

O que são Expressões Regulares?
Expressões regulares, também chamadas de regex (de regular expression), são meios de descrever padrões que podem ser encontrados dentro de um texto. Os padrões podem ser simples como a busca de um ou dois dígitos especificados, ou padrões complexos que incluem a posição do padrão no texto, o número de repetições, etc.

regex.
Os métodos da classe String estão listados em Python: Strings.
Um resumo de Regex: Regex, Consulta Rápida.
Regex são usados basicamente para a busca de um padrão, substituição de texto, validação de formatos e filtragem de informações. Praticamente todas as linguagens de programação possuem ferramentas de uso de regex, assim como grande parte dos editores de texto. As diferentes linguagens de programação e aplicativos que incorporam funcionalidade de regex possuem sintaxes ligeiramente diferentes, cada uma, mas há uma embasamento geral que serve a todas. Existem aplicativos de teste de regex em diversas plataformas e aplicativos online para o mesmo fim.
Módulo re para Regex
No Python o módulo re, parte da biblioteca padrão, carrega uma “mini-linguagem” com meios de especificar tais padrões e realizar essas buscas e substituições. Esse módulo possui os seguintes métodos que podem ser usados para encontrar padrões, partir texto e compilar padrões:
| Método | retorna |
|---|---|
re.search(padrao, texto) |
1º texto casado e sua posição, em qualquer parte do texto e em todas as linhas, |
re.match(padrao, texto) |
1º texto casado e sua posição, no início do texto e apenas na 1ª linha, |
re.findall(padrao, texto) |
retorna uma lista com todos os trechos encontrados, |
re.finditer(padrao, texto) |
retorna um iterador com os trechos não sobrepostos encontrados, |
re.fullmatch(padrao, texto) |
retorna um objeto Match se a string inteira casa com o padrão, |
re.split(padrao, texto) |
parte o texto na ocorrência do padrão e retorna as partes, |
re.sub(padrao, sub, texto) |
substitue em texto o padrao por sub, |
re.subn(padrao, texto) |
similar à sub mas retorna tupla com nova string e número de substituições |
re.compile(padrao) |
compila e retorna um padrão regex pre-compilado |
Métodos re.search e re.match
resultado = re.search(padrao, texto); resultado = re.match(padrao, texto)
Os métodos search e match são similares. Ambos procuram por um padrão dentro de um texto alvo e retornam um objeto re.Match que, por sua vez, contém a posição inicial e final do padrão encontrado. Se o padrão não for encontrado o método retorna None.
O objeto re.Match possui o método group() que retorna o trecho encontrado, sendo que apenas a primeira ocorrência é considerada. Os parâmetros são padrao, uma construção regex, e texto é o conjunto de caracteres onde se busca o padrão. Em um texto de muitas linhas search procura em todas as linhas até encontrar o padrão, diferente do método match que procura apenas na primeira linha.
![]()
Uma letra, dígito ou conjunto de caracteres é casado literalmente. Se não encontrado None é retornado.
» import re
» texto = "Este é um texto de teste para testar o funcionamento das expressões regulares"
# procuramos por "exp" no texto
» padrao = "exp"
» resultado = re.search(padrao, texto)
# o padrão "exp" é encontado na posição 57 até 60
» print(resultado)
↳ <re.Match object; span=(57, 60), match="exp">
» print(resultado.group())
↳ exp
# a busca retorna None se o padrão não é encontrado
» print(re.search("z", texto))
↳ None
# apenas o primeira coincidência é casada
» print(re.search("ste", texto))
↳ <re.Match object; span=(1, 4), match="ste">
Como search() retorna None se não houver um casamento, podemos usar o retorno do método como critério de sucesso da busca, considerando que None equivale a False quando em um teste lógico. Por exemplo, o padrão A{3} significa 3 letras A maiúsculas consecutivas, o que não existe no texto.
