['ano', 'expVida']] ↳ ano expVida 3 1967 34.020 4 1972 36.088 5 1977 38.438 6 1982 39.854 » # todas as linhas, só colunas 'ano' (restritas por head()) » dfPaises.loc[:, 'ano'].head() ↳ 0 1952 1 1957 2 1962 3 1967 4 1972
Métodos df.loc, df.iloc, df.at e df.iat
Para explorar um pouco mais a diferença no uso de df.loc e df.iloc vamos criar um dataframe bem simples e sem valores nulos.
» dic = {'Pedro': {'Prova 1': 5.4, 'Prova 2': 6.2, 'Prova 3': 7.9},
'Ana': {'Prova 1': 8.5, 'Prova 2': 9.7, 'Prova 3': 6.6},
'Luna': {'Prova 1': 5.0, 'Prova 2': 7.0, 'Prova 3': 4.3}
}
» dfNotas = pd.DataFrame(dic)
» dfNotas
↳ Pedro Ana Luna
Prova 1 5.4 8.5 5.0
Prova 2 6.2 9.7 7.0
Prova 3 7.9 6.6 4.3
df.loc e df.at usa labels de linhas e colunas.
df.iloc e df.iat usa números (índices) de linhas e colunas.
Nos comentários listamos seleções usando df.iloc para se obter o mesmo retorno.
» dfNotas.loc['Prova 1','Luna'] # dfNotas.iloc[0,2] ↳ 5.0 » dfNotas.loc['Prova 1'] # dfNotas.iloc[0] (Series) ↳ Pedro 5.4 Ana 8.5 Luna 5.0 » dfNotas.loc[['Prova 1']] # dfNotas.iloc[[0]] (dataframe) ↳ Pedro Ana Luna Prova 1 5.4 8.5 5.0 » dfNotas.loc[['Prova 1','Prova 2']] # dfNotas.iloc[0:2] (dataframe) ↳ Pedro Ana Luna Prova 1 5.4 8.5 5.0 Prova 2 6.2 9.7 7.0 » dfNotas.loc['Prova 1': 'Prova 3'] # dfNotas.iloc[0:3] (dataframe) ↳ Pedro Ana Luna Prova 1 5.4 8.5 5.0 Prova 2 6.2 9.7 7.0 Prova 3 7.9 6.6 4.3 » dfNotas.loc[['Prova 1'],['Ana','Luna']] # dfNotas.iloc[[0],[1,2]] (dataframe) ↳ Ana Luna Prova 1 8.5 5.0 » dfNotas.loc['Prova 1':'Prova 3', 'Pedro':'Luna'] # dfNotas.iloc[0:3,0:3] (dataframe) ↳ Pedro Ana Luna Prova 1 5.4 8.5 5.0 Prova 2 6.2 9.7 7.0 Prova 3 7.9 6.6 4.3 » dfNotas.loc[:,['Luna']] # dfNotas.iloc[:,[2]] ↳ Luna Prova 1 5.0 Prova 2 7.0 Prova 3 4.3
Observe que em dfNotas.iloc[0:3,0:3] são selecionadas as linhas de índices 0, 1 e 2 e colunas 0, 1 e 2.
Análogos à df.loc e df.iloc temos, respectivamente, df.at[lblLinha, lblColuna] e df.iat[m,n] onde lblLinha, lblColuna se referem aos labels e m, n aos índices das linhas/colunas. Ambos recebem um par e retornam um único valor do dataframe. Quando aplicados em uma Series iat e at recebem um único índice/label localizador de posição.
» dfNotas.iat[2,1] ↳ 6.6 » dfNotas.iloc[0].iat[1] # o mesmo que dfNotas.loc['Prova 1'].iat[1] ↳ 8.5 » dfNotas.at['Prova 1', 'Luna'] ↳ 5.0 » dfNotas.loc['Prova 1'].at['Ana'] # o mesmo que dfNotas.loc['Prova 1'].iat[1] ↳ 8.5
Nenhuma das duas formas de seleção de uma slice (.loc ou .iloc) copiam um dataframe por referência, como ocorre com numPy.ndarrays. Por exemplo, df = dfNotas.iloc[:,[2]] é uma cópia da 3ª coluna, e não uma referência ou view. Ela pode ser alterada sem que o dataframe original seja modificado. Se um novo valor for atribuído ao slice diretamente, no entanto, o dataframe fica alterado.
