Testes lógicos e Laços
As linhas de código em um programa são executadas de cima para baixo, na ordem em que aparecem. Muitas tarefas podem ser executadas com esse esquema de coisas. No entanto a funcionalidade do código fica muito aumentada quando se insere os testes lógicos e laços que permitem a ramificação do fluxo de código sob certas condições.
if, elif, else
É possível alterar a ordem de execução de um programa usando testes e laços (loops). Para ver isso usaremos o comando input() que abre um caixa de interação com o usuário para ler um input de teclado. Em seguida um teste é realizado com a valor digitado pelo usuário, transformado em um inteiro, e ocorre uma ramificação na execução do código dependendo do valor inserido.
» i = int(input('Digite um número: '))
» if i > 10:
» print(i, 'é maior que 10.')
» else:
» print(i, 'não é maior que 10!')
↳ Digite um número: 6
↳ 6 não é maior que 10!
↳ Digite um número: 12
↳ 12 é maior que 10.
A sintaxe completa do teste lógico é:

if bool_1:
execute_1
elif bool_2:
execute_2
... outros elifs, se necessário
else:
execute_3
Note que bool_1 e bool_2 devem ser valores booleanos (True ou False) ou expressões que são avaliadas como booleanos. As linhas execute_1 (2 ou 3) são quaisquer comandos ou sequência de comandos. Se bool_1 for True o código em execute_1 é executado e o teste é abandonado (nenhuma das demais linhas são executadas). Se bool_2 (após elif) for True o código em execute_2 é executado. Se nenhum dos testes resultar em True o código depois de else é executado. Tanto elif quanto else são opcionais.
No Python os blocos de código são definidos por indentação (espaços ou tabs), e não por chaves {}, como é mais comum em outras linguagens de programação. É costume se usar 4 espaços, e não tabulações para marcar esse escopo. Outro exemplo:
» i = int(input('Digite um número: '))
» if i < 10:
» print(i, 'é menor que 10.')
» elif i < 20:
» resposta = str(i) + 'é maior ou igual a 10 mas menor que 20.'
» print(reposta)
» else:
» print(i, 'é maior ou igual a 20.')
↳ Digite um número: 17
↳ 17 é maior ou igual a 10 mas menor que 20!
É importante notar que apenas o primeiro teste satisfeito é executado No caso, como o número digitado foi i = 17 o segundo teste foi satisfeito e as demais linhas ignoradas.
O operador ternário também é útil para gerar código sintético e de fácil leitura. Ele tem a seguinte sintaxe:
valor_1 if teste else valor_2. Ele retorna valor_1 se teste for verdadeira, valor_1 se falsa.
# operador ternário » i = 3 » texto = 'MAIOR que 5' if i > 5 else 'MENOR ou IGUAL a 5' » print(texto) ↳ MENOR ou IGUAL a 5
O mesmo teste admite outra sintaxe que é menos usada mas aparece em alguns códigos. Ela pode ajudar a tornar mais legível o código, dependendo da situação. Ela tem a seguinte forma:
(valor_0, valor_1)[teste], retornando valor_1 se teste == True ou valor_0 se teste == False.
» for i in range(5):
» txt = str(i) + ' é ' + ('impar', 'par')[i % 2 == 0]
» print(txt)
↳ 0 é par
↳ 1 é impar
↳ 2 é par
↳ 3 é impar
↳ 4 é par
No código acima o método str() transforma a variável de inteiro em texto para que possa ser concatenada com outras strings. O teste verifica se o resto da divisão de i por 2 é zero, ou seja, se i é par ou não.
Observe que o resultado acima é apenas uma aplicação do seguinte fato: True é avaliado como 1, False como 0.
» lista = ['valor_1','valor_2','outros_valores'] » print(lista[0], lista[1]) ↳ valor_1 valor_2 » print(lista[False], lista[True]) ↳ valor_1 valor_2
O teste pode ser aninhado. No entanto, se o código ficar muito muito complexo ou difícil de ler, pode ser mais simples quebrar a operação em partes mais simples.
» for i in range(5,11):
» txt = str(i) + (' é par', (' não é múltiplo de 3',' é múltiplo de 3')[i%3==0] )[i%2==1]
» print(txt)
↳ 5 não é múltiplo de 3
↳ 6 é par
↳ 7 não é múltiplo de 3
↳ 8 é par
↳ 9 é múltiplo de 3
↳ 10 é par
# se não for par é retornado ('não é múltiplo de 3','é múltiplo de 3')[i%3==0]
Testes lógicos compostos podem ser implementados com o uso dos operadores lógicos and, or e not:

» x = 'oup'
» if x in 'Guarda' or x in 'roupas':
» print('ok!')
↳ ok!
Intervalos podem ser testados de uma única vez. Por exemplo a < x ≤ b retorna True se x está no intervalo (a, b] (que exclui a e inclui b).
» for i in range(1, 8): » if 0 < i ≤ 3: » print(i, 'pertence [1, 3]') » elif 3 < i ≤ 6: » print(i, 'pertence [4, 6]') » else: » print(i, ' acima de 6') ↳ 1 pertence [1, 3] ↳ 2 pertence [1, 3] ↳ 3 pertence [1, 3] ↳ 4 pertence [4, 6] ↳ 5 pertence [4, 6] ↳ 6 pertence [4, 6] ↳ 7 acima de 6
Dicionários e decisões
Quando existem muitos testes no código, principalmente quando valores individuais são verificados (em oposição à intervalos), pode ser uma boa técnica usar um dicionário como seletor de valores. Esse dicionário deverá conter os valores de testes nas chaves e retornos nos valores.
» # ao invés de fazer 10 testes
» for i in range(11):
» if i==0:
» print('zero')
» elif i==1:
» print('um')
» elif i==2:
» print('dois')
» # ... etc ... (truncado)
» # podemos fazer
» num_texto = {0:'zero', 1:'um', 2:'dois',3:'três', 4:'quatro',
» 5:'cinco',6:'seis',7:'sete',8:'oito',9:'nove'}
» for i in range(11):
» print(i, num_texto.get(i,'não encontrado!'))
↳ 0 zero
↳ 1 um
↳ 2 dois
↳ 3 três
↳ 4 quatro
↳ 5 cinco
↳ 6 seis
↳ 7 sete
↳ 8 oito
↳ 9 nove
↳ 10 não encontrado!
Lembrando: O método de dicionário num_texto.get(i, default) procura pela chave i e retorna o valor correspondente. Se a chave não for econtrada o valor default é retornado.
Além disso um dicionário pode conter, em suas chaves, funções. Isso significa que podemos selecionar entre diversas funções sem usar seletores if.
# bloco 1
» dicio = {1: lambda x: x**2, 2: lambda x: x**3+4}
» print(dicio[1](3))
» print(dicio[2](3))
↳ 9
↳ 31
# bloco 2
» import math as m
» dicio2 = {1: m.sin, 2: m.exp}
» print(dicio2[1](3))
» print(dicio2[2](3))
↳ 0.1411200080598672
↳ 20.085536923187668
# bloco 3
» dicio = {'a': 'print("estou em a")', 'b': 'print("estou em b")'}
» eval(dicio['a'])
» eval(dicio['b'])
↳ estou em a
↳ estou em b
| No bloco 1 o dicionário retorna funções anônimas (lambda): |
|---|
dicio[1](3) é o mesmo que (lambda x: x**2)(3) = 3**2 =9. |
No bloco 2 o dicionário retorna funções do módulo importado math: |
dicio2[1](3) é o mesmo que math.sin(3) = 0.141... |
No bloco 3 o dicionário retorna um texto que pode ser executado com eval: |
dicio['a'] = 'print("estou em a")', |
uma string, que quando executada como comando, imprime estou em a. |
O código lambda x: x**2 corresponde à função matemática \( x \mapsto x^2\). As funções anônimas (lambda) serão vistas mais tarde nessas notas [ funções lambda].
Laços for e while