» texto = "American Automobile Association"
» busca = re.search("A{3}", texto)
» if busca:
» print(busca.group())
» else:
» print("não encontrado")
↳ não encontrado
Como recordação e para uso posterior, observe que podemos escrever o código acima de forma mais concisa usando a construção
<valor_se_True> if <teste_lógico> else <valor_se_False>
O código pode ser rescrito como:
» texto = "American Automobile Association"
» busca = re.search("A{3}", texto)
» print(busca.group() if busca else "não encontrado")
↳ não encontrado
busca = None porque não existem 3 “A”s consecutivos no texto.
Metacaracteres
Além de caracteres simples e grupos de caracteres os metacaracteres permitem ampliar o poder de busca das regex. No que se segue representamos os textos casados com a marcação texto. Na tabela abaixo x representa um padrão qualquer.

| padrão | significado | exemplo: | casa ou não com |
|---|---|---|---|
a |
caracter comum | a |
casa Afazer aaa |
ab |
grupos de caracteres comuns | ab |
absoluto abraço Abcd trabalho |
. |
casa com qualquer caracteres único | m.to |
mato, mito, m3to, mto |
x* |
0, 1 ou várias ocorrências de x | 13* |
1, 13456, 133, 13333-0987 |
x? |
0, 1 ocorrência de x | 13? |
1, 13456, 133, 13333-0987 |
x+ |
1 ou mais ocorrências de x | 13+ |
1, 13456, 133, 13333-0987 |
# . = qualquer caracter
» print(re.search("p.ata", "pirata pata prata").group())
↳ prata
# x* = 0, 1 ou várias repetições de x
» print(re.search("jo*e", "jose joo joe").group())
↳ joe
» print(re.search("jo*e", "jose joo jooooooe").group())
↳ jooooooe
# x? = 0 ou 1 ocorrência de x
» print(re.search("jo?e", "jose jooe je").group())
↳ je
» print(re.search("jo?e", "jose jooe joe").group())
↳ joe
# x+ = 1 ou mais ocorrências de x
» print(re.search("jo+e", "jose jooe joe").group())
↳ jooe
Nota: Sempre lembrando que search e match retornam a primeira ocorrência da corresepondência.
Chaves, colchetes, pipes e parênteses
As chaves são usadas para quantificar repetições de um padrão.
| padrão | significado | exemplo: | casa ou não com |
|---|---|---|---|
{n} |
significa exatamente n repetições do padrão | 9{3} | 999, 1999-45, 9-999, 999-00, 9, 99 |
{n,} |
mínimo de n repetições do padrão | 9{2,} | 99, 1999-45, 9-9999, 99999-00, 9, 9-9 |
{,n} |
máximo de n repetições do padrão | 9{,4} | 99, 1999-45, 9-9999, 9999-00, 9, 9-9 |
{n,m} |
mínimo de n, máximo de m repetições do padrão | 9{2,4} | 99, 1999-45, 9-9999, 99999-00, 9, 9-9 |
Um colchete [] delimita um conjunto alternativo de caracteres. Pipe, o sinal | indica uma alternativa onde um ou outro grupo é casado.
» print(re.search("pr[ae]to", "prato, preto").group())
↳ prato
» print(re.search("pr[ae]to", "proto, preto").group())
↳ preto
# [0-9] representa qualquer dígito. "[0-9]{3,}" é grupo com mais de 3 dígitos:
» print(re.search("[0-9]{3,}", "6-45-4567-345345").group())
↳ 4567
# grupo com até 2 dígitos
» print(re.search("[0-9]{,2}", "45-4567-345345").group())
↳ 45
# \d é o mesmo que [0-9] (veja "classe de caracteres" abaixo)
» print(re.search(r"\d{,2}", "45-4567-345345").group())
↳ 45
» print(re.search("q{3}", "q qq qqq").group())
↳ qqq
» print(re.search("q{,2}", "qqqqq qq qqq").group())
↳ qq
print(re.search("q{2,}", "qqqqqqqq qq qqq").group())
↳ qqqqqqqq
No código acima usamos \d para representar um dígito (o mesmo que [0-9]), e o prefixo r antes da definição do padrão para significar que estamos definindo uma “raw string”. Ambos os conceitos estão melhor explicados abaixo.
