
Pandas.Series

O que é pandas?
Pandas é uma biblioteca do Python, de código aberto e com licença BSD, desenvolvida e mantida pelo PуDаtа Dеvеlорmеnt Tеаm. Ela fornece ferramentas de manipulação e análise estatística de dados, capacidade de exibição gráfica E extração de dados análogos (mas não idênticos) aos de consultas sql.
A biblioteca foi construída com Cython e, por isso, é bastante rápida. Ela se destinava inicialmente ao uso no setor financeiro para análise de séries temporiais, tendo se tornado uma ferramenta de uso comum na manipulação de dados, particularmente em data science e machine learning. Ela tem sido usada para substituir as planilhas do Excel, para processar dados sob forma tabular, importando com facilidade dados de arquivos csv ou json.
Os experimentos abaixo foram realizados no Jupyter Notebook. Você encontra nesse site um artigo sobre instalação e uso do Jupyter Notebook. As linhas de código e suas respostas, quando existirem, serão representadas da seguinte forma:
» # Comentários (não são lidos ou executados pelo interpretador)
» Linha de input (entrada de comandos)
↳ Linha de output (resposta do código)
NumPy e matplotlib
NumPy é a abreviação de Numerical Python, a biblioteca base da computação numérica em Python. Ela fornece as estruturas de dados e algoritmos necessários para a maioria das aplicações científicas e de engenharia utilizando cálculo numérico. Entre outros objetos NumPy NumPy fornece
- o objeto multidimensional
ndarray onde se pode aplicar operações vetorializadas rápidas e eficientes,
- um conjunto de funções para cálculos elementares com vetores e matrizes,
- ferramentas de leitura e gravação de dados,
- operações da álgebra linear, transformada de Fourier e geração de números aleatórios,
- interação com
C e C++.

Para dados numéricos as matrizes do NumPy são armazenadas e manipuladas de modo mais eficiente do que as demais estruturas do Python. Além disso códigos escritos em linguagens de baixo nível, como C ou Fortran, podem operar diretamente nos dados armazenados com o NumPy. Por isso muitas ferramentas de computação numérica do Python usam as matrizes NumPy como um estrutura de dados primária.
matplotlib é a biblioteca Python mais popular usada para a produção de gráficos e visualização de dados. Ela pode ser usada na geração de gráficos estáticos ou animados e visualização interativa.
Pandas
O pandas se utiliza basicamente de 3 objetos de armazenamento de dados com as seguintes estruturas:
Estrutura de dados dos objetos do pandas:

| Nome |
dimensões |
tabela |
| Series |
1D |
coluna (vetor) |
| DataFrame |
2D |
tabela (matriz) |
| Panel |
3D |
várias tabelas (matriz multidimensional) |
As series e os dataframes são utilizados com maior frequência.
Como a manipulação de dados usando séries e dataframes frequentemente envolvem operações encontradas no módulo numpy é frequente sua importação junto com pandas.
» import pandas as pd
» import numpy as np
Series
Uma series é um objeto unidimensional, tipo um vetor, que contém uma sequência de objetos do mesmo tipo. A essa sequência está associado um outro vetor de labels chamado de index (índice). O método básico de criação de séries é da seguinte forma:
serie = pd.Series(data, index=index)
onde data pode ser um dict (um dicionário do Python), uma lista ou ndarray do numPy, ou um escalar. index é uma lista de índices que, se omitida, é preenchida com inteiros iniciando em 0.
» serie1 = pd.Series([-1, 9, 0, 2, 5])
↳ 0 -1
1 9
2 0
3 2
4 5
À esquerda estão listados os índices que, por default, são uma lista de inteiros começando por 0. Os valores podem ser listados com .values e os índices com .index.
» serie1.values
↳ array([-1, 9, 0, 2, 5])
» serie1.index
↳ RangeIndex(start=0, stop=5, step=1)
Os índices podem ser inseridos manualmente e não precisam ser inteiros. O valor correspondente ao índice i pode ser acessado com serie[i], como mostrado abaixo, onde os índices são strings.
