About this
These are collected answers I wrote for sites on Questions and Answers, like Quora. I tried to remove duplicates but some may be left still.
Science
Relativity Theory
Question: How does the Theory of General Relativity work?
Answer: To talk about time we need a way to measure time, the same as a way to measure distances (space). Relativity says all clocks (and rules) will change in moving systems or close to a massive body. It is natural that we expect time and space to be independent on movement because we live in a world of slow speeds (compared to the speed of light). Relativity says that the distance between two points in space (the size of a rule, for instance) is not constant as it is in Newtonian mechanics. To build another constant thing, one that is invariant with motion, you need to include time in your measurement (this is the special theory). Points (x, y, z) are replaced by “events” (x, y, z, t) (where and when) and the interval between two events is now a constant of motion.
To describe gravity Einstein made a generalization of this concept. The “metric” of spacetime (the way to measure distances between two events) changes in the presence of matter (or energy, all the same). The theory says time slows down close to a planet or star (and space shrinks). In this framework time is just another aspect of space. Those statements seem strange but all the predictions of relativity (special and general) have been confirmed by experiments with great precision. So it is a mathematical perfect framework that describes nature in a correct way. This is called a “theory”.
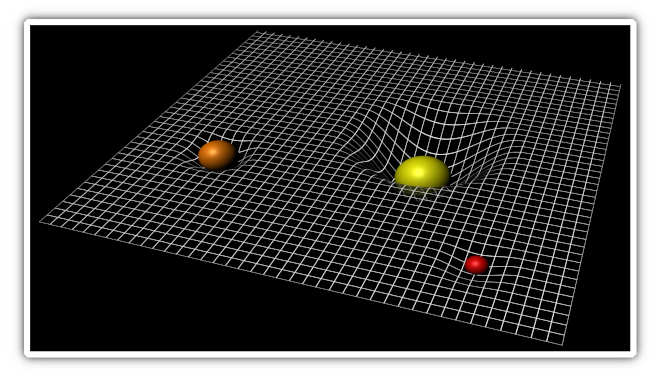
The general theory, together with observations some general assumptions (as homogeneity and isotropy of space, also observed to some degree) leads to a model which includes the Big Bang and a finite age for the universe. The 13 plus something billion years is the time as measured by a “comoving” observer, floating away with the galaxies.
No one expects the theory to hold in any situation. We know already it is not good for very small things that need quantum mechanics. And the theory itself predicts situations in which it fails ( in singularities as black holes or the beginning of the universe).
By the way, there is a good theory that puts quantum mechanics and special theory together, a relativistic quantum theory. It predicts, for instance, the existence of antimatter. There is no good theory yet mixing quantum mechanics and general relativity and this is, I think, the main open problem in theoretical physics.
Question: If somehow I was able to throw a rock at the speed of light towards the sun, would it reach the sun?
Answer: You can’t because no massive body can travel at the speed of light. But, supposing just for fun, you could, the rock would hit the Sun literally “in no time” for there would not be enough time for the heat to warm the rock.
As mentioned in another comment, it is hard to predict what would happen then, because a rock traveling that fast would carry huge amount of energy. Also it would traverse the sun fast … I don’t know what would happen to the sun. (Good example of how accepting unreasonable arguments may lead to weird answers!)
Question: I have heard some people claim Einstein was a fraud. Is there any truth to that claim?
Answer: I think Einstein was brought to public attention for some other reason than purely his science. He was kind a celebrity, friend of Charles Chaplin and many other famous guys. Relativity is pretty much something hard to grasp in terms of everyday experience (so is quantum mechanics). He and his theory became a target for all kinds of nutcrackers. Whoever proves Relativity wrong will be instantly famous.
Question: Is it possible to have a unified theory of everything?
Answer: This is exactly what most theoretical physicists are trying to do. This project has been carried for the last 100 years or so. Needless to say, no success! The main problem is the severe difficulty of putting gravity in the same picture as the other 3 force fields.
We have a pretty sound description of gravity as curvature of space-time (Einstein theory), and for the electromagnetic, weak and strong nuclear in the quantum field theory, mostly done by exchange of virtual particles between interacting objects.
But there is not yet a means of putting the two together.
String theory is one of such attempts. There are many other approaches, one of them considering that gravity is not a real force (not like the others) and formulating quantum field theory in curved space-time – but this is also hard to do.
I would guess there such a theory exists and will be found. I also think math is in the very kernel of everything that exists. But this is a believe, although all we have seen so far supports this idea.
Question: Is there any alternative to the multiverse theory to explain the fine tuning of the cosmological constant?

