Introdução
Sequências: no Python sequências são conjuntos de elementos ordenados que podem ser acessados em sua ordem (o que chamamos de iteráveis. Já vimos que strings são sequências. Por ex., print('Casa da Mãe Joana'[3]) resulta em 'a'.
Outra sequência de uso comum é range, que é o tipo de objeto retornado pela “função” range(). Ela tem a seguinte sintaxe ou assinatura:
range(inicio, fim, passo)
onde inicio e passo são opcionais. Ela gera uma sequência de inicio até fim (exclusivo) com intervalo de passo.
range(), na verdade, não é uma função mas uma classe geradora de um iterador, como veremos mais tarde. Ela fornece objetos que produzem os elementos sob demanda, sem precisar guardar todos na memória.» faixa = range(2, 20, 3)
» print('o objeto é', faixa)
↳ o objeto é range(2, 20, 3)
» print('o tipo do objeto é', type(faixa))
↳ o tipo do objeto é <class 'range'>
» print('o segundo elemento é', faixa[1])
↳ o segundo elemento é 5
# podemos iterar pelos itens de faixa
» for t in faixa:
» print(t, end=' ')
↳ 2 5 8 11 14 17
Coleções são conteineres de dados. No módulo básico do Python existem quatro tipos de dados em coleções:
- Lista (list): ordenada e mutável, pode ter membros duplicados.
- Tupla (tuple): ordenada e imutável, pode ter membros duplicados.
- Conjunto (set): não ordenada e não indexada, sem membros duplicados.
- Dicionário (dictionary): não ordenada, mutável, sem membros duplicados.

sets são mutáveis mas não admitem objetos mutáveis como seus elementos. Podemos ter, portanto, conjuntos de inteiros, strings ou tuplas, mas não de listas ou dicionários.Existe um módulo chamado collections com outros tipos de conteineres com estruturas de dados mais específicas como, por exemplo, uma tupla nomeada e um dicionário ordenado.
Listas
Além dos objetos já vistos, muitos outros são pre-programados no núcleo básico do Python. A listas (lists) são sequências ordenadas de objetos que podem ser acessados por meio de seu índice (ou index), um marcador de sua posição. Os objetos de uma lista não precisam ser do mesmo tipo, são delimitados por colchetes e separados por vírgulas.
lista = [valor_0, …, valor_n]
As listas são mutáveis, podem ser encolhidas ou expandidas e ter seus elementos substituídos. Exemplos de listas são dados a seguir:
» lista1 = ['Maria', 25] » lista2 = ['José', 27] » lista3 = [lista1, lista2] » print(lista1[0], lista1[1]) ↳ Maria 25 # lista3 é uma lista de listas » print(lista3) ↳ [['Maria', 25], ['José', 27]] # o 2º elemento da 2ª lista é » print(lista3[1][1]) ↳ 27
Da mesma forma que sequências de caracteres (nas strings), elementos em listas e tuplas podem ser acessados por meio de seus índices. Fatias (ou slices) lista[i:j] se iniciam no i-ésimo elemento, até o j-ésimo, exclusive, de forma que len(lista[i:j]) = j-i. Índices negativos contam a partir do final.
» lista4 = [10, 23, 45, 56, 67, 78, 89, 90] » lista4[1:3] ↳ [23, 45] # omitindo o 1º índice » lista4[:2] ↳ [10, 23] # omitindo o 2º índice » lista4[4:] ↳ [67, 78, 89, 90] # o último elemento » lista4[-1] ↳ 90 » lista4[-4:-2] ↳ [67, 78] # len fornece o número de elementos na lista » len(lista4[3:7]) ↳ 4 # um 3º parâmetro indica o "passo" » lista4[::2] ↳ [10, 45, 67, 89] # um passo negativo indica contagem do fim para o início » lista4[::-1] ↳ [90, 89, 78, 67, 56, 45, 23, 10]
Vimos que a ausência do 1º índice assume o início, a ausência do 2º assume o final. O 3º indica para pular um número de elementos.

Uma função que retorna uma lista (ou outra sequência qualquer) pode ser diretamente indexada. Por ex., podemos construir uma função que retorna o mês abreviado em 3 letras. O índice do mês pode ser atribuído diretamente ao retorno da função:
» def mes_abrev(): » m = ['jan','fev','mar','abr','mai','jun','jul','ago','set','out','nov','dez',] » return m # para pegar o segundo mês: » mes_abrev()[1] ↳ 'fev' # para pegar o 1º trimestre: » mes_abrev()[:3] ↳ ['jan', 'fev', 'mar'] # para pegar o último trimestre: » mes_abrev()[-3:] ↳ ['out', 'nov', 'dez']
Assim como ocorre com strings, listas podem ser somadas (concatenadas) e multiplicadas por um número (repetidas). O efeito é o mesmo.