» serie2 = pd.Series([4, 7, -5, 3], index=['a', 'b', 'c', 'd'])
» serie2
↳ a 4
b 7
c -5
d 3
dtype: int64
» serie2['c']
↳ -5
Uma série pode ser filtrada passando como índice outra série de elementos boolenos, (True, False). Além disso operações vetorializadas podem ser realizadas sobre todos os elementos da série.
# O teste seguinte gera uma série de booleanos
» serie2 > 3
↳ a True
b True
c False
d False
dtype: bool
# Essa serie de True e False filtra a serie original
» serie2[serie2 > 3]
↳ a 4
b 7
dtype: int64
# Operações podem, ser realizadas sobre todos os elementos
» serie2 * 3
↳ a 12
b 21
c -15
d 9
dtype: int64
# o módulo Numpy possui a função exponencial
» np.exp(serie2)
↳ a 54.598150
b 1096.633158
c 0.006738
d 20.085537
dtype: float64
Séries se comportam, em muitos sentidos, como um dicionário. Uma série pode ser criada passando-se um dicionário como argumento para pd.Series().
» populacao = {
'Sudeste': 89012240,
'Nordeste': 57374243,
'Sul': 30192315,
'Norte': 18672591,
'Centro-Oeste':16504303
}
» serie3 = pd.Series(populacao)
» serie3
↳ Sudeste 89012240
Nordeste 57374243
Sul 30192315
Norte 18672591
Centro-Oeste 16504303
dtype: int64

A ordem dos itens na série pode ser alterada através do fornecimento de uma lista com o ordenamento desejado para o argumento index. A elementos não presentes no dicionário serão atribuídos o valor NaN, Not a Number (não número). O método pd.isnull(serie) permite a avalição de quais elementos estão nulos ou NaN.
# fornecendo uma lista para o argumento index:
» ordem_alfabetica = ['Brasil', 'Centro-Oeste', 'Nordeste', 'Norte', 'Sudeste', 'Sul']
» serie4 = pd.Series(populacao, index=ordem_alfabetica)
» serie4
↳ Brasil NaN
Centro-Oeste 16504303
Nordeste 57374243
Norte 18672591
Sudeste 89012240
Sul 30192315
dtype: int64
# para verificar quais valores são nulos (NaN)
» pd.isnull(serie4)
↳ Brasil True
Centro-Oeste False
Nordeste False
Norte False
Sudeste False
Sul False
dtype: bool
# os seguintes registros são NaN
» serie4[pd.isnull(serie4)]
↳ Brasil NaN
dtype: float64
» serie4[pd.notnull(serie4)]
↳ Centro-Oeste 16504303.0
Nordeste 57374243.0
Norte 18672591.0
Sudeste 89012240.0
Sul 30192315.0
dtype: float64
» 'Brasil' in serie4
↳ True
» 'EUA' in serie4
↳ False
# uma excessão KeyError é lançada se o indice não existe
» serie4['EUA']
↳ KeyError
Como não existe no dicionário um valor para o índice Brasil a série atribuiu o valor NaN (Not a Number) para essa chave, a forma de NumPy e pandas indicar a ausência de um valor. O método retorna True ou False para cada item da série e pd.notnull() o seu inverso booleano. Alternativamente se pode usar o método das séries serie4.isnull().
Ainda sobre a semelhança entre séries e dicionários, podemos testar a existência de uma chave usando o operador in, como em 'Brasil' in serie4. A tentativa de recuperar um valor com índice não existente gera uma exceção (um erro do Python).
Observe que uma series tem propriedades de numpy ndarray, mas é um objeto de tipo diferente. Se um ndarray é necessário use series.to_numpy().
» type(serie4)
↳ pandas.core.series.Series
» type(serie4.to_numpy())
↳ numpy.ndarray
Series podem ser fatiadas com a notação serie[i:f] onde serão retornadas a i-ésima linha até a f-ésima, exclusive. Se i for omitido a lista se inicia em 0, se f for omitido ela termina no final da series.