Answer: An infinite universe with different set of constants in different parts may do the job. Also there may be unknown reasons for some or all of the constants. For example, the square in 1/r^2 for electromagnetic and gravitational forces decay may just be due to geometric reasons (since the area of a sphere around charges grow with r^2.)
We should be clear about things we don’t know and not fear them at all. It will be a sad time when people can not think of open questions.
Even the multiverse hypothesis is very speculative and should not be considered an answer.
For this reason I believe we should call it a hypothesis and never a theory.
Question: Is the gravity theory by Newton true?
Answer: There is no such a thing as “true” in science.
Newton’s theory of gravity, the same as Newtonian mechanics, works really well to describe non relativistic phenomena (weak gravitational fields, low speeds compared to the speed of light).
Otherwise we need to extend the theory (Einstein did it for us, with a little help from his friends, Michelson and Morley, Minkowsky, Riemann, …).
Special and General relativity have worked very well so far to describe all known phenomena. No one knows it will hold true for extreme environment, like very strong gravitational fields and very high energy particles. Probably not!
Question: What is the speed of gravity?
Answer: Photons, and thus light, are excitation of the electromagnetic field. Gravitational waves (and gravitons in case the gravitational field is ever quantized) are excitation of the gravitational field. According to the Relativity theory these waves travel with the speed of light. I am not aware of the status of the experimental (observational) detection of these waves and its speed.
Question: Does light have a gravitational field?
Answer: Light is made of photons which have zero rest mass (or energy, the same). In movement, which it is always, it has mass which, in turn, is the source of gravitational field. The same is true about any other field. If it has energy it has mass.
Question: Why is E=MC^2 so popular?
Answer: First, because it is a simple and compact equation. Easy to remember. Actually it is part of a much more complex equation.
Second, it conveys a deep meaning. Matter and energy are not separate entities but aspects of a higher entity (which we call matter-energy, for lack of a better term). That part is harder to fully understand.
Third, it is very useful and helps us understand many phenomena that occurs daily in ordinary life. They go from nuclear reactions inside stars or nuclear energy plants to chemical effects.
Question: What is the difference between a year and a light year?
Answer: In the language of relativity, special or general, the distance travelled by light in one year and the time taken is one and the same thing.
Question: How do physicists say that Einstein’s theory of relativity breaks down in the interior of a black hole when it is not possible to make observations of the interior of a black hole?
Answer: The equations break down. Some physical properties go to infinite at the singularity. Density, for example. I don’t think there many, if any, physicists who believe the equations are correct at this level. It would probably be necessary a quantum version of relativity at this level.
Question: It is true that science knows nothing about gravity? We still have to realize how it exists and what causes it.
Answer: No, it is not true that “that science does not know nothing of gravity”. Actually we have a pretty good description of gravity both in classical terms and relativity. (The classical case is the limit of the later, when fields are not too strong).
General Relativity is a very clear and precise theory. It describes gravity as a change in geometry of space-time, caused by matter-energy. Unfortunately it is not consistent with the quantum theory of fields that describe the other known 3 fields (weak and strong nuclear and electromagnetic).
We sure have a problem there. There is not yet a quantum theory of gravitation. But that doesn’t mean we know nothing.
Question: Do all modern theories of physics have the same concept of time?
Answer: No. The main accepted theories are built on 3 different concepts of time.
Classical physics and quantum theory (the non relativistic portion, as Schrodinger equation) use the universal time, the same proposed by Newton in his mechanical theory. It is time as an universal flow, independent of space or anything that happens in space.
Electromagnetism and relativistic quantum theory use the same time concept as special relativity, an entity correlated with space. Still a flat (Minkowsky) space-time.
General relativity stands alone with a curved spacetime.
Quantum Theory
Question: Is nature really quantized or is quantization imposed by the mathematical and technological tools used to study natural phenomena?
Answer: Nature is really quantized. All we see in the macro world is an average of many quantum measurements. That means even properties we see with our common perceptions are made of, in principle, of quantum measurements.

Question: Would it be possible to set up a real Schrödinger’s cat experiment?
Answer: Yes, but you would have to kill many cats!
Question: Is quantum physics mostly theory, or has much of it been proven?
Answer: If it is a theory, it has been proven.
Other Topics in Physics
Question: How did the Arabian culture influence Eastern Europe through the ages?
Answer: During the middle ages most classic books (specially Greek works) were destroyed due to christian bigotry. Most books we have today were kept by the Arabs. There were a time when Arabian culture was much more advanced in terms of math and science than European culture. Renaissance was possible because of the Arabs.
Question: Where does the earth get the energy to revolve around the sun?
Answer: By conservation of angular momentum the Earth (and all the other orbiting objects) doesn’t need to receive any energy to keep on rotating. The reason it was first put in motion is a bit more complicated and it has to do with the way the galaxy and later the solar system was formed. The make it short a rotating disk of particles around te Sun gather into blobs (planets) also rotating.