Outra estrutura útil de controle do fluxo de execução do código são os laços for. Eles servem para percorrer valores dentro de um objeto iterável.
# dentro do loop letra = P, y, t, h, o, n, sucessivamente
» for letra in 'Python':
» if letra == 'y':
» print('Chegamos na letra y')
↳ Chegamos na letra y
A variável letra assume os valores P, y, t, h, o, n sucessivamente mas apenas quando a letra é y uma mensagem é impressa. Observe os oito espaços abaixo do teste if para representar uma dupla indentação.
É comum que uma operação tenha que ser repetida um determinado número de vezes. Isso pode ser feito criando um objeto iterável e percorrendo seus valores.
# primeiro percorremos uma tupla » for t in (1,3,5,7,9): » print(t, end=', ') ↳ 1, 3, 5, 7, 9, # criamos uma 'faixa' de números (range) de 0 a 10, exclusive » for t in range(10): » print(t, end=', ') ↳ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
Nos dois casos acima usamos o parâmetro end para a função print para que ela não insira uma quebra de linha após cada impressão, que é o comportamento default. Podemos usar a instrução else para inserir código a ser executado no final do loop.
» alunos = ['Martha', 'Renato', 'Paula']
» for aluno in alunos:
» print(aluno, end=", ")
» else:
» print("\b\b.\nTodos os nomes foram listados!")
↳ Martha, Renato, Paula.
↳ Todos os nomes foram listados!
A instrução print("\b\b.\nTodos...") faz o retrocesso de dois caracteres, substitui a vírgula final por um ponto e pula para a proxima linha, antes de imprimir Todos….

Instruções break, continue e pass são usadas dentro de laços para alterar o fluxo de execução. break interrompe o laço, continue instrui pela continuação do laço e passserve apenas para marcar uma posição nas linhas de código, sem executar nenhuma tarefa. No exemplo abaixo o laço for percorre números de 0 até 99. O laço é abandonado quando num = 50.
» for num in range(100): » if num < 50: » continue » else: » break » print(num) ↳ 50
Também são permitidos laços while que executam operações enquanto uma condição for verdadeira. No exemplo abaixo inicializamos a variável i = 1 e percorremos o laço enquanto i < 10. Dentro do laço a variável é impressa e incrementada de 1. O caracter especial “\n” serve para que uma quebra de linha seja inserida.
» i = 1
» while i < 10:
» print(i, end=' ')
» i += 1
» print('\nFim do loop. i =', i)
↳ 1 2 3 4 5 6 7 8 9
↳ Fim do loop. i = 10
Não é raro criarmos um laço infinito a ser abandonado sob condição dada.
» num = 0
» while True:
» num +=1
» if num == 50:
» print('cinquenta')
» if num >= 100:
» break
» print(num)
↳ cinquenta
↳ 100
Advertência importante: Sempre que se usa laços deve-se ter certeza de que o laço termina após um número finito de iterações. Caso contrário a execução do código entra em um loop infinito que pode exigir uma interrupção forçada. Por exemplo, o código abaixo entra em um loop infinito pois a variável t, dentro do loop, nunca assume o valor t=5, que é a condição de saída do laço.

» t = 0
» while t ! = 5:
» t +=2
» print(t, end='-')
↳ 2-4-6-8-10
# execução interrompida pelo usuário
Para interromper esse loop você pode apertar CTRL-C se estiver em sessão interativa do Python. No Jupyter Notebook aperte ■ na barra de ferramentas ou I-I com o cursor no modo de controle da célula.
Funções

Uma outra alternativa para alterar o fluxo de execução do código são as funções. Sempre que um bloco de código (um conjunto de operações) deve ser executado várias vezes esse bloco pode ser colocado dentro de uma função. As funções podem ser muito úteis para reaproveitamente do código dentro do módulo em que se está trabalhando ou mesmo em outros módulos diferentes. Funções são criadas e executadas da seguinte forma:
# definição » def nome_da_funcao(argumentos): » operações # usando os argumentos » return valor # para usar essa função » nome_da_funcao(argumentos)
Nessa definição argumentos são um ou diversos objetos de quaisquer tipo que contém as informações que serão usadas no corpo da função. As operações podem conter instruções de qualquer tipo, tais como a impressão de texto, de leitura ou gravação de arquivos, ou o cálculo de valor a ser retornado pela função. A instrução return é opcional: se ela não for incluída a função retorna None.
» def minha_funcao(numero1, numero2): » resultado = numero1 ** numero2 » return resultado # para calcular 23 » minha_funcao(2,3) ↳ 8 # a chamada à função pode ser usada dentro de um cálculo » minha_funcao(2,10) - 24 ↳ 1000