» serie4
↳ Brasil NaN
Centro-Oeste 16504303.0
Nordeste 57374243.0
Norte 18672591.0
Sudeste 89012240.0
Sul 30192315.0
dtype: float64
» serie4[2:5]
↳ Nordeste 57374243.0
Norte 18672591.0
Sudeste 89012240.0
dtype: float64
» serie4[:2]
↳ Brasil NaN
Centro-Oeste 16504303.0
dtype: float64
» serie4[4:]
↳ Sudeste 89012240.0
Sul 30192315.0
dtype: float64
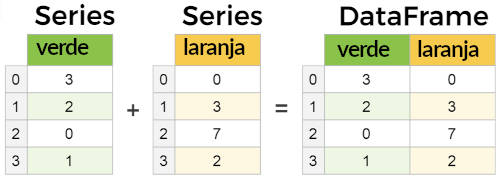
Series podem ser exibidas com o método display(serie_0, serie_1, ..., serie_n). O resultado de operações envolvendo mais de uma serie, como a soma, alinha os valores por chaves (como uma UNION). Valores não presentes em um dos operandos terá NaN como resultado.
» serie5 = pd.Series([2, -1, -2, 1], index=['a', 'b', 'c', 'd'])
» serie6 = pd.Series([3, 4, 7, -1], index=['e', 'c', 'b', 'f'])
» display(serie5, serie6)
↳ a 2
b -1
c -2
d 1
dtype: int64
↳ e 3
c 4
b 7
f -1
dtype: int64
» serie5 + serie6
↳ a NaN
b 6.0
c 2.0
d NaN
e NaN
f NaN
dtype: float64
Series possuem a propriedade name que pode ser atribuída na construção ou posteriormente com o método .rename(). No exemplo usamos o método np.random.randn(n) de numpy para fornecer um numpy.ndarray com n números aleatórios. Damos inicialmente a essa série o nome ‘randomica’, depois a renomeamos para ‘aleatoria’.
» serie7 = pd.Series(np.random.randn(5), name='randomica')
» serie7
↳ 0 -1.703662
1 1.406167
2 0.966557
3 -0.557846
4 -0.264914
Name: randomica, dtype: float64
» serie7.name
↳ 'randomica'
» serie7= serie7.rename('aleatoria')
» serie7.name
↳ 'aleatoria'
O nome de uma série se torna seu índice ou nome de coluna caso ela seja usada para formar um DataFrame.
Atributos e Métodos das Series
Os atributos e métodos mais comuns e úteis das Series estão listados abaixo. Para uma lista completa consulte pandas.Series: API Reference.
Atributos
| Atributo |
Descrição |
at[n] |
Acesso ao valor na posição n |
attrs |
Retorna ditionario de atributos globais da series |
axes |
Retorna lista de labels do eixo das linhas |
dtype |
Retorna o tipo (dtype) dos objetos armazenados |
flags |
Lista as propriedades do objeto |
hasnans |
Informa se existem NaNs |
iat[n] |
Acesso ao valor na posição n inteiro |
iloc[n] |
Acesso ao valor na posição n inteiro |
index |
Retorna lista de índices |
index[n] |
Retorna índice na n-ésima posição |
is_monotonic |
Booleano: True se valores crescem de forma monotônica |
is_monotonic_decreasing |
Booleano: True se valores decrescem de forma monotônica |
is_unique |
Booleano: True se valores na series são únicos |
loc |
Acessa linhas e colunas por labels em array booleano |
name |
O nome da Series |
nbytes |
Número de bytes nos dados armazenados |
shape |
Retorna uma tuple com forma (dimensões) dos dados |
size |
Número de elementos nos dados |
values |
Retorna series como ndarray |
Alguns casos de acessos à essas propriedades. Os outputs são exibidos como comentários:
» import pandas as pd
» import numpy as np
» serie = pd.Series([1,-1, 2, 2, 6, 63])
» serie.size # 6, o mesmo que len(serie)
» serie.at[5] # 63
» serie.iloc[0] # 1
» serie.index # RangeIndex(start=0, stop=6, step=1)
» serie.is_monotonic # False
» serie.is_unique # False
» serie.shape # (6,)
Métodos
Nas tabelas abaixo a expressão “elemento a elemento” é abreviada para “e/e”. Estas operações são repetidas a cada elemento da, ou das, séries envolvidas. Por exemplo, o método serie.add(s2) é feita “elemento a elemento” (e/e):
» import pd
» serie_a = pd.Series([-1,9,0,2, 5, -8])
» serie_b = pd.Series([1,-9,0, -2,-5, 8])
» serie_a.add(serie_b)
» # é o mesmo que
