
Definições
Um banco de dados é uma coleção de dados armazenada e acessada eletronicamente. Tipicamente consiste em várias tabelas e das relações predefinidas entre elas. Cada tabela contém colunas ou campos, cada uma delas com seu nome exclusivo e tipos de dados definido. Elas podem ter atributos que definem a funcionalidade da coluna (se é uma chave primária, se há um valor default, etc.). As linhas da tabela são chamadas de registros e contêm os dados armazenados.

Banco de dados relacional é um banco de dados digital baseado no modelo relacional proposto por E. F. Codd em 1970. Sistema de software usados para construir e manter bancos de dados relacionais são chamados Sistema de Gerenciamento de Banco de Dados Relacionais (RDBMS).
SQL, (Structured Query Language) ou Linguagem de Consultas Estruturada é uma linguagem de programação usada para manipular de bancos de dados relacionais. Usando SQL é possível construir o BD, estabelecer relações entre dados nas tabelas, fazer consultas, inserir, apagar ou editar dados.
Para que serve a SQL?

Consultas SQL podem ser feitas dentro de diversos aplicativos tais como em suites MS Office, em particular no MS Access, e seus equivalentes open source. Elas também são frequentes em aplicativos que armazenam e manipulam informações, de Business Inteligence e análises de dados tais como Qlikview e MS PowerBI. A maior parte dos sistemas de gerenciamento de conteúdo usados em sites na Internet, como WordPress e Joomla usam bancos de dados controlados por SQL.
A maioria das linguagens de programação fornecem interfaces com as variantes de bancos de dados SQL. Além disso podemos instalar um Sistema Gerenciador de Banco de Dados (DBMS) em seu computador, seja ele um servidor ou sua desktop pessoal, disponíveis em todas as plataformas. Os DBMS mais populares são: SQLite, MySQL, PostgreSQL, LibreOffice Base (todos eles open source) e Microsoft Access, SQL Server, FileMaker, Oracle (proprietários).
Comandos e instruções do SQL
Vamos considerar o exemplo de uma escola que mantém um banco de dados com informações sobre alunos, professores, funcionários, disciplinas lecionadas, salas de aulas, e a descrição de relacionamentos entre eles. Segue um exemplo simples de uma tabela contendo o dados (simplificados e fictícios) de alunos. A primeira linha, em negrito, contém os nomes das colunas da tabela (os campos):
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 734236 | João | Santos | joao@yahoo.com | 02-04-1998 | 61 123455667 |
| 789234 | George | Pereira | george@gmail.com | 04-04-2000 | 41 345678987 |
| 654987 | Paula | Torres | ptorres@globo.com | 25-01-2004 | 31 987854543 |
| 765098 | Marcos | Melo | mamelo@gmail.com | 25-10-2004 | 31 987843231 |
Nessa tabela Matricula é um campo numérico que, sendo composto de valores únicos, pode ser usado como um id ou identificador. Nome, Sobrenome, email e Fone são campos de strings, Nascimento é um campo de datas.
SELECT
SQL não são sensíveis à maiúsculas e minúsculas mas é uma convenção escrevê-los em maiúsculas, o que ajuda a diferenciá-los quando embutidos dentro de códigos de outra linguagem.
A instrução SELECT é usada para recuperar (ler e retornar) dados de uma tabela. Ela tem a seguinte sintaxe geral:
SELECT Coluna1, ..., Colunan FROM Tabela1 SELECT * FROM Tabela1
A primeira consulta retorna todos os registros (linhas) da Tabela1, existentes nos campos listados, Coluna1, …, Colunan, sem qualquer critério de seleção. A segunda consulta retorna todas as linhas e todos os campos da Tabela1. O asterisco * substitui a lista de todos os campos. Devemos observar que a declaração explícita de quais campos se pretende retornar torna a consulta mais eficiente (rápida). O sinal -- (dois hífens) marca o início de um comentário em SQL, uma parte da instrução que será ignorada.
