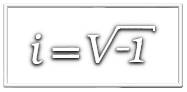Funções de uma variável complexa
Uma função \(f:\mathbb{C}\rightarrow \mathbb{C}\) é uma operação que transforma pontos do plano complexo em outros pontos. A cada função de uma variável complexa
$$
w=f\left( z\right) =u\left( x,y\right) +i\left( x,y\right)
$$
estão associadas duas funções reais: \(u\left( x,y\right) =\text{Re}f\left( z\right) \;\text{ e }\; v(x,y)=\text{Im}f\left( z\right)\). Como estas funções levam pontos do plano \(\mathbb{C}\) em pontos de \(\mathbb{C}\) há uma dificuldade natural em se visualizar geometricamente seu efeito. Em algumas situações é útil visualizar funções complexas como transformações. Neste caso se observa como um determinado conjunto de pontos de \(\mathbb{C}\) é levado no próprio \(\mathbb{C}\) pela função.
Exemplo 1: O valor absoluto é uma função que tem como argumento números complexos e retorna números reais: \(\;f:\mathbb{C}\rightarrow \mathbb{R}\). Representaremos esta função por \(\;f(z) = \left\vert z \right\vert\) e a definimos como
$$
w=f\left( z\right) =\left\vert z\right\vert =\sqrt{x^{2}+y^{2}}.
$$
A imagem desta função é \(\mathbb{R}^{+}\).
Exemplo 2: A função
$$
w=f\left( z\right) =\frac{2z-3i}{\left( z-2\right) \left( z+i\right) }
$$
é válida para todos os pontos de \(\mathbb{C}\), exceto \(z=2\) e \(z=-i\). Seu domínio é, portanto, \(D\left(f\right) =\mathbb{C}-\left\{ 2\right\} -\left\{ -i\right\}\).
Exercício Resolvido: Encontre as partes real e imaginária da função
$$
w=\frac{3}{z-5}.
$$
Em coordenadas cartesianas temos
$$
w=\frac{3}{x-5+iy}=\frac{3\left( x-5-iy\right) }{\left( x-5\right) ^{2}+y^{2}}=\frac{3x-15-3iy}{\left( x-5\right) ^{2}+y^{2}}.
$$
Portanto
$$
u\left( x,y\right) = \frac{3x-15}{\left( x-5\right) ^{2}+y^{2}} \;\;\;\;\text{ e }\;\;\;\; v\left( x,y\right) =\frac{3y}{\left( x-5\right) ^{2}+y^{2}}
$$
são as partes real e imaginária, respectivamente.
Limites e Continuidade
Algumas definições são necessárias para prosseguirmos nosso estudo.
Definição: Se \(z_{0}\) é um ponto de acumulação do domínio \(D\) de uma função \(f\) então
$$
\lim_{z\rightarrow z_{0}}f\left( z\right) =L
$$
se, dado qualquer \(\epsilon >0\) existe um \(\delta >0\) tal que
$$
z\in D,\;0<\left\vert z-z_{0}\right\vert <\delta \Rightarrow \left\vert f\left( z\right) -L\right\vert <\epsilon .
$$
Equivalentemente:
$$
z\in D\cap V_{\delta }\left( z_{0}\right) \Rightarrow f\left( z\right) \in V_{\varepsilon }\left( L\right).
$$
Definição: Se \(\lim_{z\rightarrow z_{0}}f\left( z\right) =f\left( z_{0}\right)\) então \(f\) é contínua em \(z_{0}\).
Teorema: Seja \(f=u+iv\) e \(L=U+iV\). Então
$$
\lim_{z\rightarrow z_{0}}f\left( z\right) =L\Longleftrightarrow \lim_{z\rightarrow z_{0}}u=U\text{ }\;\;\;\;\;\text{ e }\;\;\;\;\lim_{z\rightarrow z_{0}}v=V.
$$
Corolário: Uma função \(f\left(z\right) =u\left( x,y\right) +iv\left( x,y\right)\) é contínua se, e somente se, as funções \(u\) e \(v\) são contínuas.
Teorema: Se \(\lim_{z\rightarrow z_{0}}f\left( z\right) =F\) e \(\lim_{z\rightarrow z_{0}}g\left( z\right) =G\) então
(c) \(\lim_{z\rightarrow z_{0}}\left[ f\left( z\right) /g(z)\right] =F/G\), se \(G\neq 0\).
Teorema: Se \(\lim_{z\rightarrow z_{0}}f\left( z\right) =F\) então existe uma vizinhança \(V_{\delta }\left( z_{0}\right)\) onde \(f\left(z\right)\) é limitada.
Teorema: A soma e o produto de funções contínuas são contínuas. O quociente é contínuo se o denominador não se anula.
Analiticidade
Diferente do que acontece com as funções de uma variável real, quando se analisa o comportamento de uma função de uma variável complexa na vizinhança de um ponto \(z_{0}\) é necessário considerar os diferentes caminhos tomados para se chegar a \(z_{0}\) no plano complexo. De modo análogo ao que ocorre com funções de duas variáveis reais, diremos que uma função \(f:D\rightarrow \mathbb{C}\) é derivável em \(z_{0}\) se sua derivada não depende do caminho tomado para se chegar a \(z_{0}\).
Definição: Uma função \(f:D\rightarrow \mathbb{C}\) é derivável em \(z\in D\) se existe o limite
$$
\lim_{\Delta z\rightarrow 0}\frac{f\left( z+\Delta z\right) -f\left(
z\right) }{\Delta z}\equiv f^{\prime }\left( z\right).
$$
Este limite deve ser único, não podendo depender de como \(z+\Delta z\) se aproxima de \(z\) ou, equivalentemente, de como \(\Delta z\rightarrow 0\).
Exemplo 3: A função \(f\left( z\right) =\left\vert z\right\vert ^{2}\) não é derivável em nenhum ponto de \(\mathbb{C}\). Para ver isto fazemos \(f\left( z\right) =\left\vert z\right\vert ^{2}=z \bar{z}\) e, usando a definição,
$$
f^{\prime }\left( z\right) =\lim_{\Delta z\rightarrow 0}\frac{\left(
z+\Delta z\right) \left( \bar{z}+\Delta \bar{z}\right) -z\bar{z}}{\Delta z}
=\lim_{\Delta z\rightarrow 0}\frac{z\Delta \bar{z}}{\Delta z}+\Delta \bar{z}+
\bar{z}.
$$
Escrevendo o incremento em forma polar,
$$
\Delta z=re^{i\theta };\ \Delta \bar{z}=re^{-i\theta },
$$
e lembrando que \(\Delta z\rightarrow 0\) equivale a \(r\rightarrow 0\) temos que
$$
f^{\prime }\left( z\right) =\lim_{r\rightarrow 0}\ \left( ze^{-2i\theta
}+re^{-i\theta }+\bar{z}\right) =ze^{-2i\theta }+\bar{z}.
$$
Observe que este limite depende do ângulo \(\theta\) com que se aproxima de \(z\) e, portanto, o limite não é único. Dizemos que esta função só tem derivada no ponto \(z=0\) e, neste ponto, \(f^{\prime}\left( 0\right) =0\).