» serie_a + serie_b
» # que resulta em serie nula
» # pd.Series([0,0,0,0,0,0])
Manipulação e gerenciamento das Series
| Método (sobre série s, outra s2) |
Descrição |
s.align(s2) |
Alinha 2 objetos em seus eixos usando método especificado |
s.append(to_append[, ignore_index, …]) |
Concatena 2 ou mais Series |
s.asof(where[, subset]) |
Último elemento antes da ocorrência de NaNs após ‘where’ |
s.backfill([axis, inplace, limit, downcast]) |
Aliás para DataFrame.fillna() usando method=’bfill’ |
s.bfill([axis, inplace, limit, downcast]) |
Alias para DataFrame.fillna() usando method=’bfill’ |
s.clip([min, max, axis, inplace]) |
Inclui apenas valores no intervalo |
s.combine(s2, func[, fill_value]) |
Combina a s com s2 ou escalar, usando func |
s.copy([deep]) |
Cópia do objeto s, índices e valores |
s.drop_duplicates([keep, inplace]) |
Remove elementos duplicados de s |
s.dropna() |
Remove valores faltantes de s |
s.duplicated([keep]) |
Exibe valores duplicados na s |
s.explode([ignore_index]) |
Transforma cada elemento de um objeto tipo lista em uma linha |
s.fillna([value, method, axis, inplace, …]) |
Substitui valores NA/NaN usando método especificado |
s.get(key) |
Retorna item correspondente à key |
s.groupby([by, axis, level, as_index, sort, …]) |
Agrupa a s |
s.head([n]) |
Retorna os n primeiros valores |
s.interpolate([method, axis, limit, inplace, …]) |
Preenche valores NaN usando metodo de interpolação |
s.item() |
Primeiro elemento dos dados como escalar do Python |
s.items() |
Iteração (lazy) sobre a tupla (index, value) |
s.iteritems() |
Iteração (lazy) sobre a tupla (index, value) |
s.mask(cond[, s2, inplace, axis, level, …]) |
Substitui valores sob condição dada |
s.max([axis, skipna, level, numeric_only]) |
Valor máximo |
s.memory_usage([index, deep]) |
Memória usada pela s |
s.min([axis, skipna, level, numeric_only]) |
Menor dos valores da s |
s.nlargest([n, keep]) |
Retorna os n maiores elementos |
s.nsmallest([n, keep]) |
Retorna os n menores elementos |
s.nunique([dropna]) |
Retorna quantos elementos únicos existem na s |
s.pad([axis, inplace, limit, downcast]) |
O mesmo que DataFrame.fillna() usando method=’ffill’ |
s.plot() |
O mesmo que pandas.plotting._core.PlotAccessor |
s.pop(i) |
Remove s[i] de s e retorna s[i] |
s.repeat(repeats[, axis]) |
Repete elementos da s |
s.replace([to_replace, value, inplace, limit, …]) |
Substitui valores em to_replace por value |
s.sort_values([axis, ascending, inplace, …]) |
Reorganiza s usando seus valores |
s.str |
Usa funções de string sobre s (se string). Ex. s.str.split(“-“) |
s.tail([n]) |
Últimos n elementos |
s.unique() |
Retorna os valores da s, sem repetições |
s.update(s2) |
Modifica s usando valores de s2, usando índices iguais |
s.view([dtype]) |
Cria uma nova “view” da s |
s.where(cond[, serie, inplace, axis, level, …]) |
Substitui valores se a condição cond = True |
Operações matemáticas básicas:
s.ewm([com, span, halflife, alpha, …])Calcula exponencial com peso
s.abs() |
Retorna s com valor absoluto, e/e |
s.add(s2) |
Soma s com s2, e/e |
s.agg([func, axis]) |
Agrega usando func sobre o eixo especificado |
s.apply(func[, convert_dtype, args]) |
Aplica func sobre os valores de s, e/e |
s.div(s2) |
Divisão (float) de s por s2, e/e |
s.divmod(s2) |
Divisão inteira e módulo de s por s2, e/e |
s.dot(s2) |
Produto interno entre a s e s2 |
s.floordiv(s2) |
Divisão inteira da s por s2, e/e |
s.mod(s2[, level, fill_value, axis]) |
Módulo de s por s2, e/e |
s.rfloordiv(s2[, level, fill_value, axis]) |