» lista5 = [0, 1, 2, 3, 4] » lista6 = [10, 11, 12, 13, 14] » lista5 + lista6 ↳ [0, 1, 2, 3, 4, 10, 11, 12, 13, 14] » lista5 * 2 ↳ [0, 1, 2, 3, 4, 0, 1, 2, 3, 4]
Uma lista pode ser inicializada vazia ou com um número especificado de itens.
» lista_vazia = [] # lista vazia » lista_vazia ↳ [] # elementos podem ser inseridos com o método append » lista_vazia.append(12) » lista_vazia.append(13) » lista_vazia ↳ [12, 13] # o mesmo efeito seria obtido com concatenação » lista_vazia.clear() # a lista volta a ser vazia » lista_vazia += [12, 13] » lista_vazia ↳ [12, 13] # lista com 5 entradas » lista_none = [None]*5 » lista_none ↳ [None, None, None, None, None]
Sendo mutáveis listas podem ser alteradas in place tendo qualquer de seus valores trocados sem a necessidade de criação de nova lista. count(item) retorna quantas vezes item aparece na lista. index(item) retorna o índice onde item aparece.
» palavras = ['palha', 'grande', 'casa', 'dado', 'pequeno',
'coisa', 'gado', 'fato', 'gato', 'lá' ]
» print('A terceira palavra é ---| %s |---' % palavras[2] )
↳ A terceira palavra é ---| casa |---
» palavras[2] = 'house'
» print('A terceira palavra é ---| %s |---' % palavras[2] )
↳ A terceira palavra é ---| house |---
# inserindo mais uma 'house'
» palavras[3] = 'house'
» palavras.count('house')
↳ 2
# o índice de 'coisa'
» palavras.index('coisa')
↳ 5
# index retorna a 1ª ocorrência, quando existem mais de 1
» palavras.index('house')
↳ 2
Objetos podem ser inseridos em uma lista, na n-ésima posição, com lista.insert(n, obj). Um membro do lista pode ser removido com lista.pop(n). Esse método retorna o objeto removido. lista.remove(obj) também faz a remoção, sem retornar o objeto.
# inserir um objeto na posição 3
» palavras.insert(3, 'estrela')
» print(palavras)
↳ ['pequeno', 'palha', 'lá', 'estrela', 'house', 'house', 'grande', 'gato', 'gado', 'fato', 'coisa']
# pop extrai e retira elemento no índice dado
» saiu = palavras.pop(3)
» print(saiu)
↳ estrela
# a lista fica sem esse elemento
» print(palavras)
↳ ['pequeno', 'palha', 'lá', 'house', 'house', 'grande', 'gato', 'gado', 'fato', 'coisa']
# se nenhum índice for fornecido o último elemento é removido (e retornado)
» palavras.pop()
↳ coisa
» print(palavras)
↳ ['pequeno', 'palha', 'lá', 'house', 'house', 'grande', 'gato', 'gado', 'fato']
# remove não retorna o item removido
» palavras.remove('house')
» print(palavras)
↳ ['pequeno', 'palha', 'lá', 'house', 'grande', 'gato', 'gado', 'fato', 'coisa']
# o item deve estar na lista ou exceção será lançada
» palavras.remove('pedra')
↳ ValueError: list.remove(x): x not in list
O método .sort() ordena itens de uma lista. Ele admite os parâmetros opcionais key, reverse que podem ser usados para fazer ordenamentos diferentes que o default. Por ex., se key = len o ordenamento se dará por comprimento das palavras, da menor para a maior. Se, além disso reverse = True o ordenamento se dará no sentido contrário. Também se pode definir uma função customizada para fazer essa ordenação.