Definição: Uma função \(f:D\rightarrow \mathbb{C}\) é analítica em uma região \(R\) se é derivável em cada ponto de \(R\). \(f\) é analítica no ponto \(z_{0}\) se é analítica numa vizinhança \(V_{\delta }\left( z_{0}\right)\). Uma função é dita inteira se for analítica em todo o plano complexo. As expressões holomorfa ou regular são também empregadas.
Regras de derivação
As funções elementares, extendidas para o plano complexo, são analíticas. Veremos alguns exemplos simples deste fato.
Exemplo 4: A função contínua \(f\left( z\right)=z_0\;\) (uma constante) é analítica e sua derivada é nula em todo ponto.
Exemplo 5: Se \(f\left( z\right) =z^{2}\) então
$$
f^{\prime }\left( z\right) =\lim_{\Delta z\rightarrow 0}\frac{f\left(
z+\Delta z\right) -f\left( z\right) }{\Delta z}=\lim_{\Delta z\rightarrow 0}
\frac{\left( z+\Delta z\right) ^{2}-z^{2}}{\Delta z}=
$$
$$
= \lim_{\Delta z\rightarrow 0}\frac{2z\Delta z+\Delta z^{2}}{\Delta z}==\lim_{\Delta z\rightarrow 0}2z+\Delta z=2z.
$$
Observe que este limite não depende de como \(\Delta z\rightarrow 0\). Usando o binômio de Newton podemos generalizar este resultado para funções \(f\left( z\right) =z^{n}\), cujas derivadas são
$$
f^{\prime }\left( z\right) =nz^{n-1}.
$$
Observamos que a soma e o produto de funções analíticas são analíticas. O quociente é analítico se o denominador for não-nulo. As seguintes regras se aplicam:
| a. \(\left(f+g\right)^{\prime}=f^{\prime}+g^{\prime }\) |
| b. \(\left(fg\right)^{\prime}=f^{\prime}g+fg^{\prime }\) |
| c. \(\left(\frac{f}{g}\right)^{\prime}=\frac{f^{\prime}g-fg^{\prime }}{g^{2}},\;\;\text{ se }\;\;g\neq 0\). |
Além disto temos um resultado importante: se \(f\) é uma função derivável em \(z_{0}\) então ela é contínua neste ponto. Para ver isto notamos que
$$
f^{\prime }\left( z_{0}\right) =\lim_{z\rightarrow z_{0}}\frac{f\left(z\right) -f\left( z_{0}\right) }{z-z_{0}}.
$$
Definimos
$$
g\left( z\right) =\frac{f\left( z\right) -f\left( z_{0}\right) }{z-z_{0}}-f^{\prime }\left( z_{0}\right)
$$
e, portanto,
$$
\lim_{z\rightarrow z_{0}}g\left( z\right) =0.
$$
De (1) podemos escrever
$$
f\left( z\right) =f\left( z_{0}\right) +\left( z-z_{0}\right) g\left(z\right) +\left( z-z_{0}\right) f^{\prime }\left( z_{0}\right)
$$
e, desta última expressão
$$
\lim_{z\rightarrow z_{0}}f\left( z\right) =f\left( z_{0}\right).
$$
Logo ela é contínua.
Exemplo 6: A função
$$
f\left( z\right) =\frac{\left( z+i\right) \left( 3z+1\right) ^{2}}{z\left(z-i\right) \left( z+2\right) ^{2}}
$$
só deixa de ser analítica nos pontos \(z=0\), \(z=i\) e \(z=-2\).
Condições de Cauchy-Riemann
Seja \(f\left( z\right) =u+iv\) uma função derivável em \(z=x+iy\). Então o limite
$$
\lim_{\Delta z\rightarrow 0}\frac{f\left( z-\Delta z\right) -f\left(
z\right) }{\Delta z}=f^{\prime }\left( z\right)
$$
existe e independe de como \(\Delta z\rightarrow 0\). Tomamos em particular dois caminhos. Fazendo \(\Delta z=k\), que corresponde a \(z\) se aproximando de \(z_{0}\) ao longo do eixo real, temos
$$
f^{\prime }\left( z\right) =\lim_{k\rightarrow 0}\frac{1}{k}\left[ u\left(
x+k,y\right) +iv\left( x+k,y\right) -u\left( x,y\right) -iv\left( x,y\right)
\right]
$$
$$
=\lim_{k\rightarrow 0}\frac{1}{k}\left[ u\left( x+k,y\right) -u\left(
x,y\right) +iv\left( x+k,y\right) -iv\left( x,y\right) \right] =
$$
$$
=\frac{\partial u\left( x,y\right) }{\partial x}+i\frac{\partial v\left(
x,y\right) }{\partial x}.
$$
Por outro lado, fazendo \(\Delta z=it\), o que corresponde a tomar \(z\) se aproximando de \(z_{0}\) ao longo do eixo imaginário, temos
$$
f^{\prime }\left( z\right) =\lim_{t\rightarrow 0}\frac{1}{it}\left[ u\left(x,y+t\right) +iv\left( x,y+t\right) -u\left( x,y\right) -iv\left( x,y\right)
\right].
$$
Para explicitar as partes real e imaginária deste limite multiplicamos numerador e denominador por \(-i\),
$$
f^{\prime }\left( z\right) =\lim_{t\rightarrow 0}\frac{1}{t}\left[ v\left(x,y+t\right) -v\left( x,y\right) -iu\left( x,y+t\right) +iu\left( x,y\right) \right] =
$$
$$
=\frac{\partial v\left( x,y\right) }{\partial y}-i\frac{\partial u\left(x,y\right) }{\partial y}.
$$
Para que a função seja derivável os limites tomados para os dois casos devem ser iguais. Identificando as partes reais e imaginárias chegamos às equações de Cauchy-Riemann:
$$
\frac{\partial u\left( x,y\right) }{\partial x}=\frac{\partial v\left(x,y\right) }{\partial y};
$$
$$
\frac{\partial u\left( x,y\right) }{\partial y}=-\frac{\partial v\left(x,y\right) }{\partial x}.
$$
Para simplificar a notação faremos
$$
\frac{\partial u}{\partial x}=u_{x};\;\ \frac{\partial v}{\partial y}=v_{y};\ \;\frac{\partial u}{\partial y}=u_{y};\ \;\frac{\partial v}{\partial x}=v_{x},
$$
de forma que as equações de Cauchy-Riemann podem ser escritas simplesmente como
$$
u_{x}=v_{y};\;\;\ \;u_{y}=-v_{x}.
$$
Estas condições, no entanto, são necessárias mas não suficientes para que \(f=u+iv\) seja uma função analítica. O seguinte teorema exibe as condições para que isto seja verdadeiro.
Teorema: Sejam \(u\left( x,y\right)\) e \(v\left(x,y\right)\) funções reais com derivadas parciais contínuas numa região \(R\). Então as equações de Cauchy-Riemann são condições necessárias e suficientes para que \(f=u+iv\) seja analítica.
Observe que, para uma função analítica, podemos tomar\ \(\Delta z\rightarrow 0\) ao longo de qualquer caminho, em particular podemos fazer \(\Delta z=\Delta x\), como fizemos na derivação das equações de Cauchy-Riemann. Sua derivada é, portanto
$$
\frac{df\left( z\right) }{dz}=\frac{\partial f\left( z\right) }{\partial x}.