Divisão inteira de s por s2, e/e |
s.rmod(s2[, level, fill_value, axis]) |
Modulo da divisão da s por s2, e/e |
s.rmul(s2[, level, fill_value, axis]) |
Multiplicação de s por s2, e/e |
s.round([n]) |
Arredonda valores da s para n casas decimais. |
s.rpow(s2[, level, fill_value, axis]) |
Exponential de s por s2, e/e |
s.rsub(s2[, level, fill_value, axis]) |
Subtração da s por s2, e/e |
s.rtruediv(serie[, level, fill_value, axis]) |
Divisão (float) de s por s2, e/e |
s.sub(s2) |
Subtração de s por s2, e/e |
s.subtract(serie) |
Idem |
s.sum([axis, skipna, level, numeric_only, …]) |
Soma dos valores da s |
s.transform(func[, axis]) |
Executa func sobre elementos de s |
s.truediv(s2) |
Divisão (float) de s por s2, e/e |
s.truncate([before, after, axis, copy]) |
Trunca a s antes e após índices dados |
s.mul(s2[, level, fill_value, axis]) |
Multiplicação de s por s2, e/e |
s.multiply(s2[, level, fill_value, axis]) |
Idem |
s.pow(s2) |
Exponential de s por s2, e/e |
s.prod([axis, skipna, level, numeric_only, …]) |
Produto dos elementos da s |
s.product([axis, skipna, level, numeric_only, …]) |
Idem |
s.rdiv(s2[, level, fill_value, axis]) |
Divisão (float) de s por s2, e/e |
s.rdivmod(s2) |
Divisão inteira e módulo de s por s2, e/e |
Operações estatísticas:
| Método (sobre série s, outra s2) |
Descrição |
s.corr(s2) |
Correlação de s com s2, excluindo NaNs |
s.count([level]) |
Número de observações na s, excluindo NaN/nulls |
s.cov(s2[, min_periods, ddof]) |
Covariância da s, excluindo NaN/nulls |
s.cummax([axis, skipna]) |
Máximo cumulativo |
s.cummin([axis, skipna]) |
Mínimo cumulativo |
s.cumprod([axis, skipna]) |
Produto cumulativo |
s.cumsum([axis, skipna]) |
Soma cumulativa |
s.describe([percentiles, include, exclude, …]) |
Gera descrição estatística |
s.kurt([axis, skipna, level, numeric_only]) |
Kurtosis imparcial |
s.kurtosis([axis, skipna, level, numeric_only]) |
Idem |
s.hist() |
Plota histograma da s usando matplotlib. |
s.mad([axis, skipna, level]) |
Desvio médio absoluto dos valores de s
|
s.mean([axis, skipna, level, numeric_only]) |
Média dos valores |
s.median([axis, skipna, level, numeric_only]) |
Mediana dos valores |
s.mode([dropna]) |
Moda da s |
s.quantile([q, interpolation]) |
Valor no quantil dado |
s.ravel([order]) |
Retorna dados como um ndarray |
s.sample([n, frac, replace, weights, …]) |
Amostra randomizada de items da s |
s.sem([axis, skipna, level, ddof, numeric_only]) |
Erro padrão imparcial da média |
s.skew([axis, skipna, level, numeric_only]) |
Inclinação imparcial |
s.std([axis, skipna, level, ddof, numeric_only]) |
Desvio padrão da amostra |
s.value_counts([normalize, sort, ascending, …]) |
Retorna s com a contagem de valores únicos |
s.var([axis, skipna, level, ddof, numeric_only]) |
Variância imparcial dos valores da s |
Operações com índices:
s.add_prefix('prefixo') |
Adiciona prefixo aos labels com string ‘prefixo’ |
s.add_suffix('sufixo') |
Adiciona sufixo aos labels com string ‘sufixo’ |
s.argmax([axis, skipna]) |
Posição (índice inteiro) do valor mais alto de s |
s.argmin([axis, skipna]) |
Posição (índice inteiro) do menor valor de s |
s.argsort([axis, kind, order]) |
Índices inteiros que ordenam valores da s |
s.drop([labels]) |
Retorna s com labels removidos |
s.first_valid_index() |
Índice do primeiro valor não NA/null |
s.idxmax([axis, skipna]) |
Label do item de maior valor |
s.idxmin([axis, skipna]) |
Label do item de menor valor |
s.keys() |
Alias de index |
s.last_valid_index() |
Índice do último valor não NA/null |