» df = dfNotas.iloc[:,[2]]
» df.Luna = 10
» display(df,dfNotas)
↳ Luna
Prova 1 10
Prova 2 10
Prova 3 10
↳ Pedro Ana Luna
Prova 1 5.4 8.5 5.0
Prova 2 6.2 9.7 7.0
Prova 3 7.9 6.6 4.3
» # no entanto se o slice receber atribuição direta o dataframe fica alterado
» dfNotas.iloc[:,[2]] = 10
» dfNotas
↳ Pedro Ana Luna
Prova 1 5.4 8.5 10.0
Prova 2 6.2 9.7 10.0
Prova 3 7.9 6.6 10.0
» # para inserir valores diferentes outro dataframe de ser atribuído ao slice
» dic = {'Luna': {'Prova 1': 8.5, 'Prova 2': 7.9, 'Prova 3': 10}}
» dfLuna = pd.DataFrame(dic)
» dfNotas.iloc[:,[2]] = dfLuna
» dfNotas
↳ Pedro Ana Luna
Prova 1 5.4 8.5 8.5
Prova 2 6.2 9.7 7.9
Prova 3 7.9 6.6 10.0
» # alternativamente, um np.array com shape apropriado pode ser atribuído ao slice
» arrLuna =np.array([2.3, 4.5, 5.6]).reshape(3,1)
» dfNotas.iloc[:,[2]] = arrLuna
» dfNotas
↳ Pedro Ana Luna
Prova 1 5.4 8.5 2.3
Prova 2 6.2 9.7 4.5
Prova 3 7.9 6.6 5.6
Na atribuição dfNotas.iloc[:,[2]] = 10 houve o broadcasting de 10 para uma forma compatível com o slice.
Para que a atribuição seja bem sucedida, sem necessidade de broadcasting, um objeto de mesmo formato deve ser atribuído. No caso dfNotas.iloc[:,[2]].shape = dfLuna.shape = (3, 1) (3 linhas, 1 coluna). O mesmo ocorre com a atribuição de um array do numpy.
Manipulando linhas e colunas
Um array booleano pode ser passado como índice de um dataframe. Apenas as linhas correspondentes ao índice True será exibida. Alguns métodos de string estão disponíveis para testes em campos, como df['campo'].str.startswith('str') e df['campo'].str.endswith('str') (começa e termina com). O teste df['campo'].isin(['valor1', 'valor2'])] retorna True se os campos estão contidos na lista.
Para os exemplos usamos o dataframe dfPaises.
» # seleção por array booleano
» dfPaises.loc[dfPaises['ano'] == 2002].head(3)
↳ continente pais ano expVida populacao pibPercap
10 Asia Afghanistan 2002 42.129 25268405 726.734055
22 Europe Albania 2002 75.651 3508512 4604.211737
34 Africa Algeria 2002 70.994 31287142 5288.040382
» # quais os paises tem nome começados com 'Al'
» dfPaises.loc[dfPaises['pais'].str.startswith('Al')]['pais'].unique()
↳ array(['Albania', 'Algeria'], dtype=object)
» # quais os paises tem nome terminados em 'm'
» dfPaises.loc[dfPaises['pais'].str.endswith('m')]['pais'].unique()
↳ array(['Belgium', 'United Kingdom', 'Vietnam'], dtype=object)
» # quantas linhas se referem à 'Europe' e 'Africa'
» dfPaises.loc[dfPaises['continente'].isin(['Europe', 'Africa'])].shape[0]
↳ 984
» dfPaises.loc[(dfPaises['continente']=='Africa') & (dfPaises['ano']==1957)].head(4)
↳ continente pais ano expVida populacao pibPercap
25 Africa Algeria 1957 45.685 10270856 3013.976023
37 Africa Angola 1957 31.999 4561361 3827.940465
121 Africa Benin 1957 40.358 1925173 959.601080
157 Africa Botswana 1957 49.618 474639 918.232535
» # paises e anos com população < 7000 ou expectativa de vida > 82
» dfPaises.loc[(dfPaises['populacao'] < 70000) | (dfPaises['expVida'] > 82)][['ano','pais']]
↳ ano pais
420 1952 Djibouti
671 2007 Hong Kong, China
803 2007 Japan
1296 1952 Sao Tome and Principe
1297 1957 Sao Tome and Principe
1298 1962 Sao Tome and Principe
| Operador | significa |
|---|---|
| & | and, e |
| | | or, ou |
| ~ | not, negação |
O método arr.unique() acima foi aplicado para ver quais os países satisfazem as condições, sem repetições. arr.shape é uma tupla (número linhas, número colunas). Os últimos exemplos fazem testes compostos usando os operadores & (and, e lógico) e | (or, ou lógico).
Se nenhum campo for submetido ao teste lógico todos os valores do dataframe são usados. O mesmo ocorre com a aplicação de uma função, como mostrado para uma função lambda.
