O aperfeiçoamento de tecnologias da informação, não diferente de outras tecnologias, tem causado grande impacto na sociedade humana. Grande parte deste impacto é positiva no sentido de aprimorar a experiência do indivíduo, liberando-o de tarefas mecânicas pesadas ou atividades intelectuais extenuantes. No geral a tecnologia amplia a capacidade humana de transformação da natureza ao mesmo tempo em que facilita a exploração científica que, por sua vez, realimenta o avanço tecnológico. No entanto os mesmos aspectos que podem ser benéficos também podem introduzir desafios. Máquinas, como ferramentas mecânicas, aumentam a eficiência e produtividade de um indivíduo, colateralmente provocando desemprego e concentração de renda. Da mesma forma máquinas eletrônicas que simulam as atividades de cognição e interpretação humanas estão, já há alguns anos, transformando a sociedade e as relações entre indivíduos de modo construtivo, em certa medida. Muitos aspectos desta transformação são claramente nocivos, como a evidente tendência da substituição de trabalhadores por máquinas “inteligentes” ou, por exemplo, a manipulação de opiniões para fins políticos usando o levantamento de perfis psicológicos. No entanto esta é uma tecnologia nova e de crescimento muito rápido e a maior parte do impacto causado por ela continua desconhecido e deve ser considerado com atenção.
A inteligência artificial (IA) começou a ser desenvolvida na década de 1950, em um esforço para automatizar atividades antes empreendidas apenas por humanos. Tomadas de decisão básicas podem ser implementadas por equipamentos simples, tal como um termostato que limita a atividade de um condicionador de ar desligando-o quando uma temperatura mínima é atingida. Processadores, que são o núcleo dos computadores eletrônicos, são formados por grande número de circuitos capazes de implementar testes lógicos básicos descritos na chamada Álgebra de Boole. Com o desenvolvimento da programação, que consiste em uma fila de instruções a serem seguidas pelo computador, tornou-se viável a elaboração de sistemas especialistas. Esses sistemas são compostos por uma longa série de instruções, geralmente com acesso a um repositório de informações (um banco de dados) para a tomada de decisões. Eles podem classificar vinhos, jogar xadrez, resolver problemas matemáticos usando apenas símbolos, entre muitas outras tarefas.
Apesar do sucesso de tais sistemas especialistas existem tarefas de complexidade muito superior à de jogar xadrez ou classificar objetos de um conjunto, mesmo que com milhares de elementos. Uma tarefa como a identificação e localização de objetos em uma imagem, por exemplo, exigiria um conjunto gigantesco de linhas de instruções ou informações em bancos de dados. Para tratar grandes volumes de dados e questões que não admitem soluções por meio de algoritmos fixos, mesmo que complexos, foi desenvolvido o Aprendizado de Máquina Artificial (Machine learning).
Ada Lovelace e Charles Babbage
Nas décadas de 1830 e 1840, quando Ada Lovelace e Charles Babbage desenvolveram o Analytical Engine, o primeiro computador mecânico, eles não o consideravam uma máquina a ser utilizada para a solução de problemas genéricos. Pelo contrário, ele foi concebido e utilizado em problemas específicos na área da análise matemática. Nas palavras de Lovelace:
“O Analytical Engine não tem pretensões de criar coisa alguma. Ele apenas pode fazer aquilo que conhecemos e sabemos como instruí-lo em sua execução… Sua função é a de nos ajudar com o que já estamos familiarizados.…”
Essas conclusões foram analisadas por Alan Turing, o pioneiro da IA, em seu artigo de 1950 “Computing Machinery and Intelligence”, onde são introduzidos os conceitos de teste de Turing e outros que se tornaram fundamentos da IA. Ele concluiu que máquinas eletrônicas poderiam ser capazes de aprendizado e originalidade. Aprendizado de máquina (machine learning) é a resposta positiva para a pergunta: um computador pode ir além das instruções com as quais foi programado e aprender a executar tarefas?
O aprendizado de máquina representa um novo paradigma na programação. Ao invés de armazenar na memória do computador um conjunto de regras fixas a serem usadas na execução de uma tarefa o computador é carregado com algoritmos flexíveis que podem ser modificados por meio de treinamento. O aprendizado consiste em exibir para a máquina um conjunto grande de exemplos anotados (devidamente etiquetados) por um humano ou por outra máquina previamente treinada. Uma vez treinado o mesmo sistema será capaz de identificar corretamente (ou com bom nível de precisão) casos novos além daqueles antes exibidos.
Programação clássica x Aprendizado de Máquina
Suponha, por exemplo, que queremos identificar em uma pilha de fotos aquelas que contêm imagens de gatos ou cachorros. O código contendo os algoritmos é alimentado com fotos dos animais, cada uma devidamente etiquetada. Uma forma de avaliação de erro da previsão é fornecida juntamente com um algoritmo flexível que pode ser alterado automaticamente de forma a minimizar os erros da avaliação. Por meio da leitura repetida destas imagens o algoritmo é modificado para produzir o menor erro possível de leitura.
Treinamento de máquina
A este processo chamamos de treinamento. Em terminologia técnica dizemos que ele consiste em alterar os parâmetros do algoritmo de forma a minimizar os erros. Uma vez encontrados estes parâmetros o algoritmo pode ser usado para identificar novas fotos contendo gatos ou cachorros. Ao treinamento feito com o uso de dados etiquetados é denominado supervised learning (aprendizado supervisionado). É também possível submeter à análise do computador um conjunto de dados não identificados com a demanda de que o o algoritmo identifique padrões de forma autônoma e classifique elementos de um conjunto por similaridade desses padrões. No unsupervised learning (aprendizado não supervisionado) é possível que o sistema inteligente distinga padrões que mesmo um humano não seria capaz de perceber.
Machine learning é um método de análise e processamento de dados que automatiza a construção do algoritmo de análise.
O treinamento de máquinas depende da velocidade e capacidade de computadores mas, também, do acesso à informação ou dados. Esse acesso é fornecido pela atual conectividade entre fontes diversas de dados, armazenados de forma estruturada ou não. A habilidade dos computadores de realizar uma análise sobre um volume muito grande desses dados leva ao conceito de Big Data. A operação de busca e coleta desses dados é a atividade de Data Mining (mineração de dados) enquanto a seleção e interpretação desses dados é eficientemente realizada por sistemas inteligentes.
Embora os primeiros passos na construção de sistemas de aprendizado tenham sido inspirados no funcionamento de cérebros e neurônios humanos (ou animais), as chamadas redes neurais artificiais não são projetadas como modelos realistas da arquitetura ou funcionalidade biológica. A expressão deep learning ou aprendizado profundo se refere apenas às múltiplas camadas usadas para o aprendizado artificial. A plasticidade do cérebro biológico, que é a capacidade de partes do cérebro de se reordenar para cumprir tarefas diferentes daquelas em que estava inicialmente treinado, levantou a hipótese de que algoritmos simples e comuns podem ser especializados para resolver tarefas diversas. Reconhecimento de imagens ou textos, por exemplo, podem ser efetuados por estruturas similares. A neurociência mostrou que a interação de partes simples pode exibir comportamento inteligente e complexo. Considerando as grandes lacunas existentes no entendimento da inteligência biológica, a memória e outras funções dos organismos vivos, é de se esperar que os avanços nessa área da ciência, juntamente com a evolução dos computadores, ainda venha a oferecer guias importantes para o aperfeiçoamento da inteligência artificial.
Esta é uma seção mais técnica que pode ser lida por último. Nesse caso pule para a seção Aquisição de Dados.
Esta seção apresenta uma formalização um pouco mais rigorosa dos conceitos do R como linguagem de programação. Em uma primeira leitura, para aqueles que ainda estão se familiarizando com a linguagem, ela pode ser pulada e lida mais tarde. Ela contém um pouco de repetição do material já visto, para fins de completeza.
Objetos
R é uma linguagem de programação de array, funcional e orientada a objeto. Todos os elementos de R, variáveis de dados e funções, são objetos. Não se pode acessar locais da memória diretamente e todos os objetos usados na execução de um programa são armazenados em memória RAM. Isso acaba tendo um peso importante quando se processa um grande volume de dados.
Linguagens de programação de arrays (também chamadas de linguagens vetoriais ou multidimensionais) são linguagens onde operações sobre objetos multidimensionais (vetores, matrizes, etc.) generalizam as operações sobre escalares de forma transparente. Elas permitem um código mais conciso e legível.
Todos os objetos possuem atributos que são meta-dados descrevendo suas características. Estes atributos podem ser listados com a função attributes() e definidos com a função attr(). Um desses atributos, bastante importante, é a classe de um objeto pois as funções de R usam essa informação para determinar como o objeto deve ser manipulado. A classe de um objeto pode ser lida ou alterada com a função class().
Existem os seguintes tipos de dados: Lógico ou booleano (logic), numérico (numeric), inteiro (integer), complexo (complex), caracter (character) e Raw.
Estes dados podem ser agrupados em estruturas de dados. Existem dois tipos fundamentais de estruturas: vetores atômicos e vetores genéricos. Vetores atômicos são matrizes de qualquer dimensão contendo um único tipo de dados. Vetores genéricos são também chamados de listas e são compostas por vetores atômicos. Listas são recursivas, no sentido de que podem conter outras listas.
Uma variável não precisa ser inicializada nem seu tipo declarado, sendo determinado implicitamente a partir do conteúdo do objeto. Seu tamanho é alterado dinamicamente.
Não existe o tipo “escalar” em R. Um escalar é simplesmente um vetor com um único elemento. Portanto a atribuição u <- 1 é apenas um atalho para u <- c(1).
Uma matriz é um vetor atômico acrescentado de um atributo dim com dois elementos (o número de linhas e de colunas). No exemplo seguinte, um vetor é transformado em uma matriz e depois recuperado como vetor:
> v <- 1:12
> print(v)
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> class(v)
[1] "integer"
> x <- c(1,2,3,4,5,6,7,8)
> class(x)
[1] "numeric"
> attr(v, "dim") <- c(2,6)
> print(v)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 3 5 7 9 11
[2,] 2 4 6 8 10 12
> class(v)
[1] "matrix"
> # Um atributo arbitrário pode ser incluído
> attr(v, "nome") <- "minha matriz"
> attributes(v)
$dim
[1] 2 6
$nome
[1] "minha matriz"
> attr(v, "nome") <- NULL # o atributo é removido
> attributes(v)
$dim
[1] 2 6
> # Um atributo pode ser alterado
> dim(v) <- c(3,4)
> print(v)
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> # Removido o atributo "dim" v volta a ser um vetor
> attr(v, "dim") <- NULL
> v
[1] 1 2 3 4 5 6 7 8 9 10 11 12
A atribuição v <- 1:4 é idêntica à v <- c(1:4) e análoga, mas não idêntica à v <- c(1, 2, 3, 4). Nos dois primeiros casos o resultado é um vetor de inteiros. No terceiro temos um vetor numérico (de ponto flutuante).
Existem funções para a marcação de atributos: dim(), dimnames(), names(), row.names(), class() e tsp() (usado para a criação de séries temporais). Estas funções são preferíveis à simplesmente usar attr(vetor, "atributo") porque fazem um tratamento e análise dos parâmetros usados, emitindo notificações de erros mais detalhadas.
A igualdade entre objetos atômicos pode ser testada com o uso do operador ==, que verifica recursivamente a identidade de cada um dos elementos dos objetos comparados, ou da função identical(), que verifica a igualdade completa entre os dois objetos.
> a <- c(1,3,5); b <- c(1,3,5); c <- c(1,2,5)
> a==b
[1] TRUE TRUE TRUE
> a==c
[1] TRUE FALSE TRUE
> identical(a,b)
[1] TRUE
> identical(a,c)
[1] FALSE
Listas e Data Frames
As listas são coleções de vetores atômicos, não necessariamente de mesmo tipo. Elas são recursivas no sentido de que podem ter outras listas como seus elementos. Data frames são listas onde todos os vetores possuem o mesmo comprimento. Muitas funções recebem listas como argumentos ou retornam listas.
Para exemplificar vamos usar uma lista contendo as 5 primeiras observações do data frame warpbreaks, com 3 variáveis.
> quebras <- head(warpbreaks, n=5)
> quebras
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
> # Usamos unclass() para ver seus componentes
> unclass(quebras)
$breaks
[1] 26 30 54 25 70
$wool
[1] A A A A A
Levels: A B
$tension
[1] L L L L L
Levels: L M H
attr(,"row.names")
[1] 1 2 3 4 5
> # Usamos attributes() para ver seus atributos
> attributes(quebras)
$names
[1] "breaks" "wool" "tension"
$row.names
[1] 1 2 3 4 5
$class
[1] "data.frame"
A igualdade entre objetos não atômicos não é implementado com o operador ==. Neste caso é necessário usar a função identical(), que verifica a igualdade completa entre os dois objetos.
> u <- list(v1=1,v2=2); v <- u
> v==u
Error in v == u : comparison of these types is not implemented
> identical(u,v)
[1] TRUE
> # identical testa a identidade entre quaisquer dois objetos:
> f <- function(x,y) x+y; g <- function(x,y) x+y
> identical(f,g)
[1] TRUE
Agrupamento k-means é um método de agrupamento de dados muito utilizado em data mining que busca realizar uma partição de um número de observações em k grupos próximos de uma média comum. O resultado é o particionamento do espaço de dados nas chamadas células de Voronoi.
A função unclass() retorna uma cópia de seu argumento sem seus atributos de classe. attributes() retorna uma lista com os atributos de seu argumento.
Selecionar partes de uma lista é uma operação importante em R. Para ilustrar algumas operações vamos usar o data frameiris que é uma lista contendo 5 vetores atômicos. Ela contém os campos (ou observações) Sepal.Length, Sepal.Width, Petal.Length, Petal.Width e Species. Relembrando, a função unclass(iris) exibe todos os valores em cada campo e seus atributos, separadamente. A função attributes(iris) exibe apenas os atributos. No exemplo abaixo aplicamos o agrupamento K-means usando a função kmeans(). Em seguida exploramos o objeto retornado que é uma lista.
> head(iris, n=2)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
> # Para selecionar apenas os 4 primeiros campos usamos iris[1:4]
> kGrupo <- kmeans(iris[1:4],3)
> typeof(kGrupo) # para ver de que tipo é o objeto
[1] "list"
> length(kGrupo) # kGrupo é uma lista com 9 elementos
[1] 9
> print(kGrupo) # para listar todos os elementos do objeto
K-means clustering with 3 clusters of sizes 50, 38, 62
Cluster means:
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 6.850000 3.073684 5.742105 2.071053
3 5.901613 2.748387 4.393548 1.433871
Clustering vector:
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[31] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 3 2 3 3 3 3 3 3 3
[61] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 3 3 3 3 3 3 3 3 3 3 3 3
[91] 3 3 3 3 3 3 3 3 3 3 2 3 2 2 2 2 3 2 2 2 2 2 2 3 3 2 2 2 2 3
[121] 2 3 2 3 2 2 3 3 2 2 2 2 2 3 2 2 2 2 3 2 2 2 3 2 2 2 3 2 2 3
Within cluster sum of squares by cluster:
[1] 15.15100 23.87947 39.82097
(between_SS / total_SS = 88.4 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss"
[7] "size" "iter" "ifault"
> str(kGrupo)
List of 9
$ cluster : int [1:150] 1 1 1 1 1 1 1 1 1 1 ...
$ centers : num [1:3, 1:4] 5.01 6.85 5.9 3.43 3.07 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:3] "1" "2" "3"
.. ..$ : chr [1:4] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width"
$ totss : num 681
$ withinss : num [1:3] 15.2 23.9 39.8
$ tot.withinss: num 78.9
$ betweenss : num 603
$ size : int [1:3] 50 38 62
$ iter : int 2
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
> # A lista contém os seguintes atributos
> attributes(kGrupo)
$names
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
$class
[1] "kmeans"
> # sapply(objeto, class) exibe a classe de cada elemento na lista
> # A função sapply é tratada com maiores detalhes na próxima seção
> sapply(kGrupo, class)
cluster centers totss withinss tot.withinss betweenss
"integer" "matrix" "numeric" "numeric" "numeric" "numeric"
size iter ifault
"integer" "integer" "integer"
> # Podemos visualizar simultaneamente o segundo elemento, "centers"
> # que fornece uma matriz com os valores do centro de cada agrupamento
> e size, 7º elemento, com o número de pontos em cada grupo
> kGrupo[c(2,7)]
$centers
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 6.850000 3.073684 5.742105 2.071053
3 5.901613 2.748387 4.393548 1.433871
$size
[1] 50 38 62
> # Para visualizar o segundo componente da lista kGrupo,
> # que é uma matriz, usamos
> kGrupo[2]
$centers
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 6.850000 3.073684 5.742105 2.071053
3 5.901613 2.748387 4.393548 1.433871
> # Para ver apenas os componentes desta matriz:
> kGrupo[[2]]
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 6.850000 3.073684 5.742105 2.071053
3 5.901613 2.748387 4.393548 1.433871
> # O mesmo resultado seria obtido por kGrupo$centers
> # Para listar a primeira linha da matriz
> kGrupo[[2]][,1]
1 2 3
5.006000 6.850000 5.901613
> # Para listar a primeira coluna da matriz
> kGrupo[[2]][1,]
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.006 3.428 1.462 0.246
> # Para listar o primeiro elemento da primeira linha
> kGrupo[[2]][1,1]
[1] 5.006
> # que é o mesmo que kGrupo$centers[1,1]
Funções em R
Quase tudo em R é uma função. Até os operadores comuns são funções. A declaração 2 + 3 é, na verdade, uma forma sintética para "+"(2, 3).
> '+'(2,3)
[1] 5
> "*"(13, 9)
[1] 117
Em funções, parâmetros são passados por valor e não por referência. Isso significa que um objeto passado como parâmetro é copiado e a cópia passada para a função. O objeto original não é alterado. Além disso variáveis definidas no corpo de funções são locais e não podem ser usadas fora dela. Para tornar globa uma variável usada dentro de uma função podemos usar o operador de "super atribuição" <<-. Considere, por exemplo, o código abaixo.
> f <- function(x) x <- x^2
> u <- c(1,2,3)
> v <- f(u)
> v
[1] 1 4 9
> u
[1] 1 2 3
> # x é local à função
> print(x)
Error: object 'x' not found
> # Se necessário tornar x global fazemos
> f <- function(x) x <<- x^2
> v <- f(x)
> x
[1] 1 4 9
Funções podem ser usadas recursivamente (ou sejam, podem fazer chamadas a si mesmas). Dois exemplos são mostrados abaixo: o primeiro calcula o fatorial de um inteiro, o segundo exibe a sequência de Fibonacci com n elementos.
> fatorial <- function(x) {
if (x == 0) return (1)
else return (x * fatorial(x-1))
}
> fatorial(0)
[1] 1
> fatorial(6)
[1] 720
> # Obs.: a mesma função poderia ser definida em forma mais compacta como
> fatorial <- function(x) ifelse (x == 0, 1, x * fatorial(x-1))
> # A sequência de Fibonacci:
> fibonacci <- function(n) {
if(n <= 0) return("Nada")
fib <- function(m) ifelse(m <= 1, m, fib(m-1) + fib(m-2))
seq <- c(0)
if (n>1) { for(i in 1:(n-1)) seq[i+1] <- fib(i) }
print("Sequência de Fibonacci:")
print(seq)
}
> fibonacci(9)
[1] "Sequência de Fibonacci:"
[1] 0 1 1 2 3 5 8 13 21
Funções apply(), lapply(), sapply(), tapply()
A função apply() recebe como argumentos uma coleção de objetos (data frame, lista, vetor, etc.), o parâmetro MARGIN (que informa onde será aplicada a função) e uma função (qualquer função pode ser usada). Ela serve para executar alguma operação sobre essa coleção. Seu objetivo é principalmente o de evitar o uso de laços ou loops. Ela tem a seguinte estrutura:
apply(X, MARGIN, FUN)
onde:
x: uma matriz ou array
MARGIN=n : onde n = 1 ou 2, definindo onde a função será aplicada:
se n=1: a função será aplicada nas linhas
se n=2: função aplicada nas colunas
se n=c(1,2): função aplicada nas linhas e colunas
FUN: define função a ser usada.
Podem ser funções internas (mean, median, sum, min, max, ...)
ou definidas pelo usuário
> # Usando a matriz v, já definida:
> print(v)
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> # A média das colunas
> apply(v,2,mean)
[1] 2 5 8 11
> # A soma das colunas
> apply(v,2,sum)
[1] 6 15 24 33
> minimosNasLinhas <- apply(v, 1, min)
> print(minimosNasLinhas)
[1] 1 2 3
A função lapply() recebe como argumentos uma coleção de objetos (data frame, lista, etc.) e uma função. Ela executa a função sobre todos os elementos da coleçao e retorna um objeto do tipo lista:
lapply(X, FUN)
onde:
X: vetor, lista, data frame, ...