# ordenar » palavras.sort() » print(palavras) ↳ ['coisa', 'fato', 'gado', 'gato', 'grande', 'house', 'house', 'lá', 'palha', 'pequeno'] # outra form de ordenar item em qualquer sequência é a função sorted() # que retorna a lista palavras ordenada sem alterar a lista original » sorted(palavras) # nesse caso a lista já estava ordenada ↳ ['coisa', 'fato', 'gado', 'gato', 'grande', 'house', 'house', 'lá', 'palha', 'pequeno'] # inverter a ordenação » palavras.reverse() » print(palavras) ↳ ['pequeno', 'palha', 'lá', 'house', 'house', 'grande', 'gato', 'gado', 'fato', 'coisa'] » palavras.sort(key= len) » palavras ↳ ['lá', 'fato', 'gado', 'gato', 'coisa', 'house', 'house', 'palha', 'grande', 'pequeno'] » palavras.sort(key= len, reverse=True) ↳ ['pequeno', 'grande', 'coisa', 'house', 'house', 'palha', 'fato', 'gado', 'gato', 'lá']

Métodos das listas (lists)
| Método | Descrição |
|---|---|
| append() | insere elementos na lista |
| clear() | remove todos os elementos na lista |
| copy() | retorna uma cópia da lista |
| count() | retorna o número de elementos com valor especificado |
| extend() | insere os elementos de outra lista (ou iterável) ao final da lista |
| index() | retorna o índice do 1º elemento com valor especificado |
| insert() | insere elemento em posição especificada |
| pop() | remove elemento em posição especificada por índice e retorna esse elemento |
| remove() | remove elemento em posição especificada por índice |
| reverse() | inverte a ordem da lista |
| sort() | ordena a lista |
Além desses as seguintes funções são úteis para se lidar com listas (e outras sequências):
| Função | Descrição |
|---|---|
| cmp(x, y) | compara dois valores |
| len(seq) | retorna o comprimento da sequência |
| list(seq) | converte uma sequência em lista |
| max(args) | retorna o valor máximo na sequência |
| min(args) | retorna o valor mínimo na sequência |
| reversed(seq) | retorna um iterador com os valores na sequência |
| sorted(seq) | retorna lista ordenada dos elementos na sequência |
| tuple(seq) | converte a sequência em uma tupla |
É possível testar se um determinado elemento é membro da lista:
» 'gado' in palavras
↳ True
» 'pedra' in palavras
↳ False
# definimos uma lista de listas (com nome e senha de usuários)
» usuarios = [
» ['alberto', '1234'],
» ['mario', '6282'],
» ['maria', '5274'],
» ['joana', '9943']
» ]
» nome = input('Nome do usuário: ')
» pin = input('Código PIN: ')
» msg = 'Accesso liberado' if [nome, pin] in usuarios else 'Acesso negado'
» print(msg)
# uma entrada de dados que não corresponde a nenhuma entrada da lista
↳ Nome do usuário: lucas
↳ Código PIN: 1234
↳ Acesso negado
# dados de usuário cadastrado
↳ Nome do usuário: joana
↳ Código PIN: 9943
↳ Accesso liberado
Assim como existe uma função interna len() que retorna o comprimento de sequências, temos também max(), min() que retornam o maior e menor valor dentro da lista. Essas funções funcionam também com strings, considerada a ordem alfabética.
» numeros = [100, 23, 987] » print(len(numeros)) ↳ 3 » print(max(numeros)) ↳ 987 » print(min(numeros)) ↳ 23 » print(max(2, 3)) ↳ 3 » print(min(9, 3, 2, 5)) ↳ 2 # min e max fazem comparações entre strings: » palavras ↳ ['pequeno', 'palha', 'lá', 'grande', 'gato', 'gado', 'fato', 'coisa'] » min(palavras) ↳ 'coisa' » max(palavras) ↳ 'pequeno'
Tuplas
Tuplas (tuples) são sequências ordenadas e imutáveis de objetos, que podem ser acessados por meio de seu índice (index), um marcador de sua posição. Os objetos que a compõem não precisam ser mesmo tipo e são delimitados por parênteses e separados por vírgulas.
tupla = (valor_0, …, valor_n)
Tuplas e listas se comportam de modo análogo, exceto em que tuplas são imutáveis (como as strings), não podem ser alteradas após sua criação. Existem razões técnicas para a existência de tuplas: operações com tuplas são mais rápidas que as com listas, e elas ocupam menos espaço na memória. Por isso não é raro que um método retorne uma tupla ou as demande como parâmetro. Daí a necessidade de conhecê-las.
# é comum usar tuplas na formatação de strings:
» print('Essa frase %s %d %s %s %s.' % ('lê', 4, 'palavras','na','tupla'))
↳ Essa frase lê 4 palavras na tupla.
# elementos são acessados por índice
» tupla = (0,1,2,3,4,'cinco')
» tupla[5]
↳ 'cinco'
# tuplas são imutáveis
» tupla[5] = 5
↳ TypeError: 'tuple' object does not support item assignment
# um erro é lançado se o índice não existe no objeto
» tupla[6]
↳ IndexError: tuple index out of range
# tuplas são iteráveis
» for t in tupla:
» print(t, end=', ')
↳ 0, 1, 2, 3, 4, cinco,
# a função len funciona para tuplas
» print(tupla[len(tupla) - 1])
↳ cinco
# é o mesmo que
» print(tupla[-1])
↳ cinco
# tuplas podem conter outras tuplas como elemento
» a = ('primeiro', 'segundo', 'terceiro')
» b = (a, 'segundo elemento de b')
» print('%s' % b[1])
↳ segundo elemento de b
» print(b[0][0], b[0][1], b[0][2])
↳ primeiro segundo terceiro
Métodos das Tuplas (tuples)
| Método | Descrição |
|---|---|
| count(X) | retorna quantas vezes o objeto X ocorre na tupla |
| index(x) | procura pela 1ª ocorrência do objeto X na tupla e retorna sua posição |
| index(x, i) | procura pela 1ª ocorrência do objeto X na tupla, à partir da posição i, e retorna sua posição |
| index(x, i, f) | procura pela 1ª ocorrência de X na tupla, à partir da posição i até j, e retorna sua posição |
Por exemplo:
» tupla = ("porco", "boi", "cobra", "galinha", "cobra", "raposa", "gavião")
» print (tupla.index("cobra"))
↳ 2
» print (tupla.index("cobra", 3))
↳ 4
» print (tupla.index("cobra", 3, 5))
↳ 4
» tupla.count("cobra")
↳ 2
As funcões globais sobre sequências já listadas podem ser usadas com tuplas:
» print(len(tupla))
↳ 7
» print(sorted(tupla))
↳ ['boi', 'cobra', 'cobra', 'galinha', 'gavião', 'porco', 'raposa']
# a operação sorted() não altera a tupla original
» print(tupla)
↳ ('porco', 'boi', 'cobra', 'galinha', 'cobra', 'raposa', 'gavião')
» print(min(tupla))
↳ boi
» print(max(tupla))
↳ raposa
Conjuntos (sets)
Conjuntos (sets) são coleções não ordenadas de objetos únicos e imutáveis. Conjuntos podem ser criados listando-se diretamente os elementos ou passando-se uma sequência pelo construtor set().