» # novos teste com loc e iloc
» dic = {'Pedro': {'Prova 1': 5.4, 'Prova 2': 6.2, 'Prova 3': 7.9},
'Ana': {'Prova 1': 8.5, 'Prova 2': 9.7, 'Prova 3': 6.6},
'Luna': {'Prova 1': 5.0, 'Prova 2': 7.0, 'Prova 3': 4.3}
}
» dfNotas = pd.DataFrame(dic)
» dfNotas
↳ Pedro Ana Luna
Prova 1 5.4 8.5 5.0
Prova 2 6.2 9.7 7.0
Prova 3 7.9 6.6 4.3
» # o teste retorna um df com o mesmo shape que dfNotas
» dfNotas > 6
↳ Pedro Ana Luna
Prova 1 False True False
Prova 2 True True True
Prova 3 True True False
» # os campos do df são filtrados pelo df booleano
» dfNotas[dfNotas > 6]
↳ Pedro Ana Luna
Prova 1 NaN 8.5 NaN
Prova 2 6.2 9.7 7.0
Prova 3 7.9 6.6 NaN
Funções lambda
Uma função pode ser aplicada sobre elementos de uma coluna específica ou sobre todas as colunas. Veremos mais tarde detalhes sobre o uso de dataframe.apply().
» dfNotas ↳ Pedro Ana Luna Prova 1 5.4 8.5 5.0 Prova 2 6.2 9.7 7.0 Prova 3 7.9 6.6 4.3 » # uma função aplicada à todos os elementos do df » dfNotas.apply(lambda x: x**2) ↳ Pedro Ana Luna Prova 1 29.16 72.25 25.00 Prova 2 38.44 94.09 49.00 Prova 3 62.41 43.56 18.49
Funções lambda que retornam valores booleanos podem ser usadas para filtragem dos campos de um dataframe. No exemplo dfPaises['pais'].apply(lambda x: len(x)) == 4 retorna True para as linhas onde o campo pais tem comprimento de 4 letras.
» dfPaises.loc[dfPaises['pais'].apply(lambda x: len(x)) == 4].head(2)
↳ continente pais ano expVida populacao pibPercap
264 Africa Chad 1952 38.092 2682462 1178.665927
265 Africa Chad 1957 39.881 2894855 1308.495577
# são os países com nomes de 4 letras:
» set(dfPaises.loc[dfPaises['pais'].apply(lambda x: len(x)) == 4]['pais'])
↳ {'Chad', 'Cuba', 'Iran', 'Iraq', 'Mali', 'Oman', 'Peru', 'Togo'}
# o mesmo que
# dfPaises.loc[dfPaises['pais'].apply(lambda x: len(x)) == 4]['pais'].unique() # (um array)
O seletor pode ser composto de mais testes, ligados pelos operadores lógicos & e |.
» # paises/anos com nomes compostos por mais de 2 palavras e população acima de 50 milhões
» dfPaises.loc[(dfPaises['pais'].apply(lambda x: len(x.split(' '))) > 2) &
(dfPaises['populacao']>50_000_000)]
↳ continente pais ano expVida populacao pibPercap
334 Africa Congo, Dem. Rep. 2002 44.966 55379852 241.165876
335 Africa Congo, Dem. Rep. 2007 46.462 64606759 277.551859
Ordenamento com Sort
Para ordenar um dataframe podemos usar o método sort, com a seguinte sintaxe:
dataframe.sort_values(by=['campo'], axis=0, ascending=True, inplace=False) |
|---|
| onde |
by pode ser uma string ou lista com o nome ou nomes dos campos, na prioridade de ordenamento, |
axis{0 ou ‘index’, 1 ou ‘columns’} default 0, indica o eixo a ordenar, |
ascending=True/False se ordenamento é crescente/decrescente. |
Existem vários outros parâmetros para o controle de ordenamentos, como pode ser lido no API reference do pandas.
Muitas informações importantes sobre um conjunto de dados podem ser obtidas apenas pela inspecção dos dados. Por exemplo, podemos encontrar respostas para:
- que país do mundo teve, em qualquer ano, o PIB percapita mais elevado?
- no ano de 2007 (o último de nossa lista), quais são os 5 países com maior população, e quais são os 5 com PIB mais baixo, no mundo?
- no ano de 2002, quantos países no mundo tinham PIB percapita acima e abaixo da média?
# encontramos o maior pib percapita e a linha que corresponde a ele
» dfMax = dfPaises[dfPaises['pibPercap']==dfPaises['pibPercap'].max()]
» dfMax
↳ continente pais ano expVida populacao pibPercap
853 Asia Kuwait 1957 58.033 212846 113523.1329
» # para formatar uma resposta amigável
» ano = dfMax['ano'].values[0]
» pais = dfMaxPib['pais'].values[0]
» pibP = dfMaxPib['pibPercap'].values[0]
» print('O PIB percapita máximo foi de {} e ocorreu no {} em {}.'.format(pibP, pais, ano))
↳ O PIB percapita máximo foi de 113523.1329 e ocorreu no Kuwait em 1957.
» # ordenando em ordem decrescente
» dfPaises.sort_values(by=['pibPercap'], ascending=False).iloc[[0]]
↳ continente pais ano expVida populacao pibPercap
853 Asia Kuwait 1957 58.033 212846 113523.1329
Observe que dfMax['ano'] é uma Series que, se exposta diretamente, não contém apenas o ano. Por isso extraimos dele o valor, 1º campo: dfMax['ano'].value[0]. Idem para pais e pibPercap.