Parênteses () indicam um grupo, a ser procurado como um bloco. O sinal |indica uma alternativa onde um ou outro grupo é procurado.
# procurando por mato ou mito
» print(re.search("m(a|i)to", "moto mato mito").group())
↳ mato
# só a primeira ocorrência é retornada
» print(re.search("m(a|i)to", "moto muto mito").group())
↳ mito
» print(re.search("J(osé|oão) Paulo", "José Paulo Souza").group())
↳ José Paulo
» print(re.search("J(osé|oão) Paulo", "João Paulo Souza").group())
↳ João Paulo
» print(re.search(r"@(\d{3}|\D{2})", "@963 é a senha!").group())
↳ @123
» print(re.search(r"@(\d{3}|\D{2})", "@aB é a senha!").group())
↳ @aB
Classes de caracteres
Classes de caracteres são marcações que funcionam como “shortcuts”, representando um grupo de caracteres ou controles.

\s |
representa um espaço simples, |
\S |
representa espaço negado (não é um espaço), |
\d |
representa qualquer dígito. O mesmo que [0-9], |
\D |
\d negado. Qualquer não dígito. O mesmo que [^0-9], |
\w |
caracter alfanumérico e sublinhado, |
\W |
\w negado. Qualquer sinal exceto caracter alfanumérico e sublinhado. |
\b |
borda de palavra. Um padrão de comprimento nulo usado para marcar início e fim das palavras. |
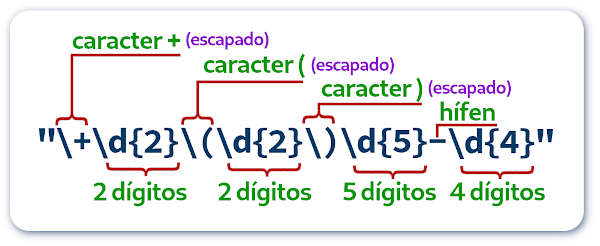
O padrão usado abaixo, padrao = r"\+\d{2}\(\d{2}\)\d{5}-\d{4}" significa um número escrito como um telefone no formato + cód país (cod área) 5 dígitos – 4 dígitos.
» texto = """
» Suponha que temos um texto com um número de telefone
» Telefone do cliente: +55(21)99876-5432
» mais texto irrelevante
» """
» padrao = r"\+\d{2}\(\d{2}\)\d{5}-\d{4}"
» fone = re.search(padrao, texto).group()
» print(fone)
↳ +55(21)99876-5432
# uso de \b para demarcar palavras
» texto = "Apata patati patacolá para achar pata"
» casa = re.search(r"\bpata\b", texto)
» print(casa.group(), "posição:" ,casa.start())
↳ pata posição: 33
# uso de \D representando não-dígito
» texto = "0123-45 6123-45 A123-45"
» casa = re.search(r"\D123-45", texto)
» print(casa.group(), "posição:" ,casa.start())
↳ A123-45 posição: 16
» texto = "123A_B"
» casa = re.search(r"\D{3}", texto)
» print(casa.group(), "posição:" ,casa.start())
↳ A_B posição: 3
# \w = alfanumérico e sublinhado
» texto = "\t\n casa 123_5 123-45"
» casa = re.search(r"\w{5}", texto)
» print(casa.group(), "posição:" ,casa.start())
↳ 123_5 posição: 8
# \W nem alfanumérico nem sublinhado
» casa = re.search(r"\W+", "*-!@#123A_B")
» print(casa.group(), "posição:" ,casa.start())
↳ *-!@# posição: 0
Um regex simples para selecionar um email pode ser:
» texto = "Email: 123casa@dasogra.com.br pode ser extraído!" » padrao = r"\w+@\w+(\.\w+)+" » print(re.search(padrao,texto).group()) ↳ 123casa@dasogra.com.br
O padrão “casa” com um email no formato <palavra>@<palavra><uma ou mais .palavras>. Aqui palavra é qualquer sequência contínua de caracteres ou dígitos, @ é literal (pois não é um metacarater do regex). O grupo (\.\w+)+ casa com .com e com .com.br.