conjunto = {e_1, …, e_n}
conjunto = set(sequencia)
Por exemplo, abaixo dois sets são criados e as operações de interseção, união e diferença são mostradas. Nenhuma dessa operações alteram os sets envolvidos.
# dois sets são criados
» X = {'a', 'b', 'c', 'd'}
» Y = set('cdef')
» print(X, Y)
↳ {'d', 'c', 'b', 'a'} {'f', 'c', 'd', 'e'}
# a interseção é obtida com & (e comercial)
» X & Y
↳ {'c', 'd'}
# a união com |
» X | Y
↳ {'a', 'b', 'c', 'd', 'e', 'f'}
# a diferença de conjuntos
» X-Y
↳ {'a', 'b'}
# comprehension (veremos mais sobre esses métodos mais tarde)
» Z = {i**2 for i in [1,2,3,4] }
» Z
↳ {1, 4, 9, 16}
» type(Z)
↳ set
# os elementos podem ser percorridos um a um (mas não de forma ordenada)
» for i in Z:
» print(i, end=', ')
↳ 16, 1, 4, 9,
# testes para pertinência
» 16 in Z
↳ True
» 5 in Z
↳ False
Alternativamente, as operações de interseção, união e diferença podem feitas com métodos da classe. Nesse caso o conjunto X fica alterado na operação.
» X = {'a', 'b', 'c', 'd'}
» Y = {'c', 'd', 'e', 'f'}
# a união de dois sets (fica armazenada em X)
» X.union(Y)
» print(X)
↳ {'a', 'b', 'c', 'd', 'e', 'f'}
» X = {'a', 'b', 'c', 'd'}
» Y = {'c', 'd', 'e', 'f'}
# elementos que não são comuns
» X.symmetric_difference_update(Y)
» print(X)
↳ {'a', 'b', 'e', 'f'}
» X = {'a', 'b', 'c', 'd'}
» Y = {'c', 'd', 'e', 'f'}
# elementos em ambos os sets (interseção)
» X.intersection_update(Y)
» print(X)
↳ {'c', 'd'}
Outros métodos de sets são mostrados.
# o comprimento é o número de elementos
» Z = {1, 4, 9, 16}
» len(Z)
↳ 4
# novos elementos podem ser adicionados
» Z.add(133)
» Z
↳ {1, 4, 9, 16, 133}
# qualquer sequência pode ser adicionada
» qualquer =[1, 100, 'coisa']
» Z.update(qualquer)
» Z
↳ {1, 100, 133, 16, 4, 9, 'coisa'}
# um elemento pode ser removido
» Z.remove('coisa')
» Z
↳ {1, 4, 9, 16, 100, 133}
# um erro é lançado no uso de remove se elemento não existe
» Z.remove(45)
↳ KeyError: 45
# também se pode remover com discard
» Z.discard(133)
» Z
↳ {1, 4, 9, 16, 100}
# nenhum erro é lançado com discard
» Z.discard(45)
# para limpar todos os elementos do set
» Z.clear()
» Z
↳ set()
# para apagar a variável (válido para qualquer variável do Python)
» del Z
» Z
↳ NameError: name 'Z' is not defined
Suponha que temos uma lista longa de elementos muitos dos quais podem ser repetidos e queremos que essa lista não contenha repetições. Para remover repetições podemos transformar a lista em set (que não contém repetições) e depois retornando os dados para uma lista, caso isso seja necessário.
# queremos remover as repetições de » lista_original = [1,2,3,4,4,3,2,1,6,6,7,8,8,8,9] » conjunto = set(lista_original) » lista_nova= list(conjunto) » lista_nova ↳ [1, 2, 3, 4, 6, 7, 8, 9]
Seguem mais algumas ilustrações de uso de métodos de sets.