\label{dparc}
$$
Se for conveniente podemos também usar a derivada parcial em \(y\).
Exemplo 8: A função \(f\left( z\right) =\bar{z}\) não é analítica. Note que \(\bar{z}=x-iy\). Dai
$$
u\left( x,y\right) =x,\; v\left( x,y\right) =-y,\; u_{x}=1,\; v_{x}=0,\; u_{y}=0,v_{y}=-1.
$$
Exemplo 9: Como já sabemos a função \(f\left(z\right) =z^{2}\) é analítica. Observe que, em coordenadas cartesianas,
$$
f\left( z\right) =\left( x+iy\right) ^{2}=x^{2}-y^{2}+2xyi.
$$
Suas partes real e imaginária são
$$
u\left( x,y\right) =x^{2}-y^{2};\ \ v\left( x,y\right) =2xy
$$
e suas derivadas parciais
$$
\begin{array}{ll}
\frac{\partial u}{\partial x}=2x, & \frac{\partial v}{\partial y}=2x \\
\frac{\partial u}{\partial y}=-2y,\ \ \ \ & \frac{\partial v}{
\partial x}=2y.
\end{array}
$$
Como \(u_{x}=v_{y}\), \(\ u_{y}=-v_{x}\) e as derivadas parciais são contínuas então a função é analítica. Sua derivada é, usando (2),
$$
\frac{dz^{2}}{dz}=\frac{\partial z^{2}}{\partial x}=u_{x}+iv_{x}=2x+2iy=2z.
$$
Exemplo 10: Vamos verificar que se a função \(f\left(z\right) =1/z\) é analítica e encontrar sua derivada. Precisamos primeiro escrever a função de forma a explicitar sua parte real e imaginária,
$$
f\left( z\right) =\frac{1}{z}=\frac{1}{x+iy}=\frac{1}{x+iy}\frac{x-iy}{x-iy}=
\frac{x-iy}{x^{2}+y^{2}}.
$$
Portanto
$$
u\left( x,y\right) =\frac{x}{x^{2}+y^{2}},\;\;\;v\left( x,y\right) =\frac{-y}{x^{2}+y^{2}}.
$$
Lembrando que a derivada de um quociente é
$$
\left( \frac{f}{g}\right) ^{\prime }=\frac{f^{\prime }g-fg^{\prime }}{g^{2}}
$$
calculamos
$$
u_{x}=\frac{x^{2}+y^{2}-x\left( 2x\right) }{\left( x^{2}+y^{2}\right) ^{2}}=
\frac{y^{2}-x^{2}}{\left( x^{2}+y^{2}\right) ^{2}},
$$
$$
u_{y}=\partial _{y}\left[ x\left( x^{2}+y^{2}\right) ^{-1}\right] =\frac{-2xy}{\left( x^{2}+y^{2}\right) ^{2}},
$$
$$
v_{x}=\partial _{x}\left[ -y\left( x^{2}+y^{2}\right) ^{-1}\right] =\frac{2xy}{\left( x^{2}+y^{2}\right) ^{2}},
$$
$$
v_{y}=-\frac{x^{2}-y^{2}}{\left( x^{2}+y^{2}\right) ^{2}}=\frac{y^{2}-x^{2}}{\left( x^{2}+y^{2}\right) ^{2}}.
$$
Observamos que as equações de Cauchy-Riemann, \(u_{x}=v_{y},\;u_{y}=-v_{x},\;\) são satisfeitas em todo o plano complexo. No entanto as derivadas parciais de \(u\) e \(v\) não são contínuas em \(\left(x,y\right) =\left( 0,0\right)\) de onde concluímos que \(f\left(z\right)\) é analítica em \(\mathbb{C}-\left\{ 0\right\}\). Fora de \(z=0\) a função é analítica e podemos usar (2) para obter sua derivada:
$$
\frac{d}{dz}\left( \frac{1}{z}\right) =\frac{\partial }{\partial x}\left(\frac{1}{z}\right) =\frac{\partial }
{\partial x}\left( \frac{x-iy}{x^{2}+y^{2}}\right) =-\frac{1}{z^{2}}.
$$
Obtenha, como um exercício, a última igualdade.
Exercício Resolvido: Verifique se são analíticas e em que região são analíticas as funções:
a. \(f(z)=e^z\) b. \(f(z) =z\bar{z}\) c. \(f(z) =1\)
Encontre as derivadas das funções, quando existirem.
a. A função exponencial pode ser escrita como
$$
f\left( z\right) =e^{z}=e^{x+iy}=e^{x}e^{iy}=e^{x}\left( \cos y+i\text{sen }y\right).
$$
Portanto
$$
u\left( x,y\right) =e^{x}\cos y\;\;\;\Rightarrow \;\;\;u_{x}=e^{x}\cos y,\;\;\;u_{y}=-e^{x}\text{sen }y
$$
$$
v\left( x,y\right) =e^{x}\text{sen }y\;\;\;\Rightarrow \;\;v_{x}=e^{x}\text{sen }y,\;\;\;v_{y}=e^{x}\cos y.
$$
Como as condições de Cauchy Riemann são satisfeitas e as derivadas parciais são contínuas a função é analítica em todo o plano complexo. Além disto sua derivada é
$$
\frac{d\,e^{z}}{dz}=\frac{\partial \,e^{z}}{\partial x}=u_{x}+iv_{x}=e^{x}\cos y+ie^{x}\text{sen }y=e^{x}e^{iy}=e^{z}.
$$
b. A função \(f\left( z\right) =z\bar{z}=(x+iy)\left( x-iy\right)=x^{2}+y^{2}\) só é analítica em \(z=0\) pois
$$
u\left( x,y\right) =x^{2}+y^{2}\;\;\;\Rightarrow \;\;\;u_{x}=2x,\;\;\;u_{y}=2y
$$
$$
v\left( x,y\right) =0\;\;\;\Rightarrow \;\;v_{x}=0,\;\;\;v_{y}=0.
$$
c. Já a função constante \(f\left( z\right) =1\) é analítica em \(\mathbb{C}\) pois \(u=1,\;v=0\), e todas as derivadas são nulas, portanto contínuas. Sua derivada é
$$
\frac{d\,1}{dz}=\frac{\partial \,1}{\partial x}=0.
$$
Equações de Cauchy-Riemann em coordenadas polares
Algumas vezes é mais fácil trabalhar com as funções em coordenadas polares para testar sua analiticidade. Para obter as equações de Cauchy-Riemann nestas coordenadas partimos das relações entre as coordenadas polares e as coordenadas cartesianas,
$$
r\left( x,y\right) =\sqrt{x^{2}+y^{2}};\;\;\theta \left( x,y\right) =\arctan\left( \frac{y}{x}\right)
$$
ou, inversamente,
$$
x=r\cos \theta ,\ \ y=r\text{sen }\theta .