Na figura ilustramos as partes de uma função. Parâmetros são as variáveis definidas e usadas no corpo da função. Os valores passados como parâmetros são os argumentos. No caso do uso da raiz quadrada seria necessária a importação da biblioteca math, na forma de from math import sqrt antes do uso.
Os argumentos (passados como parâmetros) das funções podem ter um valor default. Os parâmetros com valor default devem sempre ser inseridos por último, na definição da função.
» def outra_funcao(numero1, numero2 = 3): » return numero1 ** numero2 # se numero2 for omitida ela assume o valor default » outra_funcao(6,) # 63 ↳ 216 # se numero2 for fornecida o valor default é sobrescrito » outra_funcao(6,2) # 62 ↳ 36
Parâmetros podem ser usados como palavras chaves (keywords). Nesse caso eles podem aparecer em qualquer ordem, desde que nomeados durante a chamada à função.
» def funcao(a, b): » return 10 * a + b # chamando a função sem usar palavras chaves » funcao(10, 5) ↳ 105 # usando as palavras chaves » funcao(b = 2, a = 11) ↳ 112
Finalmente, se pode passar um número arbitrário de argumentos passando um objeto iterável para a função. Isso é útil quando se escreve uma função que deve agir sobre um número desconhecido de argumentos. Isso é feito colocando-se um asterisco (*) antes do parâmetro.
» def somar(*numeros): » soma = 0 » for num in numeros: » soma += num » return soma # exemplo de uso » somar(1,34,67,23,876) ↳ 1001
Recursividade
Função fatorial: para consolidar o conceito de função vamos considerar o exemplo de uma função para calcular o fatorial de um número inteiro. Por definição o fatorial de n é
$$
n! = \bigg\{ \begin{array}{lr}
1, & \text{ se n = 0,}\\
1 \times 2 \times 3 \times \cdots \times n, & \text{ se n > 0.}\\
\end{array}
$$
» def fatorial(n): » fat = 1 » while n > 1: » fat *= n » n -= 1 » return fat » fatorial(11) ↳ 39916800
Lembrando, n -= 1 é o mesmo que n = n - 1 e fat *= n é fat = fat * n. O loop while só é executado se n = 2 ou maior. Dentro do loop a variável é decrementada de 1 e o produto armazenado em fat.
Uma definição mais elegante pode ser obtida usando recursividade. A função pode fazer uma chamada a si mesma.
» def fatorial_recursivo(n): » if n ≤ 1: » return 1 » else: » return n * fatorial_recursivo(n-1) » fatorial_recursivo(3) ↳ 6
A mesma função pode ser definida de forma ainda mais compacta usando-se a estrutura valor1 if teste_booleano else valor2.
» def fatorial(n): » return 1 if n <=1 else n * fatorial(n-1) » print(fatorial(10)) ↳ 3628800
No entanto, é muito comum que uma função de muito uso já esteja incluída em alguma biblioteca do Python, como é o caso da função fatorial que está na biblioteca math. Para usar um recurso que está em uma biblioteca externa ao núcleo básico do Python usamos import.
» import math » math.factorial(11) ↳ 39916800
A série de Fibonacci é outro exemplo interessante. Essa é uma série de inteiros com muitas aplicações práticas. Ela é definida da seguinte forma: denotando o n-ésimo termo da série por \(f_n \) temos
$$f_0=1, f_1=1, f_n = f_{n-1} + f_{n-2} \text{ para } n \geq 2.$$