Por exemplo, para retornar todos os Nomes e Sobrenomes da tabela usamos
SELECT Nome, Sobrenome FROM Alunos -- a tabela abaixo será retornada
| Nome | Sobrenome |
|---|---|
| João | Santos |
| George | Pereira |
| Paula | Torres |
| Marcos | Melo |
Cláusula WHERE
A Cláusula WHERE é uma modificação da consulta com SELECT especificando condições de retorno. Ela restringe os dados retornados para apenas aqueles satisfeitos pela cláusula. Por exemplo, lembrando que o campo matrícula é numérico:
SELECT Nome, Sobrenome, email FROM Alunos WHERE Matricula = 654987
| Nome | Sobrenome | |
|---|---|---|
| Paula | Torres | ptorres@globo.com |
SELECT Matricula, email FROM Alunos WHERE Nome = 'Marcos'
| Matricula | |
|---|---|
| 765098 | mamelo@gmail.com |
Os seguintes operadores de comparação podem ser usados com WHERE:
= |
igual, usado acima | 🔘 | < |
menor que |
<> |
diferente | 🔘 | =< |
menor ou igual |
> |
maior que | 🔘 | LIKE |
similar |
>= |
maior ou igual | 🔘 | BETWEEN |
entre (define uma faixa) |
Podemos então requisitar todos os registros com Matricula > 740000 ou Nascimento <> '25-01-2004':
SELECT Matricula, Nome, Sobrenome FROM Alunos WHERE Matricula > 740000
| Matricula | Nome | Sobrenome |
|---|---|---|
| 789234 | George | Pereira |
| 765098 | Marcos | Melo |
SELECT Matricula, Nome, Sobrenome FROM Alunos WHERE Nascimento <> '25-01-2004'
| Matricula | Nome | Sobrenome |
|---|---|---|
| 734236 | João | Santos |
| 789234 | George | Pereira |
O mesmo procedimento é usado para os demais operadores.
O Operador LIKE pode ser usado junto com %, um wildcard ou coringa que representa qualquer string (um ou mais caracteres). Ele pode ser posto em qualquer lugar, quantas vezes for necessário.
SELECT * FROM Alunos WHERE Nome LIKE 'PA%' -- Nomes que começam com 'PA'
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 654987 | Paula | Torres | ptorres@globo.com | 25-01-2004 | 31 987854543 |
O Operador BETWEEN possui sintaxe um pouco diferente para cada RDBMS. Em geral é algo do tipo:
SELECT * FROM Alunos WHERE Nascimento BETWEEN '01-01-2002' AND '01-01-2005' -- Nascidos no intervalo
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 654987 | Paula | Torres | ptorres@globo.com | 25-01-2004 | 31 987854543 |
| 765098 | Marcos | Melo | mamelo@gmail.com | 25-01-2004 | 31 987843231 |
O coringa _ representa um único caracter e [] uma faixa de valores. Por exemplo, a consulta seguinte retorna todos os registros onde Fone começa com 3, 4, 5 ou 6 e tem qualquer segundo dígito. No caso de nossa tabela Alunos seriam todos os registros.
SELECT * FROM Alunos WHERE Fone LIKE '[3-6]_%'
SELECT DISTINCT
Se você quiser obter valores únicos de uma tabela, sem repetições, use a cláusula DISTINCT.
SELECT DISTINCT Nascimento FROM Alunos
| Nascimento |
|---|
| 02-04-1998 |
| 04-04-2000 |
| 25-01-2004 |
ORDER BY
A cláusula ORDER BY é usada junto com SELECT para ordenar os resultados de uma consulta. Ela tem a seguinte sintaxe geral:
SELECT campo1, ..., campon FROM Tabela1 ORDER BY (lista de campos)
Por exemplo:
-- Para retornar todos os Nomes e Sobrenomes da tabela, em ordem de Nome SELECT Nome, Sobrenome FROM Alunos ORDER BY Nome
| Nome | Sobrenome |
|---|---|
| George | Pereira |
| João | Santos |
| Marcos | Melo |
| Paula | Torres |
ORDER BY pode ser usada com os modificadores ASC ou DESC, para produzir a lista em ordem crescente ou descendente. ASC é o default e não precisa ser especificado. Para obter a mesma lista anterior em ordem descendente no sobrenome:
-- Para retornar todos os Nomes e Sobrenomes da tabela, em ordem de Nome SELECT Nome, Sobrenome FROM Alunos ORDER BY Sobrenome DESC
| Nome | Sobrenome |
|---|---|
| Paula | Torres |
| João | Santos |
| George | Pereira |
| Marcos | Melo |
TOP
A cláusula TOP é usada junto com SELECT e, geralmente com ORDER BY para selecionar apenas um número fixo de resultados retornados por uma consulta. Ela tem a seguinte sintaxe geral:
SELECT TOP número| % campo1, ..., campon FROM Tabela1 ORDER BY (lista de campos)
Por exemplo:
-- Para retornar os dois últimos Nomes da tabela, em ordem de Nome SELECT TOP 2 Nome, Sobrenome FROM Alunos ORDER BY Nome DESC
| Nome | Sobrenome |
|---|---|
| Paula | Torres |
| Marcos | Melo |
Para ver 10% dos primeiros registros de uma lista podemos usar:
SELECT TOP 10% * FROM Tabela ORDER BY campo
Operadores lógicos
Operadores lógicos são usados para testes compostos com mais de uma condição.