# criamos um set usando compreensão
» nSet = {i**3 for i in range(4)}
» nSet
↳ {0, 1, 8, 27}
# o método pop() extrai um elemento qualquer e o retorna †
» print(nSet.pop())
↳ 0
» print(nSet)
↳ {1, 27, 8}
» print(nSet.pop())
↳ 1
» print(nSet)
↳ {27, 8}
# subset e superset
» A = {1,2}
» B = {1,2,3}
» A.issubset(B)
↳ True
» A.issuperset(B)
↳ False
» B.issuperset(A)
↳ True

† Observe que set.pop() remove e retorna um elemento qualquer do conjunto, uma vez que ele não é ordenado.
Métodos dos conjuntos (set)
| Método | Descrição |
|---|---|
| add() | insere elemento no set |
| clear() | remove todos os elementos do set |
| copy() | retorna cópia do set |
| difference() | retorna um set com a diferença entre 2 ou mais sets |
| difference_update() | remove elementos incluidos no segundo set |
| discard() | remove item especificado |
| intersection() | retorna o set interseção de 2 sets |
| intersection_update() | remove items do set não presentes no segundo set especificado |
| isdisjoint() | retorna True se os 2 sets são disjuntos |
| issubset() | retorna True se o set é subconjunto do segundo set |
| issuperset() | retorna True se o set contém o segundo set |
| pop() | remove (e retorna) um elemento arbitrário do set |
| remove() | remove o elemento especificado |
| symmetric_difference() | retorna o set com a diferença simétrica de dois sets |
| symmetric_difference_update() | insere a diferença simétrica desse set em outro |
| union() | retorna um set com a união dos sets |
| update() | atualiza o primeiro set com sua união com um ou mais sets |
Dicionários (dictionaries)
Dicionários (dictionaries) são coleções de dados armazenados em pares chave: valor (key: value). A coleção é mutável, ordenada (a partir de Python 3.7) e não admite valores duplicados. A chave de um dicionário funciona como um índice que permite a recuperação do valor a ele associado. Eles têm a forma geral de
dict = {key_1:value_1, …, key_n:value_n}
As chaves são ordenadas e podem ser de diversos tipos. Valores podem ser de qualquer tipo e podem ser alterados. Por exemplo:
# inicializando um dicionário
» dic = {'casa':'house', 'cachorro':'dog', 'caneta':'pencil','carro':'car'}
» dic
↳ {'casa': 'house', 'cachorro': 'dog', 'caneta': 'pencil', 'carro': 'car'}
» print(type(dic))
↳ <class 'dict'>
# acessando o valor com chave = 'caneta'
» dic['caneta']
↳ 'pencil'
# a função len retorna quantos pares existem no dicionário
» len(dic)
↳ 4
# chaves duplicadas são substituídas (a anterior é removida)
» dic2 = {"nome" : "Pedro",
» "sobrenome" : "Alvarez",
» "idade" : 23,
» "idade" : 27
» }
» print(dic2['idade'])
↳ 27
Um dicionário pode ser criado recebendo uma lista de tuplas em seu construtor, como se mostra no primeiro exemplo abaixo. No exemplo seguinte tuplas são usadas como chaves.
# t é uma lista de tuplas
» t = [(0, 'zero'),(1, 'um'),(2, 'dois'),(3, 'tres'),(4, 'quatro')]
» d = dict(t)
» print(d)
↳ {0: 'zero', 1: 'um', 2: 'dois', 3: 'tres', 4: 'quatro'}
» d[3]
↳ 'tres'
# usando tuplas como chaves (listas não podem ser usadas)†
» tele = dict()
» tele['Newton', 'Isaac'] = 1643
» tele['Curie','Marie'] = 1867
» tele['Einstein','Albert'] = 1879
» tele['Hawking','Stephen'] = 1942
» print(tele)
↳ {('Newton','Isaac'): 1643, ('Curie', 'Marie'): 1867, ('Einstein', 'Albert'): 1879, ('Hawking', 'Stephen'): 1942}
# o índice é uma tupla
» print(tele['Curie', 'Marie']) # ou print(tele[('Curie', 'Marie')])
↳ 1867
# o dicionário pode ser percorrido lendo-se os dois valores da tupla
» for sobrenome, nome in tele:
» print(nome, sobrenome, "nasceu em", tele[sobrenome,nome])
↳ Isaac Newton nasceu em 1643
↳ Marie Curie nasceu em 1867
↳ Albert Einstein nasceu em 1879
↳ Stephen Hawking nasceu em 1942
# o dicionário também pode ser percorrido lendo-se uma tupla de cada vez
» for t in tele:
» print(t, tele[t] )
↳ ('Newton', 'Isaac') 1643
↳ ('Curie', 'Marie') 1867
↳ ('Einstein', 'Albert') 1879
↳ ('Hawking', 'Stephen') 1942
†: Observe que, no exemplo acima, na criação de um par key : vale usando tuplas os parênteses ficam subentendidos:
» tele['Newton', 'Isaac'] = 1643
# é o mesmo que
» tele[('Newton', 'Isaac')] = 1643
# isso também ocorre quando fazemos
» a, b = 1, 2
# que é idêntico a
» (a, b) = (1, 2)
Se as chaves são strings simples elas podem ser especificadas como nomes de argumentos nomeados. No código abaixo uma lista de IDHs dos estados do sudeste é fornecida ao construtor.