s.reindex([index]) |
Ajusta a s ao novo índice |
s.reindex_like(s2[, method, copy, limit, …]) |
Série com índices em acordo com s2 |
s.rename([index, axis, copy, inplace, level, …]) |
Altera o nome (labels) dos índices |
s.reorder_levels(order) |
Reajusta níveis de índices usando order |
s.reset_index([level, drop, name, inplace]) |
Reinicializa índices |
s.searchsorted(value[, side, sorter]) |
Índices onde elementos devem ser inseridos para manter ordem |
s.sort_index([axis, level, ascending, …]) |
Reorganiza s usando os índices |
Testes, com retorno booleanos e comparações:
| Método (sobre série s, outra s2) |
Descrição |
s.all([axis, bool_only, skipna, level]) |
Booleano: se todos os elementos são True |
s.any([axis, bool_only, skipna, level]) |
Booleano: se algum elemento é True |
s.equals(s2) |
Booleano: True se s contém os mesmos elementos que s2 |
s.between(min, max) |
Booleano: satisfazendo min <= s <= max, e/e |
s.compare(s2[, align_axis, keep_shape, …]) |
Compara s com s2 exibindo diferenças |
s.eq(s2) |
Boleano: igualdade entre s e s2, e/e |
s.ge(s2) |
Booleana: maior ou igual entre s e s2, e/e |
s.gt(s2[, level, fill_value, axis]) |
Booleana: se s é maior que s2, e/e |
s.isin(valores) |
Booleano: se elementos da s estão contidos em valores |
s.isna() |
Booleano: se existem valores ausentes |
s.isnull() |
Booleano: se existem valores nulos |
s.le(s2) |
Booleana: se s é menor ou igual a s2, e/e |
s.lt(s2[, level, fill_value, axis]) |
Booleana: se s é menor que s2, e/e |
s.ne(s2[, level, fill_value, axis]) |
Booleana: se s é diferente de s2, e/e |
s.notna() |
Booleana: se existem valores não faltantes ou nulos |
s.notnull() |
Idem |
Transformações para outros formatos e tipos:
s.astype(dtype[, copy, errors]) |
Transforma (cast) para dtype |
s.to_clipboard([excel, sep]) |
Copia o object para o clipboard do sistema |
s.to_csv([path_or_buf, sep, na_rep, …]) |
Grava a s como arquivo csv |
s.to_dict() |
Converte s para dict {label ⟶ value} |
s.to_excel(excel_writer[, sheet_name, na_rep, …]) |
Grava s como uma planilha Excel |
s.to_frame([name]) |
Converte s em DataFrame |
s.to_hdf(path_or_buf, key[, mode, complevel, …]) |
Grava s em arquivo HDF5 usando HDFStore |
s.to_json([path_or_buf, orient, date_format, …]) |
Converte s em string JSON |
s.to_latex([buf, columns, col_space, header, …]) |
Renderiza objeto para LaTeX |
s.to_markdown([buf, mode, index, storage_options]) |
Escreve a s em formato Markdown (leia) |
s.to_numpy([dtype, copy, na_value]) |
Converte s em NumPy ndarray |
s.to_pickle(path[, compression, protocol, …]) |
Grava objeto serializado em arquivo Pickle |
s.to_sql(name, con[, schema, if_exists, …]) |
Grava elementos em forma de um database SQL |
s.to_string([buf, na_rep, float_format, …]) |
Constroi uma representação string da s |
s.tolist() |
Retorna uma lista dos valores |
s.to_list() |
idem |
Operações com séries temporais:
s.asfreq(freq) |
Converte TimeSeries para frequência especificada. |
s.at_time(time[, asof, axis]) |
Seleciona valores em determinada hora (ex., 9:30AM) |
s.between_time(inicio, fim) |
Seleciona valores com tempo entre inicio e fim |
s.first(offset) |
Seleciona período inicial de uma série temporal usando offset. |
s.last(offset) |
Seleciona período final de uma série temporal usando offset |
Alguns exemplos de uso dos métodos de pandas.Series:
» import pandas as pd
» import numpy as np
» serie = pd.Series([1,-1, 2, 2, 6, 63])
» serie.abs()
» # retorna pd.Series([1, 1, 2, 2, 6, 63])
» # Muitos métodos não alteram a series inplace.