| Operador | Descrição |
|---|---|
AND |
TRUE se ambas as condições ligadas forem TRUE, |
OR |
TRUE se ambas ou uma delas forem TRUE, |
IN |
se um valor está presente em uma lista |
NOT |
nega uma expressão lógica |
IS NULL |
se um valor é nulo (NULL) |
IS NOT NULL |
se um valor não é nulo |
Operadores AND e OR
Mais de uma condição podem ser anexadas à cláusula WHERE usando os operadores AND e OR.
SELECT * FROM Alunos WHERE Matricula > 700000 AND Fone LIKE '31%'
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 765098 | Marcos | Melo | mamelo@gmail.com | 25-10-2004 | 31 987843231 |
SELECT * FROM Alunos WHERE Matricula > 700000 OR Sobrenome = 'Torres'
Nessa última consulta todos os registros seriam retornados pois Paula Torres é a única aluna com matrícula inferior à 700000.
Condições mais complexas podem ser expressas usando-se parênteses.
SELECT Matricula, Nome, Sobrenome FROM Alunos WHERE (Nome = 'George' OR Nome = 'Paula') AND Sobrenome = 'Pereira'
| Matricula | Nome | Sobrenome |
|---|---|---|
| 789234 | George | Pereira |
Operador lógico IN
O operador IN é usado junto com WHERE para selecionar um campo com valor dentro de um conjunto de valores discretos. A sintaxe é
SELECT campo1, ..., campon FROM Tabela WHERE campo1 IN (valor1, ..., valorr)
SELECT * FROM Alunos WHERE Matricula IN (654987, 765098)
| Matricula | Nome | Sobrenome |
|---|---|---|
| 654987 | Paula | Torres |
| 765098 | Marcos | Melo |
SELECT INTO
A instrução SELECT INTO é usada para selecionar registros e campos de uma tabela e copiar o resultado retornado em uma nova tabela.
SELECT Coluna1, ..., Colunan INTO Tabela2 FROM Tabela1 WHERE <condições>
A Tabela2 será criada com os mesmos campos e relacionamentos da tabela inicial. Alguns casos são listados a seguir:
-- Faça uma cópia backup de Alunos SELECT * INTO AlunosBackup FROM Alunos; -- Faça uma cópia backup de Alunos cujo nome começa com 'Pa' SELECT * INTO AlunosBackup FROM Alunos WHERE Nome LIKE 'PA%'; -- Faça uma cópia backup de Alunos em outro banco de dados (BDCopia) SELECT * INTO AlunosBackup IN 'BDCopia' FROM ALunos; -- Cria tabela vazia novoAlunos com estrutura idêntica a de Alunos SELECT * INTO novoAlunos FROM Alunos WHERE 1 = 0;
Obs.: Aqui o teste 1 = 0 foi introduzida apenas para gerar um booleano FALSE. Nem todas as versões de gerenciadores comportam dados booleanos. Em alguns podemos usar WHERE TRUE, WHERE 1 (que são equivalentes), ou WHERE FALSE, WHERE 0 ou WHERE NOT TRUE(também equivalentes).