$$
Se \(f\) é uma função de \(x\) e \(y\), que, por sua vez, são funções de \(r\) e \(\theta\),
$$
f=f\left( x\left( r,\; \theta \right) ,\;\; y\left( r,\; \theta \right) \right)
$$
podemos relacionar as derivadas parciais calculadas nos dois sistemas de coordenadas por meio da regra da cadeia:
$$
\frac{\partial f}{\partial r}=\frac{\partial f}{\partial x}\frac{\partial x}{
\partial r}+\frac{\partial f}{\partial y}\frac{\partial y}{\partial r},
$$
$$
\frac{\partial f}{\partial \theta }=\frac{\partial f}{\partial x}\frac{
\partial x}{\partial \theta }+\frac{\partial f}{\partial y}\frac{\partial y}{
\partial \theta }.
$$
Como estas duas relações são válidas independentemente da função \(f\) considerada podemos escrever as relações de operadores,
$$
\frac{\partial }{\partial r}=\frac{\partial }{\partial x}\frac{\partial x}{
\partial r}+\frac{\partial }{\partial y}\frac{\partial y}{\partial r},
$$
$$
\frac{\partial }{\partial \theta }=\frac{\partial }{\partial x}\frac{
\partial x}{\partial \theta }+\frac{\partial }{\partial y}\frac{\partial y}{
\partial \theta }.
$$
Precisaremos das derivadas
$$
\begin{array}{ll}
x_{r}=\cos \theta , & y_{r}=\text{sen }\theta , \\
x_{\theta }=-r\text{sen }\theta ,\ \ \ & y_{\theta }=r\cos \theta .
\end{array}
$$
Então
$$
\frac{\partial }{\partial r}=\cos \theta \frac{\partial }{\partial x}+\text{
sen}\theta \frac{\partial }{\partial y},\; \; \; \; \frac{\partial }{
\partial \theta }=-r\text{sen }\theta \frac{\partial }{\partial x}+r\cos
\theta \frac{\partial }{\partial y}.
$$
Em particular
$$
\begin{array}{ll}
u_{r}=\cos \theta ~u_{x}+\text{sen }\theta ~u_{y}, & v_{r}=\cos \theta ~v_{x}+
\text{sen }\theta ~v_{y}, \\
u_{\theta }=-r\text{sen }\theta ~u_{x}+r\cos \theta ~u_{y},\; \; \; \; &
v_{\theta }=-r\text{sen }\theta ~v_{x}+r\cos \theta ~v_{y}.
\end{array}
$$
Usando as equações de Cauchy-Riemann em coordenadas cartesianas (\(u_{x}=v_{y}\) e \(u_{y}=-v_{x}\) ) podemos escrever
$$
\begin{array}{ll}
u_{r}=\cos \theta & v_{y}-\text{sen }\theta ~v_{x}=\frac{1}{r}v_{\theta }, \\
u_{\theta }=-r\text{sen }\theta & v_{y}-r\cos \theta ~v_{x}=-rv_{r}.
\end{array}
$$
Estas são, portanto, as equações de Cauchy-Riemann em coordenadas polares:
$$
\frac{\partial u}{\partial r}=\frac{1}{r}\frac{\partial v}{\partial \theta },
$$
$$
\frac{\partial v}{\partial r}=-\frac{1}{r}\frac{\partial u}{\partial \theta}.
$$
Observe que, se a função é analítica, sua derivada é
$$
\frac{df\left( z\right) }{dz}=\frac{\partial f\left( z\right) }{\partial x}.
$$
A derivada parcial em \(x\) pode ser associada às derivadas em \(r\) e \(\theta\) da seguinte forma: primeiro calculamos as derivadas parciais
$$
\frac{\partial r}{\partial x}=\frac{\partial }{\partial x}\sqrt{x^{2}+y^{2}}=\frac{x}{\sqrt{x^{2}+y^{2}}}=\frac{x}{r}=\cos \theta,
$$
$$
\frac{\partial \theta }{\partial x}=\frac{\partial }{\partial x}\text{arctag } \left( \frac{y}{x}\right) =\frac{1}{1+\left( y/x\right) ^{2}}\frac{-y}{x^{2}}
=\frac{-y}{x^{2}+y^{2}}=\frac{-\text{sen }\theta }{r}.
$$
Em seguida, usando a regra da cadeia, temos
$$
\frac{\partial }{\partial x}=\frac{\partial }{\partial r}\frac{\partial r}{
\partial x}+\frac{\partial }{\partial \theta }\frac{\partial \theta }{
\partial x}=\cos \theta \frac{\partial }{\partial r}-\frac{\text{sen }\theta
}{r}\frac{\partial }{\partial \theta }
$$
portanto
$$
\frac{df\left( z\right) }{dz}=\cos \theta \frac{\partial f\left( z\right) }{
\partial r}-\frac{\text{sen }\theta }{r}\frac{\partial f\left( z\right) }{
\partial \theta }.
$$
Apenas como referência vamos listar a derivada parcial em \(y:\)
$$
\frac{\partial }{\partial y}=\frac{\partial }{\partial r}\frac{\partial r}{
\partial y}+\frac{\partial }{\partial \theta }\frac{\partial \theta }{
\partial y}=\text{sen }\theta \frac{\partial }{\partial r}+\frac{\cos \theta
}{r}\frac{\partial }{\partial \theta },
$$
enquanto \(r\) e \(\theta\) tem derivadas em \(y\)
$$
\frac{\partial r}{\partial y}=\frac{\partial }{\partial y}\sqrt{x^{2}+y^{2}}=
\frac{y}{\sqrt{x^{2}+y^{2}}}=\frac{r\text{sen }\theta }{r^{2}}=\text{sen }
\theta ,
$$
$$
\frac{\partial \theta }{\partial y}=\frac{\partial }{\partial y}\text{arctag}
\left( \frac{y}{x}\right) =\frac{1}{1+\left( y/x\right) ^{2}}\frac{1}{x}=
\frac{x}{x^{2}+y^{2}}=\frac{\cos \theta }{r}.
$$
Exemplo 11: Vamos verificar se a função \(f\left(z\right) =1/z\) é analítica. Já resolvemos este exercício em coordenadas cartesianas mas vale notar que a verificação fica mais simples em coordenadas polares. Para isto escrevemos
$$
f\left( z\right) =\frac{1}{z}=\frac{1}{re^{i\theta }}=\frac{e^{-i\theta }}{r}
=\frac{1}{r}\left( \cos \theta -i\text{sen }\theta \right).
$$
Portanto
$$
u\left( r,\theta \right) =\frac{1}{r}\cos \theta ,\;\;\;v\left( r,\theta
\right) =-\frac{1}{r}\text{sen }\theta .
$$
Calculamos agora
$$
u_{r}=-\frac{1}{r^{2}}\cos \theta ,\;\;\;\;\;u_{\theta }=-\frac{1}{r}
\text{sen }\theta ,
$$
$$
v_{r}=\frac{1}{r^{2}}\text{sen }\theta, \;\;\;\;\;\;v_{\theta }=-\frac{1}{r}\cos \theta.
$$
portanto \(u_{r}=\frac{1}{r}v_{\theta },\;v_{r}=-\frac{1}{r}u_{\theta }\), as equações de Cauchy-Riemann são satisfeitas. No entanto as derivadas parciais não são contínuas em \(r=0\) logo \(f\left(z\right)\) não é analítica em \(z=0,\;\) como já havíamos concluído usando a representação em coordenadas cartesianas.