Claro que podemos também ordenar o dataframe em ordem descrecente no campo pibPercap e pegar apenas a 1ª linha.
dataframe.iloc[[0]] foi usado para pegar a 1ª linha, cujo índice é 853. A mesma linha seria retornada com dataframe.loc[[853]], o que mostra, mais uma vez, a diferença entre df.loc e df.iloc.
Para encontrar os 5 países com maior população em 2007 usamos a mesma técnica de ordenamento. Primeiro filtramos pelo ano = 2007, ordenamos por população, ordem inversa, e pegamos os 5 primeiros. Para exibir o resultado podemos transformar o dataframe em string, sem os índices.
Para encontrar os 5 países com maior população em 2007, e os 5 com menor PIB:
» # dataframe com 5 maiores populações em 2007
» popMax = dfPaises[dfPaises['ano']==2007].sort_values(by=['populacao'], ascending=False).head()
» print(popMax[['pais','populacao']].to_string(index=False))
↳ pais populacao
China 1318683096
India 1110396331
United States 301139947
Indonesia 223547000
Brazil 190010647
» # o 5 países com menor pib:
» # criamos um dataframe apenas do ano 2007 e acrescentamos o campo pib
» # pib = pibPercap * populacao
» df2007 = dfPaises[dfPaises['ano']==2007]
» df2007['pib'] = df2007['pibPercap'] * df2007['populacao']
» # são os países com menor pib em 2007
» df2007.sort_values(by=['pib']).head()['pais']
↳ 1307 Sao Tome and Principe
323 Comoros
635 Guinea-Bissau
431 Djibouti
563 Gambia
Name: pais, dtype: object
# se não precisamos mais do df, podemos apagá-lo
» del df2007
Para saber quantos países tem PIB percapita acima e abaixo da média em 2002 primeiro encontramos essa média. Depois selecionamos as linhas que satisfazem com pibPercap >= media e pibPercap < media. Para saber quantas linhas restaram contamos, por exemplo, quantos elementos existem em seu index.
» # média do pibPercap em 2002 (um escalar)
» media2002 = dfPaises[dfPaises.ano==2002]['pibPercap'].mean()
» acima = dfPaises[(dfPaises.ano==2002) & (dfPaises.pibPercap ≥= media2002)].index.size
» abaixo = dfPaises[(dfPaises.ano==2002) & (dfPaises.pibPercap < media2002)].index.size
» print('[Dos {} países, {} tem PIB percapita acima da média, {} abaixo da média.'.format(acima+abaixo, acima, abaixo))
↳ Dos 142 países, 44 tem PIB percapita acima da média, 98 abaixo da média.
Obtenção e análise de um slice : Brasil
Em diversas circunstâncias queremos fazer análise de apenas um slice da dataframe geral. Além de simplificar o conjunto de campos podemos conseguir com isso um uso menor de espaço em memória e maior velocidade de processamento.
Podemos, por ex., obter um dataframe separado apenas com a os dados referentes ao Brasil. Passando como índice o array booleano dfPaises['pais'] == 'Brazil' apenas as linhas relativas a esse país serão retornadas.
» dfBrasil = dfPaises[dfPaises['pais'] == 'Brazil'][['ano', 'expVida', 'populacao', 'pibPercap']]
» dfBrasil.head()
↳
ano expVida populacao pibPercap
168 1952 50.917 56602560 2108.944355
169 1957 53.285 65551171 2487.365989
170 1962 55.665 76039390 3336.585802
171 1967 57.632 88049823 3429.864357
172 1972 59.504 100840058 4985.711467
O dataframe dfBrasil tem os mesmos índices que aos do segmento de dfPaises, de onde ele foi retirado. Para restabelecer esses índices usamos dataFrame.reset_index(). Se utilizado com o parâmetro drop=True o índice antigo é excluído (e perdido), caso contrário é copiado como uma coluna do dataframe. Para atribuir um nome para o índice usamos dataframe.index.rename('novoNome', inplace=True).
» # os índices iniciais são
» dfBrasil.index
↳ Int64Index([168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179], dtype='int64')
» # resetamos os índices, abandonando a coluna de índices iniciais
» dfBrasil.reset_index(drop=True, inplace=True)
» # novos índices
» dfBrasil.index
↳ RangeIndex(start=0, stop=12, step=1)
» dfBrasil.index.rename('id', inplace=True)
» # o dataframe fica assim:
» dfBrasil.head(3)
↳ ano expVida populacao pibPercap
id
0 1952 50.917 56602560 2108.944355
1 1957 53.285 65551171 2487.365989
2 1962 55.665 76039390 3336.585802
Podemos usar um campo qualquer como index, com qualquer dtype. No caso abaixo usamos o campo ano como índice.