FUN: Função a ser aplicada a cada elemento de X
Podem ser funções internas ou definidas pelo usuário
Para exemplificar aplicaremos a função tolower() para reduzir a letras minúsculas todas as palavras de um vetor de caracteres:
> partes <- c("RODAS","MOTOR","CARBURADOR","PNEUS")
> partesMinuscula <- lapply(partes, tolower)
> print(partesMinuscula)
[[1]]
[1] "rodas"
[[2]]
[1] "motor"
[[3]]
[1] "carburador"
[[4]]
[1] "pneus"
> # Esta lista pode ser convertida em um vetor usando-se unlist:
> partesMinuscula <- unlist(partesMinuscula)
> print(partesMinuscula)
[1] "rodas" "motor" "carburador" "pneus"
A função sapply() recebe como argumentos uma coleção de objetos (data frame, lista, etc.) e uma função. Ela age da mesma forma que lapply() mas retorna um vetor ou uma matriz:
sapply(X, FUN)
onde:
X: vetor, lista, data frame, ...
FUN: Função a ser aplicada a cada elemento de X
Podem ser funções internas ou definidas pelo usuário
Usaremos a função sapply() com o data frame cars que traz uma coleção de observações sobre velocidades e distâncias percorridas até repouso em cada velocidade em automóveis (em 1920) para encontrar os valores mínimos em cada coluna:
> # para ver a estrutura do data frame:
> str(cars)
'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
> lMinimos <- lapply(cars, max)
> sMinimos <- sapply(cars, max)
> print(lMinimos)
$speed
[1] 25
$dist
[1] 120
> print(sMinimos)
speed dist
25 120
O exemplo abaixo mostra o uso de lapply() e sapply() junto com uma função do usuário. Ela retorna os valores do data frame que estão abaixo da média em cada coluna. Neste caso elas retornam valores iguais, como se pode ver com o uso de identical():
A função tapply() calcula um valor usando uma função (mean, median, min, max, ...) sobre os dados de um objeto agrupados para cada valor de uma variável de fator dada.
tapply(X, INDEX, FUN = NULL)
onde:
X: um objeto, geralmente um vetor
INDEX: uma lista contendo fatores
FUN: a função a ser aplicada sobre os elementos de X
Para ilustrar o uso desta função vamos usar o data frame irisCalculamos primeiro a média dos comprimentos de sépalas para todas as espécies. Depois calculamos as médias para cada espécie em separado, setosa, versicolor, virginica.
Em seguida usamos o data frame mtcars para calcular o consumo médio dos carros, agrupados por número de cilindros (cyl = 4, 6, 8) e tipos de transmissão, am = 0 (automático), 1 = (manual).
> attach(iris)
> # O comprimento médio de todas as sépalas é
> mean(Sepal.Length)
[1] 5.843333
> # O comprimento médio das sépalas agrupadas por espécie:
> tapply(Sepal.Length, Species, mean)
setosa versicolor virginica
5.006 5.936 6.588
> detach(iris)
> # Usando mtcars:
> attach(mtcars)
> # O consumo médio para todos os carros é
> mean(mtcars$mpg)
[1] 20.09062
> # O consumo médio dos carros, agrupados por cilindros e tipo de transmissão
> tapply(mpg, list(cyl, am), mean)
0 1
4 22.900 28.07500
6 19.125 20.56667
8 15.050 15.40000
> # Para efeito de conferência, calculamos a media de mpg para am=0 e cyl=8
> L <- mtcars[cyl==8 & am==0,]
> # L contém apenas carros com am=0 e cyl=8
> mean(L$mpg)
[1] 15.05
> detach(mtcars)
Lembramos que em R os índices começam em 1 e não 0, como em muitas outras linguagens.
Ambientes (environments) e escopo
R armazena seus objetos em memória RAM dentro de ambientes ou environments. Um environment fica definido por uma lista que associa os nomes dos objetos nele carregados com seus valores. Eles existem principalmente para organizar estes objetos e a forma como R os encontra. Cada ambiente está ligado a um pai (um parent environment) fazendo com que os ambientes formem uma estrutura de árvore que termina no ambiente de nível mais alto que se chama R_EmptyEnv. Quando se inicia uma sessão o R se encontra no ambiente global, global environment, denominado R_GlobalEnv, também chamado de área de trabalho do usuário. Quando o nome de um objeto é invocado em código o interpretador de R busca na lista do ambiente atual, que pode ser visto com a função environment(). Se não encontrado o nome é procurado no ambiente pai, e assim sucessivamente, até que o último é alcançado.
Um novo ambiente pode ser criado com a função new.env() e objetos dentro deste ambiente com a função assign(). Estes objetos podem ser recuperados através da função get() ou da notação ambiente$variavel. A função exists("variavel", envir = ambiente) verifica a existência de variavel no ambiente, enquanto os objetos em um ambiente são listados com ls(ambiente), como se ilustra abaixo:
> environment() # exibe ambiente atual
<environment: R_GlobalEnv>
> var <- "este objeto está em Global Env" # cria objeto em Global_Env
> novoEnv <- new.env()
> assign(var, "novo objeto em novoEnv", env=novoEnv)
> ls()
[1] "novoEnv" "var"
> var
[1] "este objeto está em Global Env"
> get(var, env=novoEnv)
[1] "novo objeto em novoEnv"
> # A notação de "$" pode ser usada:
> novoEnv$var <- " outro valor para objeto em novoEnv"
> var
[1] " este objeto está em Global_env"
> novoEnv$var
[1] " outro valor para objeto em novoEnv"
> cat("var em global_env -->", var, "\nvar em novoEnv -->", novoEnv$var)
var em global_env --> este objeto está em Global Env
var em novoEnv --> novo objeto em novoEnv
> # Para ver o ambiente pai de novoEnv
> parent.env(novoEnv)
<environment: R_GlobalEnv>
> novoEnv$x <- 1 $ insere nova variável no ambiente
> ls(envir=novoEnv)
[1] "var" "x"
> exists("x", envir = novoEnv)
[1] TRUE
> # Um ambiente pode ser criado como filho de qualquer outro ambiente
> e2 <- new.env(parent = outroEnv)
> parent.env(e2)
> # Uma variável será criada em e2
> e2$teste <- 123
> # e2 é filho de novoEnv que está em R_GlobalEnv
> # A variável teste não será encontrada em R_GlobalEnv (pois reside em um nível abaixo)
> teste
Error: object 'teste' not found
> # O objeto está no ambiente e2
> e2$teste
[1] 123
> # Para testar se um objeto é um ambiente
> is.environment(e2)
[1] TRUE
> # Observe que a variável que contém o ambiente global é .GlobalEnv
> is.environment(.GlobalEnv)
[1] TRUE
> # Seu atributo name é "R_GlobalEnv"
> environmentName(environment())
[1] "R_GlobalEnv"
A função abaixo percorre os ambientes de modo hierárquico à partir de R_GlobalEnv subindo para os pais até o último ambiente, R_EmptyEnv que é o último ambiente, sem pai. A função search() exibe os ambientes na ordem hierárquica, a mesma ordem usada para a procura de um objeto.
> exibirArvore <- function() {
a <- environment()
repeat {
print(environmentName(a))
if (environmentName(a) == "R_EmptyEnv") break
a <- parent.env(a)
}
}
> exibirArvore()
[1] ""
[1] "R_GlobalEnv"
[1] "tools:rstudio"
[1] "package:stats"
[1] "package:graphics"
[1] "package:grDevices"
[1] "package:utils"
[1] "package:datasets"
[1] "package:methods"
[1] "Autoloads"
[1] "base"
[1] "R_EmptyEnv"
> # A função environment() permite descobrir em que
> # ambiente está uma função:
> environment(exibirArvore)
<environment: R_GlobalEnv>
> search()
[1] ".GlobalEnv" "tools:rstudio" "package:stats" "package:graphics"
[5] "package:grDevices" "package:utils" "package:datasets" "package:methods"
[9] "Autoloads" "package:base"
Observe que a primeira chamada à função environmentName(a) retorna um string vazio, que é o nome do ambiente interno à função. Quando uma função é criada ela gera a criação de um ambiente próprio onde ficam as variáveis definidas em seu corpo. Para exemplificar a existência deste ambiente dedicado à definição da função criamos abaixo a função minhaFuncao(x) que retorna outra função que soma x ao seu argumento. O valor de x passado na definição da função não é alterado com uma definição de seu valor fora do corpo da função.
> f <- function() {
x <- 1
print(environment())
print(parent.env(environment()))
}
> f()
<environment: 0xd31ee80>
<environment: R_GlobalEnv>
> minhaFuncao <- function(x) { function(y) x+y }
> h <- minhaFuncao(100)
> h(10)
[1] 110
> x <- 3
> h(2)
[1] 102
> # Internamente ao ambiente de h, x = 100
> # h vive no ambiente environment(h).
> # Neste ambiente existe apenas a variável:
> ls(environment(h))
[1] "x"
No caso acima o R criou o ambiente "0xd31ee80" que é filho de R_GlobalEnv. A variável x só existe dentro do ambiente da função.
Uma função (e seu ambiente) podem ser colocados em qualquer outro ambiente usando-se a função environment(funcao ) <- outroAmbiente. No exemplo abaixo a variável anos é definida em .GlobalEnv e dentro do corpo da função quantosAnos. Três outras funções são definidas dentro desta primeira: anosLocal (que usa a variável local, a=10), anosGlobal (que usa a variável em globalEnv, a=10). Na execução da função semBusca a variável está localmente definida, a=1 e nenhuma busca é necessária para a sua execução.
O exemplo abaixo mostra que quando a função f1 é gerada seu ambiente foi armazenado junto com ela. Nele estão as variáveis a=2, b=3. Este ambiente fica inalterado mesmo depois que a variável global a foi alterado.
> funcaoSoma <- function(a, b) {
f <- function(x) return( x + a + b )
return( f )
}
> a <- 2; b <- 3
> f1 <- funcaoSoma(a, b)
> f1(3)
[1] 8
> a <- 4
> f2 <- criarFuncao(a, b)
> f2(3)
[1] 10
> f1(3)
[1] 8
> # Para forçar a permanência de uma variável após
> # a conclusão da função usamos a atribuição "<<-"
> f <- function(){w<-13}
> f() # não há retorno
> w
Error: object 'w' not found
> f <- function(){w<<-13}
> f()
> w
[1] 13
Para alocar explicitamente variáveis para um determinado ambiente, além da notação de "$" pode ser usado:
Se o nome da biblioteca onde está uma função é previamente conhecido é possível evitar a busca pela definição de uma função usando o operador ::. O mesmo procedimento pode ser usado para forçar o uso de uma função específica quando existem outras de mesmo nome definidas. Se o pacote não está carregado o operador ::: pode ser usado.
> x <- c(123, 234, 345, 242, 34, 100)
> stats::sd(x)
[1] 113.9731
> Wilks
Error: object 'Wilks' not found
> stats:::Wilks
> # ... A definição da função é exibida
> # Para verificar o que significa o operador :::
> `:::`
function (pkg, name)
{
pkg <- as.character(substitute(pkg))
name <- as.character(substitute(name))
get(name, envir = asNamespace(pkg), inherits = FALSE)
}
Decorre do que foi dito que o escopo de uma variável em R é o seguinte: a variável deve estar definida no ambiente local em que é usada ou em algum ambiente pai. Se variáveis com o mesmo nome estão definidas dentro da hierarquia de ambientes será usada aquela que for encontrada primeiro, ou seja, no ambiente de menor posição.
Muitas linguagens de programação não permitem (ou dsencorajam) o uso de variáveis globais pois elas podem tornar tornar o código mais frágil, sujeito a erros. No R elas podem ser usadas e funções podem acessar variáveis em ambientes acima delas. Mas essa não é sempre uma boa prática. Para projetos com algum nível de complexidade é recomendado que se passe todas as variáveis necessárias na definição da função ou se faça uma verificação rigorosa de escopos, oferecendo alternativas para o caso em que essas variáveios estão ausentes ou tenham tipos não apropriados. Caso as variáveis globais sejam usadas é uma boa prática dar a elas nomes identificadores tais como global.var para evitar que conflituem com outras definidas localmente.
Otimização e Pesquisa de Erros (debugging)
É possível pré-compilar uma função usando a biblioteca compiler (e sua função cmpfun()) que gera uma versão em byte-code. Nas linhas abaixo, fizemos uma medida dos tempos gastos nas funções f e sua versão pré-compilada g.
Algumas práticas podem ser aplicadas se um código estiver demorando muito para ser executado. Uma delas consiste em envolver o código a ser verificado com os comandos Rprof() e Rprof(NULL) e depois executar a função summaryRprof() para ver um resumo dos tempos gastos na execução de cada funcão.
> library(compiler)
> f <- function(n, x) { for (i in 1:n) x <- x + (1 + x)^(-1)}
> g <- cmpfun(f)
> medirTempos <- function() {
Rprof()
inicio <- Sys.time()
f(10000000,1)
duracao1 <- Sys.time() - inicio
print(duracao1)
inicio <- Sys.time()
g(10000000,1)
duracao2 <- Sys.time() - inicio
print(duracao2)
print(duracao1 - duracao2)
Rprof(NULL)
summaryRprof()
}
> # Executamos a função para medir os tempos gastos
> medirTempos()
Time difference of 1.003972 secs
Time difference of 0.9667881 secs
Time difference of 0.03718424 secs
$by.self
self.time self.pct total.time total.pct
"f" 1.00 51.02 1.00 51.02
"g" 0.96 48.98 0.96 48.98
$by.total
total.time total.pct self.time self.pct
"medirTempos" 1.96 100.00 0.00 0.00
"f" 1.00 51.02 1.00 51.02
"g" 0.96 48.98 0.96 48.98
$sample.interval
[1] 0.02
$sampling.time
[1] 1.96
A função compilada g é um pouco mais rápida que sua original. Em blocos maiores e mais demorados de código a diferença pode ser significativa.
Quando dados são importados para uma sessão de R sempre é uma boa prática ler apenas os campos necessários. Por exemplo, suponha que se deseje importar dados de uma tabela contido em um arquivo de texto arquivo.txt que contém 5 variáveis, a primeira de caracter e as 4 demais numéricas, mas apenas as duas primeiras serão usadas. A importação seletiva pode ser obtida usando-se o parâmetro colClasses. Colunas associadas com NULL serão ignoradas:
> # Para importar todos os dados usamos:
> dfLeitura <- read.table(arquivo.txt, header=TRUE, sep=',')
> # Seria mais eficiente e rápido selecionar apenas os campos desejados:
> dfLeitura <- read.table(arquivo.txt, header=TRUE, sep=',',
colClasses=c("character", "numeric", NULL, NULL, NULL))
A execução de uma operação vetorializada é mais ágil do que percorrer um laço sobre os elementos de um vetor ou matriz. Isso é obtido com o uso de funções projetadas para lidar com vetores de forma otimizada. Alguns exemplo na instalação básica são as funções colSums(), colMeans(), rowSums(),
e rowMeans(). O pacote matrixStats, plyr, dplyr, reshape2, data.table também incluem diversas funções otimizadas para esse tipo de operação.
Para mostrar isso usamos, desta vez, a função system.time(operação) que mede o tempo de execução da operação.
> partes <- 1:100000000
> soma1 <- function(x) print(sum(x))
> soma2 <- function(x) {
s <- 0
for (u in x) s <- s + u
print(s)
}
> system.time(soma1(partes))
[1] 5e+15
user system elapsed
0 0 0
> system.time(soma2(partes))
[1] 5e+15
user system elapsed
4.775 0.000 4.775
Em outro exemplo fazemos a soma dos elementos de uma matriz com 1000 colunas e 1000 linhas (portanto com 1 milhão de elementos).
> set.seed(1234)
> # Cria uma matriz 10000 x 10000
> matriz <- matrix(rnorm(100000000), ncol=10000)
> # Cria função para somar elementos de cada coluna
> somar <- function(x) {
somando <- numeric(ncol(x))
for (i in 1:ncol(x)) {
for (k in 1:nrow(x)) {
somando[i] <- somando[i] + x[k,i]
}
}
}
> # Executa a função e mede o tempo gasto
> system.time(somar(matriz))
user system elapsed
17.231 0.000 17.230
> # mede o tempo de execução de colSums
> system.time(colSums(matriz))
user system elapsed
0.108 0.000 0.107
Como vimos o cálculo é realizado aproximadamente 160 vezes mais rapidamente pela função vetorializada. Essa diferença pode ser muito maior, dependendo da situação analisada.
Sempre é mais eficiente inicializar um objeto em seu tamanho final e depois preenchê-lo de que partir de um objeto vazio e ajustar seu tamanho progressivamente.
> set.seed(1234)
> u <- rnorm(1000000)
> uQuadrado <- 0
> system.time(for (i in 1:length(u)) uQuadrado[i] <- u[i]^2)
user system elapsed
0.361 0.000 0.361
> # Tempo de execução para a mesma operação com
> # a variável inicializada em seu tamenho final
> rm(uQuadrado)
> uQuadrado <- numeric(length=1000000)
> system.time(for (i in 1:length(u)) uQuadrado[i] <- u[i]^2)
user system elapsed
0.11 0.00 0.11
> # Usando a função vetorializada
> uQuadrado <- numeric(length=1000000)
> system.time(uQuadrado <- u^2)
user system elapsed
0.002 0.000 0.001
A operação é muito mais rápida quando se usa a função vetorializada. Além da exponenciação, as funções adição, multiplicação e outras operações binárias do tipo são todas vetorializadas.
Gerenciamento de memória
Como já mencionado, R mantém em memória RAM todos os seus objetos em uso, o que pode introduzir lentidão ou mesmo a impossibilidade de realizar alguma operação. Mensagens de erro sobre a insuficiência de espaço de memória indicam que o limite foi excedido. Este limite depende, é claro, do hardware usado, do sistema operacional e da compilação de R (a versão de 64 bits é mais eficiente). Para grandes volumes de dados é preciso procurar escrever um código eficiente para acelerar a execução com o eventual armazenando dados em meio externo para diminuir a sobrecarga na memória RAM e através do uso de rotinas estatísticas especializadas, escritas para maximar a eficiência no manipulação de dados.
Para uma programação mais eficiente é recomendável aplicar operações sobre vetores sempre que possível. As funções internas para manipulação vetores, matrizes e listas (tais como ifelse, colMeans e rowSums) são mais eficientes que loops (for e while). Matrizes usam menos recursos que data frames. No uso de read.table() para carregar dados externos para um data frame especifique as opções colClasses e nrows explicitamente, defina comment.char = "" e marque como NULL as colunas não necessárias. Ao ler dados externos para uma matriz, use a função scan().
Como mencionado, sempre que possível crie objetos com seu tamanho final ao invés de aumentar seu tamanho gradualmente, inserindo valores. Teste seu código usando uma amostra de dados menor para otimizá-lo e remover erros. Exclua objetos temporários ou desnecessários usando rm(objeto). Após a remoção use gc() para iniciar a coleta de lixo. Use a função .ls.objects() para listar objetos no espaço de trabalho e encontrar o que ocupa mais memória e o que pode ser removido.
Use as funções Rprof(), summaryRprof() e system.time() para cronometrar o tempo e gasto em cada função e descobrir qual delas você deveria procurar otimizar. Rotinas externas compiladas podem ajudar a acelerar a execução do programa. Com o pacote Rcpp você pode transferir objetos de R para funções C++ e voltar quando são necessárias sub-rotinas otimizadas.
Para volumes de dados for muito grandes existem bibliotecas que incluem a funcionalidade de descarregar dados em bancos de dados externos ou arquivos binários simples e acessar parte deles. Alguns exemplos são:
Biblioteca
Descrição
bigmemory
grava e acessa matrizes em arquivos no disco.
ff
fornece estruturas de dados que podem ser grabadas em disco, agindo como se permanecessem em RAM.
filehash
implementa uma base de dados simples tipo chave-valor gravada em disco
ncdf, ncdf4
fornece interface para arquivos Unidata netCDF
RODBC, RMySQL, ROracle, RPostgreSQL, RSQLite
acesso aos respectivos DBMS externos.
No que se refere à análise dos dados em grandes volumes estão disponíveis:
Pacotes biglm e speedglm: ajuste de modelos lineares lineares e generalizados para grandes conjuntos de dados de uma maneira eficiente em termos de memória. Incluem as funções lm() e glm() para lidar com grandes conjuntos de dados.
Diversos pacotes oferecem funções para operações sobre grandes matrizes produzidas pelo pacote bigmemory. biganalytics oferece agrupamento k-means, estatísticas de coluna e um wrapper para biglm. O pacote bigrf pode ser usado para se adequar às florestas de classificação e regressão. bigtabulate fornece funcionalidade table(), split() e tapply(). O pacote bigalgebra inclui funções avançadas da álgebra linear.
biglars oferece cálculo de regressão para conjuntos grande, usado juntamente com o pacote ff.