Portanto, cada número da série, à partir de n = 2 é a soma dos dois números anteriores. Por ex,: \(f_4 = f_3 + f_2 \).
Para calcular digamos, \(f_{10}\) podemos calcular todos os elementos da série até obter \(f_8\) e \(f_9\) e calcular sua soma. Alternativamente podemos definir uma soma recursiva.
» def fibonacci(n):
» """ retorna o n-ésimo termo da série de Fibonacci """
»
» if n in (0, 1):
» return 1
» else:
» return fibonacci(n-1) + fibonacci(n-2)
» # para imprimir a série até um inteiro n
» def printFibonacci(n):
» txt = ''
» for t in range(n):
» txt += '%d, ' % fibonacci(t)
» print('Série de Fibonacci: { %s...}' % txt)
» printFibonacci(10)
↳ Série de Fibonacci: { 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, ...}
Essa função também calcula todos os elementos anteriores recursivamente, até chegar em n=0 e n=1, o que termina a recursão, mas de um modo elegante e de fácil leitura. Esses procedimentos podem envolver grande quantidade de cálculo e memória. Tanto na série de Fibonacci quanto no calculo do fatorial um valor muito grande para argumento das funções pode travar o processador por falta de memória.
Observe que, da forma como esta função foi escrita para obter a série de Fibonacci, para calcular o n-ésimo termo é necessário calcular todos os termos anteriores. Uma forma forma mais rápida e eficiente pode ser obtida da seguinte forma:
» # para calcular os 10 primeiros termos da série de Fibonacci, retornando uma lista » quantosTermos=10 » a, b = 0, 1 » fib = [] » for t in range(quantosTermos): » fib.append(b) » a, b = b, a+b » print(fib) ↳ [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
Nesse código usamos a função range(n) que retorna um objeto iterável (que pode ser percorrido um a um), de 0 até n-1. fib = [] inicializa uma lista vazia e fib.append(b) insere b nessa lista.
Gravando e importando funções
Podemos gravar em disco as funções e recuperá-las para uso no código. Suponha que gravamos o seguinte conteúdo em um arquivo com nome primo.py.
# arquivo primo.py
def primo(n):
"""
recebe um inteiro n
retorna True se n é primo, caso contrário False
"""
if n==0: return False # uma condição especial para retornar 0, não primo
primo = True
for i in range(2, n//2):
if (n % i) == 0:
primo = False # n é divisivel por i
break
return primo
No código acima procuramos por divisores de n de 2 até n//2 (metade inteira de n). Depois de gravado ele pode ser lido com import primo (o que importa todo o conteúdo do arquivo ou módulo) ou from primo import primo, que importa a função específica primo(). Depois podemos usá-la no codigo, com por ex.:
» from primo import primo
» while True:
» n = int(input("Digite um número (0 para terminar)"))
» if n==0: break
» print(n, 'é primo' if primo(n) else 'não é primo')
Esse código inicia um laço que só termina quando o usuário digita 0. Se não for 0 ele testa se número é primo usando a função importa, e emite uma mensagem.
Digamos que digitamos 4 e 5:
Digite um número (0 para terminar) 4 4 não é primo Digite um número (0 para terminar) 5 5 é primo
Docstrings
No Python você pode, e deve, inserir strings de documentação (docstrings) em suas funções para informar o que ela faz, que parâmetros recebe e que tipo dado ela retorna. Essa documentação pode ser consultada no momento em que se pretende usar a função. Docstrings também são inseridos em módulos, classes e métodos do Python.
A documentação de um objeto é definida inserindo-se uma string na primeira linha de sua definição, como um comentário.
def uma_funcao(parametros):
''' Essa função recebe parâmetros tal e tal; e retorna qual
'''
< corpo de função >
return qual
Docstrings podem ser visualizadas com a propriedade __doc__ do objeto.
» def quadrado(n): » '''Recebe um número n, retorna n ao quadrado.''' » return n**2 » print(quadrado.__doc__) ↳ Recebe um número n, retorna n ao quadrado
Por convenção docstrings devem começar com uma letra maiúscula e terminar com um ponto e a primeira linha deve conter uma breve descrição da função. Caso existam mais de uma linha a segunda deve ficar em branco, separando o resumo do resto da descrição. As demais linhas devem descrever as convenções de chamada da função, os parâmetros e seu retorno. Ela também deve explicitar as exceções que podem ser lançadas na sua execução.
As funções pré definidas no python, assim como as importadas, podem igualmente ter suas docstrings consultadas. Docstrings também podem ser consultadas com a função help().
Abaixo um exemplo de uma docstring bem estruturada, e o uso de help.
» def soma_inteiros(i, j):
» '''
» Retorna a soma de dois inteiros.
»
» Parâmetros:
» i (int): inteiro
» j (int): inteiro
» Retorna:
» string com texto: A soma i + j = soma.
» '''
» txt = 'A soma %d + %d = %d'% (i,j,i+j)
» return txt
» soma_inteiros(45,54)
↳ 'A soma 45 + 54 = 99'
» help(soma_inteiros)
↳ Help on function soma_inteiros in module __main__:
soma_inteiros(i, j)
Retorna a soma de dois inteiros.
Parâmetros:
i (int): inteiro
j (int): inteiro
Retorna:
string com texto: A soma i + j = soma.
Além de documentar o código, doscstrings podem conter testes para as suas funções correspondentes, como veremos mais tarde.
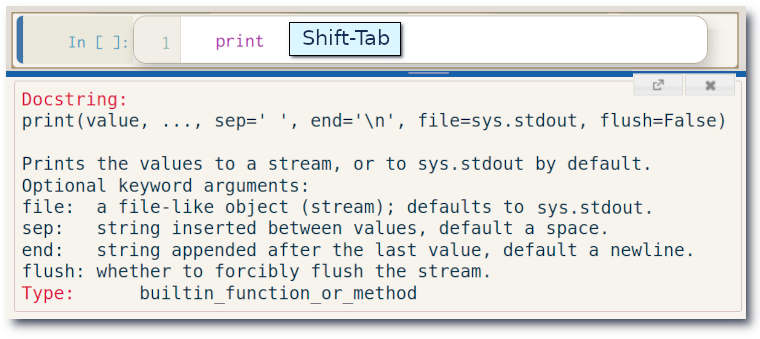
No Jupyter Notebook a doscstring é exibida pressionando-se Shift-Tab após o nome da função ou objeto, o que pode ser feito para funções internas ou aquelas criadas pelo usuário.
Gerenciando erros (exceções)
Naturalmente cometemos erros quando escrevemos código. Nesses casos o python gera uma resposta que pode nos ajudar a corrigir o problema. No python erros são denominados exceções.
Suponha que executamos o seguinte código:
» x = input('Digite um número: ')
» y = x + 10
» print('O valor de y é %d' % y)
# o usuário insere o dígito 4 e obtém a resposta
↳ x = input('Digite um número: ')
----> y = x + 10
print('O valor de y é %d' % y)
TypeError: can only concatenate str (not "int") to str