» # vamos usar o campo ano como index
» dfBrasil.set_index('ano', inplace=True)
» dfBrasil.head(3)
↳ expVida populacao pibPercap
ano
1952.0 50.917 56602560.0 2108.944355
1957.0 53.285 65551171.0 2487.365989
1962.0 55.665 76039390.0 3336.585802
» # agora os índices passam a ser o ano
» dfBrasil.loc[1997] # é uma Series
↳ expVida 6.938800e+01
populacao 1.685467e+08
pibPercap 7.957981e+03
Name: 1997.0, dtype: float64
» # dfBrasil.loc[[1997]] # é um dataframe
Para restaurar a coluna ano copiamos o índice para essa coluna e restauramos o índice.
» # restauramos a coluna ano » dfBrasil['ano'] = dfBrasil.index » # e resetamos o indice » dfBrasil.reset_index(drop=True, inplace=True) » dfBrasil.head(3) ↳ expVida populacao pibPercap ano 0 50.917 56602560 2108.944355 1952 1 53.285 65551171 2487.365989 1957 2 55.665 76039390 3336.585802 1962
Linhas podem ser inseridas de várias formas. Um delas consiste em criar novos dataframes com as linhas a inserir e concatenar como a dataframe inicial. Para isso usamos pandas.concat(): pd.concat([dfInicio, dfFinal]).
Vamos inserir linhas com dados fictícios, apenas para efeito de aprendizado.
» colunas = ['expVida','populacao','pibPercap','ano'] # nomes das colunas, na ordem dos dados » valores1 = [48.0,45000000,2000.0,1951] # valores a inserir no ínicio (ano 1951) » valores2 = [75.0, 200000000, 9500.0, 2008] # valores a inserir no final (ano 2008) » dfP = pd.DataFrame([valores1], columns=colunas) # df a inserir no ínicio » dfU = pd.DataFrame([valores2], columns=colunas) # df a inserir no final » dfBrasil = pd.concat([dfP, dfBrasil]) # 1ª linha + dfBrasil » dfBrasil = pd.concat([dfBrasil, dfU]) # dfBrasil + última linha » # agora a 1ª linha é » dfBrasil.iloc[[0]] ↳ expVida populacao pibPercap ano 0 48.0 45000000 2000.0 1951 » # a última linha é » dfBrasil.iloc[[-1]] ↳ expVida populacao pibPercap ano 0 75.0 200000000 9500.0 2008 » # como os índices ficaram duplicados e desordenados fazemos um reordenamento » dfBrasil.reset_index(drop=True, inplace=True) » dfBrasil ↳ expVida populacao pibPercap ano 0 48.000 45000000 2000.000000 1951 1 50.917 56602560 2108.944355 1952 2 53.285 65551171 2487.365989 1957 ------------ linhas 3 até 11 omitidas ---------------- 12 72.390 190010647 9065.800825 2007 13 75.000 200000000 9500.000000 2008
Como essas linhas não contém dados corretos, vamos apagá-las. Para usamos dataframe.drop(linha, axis=0, inplace = True), onde linha é o label, que pode não ser numérico) da linha ou seu índice (numérico). Várias linhas podem ser apagadas com dataframe.drop([linha0,...,linhan], axis=0, inplace = True).
» # apagar linhas 0 e 13: axis = 0 se refere às linhas
» dfBrasil.drop([0,13], axis=0, inplace = True)
» # para reordenar os índices
» dfBrasil.reset_index(drop=True, inplace=True)
» # recolocar a coluna 'ano' no início
» dfBrasil = dfBrasil[['ano', 'expVida', 'populacao', 'pibPercap']]
» dfBrasil
# o estado do dataframe agora é
↳ dfBrasil
ano expVida populacao pibPercap
0 1952 50.917 56602560 2108.944355
1 1957 53.285 65551171 2487.365989
2 1962 55.665 76039390 3336.585802
------------ linhas 3 até 8 omitidas ----------------
9 1997 69.388 168546719 7957.980824
10 2002 71.006 179914212 8131.212843
11 2007 72.390 190010647 9065.800825
Vamos inserir uma coluna, atribuindo a ela um escalar (um valor único). Aqui ocorre, como nas Series, o broadcasting, onde o escalar é transformado em uma Series de tamanho apropriado antes de ser inserido na nova coluna. Todas as linhas terão o valor 42 no campo “novoCampo”.
Em seguida alteramos o valor dessa coluna em uma linha específica, usando dataframe.loc(númeroLinha, nomeColuna) ou dataframe.iloc(numeroLinha, numeroColuna). Depois, como essa é uma coluna indesejada, nos a apagamos usando dataframe.drop('nomeColuna', axis=1, inplace=True).