O pacote data.table introduz uma versão melhorada de um data frame, com métodos mais rápidos e eficientes para: agregação de dados; junções de intervalo; adição, modificação e exclusão de colunas por referência (sem cópias). Um data.table pode ser usado em qualquer função que receba um data frame como argumento.
Depuração de Erros (debugging)
Qualquer projeto de programação com algum grau de complexidade está sujeito a erros. Depuração de erros ou debugging é o processo de se encontrar e resolver as falhas no código. Por mais interessante que seja escrever um bloco de código para resolver algum problema, encontrar erros pode ser tedioso e demorado. Existem erros que impedem a execução do código causando a emissão de mensagens de erros. Estes são, em geral, os mais fáceis de se encontrar. Mas também existem situações em que o código roda perfeitamente mas produz resultados inesperados e incorretos.
As táticas de debugging envolvem rodar as linhas de código interativamente verificando o valor das variáveis, testar o efeito sobre um conjunto de dados que produzem resultados conhecidos, análise do fluxo do código e do estado da memória a cada instante da execução.
Na programação em R erros são geralmente causados por digitação incorreta do nome de variáveis ou funções e chamadas à funções com parâmetros de tipo incorretos, inclusive quando objetos importados de fontes externas contém partes que são NULL, NaN ou NA e são passados como parâmetros para funções que não fazem a verificação para a existência desses valores.
Função
Efeito
debug()
Marca uma função para debugging.
undebug()
Desmarca uma função para debugging.
browser()
Permite percorrer o código de execução de uma função passo a passo.
trace()
Modifica a função para permite a inserção temporária de de código auxiliar.
untrace()
Cancela a função anterior e remove o código temporário.
traceback()
Imprime a sequência de chamadas a funções que produziram o último erro não capturado.
Durante a depuração com o uso de browser() a tecla executa a linha sob o cursor e passa o foco para a próxima linha. Teclar força a execução até o final da função sem pausas. Digitar exible a pilha de execução (call stack) e interrompe a execução e desloca o foco para o nível imediatamente superior. Também é possível usar comandos como ls(), print() e atribuições no prompt do depurador.
Atualizando R e suas Bibliotecas
A atualização de R pode ser um pouco trabalhosa. Seguem algumas sugestões para usuários de Windows e Linux.
No Windows
Uma forma possível e prática para atualizar a instalação do R no Windows consiste em usar a biblioteca installr. Para isso a bliblioteca deve ser instalada e executada de dentro do próprio console (ou do Rstudio, ou outra IDE).
Como eu não utilizo o Windows esta opção está mencionada aqui como uma sugestão, que eu não experimentei. Ela foi extraída da página R-statistics blog.
> # instalando e carregando a biblioteca
> install.packages("installr")
> require(installr)
> updateR()
A função updateR() iniciará o processo de atualização, verificando se novas versões estão disponíveis. Se a versão instalada for a mais recente a função termina e retorna FALSE. Caso contrário será perguntado se o usuário deseja prosseguir, após a exibição de um sumário das novidades na versão.
Será oferecida ao usuário a opção de copiar as bibliotecas instaladas para a nova versão e, em seguida, a de atualizar estas bibliotecas.
Mac e Linux
A atualização pode ser feita manualmente usando pacotes no website da CRAN.
Tanto no Windows quanto no Linux para atualizar apenas as bibliotecas que foram instaladas com install.packages() basta usar, no console a função update.packages(). A função perguntará quais as bibliotecas você deseja atualizar. Para executar a atualização de todas elas, sem o prompt de consulta digite update.packages(ask = FALSE).
Além de update.packages() existem as funções old.packages() que informa quais as bibliotecas possuem versões mais atuais nos repositórios versões aplicáveis e new.packages() que procura por novas bibliotecas disponíveis e ainda não instaladas, oferecendo a opção de instalá-las.
Obs.: Pacotes instalados por devtools::install_github() não são atualizados pelos procedimento descritos. No Windows eles podem ser atualizados por installr.
No RStudio
Para atualizar o RStudio use o item de Menu: Help > Check for Updates. Para atualizar as bibliotecas use Menu: Tools > Check for Packages updates.
Uma parte importante da análise de dados esta na visualização destes dados em forma gráfica. A representação visual de dados permite, muitas vêzes, o reconhecimento de padrões que dificilmente seriam percebidos apenas com tabelas e números. R fornece várias funções para representar dados graficamente, tanto em gráficos bidimensionais quanto tridimensionais. Em particular dá-se ênfase aos gráficos estatísticos, tais como histogramas, curvas de distribuições, gráfico de barras e outros. Existem métodos gerais que se aplicam à diversas formas básicas de gráficos. Pode-se incluir títulos, nomes para os eixos, cores, representações por pontos linhas e sinais variados e anotações.
A função plot() é a mais básica na geração de um gráfico.
> x <- -10:10; y <- x^2; plot(x,y) # resultado na figura 1
> # Parâmetro para tornar a linha contínua
> plot(x,y, type="l") # resultado na figura 2
Alguns dos parâmetros são listados abaixo:
plot(x, y, ...)
x
coordenadas horizontais dos pontos. Pode ser um objeto numerado.
y
coordenadas verticais dos pontos. Omitido se x é um objeto numerado.
…
Argumentos adicionais (parâmetros gráficos).
Entre os argumentos adicionais:
type =
“p” (pontos), “l” (linhas), “b” (ambos),
“h” (histograma), “s” (degraus), “n” (em branco)
main =
título principal
sub =
subtítulo
xlab =
título para eixo x
ylab =
título para eixo y
asp =
aspecto (razão y/x).
Observe que, se u é um objeto ordenado, então plot usa como coordenada x a ordem dos elementos. Por exemplo:
> u <- rnorm(10)
> # Os dois gráficos seguintes são idênticos
> plot(u)
> plot(1:10, u)
Algumas funções sobreescrevem o gráfico já traçado. É o caso da função lines. É possível alterar características das linhas com os parâmetros lwd (largura da linha) e lty (tipo da linha), como se mostra no exemplo:
> a <- 1:20; b <- a^2
> plot(a, .1*b ,type="l") # linha 1
> lines(a, .2*b , lwd=4 ) # linha 2
> lines(a, .3*b , lwd=2) # linha 3
> lines(a, .4*b , lty=3) # linha 4
> points(a,.5*b, pch=3) # pontos 5
> text(10, 2, "Título do gráfico") # título na posição 10 , 2
As linhas acima resultam no gráfico:
Se vários gráficos devem ser analisados ao mesmo tempo, uma nova instância da janela de saída gráfica pode ser aberta com o comando dev.new() ou X11() (apenas para sistemas tipo Unix). Pode-se navegar entre “devices” gráficos abertos usando dev.new(), dev.next(), dev.prev(), dev.set() e dev.off().
> plot(rnorm(10)) # plota o primeiro gráfico
> dev.new() # abre nova janela
> plot(rnorm(20)) # plota o segundo gráfico
Os gráficos podem ser enviados diretamente para arquivos nos formatos JPEG, BMP, PDF, TIFF, PNG, entre outros. Como exemplo, direcionamos a saída gráfica para um arquivo JPEG:
> # grava arquivo hiperbole.jpg
> jpeg(file='hiperbole.jpg')
> # plota gráfico
> plot(x<- -100:100, 1/x, type='l', main="hipérbole")
> # fecha janela gráfica
> dev.off()
> # Grava arquivo jpeg com a imagem à direita.
Outras funções capazes de escrever por cima de um gráfico já plotado são locator(n) e identify(). A primeira serve para que o se selecione regiões do gráfico utilizando o botão esquerdo do mouse até que se tenha um número n de pontos selecionados (ou até pressionar o botão direito do mouse, para terminar). A cada clique dado com o botão esquerdo do mouse a função retorna no console as coordenadas do clique. Por exemplo:
> x <- 1:100; y <- sqrt(x)
> plot(x,y, type="l")
> text(locator(1), "x é aqui!")
> text(locator(1), "y é aqui!")
> text(locator(5), paste("<", 1:4, ">")
> # A linha acima marca 4 pontos
> # no gráfico, com o texto:
> # "<1>", "<2>", "<3>", "<4>"
> # respectivamente
Para os próximos passos usaremos o dataframe carregado por padrão no R de nome mtcars. Este é um conjunto de dados sobre automóveis com campos mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb. Antes de prosseguir, observe que as quatro formas de notação abaixo são equivalentes:
Na quarta forma usamos y ~ x para representar x como variável independente, y como variável dependente.
Aproveitamos a oportunidade para conhecer uma sintaxe especial. O comando plot( cyl ~ ., data= mtcars ) realiza a plotagem de todos os gráficos de cyl como função de todos os demais campos de mtcars. O promptHit to see next plot: aparece entre as operações.
> attach(mtcars)
> plot(mpg ~ wt)
> abline(lm(mpg ~ wt))
> title("Regressão Linear de Consumo por Peso")
> detach(mtcars)
Para enviar este gráfico para um arquivo pdf basta cercar todas as linhas acima pelos comandos pdf("NomeArquivo.pdf") e dev.off().
A função abline(a,b) traça uma reta sobre o gráfico, recebendo os parâmetros a como a interseção da reta com o eixo y (x = 0) e b como a inclinação da reta. Ela recebe como argumento lm(y~x) que retorna diversos dados sobre a regressão linear da função y~x, entre eles os parâmetros a e b necessários para definar a reta.
A função abline possui outros parâmetros. Entre eles:
abline(a=NULL, b=NULL, h=NULL, v=NULL, col=, ...)
a = interseção com eixo y
b = inclinação da reta
h = y (traça reta horizontal por y)
v = x (traça reta vertical por x)
col = cor: "red", "blue", etc; ou rgb(x,y,z), onde x, y, z ∈ [0, 1]
ou hexadecimal #abcdef; a, ..., f ∈ [0, f], hexadecimal.
Alguns exemplos de uso de abline(). O código seguinte gera os gráficos abaixo:
> plot(x<- 0:10, x) # plotar uma reta
> title("Reta y = x")
> abline(v=4) # reta vertical por x = 4
> abline(v=6, col="blue") # reta vertical por x = 6, azul
> abline(h=8, col="#779900") # outra cor
> # Usando a tabela cars (embutida em R)
> dev.new()
> plot(cars)
> abline(v=c(15,20), col=c("blue", "red"), lty=c(1,2), lwd=c(1, 3), h=40)
Parâmetros Gráficos
O conjunto de parâmetros para construção de gráficos podem ser lidos e (alguns deles) alterados através da função par(). Podem ser características como fonts, cores, eixos e títulos.
par(..., no.readonly = FALSE)
Argumentos:
no.readonly = Booleano. Se TRUE apenas parâmetros que podem ser
alterados pelo usuário são exibidos.
... Outros parâmetros são passados na forma:
par1 = valor1, ..., parn = valorn
Se nenhum parâmetro for fornecido par() exibe uma lista dos parâmetros atuais, par(no.readonly = TRUE) exibe uma lista dos parâmetros que podem ser alterados. Valores alterados dessa forma permanecem válidos durante a sessão.
Para exemplificar suponha que pretendemos ter nossos gráficos plotados com quadrados sólidos ligados por retas. O seguinte código pode ser usado:
> # parâmetros default são armazenados
> oldPar <- par(no.readonly=TRUE)
> par(lty=1, pch=15)
> plot(cars$dist ~ cars$speed, type="b")
> title("Usando quadrados e retas")
> # parâmetros default são restaurados
> par(oldPar)
> # Claro que o mesmo efeito seria obtido com
> plot(cars$dist ~ cars$speed, type="b", lty=1, pch=15)
Alguns parâmetros são listados na tabela:
Parâmetro
Descrição
pch
símbolo usado para marcar pontos.
cex
tamanho do símbolo, relativo ao default. 1 = default, 1.5 is 50% maior, etc.
lty
tipo da linha.
lwd
largura da linha, relativa ao default. Ex.: lwd=2 dupla largura.
Valores de pch, lty
As cores que podem ser alteradas nos gráficos estão listas na tabela seguinte:
Parâmetro
Descrição
col
cor default do gráfico.
col.axis
cor para texto nos eixos.
col.lab
cor para labels nos eixos.
col.main
cor do título.
col.sub
cor do subtítulo.
fg
cor do primeiro plano.
bg
cor de fundo.
Para o parâmetro col algumas funções aceitam valores reciclados. Por ex., se col=c("blue", "green") e três curvas são exibidas então a primeira e a terceira serão azuis, a segunda verde. Cores podem ser especificadas por índice, nome, valores hexadecimais, RGB e HSV. A função colors() exibe uma lista de todas as cores disponíveis, por nome.
Algumas funções permitem a criação de palhetas, vetores com n cores contíguas:
rainbow(n, s = 1, v = 1, start = 0, end = max(1, n - 1)/n, alpha = 1,
heat.colors(n, alpha = 1),
terrain.colors(n, alpha = 1),
topo.colors(n, alpha = 1),
cm.colors(n, alpha = 1))
Parâmetros:
n
número (≥ 1) de cores no vetor.
s, v
“saturação” e “valor” no formato HSV.
start
[0,1] cor inicial para o arco-íris (rainbow).
end
[0,1] cor final para o arco-íris (rainbow).
alpha
[0,1], transparência.
Vamos explorar o uso destas palhetas de cores na próxima seção.
Para especificar o estilo, tamanho e família das fontes os seguintes parâmetros gráficos podem ser usados:
Parâmetro
Descrição
cex
magnificação do texto: 1 = default, 1.5 = 50% maior; 0.5 = 50% menor, etc.
cex.axis
magnificação dos eixos, relativo a cex.
cex.lab
magnificação do texto nos eixos, relativo a cex.
cex.main
magnificação do texto do título, relativo a cex.
cex.main
magnificação do texto do subtítulo, relativo a cex.
família da fonte. Os padrões são serif, sans e mono
Por exemplo, após a aplicação dos parâmetros: par(cex.main=3, cex.lab=1.5, font.lab=2, font.main=4, font.sub=3)
o texto nos gráficos serão representados com: títulos com fontes 3 vezes maior que o padrão definido em cex, eixos magnificados em 1.5, labels em negrito nos eixos, títulos em negrito itálico e subtítulos em itálico.
Para controle das dimensões do gráfico e margens usamos:
Parâmetro
Descrição
pin
largura e altura do gráfico, em polegadas.
mai
vetor com larguras das margens, c(inferior, esquerda, superior, direita) em polegadas.
mai
vetor com larguras das margens, c(inferior, esquerda, superior, direita) em linhas. [default = c(5, 4, 4, 2) + 0.1].
Função barplot()
A função barplot() permite a exibição de gráficos de barras. Um resumo de seus parâmetros está mostrado abaixo.
barplot(height, width = 1, space = NULL, names.arg = NULL,
horiz = FALSE, density = NULL, col = NULL, border = par("fg"),
main = NULL, sub = NULL, xlab = NULL, ylab = NULL, axes = TRUE)
Parâmetros:
height
vetor ou matriz contendo altura das barras.
width
vetor com largura das barras.
space
espaço deixado antes da barras (uma fração da largura).
A função bar plot pode receber uma matriz como argumento. Para ilustrar vamos usar a função table() para tabelar dados no data frame mtcars. Este data frame possui o campo mtcars$carbs que lista o número de carburadores de uma lista de automóveis. Em seguida criamos uma tabela com um teste clínico hipotético para o tratamento da gripe usando um antiviral, vitammina C e um “chazinho”.
> carburadores <- table(mtcars$carb)
> carburadores
1 2 3 4 6 8
7 10 3 10 1 1
> # A tabela mostra que existem 7 modelos com 1 carburador, 10 com 2, etc.
> barplot(carburadores, main="Modelos x carburadores", horiz=TRUE,
names.arg=c("1", "2", "3","4", "6", "8"), xlab="Quantos modelos",
ylab="Número de carburadores", col=rainbow(6))
> testeClinico <- matrix(c(45,9,12,4,31,31,1,10,7), ncol=3, byrow=TRUE)
> cores <-c("#5FC0A0", "#DE7A6B", "#6BA0DE")
> colnames(testeClinico) <- c("Antiviral","Vitamina C","Chazinho")
> rownames(testeClinico) <- c("Melhorou","Sem alteração","Piorou")
> testeClinico
Antiviral Vitamina C Chazinho
Melhorou 45 9 12
Sem alteração 4 31 31
Piorou 1 10 7
> resultado <- as.table(testeClinico)
> barplot(resultado, main="Gripe: teste clínico", xlab="Medicamento",
ylab="Eficácia", col=cores, legend=rownames(resultado))
O código acima gera os gráficos:
O mesmo gráfico, com os dados agrupados por tipo de medicamento testado pode ser obtido ao se acrescentar o parâmetro beside=TRUE que força a exibição de dados lado à lado para uma mesma coluna:
Usando funções de agregamento e passando o resultado para barplot() pode-se representar médias, medianas, desvios padrões e outros em gráficos de barras.
Para experimentar com esta funcionalidade usaremos o dataset embutido com o R denomidado states (US State Facts and Figures). Ele contém dados antigos sobre os 50 estados americanos. Em particular usaremos state.region, um fator contendo as regiões de cada estado (Northeast, South, North Central, West) e state.x77, uma matriz com 50 linhas e 8 colunas com informações sobre os estados. O campo state.x77$Illiteracy contém taxas de analfabetismo nos estados americanos em 1970, como porcentagem da população.
> # Carregamos uma palheta de 4 cores
> cor <- c("#F3E16E", "#6EC6F3", "#6FF36E", "#F36E84")
> reg <- state.region
> levels(reg) # as regiões estão em inglês
[1] "Northeast" "South" "North Central" "West"
# Para traduzir para o português alteramos os levels:
> levels(reg) <- c("Nordeste","Sul","Central Norte","Oeste")
> levels(reg)
[1] "Nordeste" "Sul" "Central Norte" "Oeste"
> # Usamos apenas a 3a. coluna de state.x77 (analfabetismo %)
> analfabetismo <- state.x77[,3]
> # Criamos um dataframe com informações: regiões x analfabetismo
> estados <- data.frame(reg, analfabetismo)
> # Agregamos a informação sobre analfabetismo por região,
> # usando a função mean (média)
> media <- aggregate(estados$analfabetismo, by=list(estados$reg), FUN=mean)
> # para alterar os nomes das colunas
> names(media) <- c("regiao", "taxa")
> # Ordenamos o resultado por taxa de analfabetismo
> media <- media[order(media$taxa),]
> View(media) # resulta na tabela 1
> # plotando o gráfico de barras
> barplot(media$taxa, names.arg=media$regiao, col=cor)
> title("Analfabetismo nos EUA / por região"
> # resultado no gráfico abaixo
O código acima gera o gráfico:
Função pie()
Gráficos de setores ou gráficos de pizza (pie charts) também são úteis para a representação de dados.
vetor de valores, exibidos como áreas dos setores no gráfico.
labels
nomes para legendas dos setores. NA ou “” = sem legenda.
edges
borda externa é um polígono com este número de lados.
clockwise
booleano. Sentido horário ou não das fatias.
init.angle
ângulo inicial (da primeira fatia).
col
vetor de cores de preenchimento das fatias.
main
título do gráfico.
> z <- (-10:10)^2 - 50
> barplot(z, col=rainbow(25), main="Gráfico de barras", ylab="y=x^2-50")
> dev.new()
> legenda <- paste("fatia ",1:16) # gera vetor fatia 1, ..., fatia 16
> cores <- c("#F3E16E", "#6EC6F3", "#6FF36E", "#F36E84")
> pie(rep(1,16), col=cores, labels=legenda, main="Setores")
O seguinte gráfico é gerado: Gráfico de Setores
O código abaixo gera três gráficos de setores (pie charts). As populações listadas para os cinco países mais populosos são dadas em milhões. No gráfico-2 os percentuais (apenas entre estes 5 países) são exibidas. No terceiro gráfico a packageplotrix é usada para desenhar um gráfico em 3 dimensões.
> populacao <- c(1420, 1368, 329, 269, 212)
> pais <- c("China", "India", "EUA", "Indonesia" , "Brasil")
> pie(populacao, labels=pais, main = "população em milhões")
> # Gera Gráfico-1
> pc <- round(populacao/sum(populacao)*100)
> pc # porcentagem de população (entre estes 5 países)
[1] 39 38 9 7 6
> label <- paste(pais, "-", pc, "%", sep="")
> label
[1] "China-39%" "India-38%" "EUA-9%" "Indonesia-7%" "Brasil-6%"
> pie(populacao, labels=label, col=rainbow(length(labels)), main = "população em milhões (%)")
> # Observe que length(labels)=5 e temos 5 cores geradas
> # Gera Gráfico-2
> library(plotrix) # deve ser instalado com install.packages("plotrix")
> pie3D(populacao, labels=label,explode=0.1, main="3D Gráfico setores")
> # Gera Gráfico-3
Os gráficos de setores são podem ser úteis para uma visualização rápida de uma relação entre valores. No entanto podem dificultar a análise mais minuciosa destes dados. Por exemplo, se dois setores tem aproximadamente o mesma área pode ser difícil perceber qual é maior. Em geral o uso de barras é mais recomendado.