Exemplo 12: Verifique se a função \(f\left( z\right) =1/z^{2}\) é analítica. Escrevemos a função em coordenadas polares,
$$
f\left( z\right) =\frac{1}{z^{2}}=\frac{1}{r^{2}e^{2i\theta }}=\frac{
e^{-2i\theta }}{r^{2}}=\frac{1}{r^{2}}\left( \cos 2\theta -i\text{sen }
2\theta \right).
$$
Portanto
$$
u\left( r,\theta \right) =\frac{1}{r^{2}}\cos 2\theta ,\;\;\;v\left(
r,\theta \right) =-\frac{1}{r^{2}}\text{sen }2\theta .
$$
As derivadas parciais de \(u\) e \(v\), em coordenadas polares, são
$$
u_{r}=-\frac{2}{r^{3}}\cos 2\theta ,\;\;\;\;\;u_{\theta }=-\frac{2}{r^{2}}\text{sen }2\theta ,
$$
$$
v_{r}=\frac{2}{r^{3}}\text{sen }2\theta ;\;\;\;\;\;\;v_{\theta }=-\frac{2}{
r^{2}}\cos 2\theta .
$$
portanto \(u_{r}=\frac{1}{r}v_{\theta },\;v_{r}=-\frac{1}{r}u_{\theta }\). As derivadas parciais não são contínuas em \(r=0\;\;\) logo \(f\left(z\right)\) não é analítica em \(r=0\).
Exercício Resolvido: Verifique se são analíticas e em que região são analíticas:
a. \(f\left( z\right) =\frac{1}{z^{3}},\;\;\;\)b.\( \; f\left( z\right) =\sqrt{z}\).
Para estas funções é mais fácil fazer o teste em coordenadas polares.
a. Escrevemos \(z=re^{i\theta }\), logo
$$
f\left( z\right) =\frac{1}{z^{3}}=\frac{1}{r^{3}e^{3\theta i}} =r^{-3}\left( \cos 3\theta -i\text{sen }3\theta \right).
$$
Foi usado aqui
$$
\frac{1}{e^{3\theta i}}=e^{-3\theta i}=\cos \left( -3\theta \right) +i \text{sen }\left( -3\theta \right) =\cos 3\theta -i\text{sen }3\theta ,
$$
pois o cosseno é uma função par enquanto o seno é impar. Temos então
$$
u=r^{-3}\cos 3\theta \;\;\;\Rightarrow \;\;\;u_{r}=-3r^{-4}\cos 3\theta ,\;\;\;u_{\theta }=-3r^{-3}\text{sen }3\theta
$$
$$
v=-r^{-3}\text{sen }3\theta \;\;\;\Rightarrow \;\;v_{r}=3r^{-4}\text{sen }3\theta ,\;\;\;v_{\theta }=-3r^{-3}\cos 3\theta .
$$
Então a função é analítica, exceto em \(z=0\), onde as derivadas parciais não são contínuas. Observe que neste ponto a função nem mesmo está definida.
b. Escrevemos \(z=re^{i\theta }\) e tomamos uma de suas raízes, observando que o mesmo resultado seria obtido com a outra raiz,
$$
f\left( z\right) =\sqrt{z}=\sqrt{re^{i\theta }}=\sqrt{r}e^{i\theta /2}=\sqrt{r}\left( \cos \frac{\theta }{2}+i\text{sen }\frac{\theta }{2}\right).
$$
Temos então
$$
u=\sqrt{r}\cos \frac{\theta }{2}\;\;\;\Rightarrow \;\;\;u_{r}=\frac{1}{2\sqrt{r}}\cos \frac{\theta }{2},\;\;\;u_{\theta }=-\frac{\sqrt{r}}{2}\text{
sen}\frac{\theta }{2},
$$
$$
v=\sqrt{r}\text{sen }\frac{\theta }{2}\;\;\;\Rightarrow \;\;v_{r}=\frac{1}{2
\sqrt{r}}\text{sen }\frac{\theta }{2},\;\;\;v_{\theta }=\frac{\sqrt{r}}{2}
\cos \frac{\theta }{2}.
$$
Então a função é analítica exceto em \(z=0\). Note que a função está definida em \(z=0\) mas suas derivadas parciais, \(u_{r}\) e \(v_{r}\), não são contínuas neste ponto.
Exercício Resolvido: Verifique se é analítica a função logaritmo, \(f\left( z\right) =\ln z=\ln \left(re^{i\theta }\right)\).
Observe que o logaritmo, que voltaremos a estudar ainda neste capítulo, pode ser escrito da seguinte forma, usando a propriedade \(\ln \left(ab\right) =\ln a+\ln b:\)
$$
\ln z=\ln \left( re^{i\theta }\right) =\ln r+\ln e^{i\theta }=\ln r+i\theta ,
$$
para \(0\leq \theta \leq 2\pi\). Nesta região temos
$$
u\left( r,\theta \right) =\ln r,\ \ v\left( r,\theta \right) =\theta .
$$
As derivadas parciais são
$$
\begin{array}{lll}
u_{r}=\frac{1}{r}, & & v_{\theta }=0, \\
v_{r}=0, & & v_{\theta }=1,
\end{array}
$$
e, portanto a função é analítica em todo o plano complexo exceto na origem, onde \(u_{r}\) não é contínua.
Interpretação geométrica da analiticidade
Para o estudo que se segue será útil fazer uma revisão dos conceitos de curva de nível e gradiente. Dada uma função de duas variáveis, \(z=u\left( x,y\right)\), então \(u\left( x,y\right) =k\), uma constante, formam famílias de curvas em \(\mathbb{R}^{2}\), cada curva correspondendo a um valor da constante \(k\). Estas são as chamadas curvas de nível de \(u\) consistindo no conjunto de pontos de \(\mathbb{R}^{2}\) que são levados no mesmo valor \(k\) pela função \(u\). Definimos o gradiente de \(u\) como o vetor
$$
\text{grad}u=\vec{\bigtriangledown}u=\left( \frac{\partial u}{\partial x},~
\frac{\partial u}{\partial y}\right)
$$
e observamos que o gradiente é perpendicular a um vetor tangente às curvas de nível, como ilustrado na figura. Para ver isto note que, sobre as curvas de nível, temos \(u\left( x,y\right) =k\) e portanto
$$
0=du=\frac{\partial u}{\partial x}dx+\frac{\partial u}{\partial y}dy=\left(
\frac{\partial u}{\partial x},~\frac{\partial u}{\partial y}\right) \cdot
\left( dx,~dy\right).
$$
Em outros termos temos
$$
\vec{\bigtriangledown}u\cdot d\vec{x}=0\Rightarrow \vec{\bigtriangledown} u\bot d\vec{x}.
$$

Podemos agora enunciar o seguinte teorema:
Teorema: Se a função \(f=u+iv\) é analítica em uma região \(R\) então as curvas de nível das famílias \(u\left( x,y\right) = \; \text{ constante e } \; v\left( x,y\right) =\) constante se cruzam em ângulo reto (são ortogonais) em todo ponto \(z_{0}\in R\) satisfazendo \(\;f^{\prime }\left( z_{0}\right) \neq 0\).