» dfBrasil['novoCampo'] = 42
» dfBrasil.head(3)
↳ ano expVida populacao pibPercap novoCampo
0 1952 50.917 56602560 2108.944355 42
1 1957 53.285 65551171 2487.365989 42
2 1962 55.665 76039390 3336.585802 42
» # alteramos o 'novoCampo' na linha 1 (usando loc)
» # e a coluna 4 ('novoCampo') na linha 2 (usando iloc, fornecendo o índice)
» dfBrasil.loc[1,'novoCampo'] = 123456
» dfBrasil.iloc[2,4] = 22222
» dfBrasil.head(3)
↳ ano expVida populacao pibPercap novoCampo
0 1952 50.917 56602560 2108.944355 42
1 1957 53.285 65551171 2487.365989 123456
2 1962 55.665 76039390 3336.585802 22222
» # apagamos essa coluna com drop
» dfBrasil.drop('novoCampo', axis=1, inplace=True)
» # o dataframe fica como no início
Um campo pode ser inserido como resultado de operações entre outros campos. No caso abaixo criamos uma coluna pib que é o produto das colunas populacao × pibPercap. O resultado é aplicado, em cada linha, à nova coluna, em notação científica. Na 1ª linha pib = 1.193716 × 1011.
Outra coluna marca a passagem de quando a expectativa de vida do brasileiro ultrapassa os 60 anos.
» dfBrasil.loc[:,'pib'] = dfBrasil['pibPercap'] * dfBrasil['populacao'] » dfBrasil.head(4) ↳ ano expVida populacao pibPercap pib 0 1952 50.917 56602560.0 2108.944355 1.193716e+11 1 1957 53.285 65551171.0 2487.365989 1.630498e+11 2 1962 55.665 76039390.0 3336.585802 2.537119e+11 3 1967 57.632 88049823.0 3429.864357 3.019989e+11 » # inserindo coluna 'acima60'(†) » dfBrasil.loc[:,'acima60'] = dfBrasil['expVida'] > 60 » dfBrasil.loc[3:6,['ano','expVida','acima60']] ↳ ano expVida acima60 3 1967 57.632 False 4 1972 59.504 False 5 1977 61.489 True 6 1982 63.336 True » dfBrasil[dfBrasil['acima60']] » # todas as linhas com expVida > 60 são exibidas (output omitido) » # as colunas podem ser removidas (para ficarmos com o dataframe original) » dfBrasil.drop(['acima60', 'pib'], axis=1, inplace=True)
(†) dfBrasil['expVida'] > 60 é uma Series booleana.
Objetos de índices
Em um dataframe, assim como nas Series, a informação relativa aos índices e seus nomes (labels ), assim como os nomes dos eixos, são armazenados em objetos Index (índice). O objeto Index é imutável (não pode ser alterado após a construção).
» pdSerie = pd.Series(range(4), index=['a1', 'a2', 'a3', 'a4']) » index = pdSerie.index » index ↳ Index(['a1', 'a2', 'a3', 'a4'], dtype='object') » # o índice é uma sequência (pode ser lido em slices) » index[2] ↳ 'a3' » index[2:] ↳ Index(['a3', 'a4'], dtype='object') » # o index é imutável » index[0] = 'A' ↳ TypeError: Index does not support mutable operations » # já vimos que índices não fornecidos são preenchidos como um range » pd.Series(range(4)).index ↳ RangeIndex(start=0, stop=4, step=1)
1 UA ≈ 149,6 × 109 m.
No exemplo abaixo construimos primeiro um objeto Index usando pandas.Index(lista). Em seguida construimos uma Series usando esse index, contendo como valores as distâncias dos planeta até o Sol, em unidaddes astronômicas (UA). Com a Series inicializamos um dataframe com o mesmo index.
» # objeto index
» labels = pd.Index(np.array(['mercurio', 'venus', 'terra']))
» labels
↳ Index(['mercurio', 'venus', 'terra'], dtype='object')
» # Serie construída com esse index
» planetas = pd.Series([0.387, 0.723, 1], index=labels)
» planetas
↳ mercurio 0.387
venus 0.723
terra 1.000
dtype: float64
» # o index da Series é o mesmo objeto que labels
» planetas.index is labels
↳ True
» # essa Series pode ser usada para construir um dataframe
» dfPlanetas = pd.DataFrame(planetas)
» dfPlanetas
↳ 0
mercurio 0.387
venus 0.723
terra 1.000
» # o index do dataframe é o mesmo que o da Series
» dfPlanetas.index is labels
↳ True
» # alteramos o nome da coluna
» dfPlanetas.rename(columns={0:'distancia'}, inplace=True)
» dfPlanetas
↳ distancia
mercurio 0.387
venus 0.723
terra 1.000
Podemos inserir uma coluna, por exemplo, relativa ao diâmetro dos planetas (comparados ao diâmetro da Terra), atribuindo valores à uma nova coluna de nome ‘diametro’. O objeto atribuído deve ter o mesmo shape (ou passar por broadcasting). Alterar a ordem das colunas, o que pode ser feito com df.reindex(listaColunas), altera todo o dataframe (embora não inplace). O objeto retornado se ajusta de acordo com os índices fornecidos.