Raw Strings
No Python uma “raw string” é uma sequência de caracteres que ignoram caracteres especiais no texto demarcado com \. "\ttexto" é “texto” após um espaçamento de tabulação mas r"\ttexto" é uma string simples. Sempre que o padrão envolve metacaracteres com a barra invertida \, é necessário usar “raw strings”.
» texto = "(casa): 72715-620, (escritório): 74854-890" » busca = re.search(r"\(casa\)", texto) » busca.group() ↳ (casa) # \n significa um caracter de "new line" » print(r"Olá\nPessoal") ↳ Olá ↳ Pessoal # em uma raw string r"\n" é tratada como literal (não um escape) » print(r"Olá\nPessoal") ↳ Olá\nPessoal # para incluir um metacaracter na busca usamos escape texto = "(casa): 72715-620, (escritório): 74854-890" re.search(r"\(casa\)", texto).group() # retorna (casa) re.search(r"(casa)", texto).group() # retorna casa # o prefixo "r" altera o signicado da string, quando existem metacarateres r"o que é regex" == "o que é regex" # True r"10\25\1991" == "10\25\1991" # False
No primeiro exemplo re.search(r"\(casa\)", texto) "\(" e "\)" representam, respectivamente os caracteres "(" e ")". O escape é necessário porque esses são metacaracteres do regex.
No Python existem outros prefixos para definir diferentes tipos de strings. Eles podem inclusive ser usados em conjunto. Entre eles estão:
- b: strings de bytes
- f: string formatada
- u: string Unicode (Legados, PEP 414)
Métodos de re.Match
O objeto re.Match possui diversos métodos:

| Método | retorna |
|---|---|
match.group() |
a parte do texto casada com o padrão, |
match.start() |
índice do início da parte do texto casada com o padrão, |
match.end() |
índice do fim da parte do texto casada com o padrão, |
match.span() |
os índices do início e do fim da parte do texto casada com o padrão, |
| Propriedade | retorna |
match.re |
a expressão regular casada (o padrão), |
match.string |
o texto passado como parâmetro. |
» texto = "Telefone: 05 (61) 3940-35356 (casa da Dinda), CEP: 123456789"
# 4 digitos, hifen, 5 dígitos
» padrao = r"\d{4}-\d{5}"
# a variável resultado contém um objeto Match
» resultado = re.search(padrao, texto)
» if resultado:
» print(resultado.group())
» print(resultado.start())
» print(resultado.end())
» print(resultado.span())
» else:
» print("Padrão não encontrado!")
↳ 3940-35356
↳ 18
↳ 28
↳ (18, 28)
» texto = "CEP do cliente: 72715-620, DF"
» busca = re.search(r"\d+", texto)
» print(busca.start(), busca.end())
↳ 16 21
# o primeiro trecho casado é retornado
» print(texto[busca.start(): busca.end()], "=", busca.group())
↳ 72715 = 72715
» busca = re.search(r"-\d+", texto)
» print(busca.group())
↳ -620
match.group(), que é o mesmo que match.group(0), se refere a todos os grupos encontrados. Se o padrão contém apenas um grupo só uma combinação é encontrada. Podemos construir padrões com mais de um grupo usando os marcadores de grupos, os parênteses ().
» texto = "Telefone: 05 (61) 3940-35356 (casa da Dinda), CEP: 123456789"
# 4 digitos (1º grupo), hifen, 5 dígitos (2º grupo)
» padrao = r"(\d{4})-(\d{5})"
» resultado = re.search(padrao, texto)
# o 1º grupo combina com
» print(resultado.group(1))
↳ 3940
# o 2º grupo combina com
» print(resultado.group(2))
↳ 35356
# ambos os grupos
» print(resultado.group())
↳ 3940-35356
Diferença entre re.search e re.match
No módulo re do Python, as funções search e match têm comportamentos diferentes:
resultado = re.match(padrao, texto): A função match só retorna uma correspondência se o padrão for encontrado no início da string.
resultado = re.search(padrao, texto): A função search retorna correspondência se o padrão for encontrado em qualquer parte da string.