Uma alternativa atraente é o fan.plot, carregado junto com a library plotrix. Neste tipo de gráfico os setores são sobrepostos e seus raios variados para que todos apareçam na representação.
> library(plotrix)
> populacao <- c(1420, 1368, 329, 269, 212)
> pais <- c("China", "India", "EUA",
"Indonesia" , "Brasil")
> fan.plot(populacao, labels=pais,
main = "Usando o fan.plot",
col=rainbow(5))
> # O gráfico à direita é gerado.
Histogramas com a função hist()
Histogramas (ou distribuições de frequências) são uma forma de exibir a distribuição de uma variável contínua. A faixa de valores a serem analisados é dividida em classes (que podem ser ou não uniformes). A base de cada retângulo na representação é dada pela extensão da classe e a altura pela quantidade de dados (frequências) dentro de cada classe. Histogramas são criados com a função hist(v) onde v é um vetor numérico.
O parâmetro freq=FALSE gera um gráfico baseado em densidades de probabilidade e não em frequências. O parâmetro break informa em quantos classes os dados devem ser divididos. Por default as classes são divididas uniformemente.
> distUniforme <- runif(1000, 0, 10)
> # gera 1000 valores distribuídos uniformemente, com média 0 e desvio padrão 1
> hist(distUniforme, col=rainbow(10))
> # plota o histograma dessa distribuição
> distNormal <- rnorm(100000, 0, sd=2)
> # gera 10^5 valores distribuídos aleatóriamente com distribuição normal,
> # com média 0 e desvio padrão 2
> hist(distNormal, col=rainbow(12))
> # plota o histograma dessa distribuição
Para os exemplos que se seguem usaremos o data frame faithful, embutido na instalação do R. Este é um data frame contendo 272 observações, registradas em 2 variáveis numéricas: eruptions, tempo de erupção, e waiting intervalo entre erupções ambas em minutos.
> attach(faithful)
> hist(eruptions)
> # Gera o primeiro histograma abaixo
> hist(faithful$eruptions, seq(1.6, 5.2, 0.2), prob=TRUE, col=rainbow(18))
> lines(density(faithful$eruptions, bw=0.1))
> rug(faithful$eruptions)
> # Gera o segundo histograma abaixo
> # Os efeitos de lines() e rug() estão marcados no gráfico
> detach(faithful)
Gráficos de densidade kernel
Dada uma variável aleatória discreta, a estimativa de densidade kernel (EDK) é uma técnica para se estimar a função de densidade de probabilidade que melhor se ajusta à esta variável. Ela busca suavizar dados discretos fazendo inferências sobre uma amostra finita de dados. Desta forma é possível extrapolar dados discretos, fazendo previsões para valores não diretamente medidos. O kernel (ou núcleo) é uma função simétrica, suave. Tipicamente se usa a gaussiana, embora outras funções podem ser escolhidas. No R um gráfico de densidade kernel para o vetor x pode ser obtido com plot(density(x, )).
> attach(mtcars)
> # Construimos uma densidade usando
> # mtcars$mpg (milhas por galão)
> d <- density(mpg)
> plot(d,
main="Milhas/galão (densidade kernel)")
> # Para colorir a área sob a curva
> polygon(d, col="lightblue", border="black")
> # Para inserir marcas nos valores
> # discretos que geraram a densidade
> rug(mpg, col="red")
> detach(mtcars)
A função polygon() desenha um polígono com vértices x, y, neste caso os pares fornecidos pela densidade. rug() marca os valores presentes no vetor mtcars$mpg.
Gráficos de densidade kernel podem ser usados para comparar dados em grupos distintos. Para isso usaremos o pacote sm. Nesse pacote usamos
a função sm.density.compare() para sobrepor gráficos nos grupos dentro de fatores cyl.f, que são, no caso, 4, 6 e 8. O formato é sm.density.compare(x, factor) onde x é um vetor numérico e o fator fornece a variável de agrupamento.
> install.package("sm")
> library(sm)
> attach(mtcars)
> cyl.f <- factor(cyl, levels= c(4,6,8),
labels = c("4 cilindros", "6 cilindros", "8 cilindros"))
> sm.density.compare(mpg, cyl, xlab="Milhas por galão")
> title(main="Consumo x Cilindros")
> cores<-c(2:(1+length(levels(cyl.f))))
> legend(locator(1), levels(cyl.f), fill=cores)
> # locator(1) faz com que o quadro de legendas
> # fique ancorado no ponto clicado pelo usuário.
> detach(mtcars)
O código acima gera o gráfico:
Gráficos de caixas boxplot()
Um gráficos de caixas (boxplot()) é uma ferramenta muita usada para analisar e comparar a variação de uma variável entre diferentes grupos de dados. Ela representa uma variável traçando as mesmas informações obtidas em sumário de cinco números:
o mínimo, o quartil inferior (percentil 25), a mediana (percentil 50), o quartil superior (percentil 75) e o máximo. Ele também pode ser usado para mostrar outliers (ou discrepantes, que são valores fora do intervalo de ± 1,5 * IQR, onde IQR é o intervalo interquartil definido como o quartil superior menos o menor quartil).
Aproveitamos, nas linhas de código abaixo, para rever algumas funções estatísticas básicas, como median(), quantil() e summary().
Boxplots podem ser usados para comparar grupos de variáveis dentro de um dataframe ou lista. O formato para isto é: boxplot(formula, data=dataframe) onde formula é uma relação entre campos do dataframe. Um exemplo de fórmula é y ~ A, onde A é uma variável categórica. Neste caso um plot separado de y é traçado para cada valor de A. A fórmula y ~ A*B resultaria em plots separados de y para cada combinação dos níveis nas variáveis categóricas A e B.
O opção varwidth=TRUE faz com que as caixas tenham larguras proportionais à raiz quadrada do tamanho das amostras. O parâmetro horizontal=TRUE (não usado no gráfico acima) produz a reversão da orientação dos eixos.
Visualizações interativas
O R fornece muitas formas de exibir gráficos que podem ser modificados por interações com o usuário. Vamos exibir aqui apenas alguns exemplos.
O leaflet é uma biblioteca javascript voltada para a visualização interativa de mapas. O código abaixo carrega uma sessão com o leaflet. A função addTiles() insere uma camada com um mapa ao leaflet inicializado.
> library(dplyr)
> library(leaflet)
> leaflet() %>% addTiles()
> # O gráfico 1 é desenhado.
> # Inserindo a latitude e a longitude da
> # Praça da Liberdade, em Belo Horizonte, MG.
> # (que foi encontrada no Google Maps)
> pcaLiberdade <- data.frame(longitude = -43.938023, latitude= -19.931743)
> pcaLiberdade$titulo <- "Praça da Liberdade, BH!"
> # pcaLiberdade é um data frame com campos:
> pcaLiberdade
longitude latitude titulo
1 -43.93802 -19.93174 Praça da Liberdade, BH!
> leaflet(pcaLiberdade)
%>% addTiles()
%>% addMarkers(lat = ~latitude, lng = ~longitude, popup = ~titulo)
> # O gráfico 2 é desenhado
Lembrando: as bibliotecas dplyr e leaflet devem ser instaladas. Observe as linhas de retorno na instalação para verificar sucesso ou erro. A biblioteca iplots, por exemplo, depende de Java.
A url mostrada (no caso “http://127.0.0.1:6260”) deve ser visualizada no Browser. A cada clique de mouse as coordenadas do cursor são exibidas na caixa abaixo, como mostra a figura.
Biblioteca plotly
O código abaixo utiliza o data frame diamonds que contém informações sobre cor, clareza, medidas, carat, preço de diamantes. O ponto clicado abre um pop-up com dados sobre a posição no gráfico e a clareza do diamante.
> library(plotly)
> set.seed(100)
> d <- diamonds[sample(nrow(diamonds), 1000), ]
> plot_ly(d, x = carat, y = price, text = paste("Clareza: ", clarity),
mode = "markers", color = carat, size = carat)
Sobre operadores em R
Em R o programador pode criar aperadores ou alterar o significado de operadores nativos usando o sinal “`” (backtick ou acento grave).
Por exemplo: `+` <- function(a, b) paste(a, b, sep="") "a"+"v" # retorna "av"
O sinal "+" se transformou no operador de concatenação.
Em geral se pode programar %X% (qualquer X) para qualquer funcionalidade. `%@%` <- function(a, b) a^b `%*%` <- function(x, y) x/y 2 %@% 3 # retorna 8 15 %*% 3 # retorna 5
As bibliotecas magrittr e dplyr definem o operador %>% com o seguinte significado: `%>%` <- function(x, FUN) FUN(x)
Isso quer dizer que x %>% hist
é o mesmo que hist(x)
Por exemplo: iris$Sepal.Length %>% hist # traça o histograma do vetor mtcars$mpg %>% hist(col=rainbow(5)) # histograma de mtcars$mpg usando 5 cores.
Gráficos tridimensionais
Existem muitas bibliotecas em R para a geração de gráficos 3D. Entre eles estão: RGL, car, lattice e scatterplot3d (e muitos outras).
Gráfico de dispersão em 3D com scatterplot3d
scatterplot3d é uma biblioteca de uso simples, com formato básico:
scatterplot3d(x, y=NULL, z=NULL)
onde x, y, z são as coordenadas dos pontos a serem plotados. Os argumentos y e z são opcionais, dependendo da estrutura de x.
Se x é uma fórmula (como em zvar ~ xvar + yvar) então xvar, yvar e zvar são usados como valores para x, y e z.
Se x é uma matriz com pelo menos 3 colunas então as variáveis x, y e z são lidas diretamente da matriz.
> library("scatterplot3d")
> data(iris)
> flor <- iris[1:50,1:3] # 50 linhas, 3 primeiras colunas
> names(flor) <- c("comprimentoSepala", "larguraSepala", "comprimentoPepala")
> # A forma mais simples de uso:
> scatterplot3d(flor)
> scatterplot3d(flor, pch = 20,
main="Gráfico dispersão 3D",
xlab = "Comprimento sétala (cm)",
ylab = "Largura sétala (cm)",
zlab = "Comprimento pétala (cm)", color="steelblue")
> # O gráfico 1 é gerado. (pch=20 usa símbolo bola cheia)
> scatterplot3d(flor, pch = 8, main="pch = 8 -> estrela",
color="#E8582D", angle=55, grid=TRUE, box=FALSE)
> # O gráfico 2 é gerado. pch=8 usa símbolo estrela,
> # o gráfico é girado de 55º, com grid e sem a caixa envelope.
> z <- seq(-10, 10, 0.01)
> x <- cos(z)
> y <- sin(z)
> scatterplot3d(x, y, z, highlight.3d = T, col.axis = "blue",
col.grid = "lightblue", main = "Hélice", pch = 20)
O gráfico ao lado é gerado.
Mais informações sobre scatterplot3d no site STHDA.
Mais informações sobre 3d scatterplots no site STHDA.
Outras visualizações em 3D com scatter3d
O formato básico para scatter3d, com alguns de seus parâmetros, é o seguinte:
Como a principal motivação para o uso do software R está na análise de dados e exibição gráfica de resultados é necessário ter formas eficientes para promover a leitura de dados para dentro de nosso ambiente.
Edição básica de tabelas
Já vimos que objetos como data frames podem ser editados por meio dos comandos edit(objeto) ou fix(objeto) que abrem uma janela para a alteração em forma de grade, permitindo inclusive a inserção de novos campos ou a alteração de nomes dos campos já existentes. Esta pode ser uma boa estratégia para se fazer pequenas alterações nas tabelas.
Outra função usada para leitura de dados do usuário ou à partir da leitura de um arquivo é scan().
scan(file = "", what = double(), n = -1, sep = "")
Valores listados para os parâmetros são default. Existem muitos outros parâmetros. file = "" indica que a leitura será feita do teclado. Se file = "arquivo" este arquivo será lido.
what indica o tipo de dado a ser lido. what=character() significa que strings serão lidas. n é o número de dados que serão inserido. n = -1 significa um número ilimitado. Neste caso a inserção (para n=-1) termina com dois <ENTER> seguidos.
sep = "" é o tipo de separador esperado. O default é um espaço em branco.
> x <- scan(n=3) # insere 3 valores do teclado
1: 12 2: 23 3: 34
Read 3 items
> x
[1] 12 23 34
Arquivos CSV
Para a leitura de bases de dados mais extensas outras formas estão disponíveis. Uma delas consiste em realizar a leitura de um arquivo csv (valores separados por vírgula, em inglês comma separated values). Este tipo de arquivo consiste em uma lista de linhas, cada uma delas contendo um número constante de valores, separados por vírgula (ou outro sinal). Estes arquivos podem ser lidos por gerenciadores de planilhas tais como o Excel ou o CALC, do Libre Office. Eles podem também ser gerados por estes aplicativos.
Vamos criar um arquivo para efeito de aprendizado dessa importação de dados. Em um editor de texto ASCII qualquer digitamos os valores seguintes:
id, Nome, Sobrenome, Idade, Sexo
1, Marta, Rocha, 24, F
2, Pedro, Souza, 12, M
3, José, Marciano, 15, M
4, Joana, Santos, 21, F
5, Lucas, Pereira, 20, M
O espaçamento entre os campos não é necessário. Digamos que gravamos este arquivo com o nome alunos.csv na pasta de trabalho em uso (ou em outra qualquer).
Estes dados podem ser lidos com o comando read.table:
Aqui o parâmetro header=TRUE indica que a primeira linha do arquivo contém títulos para as colunas, sep="," indica que as valores estão separados por vírgula (poderiam estar separados por outro caracter, como “;”) e dec="." indica que o ponto é o separador numérico de decimais.
Se o arquivo não estiver na pasta de trabalho atual o nome completo ("caminho/nomearquivo.csv") deve ser fornecido.Para a conveniência do usuário, diversas funções do R são acompanhadas de outras com nomes diversos que realizam as mesmas operações mas usam parâmetros default diferentes. É o caso de read.table() e read.csv().
Consulte a ajuda para ver quais são estes parâmetros.
Por default ítens numéricos são lidos como variáveis numéricas e texto como fatores, embora este comportamento possa ser alterado se necessário. A primeira linha (o cabeçalho) alimenta os valores de nomes de colunas.
> dir()
[1] "alunos.csv"
> alunos <- read.table("alunos.csv", header=TRUE, sep=",", dec=".")
> alunos
id Nome Sobrenome Idade Sexo
1 1 Marta Rocha 24 F
2 2 Pedro Souza 12 M
3 3 José Marciano 15 M
4 4 Joana Santos 21 F
5 5 Lucas Pereira 20 M
> class(alunos)
[1] "data.frame"
> fix(alunos) # permite a edição em uma tabela de alunos
> names(alunos) # lista propriedades names
[1] "id" "Nome" "Sobrenome" "Idade" "Sexo"
> dim(alunos) # dimensões da lista (5 linhas com 5 campos)
[1] 5 5
> alunos[1,] # primeira linha da lista
id Nome Sobrenome Idade Sexo
1 1 Marta Rocha 24 F
> # O parâmetro row.names permite usar uma coluna para nomear as linhas:
> outroAlunos <- read.table("alunos.csv", header=TRUE, row.names="id", sep=",")
> outroAlunos
N Nome Sobrenome Idade Sexo
1 Marta Rocha 24 F
2 Pedro Souza 12 M
3 José Marciano 15 M
4 Joana Santos 21 F
5 Lucas Pereira 20 M
Em muitos casos precisamos executar a operação inversa: exportamos os dados em uma tabela para um arquivo csv para transferir dados e utilizá-los em outro aplicativo. Para isso usaremos, a seguir, a função write.csv()
> # Para recordar, criamos uma nova tabela, semelhante à alunos:
> alunos2 <- data.frame(
id =1:5,
Nome = c("Marta","Pedro","José","Joana","Lucas"),
Sobrenome = c("Rocha","Souza","Marciano","Santos","Pereira"),
Idade = c(24, 12, 15, 21, 20),
Sexo = c("F", "M","M", "F", "M")
)
> # Para gravar esta tabela em disco, como um arquivo csv:
> write.csv(alunos2, file="alunos2.csv")
> # Se o parâmetro file for omitido a saída é para o console
> write.csv(alunos2)
"","id", "Nome", "Sobrenome", "Idade","Sexo"
"1", 1, "Marta", "Rocha", 24, "F"
"2", 2, "Pedro", "Souza", 12, "M"
"3", 3, "José", "Marciano", 15, "M"
"4", 4, "Joana", "Santos", 21, "F"
"5", 5, "Lucas", "Pereira", 20, "M"
Para gravar o objeto alunos2 (uma lista) para uso futuro usamos save(). O objeto pode ser recuperado para o projeto através da função load().
> save(alunos2, file="alunos2.Rdata")
> dir() # Para verificar quais são os aqruivos na pasta
[1] "alunos.csv" "alunos2.Rdata"
> rm(alunos2) # alunos2 não existe mais na sessão
> load('alunos2.Rdata') # recupera alunos2
> str(alunos2)
'data.frame': 5 obs. of 5 variables:
$ id : int 1 2 3 4 5
$ Nome : Factor w/ 5 levels "Joana","José",..: 4 5 2 1 3
$ Sobrenome: Factor w/ 5 levels "Marciano","Pereira",..: 3 5 1 4 2
$ Idade : num 24 12 15 21 20
$ Sexo : Factor w/ 2 levels "F","M": 1 2 2 1 2
Alternativamente, podemos ler uma variável de texto para dentro de uma tabela.
> dados <- " idade sexo altura 13 F 1.25 15 F 1.60 10 M 1.40 "
> tabela <- read.table(header=TRUE, text=dados)
> str(tabela)
'data.frame': 3 obs. of 3 variables:
$ idade : int 13 15 10
$ sexo : Factor w/ 2 levels "F","M": 1 1 2
$ altura: num 1.25 1.6 1.4
Nos exemplos anteriores os tipos das colunas foram inferidos à partir dos dados lidos. Os campos de texto foram convertidos em fatores. O parâmetro colClasses permite que sejam informados previamente o tipo de cada coluna lida.
> alunosNotas <- "
id| aluno |nota |bolsista
1 | Marco | 5.2 |sim
2 | Ana | 7.5 |nao
3 | Celia | 2.5 |sim"
> notas <- read.table(header=TRUE, text=alunosNotas,
row.names="id", sep="|",
colClasses=c("numeric", "character", "numeric", "character"))
> str(notas)
'data.frame': 3 obs. of 3 variables:
$ aluno : chr " Marco " " Ana " " Celia "
$ nota : num 5.2 7.5 2.5
$ bolsista: chr "sim" "nao" "sim"
> # A coluna bolsista foi importada como strings.
> # Para transformá-la em uma coluna de valores lógicos podemos fazer
> notas$bolsista <- notas$bolsista=="sim"
> str(notas)
'data.frame': 3 obs. of 3 variables:
$ aluno : chr " Marco " " Ana " " Celia "
$ nota : num 5.2 7.5 2.5
$ bolsista: logi TRUE FALSE TRUE
Se um arquivo *.csv se encontra na web, disponível através de protocolo http (como o arquivo na url usada abaixo, do site Sample Videos) podemos usar sua url:
> url <- "https://www.sample-videos.com/csv/Sample-Spreadsheet-10-rows.csv"
> dadosCsv <- read.csv(url)
> # A função carrega um data frame em dadosCsv
Se a página da web usa o protocolo https (mais seguro que o anterior) podemos usar o pacote RCurl. Como exemplo vamos baixar um arquivo diponibilizado pela cidade de Seattle, EUA (King County Open Data), contendo dados sobre animais de estimação perdidos:
Com frequência dados baixados da internet contém falhas como, por exemplo, uma entrada em texto em uma coluna numérica. Estes dados precisam ser visualizados e tratados antes de uma análise de sua informação. Podemos vizualizar estes dados de forma gráfica usando a função View() que exibe em tabela um dataframe.
Importando planilhas
O pacote xlsx depende para seu funcionamento dos pacotes rJava e xlsxjars, bem como uma instalação funcional do Java em seu computador.