INSERT INTO
A instrução INSERT INTO é usada para inserir novos registros em uma tabela. Ele pode ser usado em dois formatos:
INSERT INTO Tabela1 VALUES (valor1, ..., valorn) -- ou INSERT INTO Tabela1 (campo1, ..., campon) VALUES (valor1, ..., valorn)
No primeiro caso \(n\), o número de valores inseridos deve ser igual ao número de campos da tabela e devem estar na ordem default. No segundo caso a ordem pode ser alterada mas campon) deve corresponder à valorn. Em ambos os casos o tipo de dado do campo deve ser respeitado. Por exemplo: as seguintes instruções aplicadas sobre a tabela Alunos:
-- Inserindo todos os campos INSERT INTO Alunos VALUES (854254, 'João', 'Alves', 'jalves@yahoo.com', '15-03-2004', '31 885466112') -- Inserindo alguns campos INSERT INTO Alunos (Matricula, Nome, Sobrenome) VALUES (785294, 'Marta', 'Soares')
alteraria a tabela para
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 734236 | João | Santos | joao@yahoo.com | 02-04-1998 | 61 123455667 |
| 789234 | George | Pereira | george@gmail.com | 04-04-2000 | 41 345678987 |
| 654987 | Paula | Torres | ptorres@globo.com | 25-01-2004 | 31 987854543 |
| 765098 | Marcos | Melo | mamelo@gmail.com | 25-01-2004 | 31 987843231 |
| 854254 | João | Alves | jalves@yahoo.com | 15-03-2004 | 31 885466112 |
| 785294 | Marta | Soares |
Os valores de campos não fornecidos na última instrução ficam nulos (null, inexistência de valor) ou assumem um valor default definido na construção da estrutura da tabela.
UPDATE
A instrução UPDATE é usada para alterar registros já inseridos em uma tabela. Ela tem a sintax geral:
UPDATE Tabela1 SET campo1 = valor1, ..., campon = valorn WHERE <condições>
O formato acima mostra que podemos quebrar as linhas de uma instrução SQL para torná-la mais legível. A cláusula WHERE <condições> limita quais os registros serão alterados. Sem ela todos os registros (todas as linhas da tabela) seriam alterados.
Por exemplo, podemos completar o registro relativo à aluna Marta em nossa tabela:
UPDATE Alunos SET Sobrenome = 'Alves', email = 'marta123@yahoo.com', Nascimento = '14-03-2001', fone = '21 956855441' WHERE Matricula = 785294 -- Para ver o resultado (os demais registros ficam inalterados) SELECT * FROM Alunos WHERE Matricula = 785294
O resultado seria a tabela:
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 785294 | Marta | Alves | marta123@yahoo.com | 14-03-2001 | 21 956855441 |
Novamente, se não tivéssemos especificado a condição Matricula = 785294 todos os registros, de todos os alunos seriam alterados.
Suponha que, por algum motivo, a escola tenha decido alterar o padrão de numeração das matrículas acrescentando o dígito 1 à esquerda de todas as matrículas. Isso seria o mesmo que somar 1000000 à todas as matrículas. Podemos conseguir isso com a seguinte operação:
UPDATE Alunos SET Matricula = Matricula + 1000000 -- Para ver o resultado (os demais campos ficam inalterados) SELECT Matricula FROM Alunos
| Matricula |
|---|
| 1734236 |
| 1789234 |
| 1654987 |
| 1765098 |
| 1854254 |
| 1785294 |
DELETE
A instrução DELETE permite o apagamento de registros em uma tabela. Ela tem a sintax geral:
DELETE FROM Tabela1 WHERE <condições>
O formato acima mostra que podemos quebrar as linhas de uma instrução SQL para torná-la mais legível. A cláusula WHERE <condição> limita quais os registros serão apagados. Sem ela todos os registros (todas as linhas da tabela) seriam apagadas.
Por exemplo, podemos apagar os registros relativos aos alunos com sobrenome “Alves” de nossa nossa tabela:
DELETE FROM Alunos WHERE Sobrenome = 'Alves'
Dois alunos seriam removidos da tabela que ficaria assim:
| Matricula | Nome | Sobrenome | Nascimento | Fone | |
|---|---|---|---|---|---|
| 1734236 | João | Santos | joao@yahoo.com | 02-04-1998 | 61 123455667 |
| 1789234 | George | Pereira | george@gmail.com | 04-04-2000 | 41 345678987 |
| 1654987 | Paula | Torres | ptorres@globo.com | 25-01-2004 | 31 987854543 |
| 1765098 | Marcos | Melo | mamelo@gmail.com | 25-01-2004 | 31 987843231 |
Se não tivéssemos especificado uma condição para o apagamento todos os registros seriam apagados. A linha abaixo apagaria todos os registros da tabela Alunos:
DELETE FROM Alunos
A tabela e sua estrutura continuaria existindo.