Question: What are some obvious truths that are rarely acknowledged?
Answer: 42.

Question: What beliefs, if any, do we need to do science?
Answer: What about Occam’s razor? Is it a belief? Do we need it?
Question: Why do some of us question authority?
Answer: Some people may know a bit more than you do, in some areas. No one knows everything. No one should be considered an authority except in their areas of expertise (like a doctor in medicine).
Question: How do you explain that it’s the Earth that is rotating on its axis and revolving around the Sun, and not the Sun revolving around the Earth, to someone who is not that educated?
Answer: Just say they are orbiting one another. Since the Sun is much larger and massive, it doesn’t move much from its position.
Question: Where could a person feel the maximum gravity on earth?
Answer: At the sea level. If you can be in a rocket speeding upwards it will be even better.
Question: When a stone is dropped from a high tower, does it land at the foot, to the east (before), or west (behind the Earth’s rotational motion)?
Answer: It lands close to the point below the release point. The rock was rotating with earth before being released. It has angular momentum. But, some fictious forces may deviate the movement, just the kind that moves the Foucault pendulum.
Question: Who are the most famous scientists who believe in god?
Answer: Most scientist in the past were believers. People like Newton did their studies in order to prove “the glory of god”. But they could not do it and eventually people, like Laplace, begun to realize god was not a good hypothesis. So, slowly, most scientist begun either to disbelieve or to try to keep separate religion and science.
Question: Is our mathematics somehow constrained by the laws of physics? If so, could there possibly be alternate universes where the mathematics is completely alien to anything we know?
Answer: I think it is the other way around: Physics, as we understand so far, has to comply with math rules. Math alone is like a game were you can do whatever you want as long as you follow the rules (logic, internal coherence, etc!) Not all of math will be ever be used in physics or in any other application.
Question: Why don’t math professors explain things logically?
Answer: I had good teachers in college, can’t complain.
I think the choice and approach in basic math is very badly done. It makes math too hard and mostly useless (at least to the level most students can grasp). If you disagree ask anyone, who is not working with any aspects of math, what they remember from their courses…
I would point as example the very long calculations with trigonometric functions when all you need is the definition of sine, cossine and tan. In a certain aspect these functions are natural and should be very easy to understand. (I know they don’t look easy…!)
I’ve heard people saying that the modern math reform is to blame for all this. I disagree. What happens is that modern math, still now, have not been fully implemented in teaching curricula. If, when in fundamental level, you can grasp the concept that math IS the study of sets, the relations between elements of the set and between elements of different sets … you are doing good enough.
Question: What is the prime difference between mathematicians and physicists?
Answer: The main difference is that physicists do math with an eye in the “real world”. A theory may be mathematically right but wrong consequences when applied to nature.
Question: Will we ever be able to calculate the size of the universe, and if so, what data do we need before we can do it?
Answer: Hum, we might. And might not! Today we don’t even know if it is finite or not. We can have good estimates of how big is the observable universe and that may be (and is probably) the best we can ever know. Anything that is beyond has no causal relation to us and so, for all practical reasons, is just not inside OUR universe.
Bad thing about all this is that people talk about speculative hypothesis, like multiverses, as if they were proved theories.
Question: What are some software or anything else recommendations, besides Word or OneNote, that I can use to easily take mathematics and physics notes?
Answer: Latex is the (only) answer.
You can use a simple ASCII editor like Notepad to write text, then compile it into beautiful final texts. You would need to learn latex syntax to write things like
E = \frac{mc^2}{\sqrt{1-\frac{v^2}{c^2}}}
The above equation, when centralized to the page, would produce this display:
$$E = \frac{mc^2}{\sqrt{1-\frac{v^2}{c^2}}}$$
In case you do not feel like doing this use a Latex editor.
On the paid side of the software world (belief it or not some people like to pay for software even when you have equal or better quality free and open source similar) you can use Scientific World. It is a WYSIWYG editor (you see, as you type) rendered math on the screen.
There are many free and open source editors. I like Lyx and TexMacs. Você também pode usar TeXstudio, Texmaker, ou muitos outros, inclusive editores mais comummente usados com plugins para tex e latex. In any case I suggest you take some time to learn shortcuts for math editing.
Besides being powerful and fun to use, most of thrm will give you latex sources (which are the only thing used in the scientific community to share docs.)
Question: Can mathematics majors become theoretical physicists?
Answer: Yes, sure. But it is more difficult then doing the inverse, going from physics to math, in my opinion. The reason is the arduous path to learn quantum mechanics. A physics major takes around two years in courses about QM. There is no single discipline in math that takes so long to be grasped.