Para importar uma planilha do Excel ou Libre Office Spreadsheet podemos exportar estes dados para um arquivo *.csv e importá-lo usando as técnicas já descritas. Alternativamente é possível importar diretamente estas planilhas usando o pacote xlsx, que deve ser instalado antes do uso. Planilhas podem ser importadas com as funções read.xlsx e read.xlsx2 que têm a seguinte sintaxe:
vetor numérico indicando linhas a serem extrarídas. Se NULL todas as linhas, exceto se startRow, endRow são especificados.
colIndex
vetor numérico indicando colunas a serem extrarídas. Se NULL todas as colunas.
as.data.frame
valor lógico. Se TRUE os dados serão montados em um data.frame. Se FALSE, uma lista, com um elemento por coluna.
header
valor lógico indicando que a primeira linha contém os nomes das colunas.
colClasses
(read.xlsx) vetor de strings com a classe de cada coluna.
keepFormulas
valor lógico. Se TRUE as fórmulas do excel são mostradas como texto e não avaliadas.
encoding
codificação para strings na planilha.
startRow
numérico, especificando índice da 1ª linha. (Ativo se rowIndex=NULL).
endRow
numérico, especificando índice da última linha. Se NULL, todas as linhas. (Ativo se rowIndex=NULL).
password
senha para a pasta de trabalho.
…
outros argumentos para a data.frame. Ex. stringsAsFactors
A função read.xlsx procura adequar o tipo lido com o da planilha de acordo com cada coluna, preservando o tipo de dado lido. read.xlsx2 é mais rápida, adequada para ser usada em planilhas muito grandes, acima de 100 mil células. Ambas podem ser usadas para ler arquivos *.xlsx ou *.xls.
> library(xlsx)
> xlFrame <- read.xlsx("planilha.xlsx",1, header=TRUE); xlFrame
Data Local Crédito Débito
1 43223 Casa Coral 1002.56 65.45
2 43224 Fornecedor 1 23.34 NA
3 43225 Cliente 2 24.34 33.00
4 43226 Fornecedor 2 15.23 54.00
> # Valor não existente na planilha foi lido como 'NA'
> # A data foi lida como um campo numérico.
Gravando dados em uma planilha Excel
As funções write.xlsx e write.xlsx2 podem ser usadas para gravar dados de uma tabela em uma pasta de trabalho Excel. A segunda delas atinge uma performance melhor para planilhas longas, acima de 100 mil células.
valor lógico. Se TRUE os nomes das colunas de x são escritos no arquivo.
row.names
valor lógico. Se TRUE os nomes das linhas de x são escritos no arquivo.
append
valor lógico. Se TRUE o arquivo é lido no disco e incrementado.
showNA
valor lógico. Se FALSE valores NA são gravados em branco.
password
senha para a pasta de trabalho.
…
outros argumentos passados para addDataFrame (no caso de read.xlsx2).
Para exibir o comportamento destas funções usamos o data.frame USArrests (que vem instalado no pacote básico de R).
Primeiro criamos uma planilha com nome USA-ARRESTS. Depois gravamos em outra planilha na mesma pasta o dataframe alunos que temos carregado em nossa sessão.
O resultado é a gravação, em disco, de uma pasta de trabalho com duas planilhas com nomes USA-ARRESTS e alunos.
Existem outros pacotes destinados à manipulação de arquivos de planilhas. Entre eles citamos os pacotes XLConnect e openxlsx. Este último não depende de Java.
Manipulação de arquivos XML
XML (Extensible Markup Language) é um formato de transmissão de dados bastante usado na internet e computação em geral, usando apenas texto puro (ASCII). Ele contém tags de marcação que descrevem a estrutura dos dados.
Instale o pacote usando
install.packages("XML")
No R se pode ler e escrever em arquivos XML usando o pacote "XML". Para experimentar com a biblioteca usaremos um arquivo ASCII com o conteúdo abaixo, que gravaremos no disco com o nome livros.xml.
<biblioteca>
<livro>
<id>1</id>
<titulo>A Dança do Universo</titulo>
<autor>Marcelo Gleiser</autor>
</livro>
<livro>
<id>2</id>
<titulo>DNA: O Segredo da Vida</titulo>
<autor>James D. Watson</autor>
</livro>
<livro>
<id>3</id>
<titulo>Uma breve história do tempo</titulo>
<autor>Stephen W. Hawking</autor>
</livro>
<livro>
<id>4</id>
<titulo>Como a mente funciona</titulo>
<autor>Steven Pinker</autor>
</livro>
<livro>
<id>5</id>
<titulo>A falsa medida do homem</titulo>
<autor>Stephen Jay Gould</autor>
</livro>
<livro>
<id>6</id>
<titulo>O último teorema de Fermat</titulo>
<autor>Simon Singh</autor>
</livro>
</biblioteca>
O código seguinte carrega este arquivo para um objeto do R e o manipula.
> # Carrega os pacotes necessários
> library("XML", "methods")
> # Importa dados para um objeto de R
> livros <- xmlParse(file="livros.xml", encoding="UTF8" )
> class(livros) # "XMLInternalDocument" "XMLAbstractDocument"
> print(livros)
<biblioteca>
<livro>
<id>1</id>
<titulo>A Dança do Universo</titulo>
<autor>Marcelo Gleiser</autor>
</livro>
... (outros 5 livros)
</biblioteca>
> xmlTop <- xmlRoot(livros) # node principal > class(xmlTop)
[1] "XMLInternalElementNode" "XMLInternalNode" "XMLAbstractNode"
> xmlName(xmlTop) # nome do node principal
[1] "biblioteca"
> xmlSize(xmlTop) # tamanho do node principal
[1] 6
> xmlName(xmlTop[[1]]) # nome do primeiro node
[1] "livro"
> xmlSize(xmlTop[[1]]) # tamanho do primeiro node
[1] 3
> print(xmlTop[[2]]) # exibe o segundo node
<livro>
<id>2</id>
<titulo>DNA: O Segredo da Vida</titulo>
<autor>James D. Watson</autor>
</livro>
> xmlTop[[3]][[2]] # segundo ítem do terceiro node
<titulo>Uma breve história do tempo</titulo>
> # Dados podem ser recuperados usando-se o nome dos nodes
> xmlTop[["livro"]][["autor"]]
<autor>Marcelo Gleiser</autor>
> # Convert um objeto xml para um dataframe
> dfLivros <- xmlToDataFrame(livros) > # Visualiza o dataframe
> View(df.livros, "Dataframe Livros")
A função View() exibe o dataframe como na figura abaixo:
Conexão com banco de dados
Naturalmente, grande parte dos dados a serem analisados estão armazendos em bancos de dados relacionais. R pode se relacionar com diversos dos sistemas de gerenciamento, entre eles os mais populares como SQL Server, Access, MySQL, Oracle, PostgreSQL e SQLite. Existem pacotes que permitem o acesso direto aos drivers nativos destes sistemas e outros que permitem esse acesso via ODBC ou JDBC. Desta forma o poder das consultas SQL amplia bastante o potencial de R na análise de dados.
Usando a interface ODBC
Uma forma comum de acessar bancos de dados de dentro do R é através do pacote RODBC que permite a conexão com qualquer DBMS (Data Base Management System) que admite conexão com o driver ODBC (como é o caso de todos os sistemas listados acima). Para isso é necessário instalar o driver ODBC apropriado para o banco de dados a ser usado, na plataforma específica. Em seguida se instala o pacote ODBC, usando install.packages("RODBC"). As funções básicas do pacote são:
escreve ou atualiza um data frame para tabela da base
sqlDrop(channel,sqltable)
remove uma tabela do bando de dados
close(channel)
fecha a conexão
O pacote RODBC permite a comunicação bidirecional entre R e o banco de dados, que pode ser lido ou alterado. Suponha que um banco de dados possua duas tabelas possua, digamos debito e credito. É possível importá-las para dentro de uma sessão fazendo:
Nem todos os pacotes estão disponíveis em todas as plataformas. Confira a documentação do CRAN.
A função sqlQuery() pode ser usada para a aplicação de qualquer instrução SQL, permite uma seleção detalhada de variáveis, a criação de novos campos, alteração e inserção de dados no banco.
Usando o pacote DBI
O pacote DBI (DataBase Interface) fornece outra forma de acesso à DBMS com suporte à diversos drivers. Entre eles estão os pacotes RJDBC (acesso ao driver JDBC), RMySQL, ROracle, RPostgreSQL e RSQLite.
> library(DBI)
> library(RSQLite)
> banco <- "chinook.db"
> driver <- dbDriver("SQLite")
> db <- dbConnect(driver, banco)
> # Para exibir qual banco está associado a este objeto:
> db
<SQLiteConnection>
Path: /home/guilherme/Projetos/R/Aprendendo/chinook.db
Extensions: TRUE
> # Lista de tabelas em chinook.db
> dbListTables(db)
[1] "albums" "artists" "customers" "employees" "genres"
[6] "invoice_items" "invoices" "media_types" "playlist_track" "playlists"
[11]"sqlite_sequence" "sqlite_stat1" "sqlite_stat4" "tracks"
> # Lista de campos na tabela 'albums'
> dbListFields(db, "albums")
[1] "AlbumId" "Title" "ArtistId"
> sql <- "SELECT AlbumId, Title FROM albums"
> db <- dbConnect(driver, banco)
> rs <- dbSendQuery(db, sql)
> rs
<SQLiteResult>
SQL SELECT AlbumId, Title FROM albums
ROWS Fetched: 0 [incomplete]
Changed: 0
> dbColumnInfo(rs)
name type
1 AlbumId integer
2 Title character
> dbGetStatement(rs)
[1] "SELECT AlbumId, Title FROM albums"
> albuns <- fetch(rs, n = 5) > albuns
AlbumId Title
1 1 For Those About To Rock We Salute You
2 2 Balls to the Wall
3 3 Restless and Wild
4 4 Let There Be Rock
5 5 Big Ones
> # Lista de campos na tabela 'artists'
> dbListFields(db, "artists")
[1] "ArtistId" "Name"
> sql <- "SELECT a.Title, b.Name FROM albums
a INNER JOIN artists b ON a.ArtistId = b.ArtistId
WHERE b.Name LIKE \"Iron%\""
> # O resultado de uma consulta fica armazenado em rs:
> rs <- dbSendQuery(db, sql)
> # rs tem as seguintes colunas
> dbColumnInfo(rs)
name type
1 Title character
2 Name character
> # rs foi gerada pela consulta (sql query)
> dbGetStatement(rs)
[1] "SELECT a.Title, b.Name FROM albums a
INNER JOIN artists b
ON a.ArtistId = b.ArtistId
WHERE b.Name LIKE \"Iron%\""
> # O número de colunas alteradas
> dbGetRowsAffected(rs)
[1] 0
> # Para ler 5 linhas deste resultado
> linhas <- fetch(rs, n = 5) > linha
Title Name
1 A Matter of Life and Death Iron Maiden
2 A Real Dead One Iron Maiden
3 A Real Live One Iron Maiden
4 Brave New World Iron Maiden
5 Dance Of Death Iron Maiden
> dbGetRowCount(rs) # quantas colunas
[1] 5
> # Liberando o 'resultset' e a conexão
> dbClearResult(rs); dbDisconnect(db)
No código abaixo está mostrado como abrir e manipular um banco de dados PostgreSQL que deve estar instalado na máquina local. Ele lê uma tabela no banco de nome Notas que tem uma tabela categorias com campos id, idPai, categoria. Em seguida ele usa o data frame alunos que já está carregado na sessão de R com campos id, Nome, Sobrenome, Idade, Sexo e grava esta tabela no banco de dados, com nome “alunos”. Finalmente uma consulta de atualização é feita usando a conexão aberta.
> library(DBI)
> conn <- dbConnect(odbc::odbc(),
driver = "PostgreSQL Unicode",
database = "Notas",
uid = "nomeUsuario",
pwd = "senhaUsuario",
host = "localhost",
port = 5432)
> # Este db possui uma tabela 'categorias'
> categorias <- dbReadTable(conn, "categorias")
> categorias
id idPai categoria
1 10 0 Ciência
2 14 0 Literatura
3 15 14 Ficção Científica
4 11 10 Física
...
> # Uma consulta SQL
> sql <- "SELECT id, categoria FROM categorias ORDER BY categoria"
> categ <- dbSendQuery(conn, sql)
> primeiros_3 <- dbFetch(categ, n = 3) # primeiros 3 registros
> primeiros_3
id categoria
1 13 Biologia
2 10 Ciência
3 17 Phylos.net
> restante <- dbFetch(catg) # lê os demais registros
> # Gravando o data frame alunos no banco de dados, com nome "alunos"
> # data contém booleano com sucesso da operação
> data <- dbWriteTable(conn, "alunos", alunos)
> # Uma query de atualização na tabela Categorias
> sql <- "UPDATE Categorias SET categoria ='Nova categoria' WHERE id=17"
> dbSendQuery(conn, sql) # altera categoria com id = 17
O código a seguir cria um banco de dados virtual (que existe apenas na memória). Ele pode ser útil para teste, para operações provisórias ou mesmo para a criação completa de um banco até que ele esteja pronto para ser gravado em disco.
> library(DBI)
> # Cria um banco de dados SQL virtual
> conn <- dbConnect(RSQLite::SQLite(), dbname=":memory:") > dbListTables(conn)
character(0)
> dbWriteTable(conn, "mtcars", mtcars)
> dbListTables(conn)
[1] "mtcars"
> dbListFields(conn, "mtcars")
[1] "mpg" "cyl" "disp" "hp" "drat" "wt"
[7] "qsec" "vs" "am" "gear" "carb"
> dbReadTable(conn, "mtcars")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
> # Todas as linhas podem ser recuperadas de uma vez:
> rs <- dbSendQuery(conn, "SELECT * FROM mtcars WHERE cyl = 4")
> dbFetch(rs)
mpg cyl disp hp drat wt qsec vs am gear carb
1 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
2 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
3 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
4 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
5 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
(... continua, 32 linhas ...)
> dbClearResult(res)
> # Lendo o banco por partes
> rs <- dbSendQuery(conn, "SELECT * FROM mtcars WHERE cyl = 4")
> while(!dbHasCompleted(res)) {
parte <- dbFetch(res, n = 5)
print(nrow(parte))
}
[1] 5 [1] 5 [1] 1
> # Fecha o resultset e a conexão
> dbClearResult(rs); dbDisconnect(conn)
Um resumo das funções disponíveis no pacote DBI estão listadas abaixo. Para uma lista completa, com descrição detalhada de cada função e seus parâmetros consulte a R Database Interface (versão 0.5-1) na página R Documentation.
Função
Descrição
dbDriver
carrega e descarrega drivers
dbColumnInfo
informa sobre tipos em resultados
dbExecute
executa uma query e fecha o result set
dbCallProc
chama uma “stored procedure”
dbClearResult
limpa uma result set
dbDisconnect
fecha uma conexão
dbConnect
cria conexão com uma DBMS
dbDataType
determina o tipo (SQL) de um objeto
dbGetStatement
verifica a query associada a um result set
dbGetRowCount
número de linhas recuperadas até o momento
dbGetQuery
envia query, retorna resultado e limpa o result set
Uma grande quantidade de dados se encontra hoje disponível na internet. Por isso é importante aprender a acessá-los e selecionar aqueles que nos interessam. Esta busca e seleção de dados é denominada web scraping.
Embora existam dados em formato estruturado, como tabelas e até mesmos bancos de dados, muita informação na Web está sob formato não estruturado, como ocorre em muitas páginas de texto HTML. É necessário, portanto, converter essa informação em formatos mais úteis.
Em muitos casos copiar e colar conteúdo de uma página em arquivo local pode ser suficiente. Em arquivos pequenos eles podem ser organizados manualmente e os dados postos em forma de uma tabela, por exemplo com os campos separados por vírgula. Em outros casos uma página pode ser analisada por meio de reconhecimento de padrões, usando expressões regulares ou outro processo.
Muitos sites importantes, como Facebook, Twitter e LinkedIn, fornecem APIs públicas ou privadas, que facilitam a leitura de seus dados. Além disso as páginas da web são alimentadas para os browers dentro de estruturas DOM (Document Object Model), o que facilita a garimpagem de dados.
Se os dados já estão estruturados, sob a forma de um arquivo csv (por exemplo) então eles podem ser importados para a sessão de R com a função read.table ou read.csv. Em seguida eles podem ser manipulados de acordo com a conveniência da análise desejada.
> # Há um arquivo csv de teste no endereço abaixo:
> url <- "https://www.sample-videos.com/csv/Sample-Spreadsheet-100-rows.csv"
> dados <- read.table(url, sep=",")
> # A lista está disponível. Os dois primeiros elementos do campo V3 são:
> head(dados$V3, n=2)
[1] Muhammed MacIntyre Barry French
> # Arquivo sem títulos nas colunas: os campos ficam nomeados V1 até v10
> # Independente da formatação uma página pode ser baixada com:
> download.file("https://endereco_url.html", "caminhoOndeSalvar/arquivo.html")
Usando o pacote rvest
O pacotervest foi escrito por Hadley Wickham e é inspirado em bibliotecas como a Beautiful Soup, do Python. Um bom tutorial pode ser encontrado na página do Data Camp sobre o rvest.
XPath (XML Path Language) é uma especificação de pesquisa em nodes de um documento XML. Existem aplicativos e plugins nos principais browsers para facilitar esta localização. Para o Chrome uma boa ferramenta é o SelectorGadget.
No Firefox podemos usar o inspector, um ítem de menu em web developer, que pode ser aberto com CTRL-SHIFT-C.
Para ler uma página na web e analisar seu conteúdo podemos usar o pacote rvest. Nele encontramos a função read_html() que retorna um documento XML que contém toda a informação sobre a página.
Primeiro procuramos uma página na web contendo as informações que desejamos extrair. Para efeito de nosso aprendizado usamos uma páginas simples onde se exibe uma tabela dos estados brasileiros com suas populações e PIBs. Usaremos a página Lista de Estados Brasileiros com população e PIB em Excel. Ignoramos, claro, a possibilidade disponível nessa página de baixar diretamente a tabela em formato Excel. Abrindo esta página no browser abrimos (no Firefox) o web developer, inspector. Na janela de inspecção procuramos a tabela desejada. Ao movimentar o cursor do mouse sobre o elemento html a tabela fica sombreada. Clique na tabela e pressione o botão direito selecionando copy xpath. xpath é um localizador de posição dentro da página, que fica armazenado na área de transfrência. No nosso caso temos xpath = "/html/body/div[3]/div[1]/table", indicando que queremos extrair a tabela única dentro do primeiro div, dentro do terceiro div no corpo do documento html. Em seguida baixamos o conteúdo sob forma xml e depois selecionamos o node desejado usando html_nodes(xpath).
> library(rvest)
> url <- "http://www.servicos.blog.br/listas/lista-de-estados-brasileiros-com-populacao-e-pib-em-excel/"
> xPath <- "/html/body/div[3]/div[1]/table"
> # O seguinte comando armazena o conteúdo do elemento em xPath como
> populacao <- url %>%
read_html() %>%
html_nodes(xpath=xPath) %>%
html_table()
> # Da forma como foi obtida, populacao é uma lista com um elemento
> # Este elemento único é a tabela desejada
> populacao <- populacao[[1]]
> View(populacao)
O útimo comando abre a visualização da tabela:
Veremos em breve um pouco mais sobre o funcionamento do pipe%>%. Por enquanto basta saber que ele faz parte do pacote magrittr e facilita a notação para operações encadeadas, como a composição de funções:
x %>% f é equivalente a f(x)
x %>% f(y) é equivalente a f(x, y)
x %>% f %>% g %>% h é equivalente a h(g(f(x)))
Portanto a linha contendo pipes é idêntica aos seguintes comandos:
> pop <- read_html(url)
> pop2 <- html_nodes(pop, xpath=xPath)
> pop3 <- html_table(pop2) # pop3 é o mesmo que populacao, acima.
O interpretador de R processa as linhas de comandos de modo sequencial, uma linha após a outra. Muitas vezes é necessário bifurcar o código ou repetir um conjunto de linhas, dependendo de certas condições. Para isso temos os laços (loops) e testes lógicos.
Teste lógico if() e else
if(condicao){
Instruções1
} else {
Instruções2
}
A condição para o teste deve ser uma comparação lógica resultando em TRUE ou FALSE. Instruções1 serão executadas se a condição for verdadeira, Instruções2 caso contrário.
Teste vetorizado ifelse()
ifelse(condicão, valor1, valor1)
Retorna valor1 se condicao = TRUE, valor2 caso contrário.
Instrução switch()
switch(expr, valor1, ..., valorn)
Se expr é um inteiro i, retorna valori (o i-ésimo valor)
Se expr é um string os demais argumentos devem nomeados e switch
retorna valor correspondente ao name = expr.