» # inserir uma nova coluna » dfPlanetas['diametro'] = pd.Series([0.382, 0.949, 1], index=labels) » dfPlanetas ↳ distancia diametro mercurio 0.387 0.382 venus 0.723 0.949 terra 1.000 1.000 » # as colunas estão em um objeto Index » dfPlanetas.columns ↳ Index(['distancia', 'diametro'], dtype='object') » type(dfPlanetas.columns) ↳ pandas.core.indexes.base.Index » 'distancia' in dfPlanetas.columns ↳ True » # podemos alterar a ordem das colunas com reindex » dfPlanetas.reindex(['venus','terra','mercurio']) ↳ distancia diametro venus 0.723 0.949 terra 1.000 1.000 mercurio 0.387 0.382 » # podemos ordenar os índices para ordenar o dataframe » idx = dfPlanetas.index » idx = idx.sort_values() » idx ↳ Index(['mercurio', 'terra', 'venus'], dtype='object') » dfPlanetas.reindex(idx) ↳ distancia diametro mercurio 0.387 0.382 terra 1.000 1.000 venus 0.723 0.949
Diferentes de um conjunto (set) objetos Index podem ter índices repetidos. Se índices inseridos não correspondem à dados existentes estes são preenchidos com NaN. Os parâmetros method='bfill' (ou “ffill” forçam as colunas (ou linhas) com NaN a serem preenchidos com valores das colunas (ou linhas) anteriores ou posteriores. Claro que reindexações podem ser também obtidas com df.loc e df.iloc.
» # índices de linhas repetidos » duplicados = pd.Index(['mercurio', 'venus', 'terra', 'mercurio', 'marte']) » duplicados ↳ Index(['mercurio', 'venus', 'terra', 'mercurio', 'marte'], dtype='object') » dfPlanetas.reindex(duplicados) # default é axis = 0 ↳ distancia diametro mercurio 0.387 0.382 venus 0.723 0.949 terra 1.000 1.000 mercurio 0.387 0.382 marte NaN NaN » # índices de colunas repetidos » duplicados = pd.Index(['distancia', 'diametro', 'diametro', 'distancia', 'massa']) » dfPlanetas.reindex(duplicados, axis=1) # sobre colunas ↳ distancia diametro diametro distancia massa mercurio 0.387 0.382 0.382 0.387 NaN venus 0.723 0.949 0.949 0.723 NaN terra 1.000 1.000 1.000 1.000 NaN » # method='bfill' lê valor da coluna anterior » dfPlanetas.reindex(duplicados, axis=1, method='bfill') ↳ distancia diametro diametro distancia massa mercurio 0.387 0.382 0.382 0.387 0.387 venus 0.723 0.949 0.949 0.723 0.723 terra 1.000 1.000 1.000 1.000 1.000 » # use method='ffill' para copiar coluna posterior » # reindexação com loc » nCol = pd.Index(['diametro', 'distancia']) » dfPlanetas.loc[['venus','terra'], ['diametro', 'distancia']] ↳ diametro distancia venus 0.949 0.723 terra 1.000 1.000 » # nCol pode ser uma lista: nCol = ['diametro', 'distancia']
De posse dos índices das linhas e colunas qualquer uma delas pode ser apagada com df.drop(lista, axis). As operações retornam o dataframe modificado, sem alterar o original, a menos que seja marcado o parâmetro inplace=True. Nesse caso os dados removidos serão perdidos.
» dfPlanetas ↳ distancia diametro mercurio 0.387 0.382 venus 0.723 0.949 terra 1.000 1.000 » # apagando linhas (axis = 0 é default) » dfPlanetas.drop(['venus', 'mercurio']) ↳ distancia diametro terra 1.0 1.0 » # apagando colunas » dfPlanetas.drop(['distancia'], axis=1) ↳ diametro mercurio 0.382 venus 0.949 terra 1.000
Os seguintes argumentos são usados com reindex
| Argumento | descrição |
|---|---|
index |
Index ou sequência a ser usada como index, |
method |
forma de interpolação: ‘ffill’ preenche com valor posterior, ‘bfill’ com valor anterior, |
fill_value |
valor a usar quando dados não existentes são introduzidos por reindexing (ao invés de NaN), |
limit |
quando preenchendo com valor anterior ou posterior, intervalo máximo a preencher (em número de elementos), |
tolerance |
quando preenchendo com valor anterior ou posterior, intervalo máximo a preencher para valores inexatos (em distância numérica), |
level |
combina Index simples no caso de MultiIndex; caso contrário seleciona subset, |
copy |
se True, copia dados mesmo que novo índice seja equivalente ao índice antigo; se False, não copia dados quando índices são equivalentes. |
Métodos e propriedades de Index
| Método | descrição |
|---|---|
append |
concatena outro objeto Index objects, gerando novo Index |
difference |
calcula a diferença de conjunto como um Index |
intersection |
calcula intersecção de conjunto |
union |
calcula união de conjunto |
isin |
retorna array booleano indicando se cada valor está na coleção passada |
delete |
apaga índice, recalculando Index |
drop |
apaga índices passados, recalculando Index |
insert |
insere índice, recalculando Index |
is_monotonic |
retorna True se indices crescem de modo monotônico |
is_unique |
returns True se não existem valores duplicados no Index |
unique |
retorna índices sem repetições |
Bibliografia
Consulte bibliografia completa em Pandas, Introdução neste site.