So, take some time to learn QM. And don’t believe those who say you can pass by only with relativity theory (special and general) which is not a quantum thing and takes much less time and effort to learn.
Question: What on Earth weigh exactly 0.00 pounds?
Answer: Just get any thing at all with adjustable density and make it with the exact density of the air where you make the measurement.
Question: Why is Maxwell considered at Newton’s and Einstein’s level?
Answer: I would remember that Maxwell did (maybe the first) great unification in physics, theoretically speaking. He wrote the full set of equations showing that electricity and magnetism are but different aspects of the same phenomenon.
With this he inaugurated a trend that follows to our days. Now we have a decent unified description of electromagnetic, weak and strong nuclear forces. On the other hand Einstein described gravitational interactions and his theory is in excellent agreement with observational data. BUT there is no theory so far unifying gravity with the other 3 forces.
Question: Can you solve complex math or physics problems only by using intuition?
Answer: Quite often people can tell of a bunch of mathematicians, physicists and others who came out with complex solutions off the box, attributed to intuition alone. But those who have these insights are in fact those who are working hard in a problem, sometimes for years. Intuition is a nice thing and I suppose some have it more then others. But it never came without effort and hard thinking.
A quote attributed to Einstein: “Science is 1% inspiration and 99% perspiration.”
(I could not find out if he really said this!)
Question: How do I prove the flat earth theory?
Answer: We see some questions are wrong by themselves. The Flat Earth “thing” (at best a hypothesis) is not a theory just because it cannot be proven. At the same time it is very easy to disprove the claim, as did Eratosthenes of Cirene in Greece, born about 276 BC. He made a rough estimate of the radius of Earth.
I believe all this talk about flat earth was first proposed, in modern times, as a hoax by someone trying to be funny. But now I see people from everywhere who look serious about that hoax.
Question: How can string theory be called a theory when it’s not experimentally proven? This use diminishes the value of the word theory and enables the phrase it’s just a theory to be used for well-supported theories i.e. creationist’s view on evolution.
Answer: I agree. It should be called The String Hypothesis, or Conjecture.

Question: Who do you think was more impressive, Newton or Einstein?
Answer: I don’t think it is possible to make such a comparison. Newton had his mind filled with superstition. He spent quite a bit of his time studying the Bible and alchemy. It is impossible to say how far he would go if he had spent most of his time with physics and math. On the other hand science as a whole was much simpler at his time.
Question: When reading Maxwell, Faraday, Lord Kelvin and more recently Nikola Tesla and Richard Feynman, all of them compared to others, seem to explain quite complex phenomena with words and without exclusively relying on mathematics. Why?
Answer: There is no proper way to fully describe physical phenomena without math. People can give good descriptions of the theories, better if they understand them well. But there will always be something missing. That means: learn math – at least calculus, of you want to learn physics.
Question: How deep is Deepak Chopra’s understanding of quantum physics?
Answer: When questioned by Richard Dawkins and Leonard Mlodinow, Chopra has agreed to say he talks about quantum stuff as metaphors only. That would be fine if he is clear to everyone about that. The issue is a very serious one since you can make lots of money just working against general understanding of modern physics, which is already very little among the general public.
Question: Why are so many men, usually white males, are jealous of Deepak Chopra and his work on spirituality?
Answer: I don’t know enough about people who disagree with Chopra to conclude they are mostly “white males”. My own problem with him is the very unscientific use of physics (mostly “quantum physics”) to endorse his concepts. There are many people working hard to bring good science education to the general public. We can’t be happy with those who work against it.
Question: Is evolution still a theory?
Answer: Evolution is a fact observed in nature. The explanation that evolution occurs by random mutations and natural selection is a theory. Be sure you understand what is a theory in science.
Question: Which forces does not exist in nature?
Answer: This is not really a well posed question. There is an infinity number of not existent things.
There are only 4 types of forces recognized by science, so far.
- Electromagnetic
- Gravitational
- Strong Nuclear
- Weak Nuclear
It is a good exercise to explain, in your mind, all kinds of interactions you see in nature in terms of these 4 fields.
It is not impossible that a new force may be found one day in the future. If you find it, you’ll probably get a Nobel Prize.
Question: Why does regular matter carry so little charge?
Answer: It is not true that matter carries little charge. It happens that most blocks of matter carries equal amount of positive (protons) and negative (electrons) charge so they cancel each other. To see electrical effect you have to strip some electrons, which is usually easier them strip protons.
Question: Is negative energy stronger than positive?
Answer: There is nothing as negative energy in physics.
Question: Was Newton jealous of Einstein?
Answer: Only if he could foresee the future!