» s2 = serie.rename('NovoNome') # não altera nome de serie
» s2.name
↳ 'NovoNome'
» # para alterar o nome usamos
» serie.rename('NovoNome', inplace=True) # altera nome de serie inplace
» serie.name
↳ 'NovoNome'
» # um resumo estatístico pode ser visto com describe
» serie.describe()
↳ count 15.000000
mean 4.866667
std 3.044120
min 0.000000
25% 3.500000
50% 5.000000
75% 7.000000
max 9.000000
dtype: float64
» # gerando outra series
» data = np.random.randint(0, 10,size=15)
» serie2 = pd.Series(data)
» data
↳ array([2, 2, 6, 3, 1, 4, 3, 4, 3, 0, 8, 3, 8, 2, 7])
» serie.div(serie2)
↳ 0 2.500000
1 0.000000
...
9 inf
13 0.000000
14 1.000000
dtype: float64
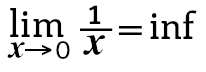
Observe que a divisão por 0 não gera erro mas é representada por inf.
Alguma habilidade gráfica pode ser encontrada entre os métodos das series. Um exemplo é o serie.hist() que traça o histograma da series usando matplotlib. Veremos com mais detalhes as funcionalidades dessa biblioteca.
» data = np.random.randint(0, 10,size=15)
» data
array([5, 0, 7, 7, 0, 9, 6, 5, 6, 9, 5, 5, 2, 0, 7])
» serie = pd.Series(data)
» serie.hist()

Objetos do pandas possuem métodos poderosos e eficientes. O método serie.str() permite operações de strings sobre os elementos da serie, se esses forem strings.
» str = ['-mercado','-tensão','-plasia']
» serie = pd.Series(str)
» serie
↳ 0 -mercado
1 -tensão
2 -plasia
» serie = serie.str.replace('-','hiper-')
» serie
↳ 0 hiper-mercado
1 hiper-tensão
2 hiper-plasia
» serie.str.split('-')
↳ 0 [hiper, mercado]
1 [hiper, tensão]
2 [hiper, plasia]
» # elementos não strings resultam em NaN
» serie = pd.Series([123,'-tensão','-plasia'])
» serie.str.replace('-','hiper-')
↳ 0 NaN
1 hiper-tensão
2 hiper-plasia
Series podem ser usadas na construção de dataframes, que serão vistos a seguir. Em particular o método to_frame() transforma uma series em um dataframe com uma coluna, onde cada valor ocupa uma linha.
» # uma series pode ser transformada em um dataframe
» df = serie.to_frame()
» # um dataframe é gerado e armazenado em df
Como a maioria dos métodos de series são análogos àqueles de dataframes faremos uma exploração mais extensa desses na sessão referente aos dataframes.
Bibliografia
- Blair,Steve: Python Data Science, The Ultimate Handbook for Beginners on How to Explore NumPy for Numerical Data, Pandas for Data Analysis, IPython, Scikit-Learn and Tensorflow for Machine Learning and Business, edição do autor disponível na Amazon, 2019.
- Harrison, Matt: Learning Pandas, Python Tools for Data Munging, Data Analysis, and Visualization,
edição do autor, 2016.
- McKinney, Wes: pandas: powerful Python data analysistoolkit, Release 1.2.1
publicação do Pandas Development Team, revisado em 2021.
- McKinney, Wes: Python for Data Analysis, Data Wrangling with Pandas, NumPy,and IPython
O’Reilly Media, 2018.
- Pandas: página oficial, acessada em janeiro de 2021.
- Pandas User Guide, acessada em fevereiro de 2021.
- Miller, Curtis: On Data Analysis with NumPy and pandas, Packt Publishing, Birmingham, 2018.