Aliases
Aliases (nomes alternativos) são usados para simplificar uma consulta. Nossa tabela de exemplo é uma tabela pequena e simples. Na prática os bancos de dados e tabelas podem conter muitos campos. A possibilidade de renomear tabelas e campos pode ser muito útil, principalmente quando a consulta envolve mais de uma tabela e a consulta se refere às tabelas e campos mais de uma vez.
Por exemplo considerando que nossa tabela está no estado da Tabela (19) a consulta
SELECT Matricula, Nome + ', ' + Sobrenome AS NomeCompleto FROM Alunos
resulta em
| Matricula | NomeCompleto |
|---|---|
| 1734236 | João Santos |
| 1789234 | George Pereira |
| 1654987 | Paula Torres |
| 1765098 | Marcos Melo |
Aqui foi feita uma concatenação das strings Nome + Sobrenome e o resultado renomeado como NomeCompleto.
Quando usamos várias tabelas de um banco de dados pode ocorrer que mais de uma delas tenha um campo com o mesmo nome. Nesse caso é obrigatória descriminar a que tabela nos referimos. A mesma consulta acima pode ser colocada na seguinte forma, com o mesmo resultado:
SELECT a.Matricula, a.Nome + ', ' + a.Sobrenome AS NomeCompleto FROM Alunos a
Aqui a tabela Alunos ganhou o alias a. a.Matricula se refere ao campo Matricula da tabela Alunos.
Agrupamentos e funções de grupos
Vamos acrescentar novas tabelas para considerar os agrupamentos. Suponha que a escola possui 4 funcionários identificados por um id único (um número de indentificação). Uma tabela armazena a relação entre id e nome (nome do funcionário). Outras tabela contém o número de horas trabalhadas por dia, para cada funcionário.
| id | dia | horas |
|---|---|---|
| 36 | ’01-03-2019′ | 6 |
| 41 | ’01-03-2019′ | 8 |
| 48 | ’01-03-2019′ | 2 |
| 58 | ’01-03-2019′ | 8 |
| 36 | ’02-03-2019′ | 5 |
| 41 | ’02-03-2019′ | 8 |
| 48 | ’02-03-2019′ | 1 |
| 58 | ’02-03-2019′ | 4 |
| id | Nome |
|---|---|
| 36 | Mariana Goulart |
| 41 | Tânia Ferreira |
| 48 | Humberto Torres |
| 58 | Francisco Pedroso |
Diversas operações são permitidas sobre as linhas de uma tabela. Em particular
| Instrução | Efeito |
|---|---|
GROUP BY |
Agrupa registros por valores do campo |
| Função | Efeito |
|---|---|
COUNT |
Conta o número de ocorrências do campo |
MAX |
Fornece o valor máximo do campo |
MIN |
Fornece o valor mínimo do campo |
AVG |
Fornece a média dos valores do campo |
SUM |
Fornece a soma dos valores do campo |
Por exemplo, para calcular o número de horas trabalhadas por todos os funcionários podemos usar a consulta
SELECT SUM(horas) as soma FROM Horas_trabalhadas
que resulta em um único registro para um único campo:
| soma |
|---|
| 42 |
Para calcular o número de horas trabalhadas por cada funcionário fazemos a soma das horas com os campos de horas agrupados por cada funcionário.
SELECT id, SUM(horas) as soma FROM Horas_trabalhadas GROUP BY id
| id | horas |
|---|---|
| 36 | 11 |
| 41 | 16 |
| 48 | 3 |
| 58 | 12 |
A consulta a seguir mostra o cálculo da média de horas trabalhadas por funcionário e de quantos dias cada um trabalhou.