Por exemplo:
> # Teste if/else
> n <- 17
> if (n %% 2 == 0) {
print(paste(m, " é par"))
} else {
print(paste(m, " é ímpar"))
}
[1] "17 é ímpar"
> # ifelse
> m <- 4
> ifelse(m==3, "é", "não é")
[1] "não é"
> m <- 3
> ifelse(m==3, "é", "não é")
[1] "é"
> # A função ifelse realiza internamente um
> # loop nos componentes de um vetor (ou outro objeto)
> teste <- c(1,2.3,4,5.5, 2.3, 7.3, 0.9)
> resultado <- ifelse(teste > 5, "aprovado", "reprovado")
> resultado
[1] "reprovado" "reprovado" "reprovado" "aprovado" "reprovado" "aprovado" "reprovado"
> # A operação acima tem idêntico resultado à:
> teste <- c(1,2.3,4,5.5, 2.3, 7.3, 0.9)
> resultado <- NULL
> for (i in 1:length(teste)) {
if (teste[i]>5) resultado[i] <-"aprovado"
else resultado[i]<- "reprovado"
}
> resultado
[1] "reprovado" "reprovado" "reprovado" "aprovado" "reprovado" "aprovado" "reprovado"
> # A primeira forma, além de mais compacta, é mais eficiente e rápida.
> # Uso de switch() com argumento inteiro:
> print(switch(3,"um", "dois", "três", "quatro"))
[1] "três"
> # Outros exemplos de uso de switch() abaixo, com a instrução for
Laço for()
for(condicao) {
Instruções1 ...
}
A condição para os laços for devem ser sempre do tipo var in seq, onde a variável var percorre uma sequência.
Laço while()
while(condicao) {
Instruções ...
}
Executa as instruções enquanto a condição for verdadeira. Deve-se ter o cuidado de providenciar um mecanismo de saída para este laço.
Laço repeat()
repeat() {
Instruções ...
}
Executa as instruções indefinidamente. Uma saída para este laço pode ser forçada com a instrução break.
As seguintes instruções são usados juntamente com os laços for, while e repeat
Instrução
Efeito
break
força a saída de um laço
next
pula uma iteração do laço (retornando para seu início)
return
retorna o valor de uma função
> # laço for
> for(i in c(1,3,5,7)) {print(paste(i,"^2 = ",i^2, sep =""))}
[1] "1^2 = 1"
[1] "3^2 = 9"
[1] "5^2 = 25"
[1] "7^2 = 49"
> # Laço while
> n <- 1
> while(n < 5) {
print(paste(n, "< 5"))
n<-n+1
}
[1] "1 < 5"
[1] "2 < 5"
[1] "3 < 5"
[1] "4 < 5"
> # Laço repeat, o mesmo que while(TRUE)
n <- 1
> repeat {
print(paste(n, "< 4"))
n <- n+1
if(n == 4) break
}
[1] "1 < 4"
[1] "2 < 4"
[1] "3 < 4"
> # Saltando dentro de um laço
> for (i in 1:10) {
if(i<4 | i>6) next
print(i)
}
[1] 4
[1] 5
[1] 6
> # Observe que a variável continua existindo após o loop
> print(i)
[1] 10
> # Uso de switch() com argumento inteiro:
> for (i in 1:4) print(switch(i,"um", "dois", "três", "quatro" ))
[1] "um"
[1] "dois"
[1] "três"
[1] "quatro"
> # Uso de switch() com argumento de string:
> sinto <- c("medo", "alegria")
> for (i in sinto) {
print(switch(i, triste = "alegre-se", medo = "calma", alegria = "aproveita") )
}
[1] "calma"
[1] "aproveita"
Funções do Usuário
O usuário pode criar funções em R de acordo com suas necessidades. Elas geralmente servem para armazenar uma série de instruções que será utilizada repetidamente ou apenas para organizar um bloco de código mais complexo. Funções possuem a seguinte estrutura básica:
funcao <- function(arg1, ..., argn) {
lista de Instruções
return(objeto)
}
A instrução return é opcional. Se omitida a função retornará o resultado da última operação realizada. Os colchetes podem também ser omitidos se a função consiste em apenas uma linha de código.
A função é chamada fornecendo-se seus argumentos
funcao(varg1, …, argn)
Quando ela retorna um valor que será usado em seguida atribuímos seu valor a uma variável:
var <- funcao(arg1, …, argn)
Qualquer objeto, ou nenhum, pode ser retornado pela função. Quanto aos argumentos eles podem ou não ser nomeados. Argumentos não nomeados devem ser identificados pela sua posição na chamada da função. Se forem nomeados eles podem receber valores default na definição da função que serão usados caso sejam omitidos quando a função é invocada.
> funcao1 <- function(x, y) {
z <- x+y
return(x + y^z) }
> funcao1(2, 3)
[1] 245
> # O mesmo resultado seria obtido se omitíssemos a instrução return:
> funcao1 <- function(x, y) x + y^(x+y)
> # Com argumentos nomeados e com valores default:
> funcao2 <- function(inicio=1,fim=10) {
v <- inicio:fim
return(v) }
> funcao2()
[1] 1 2 3 4 5 6 7 8 9 10
> funcao2(5) # apenas o primeiro arg é fornecido
[1] 5 6 7 8 9 10
> funcao2(,5) # segundo arg é reconhecido pela posição
[1] 1 2 3 4 5
> funcao2(fim=13) # segundo arg é reconhecido pelo nome
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13
> # A instrução return não é obrigatória,
> # nem os colchetes para uma função de única linha
modulo <- function(z) sqrt(Re(z)^2 + Im(z)^2)
> modulo(4+5i)
[1] 6.40312
> # A função tratará, sempre que possível, qualquer tipo de argumento
> funcao3 <- function(x, y) { return(x + y) }
> funcao3(c(1,2,3), c(4,5,6))
[1] 5 7 9
> # Você pode visualizar a constituição de uma função
> funcao1
function(inicio=1,fim=10) {return(inicio:fim)}
> # Para exibir seus argumento use:
> args(funcao1)
function (inicio = 1, fim = 10)
NULL
A função args() pode ser usada em sessões interativas para mostrar os argumentos de uma função. Para descobrir quais são esses argumentos e seus valores default programaticamente use a função formals().
Pode-se também especificar que um argumento é nulo se não for declarado explicitamente na chamada da função como, por exemplo, em:
f <- function(a, b = 1, c = NULL) {...}.
Neste caso deve-se testar no corpo da função se o argumento foi fornecido, antes de usá-lo. É importante notar que uma variável inicializada dentro do corpo de definição da função tem seu escopo limitado à esta função (e não pode ser usada fora dela).
A instrução de return, embora não obrigatória, pode ser útil para interromper o fluxo de comandos, forçando o término da função. No exemplo abaixo calculamos, apenas como exercício, o fatorial de um escalar. Claro que R já tem uma função fatorial embutida que calcula fatorial em vetores e matrizes.
> fat <- function(n) {
m <- as.integer(n)
if (length(n)!=1) return("O argumento deve ser um escalar")
if (m!=n) return("O argumento deve ser inteiro")
if (m<0) return("O argumento deve ser positivo")
return(ifelse(m==0, 1, prod(1:m))
}
> fat(4.3)
[1] "O argumento deve ser inteiro"
> fat(-3)
[1] "O argumento deve ser positivo"
> fat(1:2)
[1] "O argumento deve ser um escalar"
> fat(0)
[1] 1
> fat(9)
[1] 362880
> # Usando factorial
> u <- 1:9
> dim(u)<-c(3,3)
> u
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> factorial(u)
[,1] [,2] [,3]
[1,] 1 24 5040
[2,] 2 120 40320
[3,] 6 720 362880
O argumento ... (3 pontos) tem um significado especial em R. Ele indica que um número indeterminado de argumento podem ser passados para a função e é particularmente útil quando existe outra função aninhada (com muitos argumentos) no corpo da primeira.
Observação: Fizemos uso das funções is.character(var) e is.null(var) que testam, respectivamente, se a variável var é do tipo character ou null. Muitas outras funções de teste existem e são muito úteis, principalmente em scripts. Associadas a elas estão as funções de conversão que forçam a transformação de um tipo em outro, quando possível.
Algumas destas funções estão listadas abaixo:
Os seguintes operadores matemáticos estão definidos em R:
Operador
Descrição
Exemplo
+
adição
–
subtração
*
multiplicação
/
divisão
3/2 = 1.5;
^ ou **
exponenciação
3^2 = 6, 2**3 = 8
%%
módulo
9 %% 2 = 1
%/%
divisão inteira
9 %/% 2 = 4
Os seguintes operadores lógicos estão definidos:
Operador
Descrição
Exemplo
<
menor que
5 < 7 = TRUE
<=
menor ou igual
3 <= 9 = TRUE
>
maior que
5 > 7 = FALSE
>=
maior ou igual
7 >= 7 = TRUE
==
igual
3 == 5 = FALSE
!=
diferente
3 != 5 = TRUE
!x
não x
!(7 < 3) = TRUE
x | y
x ou y
c(T, T, F) & c(T, F, F) = (T, T, F)
x || y
ou (apenas 1º elemento examinado)
c(T, F, F) || c(F, F, F) = TRUE
x & y
x e y
c(T, T, F) & c(T, F, F) = (T, F, F)
x & y
e (apenas 1º elemento examinado)
c(T, F, F) && c(F, F, F) = FALSE
isTRUE(x)
verifica se x é TRUE
isTRUE(7 < 9) = TRUE
Outros operadores:
Operador
Descrição
Exemplo
: (dois pontos)
cria uma sequência de números
2:6 = (2, 3, 4, 5, 6)
%in%
pertence
3 %in% 1:4 = TRUE,5 %in% 1:4 = FALSE
%*%
multiplicação de matrizes por sua transposta
A %*% t(A)
any(condição sobre x)
TRUE se algum elemento de x satisfaz a condição
any(x==9)
all(condição sobre x)
TRUE se todos os elementos de x satisfazem a condição
all(x!=9)
Nos elementos de um vetor as operações ocorrem entre componentes de mesma posição em cada vetor.
> # Usando dois vetores de mesmo comprimento
> u <- c(1,2,3,4,5) > v <- c(5,4,3,2,1) > u+v
[1] 6 6 6 6 6
> u-v
[1] -4 -2 0 2 4
> u*v
[1] 5 8 9 8 5
> u**v
[1] 1 16 27 16 5
> u %% v
[1] 1 2 0 0 0
> u %/% v
[1] 0 0 1 2 5
> media <- (u + v) / 2 > media
[1] 3 3 3 3 3
> # Se os operandos têm comprimentos diferentes então um deve
> # ter comprimento múltiplo do outro. n cópias do vetor menor
> # serão usadas na operação e o resultado terá o tamanho do maior.
> u + c(1,2,3)
[1] 2 4 6 5 7
Warning message:
In u + c(1, 2, 3) :
longer object length is not a multiple of shorter object length
> u + 10
[1] 11 12 13 14 15
> w <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) > u+w
[1] 2 4 6 8 10 7 9 11 13 15
w/u
[1] 1.000000 1.000000 1.000000 1.000000 1.000000
[6] 6.000000 3.500000 2.666667 2.250000 2.000000
># Lembrando que u = (1,2,3,4,5)
> any(u > 4)
[1] TRUE
> any(u > 5)
[1] FALSE
> all(u < 4)
[1] FALSE
Comparações lógicas entre vetores também são efetuadas entre elementos, um a um.
> u > v
[1] FALSE FALSE FALSE TRUE TRUE
> x <- 1:10 > x
[1] 1 2 3 4 5 6 7 8 9 10
> x[x < 3 | x > 7]
[1] 1 2 8 9 10
> x[x > 2 & x < 8] [1] 3 4 5 6 7 >
> # O operador %in% busca valores entre todos de um vetor
> # Lembrando que u = (1, 2, 3, 4, 5)
> 1 %in% u
[1] TRUE
> 6 %in% u
[1] FALSE
Lembrando que x = 1:10, vamos verificar com maior detalhe a operação:
x[x < 3 | x > 7] = (1, 2, 8, 9, 10)
Por partes:
x < 3 = (T, T, F, F, F, F, F, F, F, F)
x > 7 = (F, F, F, F, F, F, F, T, T, T)
x < 3 | x > 7 = (T, T, F, F, F, F, F, T, T, T)
Finalmente
x[(T, T, F, F, F, F, F, T, T, T)] = (1, 2, 8, 9, 10)
Portanto selecionamos os componentes do vetor x que são menores que 3 ou maiores que 7.
Operações pode ser realizadas entre membros de outros objetos compostos. Por exemplo, usando um data frame:
> mdata<-data.frame(x = c(2, 2, 6, 4), y = c(3, 4, 2, 8)) > mdata
x y
1 2 3
2 2 4
3 6 2
4 4 8
> attach(mdata)
> mdata$soma <- x + y > mdata$media <- (x + y)/2 > detach(mdata)
> # As operações acima acrescentaram dois novos campos à mdata:
> mdata
x y soma media
1 2 3 5 2.5
2 2 4 6 3.0
3 6 2 8 4.0
4 4 8 12 6.0
> # O mesmo tipo de operação pode ser feita de forma
> # alternativa usando-se a função transform
> valores <- data.frame(x=c(1,4,6,8), y=c(1,3,5,7))
> valores <- transform(valores, soma = x+y, media = (x+y)/2, teste = x>y)
> valores
x y soma media teste
1 1 1 2 1.0 FALSE
2 4 3 7 3.5 TRUE
3 6 5 11 5.5 TRUE
4 8 7 15 7.5 TRUE
Funções internas
Quase toda a funcionalidade do R é obtida através de funções. Um grande número delas faz parte do bloco básico, carregado por default, e muitas outras podem ser utilizadas através da instalação de pacotes (packages).
Funções numéricas
Função
Descrição
abs(x)
\(\left|x\right|\), valor absoluto
sqrt(x)
\(\sqrt x\), raiz quadrada
ceiling(x)
menor inteiro acima: ceiling(3.475) = 4
floor(x)
maior inteiro abaixo: floor(3.475) = 3
trunc(x)
truncamento: trunc(5.99) is 5
round(x, digits=n)
arredondamento: round(3.475, digits=2) = 3.48
signif(x, digits=n)
n dígitos significantes: signif(3.475, digits=2) = 3.5
cos(x), sin(x), tan(x)
funções trigonométricas, seno, cosseno, tangente
acos(x), cosh(x), acosh(x)
outras funções trigonométricas
log(x)
\(\ln(x)\) logaritmo natural (base e)
log10(x)
\(\log(x)\), logaritmo de base 10
exp(x)
\(e^x\), exponencial
Funções de texto
Função
Descrição
substr(x, a, b)
retorna ou substitui parte de uma string x, da posição a até b.
sub(texto1, texto2, x)
substitui, na string x, o texto1 pelo texto2.
grep(padrao, x , ignore.case=FALSE, fixed=FALSE)
Procura padrao em x. Se fixed = FALSE o padrão é uma expressão regular, caso contrário um texto simples. Retorna índice de localização.
strsplit(x, sep)
Quebra o vetor x em sep.
paste(…, sep=”-“)
Concatena strings usando a string sep como separador.
paste(…, collapse=”-“)
Monta uma única string com partes do argumento, usando collapse como separador.
toupper(x)
retorna texto em letras maiúsculas
tolower(x)
retorna texto em letras minúsculas
nchar(x)
retorna o comprimento da string x
> # Retornar uma substring
> substr("abcdef",3,5)
[1] "cde"
> cores <- c("azul escuro", "verde escuro", "preto")
> substr(cores, 1, 5)
[1] "azul " "verde" "preto"
> # Substituir caracteres
> sub("strings", "texto", "Trocar strings")
[1] "Trocar texto"
> # A substituição pode ser feita em todos os componentes do vetor
> sub("escuro", "claro", cores)
[1] "azul claro" "verde claro" "preto"
> # Partir texto
> strsplit("as casas de maria", " ")
[[1]]
[1] "as" "casas" "de" "maria"
> strsplit("ABCDEF", "BC")
[[1]]
[1] "A" "DEF"
> strsplit("ABCDEF", "")
[[1]]
[1] "A" "B" "C" "D" "E" "F"
> # As funções agem em todos os comonentes do objeto
> x <- c("estudar", "R", "no site") > substr(x,1,2)
[1] "es" "R" "no"
> # Uso se expressão regular
> s <- "www.phylos.net" > sub("p.+s","filosofia", s)
[1] "www.filosofia.net"
> toupper("falando alto")
[1] "FALANDO ALTO"
> tolower("Não GRITE")
[1] "não grite"
> # Para juntar strings:
> paste("primeiro", "segundo", "terceiro")
[1] "primeiro segundo terceiro"
> paste("primeiro", "segundo", "terceiro", sep = ", ")
[1] "primeiro, segundo, terceiro"
> # Valores numéricos são convertidos em strings
> paste(1,2,3, sep="-")
[1] "1-2-3"
> paste(1,2,3, sep="")
[1] "123"
> paste("tentativa", 1)
[1] "tentativa 1"
> tent <- paste("tentativa", 1:5) > tent[5]
[1] "tentativa 5"
Funções Auxiliares Úteis
Função
Descrição
seq(from, to, by)
gera sequência numérica (início, fim, passo)
rep(x, times=n)
repete x n vezes
cut(x, n)
divide variável contínua (numérica) em fator com n níveis
pretty(x,n)
divide variável contínua em n intervalos
cat(… , file = nomeArquivo, append = FALSE)
concatena objectos em …e os envia para o console ou arquivo nomeArquivo (se existir)
> seq(12, 30, 2)
[1] 12 14 16 18 20 22 24 26 28 30
> # Forçando o resultado a ter 5 elementos
> seq(from=0, to=20, length.out=5)
[1] 0 5 10 15 20
> rep("ha", times=4)
[1] "ha" "ha" "ha" "ha"
> # Repetindo cada elemento n vezes
> rep(c(1,2,3), each=2)
[1] 1 1 2 2 3 3
> $ Repete o primeiro elemento 4 x, o segundo 2 x
> rep(c("a", "b"), times = c(4,2))
[1] "a" "a" "a" "a" "b" "b"
> # cut permite a criação de fator. Abaixo, com 4 níveis:
> idades <- c(12, 14, 16, 17, 34, 32, 12, 12, 11) > cut(idades, breaks=4)
[1] (11,16.8] (11,16.8] (11,16.8] (16.8,22.5] (28.2,34]
[5] (28.2,34] (11,16.8] (11,16.8] (11,16.8]
Levels: (11,16.8] (16.8,22.5] (22.5,28.2] (28.2,34]
> # Uso de pretty
> pretty(1:20, n=2)
[1] 0 10 20
> pretty(1:20, n=10)
[1] 0 2 4 6 8 10 12 14 16 18 20
> # Uso de cat
> nome <- "Ana" > cat("Olá",nome,"\b.\n", "\t \"Bom dia!\"")
Olá Ana.
"Bom dia!"
Usamos na linha de demonstração de cat() usamos as sequências de escape\n (newline), \b (backspace), \t (tab), \" (aspas duplas)
Funções úteis para a manipulação de Objetos
Listamos em seguida algumas das funções importantes para a leitura e edição de objetos.
Função
Descrição
length(obj)
retorna o número de elementos ou componentes do objeto
dim(obj)
retorna as dimensões do objeto.
str(obj)
exibe a estrutura do objeto.
head()
lista os seis primeiros elementos do objeto
tail()
lista os seis últimas elementos do objeto
class(obj)
retorna a classe do objeto.
mode(obj)
exibe como o objeto foi armazenado
names(obj)
exibe os nomes de componentes do objeto
c(obj1, …, objn)
concatena objetos em um vector
cbind(obj1, …, objn)
combina objetos em colunas
rbind(obj1, …, objn)
combina objetos em linhas
obj, print(obj)
exibe / imprime objeto.
head(obj)
lista a primeira parte do objeto
tail(obj)
lista a parte final do objeto
ls()
exibe lista dos objetos carregados, equivalenta à função objects()
rm(obj1, …, objn)
remove um ou mais objetos
rm(list = ls())
)remove todos os objetos
novoObj <- edit(obj)
edita objeto e o armazena como novoObj
fix(obj)
edita objeto salvando nele as alterações
Data e Hora
Datas são armazenadas internamente no R como o número de dias decorridos desde 01/01/1970. Datas anteriores são representadas como números negativos.