Um erro de tipo foi lançado, TypeError pois o resultado do comando input é uma string (um texto) mesmo que o usuário tenha digitado ‘4’. O erro ocorreu na linha que tenta somar uma string a um número. Vemos que a resposta a um erro é útil e informa onde ele ocorreu. Muitas vezes são dadas sugestões de possíveis reformas ou até mesmo indicações para os manuais. No caso acima esse erro poderia ser resolvido com a inserção da conversão x = int(input('Digite um número: ')) que converteria a string ‘4’ em um dígito 4. Mas, o problema não estaria resolvido se o usuário resolver digitar ‘a’, por exemplo.
# a string 'a' não pode ser convertida em um inteiro
» int('a')
↳ ValueError: invalid literal for int() with base 10: 'a'
Esse tipo de problema pode ser contornado com as cláusulas try, except, else, finally. Coloque o comando onde um erro pode ocorrer dentro de uma cláusula try.
» saida = ''
» x = input('Digite um número: ')
» try:
» x = int(x)
» except:
» saida = 'Ocorreu um erro.Digite um número, não letra.'
» else:
» y = x + 10
» saida = 'O valor da soma é %d' % y
» finally:
» print(saida)
Havendo erro o fluxo de execução é transferido para except, caso contrário para else. Em qualquer dos casos o código após finally é executado.
# o usuário digita 4: ↳ Digite um número: 4 ↳ O valor da soma é 14 # o usuário digita a: ↳ Digite um número: a ↳ Ocorreu um erro.Digite um número, não letra.
Existem muitos erros de execução pré-definidos no python. Suponha que exista uma função previamente definida, onde erros de alguns tipos podem ocorrer:
» try:
» execute_alguma_coisa()
» except SyntaxError:
» print('Ocorreu um erro de sintaxe')
» except TypeError:
» print('Erro de tipo de variável!')
» except ValueError:
» print('Um erro de valor!')
» except ZeroDivisionError:
» print('Não é permitido dividir por zero!')
» else:
» print('Relaxa, nada errado aconteceu!')
» finally:
» print('Chegamos ao final...')
Erros podem ser lançados a força pelo programador, para fins de depuração ou outro motivo qualquer.
» raise MemoryError("Acabou a memória")
↳ MemoryError: Acabou a memória
» raise ValueError("Erro de valor")
↳ ValueError: Erro de valor
Continue a leitura: Sequências e Coleções.
Bibliografia
Consulte a bibliografia no final do primeiro artigo dessa série.