Demonstração: \(\text{grad}u=\vec{\bigtriangledown} u=\left( u_{x},~u_{y}\right)\) é normal às curvas \(u=\) cte enquanto \(\vec{\bigtriangledown}v=\left( v_{x},~v_{y}\right)\) é normal às curvas \(v=\) cte. Tomamos o produto escalar
$$
\vec{\bigtriangledown}u\cdot \vec{\bigtriangledown}v=\left(
u_{x},~u_{y}\right) \cdot \left( v_{x},~v_{y}\right) =u_{x}v_{x}+u_{y}v_{y}.
$$
Usando as condições de Cauchy-Riemann para a analiticade de \(f\) temos
$$
\vec{\bigtriangledown}u\cdot \vec{\bigtriangledown}v=-u_{x}u_{y}+u_{y}u_{x}=0,
$$
de onde concluímos que \(\vec{\bigtriangledown}u\bot \vec{\bigtriangledown}v\).
Observe que estas curvas, \(u\) e \(v\) constante, são curvas no domínio da função no plano complexo, representado pelas coordenadas \(z=x+iy\) como ilustrado na figura. As curvas \(u\) e \(v\) constante na imagem, \(w=f\left( z\right)\) são perpendiculares por definição.
Exemplo 13: Vamos verificar a perpendicularidade estudada acima para a função
$$
w=z^{2}=x^{2}-y^{2}+2ixy.
$$
As curvas \(u\left( x,y\right) =k\) são as hipérboles
$$
x^{2}-y^{2}=k_{1}\Rightarrow \frac{x^{2}}{k_{1}}-\frac{y^{2}}{k_{1}}=1,
$$
enquanto \(v\left( x,y\right) =k\) são também hipérboles, dadas por
$$
2xy=k_{2}\Rightarrow y=\frac{k_{2}}{2x}.
$$
Algumas vezes é útil considerar o último teorema sob a seguinte
forma:
Teorema: Se a função \(f=u+iv\) é analítica em uma região \(R\) então as famílias de curvas
\begin{array}{ll}
F_{1}: & u\left( x,y_{0}\right) +iv\left( x,y_{0}\right) , \\
F_{2}: & u\left( x_{0},y\right) +iv\left( x_{0},y\right) ,
\end{array}
$$
parametrizadas por \(x\) e \(y\) respectivamente, são ortogonais em \(z_{0}\in R\), desde que \(f^{\prime }\left( z_{0}\right) \neq 0\).
Demonstração: Em forma vetorial as famílias \(F_{1}\) e \(F_{2}\) e suas respectivas tangentes, \(t_{1}\) e \(t_{2}\), são
$$
\begin{array}{ll}
F_{1}=\left( u\left( x,y_{0}\right) ,\ v\left( x,y_{0}\right) \right) ;\ &
t_{1}=\frac{\partial F_{1}}{\partial x}=\left. \left( u_{x},~v_{x}\right)
\right\vert _{\left( x_{0},y_{0}\right) },\; \; \\
F_{2}=\left( u\left( x_{0},y\right) ,~v\left( x_{0},y\right) \right) ;\ &
t_{2}=\frac{\partial F_{2}}{\partial y}=\left. \left( u_{y},~v_{y}\right)
\right\vert _{\left( x_{0},y_{0}\right) },
\end{array}
$$
lembrando que as tangentes são calculadas no ponto \(\left(x_{0},y_{0}\right)\). As tangentes são ortogonais, pois, tomando seu produto escalar obtemos
$$
t_{1}\cdot t_{2}=u_{x}u_{y}+v_{x}v_{y}=-u_{x}v_{x}+v_{x}u_{x}=0.
$$
Isto pode ser visualizado na figura abaixo.

Exemplo 14: Vamos visualizar a função \(w=\exp \left(z\right) =e^{z}\) como uma transformação e observar que as curvas \(\left( x_{\ },y_{0}\right)\) e \(\left( x_{0},y\right)\) no plano \(xy\) são levadas em curvas que se interceptam ortogonalmente no plano \(uv\). Notamos primeiramente que
$$
w=e^{x+iy}=e^{x}e^{iy}=e^{x}\left( \cos y+i\text{sen }y\right).
$$
As partes real e imaginária e suas derivadas são
$$
\begin{array}{lll}
u\left( x,y\right) =e^{x}\cos y, & u_{x}=e^{x}\cos y, & u_{y}=-e^{x}\text{sen }y, \\
v\left( x,y\right) =e^{x}\text{sen }y, & v_{x}=e^{x}\text{sen }y, & v_{y}=e^{x}\cos y.
\end{array}
$$
Como as condições de Cauchy-Riemann são satisfeitas e as derivadas parciais são contínuas a função é analítica. Além disto sua derivada é
$$
\frac{de^{z}}{dz}=\frac{\partial e^{z}}{\partial x}=\frac{\partial }{
\partial x}\left( e^{x+iy}\right) =e^{x+iy}=e^{z},
$$
e
$$
\vec{\nabla}u\cdot \vec{\nabla}v=u_{x}v_{x}+u_{y}v_{y}=0.
$$
A reta \(\left( x,~0\right)\) é levada em \(w=e^x\), que é a semi-reta \(u\gt 0,\; v=0\) do plano \(uv\). A reta \(\left( x,~\pi /4\right)\) é levada em \(w=e^{x}e^{i\pi /4}\), que é a semi-reta bissetriz do primeiro quadrante. A reta \(\left( 0,\ y\right)\) é levada em \(w=e^{iy}\), que é a circunferência de raio \(1\). Estas e outras retas de \(xy\) e sua imagem no plano \(uv\) estão representadas na figura. Observe que nenhum ponto de \(\mathbb{C}\) é levado na origem da imagem.

Exercícios
1. Encontre as partes real e imaginárias das seguintes funções:
$$
\begin{array}{ll}
\text{a) }\;\; w=z^{2}-5z+3 & \;\; \text{b) }\;\; w=\frac{z+2}{z-i} \\
\text{c) }\;\; w=e^{iz} & \;\; \text{d) }\;\; w=\sqrt{z}
\end{array}
$$
2. Qual é o domínio máximo de definição das seguintes funções?
$$
\begin{array}{ll}
\text{a)}\ f\left( z\right) =\frac{z}{x}-\frac{y}{z}\ \ \ \ \
& \text{b)}\ f\left( z\right) =\frac{z^{2}+\left( z-1\right) ^{3}}{\left(
e^{z}-1\right) \cos y}
\end{array}
$$
3. Mostre, usando a definição, que
$$
\frac{d}{dz}\left( \frac{1}{z}\right) =-\frac{1}{z^{2}}
$$
para \(z\neq 0\). Obtenha a mesma derivada usando
$$
\frac{d}{dz}\left( \frac{1}{z}\right) =\frac{\partial }{\partial x}\left(
\frac{1}{z}\right)
$$
na região onde \(f\) é analítica.