» idh = dict(
» SP=0.833,
» RJ=0.832,
» ES=0.802,
» MG=0.800
» )
» idh
↳ {'SP': 0.833, 'RJ': 0.832, 'ES': 0.802, 'MG': 0.8}
Embora objetos de qualquer tipo (imutável) possam ser usados como chave, não existe um índice numérico associado aos elementos dos dicionários, além das próprias chaves. Dicionários mantém a ordem em que foram criados e sempre retornam o mesmo valor para cada chave.
# Não índices existem associados às chaves dos dicionários
» idh[1]
↳ KeyError: 1
» d = {0: 'a', 1: 'b', 2: 'c', 3: 'd'}
» d[3] # operação possível porque 3 é uma chave, não um índice
↳ 'd'
Dicionários não são ordenados mas existe um objeto chamado OrderedDict que pode ser importado da classe collections que são.
O dicionário pessoa criado abaixo tem uma lista associada ao valor irmaos e outro dicionário associado ao valor filhos.
# o dicionário abaixo é inicializado vazio e preenchido de modo incremental
» pessoa = {}
» pessoa['nome'] = 'Edvaldo'
» pessoa['sobrenome'] = 'Santos'
» pessoa['idade'] = 41
» pessoa['profissao'] = 'dentista'
» pessoa['filhos'] = {'João':3, 'Ana':7, 'Marco':10 }
» pessoa['irmaos'] = ['Paulo', 'Eliane']
» pessoa
↳ {'nome': 'Edvaldo',
↳ 'sobrenome': 'Santos',
↳ 'idade': 41,
↳ 'profissao': 'dentista',
↳ 'filhos': {'João': 3, 'Ana': 7, 'Marco': 10},
↳ 'irmaos': ['Paulo', 'Eliane']}
# pelo que vimos acima poderíamos também usar a forma
» pessoa['filhos'] = dict(João=3, Ana=7, Marco=10)
A idade do filho que se chama Marco é pessoa['filhos']['Marco'] e o primeiro irmão listado é pessoa['irmaos'][0].
» pessoa['filhos']['Marco'] ↳ 10 » pessoa['irmaos'][0] ↳ 'Paulo'
Naturalmente que uma estrutura muito complexa de vários itens aninhados pode ser difícil de manipular, portanto o bom senso deve prevalecer na construção desses objetos. Para esse fim existem objetos pre-programados bem mais sofisticados, como os arrays do Numpy e os dataframes do pandas. Também, como veremos em seções posteriores, podemos definir objetos do usuário com estruturas bem mais complexas que essas.
Os valores associdas às chaves são mutáveis, podem ser alterados após a criação do dicionário. Chaves e valores podem ser percorridos separadamente ou como tuplas.
» dic2 = {"nome" : "Pedro",
» "sobrenome" : "Cabral",
» "idade" : 27
» }
# os valores são mutáveis
» dic2['sobrenome'] = 'Alves'
» dic2
↳ {'nome': 'Pedro', 'sobrenome': 'Alves', 'idade': 27}
Podem ser usados os métodos dos dicionários: dic.keys(), que retorna as chaves, dic.values(), que retorna os valores, e dic.itens(), que retorna as chaves e valores, todos eles como objetos iteráveis.
# as chaves podem ser lidas como um objeto iterável
» chaves = dic2.keys()
» chaves
↳ dict_keys(['nome', 'sobrenome', 'idade'])
» for chave in chaves:
» print(dic2[chave], end=' ')
↳ Pedro Alves 27
# os valores podem ser lidos em um objeto iterável
» valores = dic2.values()
» valores
↳ dict_values(['Pedro', 'Alves', 27])
# percorrendo os valores
» for t in valores:
» print(t, end=' ')
↳ Pedro Alves 27
# percorrendo as chaves
» for t in chaves:
» print(t, end = ' ')
↳ nome sobrenome idade
# valores e chaves podem ser lidos como uma lista de tuplas
» itn = dic2.items()
» itn
↳ dict_items([('nome', 'Pedro'), ('sobrenome', 'Alves'), ('idade', 27)])
# os pares podem ser percorridos
» for (k,v) in dic2.items():
» print(k,v)
↳ nome Pedro
↳ sobrenome Alves
↳ idade 27
O operador in verifica se um valor está presente entre as chaves ou valores.
# verificando se uma chave está no dicionário
» if 'idade' in dic2:
» print('idade é uma das chaves')
↳ idade é uma das chaves
» print('peso é uma das chaves' if 'peso' in dic2 else 'valor não encontrado')
↳ valor não encontrado
# verificando se um valor está presente no dicionário
» print('Alves é um dos valores' if 'Alves' in dic2.values() else 'valor não encontrado')
↳ Alves é um dos valores
Diversos métodos são pré-programados com a classe dos dicionários. Vemos abaixo o uso de pop(), popitem() e copy(). Uma lista de métodos pode ser vista no final dessa seção.