 Vimos, nos exemplos acima, que uma fatia (ou slice) palavra[i:f] se inicia em i e termina em f, exclusive. Os índices, e todas as contagens em python, se iniciam em 0. A posição final não é incluida de forma que
Vimos, nos exemplos acima, que uma fatia (ou slice) palavra[i:f] se inicia em i e termina em f, exclusive. Os índices, e todas as contagens em python, se iniciam em 0. A posição final não é incluida de forma que 


 Python é uma linguagem de programação de alto nível, interpretada e de propósito geral, criada por Guido van Rossum em 1985 e em franco desenvolvimento desde então. Ela está disponível sob a licença GPL (GNU General Public License). Ela permite o uso interativo, com o usuário digitando as linhas de código e obtendo o resultado imediatamente, ou através de lotes (batches), com as linhas de código armazenadas em arquivos e executadas em grupo. Apesar de ser chamada de linguagem de script é possível criar aplicativos completos, na web ou para desktop, com interfaces gráficas modernas e eficientes. Além disso existe a possibilidade de gerar arquivos compilados e executáveis usando
Python é uma linguagem de programação de alto nível, interpretada e de propósito geral, criada por Guido van Rossum em 1985 e em franco desenvolvimento desde então. Ela está disponível sob a licença GPL (GNU General Public License). Ela permite o uso interativo, com o usuário digitando as linhas de código e obtendo o resultado imediatamente, ou através de lotes (batches), com as linhas de código armazenadas em arquivos e executadas em grupo. Apesar de ser chamada de linguagem de script é possível criar aplicativos completos, na web ou para desktop, com interfaces gráficas modernas e eficientes. Além disso existe a possibilidade de gerar arquivos compilados e executáveis usando 





















 Nas consultas
Nas consultas 
 Dados ausentes são representados por
Dados ausentes são representados por 

 No SQL tabelas podem ser juntadas ou agrupadas através da cláusula
No SQL tabelas podem ser juntadas ou agrupadas através da cláusula 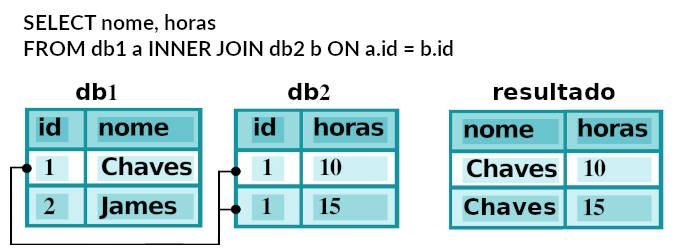

 Existem muitas formas de se excluir linhas de um dataframe mas é comum a prática de selecionar as linhas que devem ser mantidas e copiar para um novo dataframe.
Existem muitas formas de se excluir linhas de um dataframe mas é comum a prática de selecionar as linhas que devem ser mantidas e copiar para um novo dataframe.