Ambas as funções retornam um objeto re.Match se encontrarem uma correspondência, ou None caso contrário.
» padrao = r"\d{2}-\d{3}" # 2 dígitos + <hífen> + 3 dígitos
» print("1-", "Achou" if re.match(padrao, "12-345 Casa da Sogra") else "Não achou")
» print("2-", "Achou" if re.match(padrao, "Número: 12-345 Casa da Sogra") else "Não achou")
» print("3-", "Achou" if re.search(padrao, "12-345 Casa da Sogra") else "Não achou")
» print("4-", "Achou" if re.search(padrao, "Número: 12-345 Casa da Sogra") else "Não achou")
↳ 1- Achou
↳ 2- Não achou
↳ 3- Achou
↳ 4- Achou

Método re.findall
re.findall(padrao, texto)
O método findall encontra todas as ocorrências de padrao em texto e retorna uma lista com os trechos encontrados.
» import re
» texto = "Hoje 1 estamos 23 procurando 456 por 7890 números"
» padrao = r"\d" # \d = um dígito qualquer
» resultado = re.findall(padrao, texto)
» print(resultado)
↳ ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0"]
# \d+ = qualquer um ou mais dígitos
» print(re.findall(r"\d+", texto))
↳ ["1", "23", "456", "7890"]
# \d{2} = grupos de 2 dígitos
» print(re.findall(r"\d{2}", texto))
↳ ["23", "45", "78", "90"]
# \d{3} = grupos de 3 dígitos
» print(re.findall(r"\d{3}", texto))
↳ ["456", "789"]
# \d{3,} = grupos de 3 ou mais dígitos
» print(re.findall(r"\d{3,}", texto))
↳ ["456", "7890"]
# \D+ = grupos de 1 ou mais não-dígitos
» print(re.findall(r"\D+", texto))
↳ ["Hoje ", " estamos ", " procurando ", " por ", " números"]
# caracteres na faixa de a até d (a, b, c, d)
» print(re.findall("[a-d]", texto))
↳ ["a", "c", "a", "d"]
# dígitos na faixa de 1 a 4 (1,2 ,3, 4)
» print(re.findall("[1-4]", texto))
↳ ["1", "2", "3", "4"]
# texto "oje" ou "ando"
» print(re.findall("oje|ando", texto))
↳ ["oje", "ando"]
# texto "oje" ou "ando" seguindos de qualquer sequência de caracteres
» print(re.findall("oje.*|ando.*", texto))
↳ ["oje 1 estamos 23 procurando 456 por 7890 números"]
# Obs. em qualquer busca o trecho casado é excluído de buscas posteriores.
# o padrão "ando.*" é ignorando
# se os trechos casados não estão superpostos, todos são retornados
» print(re.findall("pr[aeo]to", "prato, preto pretoria proton"))
↳ ['prato', 'preto', 'preto', 'proto']
# para encontrar no texto um padrão que contém metacaracteres devemos usar "raw strings"
» texto = "Podemos usar \n para quebra de linha e \t para tabulações."
» print(re.findall(r"[\n\t]", texto))
↳ ["\n", "\t"]
findall é muito útil para se extrair uma lista de dados no mesmo padrão que se encontram repetidas vezes em um texto:
» import re
» texto = """
» Lista de alunos com número de telefone
» 1. Nome: Marco Paulo
» Tel.: +55(21)99876-5432
» 2. Nome: Ana Raio
» Tel.: +55(11)99567-0987
» """
» padrao = r"\+\d{2}\(\d{2}\)\d{5}-\d{4}"
» lista = re.findall(padrao, texto)
» for tel in lista:
» print(tel)
↳ +55(21)99876-5432
↳ +55(11)99567-0987
# um elemento individual dessa lista é obtido da forma usual
» print(lista[0])
↳ +55(21)99876-5432
Método re.split
resultado = re.split(padrao, texto, [maxsplit])
O método split parte o texto em todas as ocorrências de padrao e retorna uma lista com os trechos encontrados. Se o padrão não for encontrado uma lista com o texto inteiro é retornada. O parâmetro maxsplit é opcional e especifica o número máximo de cortes que devem ser feitos no texto. O default é maxsplit = 0, signicando que todos os cortes possíveis serão feitos.