# o método update serve para alterar o valor atribuído a uma chave
# e/ou inserir novos pares chave:valor
» dic2.update({'idade':19, 'sexo':'masc'})
» dic2
↳ {'nome': 'Pedro', 'sobrenome': 'Alves', 'idade': 19, 'sexo': 'masc'}
# um par chave valor pode ser inserido diretamente (como já fizemos acima)
» dic2['telefone'] = '21-991111110'
» dic2
↳ {'nome': 'Pedro',
↳ 'sobrenome': 'Alves',
↳ 'idade': 19,
↳ 'sexo': 'masc',
↳ 'telefone': '21-991111110'}
# um par pode ser removido pela chave
» dic2.pop('sexo')
» dic2
↳ {'nome': 'Pedro',
↳ 'sobrenome': 'Alves',
↳ 'idade': 19,
↳ 'telefone': '21-991111110'}
# o método popitem() remove o último item inserido (após versão 3.7)
» dic2.popitem()
↳ ('telefone', '21-991111110')
# dic2 fica alterado
» dic2
↳ {'nome': 'Pedro', 'sobrenome': 'Alves', 'idade': 19}
# cópias de dicionários
# a atribuição abaixo atribui a dic3 o mesmo objeto que dic2
» dic3 = dic2
» dic3['idade'] = 67
# dic2 fica alterado
» dic2
↳ {'nome': 'Pedro', 'sobrenome': 'Alves', 'idade': 67}
# para criar cópia independente (criando um novo objeto) usamos
» dic4 = dic2.copy()
# ou, usando o instanciador do objeto
» dic4 = dict(dic2)
# agora dic4 pode ser alterado sem afetar dic2
» dic4['idade'] = 3
» dic2
↳ {'nome': 'Pedro', 'sobrenome': 'Alves', 'idade': 67}
No código acima vemos que a atribuição dic3 = dic2 simplesmente associa o mesmo objeto à variável dict3. Para gerar um novo objeto, que pode ser alterado independentemente, usamos o método dic4 = dic2.copy().
Dicionários podem ser aninhados ou seja, um dicionário pode conter outros dicionários como itens.
# o construtor pode receber diretamente os dicionários
» irmaos = {
» 1:{'nome':'Maria' , 'nasc':1989},
» 2:{'nome':'Marcos' , 'nasc':1991},
» 3:{'nome':'Marla' , 'nasc':2000},
» }
# talvez seja mais legível definir separadamente (o que é equivalente)
» irmao1 ={'nome':'Maria' , 'nasc':1989}
» irmao2 = {'nome':'Marcos' , 'nasc':1991}
» irmao3 ={'nome':'Marla' , 'nasc':2000}
» irmaos = {1:irmao1, 2:irmao2,3:irmao3}
# em qualquer dos casos ficamos com o dicionário
» irmaos
↳ {1: {'nome': 'Maria', 'nasc': 1989},
↳ 2: {'nome': 'Marcos', 'nasc': 1991},
↳ 3: {'nome': 'Marla', 'nasc': 2000}}
# para acessar a data de nascimento do segundo irmão fazemos
» irmaos[2]['nasc']
↳ 1991
# lembrando que, nesse caso, 2 não é um índice mas a chave do dicionário.
Vamos usar um dicionário para contar quantas letras existem em uma palavra ou frase. Para isso criamos um dicionário vazio e iteramos pelas letras da palavra, usando a letra como índice e contagem como valor. A operação palavra.lower().replace(' ', '') transforma todas as letras em minúsculas e elimina espaços. set(palavra) pega as letras da palavra sem repetições. O método string.count(sub) conta quantas vezes a substring sub aparece na string.
# dicionário (contar quantas letras há em uma palavra)
» def letras(palavra):
» ''' Recebe parametro palavra (string)
»
» Retorna dicionário {letra: contagem}
» onde contagem é o número de letras = letra
» Todas as letras são transformadas em minúscula
» espaços são ignorados
» '''
» palavra = palavra.lower().replace(' ', '')
» contagem = {}
» for t in set(palavra):
» contagem[t] = palavra.count(t)
» return contagem
# quais e quantas letras
» dic = letras('Oftalmotorrinolaringologista')
» print(dic)
↳ {'o': 6, 'f': 1, 't': 3, 'a': 3, 'l': 3, 'm': 1, 'r': 3, 'i': 3, 'n': 2, 'g': 2, 's': 1}
# quantas letras 't'?
» dic['t']
↳ 3
# espaços são ignorados, pois foram removidos
» print(letras('Rio de Janeiro'))
↳ {'r': 2, 'i': 2, 'o': 2, 'd': 1, 'e': 2, 'j': 1, 'a': 1, 'n': 1}
O método dictionary.get(chave, default) retorna o valor relativo à chave ou o valor default, caso a chave não seja encontrada.