4. Calcule as derivadas de
$$
\begin{array}{ll}
\text{a)}\ f\left( z\right) =z^{5}+3iz^{2}-1\ \ \ \ \ & \text{b)
}\ f\left( z\right) =\left( z^{2}-1\right) ^{2}\left( iz+1\right) ^{3} \\
\text{c)}\ f\left( z\right) =\frac{z-1}{z-i} & \text{d)}\ f\left(
z\right) =ze^{iz}
\end{array}
$$
5. Mostre por indução que \(\left( z^{n}\right) ^{\prime }=nz^{n-1}\) para todo \(n\) inteiro positivo.
6. Verifique se são analíticas e, em caso afirmativo, em que região são analíticas e quais as derivadas das funções:
$$
\begin{array}{lll}
\text{a)}\;\;w=z^{3} & \text{b)}\;\;w=e^{y+ix} & \text{c)}\;\;w=\bar{z} \\
\text{d)}\;\;w=\sqrt{z} & \text{e)}\;\;w=e^{-z} & \text{f)}\;\;w=x+iy\; \text{ a identidade.}
\end{array}
$$
7. Dadas as funções
$$
\text{(a)}\;\; w=z^{2}\;\; \text{(b)}\;\; w=\frac{1}{z}
$$
faça os gráficos das famílias de curvas \(\ u\left( x,y\right)=c_{1}\) e\ \(v\left( x,y\right) =c_{2}\) e verifique se elas se cruzam ortogonalmente.
Outras funções importantes
<h3Logaritmo
Embora já tenhamos usado o logaritmo em um exercício para mostrar que é uma função analítica em \(\mathbb{C}\) será útil fazermos um estudo mais completo desta função. Como uma revisão nos lembraremos de que o logaritmo natural ou neperiano pode ser definido como a área sob a curva do hipérbole \(y=1/t\), como ilustrado na figura.

Como consequência temos as propriedades:
ii) a função está definida para \(x>0\) real, \(\ln 1=0 \text{ e } \ln e=1\),
iii) \(\ln \left( ab\right) =\ln a+\ln b\), \(\ln \left( a/b\right) =\ln a-\ln b\),
iv) \(\ln a^{n}=n\ln a\).
Além disto valem os limites
\(\lim_{x\rightarrow 0}\ln x=-\infty ,\ \lim_{x\rightarrow \infty }\ln x=\infty.\)
Uma das motivações que levaram ao estudo dos números complexos foi exatamente a necessidade de se atribuir algum sentido ao logaritmo de números negativos, que não está definido para os reais. Como veremos a extensão desta função para os complexos está definida em \(\mathbb{C}-\left\{ 0\right\}\). Esta extensão é obtida de modo muito natural escrevendo-se
$$
\ln z=\ln re^{i\theta }=\ln r+\ln e^{i\theta }=\ln r+i\theta ,
$$
lembrando que a parte real está bem definida se \(z\neq 0\) pois, neste caso, \(r=\left\vert z\right\vert >0\). Se \(z\) é real então \(\theta =0\) e \(\ln z=\ln r\) e o logaritmo coincide com a função real. Com esta definição podemos dar um sentido ao logaritmo de um número negativo. Um exemplo disto é a célebre identidade escrita por Euler “associando os 4 números mais importantes”,
$$
e^{i\pi }=-1\Rightarrow \ln \left( -1\right) =i\pi .
$$
Observe, no entanto, que definida desta forma a função tem um problema. Ela é uma função “multivalente” , isto é, o mesmo ponto \(z\) pode corresponder a diversos pontos na imagem, o que não é compatível com a definição usual de uma função. Isto ocorre por uma ambiguidade na forma de se expressar o ponto \(z\), no domínio da função. Um ponto pode ser escrito como
$$
z=re^{i\theta }=re^{i\left( \theta +2k\pi \right) },\ k=0,~\pm 1,~\pm 2,…
$$
que pode ser levado em diversos pontos da imagem,
$$
\ln z=\ln re^{i\left( \theta +2k\pi \right) }=\ln r+i\left( \theta +2k\pi
\right) ,\ k\in \mathbb{Z}.
$$
Para torná-la uma função “univalente” podemos proceder da seguinte forma: para qualquer valor do argumento \(\theta\) em \(z=re^{i\theta }=re^{i\left( \theta+2k\pi \right) }\) tomamos \(\theta _{0}\) como o valor do argumento no intervalo \(\left[ 0,~2\pi \right)\). Então
$$
\theta _{0}=\theta +2k\pi ,\ k\in \mathbb{Z}
$$
e definimos o ramo principal (ou determinação) do \(\ln\) como \(\ln \theta =\ln \theta _{0}\). Se restringirmos \(\arg \left( z\right)\) aos intervalos
$$
2k\pi \leq \theta \lt 2\left( k+1\right) \pi ,\ k\in \mathbb{Z}
$$
teremos para cada valor de \(k\) um ramo do \(\ln\), ou seja
$$
\ln _{k}z=\ln r+i\theta .
$$
O logaritmo fica, desta forma, univocamente determinado se informarmos o ramo que está sendo usado. Os pontos \(\theta =0\) representam uma reta de corte em \(\mathbb{C}\), representada na figura (a) e são chamados pontos de ramificação. Pode ser interessante, dependendo da aplicação, estabelecer outra reta de corte definindo ramos diferentes para o \(\ln\). Podemos tomar
$$
\alpha \leq \theta \lt \alpha +2 \pi \;\;\text{ ou }\;\; \alpha \lt \theta \leq \alpha +2\pi,
$$
como representado na figura (b). Ao tomar estas restrições dizemos que \(\mathbb{C}\) foi cortado ao longo de \(z=re^{i\alpha }\).

Como já visto o logaritmo é analítico em \(z\neq 0\) no ramo principal, conclusão que pode ser ampliada para qualquer ramo. Por outro lado, usando a regra da cadeia, obtemos sua derivada,
$$
\frac{d}{dz}\ln \left( z\right) =\frac{\partial }{\partial x}\ln \left(z\right) =\frac{\partial }{\partial x}\left( \ln r+i\theta \right)
=\left(\frac{\partial r}{\partial x}\frac{\partial }{\partial r}+\frac{\partial\theta }{\partial x}\frac{\partial }{\partial \theta }\right)
\left( \ln r+i\theta \right),
$$
e as derivadas \(r_x=\cos \theta,\;\; r_y=-\text{sen }\theta /r\)
$$
\frac{d}{dz}\ln \left( z\right) =\left( \frac{\partial r}{\partial x}\frac{\partial }{\partial r}+\frac{\partial \theta }{\partial x}\frac{\partial }{\partial \theta }\right) \left( \ln r+i\theta \right) =\left( \frac{1}{r}\frac{\partial r}{\partial x}+i\frac{\partial \theta }{\partial x}\right) =
$$
$$
=\frac{\cos \theta }{r}-i\frac{\text{sen }\theta }{r}=\frac{e^{-i\theta }}{r}=\frac{1}{re^{i\theta }}=\frac{1}{z}.
$$
Um maneira prática de se visualizar o efeito da função logaritmo, e de outras funções igualmente, é encará-la como uma transformação entre pontos de \(\mathbb{C}\). Na tabela seguinte estão listados alguns conjuntos de pontos no domínio e sua imagem pelo logaritmo.
$$
\begin{array}{lll}
\text{Imagem } & z & \text{Domínio, } f\left( z\right) \\
\text{ponto } & z=0 & \ln 0=1 \\
\text{ponto } & z=i & \ln \left( i\right) =i\pi /2 \\
\text{reta } & \theta = cte. & v=\theta \left( \text{reta}\right) \\
\text{círculo } & r=1 & u=0\; \text{ (reta)} \\
\text{círculo } & r \gt 1 & u= \text{ cte. positivo (reta.)}
\end{array}
$$
Cada ramo tem como imagem uma faixa no plano \(w\), satisfazendo \(-\infty\lt u\lt \infty,\;\; 0\leq v \lt 2\pi\). A totalidade dos ramos cobre o plano \(w\). Observe na figura que retas \(\theta =\) cte. no plano \(z\) são levadas em \(w=\ln r+i\theta\) no plano \(w\), que são retas \(u=\) cte., enquanto circunferências \(r=\) cte. são levadas nas retas \(v=\) cte.no plano \(w\). A circunferência \(r=1\) tem como imagem a reta \(u=0\) (o eixo \(\mathcal{O}v)\) enquanto circunferências com raios menores (maiores) que 1 são levadas em retas verticais à esquerda (direita) do eixo \(\mathcal{O}v\).