SELECT id, AVG(horas) as media, COUNT(id) as numDias FROM Horas_trabalhadas GROUP BY id
| id | media | numDias |
|---|---|---|
| 36 | 5.5 | 2 |
| 41 | 8 | 2 |
| 48 | 1.5 | 2 |
| 58 | 6 | 2 |
Cláusula HAVING
A cláusula HAVING é usada para se estabelecer critérios sobre valores obtidos em funções agregadas. No SQL não é permitido usar WHERE para restringir resultados de uma consulta agregada. A consulta seguinte resultaria em erro:
SELECT id, SUM (horas)
FROM Horas_trabalhadas
WHERE SUM (horas) > 11
-- Isso geraria um erro GROUP BY id
GROUP BY id
Para esse efeito usamos HAVING, uma forma de se especificar condições sobre o resultado de uma função agregada.
SELECT id, SUM (horas) as soma FROM Horas_trabalhadas GROUP BY id HAVING soma > 11
Essa consulta gera a tabela (uma modificação da Tabela 24), satisfeita a condição soma > 11:
| id | soma |
|---|---|
| 41 | 16 |
| 58 | 12 |
Instrução JOIN
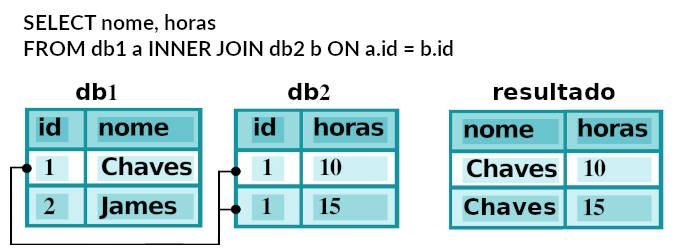
É claro que a última tabela ficaria mais fácil de interpretar se, ao invés de conter apenas ids, ela contivesse também os nomes dos funcionários. Essa informação está contida na Tabela (22): Funcionarios. A instrução JOIN serve para ler dados relacionados, gravados em mais de uma tabela. Sua forma geral é:
SELECT tabela1.campo11, tabela1.campo12, tabela2.campo21, tabela2.campo22, ... FROM tabela1 INNER JOIN tabela2 ON tabela1.id1 = tabela2.id2
Esse comando seleciona todos os campo11 e campo12 da tabela1, campo21, campo22, … da tabela2, relacionados pela condição tabela1.id1 = tabela2.id2. OS campos id1 e id2 podem ter ou não os mesmos nomes. Usando aliáses essa consulta pode ser deixada mais clara (e isso se torna mais importante para consultas mais longas envolvendos muitos campos e tabelas):
SELECT t1.campo11, t1.campo12, t2.campo21, t2.campo22, ... FROM tabela1 t1 INNER JOIN tabela2 t2 ON t1.id1 = t2.id2
Por exemplo, se quisermos uma tabela com os mesmos resultados da tabela (24) mas incluindo nomes dos funcionários fazemos
SELECT ht.id, f.Nome, SUM(horas) as soma FROM Horas_trabalhadas ht INNER JOIN Funcionarios f ON ht.id = f.id GROUP BY ht.id HAVING soma > 11
Com o resultado:
| id | Nome | soma |
|---|---|---|
| 41 | Tânia Ferreira | 16 |
| 58 | Francisco Pedroso | 12 |
Existem outros tipos de junções ou JOINs no SQL:
- (INNER) JOIN: Retorna registros com valores correspondentes nas duas tabelas.
- LEFT (OUTER) JOIN: Retorna registros da tabela esquerda (a primeira na query) e os correspondentes na tabela direita.
- RIGHT (OUTER) JOIN: Retorna registros da tabela direita e os registros correspondentes da tabela esquerda.
- FULL (OUTER) JOIN: Retorna registros quando houver correspondência em qualquer uma das tabelas.

JOINBibliografia
- Faroult, Stéphane; Robson, Peter: The Art of SQL, O’Reilly Media, Sebastopol, CA, 2006.
- Taylor,Allen: SQL For Dummies, 9th Edition John Wiley & Sons, New Jersey, 2019.
Páginas na Web:
- Sql Course: Beginner Course
- Sql Course: Advanced Course
Bem interessante como uma leitura introdutória. Gostaria de ver mais artigos sobre SQL, Phyton, etc.