» import re
» texto = "Hoje 1 estamos 23 procurando 456 por 7890 números"
» padrao = r"\d+"
» resultado = re.split(padrao, texto)
# texto picado em toda ocorrência de 1 ou mais dígitos
» print(resultado)
↳ ["Hoje ", " estamos ", " procurando ", " por ", " números"]
# texto picado em toda ocorrência de espaços (\s)
» print(re.split(r"\s", texto))
↳ ["Hoje", "1", "estamos", "23", "procurando", "456", "por", "7890", "números"]
# padrão não encontrado
» print(re.split("w", texto))
↳ ["Hoje 1 estamos 23 procurando 456 por 7890 números"]
Podemos usar o comprimento da lista retornada por split para saber se houve correspondência com o padrão. Além disso o parâmetro maxsplit limita quantas partes obteremos no retorno.
» texto = "Este_é_um_texto_sem_espaços!" » partido = re.split(r"\s", texto) » print(partido[0] if len(partido) > 1 else "Padrão não encontrado!") ↳ Padrão não encontrado! # especificando maxsplit = 2 (fazer apenas 2 cortes no texto) » print(re.split(r"\d+", texto, 2)) ↳ ["Hoje ", " estamos ", " procurando 456 por 7890 números"]
Método re.sub
resultado = re.sub(padrao, subst, texto, [quantos])
O método re.sub procura um padrão e o substitui por um texto. A variável resultado é uma string com padrao substituído por subst. Se o padrão não é encontrado o texto original é retornado. O parâmetro opcional quantos indica quantas substituições devem ser feitas. O default é quantos = 0, o que significa que todas as ocorrências do padrão devem set substituídas.
# remover todos os espaços em branco
» import re
# texto com várias linhas e espaços em branco
» texto = "Nome: Pedro \nSobrenome: Alvarez\nCabral"
# padrão para casar com espaços (troca espaços por "")
» padrao = r"\s"
» sub = ""
» resultado = re.sub(padrao, sub, texto)
» print(resultado)
↳ Nome:PedroSobrenome:AlvarezCabral
# padrão para substituir 1 ou mais espaços por espaço único
» texto = "É comum ter textos com dois ou mais espaços inseridos onde se deseja apenas um!"
» print(texto)
↳ É comum ter textos com dois ou mais espaços inseridos onde se deseja apenas um!
» print(re.sub(r"\s+", " ", texto) )
↳ É comum ter textos com dois ou mais espaços inseridos onde se deseja apenas um!
# usando o parâmetro quantos
» texto = "Esse texto possui 4 ocorrências de 3 dígitos repetidos: 012, 123, 234 e 345."
# Substituindo apenas as 2 primeiras ocorrências de 3 dígitos por ###
» print(re.sub(r"\d{3}", "###", texto, 2))
↳ Esse texto possui 4 ocorrências de 3 dígitos repetidos: ###, ###, 234 e 345.
Método re.subn
resultado = re.subn(padrao, subst, texto, [quantos])
O método re.subn é similar à re.sub mas retorna uma tupla de 2 itens, contendo a string modificada e o número de substituições feitas.
» texto = "Temos as seguintes permutações de {a, b, c}: abc, acb, bac, bca, cab, cba."
» resulta = re.subn("[abc]{3}", "|||", texto)
» print(resulta)
» print("Foram feitas {} substituições".format(resulta[1]))
↳ ("Temos as seguintes permutações de {a, b, c}: |||, |||, |||, |||, |||, |||.", 6)
↳ Foram feitas 6 substituições
O método re.search recebe dois argumentos: um padrão e o texto a ser modificado. O método procura apenas pela primeira ocorrência do padrão. Se existe um casamento o método retorna um objeto match que contém a posição da coincidência (início e final) e a parte do texto que combina com o padrão. Se não houver nenhum casamento o método retorna None.