Função
Descrição
as.Date(string)
converte a string em uma data
Sys.Date( )
retorna a data de hoje
date()
retorna data e hora corrente
data2 – data1
retorna a diferença entre data1 e data2 em dias
as.character(data)
retorna a data como um string
format(data, format=strDeFormato)
formata a data segundo o string de formatação
weekdays(data)
dia da semana correspondente a data (ou datas)
months(data)
mês não abreviado correspondente a data (ou datas)
quarters(data)
Quarter (Q1, Q2, Q3, Q4)
seq(from=data1, to=data2, by=n)
sequência de datas de data1 até data2, em passos n (dias)
> # Data do sistema (um string, formato ano/mês/dia)
> Sys.Date()
[1] "2018-11-23"
> # Transforma esta string em uma data
> data1 <- as.Date(Sys.Date()) > # Soma 250 dias à data1
> data2 <- data1 + 250 > data2 - data1
[1] Time difference of 250 days
> # Sequência de datas começando em data1 até data2 com passos de 50 dias
> seq(from=data1, to=data2, by=50)
[1] "2018-11-23" "2019-01-12" "2019-03-03"
[4] "2019-04-22" "2019-06-11" "2019-07-31"
> # Produz sequência de datas de data1 até data2 com 5 elementos
> seq(from=data1, to=data3, length.out=5)
[1] "2018-11-23" "2019-01-24" "2019-03-28"
[4] "2019-05-29" "2019-07-31"
> weekdays(data1)
[1] "sexta"
> months(data1)
[1] "novembro"
> quarters(data1)
[1] "Q4"
> format(data1, "%d/%m/%y")
[1] "23/11/18"
> format(data1, "%d/%m/%Y")
[1] "23/11/2018"
> format(data1, "%A, %d de %B de %Y")
[1] "sexta, 23 de novembro de 2018"
> # As funções se aplicam a vetores e outros objetos
> strData <- c("01/05/1965", "08/16/1975")
> datas <- as.Date(strDatas, "%m/%d/%Y") > datas
[1] "1965-01-05" "1975-08-16"
> Para lidar com o formato brasileiro de dia/mes/ano podemos fazer
> dBr <- as.Date("23/11/2018", "%d/%m/%Y") > dBr
[1] "2018-11-23"
Os seguintes símbolos (ou máscaras) podem ser usados com datas. Os resultados dependem das configurações de data/hora locais, que podem ser visualizadas com o comando Sys.localeconv().
Símbolo
Descrição
Exemplo
%d
dia, numérico
01 a 31
%a
dia da semana, abreviado
Mon, (Seg)
%A
dia da semana por extenso
Monday (segunda)
%m
mês, numérico
01 a 12
%b
nome do mês, abreviado
Feb, (Fev)
%B
nome do mês por extenso
February, (Fevereiro)
%y
ano em 2 dígitos
18
%Y
ano em 4 dígitos
2018
Funções Estatísticas
Função
Descrição
mean(x, trim=0,na.rm=FALSE)
média do objeto x
sd(x)
desvio padrão do objeto x
var(x)
variância
mad(x)
desvio absoluto médio
median(x)
mediana
quantile(x, probs)
quantil de x, probs= vetor numérico com probabilidades em [0,1]
range(x)
intervalo
sum(x)
soma
diff(x, lag=1)
diferenças defasadas, lag = defasagem a usar
min(x)
mínimo de x
max(x)
máximo de x
scale(x, center=TRUE, scale=TRUE)
centro da coluna ou padronizar uma matriz
> x <- c(123, 234, 345, 242, 34, 100, NA)
> mean(x)
[1] NA
> # mesma operação ignorando valor NA
> mean(x, na.rm=TRUE)
[1] 179.6667
> # redefinindo x
> x <- c(123, 234, 345, 242, 34, 100)
> sum(x)
[1] 1078
> range(x)
[1] 34 345
> min(x)
[1] 34
> max(x)
[1] 345
> mean(x)
[1] 179.6667
> # Eliminando valores 20% nas bordas da amostra
> mean(x, trim=.2)
[1] 174.75
> sd(x)
[1] 113.9731
> var(x)
[1] 12989.87
> mad(x)
[1] 105.2646
> median(x)
[1] 178.5
A tabela seguinte lista funções relacionadas com distribuições probabilísticas. Para gerar sequências pseudo-randômicas (que podem ser replicadas mais tarde) use set.seed(1234) (ou outro inteiro).
Distribuição uniforme, segue mesmo padrão
que a distribuição normal acima.
Voltaremos ao estudos destas funções mais tarde.
A Distribuição Normal
Por completeza listamos aqui algumas funções de distribuição de probabilidades. As funções de densidade, de distribuição, quantil e a geração aleatória para a distribuição normal podem ser obtidas com média e desvio padrão especificados.
A função rnorm gera dados aleatórios com distribuição normal:
onde \(\mu\) é a média da distribuição e \(\sigma\) é o desvio padrão.
dnorm fornece a densidade, pnorm a função de distribuição, qnorm a função quantil, rnorm gera os desvios aleatórios. O comprimento do resultado é determinado por n para rnorm. Para as demais funções ele é igual ao maior comprimento dos argumentos numéricos.
Os argumentos numéricos (exceto de n) são reciclados para o tamanho do resultado. Apenas os primeiros elementos dos argumentos lógicos são usados.
> x <- pretty(c(-3,3), 100)
> y <- dnorm(x)
> plot(x, y, type = "l", xlab = "Desvio Normal", ylab = "Densidade")
Distribuição normal
Este código gera o gráfico exibido à direita. Veremos em breve maiores detalhes sobre o uso da função plot() usada para gerar o gráfico.
A distribuição normal é uma das mais utilizadas na modelagem dos fenômenos naturais e das ciências naturais e sociais. Ela é também chamada de distribuição de Gauss ou de Laplace–Gauss, em referência aos matemáticos Pierre-Simon Laplace (1749-1827) e Carl Friedrich Gauss (1777-1855).
Dataframes são uma generalização de matrizes onde cada coluna pode ser de um tipo ou classe diferente de dados. Neste sentido este é o objeto de R que mais se aproxima de uma planilha ou de um banco de dados.
Um dataframe pode conter nomes para as colunas, uma indicação de que dado está nela armazenado, e também um atributo especial chamado row.names que guarda informações sobre cada uma de suas linhas. Eles podem ser criados explicitamente com a função data.frame() ou através da transformação forçada de outros tipos de objetos, como as listas. Por sua vez eles podem ser transformados em matrizes data.matrix().
Muitas vezes um dataframe é carregado diretamente através da leitura de dados gravados previamente por meio de comandos como read.table() ou read.csv().
Vamos criar um dataframe contendo os dados de alunos, contendo um id, nome, idade e menção final (II, MI, MM, MS, SS), expostos na tabela seguinte:
id
Nome
Idade
Menção
1
Paulo
24
MM
2
Joana
23
MS
3
Marcos
19
MM
4
Fred
21
II
5
Ana
20
MI
Estes dados podem ser inseridos em um dataframe da seguinte forma:
> id <- 1:5
> nome <- c("Paulo", "Joana", "Marcos", "Fred", "Ana")
> idade <- c(24, 23, 19, 21, 20)
> mencao <- c("MM", "MS", "MM", "II", "MI" )
> alunos <- data.frame(id, nome, idade, mencao)
> alunos
id nome idade mencao
1 1 Paulo 24 MM
2 2 Joana 23 MS
3 3 Marcos 19 MM
4 4 Fred 21 II
5 5 Ana 20 MI
> # As entradas no frame podem ser consultadas de várias maneiras
> alunos["mencao"]
mencao
1 MM
2 MS
3 MM
4 II
5 MI
> alunos[c("nome", "mencao")]
nome mencao
1 Paulo MM
2 Joana MS
3 Marcos MM
4 Fred II
5 Ana MI
> alunos$mencao
[1] MM MS MM II MI
Levels: II MI MM MS
Observe que a coluna de menções (bem como a de nomes) foi transformada em um fator, não ordenado. Em situações em que o uso de um dataframe é recorrente as funções attach(), detach() e with() podem ser bastante úteis.
A função attach() informa ao interpretador de R qual é o dataframe default a que se referem os campos citados no código. A função detach() remove esta ligação. Seu uso é opcional mas é uma boa prática de programação que deve ser seguida.
attach(alunos)
The following objects are masked _by_ .GlobalEnv:
id, idade, mencao, nome
> id
[1] 1 2 3 4 5
> summary(idade)
Min. 1st Qu. Median Mean 3rd Qu. Max.
19.0 20.0 21.0 21.4 23.0 24.0
> table(mencao)
mencao
II MI MM MS
1 1 2 1
> detach(alunos)
Quando a função attach foi executada o interpretador informou que os campos id, idade, mencao, nome receberam máscaras para sua execução. Se outra variável previamente definida tinha o mesmo nome ela terá precedência na busca pelo interpretador (o que pode não ser o comportamento desejado). Para evitar tais possíveis conflitos podemos usar with(). Desta forma se garante que todos os comandos dentro das chaves se refiram à alunos.
> with(alunos, {
print(idade)
print(mencao)
})
[1] 24 23 19 21 20
[1] MM MS MM II MI
Levels: II MI MM MS
> # Se um único comando será usado as chaves são opcionais
with(alunos, summary(idade))
Min. 1st Qu. Median Mean 3rd Qu. Max.
19.0 20.0 21.0 21.4 23.0 24.0
> # a função summary faz uma estatística básica dos dados do argumento
> # Para que a atribuição continue existindo fora das chaves usamos <<-
> with(alunos, {
estatistica <<- summary(idade)
estat <- summary(idade)
})
> estatistica
Min. 1st Qu. Median Mean 3rd Qu. Max.
19.0 20.0 21.0 21.4 23.0 24.0
> estat
Error: object 'estat' not found
> # A mesma dataframe pode ser criada com a atribuição de labels
> # às suas linhas. No caso atribuímos o id a este label
> alunos <- data.frame(id, nome, idade, mencao, row.names = id)
> # Estes labels são usados para exibição de dados e gráficos
> # O dataframe pode ser ordenado por ordem de idade dos alunos
> alunos <- alunos[order(alunos$idade),]
> alunos
id nome idade mencao
3 3 Marcos 19 MM
5 5 Ana 20 MI
4 4 Fred 21 II
2 2 Joana 23 MS
1 1 Paulo 24 MM
> # O número de linhas e colunas podem ser obtidos
> nrow(alunos)
[1] 5
> ncol(alunos)
[1] 4
> # O data frame pode ser criado vazio, com os campos especificados
> df <- data.frame(id=numeric(0), nome=character(0), nota=numeric(0))
> df
[1] id nome nota
<0 rows> (or 0-length row.names)
> # e editado na janela edit
> df <- edit(df)
Funções usadas com dataframes:
Função
Efeito
df <- data.frame(vetor1, ... , vetorn)
cria um dataframe
df[obj1]
exibe a coluna relativa à obj1
attach(df)
liga as variáveis ao dataframe df
detach(df)
remove ligação ao dataframe df
with(df, {comandos})
executa comandos com ligação ao dataframe df
summary(obj1)
retorna estatística básica dos dados de obj1
nrow(df)
retorna número de linhas de df
ncow(df)
retorna número de colunas de df
edit(df)
abre uma janela para a edição do data frame
O operador edit() permite a edição de dados e dos nomes de campos de um data frame (ou de outros objectos de R, como vetores e matrizes).
Ele, no entanto, deixa o objeto inalterado. Para que as alterações sejam passadas para o mesmo objeto devemos fazer obj <- edit(obj).
O mesmo resultado pode ser conseguido com o operador fix(): fix(obj) # alterações já ficam gravados em obj
Manipulando data frames com comandos SQL
Usando o pacote sqldf consultas podem ser feitas à um data frame usando consultas sql. Para isso instalamos o pacote e usamos a função sqldf(). Para exemplificar usamos o dataframe mtcars, que é carregado por padrão no R.
Leia mais sobre a leitura e manipulação de arquivos *.csv na sessão Aquisição de Dados.
Também é possível construir um data.frame aplicando uma consulta sql sobre um arquivo *.csv gravado no disco. Suponha que o seguinte conteúdo esteja gravado em um arquivo alunos.csv.
id, Nome, Sobrenome, Idade, Sexo
1, Marta, Rocha, 24, F
2, Pedro, Souza, 12, M
3, José, Marciano, 15, M
4, Joana, Santos, 21, F
5, Lucas, Pereira, 20, M
O código seguinte usa a função, read.csv.sql() para selecionar o nome e a idade dos alunos com idade superior a 20 anos, de dentro do arquivo.
> sql <- "SELECT Nome, Idade FROM alunos.csv WHERE Idade>20"
> rs <- read.csv.sql("alunos.csv", sql)
> # O seguinte data frame fica carregado:
> rs
Nome Idade
1 Marta 24
2 Joana 21
Listas (lists) são uma generalização dos vetores que podem conter elementos de classes diferentes.
> lista1 <- list(234, "casa", 1+2i, TRUE)
> lista1
[[1]]
[1] 234
[[2]]
[1] "casa"
[[3]]
[1] 1+2i
[[4]]
[1] TRUE
> lista1[2]
[[1]]
[1] "casa"
> lista1[3] <- "novo valor"
> lista2 <- vector("list", length=4)
> lista2[1] <- 1
> lista2[2] <- "popula"
> lista2[3] <- "a lista"
> lista2[4] <- True
> lista2
[[1]]
[1] 1
[[2]]
[1] "popula"
[[3]]
[1] "a lista"
[[4]]
[1] TRUE
> # A função list concatena os argumentos, que podem ser vetores
> v1 <- c(1,3,5)
> v2 <- c("1", "3", "5")
> v3 <- c(T, F)
> lista3 <- list(v1, v2, v3)
> lista3
[[1]]
[1] 1 3 5
[[2]]
[1] "1" "3" "5"
[[3]]
[1] TRUE FALSE
> # Várias listas podem ser concatenadas
> listona <- list(lista1, lista2, lista3)
> # O segundo elemento da terceira lista é
> listona[[3]][[2]]
[1] "1" "3" "5"
> # Uma lista pode ter seus objetos nomeados
> lista4 <- list(impares=c(1,3,5,7,9), pares=c(2,4,6,8))
> lista4
$impares
[1] 1 3 5 7 9
$pares
[1] 2 4 6 8
> # Cada objeto pode ser recuperado por seu nome de duas formas
> lista4$pares # retorna 2 4 6 8
> lista4["pares"] # retorna 2 4 6 8
> # Nos dois casos chamamos o segundo objeto da lista
> lista4[2] # $pares [1] 2 4 6 8
> # A lista pode ser criada com o atributo title (título)
> # juntamente com os nomes dos objetos anexados
> alunos <- list(title="Alunos", nome=c("Pedro", "Maria", "Jonas", "Raquel"),
idade=c(17, 19, 14, 20))
> alunos
$title
[1] "Alunos"
$nome
[1] "Pedro" "Maria" "Jonas" "Raquel"
$idade
[1] 17 19 14 20
> A lista tem os atributos
> names(alunos)
[1] "title" "nome" "idade"
> # Um atributo pode ser alterado dinamicamente
> alunos["title"]<-"Alunos - 2018"
> names(alunos)[2]<-"Apelidos"
> # A lista fica da seguinte forma:
> alunos
$title
[1] "Alunos - 2018"
$apelidos
[1] "Pedro" "Maria" "Jonas" "Raquel"
$idade
[1] 17 19 14 2
Listas são importantes para a organização de dados inicialmente coletados de forma confusa ou desorganizada. Além disso muitas funções em R retornam listas que devem ser manipuladas para uma completa análise destes resultados.
Resumimos os comandos usados:
Função
Efeito
lista <- list(obj1, … ,objn)
cria uma lista com objetos de tipos diversos
lista <- vector("list", length=n)
cria uma lista vazia de comprimento n
lista <- list(nome1=vetor1,…, nomen=vetorn)
cria uma lista com atributos nome para cada vetor
lista[nome1]
recupera o vetor1
list(title=”titulo”, obj1, … ,objn)
cria uma lista com atributo title = “titulo”
names(lista)
exibe os atributos da lista
Fatores (factors)
Fatores (factors) são variáveis em R que assumem um número finito e discreto de valores. Elas são também chamadas de categorias ou tipos enumerados e são muito usadas na modelagem estatística. Fatores são armazenados como um vetor de inteiros associado a outro vetor de caracteres, usados na exibição dos fatores. Um fator é criado com a função factor que recebe como argumento um vetor numérico ou de caracteres. No entanto os níveis de um fator sempre serão strings (caracteres ou literais).
Os níveis possíveis de um fator podem ser exibidos através do comando levels. Fatores são exibidos em ordem alfabética por default. Para alterar esta ordem de exibição o argumento levels pode receber um vetor com os valores possíveis na ordem desejada. A função table recebe um fator como argumento e retorna uma tabela com uma contagem de cada ítem do fator.
> x <- factor(c("sim", "não", "não", "não","sim", "sim"))
> x
[1] sim não não não sim sim
Levels: não sim
> table(x)
x
não sim
3 3
> # A ordem de exibição pode ser alterada após a criação do fator
> y <- c("fraco", "normal", "forte", "forte", "forte", "normal")
> cafe <- factor(y)
> cafe <- factor(cafe, levels=c("fraco","normal","forte"))
> table(cafe)
cafe
fraco normal forte
1 2 3
> # Os níves podem ser exibidos separadamente
> levels(cafe)
[1] "fraco" "normal" "forte"
> # Um nível pode ser colocado em primeiro lugar
> relevel(cafe, "forte")
[1] fraco normal forte forte forte normal
Levels: forte fraco normal
Pode ocorrer que um conjunto de dados contenha uma tabela de informações codificadas numericamente. Suponha, por exemplo, que o resultado de um questionário tenha armazenado os códigos 1 = "masculino" e 2 = "feminino". Neste caso podemos fazer com que variáveis numéricas sejam armazenadas como factors usando as opções levels e labels.
> sexo <- c(1, 1, 1, 2, 1, 2, 2, 2, 1)
> table(sexo)
sexo
1 2
5 4
> sexo <- factor(sexo, levels = c(1,2), labels=c("masculino","feminino"))
> table(sexo)
sexo
masculino feminino
5 4
> # Note que a ordem dos labels deve corresponder à ordem dos levels.
> # Para alterar os dados (ou inserir novos) os labels devem ser usados
> sexo[3] <- "feminino"
> sexo[10] <- "masculino"
> sexo[11] <- "deconhecido" # um erro é gerado e o valor NA inserido
Apesar da ordem de exibição imposta aos fatores acima, todos eles são todos não ordenados. Fatores ordenados devem ser usados se comparações entre eles for necessária. Para isso usamos o argumento opcional ordered = TRUE.
medidas <-c("grande","gigante", "grande","gigante",
"gigante","médio","grande","gigante",
"pequeno","pequeno","grande","gigante")
> medidas
[1] "grande" "gigante" "grande" "gigante" "gigante" "médio" "grande" "gigante" "pequeno"
[10] "pequeno" "grande" "gigante"
> niveis <-c("pequeno","médio","grande","gigante")
> tamanho <- factor(medidas, levels=niveis,ordered = TRUE)
> tamanho
[1] grande gigante grande gigante gigante médio grande
[8] gigante pequeno pequeno grande gigante
Levels: pequeno < médio < grande < gigante
> table(tamanho)
tamanho
pequeno médio grande gigante
2 1 4 5
> # A ordem de um fator pode ser invertida
> tamanho2 <- factor(tamanho, levels=rev(levels(tamanho)))
> levels(tamanho2)
[1] "gigante" "grande" "médio" "pequeno"
> table(tamanho2)
tamanho2
gigante grande médio pequeno
5 4 1 2
Observação: Variáveis podem ser nominais, ordinais ou contínuas. As nominais são categorias sem nenhuma ordenação. Um exemplo seriam modelos de automóveis, em uma tabela. Variáveis ordinais são formadas por texto mas com uma ordem definida. Um exemplo é a variável tamanho usada acima. Variáveis contínuas podem assumir qualquer valor, em geral dentro de limites estabelecidos.
Para uma revisão sobre matrizes na Álgebra Linear veja Matrizes
Uma matriz é um objeto de duas dimensões, um conjunto de elementos organizados em linhas e colunas. Todos os componentes de uma matriz devem ser do mesmo tipo. Uma matriz Mm×n contém m linhas e n colunas. Em R uma matriz pode ser criada à partir de um vetor, através da função matrix():
> # Criando uma matriz de 4 linhas e 5 colunas
> n <- matrix(1:20, nrow=4, ncol=5)
> n
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> # Por default as colunas são preenchidas por colunas.
> # Para preencher por linhas fazemos
> m <- matrix(1:20, nrow=4, ncol=5, byrow=TRUE)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
> # Os elementos podem ser lidos diretamente
> m[3,4]
[1] 14
> # A n-ésima linha pode ser obtida (fazendo n=2)
> m[2,]
[1] 6 7 8 9 10
> # A n-ésima coluna pode ser obtida (n=3)
> m[,3]
[1] 3 8 13 18
> # O segundo elemento da terceira coluna é
> m[,3][2]
[1] 8
> # O mesmo que
> m[2,3]
[1] 8
> # Mais de uma coluna pode ser extraída
> # Extraindo a 1a e 3a coluna da matriz m
> m [, c(1,3)]
[,1] [,2]
[1,] 1 3
[2,] 6 8
[3,] 11 13
[4,] 16 18
> # Uma matrix também pode ser declarada sem ter seus elementos definidos
> matr <- matrix(nrow=3,ncol=2)
> matr
[,1] [,2]
[1,] NA NA
[2,] NA NA
[3,] NA NA
> # NA é a forma de R representar que o valor não está disponível
> # A matrix pode ser populada em seguida:
> matr[1,1] <- 1
> matr[1,2] <- 4 # etc.