» dic.get('t',0)
↳ 3
# não existe a letra 'b'
» dic.get('b',0)
↳ 0
Compreensão de dicionários: Dicionários podem ser construídos com compreensão:
» x = {i : i+2 for i in range(5)}
» x
↳ {0: 2, 1: 3, 2: 4, 3: 5, 4: 6}
# outro exemplo
» lista = ('a', 'céu de brigadeiro', 'de', 'prateado', 'laguna', 'introvertido', 'a' )
» dicio = {p : len(p) for p in lista}
» dicio
↳ {'a': 1,
'céu de brigadeiro': 17,
'de': 2,
'prateado': 8,
'laguna': 6,
'introvertido': 12}

Métodos dos dicionários (dictionary)
| Método | Descrição |
|---|---|
| clear() | remove todos os elementos do dictionário |
| copy() | retorna uma cópia do dicionário |
| fromchaves() | retorna dicionário com chaves e valores especificados |
| get() | retorna o valor relativo a chave dada, ou valor default dado |
| items() | retorna uma lista contendo uma tupla para cada par chave:valor |
| keys() | retorna objeto iterável com as chaves do dicionário |
| pop() | remove o elemento relativo à chave especificada |
| popitem() | remove o último par chave:valor inserido |
| setdefault() | retorna o valor relativo à chave dada. Se a chave não existe insere chave:valor |
| update() | Atualiza o dicionário com pares chave:valor dados |
| values() | retorna objeto iterável os valores do dicionário |
Continue lendo: Arquivos e Pastas .
Bibliografia
Consulte a bibliografia no final do primeiro artigo dessa série.












 Vimos, nos exemplos acima, que uma fatia (ou slice) palavra[i:f] se inicia em i e termina em f, exclusive. Os índices, e todas as contagens em python, se iniciam em 0. A posição final não é incluida de forma que
Vimos, nos exemplos acima, que uma fatia (ou slice) palavra[i:f] se inicia em i e termina em f, exclusive. Os índices, e todas as contagens em python, se iniciam em 0. A posição final não é incluida de forma que 


 Python é uma linguagem de programação de alto nível, interpretada e de propósito geral, criada por Guido van Rossum em 1985 e em franco desenvolvimento desde então. Ela está disponível sob a licença GPL (GNU General Public License). Ela permite o uso interativo, com o usuário digitando as linhas de código e obtendo o resultado imediatamente, ou através de lotes (batches), com as linhas de código armazenadas em arquivos e executadas em grupo. Apesar de ser chamada de linguagem de script é possível criar aplicativos completos, na web ou para desktop, com interfaces gráficas modernas e eficientes. Além disso existe a possibilidade de gerar arquivos compilados e executáveis usando
Python é uma linguagem de programação de alto nível, interpretada e de propósito geral, criada por Guido van Rossum em 1985 e em franco desenvolvimento desde então. Ela está disponível sob a licença GPL (GNU General Public License). Ela permite o uso interativo, com o usuário digitando as linhas de código e obtendo o resultado imediatamente, ou através de lotes (batches), com as linhas de código armazenadas em arquivos e executadas em grupo. Apesar de ser chamada de linguagem de script é possível criar aplicativos completos, na web ou para desktop, com interfaces gráficas modernas e eficientes. Além disso existe a possibilidade de gerar arquivos compilados e executáveis usando 

















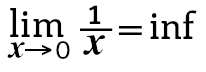




 Nas consultas
Nas consultas 
 Dados ausentes são representados por
Dados ausentes são representados por 

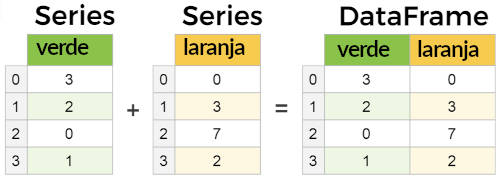
 No SQL tabelas podem ser juntadas ou agrupadas através da cláusula
No SQL tabelas podem ser juntadas ou agrupadas através da cláusula 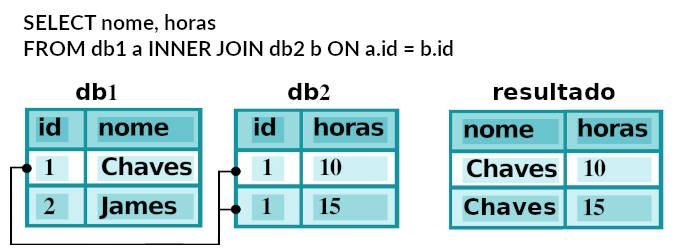

 Existem muitas formas de se excluir linhas de um dataframe mas é comum a prática de selecionar as linhas que devem ser mantidas e copiar para um novo dataframe.
Existem muitas formas de se excluir linhas de um dataframe mas é comum a prática de selecionar as linhas que devem ser mantidas e copiar para um novo dataframe.