Método re.compile
padraoCompilado = re.compile(padrao, flags = 0)
O método re.compile() é especialmente útil quando o mesmo padrão será usado muitas vezes. Ele prepara um padrão através de uma pré-compilação e as armazena em cache que torna mais rápidas as buscas.
O método retorna um objeto re.Pattern que representa o padrao compilado sobre efeito dos parâmetros opcionais flags. Um exemplo é flag = re.I que determina que a busca será “insensível ao caso”. O objeto possui métodos que permitem as buscas pelo padrão dentro de um texto, tal como padrao.findall(texto), que retorna uma lista, ou padrao.finditer(texto) que retorna um iterável com os casamentos encontrados.
Por exemplo, o padrão patt = “(xa|ma){2}” significa um dos dois grupos, “xa” ou “ma”, repetidos 2 vezes.
# 2 ocorrências de "xa" ou "ma"
» patt = "(xa|ma){2}"
» padrao = re.compile(patt)
» texto = "xa, xaxado, ma, mamata, errata"
» busca = padrao.findall(texto)
» print(busca)
↳ ["xa", "ma"]
# ocorrência de 5 dígitos juntos
» padrao = re.compile(r"\d{5}")
» texto = "12345 543213 858 9658 96521"
» busca = padrao.finditer(texto)
» for t in busca:
» print(t.group())
↳ 12345
↳ 54321
↳ 96521
Nota: Nas versões mais modernas da Python e do módulo re não há uma diferença muito grande no uso de uma expressão compilada ou não. De qualquer forma, quando se faz uma busca como re.find(padrao, texto) o padrão é internamente compilado. Muitos programadores gostam de fazer as compilações de padrões por clareza de código, e para separa a definição do padrão de seu uso. Por exemplo:
regex = "padrao"
# em outra parte do código (ou usado múltiplas vezes):
m = re.match(regex, texto)
# talvez seja mais claro o seguinte uso:
regex = re.compile("padrao")
# em outra parte (ou usado múltiplas vezes):
m = regex.match(texto)
O objeto retornado, representado pela variável padraoCompilado acima, tem vários atributos, que podem ser vistos com a função dir(). Entre eles temos:
Flags ou sinalizadores
Os métodos do módulo re admitem um parâmetro extra chamado de flag (sinalizador ou marcador). Eles modificam o significado do padrão que se pretende buscar.
Os sinalizadores podem ser qualquer um dos seguintes:
| Abreviado | longo | integrado (inline) | significado |
|---|---|---|---|
re.I |
re.IGNORECASE |
(?i) |
ignorar maiúsculas e minúsculas. |
re.M |
re.MULTILINE |
(?n) |
força os localizadores ^ $ a considerarem uma linha inteira. |
re.S |
re.DOTALL |
(?s) |
força . a casar com a newline, \n. |
re.U |
re.UNICODE |
(?u) |
força \w, \W, \b, \B} a seguirem regras Unicode. |
re.L |
re.LOCALE |
(?L) |
força \w, \W, \b, \B} a seguirem regras locais. |
re.X |
re.VERBOSE |
(?x) |
permite comentários no regex. |
» txt = "estado, Estudo, estrume, ESTATUTO"
» r1 = re.findall("est[a-z]+", txt)
» r2 = re.findall("est[a-z]+", txt, flags=re.IGNORECASE)
» print(r1)
↳ ["estado", "estrume"]
» print(r2)
↳ ["estado", "Estudo", "estrume", "ESTATUTO"]
# o mesmo resultado pode ser obtido com a notação inline
» re.findall("(?i)est[a-z]+", txt)
↳ ["estado", "Estudo", "estrume", "ESTATUTO"]
» re.findall("[a-z]+[dt]o", txt, flags=re.I)
↳ ["estado", "Estudo", "ESTATUTO"]
Para usar mais de uma flag é possível separá-las com uma barra vertical (ou pipe). Por exemplo para uma busca multiline, insensível ao caso e com comentário:
re.findall(padrao, texto, flags=re.I|re.M|re.X)
» texto = """
» Gato é um bicho engraçado.