Observe as funções exponencial e logaritmo são inversas mútuas: tome
$$
w=\ln _{k}z=\ln r+i\left( \theta +2k\pi \right) ,\ k=0,1,2,…
$$
Então, tomando a exponencial deste último termo temos
$$
e^{w}=e^{\ln _{k}z}=e^{\left[ \ln r+i\left( \theta +2k\pi \right) \right]
}=re^{i\left( \theta +2k\pi \right) }=re^{i\theta }=z.
$$
Por outro lado
$$
\ln _{k}\left( e^{w}\right) =\ln _{k}e^{\left[ \ln r+i\left( \theta +2k\pi\right) \right] }
=\ln _{k}\left( re^{i\theta }\right) =\left[ \ln r+i\left(\theta +2k\pi \right) \right] =w,
$$
como foi afirmado. Outras propriedades adicionais do logaritmo são:
ii) Da propriedade anterior se conclui que \(\ln \left( z^{2}\right) =2\ln z\), ou, por indução, \(\ln \left( z^{n}\right) =n\ln z\).
Funções trigonométricas e Hiperbólicas
A partir da equação de Euler e seu conjugado complexo
$$
\begin{array}{l}
e^{iy}=\cos y+i\text{sen }y \\
e^{-iy}=\cos y-i\text{sen }y
\end{array}
$$
podemos verificar que as funções trigonométricas seno e cosseno podem ser escritas como
$$\begin{array}{l}
\cos y=\frac{1}{2}\left( e^{iy}+e^{-iy}\right), \\
\text{sen }y=\frac{1}{2i}\left( e^{iy}-e^{-iy}\right),
\end{array}
$$
definidas apenas para valores reais de \(y\). Podemos extender as funções para ter validade sobre todo o plano complexo fazendo
$$
\cos z=\frac{1}{2}\left( e^{iz}+e^{-iz}\right) ,
$$
$$
\text{sen }z=\frac{1}{2i}\left( e^{iz}-e^{-iz}\right).
$$
De forma análoga definimos
$$
\text{tag}z=\frac{\text{sen }z}{\cos z},\ \text{cotg}z=\frac{\cos z}{\text{sen }z},\ \sec z=\frac{1}{\cos z},\ \csc z=\frac{1}{\text{sen }z},
$$
respectivamente a tangente, cotangente, secante e cossecante. As derivadas das funções continuam formalmente iguais as derivadas no eixo real:
$$
\left( \text{sen }z\right) ^{\prime }=\cos z,\ \left( \cos z\right)^{\prime }=-\text{sen }z,
$$
como pode ser facilmente verificado derivando-se as expressões em (3). Da mesma forma se verifica que
$$
\begin{array}{l}
\text{sen }\left( -z\right) =-\text{sen }z,\ \ \cos \left( -z\right) =\cos z, \\
\text{sen }^{2}z+\cos ^{2}z=1, \\
\text{sen }\left( z_{1}+z_{2}\right) =\text{sen }z_{1}\cos z_{2}+\cos z_{1}\text{sen }z_{2}, \\
\cos \left( z_{1}+z_{2}\right) =\cos z_{1}\cos z_{2}-\text{sen }z_{1}\text{sen }z_{2}, \\
\text{sen }z=\cos \left( \frac{\pi }{2}-z\right) ;\ \ \cos z=\text{sen }\left( \frac{\pi }{2}-z\right).
\end{array}
$$
As funções hiperbólicas são extendidas para o plano complexo através das definições:
$$
\text{senh}z=\frac{1}{2}\left( e^{z}-e^{-z}\right) ,
$$
$$
\cosh z=\frac{1}{2}\left( e^{z}+e^{-z}\right).
$$
Com estas definições valem
$$
\left( \text{senh }z\right) ^{\prime }=\cosh z;\ \ \left( \cosh z\right) ^{\prime }=\text{senh}z.
$$
Exercícios :
1. Mostre que \(\ln \left( -1\right) =\left( 2k+1\right) \pi i\) e \(\ln \left(i\right) =\left( \frac{4k+1}{2}\right) \pi i,~k=0,\pm 1,\pm 2,…\).
2. Mostre que, se \(x\neq 0\),
$$
\ln \left( x+iy\right) =\frac{1}{2}\ln \left( x^{2}+y^{2}\right) +i\left(
\theta _{0}+2k\pi \right) ,
$$
onde \(\theta _{0}\) é uma das determinações de \(\text{arctg}\left( y/x\right)\).
3. Determine as raízes de
$$
\begin{array}{lll}
\text{(a)}\ e^{z}=-1, & & \text{(b)}\ e^{2z}=-e, \\
\text{(c)}\ e^{z}=-\sqrt{3}+3i, & & \text{(d)}\ \ln z=\pi i/2, \\
\text{(e)}\ e^{z}+6e^{-z}=5, & & \text{(f)}\ e^{3z-4}=-1.
\end{array}
$$
4. Mostre as seguintes relações:
$$
\begin{array}{lll}
\text{(a)}\ \left( \text{sen }z\right) ^{\prime }=\cos z, & \text{(b)}\
\left( \cos z\right) ^{\prime }=-\text{sen }z, & \text{(c)}\ \text{sen }^{2}z+\cos ^{2}z=1, \\
\text{(d)}\ \left( \text{senh}z\right) ^{\prime }=\cosh z, & \text{(e)}\ \left( \cosh z\right) ^{\prime }=\text{senh}z, & \text{(f)}\ \text{sen }\left( iz\right) =i\text{senh }z, \\
\text{(g)}\ \cos \left( iz\right) =\cosh z, & \text{(h)}\ \cosh ^{2}z-\text{senh}^{2}z=1, & \text{(i)}\ \text{senh}\left( z+i\pi \right) =-
\text{senh}z, \\
\text{(j)}\ \cosh \left( z+i\pi \right) =-\cosh z, & \text{(k)}\;\; \cos \left(x+iy\right) =\cos x\cosh y-i\text{sen }x\text{ senh }y.&
\end{array}
$$



 Representamos graficamente as raízes obtidas nos dois exercícios na figura.
Representamos graficamente as raízes obtidas nos dois exercícios na figura.





 Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.
Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.