> # Matrizes, como vetores, possuem atributos.
> attributes(m)
$ dim
[1] 4 5
> # A matriz m possui apenas o atributo dimensão
> dim(m)
[1] 4 5
> # 4 linhas e 5 colunas.
> # Uma matriz pode ser criada associando-se dimensões à um vetor
> k <- 1:10
> k
[1] 1 2 3 4 5 6 7 8 9 10
> dim(k) <- c(2,5)
> k
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> # Finalmente matrizes podem ser criadas por agrupamento de colunas
> x <- 1:3
> y <- 10:12
> cbind(x,y)
x y
[1,] 1 10
[2,] 2 11
[3,] 3 12
> # ou agrupamento de linhas
> rbind(x,y)
[,1] [,2] [,3]
x 1 2 3
y 10 11 12
> # Os argumentos de rbind e cbind são vetores ou matrizes.
> # Por ex., se xy = rbind(x,y) então
> rbind(x,xy)
[,1] [,2] [,3]
x 1 2 3
x 1 2 3
y 10 11 12
> # As dimensões devem ser compatíveis ou os argumentos podem ser truncados
> rbind(xy, 100:104)
[,1] [,2] [,3]
x 1 2 3
y 10 11 12
100 101 102
Warning message:
In rbind(xy, 100:104) :
number of columns of result is not a multiple of vector length (arg 2)
> # Uma mensagem de erro foi gerada.
>
> # Uma matrix pode ser criada com atributos m linhas, n colunas
> # juntamente com nomes para as linhas e colunas
> celulas <- c(11, 12, 21, 22)
> nomesLinhas <- c("Linha 1", "Linha 2")
> nomesColunas <- c("Coluna 1", "Coluna 2")
> matriz <- matrix(celulas, nrow=2, ncol=2, byrow=TRUE,
dimnames=list(nomesLinhas, nomesColunas))
> matriz
Coluna 1 Coluna 2
Linha 1 11 12
Linha 2 21 22
>
> # Esta matriz tem atributos dim (dimensões 2X2) e dimnames
> attributes(matriz)
$dim
[1] 2 2
$dimnames
$dimnames[[1]]
[1] "Linha 1" "Linha 2"
$dimnames[[2]]
[1] "Coluna 1" "Coluna 2"
> # Os nomes das linhas e colunas podem ser lidos e alterados
> colnames(matriz)
[1] "Coluna 1" "Coluna 2"
> colnames(matriz) <- c("col1", "col2")
> row.names(matriz)
[1] "Linha 1" "Linha 2"
> row.names(matriz) <- c("lin1" , "lin2")
> # Agora a matriz tem novos atributos names
> matriz
col1 col2
lin1 11 12
lin2 21 22
> # O nome de uma linha (ou coluna) pode ser alterado isoladamente
> row.names(matriz)[2] <- "linha dois"
> matriz
col1 col2
lin1 11 12
linha dois 21 22
Os seguintes funções foram usadas para a criação, acesso e manipulação de matrizes:
Função
Efeito
M = matrix(vetor, nrow=m, ncol=n, byrow=TRUE)
cria matriz Mm x n usando os elementos do vetor, distribuídos por linhas
matriz[m,n]
retorna o elemento Mm,n
matriz[m,n] <- q
associa o valor q ao elemento Mm,n
matriz[m,]
retorna a m-ésima linha da matriz M
matriz[,n]
retorna a n-ésima coluna da matriz M
attributes(M)
exibe atributos da matriz M
rbind(x, y)
junta por linhas os objetos x, y
cbind(x, y)
junta por colunas os objetos x, y
colnames(M)
exibe (ou atribue) nomes para as colunas de M
row.names(M)
exibe (ou atribue) nomes para as linhas de M
Arrays
Arrays são generalizações dos objetos matrizes e são manipulados de forma semelhante. Um array de dimensões 2 × 3 × 5 pode ser visto como uma coleção de 5 matrizes 2 × 3. Para efeito de sua representação no console elas são representadas exatamente desta forma.
> arr <- array(1:12, c(2, 3, 2))
> arr
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
> # Como vemos acima o componente [,, 2] é uma matriz 2 por 3
> arr[,,2]
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
> # que tem na primeira linha e segunda coluna o valor
> arr[,,2][1,2]
[1] 9
>
> # Um array pode ser construído com seus atributos names
> # Um ex, a terceira dimensão do array representa valores em anos diversos
> dim1 <- c("Filho 1","Filho 2")
> dim2 <- c("Educação", "Saúde", "Alimentação")
> dim3 <- c("2010", "2011")
> Despesas <- array(, c(2, 3, 2), dimnames=list(dim1, dim2, dim3))
> # Todos os elementos são 'NA'Despesas
> Despesas[1,1,1]<-90.80
> Despesas[1,1,2]<-98.80
> Despesas
, , 2010
Educação Saúde Alimentação
Filho 1 90.8 NA NA
Filho 2 NA NA NA
, , 2011
Educação Saúde Alimentação
Filho 1 98.8 NA NA
Filho 2 NA NA NA
> Despesas["Filho 1",,]
2010 2011
Educação 90.8 98.8
Saúde NA NA
Alimentação NA NA
> Despesas["Filho 1","Saúde","2010"]<-456
> Despesas["Filho 1","Saúde","2010"]
[1] 456
> Despesas["Filho 1",,]
2010 2011
Educação 90.8 98.8
Saúde 456.0 NA
Alimentação NA NA
No R existem os seguintes tipos de dados e variáveis:
Tipo de Dado
Exemplo
Lógico (Logic)
TRUE, FALSE
Numérico (Numeric)
12.3, 5, 999
Inteiro (Integer)
2L, 34L, 0L
Complexo (Complex)
1 + 2i
Caracter (Character)
‘a’, “Bom dia”, “TRUE”, ‘23.4’
(Raw)
“Bom dia” é armazenado como 42 6f 6d 20 64 69 61
*Em R não existem, de fato, escalares. Eles são representados por vetores com um único componente.
Com estes dados (e variáveis) se pode construir objetos predefinidos e mais complexos: eles são os escalares* (scalars), vetores (vectors), matrizes (matrices), arrays (matrizes em dimensões maiores que m × n), data frames e listas (lists).
Observe que R é sensível ao caso. TESTE, Teste e teste são variáveis diferentes. Os valores lógicos devem ser escritos em maiúsculas (mas podem ser abreviados para T e F).
Com frequência mencionaremos o nome de uma entidade em inglês para facilitar a leitura dos textos abundantes na internet. Em alguns casos podemos manter a nomenclatura original, em inglês.
Variáveis e vetores
e <- 154 # um escalar, numérico
l <- "pedro" # um escalar, caracter
a <- c(1, 3, 9.5, 6, -2, 4) # vetor numérico
b <- c("um", "dois", "três") # vetor de caracter
c <- c(TRUE, TRUE, FALSE, TRUE, FALSE) # vetor lógico
Todos os componentes de um vetor devem ser do mesmo tipo.
> # um escalar pode ser criado assim:
> x <- 10
> x
[1] 10
> print(x)
[1] 10
> # um vetor é criado usando o operador c()
> vetor_numerico <- c(1.2, 3.4, 5, 7, 8)
> vetor_numerico
[1] 1.2 3.4 5.0 7.0 8.0
> vetor_string <- c("a", "b", "c", "d")
> vetor_string
[1] "a" "b" "c" "d"
> vetor_logico <- c(FALSE, TRUE, TRUE)
> vetor_logico
[1] FALSE TRUE TRUE
> vetor_inteiros <- c(12L, 15L, 18L)
> vetor_inteiros
[1] 12 15 18
> # a classe de um objeto pode ser consultada com a função class()
> class(vetor_inteiros)
[1] "integer"
> class(vetor_logico)
[1] "logical"
> # O primeiro componente do vetor_numerico é
> vetor_numerico[1]
[1] 1.2
> # Seu comprimento
> length(vetor_numerico)
[1] 5
> # Podemos então obter seu último componente
> vetor_numerico[length(vetor_numerico)]
[1] 8
> # O terceiro e o quinto componentes são
> vetor_numerico[c(3, 5)] # 2nd and 4th elements of vector
[1] 5 8
> # O vetor v = (1, 2, 3, 4, 5, 6) pode ser criado com
> v <- c(1:6)
> v
[1] 1 2 3 4 5 6
> # Desta forma podemos obter 4 (por ex.)
> # elementos sequenciados de vetor_numerico
> vetor_numerico[(1:4)]
[1] 1.2 3.4 5.0 7.0
# Um componente pode ser alterado a qualquer momento
> vetor_numerico[1] <- 0
> vetor_numerico
[1] 0.0 3.4 5.0 7.0 8.0
# Novos componentes podem ser inseridos
> vetor_numerico[6] <- 203
> vetor_numerico
[1] 0 3 5 7 8 203
> Observe que o operador c concatena vetores
> frutas <- c("maçã","laranja")
> verduras <- c("alface", "brocolis","couve")
> c(frutas, verduras)
[1] "maçã" "laranja" "alface" "brocolis" "couve"
> # Em R um objeto é dinâmicamente modificado para acomodar uma atribuição
> w <- 1:3
> w[7] <- 17
> w
[1] 1 2 3 NA NA NA 17
NA é uma constante interna representando um valor ausente ou não disponível, Not Available.
Diferente do que ocorre na maioria das linguagens de programação os índices são contados à partir de 1 (e não 0).
Usamos os seguintes novos operadores:
Operador
Efeito
v <- c(1:6)
cria* o vetor v = (1, 2, 3, 4, 5, 6)
v <- c(a1, ..., an)
cria o vetor v = (a1, ..., an), de comprimento n
v[r]
retorna o r-ésimo componente, ar, se r ≤ n, NA caso contrário
v[c(p, q)]
retorna componentes ap e aq
v[r] <- 5
substitui o valor de ar se r ≤ n, insere caso contrário
lenght(v)
retorna o comprimento do vetor, lenght(v) = n neste caso.
*Mencionamos que o operador cconcatena vetores.
Como já foi usado acima, podemos filtrar um vetor para pegar apenas alguns de seus componentes. Para ilustrar esta operação vamos criar um longo vetor e, a partir dele construir outro vetor apenas com algumas de suas componentes:
> u <- 1:10 # forma resumida de c(1:10)
> filtro <- c(T,T,T,F,F,F,T,T,T,F) # resumindo T = TRUE, F = FALSE
> u[filtro]
[1] 1 2 3 7 8 9
> # Observe ainda que podemos excluir o terceiro elemento
> u[-3]
[1] 1 2 4 5 6 7 8 9 10
> # ou todos os elementos entre o terceiro e o quinto, inclusive
> u[-3:-5]
[1] 1 2 6 7 8 9 10
> # Podemos atribuir este vetor filtrado a outra variável, para uso futuro
> novo_u <- u[-3:-5]
> # e remover o antigo, caso ele não seja mais necessário
> rm(u)
> # Se um valor for inserido o vetor muda de comprimento
> u[12] <- 100
> u
[1] 1 2 3 4 5 6 7 8 9 10 NA 100
> # A posição 11 fica indeterminada (NA)
> # A função seq fornece uma forma adicional de criar um vetor
> # onde se fornece os valores inicial e final e o acréscimo (ou passo)
> v2 <- seq(from=0, to=3, by=.25)
> v2
[1] 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 2.25 2.50 2.75 3.00
> # Um vetor pode ser repetido dentro de outro vetor maior
> v <- 1:3 # um shortcut para c(1:3)
> rep(v, times=3)
[1] 1 2 3 1 2 3 1 2 3
# Para repetir cada componente 2 vezes
> rep(v, each=2)
[1] 1 1 2 2 3 3
> # Podemos especificar quantas vezes repetir cada componente
> # No ex. abaixo repetir o primeiro componente 4 x, o segundo 2
> rep(c(0, 7), times = c(4,2))
[1] 0 0 0 0 7 7
> rep(v, times = c(1,0,3))
[1] 1 3 3 3
> # Repetir um vetor até obter outro de comprimento length.out
> rep(v,length.out=7)
[1] 1 2 3 1 2 3 1
> # Além das funções rep e seq podemos usar:
> # any: testa se algum elemento do vetor satisfaz uma condição
> any(v > 2)
[1] TRUE
> any(v >= 4)
[1] FALSE
> # all: testa se todos os elementos do vetor satisfazem uma condição
> all(v > 2)
[1] FALSE
> all(v >= 0)
[1] TRUE
Resumindo, usamos:
Função
Efeito
rep(v, times = n)
repete o vetor v n vezes
rep(v, times = c(r, s))
repete o primeiro componente r vezes, o segundo s vezes
rep(v, each = n)
repete o vetor v, cada componente n vezes
rep(v, lenght.out = l)
repete o vetor v até atingir um vetor de comprimento l
any(v condição)
verifica se algum componente de v satisfaz à condição
all(v condição)
verifica se todos os componentes de v satisfazem à condição
Um vetor vazio pode ser criado através da função vector(). O vetor pode ser populado em seguida. Além disso vetores possuem o atributo names que é também um vetor. Ele permite atribuir nomes aos componentes do vetor, como mostrado abaixo:
> # Cria um vetor vazio (inicialmente um vetor lógico)
> v <- vector()
> v
logical(0)
> # Popula o vetor v
> v[1] <- 1
> v[2] <- 2
> v[3] <- 3
> v
[1] 1 2 3
> is.vector(v)
[1] TRUE
# Nenhum valor foi associado a names
> names(v)
NULL
> # Popula o vetor names associado a v
> names(v)[1] <- "primeiro"
> names(v)[2] <- "segundo"
> names(v)[3] <- "terceiro"
> v
primeiro segundo terceiro
1 2 3
> # Alternativamente
> names(v) <- c("um", "dois" ,"três")
> v
um dois três
1 2 3
> # O vetor continua sendo um vetor numérico
> class(v)
[1] "numeric"
> # Um vetor pode ser criado com seu atributo names definido
> v <- c('a'=1, 'b'=2, 'c'=3)
> names(v)
[1] "a" "b" "c"
> # As aspas acima são opcionais.
> # O mesmo efeito seria obtido com v <- c(a=1, b=2, c=3)
> v
a b c
1 2 3
> # Como dito, names é um vetor. Seu primeiro componente é
> names(v)[1]
[1] "a"
> # É possível obter o componente do vetor pelo seu atributo
> pessoa <- c("nome"="Pedro","Sobrenome"="Malazartes")
> pessoa["nome"]
nome
"Pedro"
Regras de reciclagem (recycling)
Vetores que aparecem um uma expressão não precisam, necessariamente, ter o mesmo comprimento. Caso um dos vetores seja de menor comprimento que o outro (ou outros) o resultado da expressão terá o comprimento do maior deles e os vetores menores serão reciclados (recycled). Na reciclagem eles são repetidos quantas vezes for necessário, podendo ser fracionados. Uma constante (um vetor de um elemento) é simplesmente repetido.
> u <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
> v <- c(1, 2, 3)
> u + v
[1] 2 4 6 5 7 9 8 10 12 11
> # v é reciclado para v' = (1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2)
> u + 10
[1] 11 12 13 14 15 16 17 18 19 20








 > # grava arquivo hiperbole.jpg
> jpeg(file='hiperbole.jpg')
> # plota gráfico
> plot(x<- -100:100, 1/x, type='l', main="hipérbole")
> # fecha janela gráfica
> dev.off()
> # Grava arquivo jpeg com a imagem à direita.
> # grava arquivo hiperbole.jpg
> jpeg(file='hiperbole.jpg')
> # plota gráfico
> plot(x<- -100:100, 1/x, type='l', main="hipérbole")
> # fecha janela gráfica
> dev.off()
> # Grava arquivo jpeg com a imagem à direita.
 > x <- 1:100; y <- sqrt(x)
> plot(x,y, type="l")
> text(locator(1), "x é aqui!")
> text(locator(1), "y é aqui!")
> text(locator(5), paste("<", 1:4, ">")
> # A linha acima marca 4 pontos
> # no gráfico, com o texto:
> # "<1>", "<2>", "<3>", "<4>"
> # respectivamente
> x <- 1:100; y <- sqrt(x)
> plot(x,y, type="l")
> text(locator(1), "x é aqui!")
> text(locator(1), "y é aqui!")
> text(locator(5), paste("<", 1:4, ">")
> # A linha acima marca 4 pontos
> # no gráfico, com o texto:
> # "<1>", "<2>", "<3>", "<4>"
> # respectivamente
 > attach(mtcars)
> plot(mpg ~ wt)
> abline(lm(mpg ~ wt))
> title("Regressão Linear de Consumo por Peso")
> detach(mtcars)
> attach(mtcars)
> plot(mpg ~ wt)
> abline(lm(mpg ~ wt))
> title("Regressão Linear de Consumo por Peso")
> detach(mtcars)


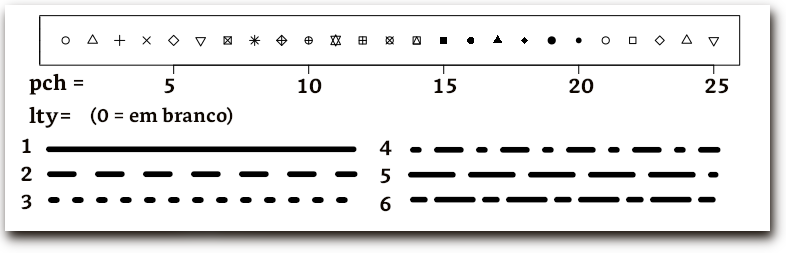
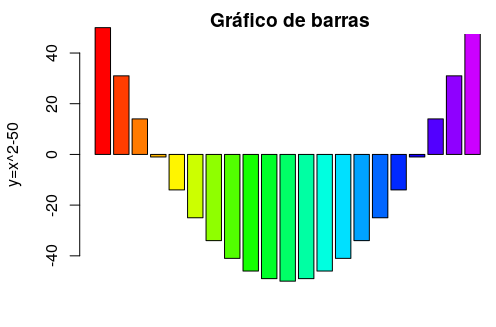

 cores <-c("#5FC0A0", "#DE7A6B", "#6BA0DE")
> barplot(resultado,
main="Gripe: teste clínico",
xlab="Medicamento",
ylab="Eficácia",
col=cores, beside=TRUE)
cores <-c("#5FC0A0", "#DE7A6B", "#6BA0DE")
> barplot(resultado,
main="Gripe: teste clínico",
xlab="Medicamento",
ylab="Eficácia",
col=cores, beside=TRUE)
 > # Ordenamos o resultado por taxa de analfabetismo
> media <- media[order(media$taxa),]
> View(media) # resulta na tabela 1
> # plotando o gráfico de barras
> barplot(media$taxa, names.arg=media$regiao, col=cor)
> title("Analfabetismo nos EUA / por região"
> # resultado no gráfico abaixo
> # Ordenamos o resultado por taxa de analfabetismo
> media <- media[order(media$taxa),]
> View(media) # resulta na tabela 1
> # plotando o gráfico de barras
> barplot(media$taxa, names.arg=media$regiao, col=cor)
> title("Analfabetismo nos EUA / por região"
> # resultado no gráfico abaixo



 > library(plotrix)
> populacao <- c(1420, 1368, 329, 269, 212)
> pais <- c("China", "India", "EUA",
"Indonesia" , "Brasil")
> fan.plot(populacao, labels=pais,
main = "Usando o fan.plot",
col=rainbow(5))
> # O gráfico à direita é gerado.
> library(plotrix)
> populacao <- c(1420, 1368, 329, 269, 212)
> pais <- c("China", "India", "EUA",
"Indonesia" , "Brasil")
> fan.plot(populacao, labels=pais,
main = "Usando o fan.plot",
col=rainbow(5))
> # O gráfico à direita é gerado.


 > attach(mtcars)
> # Construimos uma densidade usando
> # mtcars$mpg (milhas por galão)
> d <- density(mpg)
> plot(d,
main="Milhas/galão (densidade kernel)")
> # Para colorir a área sob a curva
> polygon(d, col="lightblue", border="black")
> # Para inserir marcas nos valores
> # discretos que geraram a densidade
> rug(mpg, col="red")
> detach(mtcars)
> attach(mtcars)
> # Construimos uma densidade usando
> # mtcars$mpg (milhas por galão)
> d <- density(mpg)
> plot(d,
main="Milhas/galão (densidade kernel)")
> # Para colorir a área sob a curva
> polygon(d, col="lightblue", border="black")
> # Para inserir marcas nos valores
> # discretos que geraram a densidade
> rug(mpg, col="red")
> detach(mtcars)