» gato não é como cachoroo.
» Gato mia!
» """
# a 1&orf; linha não começa com "gato"
» re.findall("^gato", texto, flags=re.IGNORECASE)
↳ []
# procurando em todoas as linhas
» re.findall("^gato", texto, flags=re.M)
↳ ["gato"]
# procurando em todoas as linhas, insensível ao caso
» re.findall("^gato", texto, flags=re.I | re.M)
↳ ["Gato", "gato", "Gato"]
# o mesmo resultado pode ser conseguido com flags inline
» re.findall("(?i)(?m)^gato", text)
↳ ["Gato", "gato", "Gato"]
Exemplos
Um exemplo simples de remoção de tags aplicado a um texto HTML pode ser o seguinte: O padrão padrao = "<.*?>|[\n]" apenas casa com qualquer conteúdo dentro de <>, não guloso ou um sinal de quebra de linha, [\n]. Usando o método re.sub removemos todos os trechos que casam com esse padrão.
» html = """ » <html> » <body> » <p>Parágrafo um.</p> » <p>Parágrafo dois.</p> » </body> » </html> » """ » padrao = r"<.*?>|[\n]" » textoSemTags = re.sub(padrao, "", html) » print(textoSemTags) ↳ Parágrafo um.Parágrafo dois.
Existem bibliotecas sofisticadas para web scrapping, como Beautiful Soup que permite a busca, modificação e completa navegação de um documento extraído de uma página HTML. Buscas podem ser feitos por elementos de css, ids e classes e tags.
Padrões muito complexos são difíceis de serem lidos e alterados. Para quem programa em Python as buscas regex são geralmente ferramentas auxiliares que podem ser complementadas com manuseios do texto feitos em código.
Suponha que temos um texto no formato *.csv (valores separados por vírgulas) com 5 colunas. Na quarta coluna existe uma data com formato nem sempre consistente, como 26/06/2021 onde o ano pode ter apenas 2 dígitos e o separador pode ser um barra ou hífen. Queremos extrair o valor da quinta coluna quando o ano for posterior a 2015.
» csv = """
» col1, col2, col3, data, valor
» a1 , a2 , a3 , 01/06/01, 1000
» b1 , b2 , b3 , 06/05/2016, 1000
» c1 , c2 , c3 , 4/3/17, 2000
» d1 , d2 , d3 , 14-12-2018, 600
» e1 , e2 , e3 , 19-09-19, 600
» """
» for t in csv.split(r"\n"):
» data = t.split(",")
» if len(data) != 5: continue
» dt = data[3].strip()
» if not re.match(r"\d{1,2}[/|-]\d{1,2}[/|-]\d{2,4}", dt): continue
» ano = int(re.split("[/|-]",dt)[2])
» ano = ano + 2000 if ano < 100 else ano
» if ano > 2015:
» print(ano, data[4])
↳ 2016 1000
↳ 2017 2000
↳ 2018 600
↳ 2019 600
O texto é partido em linhas, cada linha em campos separados por vírgula. Como existem linhas vazias só são aproveitadas aquelas com 5 campos. Formatos de data não admissíveis são excluídos e uma correção para anos com apenas dois dígitos inserida.

Bibliografia
- Python Docs: Regular Expression HOWTO, acessado em fevereiro de 2025.
- Phylos.net: Expressões Regulares (regex).
- Hunt, John: Advanced Guide to Python 3 Programming, Springer, Switzerland, 2019.
- Teste de Regex online: Untitled Pattern, acessado em junho de 2021.
- Programiz: Python, programming regex, acessado em junho de 2021.
- PYnative: Compile Regex Pattern using re.compile, acessado em junho de 2021.
- Regular-Expressions.info:Consulte a bibliografia no final do primeiro artigo dessa série.