Nesse site:





 » # A A-1 é a identidade
» np.dot(arr,inv(arr))
↳ array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
» # A A-1 é a identidade
» np.dot(arr,inv(arr))
↳ array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])







 No caso de arrays bidimensionais os elementos do array são acessados pelos índices de suas linhas e colunas, sendo que
No caso de arrays bidimensionais os elementos do array são acessados pelos índices de suas linhas e colunas, sendo que 





































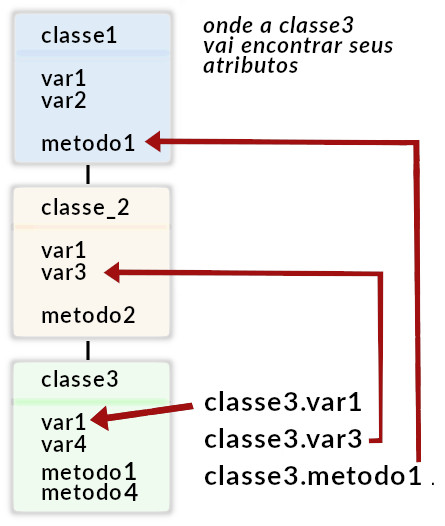
 Uma classe definida dessa forma não deixa claro quais são as propriedades que ele deve usar. Considerando que o método __init__() é acionado internamente, podemos tirar vantagem desse método fazendo seu overload e inicializando as propriedades explicitamente.
Uma classe definida dessa forma não deixa claro quais são as propriedades que ele deve usar. Considerando que o método __init__() é acionado internamente, podemos tirar vantagem desse método fazendo seu overload e inicializando as propriedades explicitamente. A segunda definição é considerada um melhor design uma vez que torna mais clara a leitura do código e seu uso durante a construção de um aplicativo. A própria definição da classe informa quais são os parâmetros usados pelos objetos dela derivados.
A segunda definição é considerada um melhor design uma vez que torna mais clara a leitura do código e seu uso durante a construção de um aplicativo. A própria definição da classe informa quais são os parâmetros usados pelos objetos dela derivados.






 Funções compostas são chamadas de objetos de segunda classe ou funções de ordem superior. Decoradores envolvem uma função, modificando seu comportamento. Quando executamos
Funções compostas são chamadas de objetos de segunda classe ou funções de ordem superior. Decoradores envolvem uma função, modificando seu comportamento. Quando executamos 

 Outro tipo de erro são os erros lógicos que, provavelmente, ocupam a maior parte do tempo de debugging dos desenvolvedores. Eles ocorrem quando o código não tem erros de sintaxe nem exceções de tempo de execução mas foram escritos de forma que o resultado da execução é incorreto. Um exemplo simples seria de uma lista que começa a ler os elementos com índice i=1, o que faz com que o primeiro elemento seja ignorado. Esses erros podem ser complexos e difíceis de serem encontrados e corrigidos pois não causam a interrupção do programa nem lançam mensagens de advertência.
Outro tipo de erro são os erros lógicos que, provavelmente, ocupam a maior parte do tempo de debugging dos desenvolvedores. Eles ocorrem quando o código não tem erros de sintaxe nem exceções de tempo de execução mas foram escritos de forma que o resultado da execução é incorreto. Um exemplo simples seria de uma lista que começa a ler os elementos com índice i=1, o que faz com que o primeiro elemento seja ignorado. Esses erros podem ser complexos e difíceis de serem encontrados e corrigidos pois não causam a interrupção do programa nem lançam mensagens de advertência.


 Suponha que desejamos elaborar um programa para controle de uma escola. Um elemento básico desse programa seria, por ex., a descrição dos alunos. Um aluno pode ser descrito por uma série de dados de tipos diversos, como uma string para armazenar seu nome, inteiros para sua idade, floats para suas notas, datas para a data de nascimento, etc. É claro que podemos configurar listas ou dicionários complexos que contenham toda essa informação. No entanto temos uma ferramenta mais sofisticada e poderosa: as classes.
Suponha que desejamos elaborar um programa para controle de uma escola. Um elemento básico desse programa seria, por ex., a descrição dos alunos. Um aluno pode ser descrito por uma série de dados de tipos diversos, como uma string para armazenar seu nome, inteiros para sua idade, floats para suas notas, datas para a data de nascimento, etc. É claro que podemos configurar listas ou dicionários complexos que contenham toda essa informação. No entanto temos uma ferramenta mais sofisticada e poderosa: as classes.



 Operadores pré-definidos em tipos criados pelo usuário, tal como o operador de soma
Operadores pré-definidos em tipos criados pelo usuário, tal como o operador de soma